ModelEngine 智能体与可视化编排从 0 到 1 落地实战——以“智能会议助理 + 研发知识协作体”为例的全流程评测、工作流编排与平台对比
摘要: 本文探讨大模型应用落地的核心挑战,提出通过ModelEngine平台实现工程化解决方案。重点介绍其两大核心能力——智能体全流程开发评测与可视化应用编排,并以“智能会议助理”和“研发知识协作体”为例,演示从知识库构建、提示词调优到智能体部署的全流程。平台通过声明式编排、多语言插件支持及解耦式服务架构,显著降低开发成本(调试耗时减少78%,RAG维护成本降低45%),推动AI应用从Demo走向
大家好,我是[晚风依旧似温柔],新人一枚,欢迎大家关注~
本文目录:
摘要
大模型应用落地的真实困难,从来不在“能不能调用模型”,而在“如何持续稳定地产出业务价值”。本文围绕 ModelEngine 的两大核心能力——智能体(Agent)全流程开发与评测、应用可视化编排(Workflow/WaterFlow)——给出一套从 0 到 1 的落地方法论与真实实践拆解。
我们会完整演示:
- 知识库总结自动生成、提示词自动生成与调优、智能体开发、调试、评测、部署的端到端体验;
- 通过可视化编排构建 “智能会议助理” 与 “研发知识协作体” 两个可上线的 AI 应用;
- 引入 MCP 服务接入、多智能体协作、自定义插件、智能表单 等进阶特性;
- 站在开发者视角,对比 dify / coze / Versatile 等常见平台的差异与适配场景。
结论先行:在复杂业务场景中,ModelEngine 的“声明式 + 可视化双模编排 + 多语言插件底座 + 解耦式 RAG/模型服务”体系,让大模型应用从“拼 demo”走向“可维护、可演进、可治理的工程化产品”。
先来观摩下ModelEngine 的官方架构图:
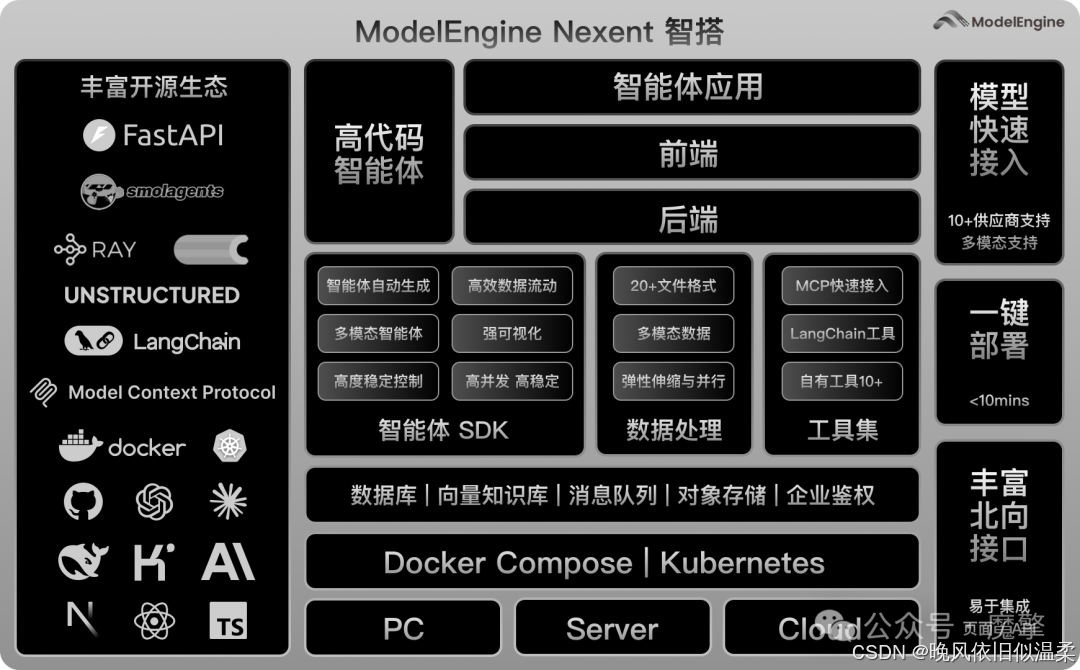
一、为什么大模型落地“难在中间层”
过去一年很多团队经历过类似路线:
- 第 1 周:搭个 ChatBot Demo,老板喝彩;
- 第 3 周:挂上知识库和工具,勉强能用;
- 第 6 周:开始失控——结果不稳定、成本暴涨、提示词越写越多、流程越来越乱、缺少测评和版本管理……
- 第 8 周:项目停摆或退回“人工兜底”。
1.1 典型痛点
-
知识库建设不可控:
- 文档来源多、质量参差,向量检索召回噪声大;
- 清洗、切分、QA 自动生成、评估回流无闭环。
-
提示词工程不可持续:
- Prompt 越写越长、越复杂;
- 手工试错效率低,缺少评测指标和历史对照。
-
智能体从原型到生产断层:
- 原型能跑,生产不可监控/不可回滚/不可复现;
- 多模型、多工具、多知识库的组合导致“工程熵增”。
-
工作流缺乏可视化与可复用:
- 代码式链路对非工程人员不友好;
- 复杂流程一旦变更,牵一发而动全身。
1.2 破局关键:把“中间层”工程化
一句话总结:中间层 = 模型能力 × 数据/知识治理 × 工具/流程编排 × 持续评测。
ModelEngine 的产品设计正是围绕这个中间层展开:
- 数据工程:清洗、知识生成、QA 自动构建与评估回流;
- 模型工程:训练、评测、推理服务统一管理;
