在脑部MRI数据集上对MedGemma进行微调
本文介绍了在医疗影像分析中使用MedGemma-4B模型进行脑部MRI分类任务的微调方法。首先加载并预处理脑肿瘤MRI数据集,将其转换为适合模型训练的对话格式。通过LoRA微调技术,仅训练少量参数就使模型准确率从基础模型的33%大幅提升至92%。教程详细展示了从数据准备、模型配置到训练评估的全流程,证明了MedGemma在医学图像分类任务中的强大潜力,为医疗AI应用提供了高效精准的解决方案。
引言
人工智能在医疗影像分析领域的应用正以前所未有的速度发展,为早期诊断和精准治疗带来了革命性的机遇。多模态大型模型,特别是那些专为医疗领域设计的模型,正成为这一变革的核心。
MedGemma是Gemma 3模型家族中专注于医疗的变体集合,旨在有效地地处理医疗文本和图像。该系列目前包含两个强大的变体:一个4B参数的多模态版本和一个27B参数的纯文本版本。
本教程将重点关注MedGemma 4B模型。该模型巧妙地结合了 SigLIP 图像编码器与一个大型语言模型(LLM)。其图像编码器已在多样化的、匿名的医疗数据集(如胸部X光、皮肤镜、眼科图像和病理切片)上进行了预训练,而语言模型则在海量的医学文本数据上进行了训练。
在本教程中,我们将在一个脑部MRI数据集上对MedGemma 4B模型进行微调,以完成图像分类任务。我们的目标是让这个更小的MedGemma 4B模型能够高效、准确地对脑部MRI扫描进行分类,并预测脑癌的存在。
微调流程
1.安装 Python 包
首先通过运行以下命令安装本次任务所需要的Python 包
!pip install --upgrade --quiet transformers bitsandbytes datasets evaluate peft trl scikit-learnWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager, possibly rendering your system unusable.It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv. Use the --root-user-action option if you know what you are doing and want to suppress this warning.
2.加载数据集
首先指定脑部肿瘤 MRI 数据集路径,按 8:2 比例划分训练集和验证集,加载数据后进行拆分(打乱顺序且固定种子),最后打印数据集信息,完成数据加载与划分准备。
from datasets import load_dataset
data_dir = "/data/Brain_Cancer_MRI-dataset"
train_size = 0.8
validation_size = 0.2
data = load_dataset("imagefolder", data_dir=data_dir, split="train")
data = data.train_test_split(
train_size=train_size,
test_size=validation_size,
shuffle=True,
seed=42,
)
data["validation"] = data.pop("test")
print(data)/opt/conda/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 4844
})
validation: Dataset({
features: ['image', 'label'],
num_rows: 1212
})
})
输出是数据集的结构化信息,已成功将数据拆分为训练集和验证集两个部分。训练集包含 4844 个样本,验证集包含 1212 个样本,两者都有 “image”(图像数据)和 “label”(对应标签)两类信息,整体数据格式符合图像分类任务的使用需求。
检查训练集中的一张图像及其相应的标签:
data["train"][18]["image"]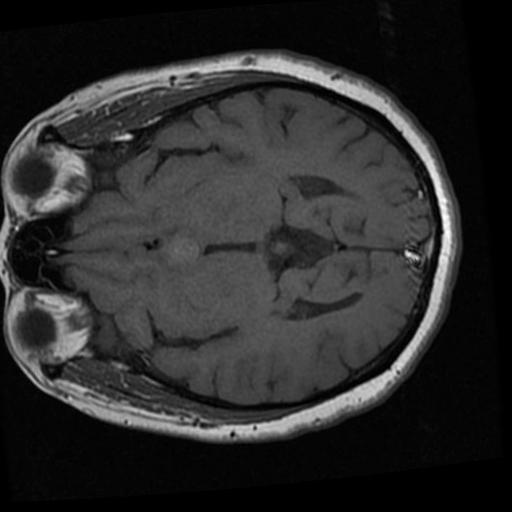
print(data["train"][18]["label"])2
3.数据集处理
在处理数据集之前,先检查标签名称以确保能正确处理分类任务。
BRAIN_CANCER_CLASSES = data["train"].features["label"].names
print("Detected classes:", BRAIN_CANCER_CLASSES)Detected classes: ['brain_glioma', 'brain_menin', 'brain_tumor']
输出表明数据集标签包含 3 类:分别是 “brain_glioma”(脑部胶质瘤)、“brain_menin”(脑部脑膜瘤)和 “brain_tumor”(脑部肿瘤)。为优化分类流程,我们将对这些类别标签进行修改,为其添加前缀(A、B、C)。这样做既能让标签组织更清晰,也能使其适配自定义的提示词格式。
BRAIN_CANCER_CLASSES = ['A: brain glioma', 'B: brain menin', 'C: brain tumor']创建模型微调时用的自定义提示词,将之前添加前缀后的 3 个脑部肿瘤类别用换行符连接,再将问题与这个选项列表组合,形成完整的提示词。这样的提示词能清晰引导模型在微调时,基于 MRI 图像从给定类别中判断肿瘤类型,确保模型理解任务目标和可选答案范围。
options = "\n".join(BRAIN_CANCER_CLASSES)
PROMPT = f"这张 MRI 图像中显示的最可能是哪种类型的脑癌?\n{options}"随后,将数据集转换为适合大模型微调的 “对话格式”,让模型能理解输入(图像 + 问题)与输出(答案)的对应关系。
def format_data(example: dict[str, any]) -> dict[str, any]:
example["messages"] = [
{
"role": "user",
"content": [
{
"type": "image",
},
{
