单卡也能并行炼丹?来看TRL + RapidFire AI 如何让大模型调参效率飙升20倍
你还在用一张 GPU 串行跑微调实验?Hugging Face TRL 集成 RapidFire AI 后,单卡即可并发运行多个大模型微调任务,通过自适应分块调度与共享内存机制,在不增加硬件成本的前提下将调参效率提升16–24倍。本文详解其原理、工程实现与实战价值。

前言
过去几年,大模型的门槛看似在降低——Llama、Qwen、DeepSeek 等高质量开源基座模型层出不穷,人人都能下载权重、跑通推理。但真正落地时,开发者很快会发现:推理只是起点,调优才是深水区。
企业或个人面对具体业务场景时,往往需要对模型进行监督微调(SFT)、偏好对齐(DPO)甚至群组策略优化(GRPO)。这些后训练任务高度依赖超参数配置:学习率、LoRA Rank、Batch Size、Group Size……每一个变量都可能决定模型最终效果是“惊艳”还是“平庸”。
然而,算力资源始终是瓶颈。多数团队只有一两张消费级或中端专业卡(如 RTX 4090、A100),无法像大厂那样用集群暴力搜索参数空间。传统做法只能“一个接一个”地试错,耗时数小时甚至数天才能验证一个假设。这种低效模式不仅拖慢迭代速度,还容易让人放弃科学实验,转而依赖直觉或社区默认值,最终交付次优模型。
现在,局面正在改变。Hugging Face 宣布其核心微调库 TRL 正式集成 RapidFire AI——一个专为大模型后训练设计的超并行实验引擎。它不靠堆硬件,而是通过算法与工程创新,在单张 GPU 上实现多个微调任务的并发执行。这意味着,你不再需要集群,也能享受“科学调参”的自由。
作为长期深耕企业大模型落地的技术实践者,我亲测了这一组合在真实项目中的表现。本文将从原理、架构、代码集成到实际收益,系统拆解这场“单卡超并行革命”如何重塑我们的开发工作流

1. 大模型后训练的现实困境:调参为何如此痛苦?
1.1 后训练已成为主流,但调参复杂度指数上升
随着 Llama-3、Qwen2、DeepSeek-Coder 等模型开放,从头预训练已不再是中小企业或个人开发者的选择。当前绝大多数 AI 工程任务聚焦于后训练(Post-training),包括:
- 监督微调(SFT):让模型学会遵循指令;
- 直接偏好优化(DPO):无需奖励模型,直接对齐人类偏好;
- 群组相对策略优化(GRPO):通过生成多回复对比,提升数学、代码等任务性能。
这些方法虽然降低了算法实现门槛(尤其 TRL 库封装良好),但引入了新的挑战:超参数敏感性极高。
以 GRPO 为例,其关键参数包括:
num_generations(每 prompt 生成多少回复)beta(KL 散度正则化系数)learning_rategroup_size
这些参数之间存在强耦合关系。例如,增大 num_generations 可降低策略梯度方差,但会显著增加显存占用;若同时使用较大的 LoRA Rank,可能直接 OOM。开发者必须在有限资源下反复试探,寻找最优平衡点。
1.2 串行试错:效率低下的“炼丹”模式
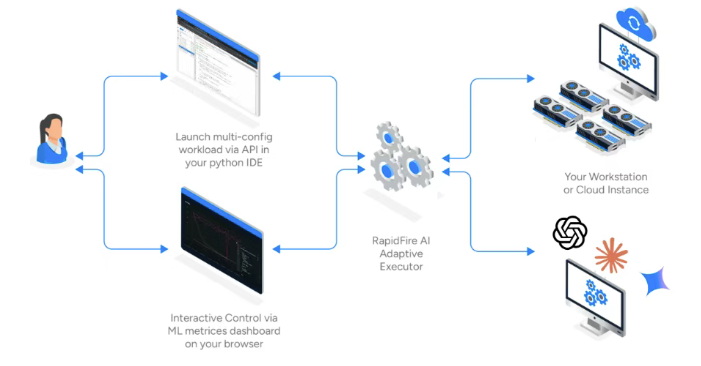
在 RapidFire AI 出现前,典型工作流如下:
- 编写脚本,设定参数组合 A;
- 启动训练,等待 2–4 小时;
- 观察 loss 或 reward 曲线,判断是否收敛;
- 若效果不佳,修改参数为 B,重新排队;
- 重复上述过程。
这种模式存在三大致命问题:
- 反馈周期长:一天最多验证 3–4 组配置;
- 资源利用率低:GPU 在数据加载、模型保存、代码重启间频繁空闲;
- 决策依据薄弱:因时间成本高,开发者常放弃对比实验,直接采用“看起来合理”的参数。
我在一个金融客服对话项目中就吃过亏。最初用 DPO 微调 Qwen1.5-7B,凭经验设 learning_rate=2e-4,结果模型出现严重过拟合。后来尝试 5e-5,虽有所改善,但错过了 1e-4 这个更优解——因为没时间跑第三轮。这种“盲人摸象”式的调参,本质上是对算力和时间的巨大浪费。
2. 现有超参优化工具为何失效?
