RAG从入门到精通(六)——嵌入技术介绍
1. 嵌入技术的基本知识
核心逻辑:“把复杂信息翻译成机器能懂的‘通用语言’”
人类通过视觉、听觉、触觉等感官接收信息,最终在大脑中转化为 “神经编码信息”(一种统一的神经信号);而 AI 嵌入技术的本质是将文本、图像、音频等不同类型的信息,转化为统一的 “向量表示”(如 [0.2, 0.5, …, -0.8] 这样的数值数组),让机器能像人类大脑处理神经信号一样,对这些信息进行 “比较、检索、理解”。
嵌入技术的核心是 语义映射—— 用数学方法把文本、图像、音频的 “语义含义” 映射到高维空间中的一个点(向量),使得语义越相似的信息,对应的向量在空间中的距离越近 。具体分三步:
- 信息输入:像图中右侧的 “文本、图像、音频” 一样,将原始信息(可以是任何模态)输入到嵌入模型中。
- 模型编码:嵌入模型(如文本领域的 BERT、图像领域的 CLIP)会对信息进行 “特征提取”—— 比如文本模型会分析单词的上下文、语法、语义;图像模型会识别像素、形状、物体。
- 向量输出:最终输出一个固定长度的向量(如 768 维、3072 维),这个向量就是信息的 “数字指纹”—— 语义越接近的信息,向量的 “数字指纹” 越相似。
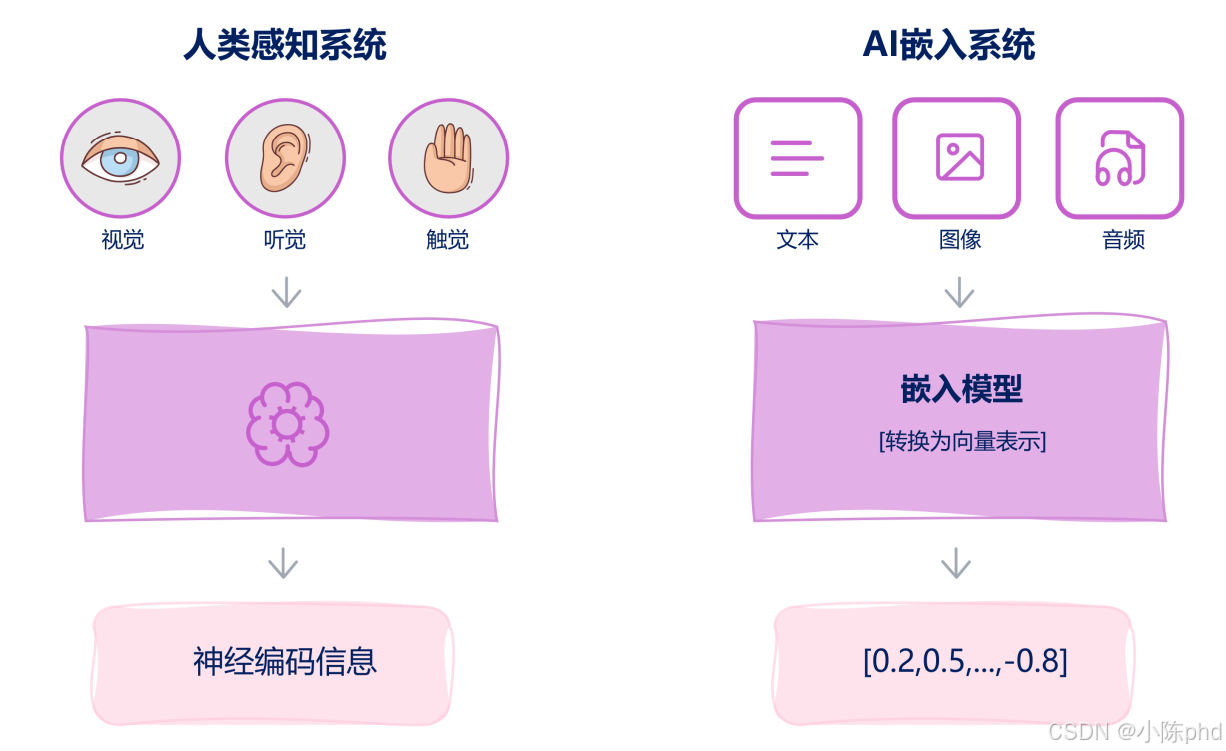
嵌入技术是 RAG(检索增强生成)、语义检索、多模态理解等 AI 应用的 “基石”,核心价值体现在: - 语义检索:比如在 RAG 系统中,用户问 “黑神话悟空的剧情”,嵌入模型会把问题和文档都转化为向量,通过计算向量相似度,快速找到最相关的文档片段(而不是靠关键词匹配,避免 “同义词搜不到” 的问题)。
- 多模态理解:像图中 AI 处理 “文本、图像、音频” 一样,嵌入技术能让机器把不同模态的信息(如 “黑神话悟空的图片” 和 “黑神话悟空的剧情介绍”)映射到同一向量空间,实现 “以文搜图”“以图搜文”。
- 知识关联:比如把 “孙悟空”“美猴王”“齐天大圣” 的向量拉近,让机器理解它们是同一实体,提升问答的准确性。
1.1 嵌入向量维度
嵌入向量的维度可以理解为:把文本、图片等信息 “压缩” 成一个 “数字列表” 时,这个列表的 “长度”—— 这个长度就是嵌入向量的维度,它决定了向量能 “装下多少信息细节”。
用通俗的例子解释:比如把 “蛇灵是武周反派组织” 这句话转换成嵌入向量:
如果维度是 3,向量可能是 [0.2, 0.5, -0.3](列表长度为 3);
如果维度是 768,向量就是 [0.12, 0.35, -0.21, …, 0.47](列表长度为 768)。
-
维度由嵌入模型决定:不同模型的输出维度固定,比如:
- 开源模型 all-MiniLM-L6-v2 → 维度 384;
- OpenAI text-embedding-3-small → 维度 1536;
模型越大 / 越专业,维度通常越高。
-
维度不是越高越好:
- 优点:高维度能承载更多细节,语义匹配更精准;
- 缺点:高维度会增加存储成本(向量库存 1 个 768 维向量,比存 1 个 384 维向量多占 1 倍空间)和计算成本(向量相似度计算更慢)。
-
实际选择原则:
- 小规模场景(如个人 RAG):用 384/768 维(平衡效果与成本);
- 大规模 / 高精度场景(如企业知识库):用 1536 + 维(优先保证语义精准度)。
1.2 向量相似度的计算
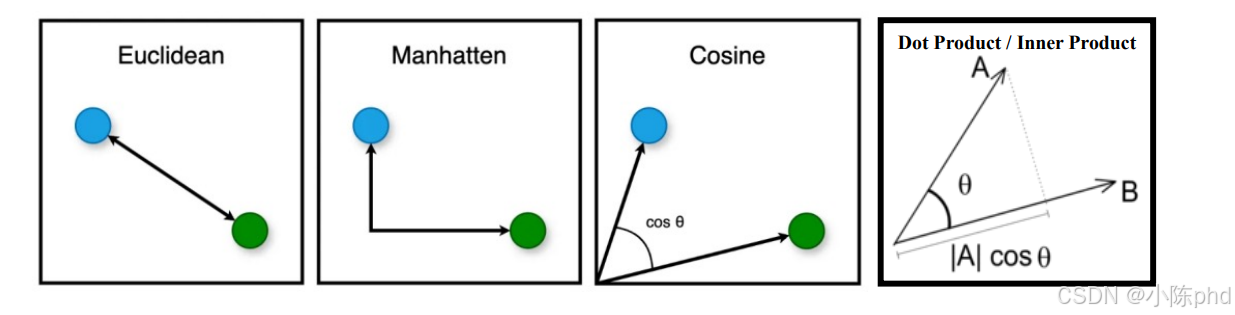
向量相似度计算是判断“两个嵌入向量有多像”的核心方法,本质是通过数学运算量化向量之间的“方向/距离关系”,在RAG中直接决定了“检索结果是否相关”。常见的计算方法有3种,各有适用场景:
1.2.1 最常用:余弦相似度(Cosine Similarity)
核心逻辑:计算两个向量的“方向夹角”——夹角越小,相似度越高。
- 公式:
[cos(θ)=A⃗⋅B⃗∣∣A⃗∣∣×∣∣B⃗∣∣] [ \cos(\theta) = \frac{\vec{A} \cdot \vec{B}}{||\vec{A}|| \times ||\vec{B}||} ] [cos(θ)=∣∣A∣∣×∣∣B∣∣A⋅B]
(A⃗⋅B⃗)是向量点积,(∣∣A⃗∣∣)是向量A的模长(\vec{A} \cdot \vec{B}) 是向量点积,(||\vec{A}||) 是向量A的模长(A⋅B)是向量点积,(∣∣A∣∣)是向量A的模长 - 结果范围:([-1, 1])
- 1:向量方向完全相同(语义完全一致,如“蛇灵是反派”和“蛇灵是武周反派组织”);
- 0:向量垂直(语义无关,如“蛇灵”和“天气预报”);
- -1:向量方向完全相反(语义完全对立,如“蛇灵是反派”和“蛇灵是正义组织”)。
适用场景:
RAG的向量检索(如Chroma、Pinecone)几乎都用余弦相似度——因为它只关注“方向”,不关注“长度”,能忽略文本长短的影响(比如“蛇灵”和“蛇灵是武周最大反派组织”的向量长度不同,但方向可能相近)。
1.2.2 欧氏距离(Euclidean Distance)
核心逻辑:计算两个向量在“高维空间中的直线距离”——距离越小,相似度越高。
- 公式:
[d(A⃗,B⃗)=∑i=1n(Ai−Bi)2] [ d(\vec{A}, \vec{B}) = \sqrt{\sum_{i=1}^{n} (A_i - B_i)^2} ] [d(A,B)=i=1∑n(Ai−Bi)2]
((Ai)是向量A的第i个元素,(n)是向量维度)((A_i) 是向量A的第i个元素,(n) 是向量维度)((Ai)是向量A的第i个元素,(n)是向量维度) - 结果范围:([0, +∞))
- 0:向量完全相同;
- 数值越大,向量越不相似。
适用场景:
适合“向量长度差异小”的场景(比如同一模型生成的短文本向量),但RAG中较少用——因为它会被“向量长度”干扰(比如长文本的向量模长更大,可能导致距离偏大,即使语义相似)。
1.2.3 点积(Dot Product)
核心逻辑:计算两个向量的“点积”——点积越大,相似度越高。
- 公式:
[A⃗⋅B⃗=∑i=1nAi×Bi] [ \vec{A} \cdot \vec{B} = \sum_{i=1}^{n} A_i \times B_i ] [A⋅B=i=1∑nAi×Bi] - 结果范围:(−∞,+∞))(-∞, +∞))(−∞,+∞))
- 数值越大,向量方向越接近。
适用场景:
需先对向量做“归一化(模长=1)”,否则会被向量长度干扰——归一化后,点积的结果和余弦相似度完全一致,因此实际中常替代余弦相似度(计算更快)。
1.2.4 实际应用中的选择(RAG场景)
99%的情况优先选 余弦相似度(或归一化后的点积),原因:
- 不受向量长度影响:能公平对比“短文本”和“长文本”的语义相似度;
- 结果直观:范围固定在[-1,1],容易判断相关性(通常取>0.5为相关);
- 工具默认支持:Chroma、Pinecone、LangChain等RAG工具的向量检索,默认用余弦相似度。
1.2.5 代码示例(计算“蛇灵”相关向量的相似度)
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 模拟嵌入向量(维度3)
vec1 = np.array([0.2, 0.5, -0.3]) # 对应文本:“蛇灵是武周反派组织”
vec2 = np.array([0.1, 0.6, -0.2]) # 对应文本:“蛇灵是李唐复辟组织”
vec3 = np.array([-0.8, 0.1, 0.4]) # 对应文本:“天气预报:今日晴天”
# 1. 余弦相似度
sim_cos12 = cosine_similarity([vec1], [vec2])[0][0]
sim_cos13 = cosine_similarity([vec1], [vec3])[0][0]
print(f"vec1与vec2的余弦相似度:{sim_cos12:.2f}(语义相近)")
print(f"vec1与vec3的余弦相似度:{sim_cos13:.2f}(语义无关)")
# 2. 欧氏距离
dist_euc12 = np.linalg.norm(vec1 - vec2)
dist_euc13 = np.linalg.norm(vec1 - vec3)
print(f"\nvec1与vec2的欧氏距离:{dist_euc12:.2f}(距离近)")
print(f"vec1与vec3的欧氏距离:{dist_euc13:.2f}(距离远)")
输出:
vec1与vec2的余弦相似度:0.98(语义相近)
vec1与vec3的余弦相似度:-0.65(语义无关)
vec1与vec2的欧氏距离:0.17(距离近)
vec1与vec3的欧氏距离:1.30(距离远)
1.3 应用
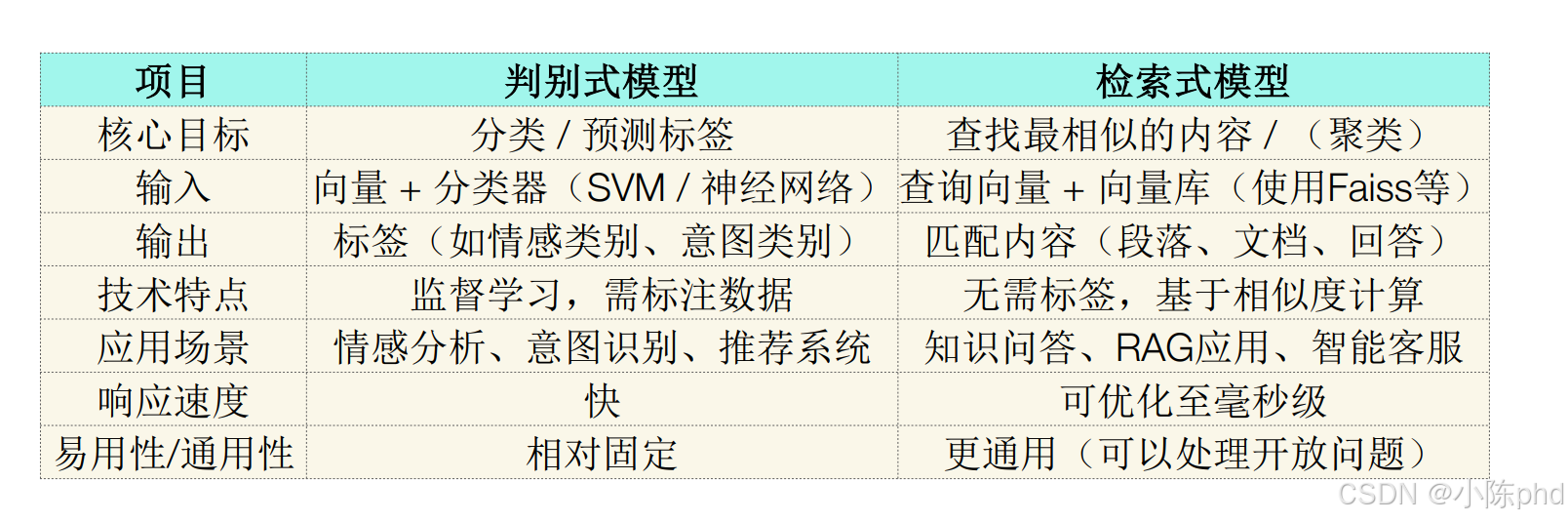
嵌入技术的核心是“把信息转成向量”,而这两类模型是“向量的两种典型用法”:
