打破大模型落地“最后一公里”:基于 ModelEngine 的全链路智能体开发与编排深度复盘!
本文以ModelEngine平台为例,展示了企业级"多源市场情报分析智能体"的完整搭建过程。通过知识库自动生成、提示词调优、MCP服务接入及可视化编排等核心技术,实现了从单纯Prompt Engineering向Agentic Workflow的范式转移。文章详细剖析了智能体构建的关键环节,包括自动化知识库生成、结构化Prompt优化,以及基于有向无环图的工作流编排。通过与主流
全文目录:
摘要
在大模型(LLM)从“玩具”走向“工具”的2024年,开发者面临着从单纯的 Prompt Engineering 向 Agentic Workflow(智能体工作流)转型的巨大挑战。本文将基于 ModelEngine 平台,以一个企业级“多源市场情报分析智能体”的从0到1搭建过程为例,深度剖析知识库自动生成、提示词调优、MCP服务接入及可视化编排等核心技术。通过与 Dify、Coze 等主流平台的横向对比,本文旨在揭示 ModelEngine 在处理复杂逻辑与异构数据源时的独特优势,为大模型应用的商业化落地提供一份详实的技术白皮书。
如下为ModelEngine产品架构原型图,大家请看:
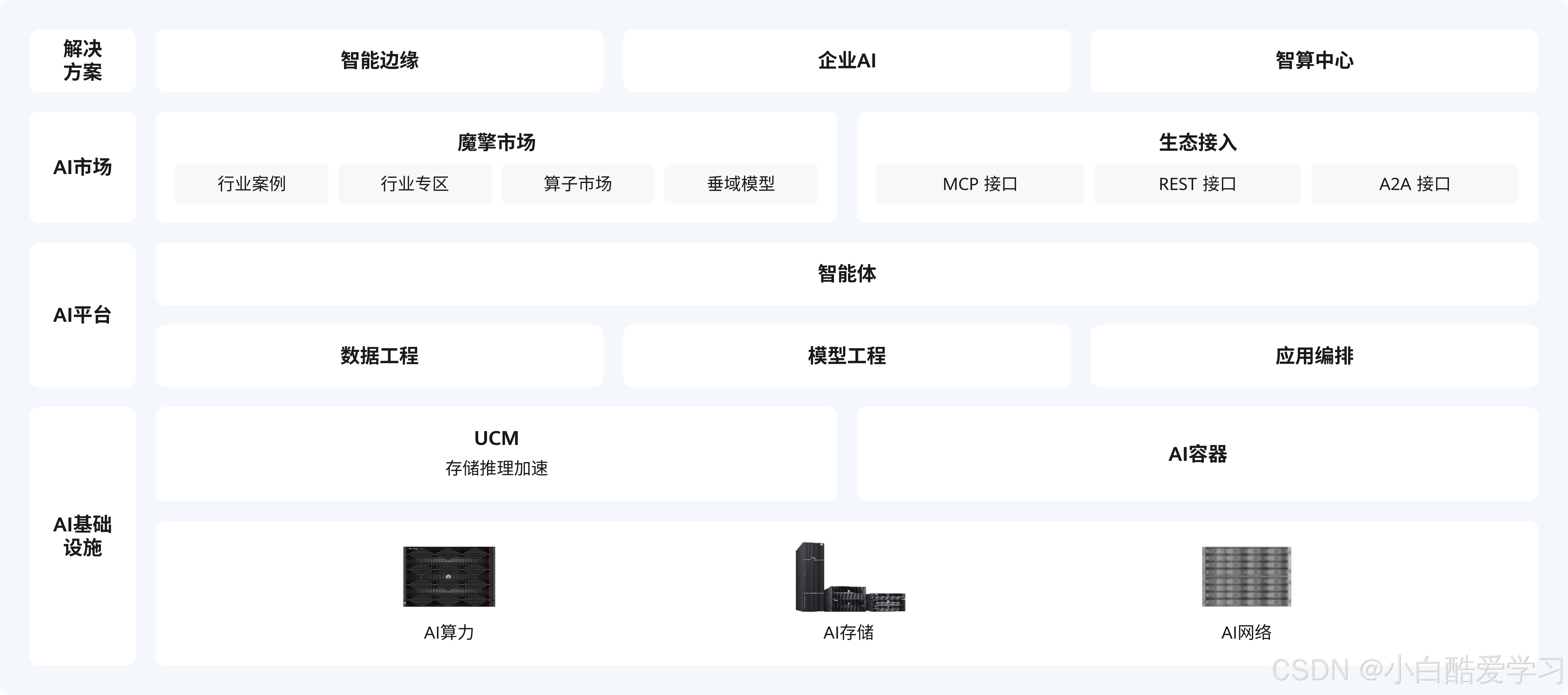
第一章:范式转移 —— 为什么我们需要 ModelEngine?