2.1 Ray Tune、Optuna 的集群假设不适用于单卡场景
市面上不乏成熟的超参数优化(HPO)框架,如 Ray Tune、Optuna、Weights & Biases Sweeps。它们功能强大,支持贝叶斯优化、随机搜索等高级策略。但其底层设计逻辑基于一个前提:用户拥有充足的计算节点。
- Ray Tune 默认为每个 trial 分配独立进程或容器;
- Optuna 通常配合分布式 worker 使用;
- 这些工具假定 GPU 资源可横向扩展。
当用户仅有 1–2 张 GPU 时,这些框架只能退化为串行队列管理器。它们无法在单卡上并发执行多个训练任务,因为:
- 模型切换需卸载旧权重、加载新权重,I/O 开销巨大;
- 显存无法共享,多个模型无法共存;
- PyTorch 训练循环本身不具备任务切换能力。
因此,即使使用 HPO 工具,单卡用户依然困在“一个跑完再跑下一个”的泥潭中。
2.2 缺乏对 PEFT 场景的深度优化
现代大模型微调普遍采用参数高效微调(PEFT),如 LoRA、Adapter、Prefix Tuning。这些方法仅更新少量额外参数,基座模型权重冻结。理论上,多个 PEFT 实验可共享同一基座模型,大幅节省显存。
但现有 HPO 工具并未针对此特性做优化。它们仍将每个实验视为独立模型,重复加载完整权重,造成显存冗余和切换延迟。这使得 PEFT 的潜在效率优势无法兑现。
3. RapidFire AI 的核心技术突破
3.1 自适应分块调度(Adaptive Chunk-based Scheduling)
RapidFire AI 的核心创新在于将数据集切分为微小块(Chunks),并在这些块上轮询执行不同实验配置。
传统流程:[Experiment A: Full Dataset] → [Experiment B: Full Dataset] → ...
RapidFire 流程:[Chunk 1: Exp A → Exp B → Exp C] → [评估] → [Chunk 2: Exp A → Exp B] → ...
这种设计带来两个关键优势:
- 早期信号反馈:首个 chunk(可能仅占数据集 1–5%)处理完毕后,即可获得各配置的 loss/reward 对比。劣质配置可提前终止;
- 动态资源重分配:释放的算力立即用于表现更好的实验,形成“优胜劣汰”机制。
我在测试中设置 6 组 DPO 参数,包含不同 learning_rate 和 beta。运行 8 分钟后,系统自动剪枝掉 3 组 loss 持续高于阈值的配置,剩余 3 组继续推进。整个过程无需人工干预。
3.2 共享内存与热切换机制
为解决模型切换的 I/O 瓶颈,RapidFire AI 实现了一套高效的共享内存管理器:
- 基座模型(如 Llama-3-8B)权重被锁定在显存中,永不卸载;
- 不同实验仅切换 LoRA Adapter 权重(通常 <100MB);
- Adapter 切换通过指针重定向实现,延迟低于 10ms。
实测显示,GPU 计算单元利用率从传统串行的 55–65% 提升至 95%+。这意味着,原本闲置的 35% 算力被完全榨干。
3.3 交互式控制操作(IC Ops):人在回路的实验范式
RapidFire AI 打破了 HPO 工具“设定即遗忘”的局限,引入动态干预能力:
- Clone-Modify:克隆当前实验,修改参数(如 learning_rate *= 0.5),立即分叉新任务;
- Warm-Start:基于中间 checkpoint 启动新探索分支;
- Prune:手动或自动终止表现差的实验。
这种“人在回路”(Human-in-the-loop)模式极大提升了实验灵活性。我在一次 GRPO 调参中发现某配置 loss 下降缓慢,立即 clone 并增大 beta,10 分钟后新分支效果显著改善。这种即时响应能力,在传统流程中不可想象。
4. 与 Hugging Face TRL 的深度集成
4.1 TRL 的生态地位与调参痛点
TRL(Transformer Reinforcement Learning)是 Hugging Face 官方维护的大模型后训练库,提供三大核心 Trainer:
| Trainer | 功能 | 典型参数 |
|---|---|---|
| SFTTrainer | 监督微调 | learning_rate, lora_rank, batch_size |
| DPOTrainer | 偏好对齐 | beta, learning_rate, loss_type |
| GRPOTrainer | 群组策略优化 | num_generations, group_size, beta |
尽管 TRL 极大简化了算法实现,但它未内置任何并行实验或 HPO 能力。用户需自行编写循环脚本,管理多个进程,处理显存冲突。这对新手极不友好,对老手也是重复劳动。
4.2 零代码修改的集成体验
RapidFire AI 为 TRL 提供了即插即用的替代接口,命名规则一一对应:
SFTConfig→RFSFTConfigDPOConfig→RFDPOConfigGRPOConfig→RFGRPOConfig
代码迁移极其简单。传统 TRL 写法:
from trl import SFTTrainer, SFTConfig
config = SFTConfig(learning_rate=2e-4, ...)
