AQL多集合关联实战:Traits属性导入与角色-特征数据合并
AQL多集合关联实战:Traits属性导入与角色-特征数据合并
前面我们已经掌握了单集合的文档操作和高级查询,但实际业务中,数据往往分散在多个集合里——比如《权力的游戏》数据中,“角色”(Characters)的特征用字母数组存储,而字母对应的具体含义在“属性”(Traits)集合里。这篇就教你如何用AQL关联多个集合,实现“角色数据”与“属性数据”的匹配和合并,让分散的数据产生关联价值。
一、先搞懂:为什么角色特征要“引用式存储”?
在Characters集合里,每个角色的traits字段是类似["A","H","C"]的字母数组——这些字母不是随机的,而是Traits集合中“属性文档”的_key(唯一标识)。可能有人会问:为什么不直接把“strong”“loyal”这类具体标签存在角色文档里,反而要拆成两个集合?
这就要说说“引用式存储”的优势,以及“直接嵌入”的弊端:
1. 引用式存储:灵活、易维护
如果用引用式存储(角色存字母键,属性集中存在Traits集合),有三个明显好处:
- 集中管理属性:所有角色的特征标签都存在Traits里,想查现有哪些属性,直接查Traits集合就行,不用在角色数据里逐个找;
- 支持多语言:Traits集合的属性可以存双语言标签(比如英文“strong”、德文“stark”),角色文档不用管语言,只存键即可;
- 修改成本低:如果要把“strong”改成“very strong”,只需要改Traits里对应
_key的文档,所有引用这个键的角色数据都会自动生效,不用逐个修改角色文档。
2. 直接嵌入:冗余、难维护
如果把特征标签直接嵌入角色文档(比如traits: [{"en":"strong","de":"stark"}, ...]),问题会很明显:
- 数据冗余:每个角色的特征都要存完整的标签对象,重复内容多,浪费存储空间;
- 修改麻烦:如果要改某个特征的标签(比如“stark”改成“sehr stark”),需要找到所有包含这个特征的角色文档,逐个修改,效率极低。
所以,把“角色”和“属性”拆成两个集合,用引用键关联,是更合理的设计——这也是AQL多集合操作的典型场景。
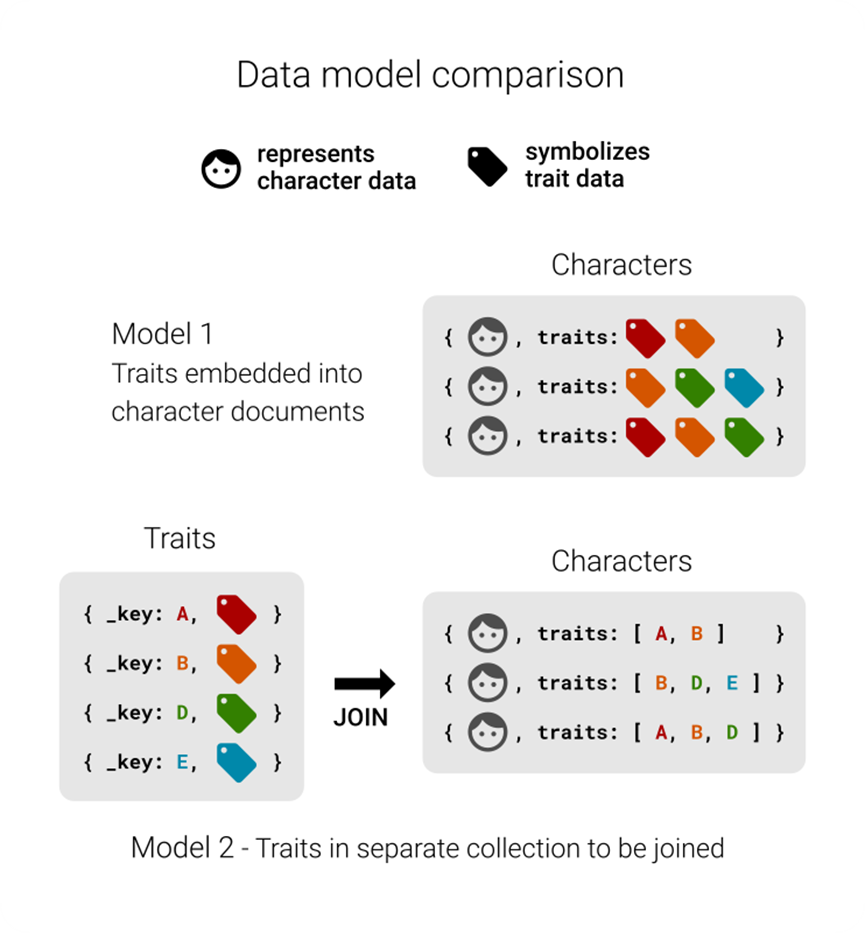
二、导入Traits属性数据(创建属性集合)
要关联两个集合,首先得有“属性集合”和数据。我们先通过Web界面创建Traits集合,再用AQL导入18个唯一属性的数据。
1. 创建Traits集合(Web界面操作)
和之前创建Characters集合的步骤类似,重点是集合名和分片数:
- 登录ArangoDB WebUI,进入之前的数据库;
- 点击“COLLECTIONS”→“Add Collection”;
- 集合名称填“Traits”,分片数设为3(和Characters保持一致,保证数据存储均衡);
- 点击“Save”,确认Traits出现在集合列表里,集合创建完成。
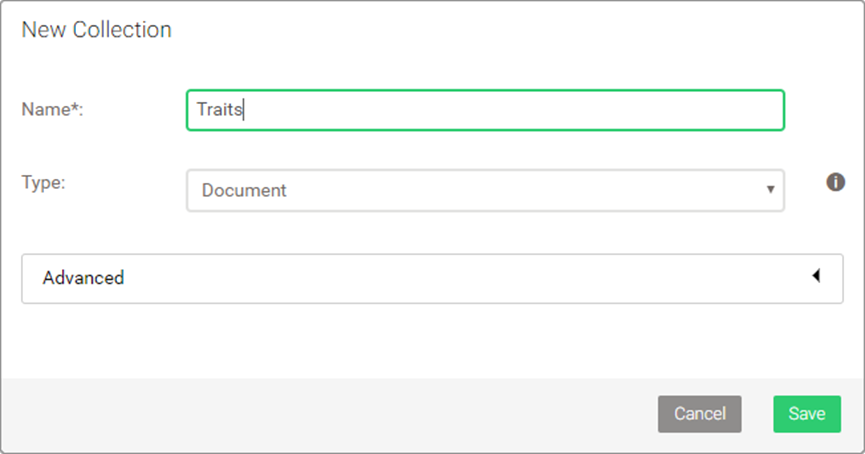
2. 用AQL批量导入属性数据
Traits集合需要存储18个属性,每个属性包含_key(对应角色traits的字母)、en(英文标签)、de(德文标签)。我们用LET定义数据变量,再用FOR循环批量插入:
LET data = [
{ "_key": "A", "en": "strong", "de": "stark" },
{ "_key": "B", "en": "polite", "de": "freundlich" },
{ "_key": "C", "en": "loyal", "de": "loyal" },
{ "_key": "D", "en": "beautiful", "de": "schön" },
