深入理解 LlamaIndex 的 Index:RAG 的核心基础设施详解
Index 是 LlamaIndex 框架最重要、也是最容易被忽略的组件。它不仅负责将文档拆解为结构化的数据单元,还承担了检索、组织、路由和查询优化的功能。如果把 RAG 的整体结构比作一辆汽车,那么 Index 就是其中的引擎。本文将深入讲解 LlamaIndex 中 Index 的设计理念、工作机制、常见类型、构建流程以及与 Query Engine / Chat Engine 的协同关系,帮
前言
随着大模型在企业业务中的落地逐步加速,RAG(Retrieval-Augmented Generation,检索增强生成) 已成为提升模型事实准确性、可控性与可追溯性的关键手段。然而,一个高效、稳定的 RAG 系统绝不仅仅是将Embedding 和向量数据库接在一起,而是需要一套能稳定处理文档、组织知识结构、支持多种检索模式的基础设施。在 LlamaIndex 中,这个核心便是 Index(索引)。
Index 是 LlamaIndex 框架最重要、也是最容易被忽略的组件。它不仅负责将文档拆解为结构化的数据单元,还承担了检索、组织、路由和查询优化的功能。如果把 RAG 的整体结构比作一辆汽车,那么 Index 就是其中的引擎。本文将深入讲解 LlamaIndex 中 Index 的设计理念、工作机制、常见类型、构建流程以及与 Query Engine / Chat Engine 的协同关系,帮助读者在构建 RAG 系统时更加得心应手。
1 什么是 Index?
1.1 Index 的官方定义与核心职责
根据 LlamaIndex 的定义:
Index 是一个数据结构,用来从用户查询中快速检索相关上下文,是 RAG 的核心基础。
这一定义虽然简洁,但体现了 Index 的三个关键点:
- 它是一种数据结构,而不是数据库或模型。
- 它的目标是 “快速检索”,强调性能和相关性。
- 它服务于 RAG,专为问答和聊天类任务设计。
换言之,Index 是数据进入 RAG 系统的 “入口与枢纽”。它决定了:
- 文档如何拆分
- 如何存储成 Node
- 如何进行向量化与结构化
- 如何执行检索逻辑
从系统角度看,它是一层封装:
输入 → 文档(Documents)
输出 → 检索器(Retriever)
而应用层的 Query Engine 与 Chat Engine 都构建在 Index 之上。
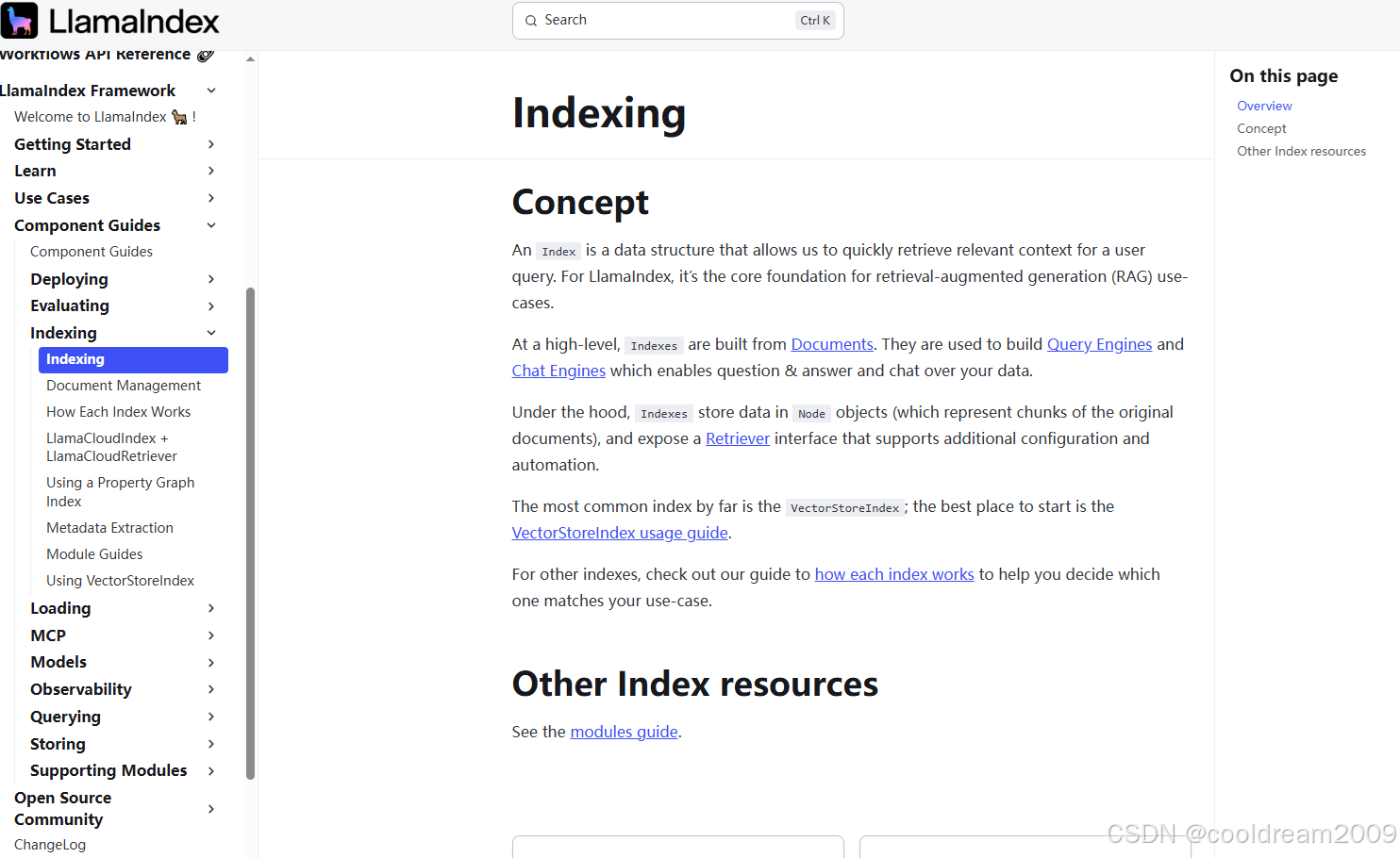
1.2 Index 的三层结构:Documents → Nodes → Index
为了让数据更易于检索与管理,LlamaIndex 将所有输入文档标准化为如下三层结构:
| 层级 | 含义 | 主要内容 | 作用 |
|---|---|---|---|
| Documents | 原始文档 | 文本、PDF、网页、数据库结果 | 数据来源 |
| Nodes | 文档块 | 文本片段、分段、带 metadata | 检索粒度 |
| Index | 节点组织结构 | 向量结构、树结构、关键词表 | 提供快速检索能力 |
其中,Node 是最关键的一层,它包含:
- 文本 chunk
- 原文位置(引用用)
- 文档关联 metadata(如时间、作者、路径)
- 结构关系(如前后节点、章节隶属)
Index 正是建立在 Node 之上,将它们组织成最适合检索的结构。