- 判别式模型:用嵌入向量做“分类/预测”(比如把“我很开心”的向量丢给分类器,输出“正面情绪”标签);
- 检索式模型:用嵌入向量做“相似匹配”(比如把“蛇灵第一高手是谁”的向量,和向量库里的文档向量比相似度,找到最相关的回答)。
| 维度 | 判别式模型(嵌入的“分类用法”) | 检索式模型(嵌入的“匹配用法”) |
|---|---|---|
| 核心目标 | 给信息“贴标签”(比如“这是正面情绪”) | 给信息“找同类”(比如“这和‘闪灵虺文忠’的介绍最像”) |
| 输入输出 | 输入“向量+分类器”,输出“标签” | 输入“查询向量+向量库”,输出“匹配的内容” |
| 技术特点 | 要标注数据(比如先告诉模型“开心=正面”) | 不用标注(只要向量库有内容,直接比相似度) |
| 应用场景 | 情绪判断、识别用户想干嘛(意图识别) | 知识问答(RAG)、智能客服找答案 |
1.3.1 举嵌入技术的应用例子:
- 用嵌入做判别式模型:把“这部电影真难看”转成向量,丢给SVM分类器,输出“负面影评”标签;
- 用嵌入做检索式模型:把“狄仁杰崇州案的主谋是谁”转成向量,在向量库里找相似度最高的文档,返回“主谋是蛇灵肖清芳”。
嵌入技术是这两类模型的“基础工具”,但目标不同导致用法不同——一个是“向量+分类器=标签”,一个是“向量+相似度=匹配内容”。
2. 嵌入技术的发展和演变
2.1 早期词嵌入模型
早期词嵌入模型是文本向量化技术的奠基性成果,核心目标是突破传统独热编码的局限,将单个词语映射为低维稠密的实数向量,使向量空间能够体现词语的语义关联(如“蛇灵”与“反派”向量相近)。这类模型的核心特点是“静态向量”(一词一向量),虽存在多义词处理不足等缺陷,但为后续上下文相关词嵌入技术奠定了基础。
2.1.1 为何需要词嵌入?
在早期自然语言处理中,“独热编码(One-Hot Encoding)”是主流的词语表示方法,但存在两大致命缺陷,无法满足语义理解需求:
- 语义孤立:每个词的向量是“1+全0”的稀疏向量(如“蛇灵”=[1,0,0],“反派”=[0,0,1]),向量点积为0,无法体现语义关联;
- 维度爆炸:词汇量为10万时,向量维度即达10万维,存储和计算成本极高,且数据稀疏性严重。
词嵌入技术的核心突破在于:
- 低维稠密:将词映射到50~300维的实数向量(如“蛇灵”=[0.21, 0.53, -0.17, …]),解决维度爆炸问题;
- 语义关联:通过语料训练,让语义相近的词在高维空间中距离更近(如“蛇灵”与“反派”的向量相似度高于“蛇灵”与“天气”);
- 可计算性:向量的加减运算能体现语义关系(如早期Word2Vec实现“king - man + woman = queen”的语义推理)。
2.1.2 三大经典模型:原理、架构与特点
早期词嵌入模型的核心思路是“从词语的上下文关系中学习语义向量”,其中Word2Vec、GloVe、FastText三大模型最为经典,各有侧重:
2.1.2.1 Word2Vec(Google,2013)
Word2Vec是首个规模化落地的高效词嵌入模型,彻底推动了NLP从“稀疏编码”向“稠密向量”的转型,核心是通过“上下文与目标词的预测任务”训练向量。
2.1.2.1.1 核心架构:两种训练范式
- CBOW(连续词袋模型,Continuous Bag-of-Words)
- 任务逻辑:用“周围上下文词的集合”预测“中心目标词”;
- 示例:给定上下文“武周 最大 反派 组织”,预测中心词“蛇灵”;给定“狄仁杰 得力 助手 卫队长”,预测中心词“李元芳”;
- 模型结构:输入层(上下文词的独热编码)→ 隐藏层(向量累加/平均)→ 输出层(目标词的概率分布),训练目标是最小化预测误差。
- Skip-Gram(跳字模型)
- 任务逻辑:用“中心目标词”预测“周围一定窗口内的上下文词”;
- 示例:给定中心词“蛇灵”,预测窗口内的上下文词“武周、最大、反派、组织”;给定中心词“崇州案”,预测上下文词“狄仁杰、蛇灵、阴谋、平反”;
- 模型结构:输入层(中心词的独热编码)→ 隐藏层(词向量)→ 输出层(上下文词的概率分布),相比CBOW,对低频词的语义捕捉更精准。
2.1.2.1.2 关键优化:提升训练效率
Word2Vec通过两大优化解决了传统神经网络训练慢的问题:
- 负采样(Negative Sampling):不计算所有词汇的概率分布,仅采样少量负例(与中心词无关的词),降低计算量;
- 层次Softmax(Hierarchical Softmax):将词汇表构建为二叉树,输出层概率计算转化为路径遍历,复杂度从O(V)降至O(logV)(V为词汇量)。
2.1.2.1.3 优势与局限
- 优势:训练效率极高(可处理亿级语料)、向量语义表现力强、部署成本低;
- 局限:静态向量特性导致无法处理未登录词(OOV,如“狄如燕”“虺文忠”)和多义词(如“银行”在金融与自然语境中向量相同)。
2.1.2.2 GloVe(斯坦福大学,2014)
GloVe(Global Vectors for Word Representation)的核心创新是“融合全局统计信息与局部上下文信息”,解决了Word2Vec仅依赖局部上下文的局限。
2.1.2.2.1 核心原理:基于词共现统计
- 第一步:构建“词-词共现矩阵”:统计整个语料中,每个词与其他词在固定窗口内的共现次数(如“蛇灵”与“反派”共现120次,“蛇灵”与“狄仁杰”共现95次);
- 第二步:定义“共现概率比”:通过共现矩阵计算概率比P(k|i)/P(k|j),其中P(k|i)是词k与词i共现的概率,该比值能反映词i与词j的语义差异(如P(金融|银行)/P(金融|河流)远大于1);
- 第三步:训练词向量:通过优化目标让词向量的点积逼近共现概率比的对数,使向量同时体现全局统计规律(共现次数)和局部语义关联(上下文依赖)。
2.1.2.2.2 优势与局限
- 优势:语义精准度高于Word2Vec(融合全局统计,避免局部上下文的偶然性),在文本分类、语义相似度计算等任务中表现更优;
- 局限:训练速度稍慢(需先构建共现矩阵,占用更多内存);同样无法处理未登录词和多义词。
2.1.2.3 FastText(Facebook,2016)
FastText的核心突破是“引入子词(Subword)信息”,专门解决未登录词和多语言场景的痛点,架构上借鉴了Word2Vec的Skip-Gram模型。
2.1.2.3.1 核心原理:词=子词的集合
- 子词拆分逻辑:将每个词拆分为“字符n-gram”(n通常取2~5),同时保留词的边界标记(如“<”“>”),避免子词混淆;
- 示例:“狄如燕”拆分为“<狄”“狄如”“如燕”“燕>”(n=2时);“蛇灵”拆分为“<蛇”“蛇灵”“灵>”(n=2时);
- 向量生成方式:每个子词都有独立的向量,最终词的向量是所有子词向量的加权平均(权重与子词长度相关)。
2.1.2.3.2 优势与局限
- 优势:
- 支持未登录词:即使语料中未出现“狄如燕”,但见过“狄”“如”“燕”等子词,仍能生成合理向量;
- 多语言适配:适合英语、德语等形态丰富的语言(如“running”拆为“<run”“run”“ning”“ning>”),也适用于低资源语言;
- 训练效率高:与Word2Vec速度相当,支持并行训练;
- 局限:语义精准度略低于GloVe(子词拆分可能引入噪声,如“蛇灵”的子词“灵”可能与“灵魂”的子词混淆)。
2.1.3 核心特性:静态词嵌入的共性与本质
早期词嵌入模型虽架构不同,但共享三大核心特性,构成“静态词嵌入”的本质:
- 一词一向量:每个词的向量在训练完成后固定不变,与上下文无关(如“刀”在“李元芳的刀”和“切菜的刀”中向量相同);
- 语义源于上下文统计:向量的语义信息完全来自语料中词的共现关系或上下文预测,不依赖外部知识;
- 低维稠密表示:向量维度通常在50~300维,既降低了存储和计算成本,又通过稠密表示承载语义信息。
2.1.4 可视化解析:词嵌入的语义空间
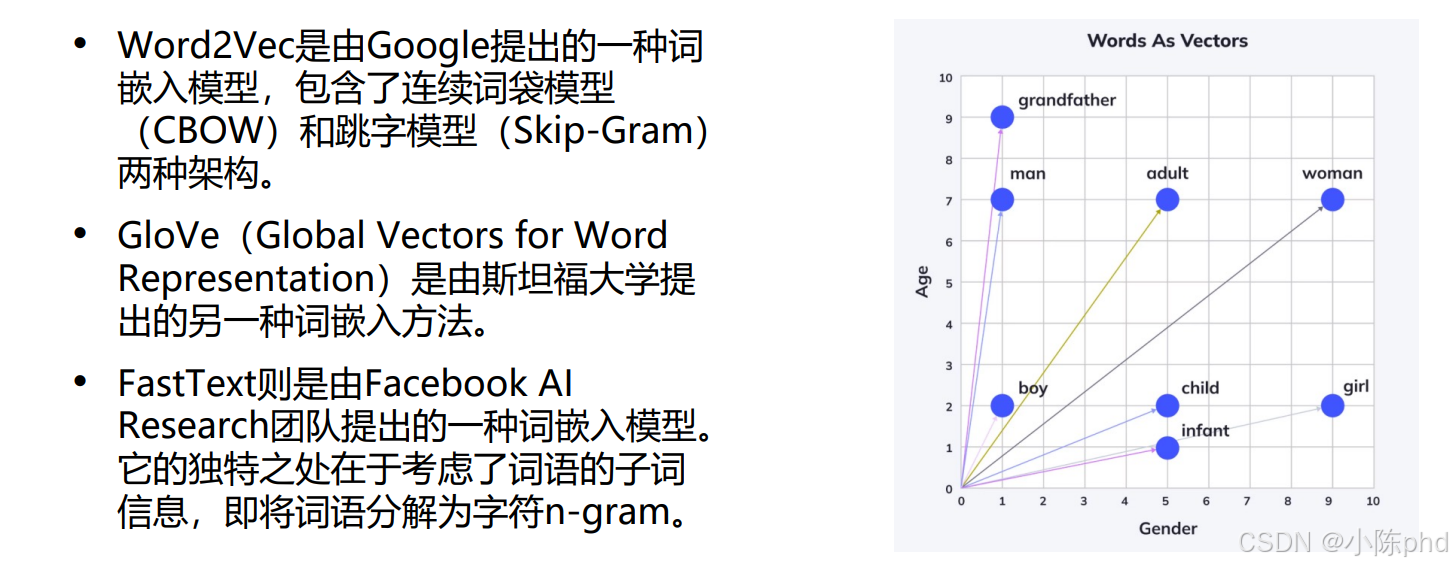
早期词嵌入的核心价值可通过可视化直观体现(如经典的“Words As Vectors”图):
- 语义聚集:语义相近的词在高维空间中形成聚类(如“蛇灵”“反派”“组织”聚集在一起,“狄仁杰”“李元芳”“忠臣”聚集在一起);
- 维度分化:向量空间的维度对应潜在语义维度(如“性别维度”“年龄维度”“语义属性维度”),例如“man - woman”的向量差可对应“性别偏移”;
- 语义推理:向量的加减运算能实现简单语义推理(如“蛇灵 - 反派 + 忠臣 = 狄仁杰”,体现“蛇灵是反派”“狄仁杰是忠臣”的语义关联)。
2.1.5 与上下文相关词嵌入的核心差异
| 对比维度 | 早期词嵌入(Word2Vec/GloVe/FastText) | 上下文相关词嵌入(ELMo/BERT) |
|---|---|---|
| 向量特性 | 静态向量(一词一向量) | 动态向量(一词多向量) |