{ "_key": "E", "en": "sneaky", "de": "hinterlistig" },
{ "_key": "F", "en": "experienced", "de": "erfahren" },
{ "_key": "G", "en": "corrupt", "de": "korrupt" },
{ "_key": "H", "en": "powerful", "de": "einflussreich" },
{ "_key": "I", "en": "naive", "de": "naiv" },
{ "_key": "J", "en": "unmarried", "de": "unverheiratet" },
{ "_key": "K", "en": "skillful", "de": "geschickt" },
{ "_key": "L", "en": "young", "de": "jung" },
{ "_key": "M", "en": "smart", "de": "klug" },
{ "_key": "N", "en": "rational", "de": "rational" },
{ "_key": "O", "en": "ruthless", "de": "skrupellos" },
{ "_key": "P", "en": "brave", "de": "mutig" },
{ "_key": "Q", "en": "mighty", "de": "mächtig" },
{ "_key": "R", "en": "weak", "de": "schwach" }
]
FOR d IN data
INSERT d INTO Traits
- 语句解析:
data变量是18个属性的数组,每个元素的_key是字母(A-R),en和de是对应的语言标签;FOR d IN data遍历数组,把每个属性文档插入Traits集合; - 执行验证:点击“Execute”后,响应结果为
[ ],说明所有属性都导入成功。
三、关联查询——把角色的“字母特征”解析成“具体标签”
现在Characters和Traits都有数据了,但角色的traits还是["A","H","C"]这样的字母数组,我们需要通过AQL关联两个集合,把字母换成对应的英文/德文标签——这就要用到“嵌套FOR循环+FILTER匹配”的逻辑。
1. 先看基础:只查角色的字母特征
在关联之前,我们先确认角色的traits数据:
FOR c IN Characters
RETURN c.traits
执行后会返回每个角色的traits数组(比如Ned的["A","H","C","N","P"]),这是我们要解析的原始数据。
2. 关联查询:解析字母对应的特征标签
核心思路是“三层嵌套循环”:外层遍历角色,中层遍历角色的traits字母数组,内层遍历Traits属性,最后用FILTER匹配字母和属性的_key:
FOR c IN Characters // 外层:遍历每个角色(c代表单个角色文档)
FOR key IN c.traits // 中层:遍历当前角色的traits数组(key是单个字母,如"A")
FOR t IN Traits // 内层:遍历Traits集合的每个属性文档(t代表单个属性)
FILTER t._key == key // 匹配:属性的_key等于角色的traits字母
RETURN t // 返回匹配到的属性文档(含en、de标签)
- 执行结果:会返回每个角色的每个特征对应的属性文档,比如Ned的“A”对应
{"_key":"A","en":"strong","de":"stark"},“H”对应{"_key":"H","en":"powerful",...}; - 优化说明:不用担心“三层循环会产生大量冗余数据”——ArangoDB会自动把内层