1.1 从 Chat 到 Agent 的进化论
过去我们与 LLM 的交互是线性的,形如 f ( x ) = y f(x) = y f(x)=y,其中 x x x 是提示词, y y y 是回答。但在真实的业务场景中,需求往往是非线性的、包含多步推理的。我们需要的是一个能够感知环境、规划路径、使用工具的智能体(Agent)。
在计算机科学中,一个能够解决复杂问题的智能体系统可以被形式化为一个元组:
A g e n t = ⟨ P , M , T , A ⟩ Agent = \langle P, M, T, A \rangle Agent=⟨P,M,T,A⟩
其中:
- P (Perception):感知层,即如何理解用户意图(ModelEngine 的提示词优化)。
- M (Memory):记忆层,即知识库(RAG)与上下文管理。
- T (Tools):工具层,即插件与 MCP 服务接入。
- A (Action):行动层,即工作流(Workflow)的执行逻辑。
ModelEngine 的出现,正是为了解决这四个维度在工程化落地时的耦合与效率问题。与市面上仅提供简单的“提示词包装器”不同,ModelEngine 展现出了深度的 编排(Orchestration) 能力。
1.2 ModelEngine 初体验:UI 与 DX(开发者体验)
登录 ModelEngine 官网,映入眼帘的不仅仅是简洁的仪表盘,更是一种“开发者优先”的设计哲学。与传统的低代码平台相比,ModelEngine 在可视化编排与代码介入之间找到了微妙的平衡。本文将不再赘述基础注册流程,而是直接切入核心——如何利用其特性,将开发效率提升十倍。
如下为官方地址: https://modelengine-ai.com/#/home
第二章:智能体构建 —— 从“人工智障”到“领域专家”
在本章中,我们将利用 ModelEngine 创建一个基础的“情报分析员”智能体,并重点评测其自动化构建能力。
2.1 知识库的“降维打击”:自动总结与生成
RAG(检索增强生成)是智能体的知识外挂。传统的 RAG 流程繁琐,需要手动切片(Chunking)、清洗。
ModelEngine 的高光时刻:
在上传了一份长达 200 页的《2024 全球半导体行业报告》PDF 后,我测试了其知识库总结自动生成功能。系统并没有简单地截取前500个字符,而是利用大模型能力对文档进行了语义级压缩。