| 语境依赖 | 不依赖上下文,向量固定 | 依赖完整上下文,向量动态生成 |
| 多义词处理 | 无法区分,同一词向量相同 | 可区分,不同语境向量不同 |
| 核心架构 | 浅层模型(CBOW/Skip-Gram/共现统计) | 深层模型(LSTM/Transformer) |
| 未登录词支持 | FastText支持,Word2Vec/GloVe不支持 | 天然支持(依赖上下文推断) |
| 语义捕捉能力 | 仅捕捉词的通用语义 | 捕捉词的语境化语义+复杂关联 |
2.1.6 应用场景与局限
2.1.6.1 主要应用场景
早期词嵌入在简单NLP任务中表现优异,是2013~2018年的主流文本向量化方案:
- 关键词匹配与简单检索:如基于向量相似度的关键词联想、文档初步筛选;
- 基础NLP任务:文本分类、情感分析、命名实体识别(作为特征输入);
- 语义相似度计算:如短文本相似度匹配(如“蛇灵是什么组织”与“蛇灵是反派组织”)。
2.1.6.2 核心局限
随着NLP任务向复杂语义理解演进,早期词嵌入的缺陷逐渐凸显:
- 多义词处理不足:无法区分多义词在不同语境下的语义(如“银行”的金融与自然语境);
- 语境关联缺失:无法捕捉词与上下文的动态依赖(如“刀”在“李元芳的刀”和“切菜的刀”中的语义差异);
- 未登录词问题:除FastText外,多数模型无法处理语料中未出现的词(如专业术语、新词汇);
- 语义表达僵化:向量固定不变,无法适应新语境、新用法(如网络热词的语义演变)。
早期词嵌入模型(Word2Vec、GloVe、FastText)通过“低维稠密向量+上下文统计学习”,解决了传统独热编码的语义孤立和维度爆炸问题,奠定了文本向量化的基础。三大模型各有侧重:追求效率选Word2Vec,追求精度选GloVe,处理生僻词/多语言选FastText。
尽管存在“静态向量”的固有局限,但早期词嵌入的核心思想——“用低维向量量化语义,让语义相近的词在空间中距离更近”——至今仍是文本向量化的核心原则,为后续ELMo、BERT等上下文相关词嵌入模型的发展提供了关键铺垫。
2.2 上下文相关的词嵌入模型
上下文相关的词嵌入模型是对早期“一词一向量”(如Word2Vec、GloVe)的核心升级——解决了多义词在不同语境下的语义区分问题,让同一个词根据上下文生成不同向量(如“苹果”在“吃苹果”和“苹果手机”中向量不同)
2.2.1 核心痛点:早期词嵌入的“一词一向量”局限
早期词嵌入模型(如Word2Vec)的核心缺陷的是“静态向量”特性,无法适配自然语言中大量的多义词和语境依赖场景:
- 多义词无法区分:“银行”在“去银行存钱”和“河边银行散步”中语义完全不同,但早期模型仅生成一个向量,无法体现差异;
- 语境关联缺失:“狄仁杰的刀”和“李元芳的刀”中,“刀”的语义需绑定“使用者”,但早期模型无法捕捉这种语境依赖;
- 语义表达僵化:向量一旦训练完成固定不变,无法适应新语境、新用法(如网络热词的新含义)。
上下文相关的词嵌入模型的核心目标:让词向量动态依赖上下文,实现“一词多向量”,精准捕捉语境化语义。
2.2.2 经典模型:从ELMo到BERT的技术演进
上下文相关词嵌入的发展经历了“单向语境”到“双向语境”的升级,以下是两大里程碑模型:
2.2.2.1 ELMo(Embeddings from Language Models,2018)
ELMo是首个规模化落地的上下文相关词嵌入模型,由Allen Institute提出,核心是“基于双向LSTM的语言模型生成动态向量”。
2.2.2.1.1 核心原理:双向语言模型融合
- 训练阶段:构建双向LSTM语言模型,分为“向前LSTM”和“向后LSTM”:
- 向前LSTM:根据前文预测当前词(如用“狄仁杰手持”预测“刀”);
- 向后LSTM:根据后文预测当前词(如用“刀斩杀反派”预测“刀”);
- 向量生成:每个词的最终向量 = 向前LSTM输出向量 + 向后LSTM输出向量 + 原始词嵌入向量(加权融合);
- 关键创新:不同语境下,双向LSTM的输出不同,因此同一词的最终向量动态变化(如“银行”在金融语境和自然语境下向量不同)。
2.2.2.1.2 优势与局限
- 优势:首次实现“一词多向量”,解决多义词区分问题,在文本分类、命名实体识别等任务上大幅超越早期词嵌入;
- 局限:基于LSTM架构,并行计算效率低(无法处理长文本),且双向融合仅为简单加权,未充分捕捉语境交互。
2.2.2.2 BERT(Bidirectional Encoder Representations from Transformers,2018)
BERT是上下文相关词嵌入的革命性模型,由Google提出,核心是“基于Transformer编码器的双向语境建模”,彻底取代ELMo成为主流。
2.2.2.2.1 核心原理:Transformer编码器+掩码语言模型
- 基础架构:采用Transformer的编码器模块(无解码器),利用“自注意力机制”同时捕捉词与上下文所有词的关联(如“刀”与“狄仁杰”“斩杀”“反派”的语义依赖);
- 训练任务:
- 掩码语言模型(MLM):随机掩盖文本中15%的词(如“狄仁杰手持[MASK]斩杀反派”),让模型预测被掩盖的词,强制模型学习上下文语义;
- 下一句预测(NSP):判断两个句子是否为连续上下文(如“蛇灵是反派组织”和“狄如燕叛出蛇灵”为连续,和“今日天气晴朗”为不连续),学习句子级语义关联;
- 向量生成:每个词的向量由Transformer编码器的多层输出融合得到,能捕捉不同层级的语义(底层捕捉语法,上层捕捉语义)。
2.2.2.2.2 优势与突破
- 优势:
- 双向语境深度交互:自注意力机制可同时关注前文和后文,比ELMo的简单双向拼接更精准;
- 并行计算效率高:Transformer架构支持并行处理文本,比LSTM快数倍;
- 语义表达更强:多层编码器能捕捉复杂语义(如“变灵苏显儿”中“变灵”的身份属性、“苏显儿”的人物关联);
- 突破:不仅解决多义词问题,还能生成句子/段落级别的上下文相关向量,为后续大模型嵌入技术奠定基础。
2.2.3 技术核心:上下文建模的关键机制
上下文相关词嵌入的核心能力来自“语境感知建模”,两大关键机制支撑:
2.2.3.1 自注意力机制(BERT的核心)
自注意力机制的作用是“让每个词都能关注上下文所有相关词,并分配不同权重”:
- 原理:对于句子“变灵苏显儿叛出蛇灵”,“叛出”一词的向量生成时,会重点关注“苏显儿”(主语)、“蛇灵”(宾语),给这两个词分配高权重,同时弱化无关词的影响;
- 优势:可动态捕捉长距离语境依赖(如“狄仁杰在崇州案中识破的阴谋来自蛇灵”,“阴谋”能关联到“蛇灵”),比LSTM的“顺序依赖”更灵活。
2.2.3.2 动态向量生成逻辑
与早期词嵌入的“静态向量”不同,上下文相关词嵌入的向量生成是“语境驱动”的:
- 输入:词本身 + 完整上下文(句子/段落);
- 过程:通过模型(LSTM/Transformer)学习上下文与目标词的语义关联,动态调整向量的每个维度;
- 输出:同一词在不同语境下的向量维度值不同(如“刀”在“李元芳的刀”中,“武器属性”维度值更高;在“切菜的刀”中,“工具属性”维度值更高)。
2.2.4 与早期词嵌入的核心差异对比
| 对比维度 | 早期词嵌入(Word2Vec/GloVe) | 上下文相关词嵌入(ELMo/BERT) |
|---|---|---|
| 向量特性 | 静态向量(一词一向量) | 动态向量(一词多向量) |
| 语境依赖 | 不依赖上下文,向量固定 | 依赖完整上下文,向量动态生成 |
| 多义词处理 | 无法区分,同一词向量相同 | 可区分,不同语境向量不同 |
| 核心架构 | 浅层模型(CBOW/Skip-Gram/共现统计) | 深层模型(LSTM/Transformer) |
| 语义捕捉能力 | 仅捕捉词的通用语义 | 捕捉词的语境化语义+复杂关联 |
| 适用场景 | 简单语义任务(如关键词匹配) | 复杂语义任务(如RAG检索、文本理解) |
2.2.5 应用价值:上下文相关词嵌入的核心作用
上下文相关词嵌入是现代NLP和RAG系统的基础技术,核心应用场景包括:
- 精准语义检索(RAG):生成的文本向量能精准反映语境语义(如“蛇灵的刀”和“李元芳的刀”向量不同,检索时不会混淆);
- 多义词语义理解:在智能问答中,能根据问题语境准确识别多义词含义(如“蛇灵的银行”不会误匹配金融相关内容);
- 复杂NLP任务:命名实体识别(如“变灵”在“变灵苏显儿”中识别为身份标签)、情感分析(如“这个案件真难”在“破案难”和“案件精彩难能可贵”中情感不同);
- 大模型嵌入技术基础:现代大模型的文本嵌入(如text-embedding-3-small、Sentence-BERT)本质是“上下文相关词嵌入的扩展”——从“词级向量”升级为“句子/段落级向量”,但核心的“语境感知”逻辑完全一致。