"type": "text",
"text": PROMPT,
},
],
},
{
"role": "assistant",
"content": [
{
"type": "text",
"text": BRAIN_CANCER_CLASSES[example["label"]],
},
],
},
]
return example
formatted_data = data.map(format_data)查看格式化后的训练集中某个样本的核心对话内容。
formatted_data["train"][18]["messages"][{'content': [{'text': None, 'type': 'image'},
{'text': '这张 MRI 图像中显示的最可能是哪种类型的脑癌?\nA: brain glioma\nB: brain menin\nC: brain tumor',
'type': 'text'}],
'role': 'user'},
{'content': [{'text': 'C: brain tumor', 'type': 'text'}],
'role': 'assistant'}]
整个结构清晰呈现了 “输入(图像 + 问题 + 选项)→输出(答案)” 的对应关系,模型在微调时会通过大量此类样本学习:当收到包含 MRI 图像和同类问题的输入时,应从给定选项中选择匹配的肿瘤类型作为输出。
4.加载模型
指定本地 MedGemma-4B-it 模型路径,先检查 GPU 是否支持 bfloat16 格式以确保兼容性,再配置模型加载参数,随后加载模型和处理器,最后调整处理器填充方向,为后续医学图像文本任务做好模型准备。
import torch
from transformers import AutoProcessor, AutoModelForImageTextToText, BitsAndBytesConfig
model_id = "/model-202510/medgemma-4b-it"
if torch.cuda.get_device_capability()[0] < 8:
raise ValueError("GPU does not support bfloat16, please use a GPU that supports bfloat16.")
model_kwargs = dict(
attn_implementation="eager",
dtype=torch.bfloat16,
device_map="auto",
)
model = AutoModelForImageTextToText.from_pretrained(model_id, **model_kwargs)
processor = AutoProcessor.from_pretrained(model_id)
processor.tokenizer.padding_side = "right"Loading checkpoint shards: 100%|██████████| 2/2 [00:02<00:00, 1.28s/it]
5.模型设置
我们采用LoRA微调方法,无需训练模型全部参数,仅通过训练少量额外的低秩矩阵参数来适配模型,既能让模型较好贴合脑部肿瘤 MRI 分类任务需求,又能大幅减少计算资源消耗、降低显存占用,兼顾微调效果与效率
from peft import LoraConfig
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.05,
r=16,
bias="none",
target_modules="all-linear",
task_type="CAUSAL_LM",
modules_to_save=[
"lm_head",
"embed_tokens",
],
)为在训练过程中同时处理图像和文本输入,我们定义了一个自定义的数据整理函数。该函数会将数据集中的样本处理成模型可接受的格式,具体包括对文本进行分词处理,以及对图像数据进行预处理准备。
def collate_fn(examples: list[dict[str, any]]):
texts = []
images = []
for example in examples:
images.append([example["image"]])
texts.append(
processor.apply_chat_template(
example["messages"], add_generation_prompt=False, tokenize=False
).strip()
)
batch = processor(text=texts, images=images, return_tensors="pt", padding=True)
labels = batch["input_ids"].clone()
image_token_id = [
processor.tokenizer.convert_tokens_to_ids(
processor.tokenizer.special_tokens_map["boi_token"]
)
]
labels[labels == processor.tokenizer.pad_token_id] = -100
labels[labels == image_token_id] = -100
labels[labels == 262144] = -100
batch["labels"] = labels
return batch通过 trl 库的 SFTConfig 定义模型微调的配置参数,包括指定输出目录、训练轮次、批次大小、梯度累积步数等训练设置,以及学习率、优化器、保存和评估策略等关键参数,同时配置了混合精度训练、梯度检查点等以提升效率,为 MedGemma 模型的微调过程提供全面的参数规范。
from trl import SFTConfig
args = SFTConfig(
output_dir="medgemma-brain-cancer",
num_train_epochs=1,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
gradient_accumulation_steps=8,