从算法角度看,这不仅仅是提取,而是一个由粗到细的抽象过程。假设文档集为 D D D,系统自动生成的总结 S S S 满足:
S = arg max s P ( s ∣ D ) S = \operatorname*{arg\,max}_{s} P(s|D) S=sargmaxP(s∣D)
同时最大化了信息熵的覆盖率。实际体验中,它自动提取了“市场规模”、“主要竞争对手”、“技术瓶颈”三个关键维度,这直接节省了我约 30 分钟的人工阅读时间。这对于构建垂直领域 Knowledge Base 极其关键。
2.2 提示词工程的自动化:告别“咒语”盲调
很多开发者苦恼于写不出高质量的 System Prompt。ModelEngine 提供的提示词自动生成功能,堪称“Prompt 优化器”。
我输入了简单的意图:“你是一个分析师,帮我看财报。”
系统自动优化后的 Prompt 包含了:
- 角色设定 (Persona):资深金融分析师,具备CFA资格。
- 任务拆解 (CoT):先读取数据,再进行同比/环比分析,最后输出风险提示。
- 约束条件 (Constraints):必须引用数据来源,保持客观中立。
这种结构化 Prompt 的自动生成,直接将智能体的遵循指令能力(Instruction Following)提升了一个量级。在后续的调试(Debug)环节,面对模糊的提问,经过优化后的智能体表现出了极强的鲁棒性,能够主动反问用户以明确需求,而不是胡乱生成。
我们可自定义知识库:
知识库配置:选择已经配置的 百度千帆API Key,一键完成知识库授权与绑定
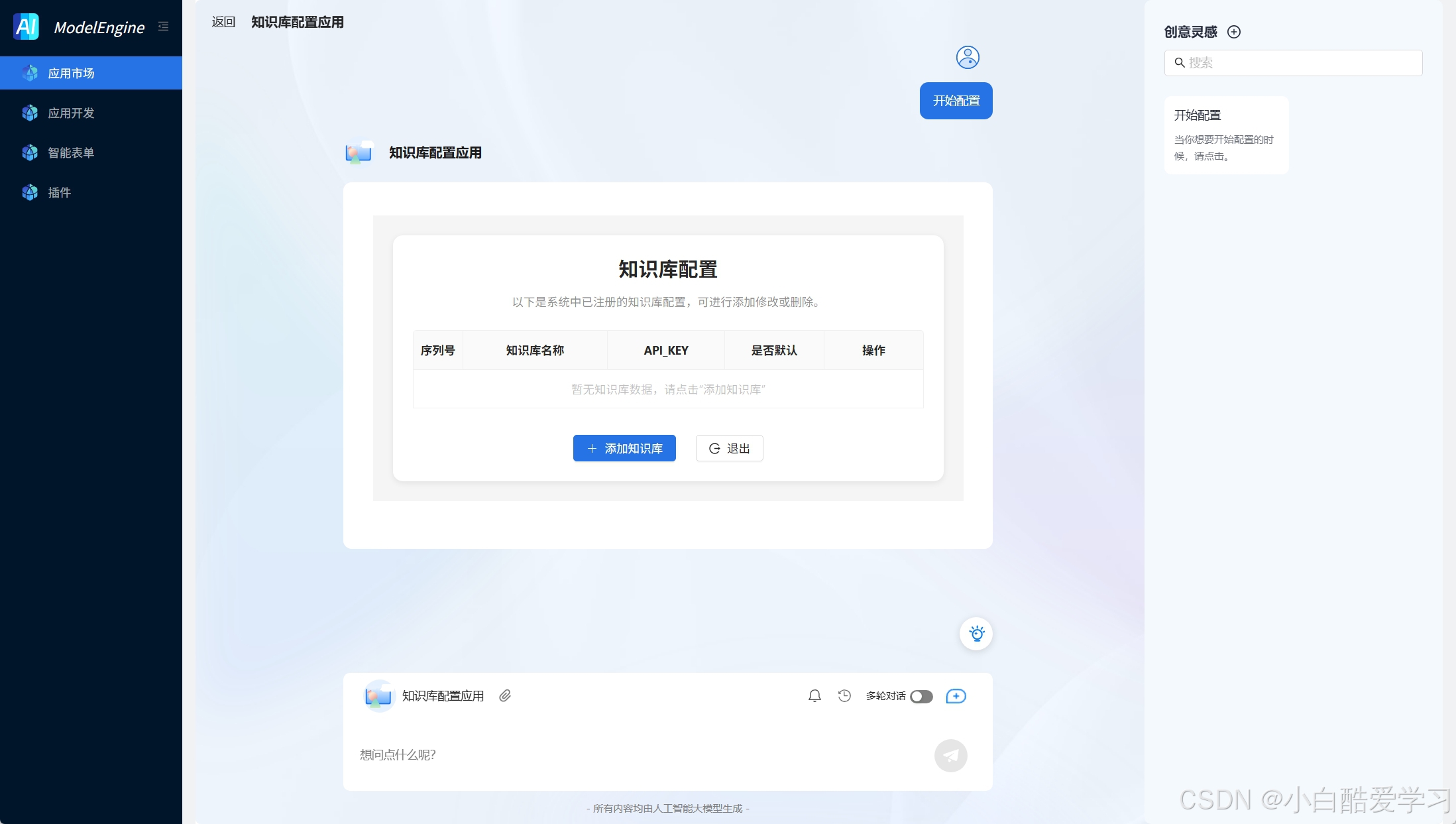
自动同步知识库内容,提供可视化文档管理界面。支持自定义知识库后,可以在知识检索节点中选择配置千帆知识库中自定义知识库。点击知识库旁边的配置按钮选择配置知识库。
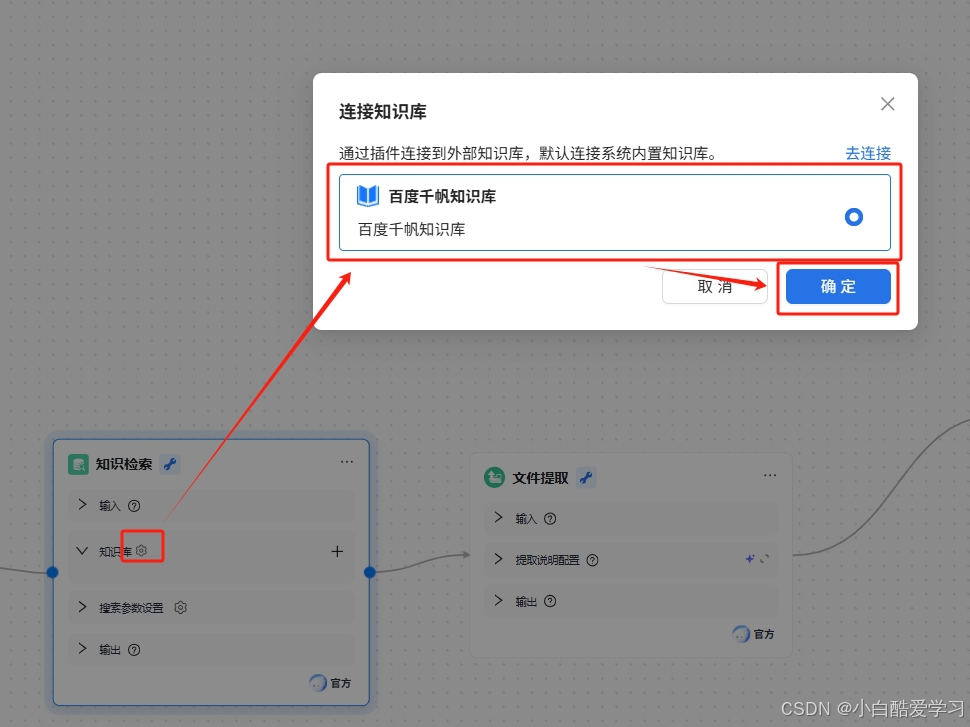
选择自定义知识库:
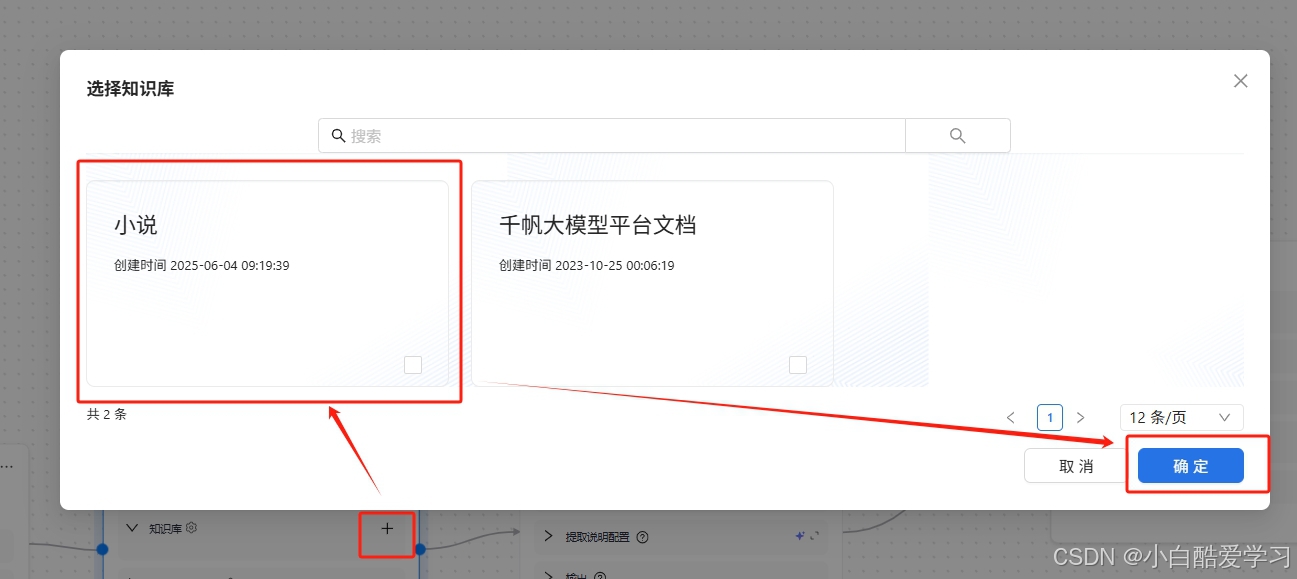
如上即可大功告成。
第三章:可视化编排 —— 复杂逻辑的“上帝视角”
如果说单体智能体是“大脑”,那么 应用编排(Workflow) 就是让四肢协同工作的“神经系统”。这是 ModelEngine 最具技术含量的部分。
