UNLEASHING LARGE-SCALE VIDEO GENERATIVE PRE-TRAINING FOR VISUAL ROBOT MANIPULATION
GR-1 将。
|
序号 |
属性 | 值 |
|---|---|---|
| 1 | 论文名称 | GR-1 |
| 2 | 发表时间/位置 | 2023 |
| 3 | Code | Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation |
| 4 | 创新点 |
1:用视频生成任务作为 机器人动作学习的先验,实现通用操作知识迁移。给定过去的视频帧 + 一条语言描述,让模型预测未来的视频帧。首次证明 GPT 风格统模型一 Transformer + 视频生成预训练 可以很好地应用于视觉机器人操作任务。 2:统一 GPT 风格 Transformer 处理多模态输入。端到端多模态、多任务统一建模,避免单独训练视觉、语言、动作模块。 3:引入 [ACT] token(动作预测)、[OBS] token(视频预测)。每个时间步重复语言 token + 添加相对时间步嵌入。有效融合语言、视觉和状态信息,同时建模时间序列,保证动作预测和视频生成因果一致。 4:因果注意力 + 屏蔽机制。预训练阶段:[OBS] token 被屏蔽,模型只能看到过去帧。微调阶段:[OBS] 和 [ACT] token 被屏蔽,保证动作预测和视频生成的自回归性。保证未来帧和动作预测时不会偷看未来信息,强化时序建模能力。 |
| 5 | 引用量 | GR-1 的核心创新是给定过去的视频帧 + 一条语言描述,让模型预测未来的视频帧,结合统一 GPT 风格 Transformer 的多模态、多任务端到端建模,实现视觉机器人操作的高效学习和强零样本泛化能力。 |
一:提出问题
生成式预训练模型在语言和视觉领域中通过学习有用的表示展现出了显著的效果。本文展示了大规模视频生成预训练在视觉机器人操作上的表现。将这种 生成式预训练方法 引入机器人操作领域,让机器人通过 观看视频学习动作和环境变化,提出了GR-1模型:
-
输入多模态信息:语言指令 + 图像序列 + 机器人状态序列。
-
输出多任务结果:动作预测 + 未来图像预测(这类似“视频作为策略”的思路)。
-
端到端:从输入到动作预测和未来图像生成都是一个统一模型完成。
模型具有可迁移性,能够在规模视频上预训练,再在机器人数据上微调。具备多任务执行能力和较强的泛化能力及零样本泛化能力。首次证明 GPT 风格统模型一 Transformer + 视频生成预训练 可以很好地应用于视觉机器人操作任务。提供了一条可扩展、可迁移的机器人操作学习路线:先大规模学习视频规律,再迁移到具体操作。
二:解决方案
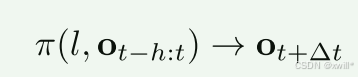
给定过去的视频帧 + 一条语言描述,让模型预测未来的视频帧。将这个任务作为生成预训练任务,训练一个模型 π 来预测时间步 t+Δt的视频帧,给定视频的语言描述 l 和从时间步 t−h 到 t 的视频帧序列 ot−h:t。
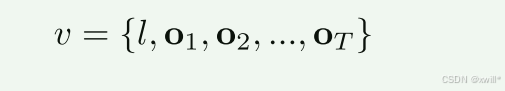
假设有一个数据集,其中每条数据包含视频及对应的语言描述。