gradient_checkpointing=True,
optim="adamw_torch_fused",
logging_steps=0.1,
save_strategy="epoch",
eval_strategy="steps",
eval_steps=0.1,
learning_rate=2e-4,
bf16=True,
max_grad_norm=0.3,
warmup_ratio=0.03,
lr_scheduler_type="linear",
push_to_hub=False,
report_to="none",
gradient_checkpointing_kwargs={"use_reentrant": False},
dataset_kwargs={"skip_prepare_dataset": True},
remove_unused_columns=False,
label_names=["labels"],
)通过 trl 库的 SFTTrainer 构建模型微调训练器,将之前加载的 MedGemma 模型、配置好的训练参数、格式化后的训练集与筛选后的验证集(打乱后选前 50 个样本),以及 LoRA 配置、处理器和数据整理函数整合起来,为后续启动模型微调做好完整的训练框架搭建。
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=formatted_data["train"],
eval_dataset=formatted_data["validation"].shuffle().select(range(50)),
peft_config=peft_config,
processing_class=processor,
data_collator=collate_fn,
)The model is already on multiple devices. Skipping the move to device specified in `args`.
6.模型训练
当模型、数据集与训练配置全部设置完成后,我们即可启动微调流程,只需一条命令就能触发模型训练。
trainer.train()The tokenizer has new PAD/BOS/EOS tokens that differ from the model config and generation config. The model config and generation config were aligned accordingly, being updated with the tokenizer's values. Updated tokens: {'eos_token_id': 1, 'bos_token_id': 2, 'pad_token_id': 0}.
[76/76 1:05:42, Epoch 1/1]
| Step | Training Loss | Validation Loss | Entropy | Num Tokens | Mean Token Accuracy |
|---|---|---|---|---|---|
| 8 | 4.099500 | 1.447292 | 5.578917 | 155819.000000 | 0.858661 |
| 16 | 0.827100 | 0.433281 | 4.321393 | 311636.000000 | 0.944832 |
| 24 | 0.213700 | 0.055273 | 0.138196 | 467465.000000 | 0.965619 |
| 32 | 0.053400 | 0.046049 | 0.116854 | 623284.000000 | 0.973940 |
| 40 | 0.045800 | 0.042925 | 0.129749 | 779099.000000 | 0.975818 |
| 48 | 0.039600 | 0.038910 | 0.131056 | 934927.000000 | 0.976948 |
| 56 | 0.037700 | 0.040360 | 0.123941 | 1090751.000000 | 0.975822 |
| 64 | 0.035600 | 0.035917 | 0.117540 | 1246553.000000 | 0.976578 |
| 72 | 0.033800 | 0.034258 | 0.113658 | 1402375.000000 | 0.977322 |
TrainOutput(global_step=76, training_loss=0.5687087219404546, metrics={'train_runtime': 3995.0692, 'train_samples_per_second': 1.212, 'train_steps_per_second': 0.019, 'total_flos': 3.841279229514355e+16, 'train_loss': 0.5687087219404546, 'entropy': 0.10624703541398048, 'num_tokens': 1474200.0, 'mean_token_accuracy': 0.9782642483711242, 'epoch': 1.0})
模型训练过程耗时约 1 小时完成。在此期间,训练损失与验证损失随每一步训练稳步下降,这表明模型正在有效学习任务相关知识。
7.模型评估
为评估 MedGemma 4B 模型的性能,我们将在验证集上对基础模型与微调后模型分别进行测试。该过程包含清理内存、准备测试数据、生成模型响应,以及计算准确率、F1 分数等关键指标。
在开始评估前,我们会移除训练相关配置以释放 GPU 内存,为测试环节确保一个干净的运行环境。
del model
del trainer
torch.cuda.empty_cache()我们同样对验证集进行格式化处理,使其匹配模型所需的输入结构。验证集样本格式化为仅含用户角色的对话结构(包含图像标记和提示词),得到用于模型评估的测试数据,为后续生成预测结果做准备。