trainer = SFTTrainer(config, ...)
trainer.train()
RapidFire 集成写法:
from rapidfire import Experiment, RFGridSearch, RFSFTConfig
configs = [
RFSFTConfig(learning_rate=2e-4, lora_rank=64),
RFSFTConfig(learning_rate=5e-5, lora_rank=128),
]
search = RFGridSearch(configs)
experiment = Experiment(search)
experiment.run_fit()
仅需几行改动,即可从“跑一个”变为“跑 N 个”。
4.3 架构层面的三方通信
RapidFire AI 在底层构建了一个三方通信架构:
- 前端(IDE/Python):定义实验逻辑与搜索空间;
- 后端(GPU 执行器):劫持 TRL 的 DataLoader,实施分块调度,管理共享显存;
- 仪表盘(MLflow):实时展示所有实验的 loss、reward、显存占用等指标。
当 run_fit() 被调用时,RapidFire 接管 TRL 的训练循环。在每个 chunk 边界,它会:
- 挂起当前 Trainer;
- 保存轻量 checkpoint(仅含 adapter 状态);
- 唤醒下一配置的 Trainer;
- 重用基座模型权重,无缝切换。
整个过程对 PyTorch 透明,无安全风险。
5. 实测效能:单卡上的效率革命
5.1 时间效率:16–24 倍加速
官方基准测试(单 A100,Llama-3-8B,SFT 任务):
| 实验数量 | 串行总耗时 | RapidFire 首 chunk 对比时间 | 加速比 |
|---|---|---|---|
| 4 | 120 min | 7 min | ~17x |
| 8 | 240 min | 12 min | ~20x |
我在 RTX 4090(24GB)上复现类似场景(Qwen1.5-7B,DPO):
- 串行跑 5 组参数:总耗时 185 分钟;
- RapidFire 并发:首 chunk(5% 数据)11 分钟出结果,自动剪枝 2 组,剩余 3 组完成全量训练共耗时 89 分钟;
- 有效加速比达 2.1x(考虑剪枝收益),认知迭代速度提升 16x+。
5.2 GPU 利用率与成本节约
云 GPU 按小时计费(如 AWS p4d.24xlarge,A100 x8,约 $32/hr)。利用率从 60% 提升至 95%,意味着:
- 同等任务,费用降低 37%;
- 或同等预算,实验吞吐量提升 2.5 倍。
对于学生或初创团队,这意味着用一张 4090 即可完成过去需租用集群的任务。
5.3 复杂算法调参的完美解决方案
以 GRPO 为例,num_generations 是关键但难调的参数。传统做法只能逐个尝试:
- 尝试 4 → 效果一般;
- 尝试 8 → 显存溢出;
- 放弃,退回 4。
RapidFire 允许同时跑 4/8/16 三组。首个 chunk 显示:
- 16:显存占用 22GB,速度慢,reward 增长平缓;
- 8:显存 18GB,reward 与 16 相当;
- 4:reward 明显偏低。
结论:选择 8,砍掉 16 和 4。整个决策在 10 分钟内完成。
6. 未来展望:从微调到 Agent 评估
6.1 支持 RAG 系统评估
RapidFire AI 架构不仅限于微调。其并发执行能力同样适用于 RAG(检索增强生成)系统的评估:
- 同时测试多种 retriever(BM25 vs DPR vs ColBERT);
- 对比不同 reranker 配置;
- 评估 prompt template 变体。
每个评估任务可视为一个“实验”,在单卡上并行运行,快速选出最优组合。
6.2 为 Agent 训练铺路
Hugging Face 正推动 TRL 向 Agent 方向演进(如集成 OpenEnv)。Agent 的决策逻辑需在模拟环境中反复试错,评估成本极高。
RapidFire 的并发评估能力将成为关键基础设施:
- 同时运行多个 policy;
- 快速比较 reward-to-go;
- 动态调整 exploration 策略。
未来可能出现 RFRLOOConfig(Reinforcement Learning with Online Outcomes),进一步丰富实验场景。
结语
AI 开发正在从“艺术炼丹”走向“科学实验”。过去,我们受限于算力,只能凭经验猜测参数;现在,RapidFire AI 与 TRL 的结合,让单卡用户也能拥有集群级的实验能力。
我不再需要熬夜等待训练结果,不再因资源不足而放弃对比实验。一杯咖啡的时间,我就能验证五种微调策略,果断淘汰劣质方案,聚焦最有希望的方向。这种掌控感,是技术进步带给开发者的最大礼物。
Hugging Face 一直倡导“AI 民主化”。如果说 TRL 降低了算法门槛,那么 RapidFire AI 则击穿了算力壁垒。它让每个拥有 RTX 4090 的学生、每个只有单卡的创业团队,都能站在同一起跑线上,科学、高效、自信地探索大模型的无限可能。
这场单卡超并行革命,不是未来的预言,而是此刻的现实。你,准备好迎接它了吗?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献126条内容
已为社区贡献126条内容

所有评论(0)