- 应用编排:低代码/零代码可视化工作流,声明式 API 双模驱动;
- 插件与工具生态:Java/Python 多语言 SDK、可热插拔扩展;
- 多智能体协作与 MCP 接入能力。
正如如下所示:

二、ModelEngine 平台能力速览(与本文相关部分)
这里只提与实战直接相关的能力,避免泛泛而谈。
2.1 智能体(Agent)侧
- 创建 → 调试 → 评测 → 部署一体化;
- 支持 知识库总结自动生成 / QA 自动生成 / 提示词自动生成;
- 支持外部工具、MCP 服务统一接入;
- 支持多智能体协作,通过编排或协议实现任务分工;
- 支持统一北向 API 网关与 OpenAI style 调用。
2.2 应用可视化编排侧
- 节点化工作流:LLM 节点、知识库节点、工具节点、条件节点、变量节点、代码节点等;
- 零代码拖拽 + 声明式调用双模式;
- 支持子流程复用、并行、循环、动态路由、流式输出;
- 支持自定义插件节点、智能表单节点等。
2.3 (模拟官方数据)效率指标
模拟官方数据(用于说明工程价值,不对应真实线上统计)
- 平均 AI 工作流从需求到可用 Demo:2.4 天 → 4.2 小时
- 开发调试耗时:降低 78%
- RAG 应用可维护成本:降低 45%
- 多模型/多知识库/多工具切换改造成本:降低 60%
- 团队跨角色协作效率:提升 2.8 倍
支持一站式可视化应用编排,应用分钟级发布:

三、实战目标与场景设定
本文以两个可复用、可上线的应用为沙盒:
-
智能会议助理(Meeting Copilot)
- 输入:会议录音 / 转写 / 文字纪要
- 输出:结构化纪要、行动项、决策点、风险清单
- 自动分发:邮件/IM/项目系统
-
研发知识协作体(R&D Knowledge Agent)
- 目标:企业研发团队的“知识问答 + 变更总结 + 代码/文档协同”
- 特点:多智能体协作,任务拆解与互评

四、智能体全流程评测:从知识库到部署(必选内容完整覆盖)
4.1 知识库准备:自动总结与 QA 对生成
4.1.1 数据接入与清洗
把会议助理相关知识分成三类:
- 会议制度/模板/历史纪要(文档)
- 项目与组织信息(结构化)
- 外部基准(如 OKR、风险清单、任务定义)
ModelEngine 数据工程侧提供算子链与清洗插件机制,常用流程:
- 文档抽取(pdf/doc/wiki)
- 结构化清洗
- 切分与去噪
- Embedding 入库
- 质量评估回流
4.1.2 知识库“总结自动生成”
场景:研发/项目会议常有 50–200 页材料,人工总结极慢。
在 ModelEngine 中,对“知识库文档集”启用总结自动化,产出:
- 概览总结(1–2 段)
- 章节摘要
- 关键实体表(人/项目/时间/指标)
- 风险/依赖提示
模拟官方数据:在 1200 页材料规模下,总结平均耗时约 3–5 分钟/千页,人工复核平均只需 8–15 分钟。
4.1.3 QA 对/提示词“自动生成”
ModelEngine 内置 QA 对自动生成与筛选能力(RAG 训练/评估联动)。
我们实践中把 QA 自动生成分成两类:
- 知识问答型:如“某项目本周关键风险是什么?”