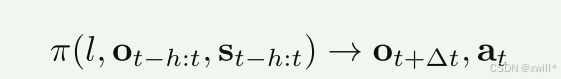
将多任务语言条件视觉机器人操作定义为:训练一个模型 π,将语言指令 l、从时间步 t−h到 t的观测图像序列 ot−h:t以及机器人状态序列 st−h:t映射到动作 at。
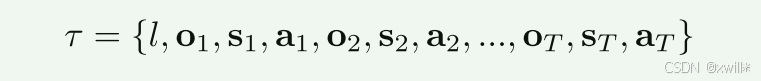
假设有一个数据集包含 N 条专家轨迹、M 个不同任务。
1 ARCHITECTURE
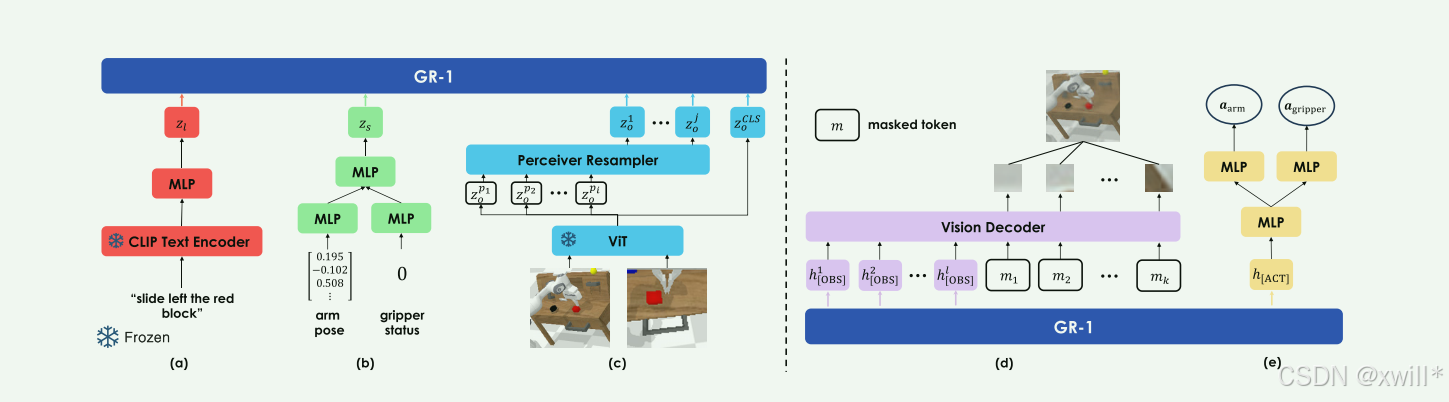
-
语言输入:使用文本编码器对语言 l编码(图 2(a)),采用 CLIP。
-
视觉输入:视觉观测 o使用 MAE 预训练的 ViT 编码(图 2(c))。
-
CLS token zCLSo作为全局图像表示
-
Patch token zp1:io 作为局部表示,经过 Perceiver Resampler(Jaegle 等, 2021)降低 token 数量。
-
-
机器人状态输入:状态 s包含末端执行器 6D 位姿 sarm∈SE和夹爪二值状态 sgripper∈{0,1},通过线性层编码(图 2(b))。
-
所有模态嵌入通过线性层对齐维度后,输入因果 Transformer。
-
动作预测:学习一个 [ACT] token 嵌入,用于预测机械臂和夹爪动作
-
视频预测:学习多个 [OBS] token 嵌入,用于预测未来帧
CLIP (Contrastive Language–Image Pretraining)
把图像和文本映射到同一个向量空间,让模型理解图像和语言之间的对应关系。
在 GR-1 中:用于把语言指令 l编码成向量,供 Transformer 使用。
把“文字”变成模型能理解的数字表示,类似“翻译成模型语言”。
MAE (Masked Autoencoder)
一种自监督视觉预训练方法,随机遮挡图像的一部分,然后让模型重建缺失部分。
在 GR-1 中:用于预训练视觉编码器(ViT),把观测图像 o编码成向量表示。
让模型学会理解图像结构和细节,即使部分信息缺失也能理解整体内容\
**CLS token 是 Class Token
ViT(Vision Transformer)中专门用来代表整个图像的全局向量。
在 GR-1 中:输出 CLS token zCLSo作为图像的全局表示,用于全局决策或作为 Transformer 输入的一部分。
把整张图压缩成一个总结向量,“一句话概括图像内容”。
**Patch token 是 ViT 将图像切成小块(patch),每块对应一个 token,保留局部信息。
在 GR-1 中:
Patch token zp1:io用于表示图像局部区域
经过 Perceiver Resampler 减少 token 数量,降低计算量
把图像拆成小拼图,每块提供局部信息
ACT token 是动作预测 token
在 GR-1 中:
用于预测机械臂连续动作(arm)和夹爪离散动作(gripper)
Transformer 输出对应的 ACT token,通过线性层映射为具体动作
每个 ACT token 就像一个“小指令”,告诉模型机器人应该怎么动
OBS token 是观测/视频预测 token
在 GR-1 中:
用于预测未来图像帧(视频生成)
Transformer 输出对应 OBS token,然后解码为图像 patch