def format_test_data(example: dict[str, any]) -> dict[str, any]:
example["messages"] = [
{
"role": "user",
"content": [
{
"type": "image",
},
{
"type": "text",
"text": PROMPT,
},
],
},
]
return example
test_data = data["validation"]
test_data = test_data.map(format_test_data)为评估模型性能,我们使用 evaluate 库 —— 该库为分类等任务提供了预构建的评估指标。导入库并加载所需指标后,我们从测试集中提取真实标签,随后定义一个辅助函数 compute_metrics,通过将预测结果与这些标签进行比对,来计算准确率和 F1 分数。
import evaluate
accuracy_metric = evaluate.load("accuracy")
f1_metric = evaluate.load("f1")
REFERENCES = test_data["label"]
def compute_metrics(predictions: list[int]) -> dict[str, float]:
metrics = {}
metrics.update(
accuracy_metric.compute(
predictions=predictions,
references=REFERENCES,
)
)
metrics.update(
f1_metric.compute(
predictions=predictions,
references=REFERENCES,
average="weighted",
)
)
return metrics为确保标签处理的一致性,我们将数据集的 “label” 列转换为 ClassLabel 类型。这一操作可实现标签索引与其对应名称之间的高效映射,同时我们还定义了替代标签映射,以应对后续处理过程中可能出现的标签格式差异。
from datasets import ClassLabel
test_data = test_data.cast_column(
"label",
ClassLabel(names=BRAIN_CANCER_CLASSES)
)
LABEL_FEATURE = test_data.features["label"]
ALT_LABELS = dict([
(label, f"({label.replace(': ', ') '})") for label in BRAIN_CANCER_CLASSES
])Casting the dataset: 100%|██████████| 1212/1212 [00:00<00:00, 13316.37 examples/s]
为将模型的预测结果映射到正确的类别标签,我们定义了一个后处理函数。该函数会考虑标准标签格式和替代标签格式,确保预测结果与相应标签准确匹配。
def postprocess(prediction, do_full_match: bool = False) -> int:
if isinstance(prediction, str):
response_text = prediction
else:
response_text = prediction[0]["generated_text"]
if do_full_match:
return LABEL_FEATURE.str2int(response_text)
for label in BRAIN_CANCER_CLASSES:
if label in response_text or ALT_LABELS[label] in response_text:
return LABEL_FEATURE.str2int(label)
return -1为评估基础模型的性能,我们加载预训练模型和处理器,配置生成参数,并准备好用于测试的提示文本和图像。
import torch
from transformers import AutoModelForImageTextToText, AutoProcessor
model_kwargs = dict(
torch_dtype=torch.bfloat16,
device_map="auto",
)
model = AutoModelForImageTextToText.from_pretrained(
model_id, **model_kwargs
)
from transformers import GenerationConfig
gen_cfg = GenerationConfig.from_pretrained(model_id)
gen_cfg.update(
do_sample=False,
top_k=None,
top_p=None,
cache_implementation="dynamic"
)
model.generation_config = gen_cfg
processor = AutoProcessor.from_pretrained(model_id)
tok = processor.tokenizer
model.config.pad_token_id = tok.pad_token_id
model.generation_config.pad_token_id = tok.pad_token_id
def chat_to_prompt(chat_turns):
return processor.apply_chat_template(
chat_turns,
add_generation_prompt=True,
tokenize=False
)
prompts = [chat_to_prompt(c) for c in test_data["messages"]]
images = test_data["image"]
assert len(prompts) == len(images), "1 prompt must match 1 image!"`torch_dtype` is deprecated! Use `dtype` instead!