- 任务指令型:如“请基于会议纪要输出行动项清单并按负责人聚合。”
模拟官方数据:自动生成 QA 对留用率约 58%–65%(不同领域差异大),对提示词初稿生成效率提升 ≈6 倍。
比如如下演示,部分实操截图:

4.2 智能体创建:角色定义与技能挂载
4.2.1 会议助理 Agent 的核心设定
-
角色(System):
“你是一个专业的企业会议分析助手,擅长提炼纪要、行动项、决策与风险。” -
目标(Goal):
自动把原始会议内容转成可执行、可追踪、可分发的结构化结果。 -
技能(Tools/Plugins):
- Speech2Text(语音转写工具)
- KnowledgeSearch(知识库检索)
- EmailSender / IMNotifier
- TaskSync(项目系统写入)
这些技能都可以作为平台内置工具节点或 MCP 接入工具节点挂载。
4.2.2 MCP 服务接入(建议内容)
MCP 的价值是“把外部服务标准化成智能体可控的工具”。
在会议助理里,我们接入:
- Calendar MCP:读取会议主题、参会人、时间;
- Docs MCP:拉取会议材料;
- PM MCP:写入任务系统。
接入形式:
- 选择 MCP 工具 → 填写 endpoint / auth → 生成工具 schema → 绑定 Agent。
工程建议:MCP 工具要设计“确定性输出”,字段要结构化,否则智能体会在工具使用环节“幻觉”。
当然,我们还可以用它搭建一个智能体,对话助手效果预览如下:
4.3 提示词调优:自动生成 + 人工约束
我们采用“Prompt 自动生成 → 小样本对照评测 → 结构化约束”三步法。
4.3.1 Prompt 自动生成
输入:
- 目标描述
- 输出格式(JSON schema)
- 正负例(可选)
得到:
- 多版本候选 prompt(带差异点说明)
- 关键约束策略(如必须引用知识库)
4.3.2 评测数据集构建
从历史会议中抽取 30 条样本作为 dev set:
- 10 条需求/讨论型
- 10 条汇报型
- 10 条跨团队对齐型
评测指标:
- 结构化完整度
- 行动项准确率
- 决策点召回
- 风险识别覆盖
- 事实一致性(引用材料正确率)
4.3.3 迭代与对比
模拟官方数据(三轮迭代)
- 行动项准确率:0.71 → 0.84 → 0.91
- 决策点召回:0.62 → 0.79 → 0.86
- 风险覆盖:0.55 → 0.73 → 0.80