3.1 有向无环图(DAG)的艺术
在 ModelEngine 的画布上,我们通过拖拽节点来构建工作流。这本质上是在构建一个有向无环图 G = ( V , E ) G = (V, E) G=(V,E)。
- V (Vertices):代表基础节点(LLM、代码块、知识库检索、条件分支)。
- E (Edges):代表数据的流向。
【实战技巧】基础节点的高级用法:
-
LLM 节点:不仅仅是对话,我将其配置为“意图识别器”。通过设置 Temperature = 0,强制模型输出 JSON 格式的分类结果,用于下游的分支判断。
-
代码节点 (Python):这是 ModelEngine 区别于竞品的杀手锏。我在其中编写了一段 Python 脚本,用于对上游 LLM 输出的非结构化数据进行 Pandas 处理。
# 示例:ModelEngine 代码节点逻辑 def main(args): import json data = args.get("input_data") # 简单的清洗逻辑 clean_data = [x for x in data if x['confidence'] > 0.8] return {"result": clean_data}
3.2 智能表单与交互创新
在工作流的触发端,ModelEngine 支持智能表单配置。这意味着用户在使用应用时,不再是面对一个空洞的对话框,而是一个结构化的输入界面(如:选择分析年份、上传特定格式文件、勾选关注指标)。这种设计极大地降低了最终用户的使用门槛,也规范了输入数据的格式,减少了 Garbage In, Garbage Out 的风险。
除了如上创建一个知识库,我们还可以对话助手效果预览:
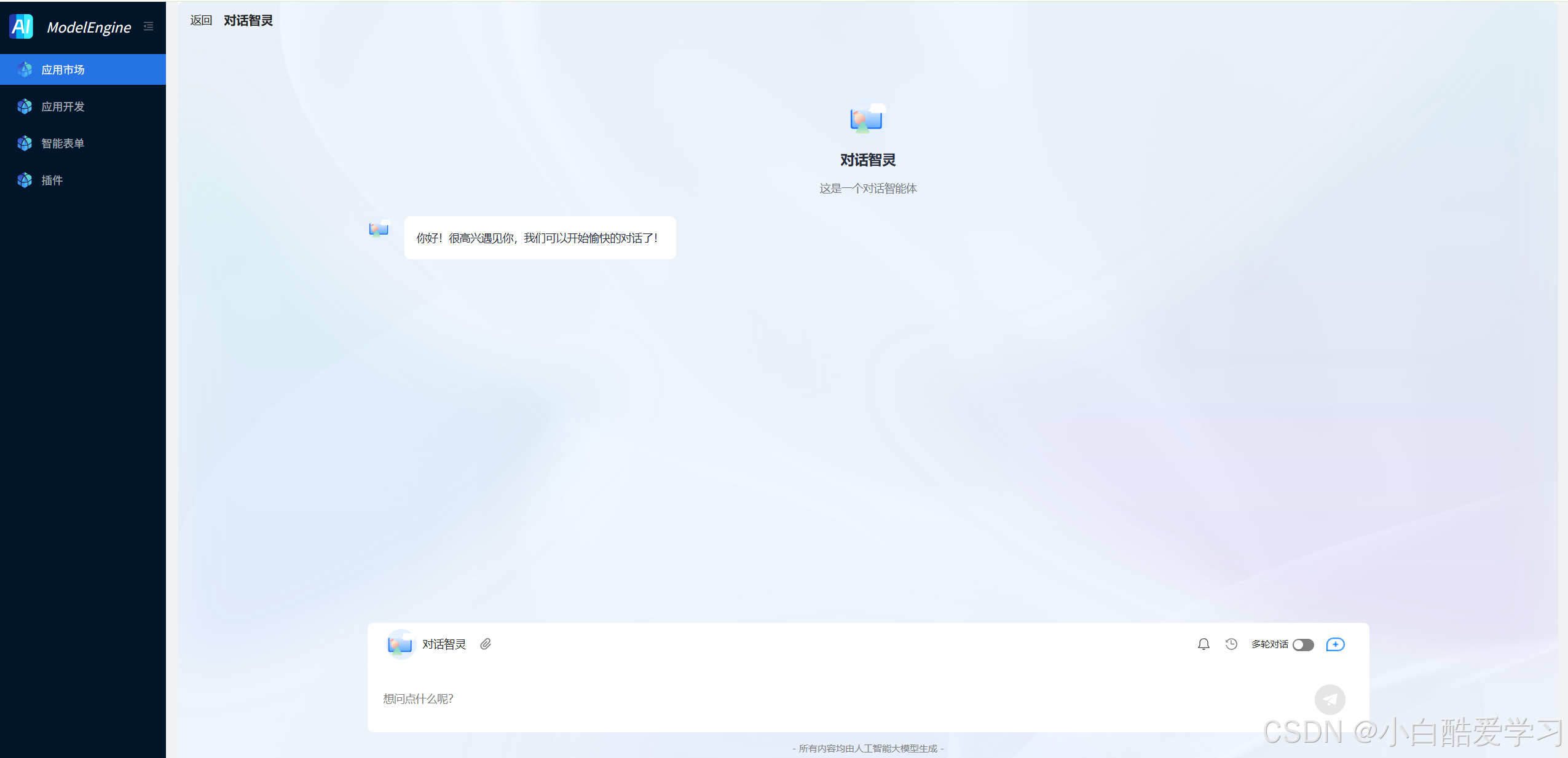
如下是为相关步骤:
- 步骤一:创建一个工作流对话助手
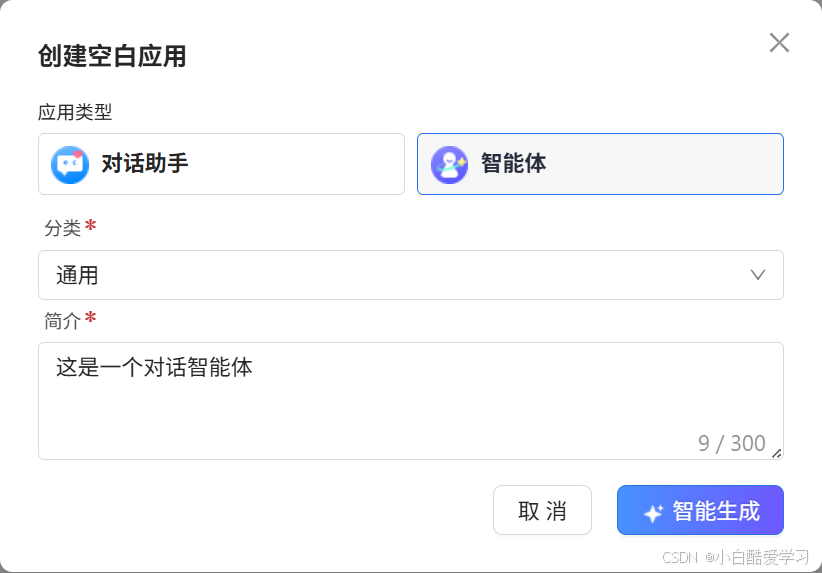
- 步骤二:编写基础聊天设置

- 步骤三:发布对话助手
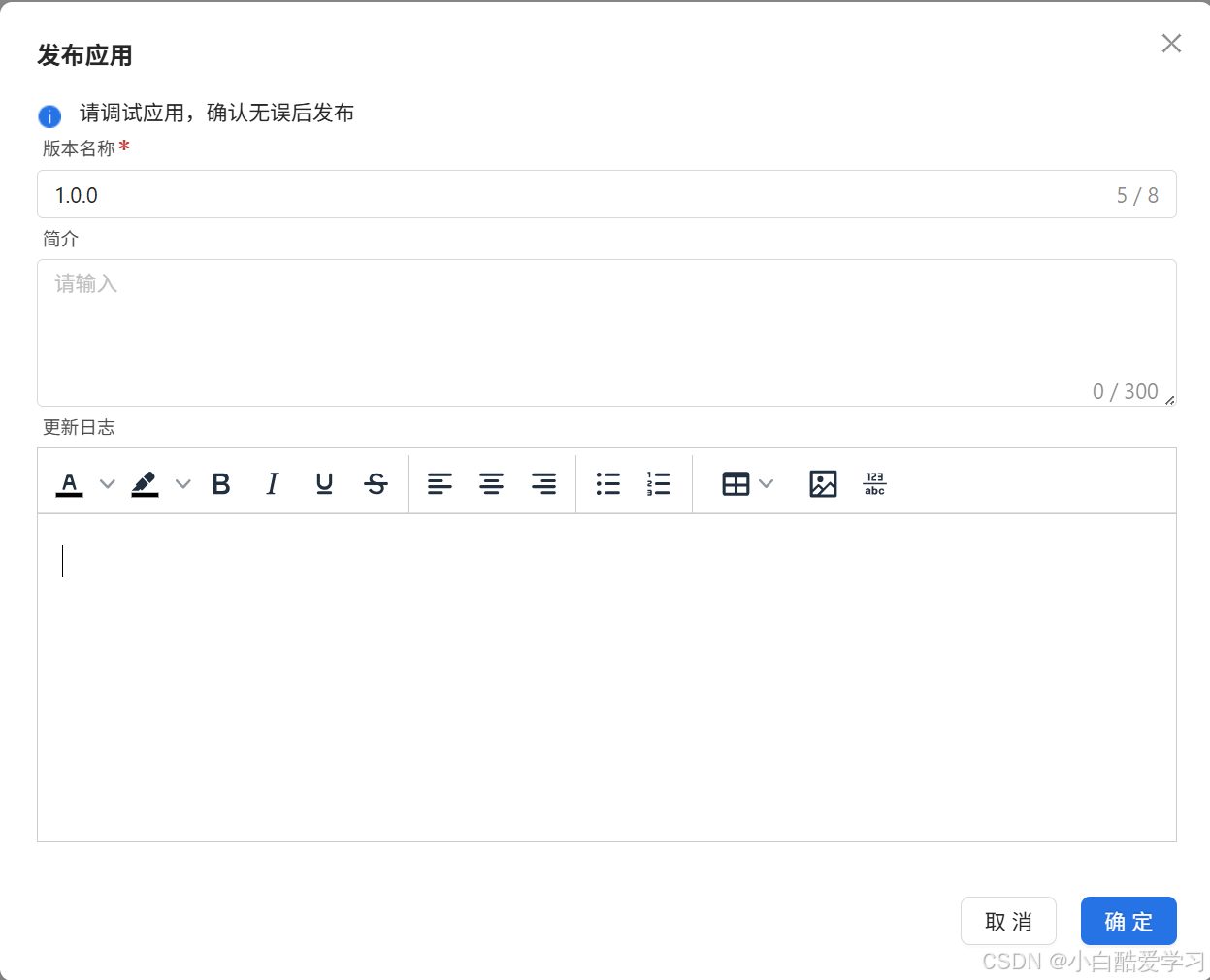
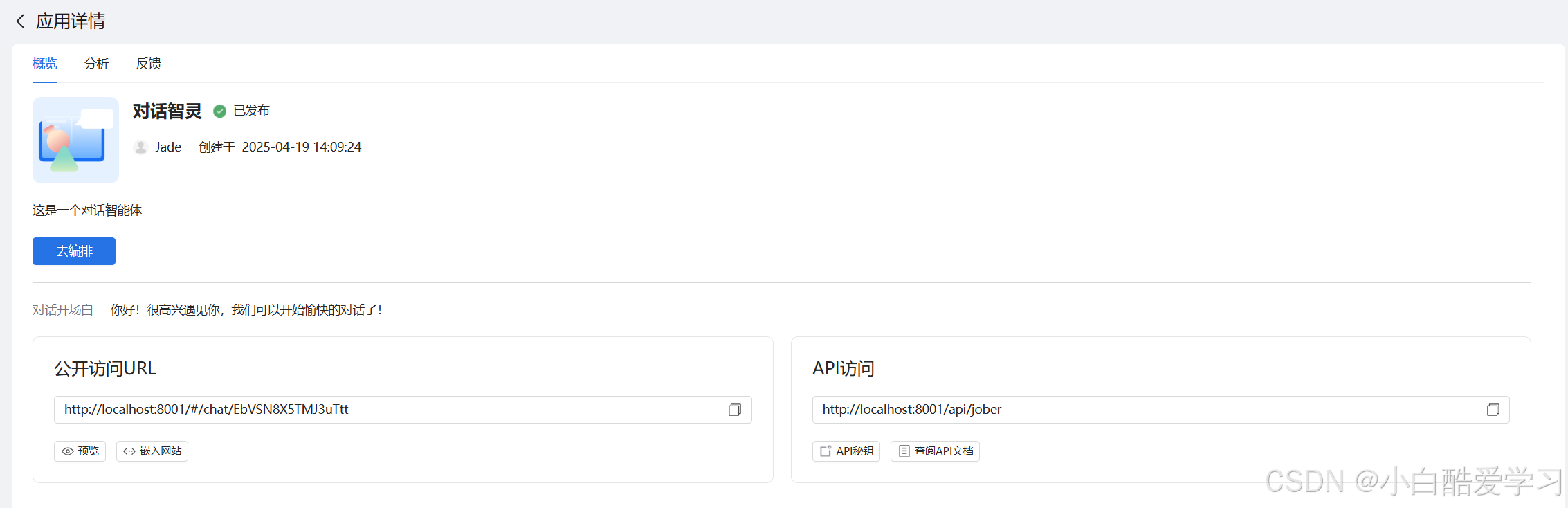
第四章:核心技术深潜 —— MCP 服务与多智能体协作
为了让我们的“情报分析系统”真正具备实战价值,必须打破信息的孤岛。