Loading checkpoint shards: 100%|██████████| 2/2 [00:02<00:00, 1.21s/it]
我们创建了一个 batch_predict 函数,用于按批次处理测试数据集。该函数为每个提示文本 - 图像对生成预测结果,并通过后处理将输出映射到正确的标签。
import torch
from typing import List, Any, Callable
def batch_predict(
prompts,
images,
model,
processor,
postprocess,
*,
batch_size=64,
device="cuda",
dtype=torch.bfloat16,
**gen_kwargs
):
preds = []
for i in range(0, len(prompts), batch_size):
texts = prompts[i : i + batch_size]
imgs = [[img] for img in images[i : i + batch_size]]
enc = processor(text=texts, images=imgs, padding=True, return_tensors="pt").to(
device, dtype=dtype
)
lens = enc["attention_mask"].sum(dim=1)
with torch.inference_mode():
out = model.generate(
**enc,
disable_compile=True,
**gen_kwargs
)
for seq, ln in zip(out, lens):
ans = processor.decode(seq[ln:], skip_special_tokens=True)
preds.append(postprocess(ans))
return predsbf_preds = batch_predict(
model=model,
processor=processor,
prompts=prompts,
images=images,
batch_size=64,
max_new_tokens=40,
postprocess=postprocess,
)
bf_metrics = compute_metrics(bf_preds)
print(f"Baseline metrics: {bf_metrics}")Baseline metrics: {'accuracy': 0.33828382838283827, 'f1': 0.17393878722027564}
基础模型评估仅得到约 33% 的准确率,整体预测效果有待提升。
为了更深入地了解模型的表现,我们可以从数据集中选取单个样本生成预测结果。这需要创建一个辅助函数来处理输入并返回模型的响应。predict_one 函数以提示文本和图像作为输入,借助模型的处理器对其进行处理并生成响应。该函数会将模型的输出解码为人类可读懂的文本。
import torch
from typing import Union, Dict, Any, List
from transformers import AutoModelForImageTextToText, AutoProcessor
def predict_one(
prompt,
image,
model,
processor,
*,
device="cuda",
dtype=torch.bfloat16,
disable_compile=True,
**gen_kwargs
) -> str:
inputs = processor(text=prompt, images=image, return_tensors="pt").to(
device, dtype=dtype
)
plen = inputs["input_ids"].shape[-1]
with torch.inference_mode():
ids = model.generate(
**inputs,
disable_compile=disable_compile,
**gen_kwargs
)
return processor.decode(ids[0, plen:], skip_special_tokens=True)idx = 12
chat = test_data["messages"][idx]
prompt = processor.apply_chat_template(
chat,
add_generation_prompt=True,
tokenize=False
)
# 运行单样本预测
answer = predict_one(
prompt=prompt,
image=test_data["image"][idx],
model=model,
processor=processor,
max_new_tokens=40
)
print("Model answer:", answer)Model answer: 根据您提供的 MRI 图像,最可能的诊断是 **A: brain glioma**。
以下是原因:
* **图像特征:** 图像显示了一个位于大脑中部的圆形或
最终我们得到了一段冗长的文本,内容是解释为何选择 “脑胶质瘤” 这一诊断。但这个响应完全错误,甚至连类别判断本身都是错的。
为评估微调后的模型,我们重复评估流程:从输出目录加载模型,生成预测结果并计算指标。
import torch
from peft import PeftModel
from transformers import AutoModelForImageTextToText, AutoProcessor
base_model_path = "/model-202510/medgemma-4b-it"
model = AutoModelForImageTextToText.from_pretrained(
base_model_path,
torch_dtype=torch.bfloat16,
device_map="auto"
)
adapter_path = "medgemma-brain-cancer/checkpoint-76"
model = PeftModel.from_pretrained(model, adapter_path)
processor = AutoProcessor.from_pretrained(base_model_path)
tok = processor.tokenizer
model.generation_config = gen_cfg
model.config.pad_token_id = tok.pad_token_id
model.generation_config.pad_token_id = tok.pad_token_id
model.eval()af_preds = batch_predict(
model=model,
processor=processor,
prompts=prompts,
images=images,
batch_size=64,
max_new_tokens=40,
postprocess=postprocess,
)
af_metrics = compute_metrics(af_preds)
print(f"Fine-tuned metrics: {af_metrics}")Loading checkpoint shards: 100%|██████████| 2/2 [00:02<00:00, 1.00s/it]
Fine-tuned metrics: {'accuracy': 0.9282178217821783, 'f1': 0.9282706110439416}
结果表明,微调后的模型相比基础模型有显著提升,仅经过 1 轮训练,模型准确率就从 33% 跃升至 92%。同样,我们从测试数据集中选取一个样本生成预测结果。
idx = 12
chat = test_data["messages"][idx]
prompt = processor.apply_chat_template(
chat,
add_generation_prompt=True,
tokenize=False
)
answer = predict_one(
prompt=prompt,
image=test_data["image"][idx],
model=model,
processor=processor,
max_new_tokens=40
)
print("Model answer:", answer)Model answer: C: brain tumor
模型给出的结果清晰准确,类别判断正确,且表述结构规整。
总结
MedGemma 标志着人工智能在医学领域的重大进步。它能助力医生和医师做出更快速、更准确的判断,从而为患者提供更及时的诊断和更有效的治疗方案。
对 MedGemma 4B 进行微调,可使其适配多种医疗任务 —— 无论是图像分类,还是融入推理能力的复杂场景都能覆盖。
在本教程中,我们学习了如何在脑部 MRI 数据集上微调视觉 - 语言模型,以完成脑肿瘤分类任务。最终结果十分显著:模型准确率从 33% 大幅提升至 92% ,这一巨大飞跃充分彰显了微调技术在医疗人工智能应用中的潜力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)