直观理解:每个 OBS token 就像一个“小画笔”,负责画出未来图像的某个部分
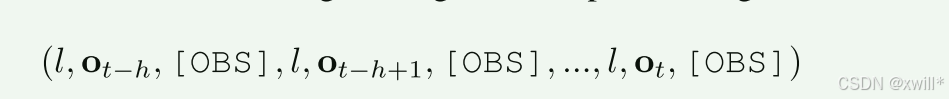
上式为视频预训练
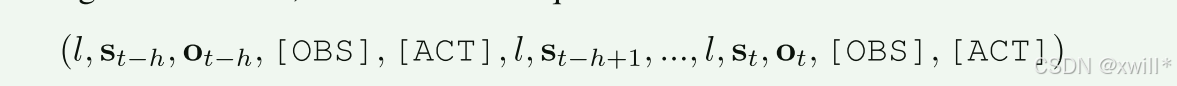
上为机器人数据微调。
给定过去的视频帧 + 一条语言描述,让模型预测未来的视频帧,这些未来帧必须符合语言描述的行为。
2 NETWORK
使用因果注意力机制(causal attention),但屏蔽 [ACT] 和 [OBS] token
-
预训练阶段:[OBS] token 被屏蔽
-
微调阶段:[OBS] 和 [ACT] token 被屏蔽
因果注意力(Causal Attention) 又叫 自回归注意力,是自注意力的一种特殊形式。每个时间步的 token 只能看到过去和当前时间步的 token,不能看到未来的 token。
3 OUTPUTS
视频预测:Transformer 解码器处理 [OBS] token 和 mask token(图 2(d)),每个 mask token 加上位置编码,用于重建图像 patch
-
损失函数 Lvideo:像素级均方误差(MSE)
动作预测:[ACT] token 输出通过线性层预测机械臂和夹爪动作(图 2(e))
-
机械臂动作连续 → Smooth-L1 损失 Larm
-
夹爪动作离散 → Binary Cross-Entropy 损失 Lgripper
4 TRAINING
阶段一:视频预训练
-
数据集:Ego4D(Grauman 等, 2022),3500 小时人-物体交互
-
每段视频裁剪 3 秒短片,总计 800,000 视频片段,约 8M 帧
-
随机采样视频序列,训练 GR-1 预测 ot+Δto**t+Δt
-
优化损失:因果视频预测损失 Lvideo
阶段二:机器人数据微调
-
随机采样机器人数据序列
-
端到端优化联合损失:
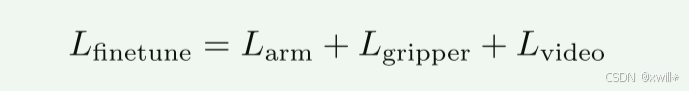
利用大规模视频生成预训练获得 通用操作表示,微调到具体机器人任务,实现 多任务、语言条件控制。
三:实验
在具有挑战性的 CALVIN 基准 和真实机器人上进行了实验。实验主要回答三个问题:
-
GR-1 在视觉机器人操作任务中是否有效?
-
GR-1 在真实机器人上是否可行?
-
GR-1 是否能应对具有挑战性的设置,包括:小数据集训练、未见场景泛化、未见物体泛化以及未见语言指令泛化?
还进行了消融实验(Ablation Studies)来理解 GR-1 不同模块对视觉机器人操作学习的贡献。四:总结
GR-1 将 大规模视频生成预训练 + 机器人微调 结合,实现多任务、语言条件视觉机器人操作模型同时预测动作和未来帧,实现端到端感知-动作建模。GR-1 是一个通过大规模视频生成预训练获得通用操作表示,并能在小数据、多任务、零样本泛化场景下高效执行视觉机器人操作的 GPT 风格 Transformer。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 32
32 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)