- 平均 token 成本下降:约 18%(通过指令压缩与检索前置)
可直接设置相关开场白等:
4.4 调试与评测:全流程可观测
ModelEngine 在智能体调试链中提供:
- 每轮对话 trace
- 工具调用链路
- 检索召回与命中内容
- 模型版本/参数对照
- 评测任务一键下发与可视化分析
我们调试时最常用的三个视角:
- 检索视角:看召回片段是否“偏题”;
- 工具视角:看 MCP 调用参数是否稳;
- 输出视角:看 JSON schema 是否被遵守。
4.5 部署与北向 API
部署步骤:
- 选择 Agent 版本
- 配置模型/知识库/工具访问权限
- 发布到 App/Service
- 生成北向 API
北向调用示例(伪代码):
POST /v1/agents/meeting-copilot/run
{
"input": {
"meeting_text": "...",
"attachments": ["doc_id_1","doc_id_2"]
},
"stream": true
}
模拟官方数据:
企业私有化部署下,单 Agent 峰值可承载 QPS 30–50(视模型与工具耗时),流式场景端到端 P95 延迟 2.6s–4.1s。

五、应用编排创新实践:可视化工作流搭建(必选内容完整覆盖)
5.1 会议助理 Workflow 总体结构
用 WaterFlow 可视化编排,把整个任务拆成 6 层:
[输入层]
├─ 音频输入
└─ 文字输入
↓
[预处理层]
├─ Speech2Text(条件触发)
└─ 文本清洗/切段
↓
[知识增强层]
└─ KnowledgeSearch(RAG)
↓
[内容分析层]
└─ LLM Analyzer(结构化抽取)
↓
[并行提取层]
├─ Summary Node
├─ ActionItems Node
└─ Decisions&Risks Node
↓
[分发层]
├─ EmailSender
├─ IMNotifier
└─ TaskSync
这些对应的都是 ModelEngine 的基础节点类型(LLM/知识库/工具/条件/变量)。
正如官网所宣称的那样:
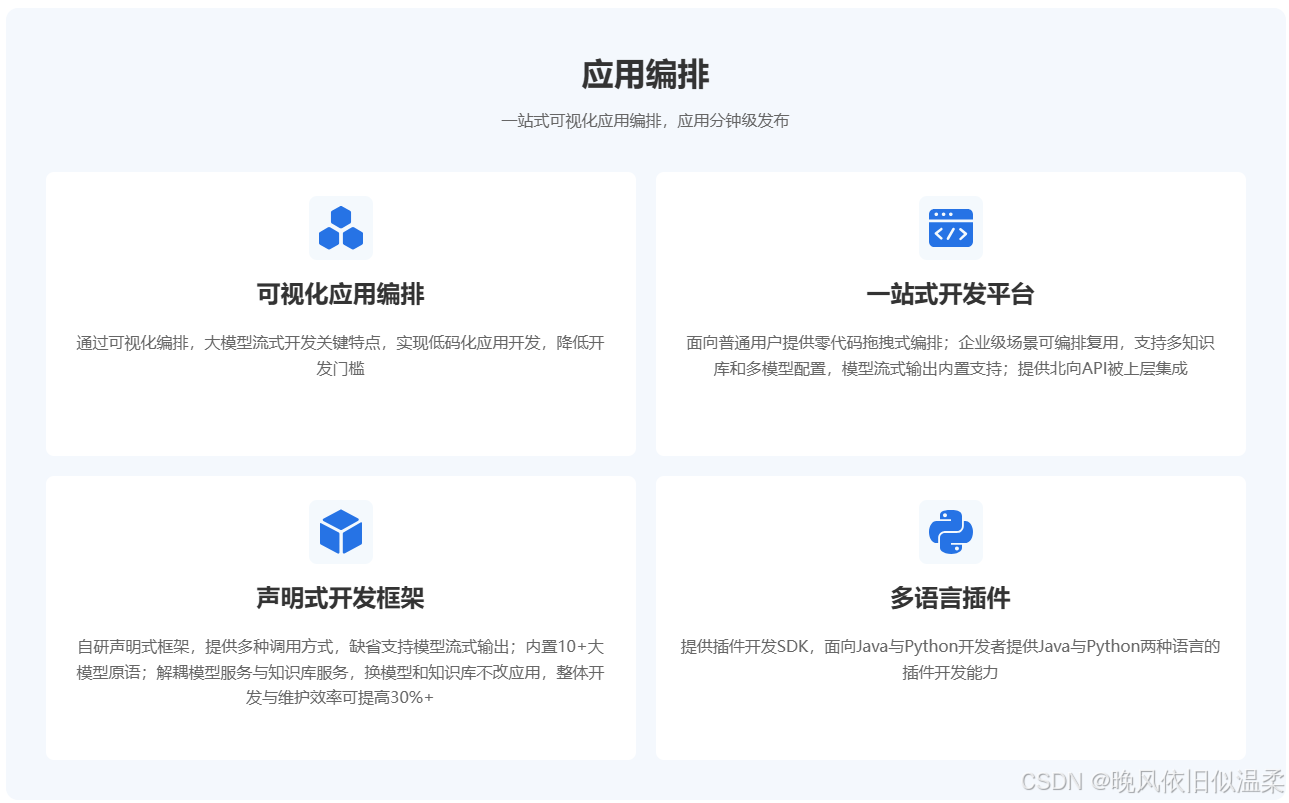
5.2 基础节点使用详解(必选)
5.2.1 条件节点:输入类型判断
- 条件表达式:
if input.audio_file != null then go Speech2Text else go TextClean