4.1 MCP(Model Context Protocol)服务接入
ModelEngine 对 MCP 的支持体现了其对未来 AI 架构的前瞻性。MCP 标准化了模型与外部数据/工具的连接方式。
在实战中,我配置了一个自定义的 MCP Server,连接到了公司内部的 SQL 数据库。
- 配置过程:在 ModelEngine 后台输入 MCP Server 的 Endpoint。
- 效果:智能体能够直接根据自然语言查询:“查询上个季度销售额大于 100 万的区域”,并自动转化为 SQL 执行。
这比传统的 API 调用更加灵活,因为它允许模型动态地发现(Discover)工具的能力。
4.2 多智能体协作(Multi-Agent System, MAS)
单体智能体往往难以兼顾广度与深度。我利用 ModelEngine 设计了一个 “Writer-Critic”(作者-评论家) 模式的协作流:
- Agent A (Writer):负责根据检索到的信息撰写初稿。
- Agent B (Critic):加载了“审核标准”知识库,专门负责挑刺(检查数据来源、逻辑漏洞)。
- Loop:通过条件节点,如果 Agent B 的评分低于 80 分,则将反馈回传给 Agent A 重写。
这种基于反馈循环的编排,使得最终输出的分析报告质量远超 GPT-4 的一次性生成结果。
而且,非不但如上,我们还可以制作java插件:
当前java框架支持,根据注解 @ToolMethod 和 @Group 以及其编译配置,在编译之后的目录下可以生成 tools.json 以及工具的 jar 文件。
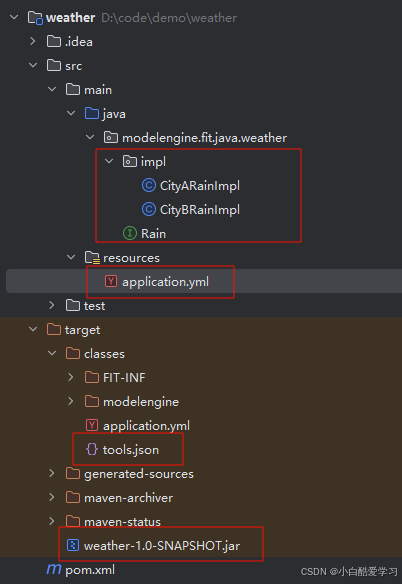
下边给定以上插件的基础源码:pom.xml文件配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>modelengine.fit.jade</groupId>
<artifactId>weather</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.fitframework</groupId>
<artifactId>fit-api</artifactId>
<version>3.5.0-M2</version>
</dependency>