FOR+FILTER转为“索引查找”(因为_key是主键,有默认索引),效率很高,不会真的遍历所有组合。
四、数据合并——让角色文档包含解析后的特征
关联查询能拿到“角色+特征”的对应关系,但我们更希望“角色文档里直接包含解析后的特征标签”(比如Ned的traits从["A","H","C"]变成["strong","powerful","loyal"])。这时候用MERGE()函数就能实现。
1. MERGE()函数的作用
MERGE(对象1, 对象2)可以把两个对象合并成一个:如果两个对象有同名属性,对象2的属性会覆盖对象1的;如果属性不同名,会新增到合并后的对象里。我们用它来“覆盖角色原有的traits字段”。
2. 合并角色与特征的AQL语句
FOR c IN Characters // 外层:遍历每个角色文档(c)
RETURN MERGE(c, { // 合并:原角色文档c + 新的traits字段
traits: ( // 子查询:把角色的traits字母解析成英文标签
FOR key IN c.traits
FOR t IN Traits
FILTER t._key == key
RETURN t.en // 只返回英文标签,也可以换t.de要德文
)
})
- 逻辑拆解:
- 子查询部分(括号里的内容):对当前角色的每个
traits字母,匹配Traits集合的属性,返回对应的英文标签(如把"A"变成"strong"),最终生成一个“标签数组”; MERGE(c, { traits: 标签数组 }):用子查询生成的“标签数组”覆盖角色原有的traits字母数组,其他属性(如name、age)保持不变;
- 子查询部分(括号里的内容):对当前角色的每个
- 执行结果:返回的角色文档中,
traits字段已经是解析后的标签数组,比如Ned的traits变成["strong","powerful","loyal","rational","brave"],更直观易读。
五、关键注意事项与扩展
- 索引优化:如果关联的不是
_key(比如用其他自定义属性匹配),一定要给“匹配属性”加“持久化索引”(Persistent Index)——比如如果用t.code替代t._key,就给code字段加索引,否则查询会变慢;如果属性值唯一,还可以设unique: true(唯一索引)。 - 灵活切换语言:想返回德文标签,只需把子查询里的
t.en换成t.de;想同时返回双语言,可写成RETURN { en: t.en, de: t.de },子查询会生成[{en:"strong",de:"stark"},...]的数组。 - 适用场景扩展:这种“嵌套FOR+FILTER+MERGE”的逻辑,不仅能关联“角色-属性”,还能关联任意两个有“键值对应关系”的集合(比如“订单-用户”“商品-分类”),是AQL多集合操作的核心思路。
六、小结
这篇我们完成了AQL多集合操作的核心流程,总结一下关键点:
- 数据拆分的意义:把“角色”和“属性”拆成两个集合,用引用式存储更易维护、更灵活;
- 关联的核心逻辑:嵌套
FOR循环遍历多个集合,用FILTER匹配关联键(如_key); - 合并的关键函数:
MERGE()能把解析后的特征标签合并到角色文档里,让结果更直观; - 效率保障:关联
_key时不用手动加索引(默认有主键索引),关联其他属性要记得加索引。
掌握多集合关联后,你就能处理更复杂的数据场景了。下一篇我们会进入ArangoDB的“图模型”实战——用边集合存储角色的家庭关系,实现“查父母、查子女”的图遍历查询!
注意:本文仅代表个人学习记录,如需生产环境级方案,请咨询艾体宝团队。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)