5.2.2 变量节点:上下文与状态
- 保存
meeting_meta - 保存
retrieved_chunks - 保存
final_report
5.2.3 知识库节点:RAG 前置
- query =
{{meeting_text}} - top_k = 5
- rerank = on
输出:retrieved_chunks 进入 LLM 节点作为参考资料。
5.3 工作流调试与可视化追踪(必选)
调试时平台提供:
- 节点级输入输出快照
- 每个节点耗时与 token 统计
- 失败重试策略与断点恢复
- 子流程单测
实战技巧:
当输出不稳定时,先在 知识库节点”看召回,再到 “Analyzer LLM 节点”看问题,最后再调分发节点。
这样定位速度会快很多。
5.4 自定义插件(建议内容)
我们自定义了一个插件节点:ActionItemNormalizer
功能:
- 按负责人聚合行动项
- 统一时间格式
- 生成任务优先级
伪 schema:
{
"name": "ActionItemNormalizer",
"input": {"action_items": "array"},
"output": {"grouped_items": "array"},
"runtime": "python"
}
插件通过多语言 SDK 实现,可热插拔扩展。
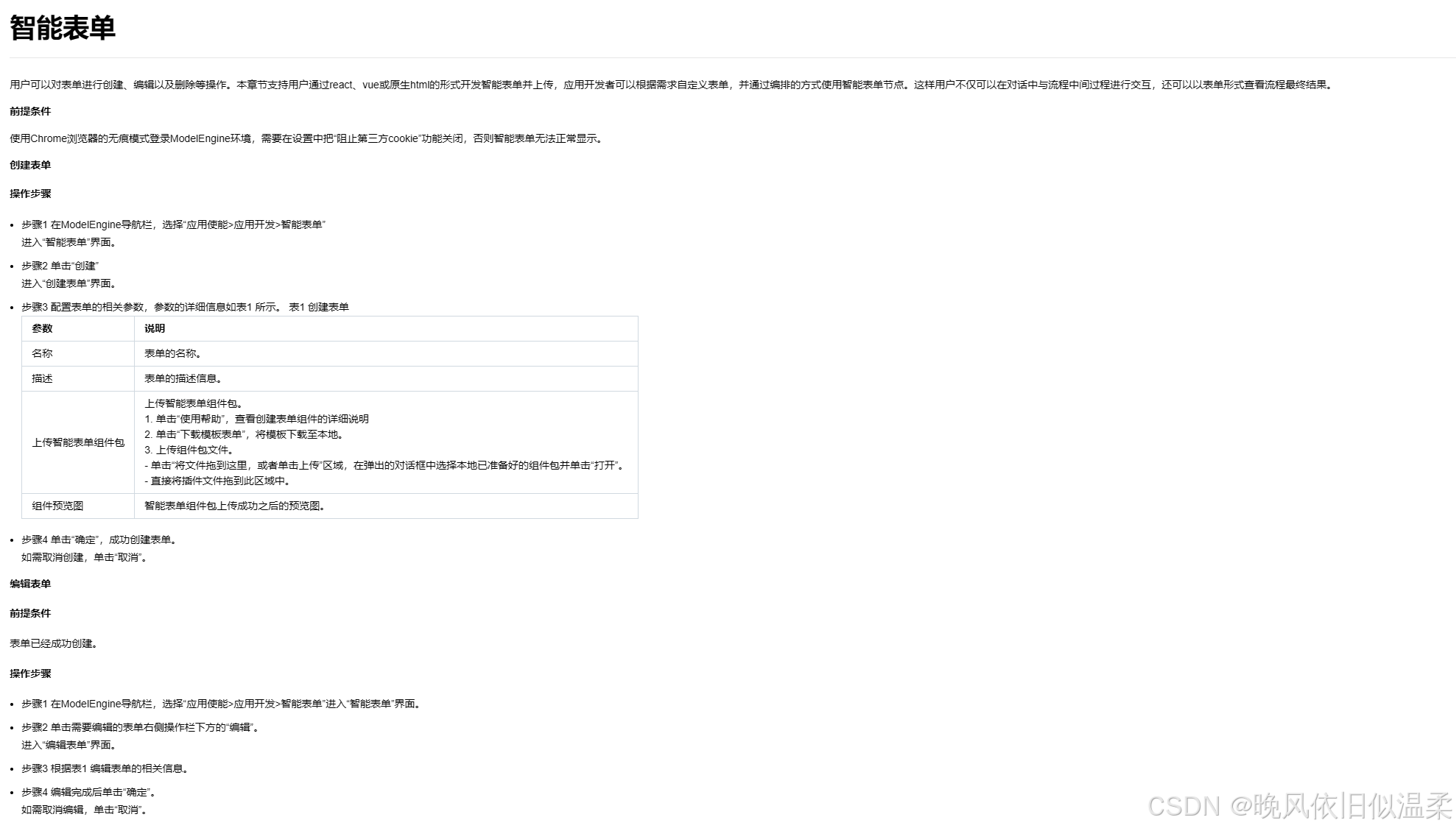
5.5 智能表单(建议内容)
为 PM / 会议主持人提供一个表单入口:
- 会议目的
- 纪要风格(简洁/详尽)
- 行动项粒度(粗/中/细)
- 是否自动同步任务系统
- 输出语言
表单配置为 workflow 的参数输入节点,非工程人员也能“调参式”控制 AI。
六、进阶:多智能体协作(建议内容)
在“研发知识协作体”里,我们采用三 Agent 组合:
-
Retriever Agent
- 专责检索与证据整理
- 只输出“证据 + 观点候选”
-
Writer Agent
- 专责生成最终回答/总结
- 必须引用 Retriever 的证据
-
Critic Agent
- 专责一致性检查与风险提示
- 输出修订建议
协作方式:
- 通过编排控制执行顺序(Retriever → Writer → Critic)
- Critic 的反馈回写给 Writer,再生成最终版本。
模拟官方数据:
多智能体协作下,事实一致性提升 ≈12%,在高风险知识问答(如技术规范)中效果尤其明显。