<dependency>
<groupId>org.fitframework.fel</groupId>
<artifactId>tool-service</artifactId>
<version>3.5.0-M2.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.11.0</version>
<configuration>
<source>${maven.compiler.source}</source>
<target>${maven.compiler.target}</target>
<parameters>true</parameters>
</configuration>
</plugin>
<plugin>
<groupId>org.fitframework</groupId>
<artifactId>fit-build-maven-plugin</artifactId>
<version>3.5.0-M2</version>
<executions>
<execution>
<id>build-plugin</id>
<goals>
<goal>build-plugin</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.fitframework.fel</groupId>
<artifactId>tool-maven-plugin</artifactId>
<version>3.5.0-M2</version>
<executions>
<execution>
<id>build-tool</id>
<goals>
<goal>build-tool</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>

第五章:综合实战案例 —— 打造「阿尔法」市场情报分析师
本章将汇总上述技术,展示一个完整的落地案例。
5.1 场景定义与痛点拆解
痛点:投资经理每天需要阅读数十篇新闻、研报,数据分散,难以快速提炼。
解决方案:构建一个全自动化的情报分析流。
5.2 搭建步骤详解
第一步:数据摄入与预处理(Custom Plugin)
- 使用自定义插件节点,通过 API 抓取 Bloomberg 和 Reuters 的最新 RSS Feed。