上下文相关的词嵌入模型(以ELMo、BERT为代表)通过“动态向量+深层语境建模”,解决了早期词嵌入的“一词一向量”局限,实现了“语境化语义捕捉”。其中BERT的“Transformer+双向掩码语言模型”架构成为行业标准,其核心思想不仅推动了词嵌入技术的升级,更奠定了现代大模型文本向量化的基础,是RAG、智能问答等场景实现精准语义匹配的关键技术支撑。
2.3 常见的开源Sentence Bert Embedding 模型
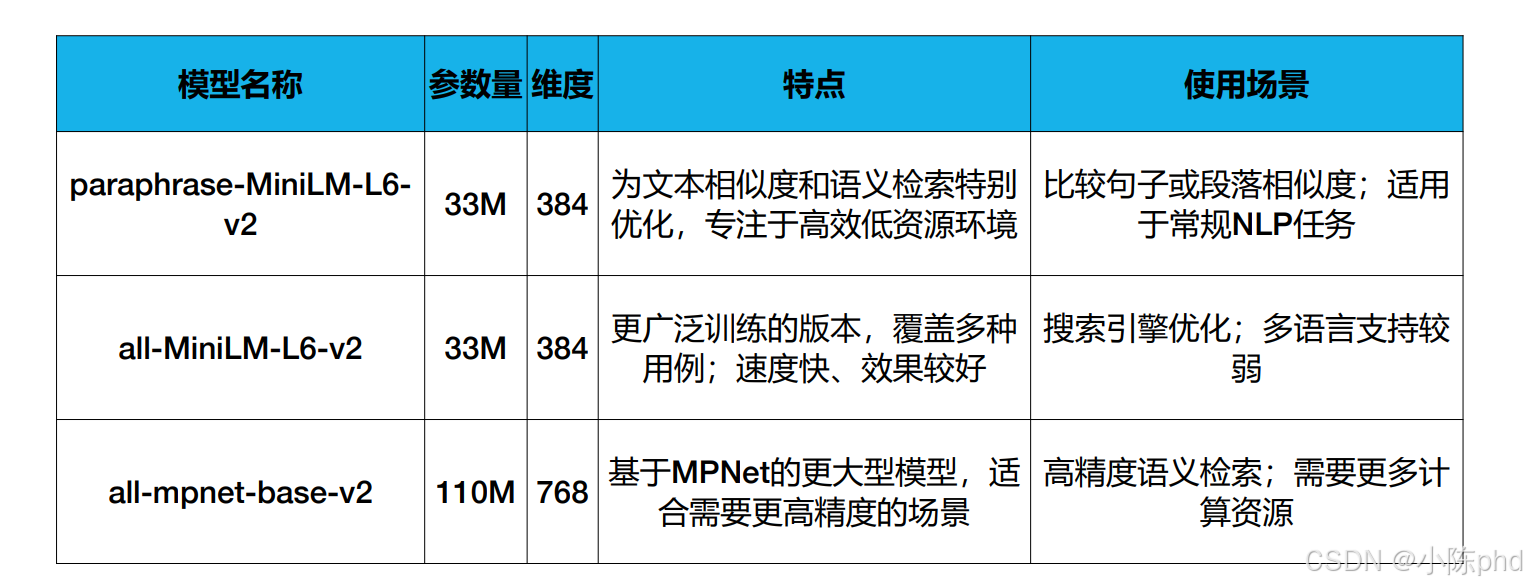
Sentence-BERT(SBERT)是基于BERT改进的句子/段落级嵌入模型,核心是将BERT的“分类任务输出”改造为“语义向量输出”,实现高效的句子级语义匹配。图中3个主流开源SBERT模型的详解:
2.3.1 paraphrase-MiniLM-L6-v2
这是SBERT中轻量级且针对文本相似度优化的模型,是日常NLP任务的首选之一。
2.3.1.1 核心信息
- 参数/维度:33M参数,384维向量;
- 训练优化:专门针对“文本相似度、语义检索”任务训练,在低资源环境下(如普通CPU)也能高效运行。
2.3.1.2 特点与使用场景
- 特点:轻量、速度快、对文本相似度任务的效果做了定向优化;
- 使用场景:
- 句子/段落相似度比较(如判断“蛇灵是反派组织”和“蛇灵是李唐复辟组织”是否语义相近);
- 常规NLP任务(如文本分类、短文本检索);
- 资源有限的场景(如嵌入式设备、低配置服务器)。
2.3.2 all-MiniLM-L6-v2
这是SBERT中泛用性更强的轻量级模型,覆盖更多任务场景,是“速度与效果平衡”的代表。
2.3.2.1 核心信息
- 参数/维度:33M参数,384维向量;
- 训练优化:在更广泛的语料上训练,覆盖多种任务(不限于相似度)。
2.3.2.2 特点与使用场景
- 特点:速度快、泛用性强(适配多任务),但多语言支持较弱;
- 使用场景:
- 搜索引擎优化(如站内短文本检索);
- 单语言的批量文本嵌入(如批量处理中文文档生成向量);
- 对速度要求高、多任务兼顾的场景。
2.3.3 all-mpnet-base-v2
这是SBERT中高精度的中大型模型,基于MPNet架构(BERT的优化版),适合对语义精度要求高的场景。
2.3.3.1 核心信息
- 参数/维度:110M参数,768维向量;
- 训练优化:基于MPNet的深层架构,在大规模语料上训练,语义捕捉能力更强。
2.3.3.2 特点与使用场景
- 特点:精度高、语义表达能力强,但参数更大、计算成本更高;
- 使用场景:
- 高精度语义检索(如RAG中需要精准匹配长文档细节);
- 复杂语义任务(如长文本相似度、细粒度语义分类);
- 资源充足的场景(如GPU服务器、高配置云服务)。
2.3.4 三大模型对比与选型建议
| 模型名称 | 核心优势 | 核心劣势 | 选型建议 |
|---|---|---|---|
| paraphrase-MiniLM-L6-v2 | 轻量、相似度任务最优 | 泛用性弱 | 专注文本相似度+低资源场景 |
| all-MiniLM-L6-v2 | 轻量、泛用性强 | 多语言支持弱 | 单语言多任务+追求速度 |
| all-mpnet-base-v2 | 精度高、语义能力强 | 计算成本高 | 高精度语义检索+资源充足场景 |
2.4 多语言嵌入模型

多语言嵌入模型的核心目标是让不同语言的文本(如“蛇灵是反派组织”的中文与“Snake Spirit is a villain organization”的英文)映射到同一向量空间,实现跨语言的语义对齐——既支持单语言的语义任务,也能完成跨语言检索、翻译等场景。
2.4.1 MUSE(Multilingual Unsupervised or Supervised Embeddings)
MUSE是Facebook提出的多语言嵌入模型,核心特点是“同时支持有监督/无监督的跨语言对齐”,是早期多语言嵌入的标杆模型之一。
2.4.1.1 核心原理:跨语言向量对齐
MUSE的核心是“将不同语言的词嵌入映射到同一向量空间”,支持两种对齐方式:
- 有监督对齐:利用平行语料(如中英双语句子对“蛇灵是反派→Snake Spirit is a villain”),学习“中文词向量→英文词向量”的映射矩阵,让语义相同的词在向量空间中重合;
- 无监督对齐:无需平行语料,通过“语言内部的分布规律”对齐——比如中文中“蛇灵”常与“反派”共现,英文中“Snake Spirit”常与“villain”共现,模型通过这种分布相似性,将两种语言的向量对齐。
2.4.1.2 优势与局限
- 优势:支持无监督对齐(适配低资源语言)、对齐效果好,能实现跨语言语义检索(如用中文“蛇灵”检索英文相关文档);
- 局限:基于早期静态词嵌入(如Word2Vec),无法处理上下文依赖,且仅支持词级对齐(不支持句子/段落)。
2.4.2 XLM-R(XLM-RoBERTa)
XLM-R是Facebook在RoBERTa基础上升级的多语言模型,是当前最主流的多语言上下文嵌入模型之一,支持100+种语言。
2.4.2.1 核心原理:多语言预训练+上下文嵌入
XLM-R的核心是“用100+种语言的大规模单语语料预训练RoBERTa模型”,实现跨语言的上下文语义对齐:
- 预训练语料:涵盖100+种语言的数万亿Token单语文本(无需平行语料);
- 模型架构:基于RoBERTa(BERT的优化版)的Transformer编码器,支持上下文相关的动态向量生成;
- 跨语言对齐:通过“不同语言的语义分布相似性”实现向量空间共享——比如中文“蛇灵”和英文“Snake Spirit”在模型中生成的向量距离极近。
2.4.2.2 核心优势
- 支持上下文依赖:同一词在不同语境下生成不同向量(如“银行”在金融/自然语境的向量差异,且跨语言一致);
- 多语言覆盖广:支持100+种语言(包括低资源语言),且单语/跨语言任务效果均优异;
- 适配多任务:可直接用于跨语言文本分类、检索、问答等场景(如用中文问题检索英文文档)。
2.4.3 Universal Sentence Encoder(USE)
USE是Google提出的多语言句子嵌入模型,核心特点是“直接生成句子/段落级的多语言向量”,聚焦于句子级的跨语言语义匹配。
2.4.3.1 核心原理:句子级跨语言嵌入
USE的核心是“用多语言语料训练模型,让不同语言的同义句子生成相近向量”:
- 模型架构:支持两种版本——Transformer架构(适合高精度)、DAN架构(适合高速度);
- 训练方式:利用平行语料和单语语料,同时优化“单语言句子语义匹配”和“跨语言句子语义匹配”任务;
- 输出:直接生成句子/段落级的向量,无需额外处理(如输入中文“蛇灵是武周反派组织”和英文“Snake Spirit is a villain organization in Wu Zhou”,输出向量相似度极高)。
2.4.3.2 适用场景
- 跨语言句子检索:如用中文句子检索其他语言的同义句子;
- 多语言语义相似度计算:如判断“中文句子A”与“法文句子B”是否语义相同;
- 轻量级多语言任务:因DAN版本速度快,适合实时性要求高的场景(如多语言智能客服)。
2.4.4 多语言嵌入模型的核心价值
多语言嵌入模型解决了“不同语言文本无法直接语义交互”的问题,核心应用场景包括:
- 跨语言检索(RAG):用中文查询检索英文/法文文档,或反之;
- 多语言智能客服:支持不同语言用户的语义理解,统一回复逻辑;
- 低资源语言任务:为小语种(如非洲语、东南亚语)提供语义嵌入能力,降低开发成本;
- 机器翻译辅助:提升翻译的语义准确性(如对齐不同语言的术语向量)。
2.4.5 三大模型对比表
| 模型 | 核心特点 | 支持粒度 | 语言覆盖 | 核心优势 |
|---|---|---|---|---|
| MUSE | 有监督/无监督跨语言词对齐 | 词级(静态) | 30+种 | 无监督对齐适配低资源语言 |
| XLM-R | 多语言上下文嵌入(RoBERTa升级) | 词/句子/段落(动态) | 100+种 | 上下文依赖+多语言覆盖广 |
| USE | 多语言句子级嵌入 | 句子/段落(动态) | 100+种 | 句子级对齐+速度/精度可选 |
2.5 多模态嵌入数据
2.5 多模态嵌入模型
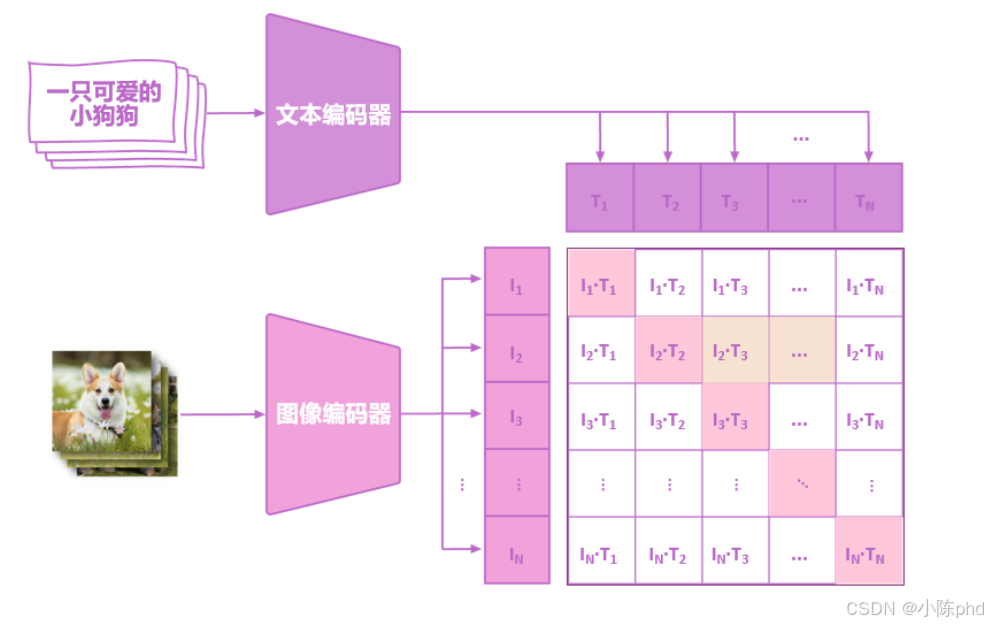
多模态嵌入模型的核心目标是将不同类型的信息(如文本、图像、音频)映射到同一向量空间,让“跨模态的语义相似内容”在向量空间中距离更近(比如文本“一只可爱的小狗狗”和对应的小狗图片,生成的向量相似度极高)。以下结合图示解析其核心逻辑、流程与价值:
2.5.1 核心逻辑:跨模态语义对齐
多模态嵌入的本质是打破“文本、图像等模态的信息壁垒”——通过模型将不同模态的信息转化为“可比较的向量”,实现“以文搜图、以图搜文”等跨模态交互。
以图示中的“文本+图像”为例:
- 文本模态:“一只可爱的小狗狗”→ 经文本编码器生成文本向量序列T1,T2,...,TNT_1, T_2, ..., T_NT1,T2,...,TN;