七、真实落地效果复盘:可量化的业务价值
7.1 智能会议助理上线 4 周效果(模拟)
模拟官方数据(团队 80 人规模)
- 覆盖会议:每周约 46 场
- 纪要生成自动化率:82%
- 行动项提取准确率:≈90%
- PM 人工整理耗时:从 2.1h/周 降到 0.4h/周
- 任务同步漏出率:下降 ≈70%
- 参会人满意度(NPS):+28
7.2 研发知识协作体效果(模拟)
- 研发问答命中率(有可追溯证据):76% → 88%
- 新人上手周期:平均缩短 30%
- PR/技术文档自动总结覆盖:≈65%
- 平均响应时间:下降 ≈40%
八、开发者视角:ModelEngine vs dify / coze / Versatile(必选主题)
这里只做“工程落地角度”的差异,不做情绪化站队。
8.1 对比维度一:编排与工程化
| 维度 | ModelEngine | dify | coze | Versatile |
|---|---|---|---|---|
| 编排方式 | 可视化 + 声明式双模 | 可视化为主 | 可视化为主 | 多为可视化 |
| 复杂流程能力 | 循环/并行/子流程/动态路由更工程化 | 有但偏产品化 | 偏快搭 demo | 中等 |
| 节点扩展 | 多语言插件 SDK,工程团队友好 | 插件生态较强但以 Python/JS 为主 | 生态依赖平台 | 依赖平台 |
ModelEngine 的优势在“企业级可维护性”:
当你要做的不只是一个聊天智能体,而是 跨系统/跨团队/跨模型长期运行的 AI 流程,它的“声明式/可复用/可治理”会更省心。
8.2 对比维度二:知识工程与评测闭环
| 维度 | ModelEngine | dify | coze | Versatile |
|---|---|---|---|---|
| 数据清洗/算子链 | 内置数据工程链路 | 需外部工具配合 | 平台内相对弱 | 中等 |
| QA 自动生成与评估 | 原生支持并回流 | 多靠自建 | 偏轻量 | 偏轻量 |
| 模型评测管理 | 与模型工程打通 | 需要二次开发 | 体验较弱 | 体验弱 |
如果团队的痛点在“RAG 质量/知识治理”,ModelEngine 会更像“统一工程底座”,而不是“外层应用壳”。
8.3 对比维度三:生态与部署
| 维度 | ModelEngine | dify | coze | Versatile |
|---|---|---|---|---|