2 为什么 Index 是 RAG 的核心?
2.1 RAG 本质上是检索质量问题
任何 RAG 系统都遵循同一条逻辑链:
- 用户查询
- 模型无法直接回答
- 系统检索相关知识
- 模型基于知识生成答案
其中获取知识的步骤,是决定输出质量的最重要环节。
如果检索不准,再强大的模型也无法给出正确答案。
Index 的职责正是解决:
- 如何拆分文档使语义清晰?
- 如何让检索结果尽量相关?
- 如何进行 metadata 的过滤?
- 如何提高查准率与查全率?
- 如何在多类型数据间协调检索策略?
这也是为什么 Index 在 LlamaIndex 中比向量库更重要——它提供了检索策略,而不仅是存储。
2.2 Index 统一了检索接口:Retriever
构建 RAG 系统时,我们通常会处理:
- 向量检索
- 关键词查询
- 混合检索(Hybrid Search)
- metadata 过滤
- rerank 二次排序
- 多模态检索(图文并存)
Retriever 是 Index 对外暴露的统一接口。
无论底层使用的是 Faiss、Milvus、Weaviate、ElasticSearch,还是自建 JSON 文件系统,Retriever 始终保持一致的 API。
它的功能包括:
- top-k 相似度检索
- 带权重的相似度融合
- reranker 调整排序
- 过滤器(例如按文档类型)
- 自定义 pipeline
因此,Index + Retriever 构成了一个抽象层,让系统可扩展、可插拔。
3 Index 的内部结构与工作流程
为了更直观地理解 Index,下面解释其完整的构建流程。
3.1 Document 构建与加载
文档进入系统后,会经历预处理:
- 去除格式异常
- 内容抽取(如 PDF、HTML)
- 分段结构识别(标题、列表、章节)
- metadata 注入(如路径、时间戳)
3.2 文档切分(Node Parsing)
这是决定检索效果的关键一步。
Node 通常按以下策略拆分:
- 固定字数(如 512 token)
- 按段落、标题、章节结构切
- 按语义切分
- 自动识别列表、表格
每个 Node 带有:
- 文本内容
- 原文引用
- 上下文关系(前后 Node)
- 文档 metadata
3.3 向量化(Embedding)
每个 Node 会转换为 embedding,用于向量检索。
LlamaIndex 不限制 embedding 模型,常见选项:
- OpenAI text-embedding-3-large
- bge-large-zh
- jina embeddings
- 本地 embedding 模型
4 常见 Index 类型与使用场景
4.1 VectorStoreIndex:最常用的向量检索索引
适用于所有 RAG 场景,是默认选择。
它的特点:
- 基于向量相似度
- 支持所有主流向量数据库
- 速度快,召回稳定
- 支持 metadata 过滤
- 适合集成 reranker
是目前 LlamaIndex 使用率最高的索引结构。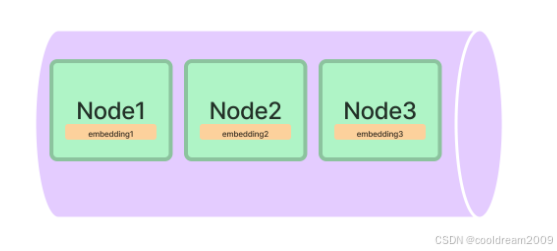
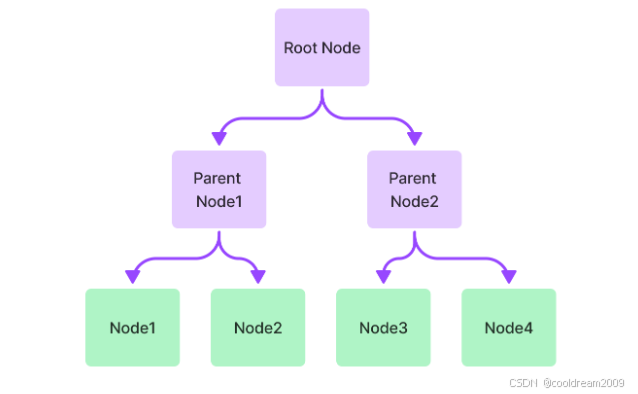
4.2 TreeIndex:用于长文档总结
TreeIndex 会将文档构建为多层树:
- 下层是原始 Node
- 上层是自动生成的摘要 Node
- 顶层是全局摘要
