【学习笔记】LLM Interview(Post Training 相关)
Boosting
文章目录
0 Post-Training 相关资料
探索垂类模型(如 qwen2.5-7b)在post-training时,哪种方案更合理?
近年来,LLM 在通用自然语言理解与生成任务上展现出强大的能力。然而,通用 LLM 往往基于大规模、多领域语料训练,缺乏对特定垂直领域知识与任务特性的适配。这导致模型在行业应用种常出现知识失配,表达偏差,任务对齐不足等问题,制约其在实际业务中的落地效果。
为提升 LLM 在垂类场景下的性能与可控性,后训练(Post-Training)已成为学界与业界的重要研究方向。
后训练通常会有监督微调(SFT)、直接偏好优化(如 DPO KTO)、强化学习式偏好优化(如 GRPO)等手段,使得模型在特定任务或价值观下实现性能提升与行为约束。
0.1 开源项目与实践指南
-
大模型 Post-Training:作为入门,很不错的文章,就是嵌套有点多
-
领域大模型-训练 Trick & 落地思考(刘聪NLP)
-
Post-Training 101: A hitchhiker’s guide into LLM po
-
HuggingFace Alignment Handbook
- GitHub:https://github.com/huggingface/alignment-handbook
- 技术报告:https://arxiv.org/abs/2310.16944
- 核心价值:
- 提供完整的后训练流程:持续预训练、SFT、奖励建模、DPO/GRPO
- 包含多个 SOTA 模型复现配方(Zephyr、SmolLM、StarChat 等)
- 支持分布式训练(DeepSpeed ZeRO-3)和 PEFT
0.2 后训练快速入门框架
- LLaMA-Factory: https://github.com/hiyouga/LLaMA-Factory
- EasyR1: https://github.com/hiyouga/EasyR1
0.3 相关论文
-
A Survey of Post-Training Scaling in Large Language Models (ACL 2025)
- http://arxiv.org/abs/2504.02181
- 最全面的后训练综述,系统性地将后训练方法分为三大类:
- SFT:指令生成、响应生成、数据合成
- RL:合成奖励建模、环境反馈、自我反馈
- TTC(测试时计算):采样、验证推理链、搜索、长上下文学习
-
A Comprehensive Survey of LLM Alignment Techniques (2024)
- https://arxiv.org/abs/2407.16216
- 核心价值:专注于对齐技术(RLHF、RLAIF、PPO、DPO),详细分类各类对齐方法
- 适用场景:重点关注模型对齐和人类偏好学习
0.4 业界技术报告
- 2024年大模型后训练总结:https://zhuanlan.zhihu.com/p/987052830
- 核心价值:
- 系统总结 9 个主流开源模型地后训练方案:Llama3, Qwen2, Nemotron, AFM, Yi, GLM-4, Gemma2, DeepSeek-V2, Baichuan2
- 关键趋势识别:
- 数据合成成为主流方案
- 拒绝采样 + LLM-as-Judge 广泛应用
- 重点能力需单独优化(代码、数学、推理、长上下文)
- 模型合并技术提升性能均衡性
- 强化学习技术对比:迭代式DPO,在线DPO,GRPO,PPO等