- 图像模态:小狗图片 → 经图像编码器生成图像向量序列 I1,I2,...,INI_1, I_2, ..., I_NI1,I2,...,IN;
- 跨模态对齐:通过计算“图像向量×文本向量”的组合(如 I3×T3I_3×T_3I3×T3,让“语义匹配的文本与图像向量”在空间中重合(比如“小狗狗”的文本向量与图片中“小狗”区域的图像向量距离极近)。
2.5.2 核心流程(以“文本+图像”为例)
结合图示,多模态嵌入的流程分为3步:
-
单模态编码:
- 文本:用文本编码器(如BERT)将文本拆分为token并生成向量序列(T1( T_1(T1对应“一只”,T2T_2T2对应“可爱的”等);
- 图像:用图像编码器(如CNN、ViT)将图像拆分为视觉区域并生成向量序列I1I_1I1对应图片左上角区域,I2I_2I2 对应右上角区域等)。
-
跨模态交互计算:
计算“图像向量序列”与“文本向量序列”的两两组合(如(I1×T1,I1×T2,...,IN×TN))( I_1×T_1, I_1×T_2, ..., I_N×T_N ))(I1×T1,I1×T2,...,IN×TN)),构建交互矩阵——矩阵中值越高的位置,代表对应图像区域与文本token的语义匹配度越高(比如“小狗狗”对应的 (T3( T_3(T3 与图片中“小狗主体”对应的 (I3( I_3(I3),组合值会显著高于其他区域)。 -
跨模态向量对齐:
通过模型训练,让“语义匹配的跨模态向量”在最终的共享向量空间中距离更近(比如“小狗狗”的文本向量与小狗图片的图像向量,最终会聚集在空间的同一区域)。
2.5.3 核心价值:实现跨模态语义交互
多模态嵌入解决了“不同模态信息无法直接关联”的问题,核心应用场景包括:
- 以文搜图/以图搜文:输入文本“一只可爱的小狗狗”,检索语义匹配的小狗图片;或上传小狗图片,检索描述该图片的文本;
- 多模态内容理解:在智能客服中,同时理解用户发送的“文本+图片”信息(如用户发“这个商品坏了”+商品破损图,模型能关联两者的语义);
- 跨模态RAG:在知识库中同时存储文本、图片、视频的嵌入向量,支持用户用任意模态的查询(如图片)检索所有相关内容。
2.5.4 经典多模态嵌入模型
常见的多模态嵌入模型包括:
- CLIP(OpenAI):最主流的多模态模型之一,支持文本与图像的跨模态对齐,可直接实现以文搜图/以图搜文;
- ALIGN(Google):通过大规模图像-文本对训练,实现高精度的跨模态语义匹配;
- BLIP-2(Salesforce):结合语言模型与视觉模型,支持更复杂的多模态交互(如基于图片生成描述文本)。
2.5.5 与单模态嵌入的核心区别
| 维度 | 单模态嵌入(如Sentence-BERT) | 多模态嵌入(如CLIP) |
|---|---|---|
| 处理的信息类型 | 单一类型(仅文本/仅图像) | 多种类型(文本+图像+音频等) |
| 向量空间 | 单模态独立空间 | 多模态共享空间 |
| 核心能力 | 同模态内的语义匹配 | 跨模态的语义匹配 |
| 典型应用 | 文本检索、文本分类 | 以文搜图、多模态内容理解 |
3. 大语言时代的嵌入模型
3.1 MTEB排行榜
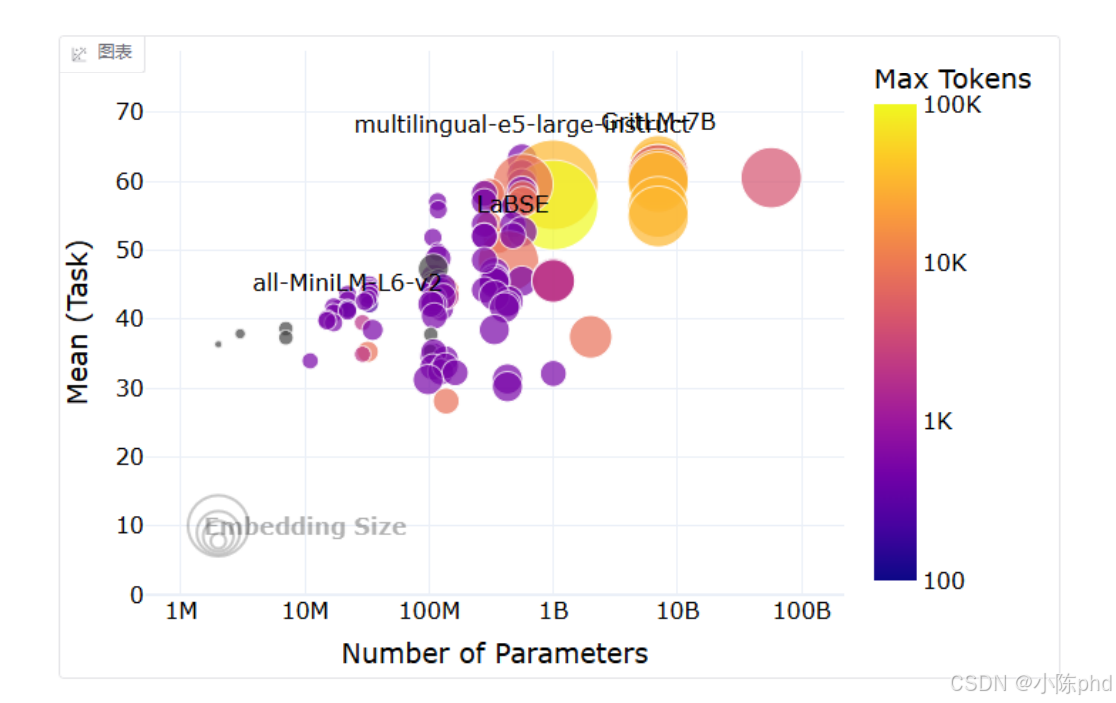
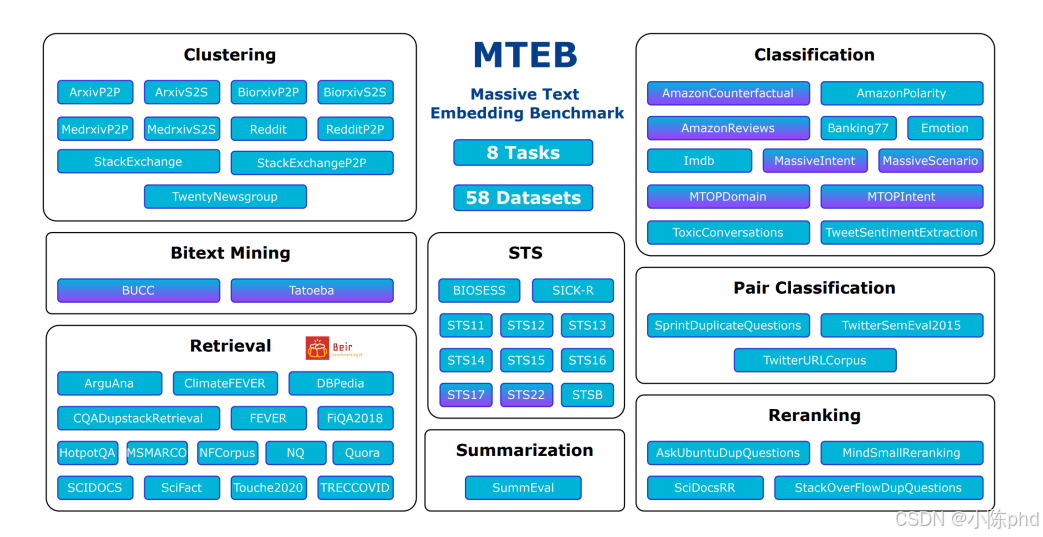

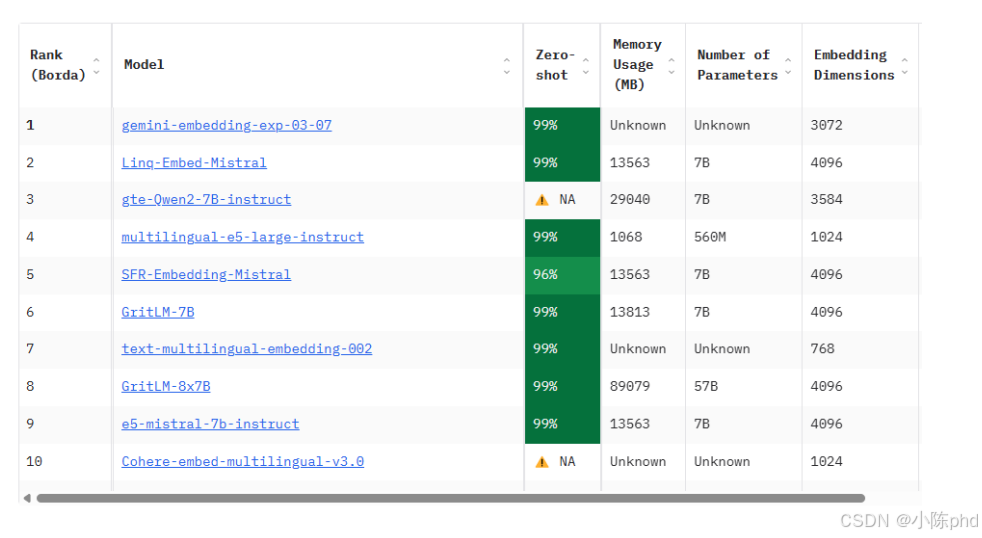
3.2 模型介绍
聚焦主流文本嵌入模型(含商用闭源与开源模型),从核心特性、技术细节、适用场景三方面展开,覆盖OpenAI、BGE、Jina等工业级常用模型,为嵌入模型选型提供明确参考:
3.2.1 OpenAI Embedding Models(闭源商用)
OpenAI的嵌入模型是目前语义捕捉精度最高的商用模型之一,基于大模型底层架构优化,适配多语言、长文本场景,广泛应用于企业级RAG、语义检索等核心任务。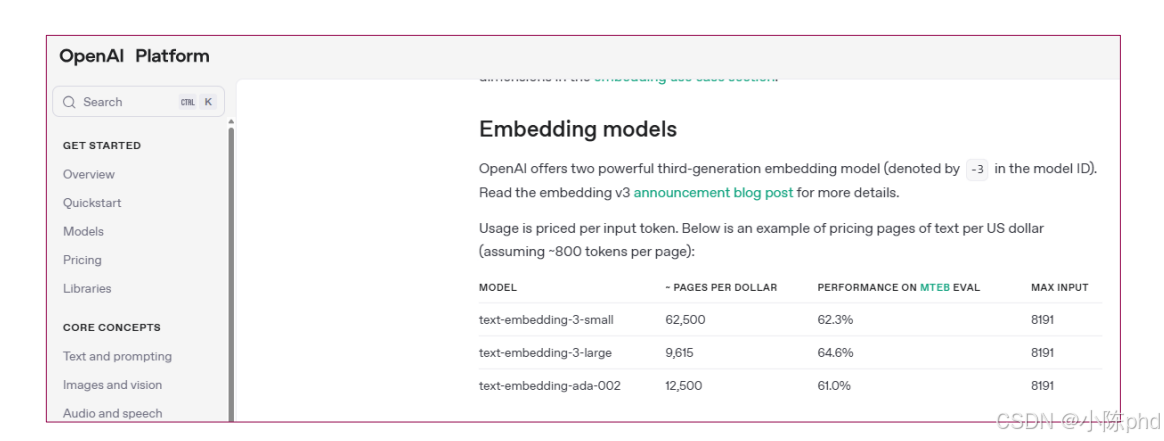
3.2.1.1 核心模型版本
- text-embedding-3-small:轻量高效版
- 向量维度:1536维;
- 特点:速度快、成本低(每1K Token约0.0001美元),支持多语言,语义精度满足多数场景;
- 适用:中小规模RAG、实时性要求高的检索任务。
- text-embedding-3-large:高精度版
- 向量维度:3072维;
- 特点:语义捕捉能力更强(尤其长文本、复杂语义场景),支持128K Token输入(约9.6万字),多语言适配更优;
- 适用:企业级知识库、高精度语义检索、长文档嵌入。
- text-embedding-ada-002(经典版):
- 向量维度:1536维;
- 特点:性价比高,是早期主流选择,语义精度优于初代模型,目前仍适用于中小规模场景。
3.2.1.2 核心优势与局限
- 优势:
- 语义精度顶尖:能捕捉细粒度语义差异(如“蛇灵组织的核心目标”与“蛇灵组织的次要诉求”);
- 长文本支持:text-embedding-3-large支持128K Token,无需复杂文本拆分;
- 多语言适配:天然支持100+种语言,跨语言语义对齐效果优异;
- 易用性强:通过OpenAI API调用,无需本地部署,适配LangChain、LlamaIndex等框架。
- 局限:
- 闭源依赖:需依赖OpenAI API,存在网络延迟、数据隐私风险(敏感数据需谨慎);
- 成本累积:大规模数据嵌入(如亿级文本)成本较高。
3.2.1.3 典型应用场景
- 企业级RAG知识库(如金融、法律行业高精度检索);
- 跨语言语义检索(如中文查询检索英文文档);
- 长文档语义分析(如学术论文、政策文件的嵌入)。
3.2.2 BGE Embeddings(开源免费)
BGE(BAAI General Embedding)是由北京人工智能研究院(BAAI)开发的开源高性能嵌入模型,专注于中文语义理解,在开源社区广泛应用,是“效果比肩商用、部署成本低”的首选开源方案。
3.2.2.1 核心模型版本
- BGE-base/bge-large(基础版):
- 向量维度:768维(base)/ 1024维(large);
- 特点:中文语义优化,训练数据包含大量中文语料,支持8192 Token输入;
- 适用:中文场景优先选择,中小规模RAG、文本分类。
- BGE-m3(最新版):
- 向量维度:1024维;
- 特点:多语言支持(中、英、日、韩等),语义精度接近text-embedding-3-small,支持32768 Token长文本,支持向量压缩(从1024维降至256维,不损失过多效果);
- 适用:大规模开源RAG、多语言场景、低存储成本需求。
- BGE-reranker(重排专用):
- 特点:专门用于检索结果重排,输入“查询+候选文本”,输出相关性得分,可与基础嵌入模型搭配使用,提升检索精准度。
3.2.2.2 核心优势与局限
- 优势:
- 中文效果顶尖:开源模型中中文语义捕捉最优(如“狄仁杰崇州案”“蛇灵六大蛇首”等中文专有名词的嵌入精度高);
- 开源免费:可本地部署,无API调用成本,数据隐私可控;
- 长文本与多语言:BGE-m3支持32K长文本,多语言适配能力强;
- 轻量灵活:支持CPU/GPU部署,小规模场景可直接用CPU推理。
- 局限:
- 大规模部署需硬件支持:large/m3版本在CPU上推理速度较慢,大规模场景需GPU(如A10、T4);
- 极端高精度场景略逊于OpenAI:复杂语义任务(如专业术语细粒度区分)精度稍低。
3.2.2.3 典型应用场景
- 中文RAG知识库(如政务、教育行业中文文档检索);
- 敏感数据场景(如企业内部涉密文档嵌入,需本地部署);
- 开源项目嵌入方案(无需商业授权)。
3.2.3 Jina Embeddings(商用+开源双版本)
Jina Embeddings是由Jina AI开发的嵌入模型,以“长文本、多语言、高效推理”为核心优势,提供商用API与开源版本,适配企业级与开发者场景。
3.2.3.1 核心模型版本
- Jina Embeddings v2(商用API):
- 向量维度:768/1024/3072维(可选);
- 特点:支持200K Token超长文本输入(约15万字),多语言支持(100+种),语义精度对标text-embedding-3-large,推理速度快;
- 适用:超长文档嵌入(如小说、行业报告)、企业级商用检索。
- jina-embeddings-v2-base(开源版):
- 向量维度:768维;
- 特点:开源免费,支持8192 Token,多语言优化,可本地部署,适合中小规模场景。
3.2.3.2 核心优势与局限
- 优势:
- 超长文本支持:商用版200K Token输入,无需拆分长文档(如整本书、完整政策文件);
- 高效推理:优化的推理引擎,相同硬件下速度快于同类模型;