适用于:
- 超长文档总结
- 分层阅读
- 面向结构化长文档(如法律文档)
4.3 KeywordTableIndex:用于关键词检索
适合:
- 文档结构清晰
- 术语固定
- 不需要 embedding 检索
如法规、手册、API 文档。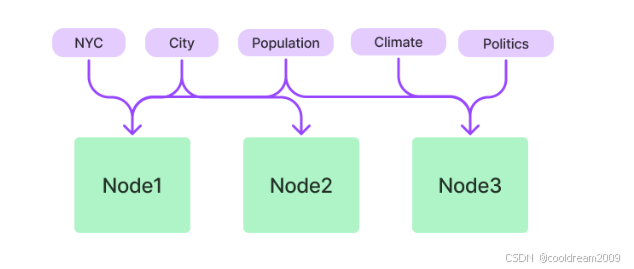
4.4 SummaryIndex:分层摘要索引
适合:
- 多文档总结
- 会议记录
- 非结构化文本梳理
5 Retriever:Index 的对外统一接口
Retriever 是 Index 的核心能力出口。
它提供:
- TopK 搜索
- Metadata 过滤
- Hybrid 检索
- reranker 支持
- 自定义检索策略
这一层抽象让 RAG 系统具有极强的灵活性,可在不同 Index 间自由切换。
6 Index、Query Engine、Chat Engine 的关系
为了理解 Index 在整个 LlamaIndex 系统中的地位,这里给出一个结构表述:
| 组件 | 输入 | 输出 | 主要作用 |
|---|---|---|---|
| Index | 文档 | Retriever | 构建知识库 |
| Query Engine | 查询 | Response | 问答、总结、检索增强 |
| Chat Engine | 多轮对话 | 回答 | 上下文增强的聊天能力 |
工作流程如下:
- 用户提问
- Chat Engine 调用 Query Engine
- Query Engine 使用 Retriever
- Retriever 查询 Index
- Index 返回 Node 列表
- 模型基于 Node 生成答案
Index 是整个数据与检索的底座。
7 实战:构建一个最小可用的 Index(示例代码)
下面的流程是构建 RAG 的最小示例:
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("什么是微服务?")
print(response)
真实系统中,你可以:
- 接入 Faiss/Milvus 等向量数据库
- 自定义 embedding
- 配置 reranker
- 添加 metadata 过滤
结语
在快速迭代的 RAG 技术体系中,LlamaIndex 的 Index 扮演着 “知识组织者” 的角色——它比向量数据库更高层,比 Query Engine 更贴近数据,是整个知识处理链条的核心。
理解 Index,不仅能够帮助你构建稳定、高质量的检索系统,更能让你根据业务特点选择最佳策略,从而构建真正可控、可解释、可扩展的企业级 RAG 应用。
无论你使用的是本地模型、云端服务还是混合部署,Index 都可以作为你的知识管理中枢,为你的 RAG 系统打下坚实基础。
参考资料
1 LlamaIndex 官方文档:https://docs.llamaindex.ai
2 Index 体系结构说明:https://docs.llamaindex.ai/en/latest/module_guides/index
3 VectorStoreIndex 使用指南:https://docs.llamaindex.ai/en/latest/examples/vector_stores

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)