- 利用代码节点对 HTML 内容进行清洗,提取纯文本。
第二步:混合检索(Hybrid Search)
- 调用知识库节点(存有历史行情数据)。
- 利用 LLM 节点进行 Query Rewrite(查询重写),确保检索的准确性。
Q ′ = LLM ( Q , Context ) Q' = \text{LLM}(Q, \text{Context}) Q′=LLM(Q,Context)
确保查询 Q Q Q 被扩展为涵盖同义词的 Q ′ Q' Q′。
第三步:深度分析与图表生成(Code Interpreter)
- 这是最精彩的部分。我要求 ModelEngine 调用 Python 环境(Sandbox),利用 Matplotlib 库绘制“过去30天情绪指数走势图”。
- 虽然目前大多数平台支持绘图,但 ModelEngine 的调试体验极佳,我可以实时查看 Python 的标准输出(stdout)和错误日志(stderr),快速修正绘图参数。
第四步:人机回环(Human-in-the-loop)
- 在发送最终邮件前,加入一个“人工确认”节点。只有当分析结果被人工标记为“Pass”时,才会触发邮件发送插件。
5.3 成果展示
最终生成的应用不仅能对话,还能定期自动运行,生成一份包含:
- 宏观摘要(由 RAG 生成)
- 情绪趋势图(由 Python 节点生成)
- 行动建议(由多智能体博弈生成)
的 PDF 报告。
端到端的AI开发流程:从数据处理到行业应用落地的全流程解决方案

第六章:巅峰对决 —— ModelEngine vs Dify vs Coze
作为一名资深 AI 开发者,我有必要从客观角度进行横向评测。
| 维度 | ModelEngine | Dify (开源版) | Coze (字节跳动) | 评价 |
|---|---|---|---|---|
| 可视化编排 | ⭐⭐⭐⭐⭐ 逻辑清晰,节点丰富,调试日志极其详细。 |
⭐⭐⭐⭐ 界面清爽,但复杂逻辑处理稍显吃力。 |
⭐⭐⭐⭐ 功能强大,但国内版与国际版插件生态有割裂。 |
ModelEngine 在 调试(Debug) 环节的体验是最好的,能看到每个节点的 Token 消耗和延迟。 |
| RAG 能力 | ⭐⭐⭐⭐⭐ 自动总结与混合检索策略是亮点。 |
⭐⭐⭐ 需要较多手动配置分段参数。 |