0.5 部分主流模型技术报告
-
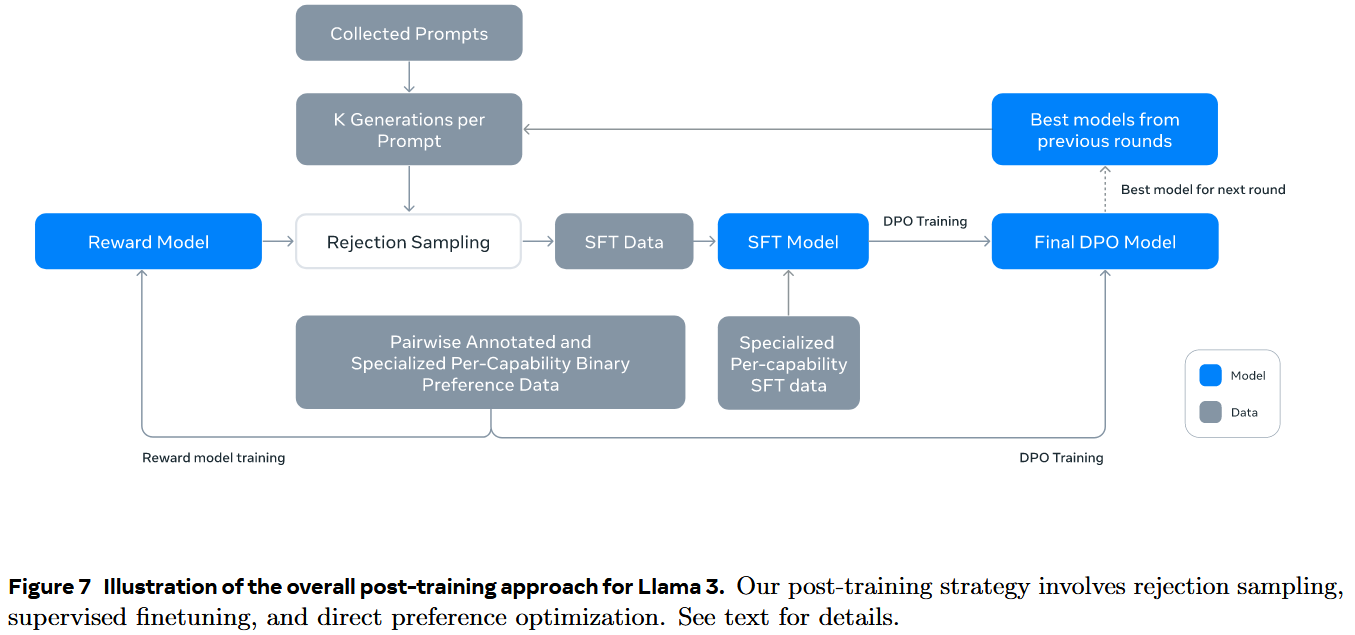
Llama3: https://arxiv.org/abs/240721783
- 迭代式 SFT + PPO(6轮)
- Figure 7
-
DeepSeek-V3: https://arxiv.org/abs/2412.19437
- 先SFT(得到DS-V3-BASE),再GRPO(数据未知)得到Zero,具体见之前的博客
-
Qwen2.5: https://arxiv.org/abs/2412.15115
- SFT → \rightarrow → DPO → \rightarrow → GRPO
1 LLM post-training 有哪些分类?
1.1 分类概述
在 A Survey of Post-Training Scaling in Large Language Models (ACL 2025) 中将后训练系统分为三大类:
- 监督微调(SFT):根据参数更新范围
- 全参微调(FFT):所有模型参数更新、现存消耗大、适合训练 base->instruct、或高质量闭源模型的内部训练
- 参数高效微调(PEFT):只训练很少一部分参数、严格按照 pretrain 权重大部分冻结、包括 adapter、prefix-tuning 以及 LoRA 等
- Adapter 类:Adapter tuning
- Prefix Tuning 类:Prefix Tuning, Prompt Tuning, P-Tuning, P-Tuning V2
- LoRA:LoRA, AdaLoRA, QLoRA
- 强化学习/对齐(RL / alignment)
- 直接偏好优化:不需要价值函数、不需要 rollout/env, 通常不依赖 ref_model, 训练稳定成本低易于扩展;优化目标直接从偏好数据推导(pairwise 或 pointwise)
- DPO:通过对比 preferred v.s. rejected 的 log-ratio 直接拟合偏好
- KTO:在 DP 框架上加入损失加权,让模型更关注严重错误(损失不对称)
- SimPO:取消ref_model 和 log-ratio,训练更稳健,适合大规模自对齐
- 强化学习式偏好优化:需要奖励/优势函数、有value baseline(但通常用 group-based 代替),训练更强但更昂贵,可进行 seq-level 优化,更适合复杂任务(推理、工具的调用)
- GRPO:DeepSeek,用group-based baseline代替value model,训练更稳定,适合长序列,多步骤推理
- DAPO:Decoupled Clip(解耦的裁剪策略),Dynamic-Sampling(动态采样)
- GSPO:引入 seq-level 重要性采样,更适合长序列任务与 reasoning
- 直接偏好优化:不需要价值函数、不需要 rollout/env, 通常不依赖 ref_model, 训练稳定成本低易于扩展;优化目标直接从偏好数据推导(pairwise 或 pointwise)
- 测试时计算/推理增强(TTC, test-time compute):训练不变、仅通过推理时间,花更多算力让模型更聪明
- Sampling-based TTC(采样类):通过增加生成样本数量来提升输出质量
- 多样采样(Multi-Sampling)
- 例如Top-k, Top-p, temperature, beam-Search
- 核心思想:多生产几个答案,再挑选最好的