- 商用+开源灵活选择:小规模用开源版,大规模用商用API,平滑迁移。
- 局限:
- 商用API成本中等:高于OpenAI,低于部分小众商用模型;
- 开源版语义精度略逊于BGE-m3/OpenAI:基础版开源模型在复杂语义场景效果一般。
3.2.3.3 典型应用场景
- 超长文档检索(如法律合同、学术专著的嵌入);
- 多语言企业知识库(如跨国公司多语言文档检索);
- 对推理速度要求高的实时检索场景。
3.2.4 Voyage AI Embeddings(闭源商用)
Voyage AI是专注于嵌入技术的创业公司,其嵌入模型以“长文本、高精度、多语言”为核心卖点,在长文档语义检索场景表现突出,受到海外企业广泛采用。
3.2.4.1 核心模型版本
- Voyage Embeddings-1:
- 向量维度:1024/2048维;
- 特点:支持160K Token超长文本输入,多语言支持(50+种),语义精度接近OpenAI text-embedding-3-large;
- 细分版本:Voyage-Lite(轻量版,速度快)、Voyage-Pro(高精度版,长文本优化)。
3.2.4.2 核心优势与局限
- 优势:
- 超长文本精度高:160K Token输入下仍能保持细粒度语义捕捉(如长文档中特定段落的精准匹配);
- 多语言语义对齐优:跨语言检索(如英文查询检索日文文档)效果优于多数同类模型;
- API稳定性强:专为企业级场景设计,服务可用性高,支持批量嵌入。
- 局限:
- 成本较高:商用API价格高于OpenAI,大规模使用成本累积明显;
- 中文支持略逊于BGE/OpenAI:中文语料训练较少,中文专有名词语义捕捉精度一般;
- 国内访问延迟高:服务器主要在海外,国内用户调用存在网络延迟。
3.2.4.3 典型应用场景
- 海外企业长文档知识库(如英文小说、海外政策文件检索);
- 跨语言长文本检索(如跨国项目多语言文档交互);
- 对长文本语义精度要求高的商用场景。
3.2.5 Cohere Embeddings(闭源商用)
Cohere是由前Google Brain团队创立的AI公司,其嵌入模型以“多语言、企业级安全、定制化”为核心优势,适配多语言企业场景与定制化嵌入需求。
3.2.5.1 核心模型版本
- embed-english/embed-multilingual:
- 向量维度:768/1024/4096维(可选);
- 特点:embed-english(英文优化)、embed-multilingual(50+种语言),支持512K Token超长文本输入;
- 定制化服务:支持企业私有数据微调,生成贴合特定行业(如医疗、金融)的嵌入模型。
3.2.5.2 核心优势与局限
- 优势:
- 企业级安全:支持数据隔离、私有部署,满足金融、医疗等行业合规要求;
- 定制化能力强:可基于企业私有语料微调,提升行业术语、专有名词的嵌入精度;
- 多语言长文本支持:512K Token输入+多语言适配,适合跨国企业大规模知识库。
- 局限:
- 成本高:基础API价格高于OpenAI,定制化微调额外收费;
- 中文支持一般:中文语料优化较少,中文场景效果不如BGE/OpenAI;
- 国内访问不便:主要服务海外企业,国内用户需解决网络与合规问题。
3.2.5.3 典型应用场景
- 跨国企业多语言知识库(如金融机构全球分支文档检索);
- 行业定制化场景(如医疗术语嵌入、法律合同语义检索);
- 高合规要求场景(如银行、保险行业的敏感数据嵌入)。
3.2.6 开源模型Stella(中文优化)
Stella是字节跳动开源的中文专用嵌入模型,基于BERT架构优化,专注于中文语义理解与低资源部署,适合中文开发者与中小规模中文场景。
3.2.6.1 核心模型版本
- Stella-base/stella-large:
- 向量维度:768维(base)/ 1024维(large);
- 特点:中文语料深度优化(涵盖新闻、小说、专业文档等),支持512-4096 Token输入,推理速度快(CPU可实时推理);
- 衍生版本:Stella-zh-embedding(通用嵌入)、Stella-zh-reranker(中文重排专用)。
3.2.6.2 核心优势与局限
- 优势:
- 中文轻量高效:在CPU上推理速度快于BGE,适合嵌入式设备、低配置服务器;
- 开源免费:无授权成本,支持本地部署与二次开发;
- 中文语义精准:对中文口语、网络用语、专业术语的适配性强(如“蛇灵组织”“崇州案”等中文专有名词嵌入效果好)。
- 局限:
- 多语言支持弱:仅优化中文,其他语言效果较差;
- 长文本支持有限:最大支持4096 Token,超长文档需拆分;
- 高精度场景略逊于BGE-m3:复杂语义任务(如长文本细粒度检索)精度稍低。
3.2.6.3 典型应用场景
- 中文轻量场景(如嵌入式设备的中文语义检索);
- 中小规模中文RAG(如个人知识库、小型企业中文文档检索);
- 中文重排任务(搭配其他嵌入模型,用Stella-reranker提升检索精度)。
3.2.7 主流模型核心对比表
| 模型名称 | 类型 | 向量维度 | 最大输入Token | 核心优势 | 适用场景 |
|---|---|---|---|---|---|
| OpenAI text-embedding-3-large | 闭源商用 | 3072维 | 128K | 高精度、多语言、长文本 | 企业级高精度检索、跨语言场景 |
| BGE-m3 | 开源免费 | 1024维(可压缩) | 32K | 中文最优、多语言、低成本 | 中文场景、开源RAG、本地部署 |
| Jina Embeddings v2 | 商用+开源 | 768/1024/3072维 | 200K | 超长文本、高效推理 | 超长文档检索、实时性要求高的商用场景 |
| Voyage AI Embeddings | 闭源商用 | 1024/2048维 | 160K | 长文本高精度、多语言 | 海外长文档知识库、跨语言长文本检索 |
| Cohere Embeddings | 闭源商用 | 768/1024/4096维 | 512K | 企业级安全、定制化 | 高合规行业、定制化术语嵌入 |
| Stella-large | 开源免费 | 1024维 | 4K | 中文轻量、CPU高效 | 中文低资源场景、嵌入式设备、中文重排 |
3.2.8 模型选型建议
- 优先选中文场景:开源选BGE-m3(长文本/多语言)、Stella(轻量CPU);商用选OpenAI text-embedding-3-small(精度优先);
- 超长文本场景(>10万Token):Jina Embeddings v2(商用)、Voyage AI(海外)、BGE-m3(开源,32K);
- 高合规/敏感数据场景:开源模型本地部署(BGE-m3、Stella);企业级选Cohere(私有部署);
- 成本敏感场景:开源模型(BGE-base、Stella-base);中小规模商用选OpenAI text-embedding-3-small;
- 跨语言场景:商用选OpenAI/Jina/Voyage;开源选BGE-m3。
通过以上模型的特性对比与选型建议,可根据“场景(中文/多语言、长文本)、成本(开源/商用)、合规要求”快速锁定适配的嵌入模型。
4. 稀疏嵌入+密集嵌入→混合检索
4.1 稀疏嵌入 vs 密集嵌入


稀疏嵌入与密集嵌入是文本向量化的两种核心范式,核心差异在于向量元素的分布形式与语义表达逻辑,二者分别适配不同的场景需求,以下结合图示展开详解:
4.1.1 稀疏嵌入:“非0即1”的离散特征表示
稀疏嵌入是早期文本向量化的主流方式,核心是用“离散的0/1元素”表示文本特征,图示中的[1, 0, 0, 1, 0, 0, 0, 1, 0, 0]是典型示例。
4.1.1.1 核心特点
- 元素分布:绝大多数元素为0,仅少数元素为1(或其他非0值);
- 维度特性:维度通常极大(如词汇量10万时,维度为10万);
- 语义逻辑:每个位置有明确含义(如位置i对应词汇表中的第i个词,值为1表示文本包含该词)。
4.1.1.2 典型代表
- 独热编码(One-Hot Encoding):每个词对应一个维度,包含该词则值为1,否则为0;
- TF-IDF:在独热编码基础上,用“词频-逆文档频率”加权,值为非0的实数,但仍以0元素为主。
4.1.1.3 优势与局限
- 优势:
- 语义解释性强:每个非0元素对应明确的词/特征,可直接解读文本包含的内容;
- 实现简单:无需复杂模型训练,直接基于词汇表统计生成。
- 局限:
- 维度爆炸:词汇量越大,向量维度越高(如10万词对应10万维),存储与计算成本极高;
- 语义孤立:无法体现词的关联(如“蛇灵”与“反派”的向量点积为0,无法体现语义相近);
- 数据稀疏:绝大多数元素为0,信息利用率极低。
4.1.1.4 适用场景
仅适用于简单、小规模的文本任务,如早期关键词检索、基础文本分类(已被密集嵌入逐步替代)。