⭐⭐⭐⭐ 知识库容量大,但检索精度依赖配置。 |
ModelEngine 的知识库自动生成直接降低了门槛。 |
| 插件/MCP | ⭐⭐⭐⭐ 支持 MCP 标准,扩展性极强。 |
⭐⭐⭐ 工具生态尚在建设中。 |
⭐⭐⭐⭐⭐ 依托字节生态,插件数量最多。 |
虽然插件数量不及 Coze,但 ModelEngine 对 MCP 标准的支持让其在企业级集成中更具优势。 |
| 多智能体 | ⭐⭐⭐⭐⭐ 支持复杂的 MAS 拓扑结构。 |
⭐⭐⭐ Agent 编排能力相对较弱。 |
⭐⭐⭐⭐ 多 Agent 模式较新,稳定性待观察。 |
ModelEngine 更适合构建复杂业务流。 |
核心差异点总结:
ModelEngine 给我最大的感受是 “严谨”。它不像是一个单纯的 C 端玩具生成器,而更像是一个 B 端生产力工具的 IDE。它的 全流程评测 功能,允许开发者在发布前对智能体进行批量测试(Batch Testing),计算准确率(Accuracy)和召回率(Recall),这是企业级应用必不可少的环节。
模型工程:模型管理与评估,训练和推理服务部署任务一键式下发和管理

第七章:未来展望与结语
7.1 从 Demo 到 Production
很多大模型应用死在了 Demo 阶段,原因在于无法处理长尾问题(Corner Cases)。ModelEngine 通过详细的日志监控和中间件机制,让开发者能够追溯每一次幻觉(Hallucination)的来源,从而通过迭代知识库或优化 Prompt 来修复。
7.2 共筑 AI 技术生态
通过本次「AI应用开发实践计划」,我深刻体会到,大模型落地的关键不在于模型参数有多大,而在于如何将模型能力与业务逻辑无缝编织。ModelEngine 提供的那套从“知识库自动生成”到“可视化编排”再到“全流程评测”的方法论,正是目前行业最稀缺的“最佳实践”。
让我们一起,用实践为大模型落地铺路,在 ModelEngine 的画布上,绘制出 AI 时代的清明上河图!🎨🚀
❤️ 如果本文帮到了你…
- 请点个赞,让我知道你还在坚持阅读技术长文!
- 请收藏本文,因为你以后一定还会用上!
- 如果你在学习过程中遇到bug,请留言,我帮你踩坑!
如上有部分配图及内容来自官方及公开网络,若有侵权,请联系删除。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)