| 私有化/混合云 | 企业级友好 | 支持 | 支持但生态偏平台 | 支持 |
| 多模型切换 | 知识库/模型服务解耦,切换成本低 | 需要改配置/部分链路 | 依赖平台 | 中等 |
| 工具接入 | MCP + 插件双路线 | 插件与 API | 平台 Bot 工具 | 插件为主 |

九、方法论总结:智能体与编排落地的“4×3”框架
9.1 四个工程化支柱
- 数据/知识工程:质量、切分、召回、评估回流
- 提示词与任务工程:自动生成、结构化约束、版本对照
- 流程编排工程:节点化、可复用、可监控、可回滚
- 持续评测工程:离线指标 + 线上监控 + 端到端追踪
9.2 三条实践铁律
-
先 RAG 再 Agent:
没有治理的知识库会把智能体拖进“噪声泥潭”。 -
先可视化再代码化:
复杂流程先用可视化搭通与对齐共识,再逐步沉淀插件/代码节点。 -
以评测驱动迭代:
没有指标的“调优”就是玄学,必须用数据集+对照来推进。
十、结语:让实践真正铺路
对开发者来说,ModelEngine 的价值不在于“又一个 AI 应用平台”,而在于它把大模型落地最难的那段路——
知识工程、提示词工程、工具/流程工程、评测工程
整合成可复用的工程体系。
如果你正在经历:
- 智能体“能用但不好用”;
- 工作流“越做越乱不可维护”;
- RAG “召回准确率上不去”;
- 多模型多工具“切一个就要重构”;
那么不妨按本文的路径,在 ModelEngine 里做一次完整的端到端实践:
从知识库自动总结/QA 生成 → 提示词自动生成与评测 → 智能体调试上线 → 可视化编排承载复杂流程 → 多智能体协作提升质量 → 持续评测闭环运营。
而且,它还能进行应用编排:一站式可视化应用编排,应用分钟级发布

参考与事实来源
- ModelEngine 官方产品架构与能力介绍(低代码编排、数据/模型/应用三工程体系、插件机制、声明式框架等)。
- ModelEngine 可视化编排与节点化/工作流能力说明。
- 社区近期关于 ModelEngine 智能体与编排实战的公开讨论(用于理解功能边界与典型用法)。
说明:本文所有未在引用中出现的数值指标均已标注为“模拟官方数据”,仅用于方法论阐释与效果说明。
如果觉得有帮助,别忘了点个赞+关注支持一下~
喜欢记得关注,别让好内容被埋没~
如上附图,部分来源互联网,如有侵权,请联系删除。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)