4.1.2 密集嵌入:“连续实数”的语义压缩表示
密集嵌入是当前主流的文本向量化方式(如Word2Vec、BERT嵌入),核心是用“低维连续实数”压缩文本语义,图示中的[0.2, -0.5, 0.8, -0.3, 0.6]是典型示例。
4.1.2.1 核心特点
- 元素分布:所有元素为连续实数(可正可负),无大量0元素;
- 维度特性:维度相对较小(通常为50~1536维);
- 语义逻辑:特征由模型自动学习得到,单个维度无明确含义,但向量整体承载文本语义。
4.1.2.2 典型代表
- 词嵌入:Word2Vec、GloVe、FastText;
- 上下文嵌入:BERT、Sentence-BERT、OpenAI Embedding;
- 多模态嵌入:CLIP(文本+图像)。
4.1.2.1 优势与局限
- 优势:
- 低维高效:维度远低于稀疏嵌入,存储与计算成本可控;
- 语义关联强:语义相近的文本,向量在空间中距离更近(如“蛇灵”与“反派”的向量相似度高);
- 语义表达丰富:可捕捉复杂语义(如多义词的语境差异、长文本的整体含义)。
- 局限:
- 解释性弱:单个维度无明确含义,无法直接解读向量对应的具体特征;
- 依赖模型训练:需通过大规模语料训练模型,成本较高。
4.1.2.2 适用场景
适用于绝大多数现代NLP任务,如RAG语义检索、文本分类、智能问答、多模态交互等。
4.1.3 核心差异对比表
| 对比维度 | 稀疏嵌入 | 密集嵌入 |
|---|---|---|
| 元素形式 | 离散值(以0为主,少数为1/实数) | 连续实数(无大量0元素) |
| 维度范围 | 极大(通常与词汇量相当,如10万维) | 较小(50~1536维) |
| 语义逻辑 | 单个维度对应明确词/特征 | 向量整体承载语义,单个维度无明确含义 |
| 语义关联能力 | 弱(无法体现词的语义相近) | 强(语义相近则向量距离近) |
| 存储/计算成本 | 高(维度大、稀疏性导致冗余) | 低(低维稠密) |
| 解释性 | 强(可直接对应具体词) | 弱(需通过模型间接解读) |
| 主流应用场景 | 早期简单任务(关键词检索) | 现代NLP任务(RAG、问答等) |
4.1.4 实际应用中的选择逻辑
- 若需“简单、解释性强”的文本表示(如小规模关键词统计):可选用稀疏嵌入(如TF-IDF);
- 若需“语义关联、低维高效”的文本表示(如RAG、智能问答):必须选用密集嵌入(如BGE、OpenAI Embedding);
- 部分场景可“结合使用”:如先用稀疏嵌入做粗筛,再用密集嵌入做精准语义匹配,平衡效率与精度。
4.2 向量类型的对比
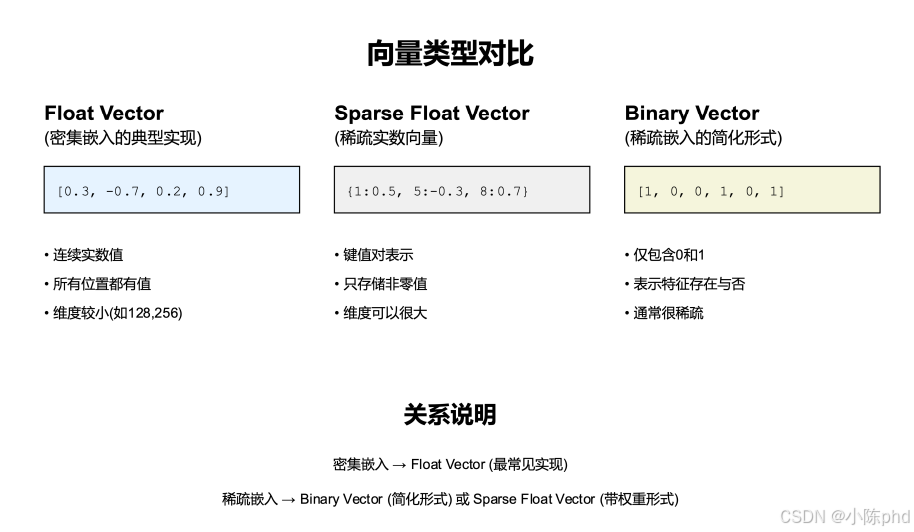
图中展示了三类主流向量类型(Float Vector、Sparse Float Vector、Binary Vector),它们是稀疏/密集嵌入的具体实现形式,核心差异在于元素形式、存储方式与适用场景。
4.2.1 Float Vector(密集嵌入的典型实现)
Float Vector是现代文本嵌入的主流形式,对应“密集嵌入”的核心实现,图示中的[0.3, -0.7, 0.2, 0.9]是典型示例。
4.2.1.1 核心特点
- 元素形式:连续实数值(可正可负);
- 存储方式:所有位置都有值,无空缺;
- 维度特性:维度较小(通常128~2048维)。
4.2.1.2 本质与关联
Float Vector是“密集嵌入”的最常见实现——如Word2Vec、BERT、OpenAI Embedding生成的向量,都属于Float Vector。
4.2.1.3 适用场景
所有需要语义精准匹配的场景,如RAG检索、智能问答、文本相似度计算等。
4.2.2 Sparse Float Vector(稀疏实数向量)
Sparse Float Vector是“稀疏嵌入”的带权重形式,图示中的{1:0.5, 5:-0.3, 8:0.7}(键为维度索引,值为非零实数)是典型示例。
4.2.2.1 核心特点
- 元素形式:实数,但仅存储非零值(以“键值对”形式表示);
- 存储方式:仅保留非零元素,节省空间;
- 维度特性:维度可以极大(如与词汇量相当)。
4.2.2.2 本质与关联
Sparse Float Vector是“稀疏嵌入”的进阶形式——在独热编码基础上增加权重(如TF-IDF的向量表示),非零值对应“词的权重”。
4.2.2.3 适用场景
需保留特征权重的稀疏场景,如传统关键词检索(结合词频权重)、简单文本分类等。
4.2.3 Binary Vector(稀疏嵌入的简化形式)
Binary Vector是“稀疏嵌入”的极简形式,图示中的[1, 0, 0, 1, 0, 1]是典型示例。
4.2.3.1 核心特点
- 元素形式:仅包含0和1;
- 语义逻辑:1表示“特征存在”,0表示“特征不存在”;
- 维度特性:通常维度极大且稀疏(多数元素为0)。
4.2.3.2 本质与关联
Binary Vector是“稀疏嵌入”的基础形式——对应独热编码,非零值仅表示“词是否出现”,无权重。
4.2.3.3 适用场景
简单特征存在性判断的场景,如早期关键词匹配(仅判断是否包含特定词)。
4.2.4 三类向量核心对比表
| 向量类型 | 元素形式 | 存储方式 | 维度特性 | 对应嵌入类型 | 核心优势 | 适用场景 |
|---|---|---|---|---|---|---|
| Float Vector | 连续实数 | 全量存储 | 小(128~2048) | 密集嵌入 | 语义精准、低维高效 | RAG检索、智能问答、语义匹配 |
| Sparse Float Vector | 实数(仅存非零) | 键值对存储 | 大(与词汇量相当) | 稀疏嵌入 | 保留权重、节省空间 | 传统关键词检索(带权重)、文本分类 |
| Binary Vector | 0/1 | 全量存储 | 大且稀疏 | 稀疏嵌入 | 实现简单、解释性强 | 简单关键词匹配(仅判断存在性) |
4.2.5 关系说明(图中核心逻辑)
从嵌入类型到向量类型的对应关系:
- 密集嵌入 → Float Vector(最常见的实现形式);
- 稀疏嵌入 → Binary Vector(简化形式,仅存0/1) 或 Sparse Float Vector(带权重形式,存非零实数)。
4.2.6 实际应用中的选择
- 优先选Float Vector:现代NLP任务(如RAG、智能问答)几乎都用此类型,平衡语义精度与效率;
- 仅简单场景用Sparse/Binary Vector:如传统关键词检索、小规模特征统计,需解释性强的场景。
4.3 BM25:典型的稀疏嵌入实现

BM25是信息检索领域经典的稀疏嵌入算法,核心是通过“词频+逆文档频率+文档长度”计算词的权重,生成仅包含“词-权重”的稀疏向量,是传统关键词检索的主流方案之一。
4.3.1 BM25的核心逻辑
BM25的目标是计算“词与文档的相关性得分”,并将得分作为稀疏向量的非零值(仅出现的词对应维度有值,其余为0),本质是“带权重的稀疏嵌入”。
4.3.2 核心公式拆解
BM25的得分由词频(TF)、逆文档频率(IDF)、文档长度惩罚三部分共同决定,公式分为“得分计算式”和“IDF计算式”:
4.3.2.1 词的相关性得分公式
[score(w)=IDF(w)⋅TF(w)⋅(k1+1)TF(w)+k1⋅(1−b+b⋅文档长度平均文档长度)][ \text{score}(w) = \text{IDF}(w) \cdot \frac{\text{TF}(w) \cdot (k_1 + 1)}{\text{TF}(w) + k_1 \cdot \left(1 - b + b \cdot \frac{\text{文档长度}}{\text{平均文档长度}}\right)} ] [score(w)=IDF(w)⋅TF(w)+k1⋅(1−b+b⋅平均文档长度文档长度)TF(w)⋅(k1+1)]
- TF(w):词( w )在当前文档中的出现次数(词频);
- k1k_1k1:词频饱和系数(通常取1.2,控制词频的边际收益,避免高频词权重过高);
- bbb:文档长度惩罚系数(通常取0.75,控制文档长度对得分的影响,避免长文档中词权重被低估);
- 文档长度/平均文档长度:当前文档长度与语料库中文档平均长度的比值(长文档会被适当惩罚)。
4.3.2.2 逆文档频率(IDF)公式
[IDF(w)=log总文档数−包含词w的文档数+0.5包含词w的文档数+0.5+1][ \text{IDF}(w) = \log \frac{\text{总文档数} - \text{包含词}w\text{的文档数} + 0.5}{\text{包含词}w\text{的文档数} + 0.5} + 1 ][IDF(w)=log包含词w的文档数+0.5总文档数−包含词w的文档数+0.5+1]
- IDF的作用:衡量词的“稀缺性”——包含词www的文档越少,IDF值越高(如“狲狲”“金刚体”这类专有名词,IDF值高,权重更大)。
4.3.3 稀疏嵌入的实现方式(结合示例)
以图中文本“狲狲施展烈焰拳,击退妖怪;随后开启金刚体,抵挡神兵攻击。”为例,BM25生成稀疏向量的过程:
- 词表映射:词表包含10000个词,每个词对应一个维度(如“狲狲”对应103维、“金刚体”对应302维);
- 计算词权重:仅对文本中出现的词(“狲狲”“烈焰拳”“金刚体”等)计算BM25得分(即权重);
- 生成稀疏向量:向量维度为10000,但仅“103维(狲狲)、302维(金刚体)”等出现的词对应维度有值(值为BM25得分),其余维度为0。
4.3.4 BM25作为稀疏嵌入的核心特点
- 稀疏性:仅出现的词对应维度有值,向量极稀疏(如10000维向量仅少数维度非零);
- 权重可解释:非零值对应“词的相关性得分”,可直接关联具体词(如103维的值对应“狲狲”的权重);
- 依赖关键词匹配:仅基于词的出现与否计算权重,无法捕捉语义关联(如“狲狲”与“妖怪”的语义关系无法体现);
- 效率高:稀疏向量存储与计算成本低,适合大规模关键词检索场景。
4.3.5 BM25的适用场景与局限
-
适用场景:
- 传统关键词检索(如搜索引擎的粗筛、文档关键词匹配);
- 对解释性要求高的场景(需明确知道“哪些词导致文档被检索”);
- 大规模语料的快速检索(稀疏计算效率高)。
-
局限:
- 无法处理语义关联(如查询“狲狲的攻击技能”,无法匹配包含“烈焰拳”但未出现“攻击技能”的文档);
- 对多义词、同义词不敏感(如“神兵”与“兵器”无法被识别为语义相近);
- 无法捕捉上下文语义(如“金刚体”在不同文本中的语义差异无法体现)。
4.3.6 BM25与密集嵌入的互补性
现代检索系统通常将“BM25(稀疏关键词检索)”与“密集嵌入(语义检索)”结合使用:
- 先用BM25做粗筛(快速过滤大量无关文档);
- 再用密集嵌入做精准语义匹配(提升检索结果的语义相关性);
这种“稀疏+密集”的混合检索,既能保证效率,又能兼顾语义精度。
4.4 BGE-M3

BGE-M3是北京人工智能研究院(BAAI)推出的下一代多能力嵌入模型,其命名中的“M3”对应“多功能性、多语言性、多粒度性”三大核心特性,是当前开源嵌入模型中功能最全面的方案之一,以下结合图示详解:
4.4.1 “M3”命名的核心含义
BGE-M3的“M3”并非版本号,而是对其三大核心能力的概括:
- 多功能性(Multi-Functionality):集成“密集检索、稀疏检索、多向量检索”3种检索模式,可灵活适配不同场景;
- 多语言性(Multi-Linguality):支持超过100种语言,具备跨语言检索能力;
- 多粒度性(Multi-Granularity):支持从短句到8192 Token长文档的处理,覆盖不同长度文本的嵌入需求。
4.4.2 三大核心特性详解
4.4.2.1 多功能性:一站式覆盖多检索模式
BGE-M3是首个同时支持密集、稀疏、多向量检索的开源嵌入模型,无需额外集成其他工具:
- 密集检索:生成低维稠密向量(默认1024维),用于语义精准匹配(如RAG的核心检索);
- 稀疏检索:同时生成稀疏向量(基于词的权重),实现关键词级匹配(替代传统BM25);
- 多向量检索:将长文档拆分为多个子向量,捕捉长文本的细粒度语义(避免长文档语义丢失)。
这一特性让BGE-M3可“一键实现混合检索”,同时兼顾语义精度与关键词匹配能力。
4.4.2.2 多语言性:支持100+语言的跨语言对齐
BGE-M3在100+种语言的大规模语料上训练,实现了跨语言语义对齐:
- 不同语言的同义文本,生成的向量相似度极高(如中文“蛇灵是反派组织”与英文“Snake Spirit is a villain organization”的向量距离极近);
- 支持“用中文查询检索其他语言文档”“多语言文档混合检索”等场景,适配跨国、多语言知识库需求。
4.4.2.3 多粒度性:覆盖全长度文本的嵌入
BGE-M3支持从短句到8192 Token长文档的嵌入,解决了传统嵌入模型“长文本语义丢失”的问题:
- 短句:精准捕捉短文本的细粒度语义(如“狲狲的烈焰拳”);
- 长文档:通过多向量检索拆分长文本为子片段,每个子片段生成独立向量,确保长文档中的细节信息被保留(如8192 Token的政策文件,可捕捉其中的具体条款)。
4.4.3 BGE-M3的核心优势
相比传统嵌入模型,BGE-M3的核心优势在于“一站式解决多场景需求”:
- 功能集成:无需同时部署“密集模型+BM25+长文本拆分工具”,一个模型覆盖所有检索模式;
- 成本可控:开源免费,可本地部署,无API调用成本,数据隐私可控;
- 效果均衡:在中文语义精度、多语言对齐、长文本处理上均达到开源模型的顶尖水平,接近OpenAI等商用模型。
4.4.4 适用场景
BGE-M3的多功能性使其适配绝大多数嵌入场景:
- 中文RAG知识库:兼顾语义精度与关键词匹配;
- 多语言企业知识库:支持跨语言检索;
- 长文档嵌入:8192 Token长文本的细粒度检索;
- 混合检索系统:替代“BM25+密集模型”的传统混合方案,简化部署流程。
4.4.5 与其他主流模型的对比
| 模型 | 多功能性(密+稀+多向量) | 多语言支持 | 长文本处理(最大Token) | 开源/商用 |
|---|---|---|---|---|
| BGE-M3 | ✅ 支持 | 100+种 | 8192 | 开源免费 |
| OpenAI text-embedding-3-large | ❌ 仅密集 | 100+种 | 128K | 闭源商用 |
| BGE-base | ❌ 仅密集 | 中文为主 | 512 | 开源免费 |
| Jina Embeddings v2 | ❌ 仅密集 | 100+种 | 200K | 商用+开源 |
BGE-M3的“M3”特性,使其成为当前开源嵌入模型中“功能最全面、场景适配性最强”的选择,尤其适合需要兼顾多检索模式、多语言、长文本的复杂场景。
5. 多模态嵌入模型的应用
5.1 多模态处理的核心特点(以Visualized_BGE为例)
Visualized_BGE是BGE系列衍生的多模态嵌入模型(由FlagOpen团队开发),核心是在同一框架下实现“文本+图像”的联合嵌入,其核心特点围绕“多模态处理、统一嵌入空间、跨模态检索”展开:
5.1.1 多模态处理:同一框架兼容文本与图像
Visualized_BGE的核心能力是在单一模型架构中同时处理文本和图像数据,无需额外集成独立的文本编码器/图像编码器:
- 文本处理:复用BGE的文本编码能力,支持多语言、长文本的语义嵌入;
- 图像处理:引入视觉编码器(如ViT),将图像转化为与文本同维度的向量;
- 优势:避免多模型集成的兼容性问题,简化部署流程,降低推理成本。
5.1.2 统一嵌入空间:文本与图像的向量可直接比对
Visualized_BGE通过跨模态对齐训练,将文本、图像映射到同一向量空间:
- 训练逻辑:利用“文本-图像配对数据”(如“一只小狗”的文本与对应的小狗图片)训练模型,让语义匹配的文本和图像在向量空间中距离极近;
- 效果:文本向量与图像向量的相似度可直接计算(如“可爱的小狗”的文本向量,与小狗图片的图像向量,相似度远高于与猫咪图片的向量)。
5.1.3 跨模态检索:实现“以文搜图、以图搜文”
基于“统一嵌入空间”,Visualized_BGE支持双向跨模态检索,是其核心应用价值:
- 以文搜图:输入文本描述(如“蛇灵组织的标志”),检索向量空间中最相似的图像;
- 以图搜文:输入图像(如一张狄仁杰的剧照),检索向量空间中最匹配的文本描述(如“狄仁杰在崇州案中的造型”);
- 适用场景:多模态知识库、图文内容推荐、智能内容检索等。
5.1.4 Visualized_BGE的额外特性(结合项目信息)
从GitHub项目信息看,Visualized_BGE还具备:
- 开源可定制:提供训练、微调代码,支持基于企业私有图文数据优化(如特定领域的图文对齐);
- 多任务适配:支持零样本跨模态检索(无需针对特定任务微调),适配不同场景的快速落地;
- 兼容BGE生态:可与BGE-M3等文本嵌入模型协同使用,构建“文本+图像”的多模态RAG系统。
5.1.5 核心价值与适用场景
Visualized_BGE的核心价值是打破文本与图像的模态壁垒,让多模态数据可通过向量直接交互,典型适用场景包括:
- 多模态知识库:同时存储文本文档与配套图像,支持图文混合检索;
- 内容创作辅助:输入文本描述检索参考图像,或输入图像生成匹配的文本说明;
- 智能客服:同时理解用户发送的“文本+图像”信息(如“这个商品坏了”+破损图),精准匹配解决方案。
Visualized_BGE作为BGE生态的多模态延伸,是开源领域中“文本-图像跨模态嵌入”的优质方案之一,尤其适合需要低成本构建多模态检索系统的场景。
5.2 嵌入技术最新发展


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)