- 常用于:创意生成,开放式问答
- Search-based TTC(搜索类):推理过程中使用搜索算法寻找更优解,让模型生成多个步骤路径,选择更优路径的解
- Simple Search(简单树搜索):BFS/DFS 思想、小规模搜索路径
- Monte-Carlo Tree Search(MCTS):用于数字推理、代码推理等任务;DeepMind AlphaCode 也用类似技术
- Beam Search:同时保留多个候选序列进行扩展
- Reasoning-based TTC(推理链类):利用思维链提升模型的可解释性推理能力,让模型多想一步,多写几个链条,再选更靠谱的
- CoT:思维链
- Self-Consistency:生成多条CoT,投票选择最佳答案
- ToT:树思维链
- GoT:图思维链
- Self-Verfication(自校验类):推理完让模型reflect
- Proof Verification:模型自己检查答案逻辑
- Self-Critique:先反思再修改
- Answer-Reranking:生成多个答案、然后自评打分、选择最优解
- Context-based TTC(上下文增强类):通过扩展输出上下文,提高推理质量,输入更丰富,推理更准确
- 长上下文推理:使用更长的上下文 100K-1M
- RAG:检索增强生成
- ICL:零射、少射
该分类包含传统的指令微调与监督学习,也涵盖了近年兴起的基于偏好/奖励的对齐训练以及在推理/部署阶段通过计算策略提升能力的做法(验证性推理链、检索增强、长上下文学习等)。
- Sampling-based TTC(采样类):通过增加生成样本数量来提升输出质量
1.2 总结
| 类别 | 优势 | 局限性 | 可扩展性 |
|---|---|---|---|
| SFT | 实现简单、数据可控 | 依赖数据质量、泛化能力有限 | 中等(受数据获取限制) |
| RLxF | 能对齐复杂偏好、自适应优化 | 训练不稳定、可能奖励欺骗 | 高(尤其自我反馈) |
| TTC | 无需重复训练、灵活高效 | 推理成本高、受模型上限约束 | 高(可动态调节) |
2 监督微调(SFT):指令与数据合成为核心的路线
工作机制:
- 以有监督学习将预训练模型调整为可遵从指令/完成特定任务的模型,常见做法包括使用人工标注指令——响应对(instruction-response datasets)或合成数据集进行微调。
- 参数高效方案(PEFT: LoRA/QLoRA等)常与全参微调结合,用于在资源受限下快速部署指令化模型。根据之前实验,PEFT中LoRA方式使用较多。
- 更多内容参考之前的微调专题
优缺点:
- 优点:工程成熟、数据驱动、易并行化、能针对单一垂类任务快速提升效果。
- 缺点:对高质量标注/合成数据依赖强;纯 SFT 在复杂偏好/价值观约束场景下可能不够稳健。
2.1 数据讨论?质量、数量、多样性
- 质量>数量:精选的小规模高质量数据集(1K-10K)可超越大规模低质量数据
- 边际收益递减:数据量超越临界点后,性能提升停滞甚至下降
- 多样性权衡:需在质量和多样性间寻找平衡,纯质量或纯多样性都不是最优
论文:
- What makes good data for alignment? (DEITA) (ICLR 2024), arxiv.2312.15685
- 只需要 6K 高质量自动筛选样本即可达到甚至超越 300K 样本训练的效果,数据减少 100 倍,性能不降反增
- 见原论文 Figure 2
- LIMA: Less is More for Alignment (from: META AI) arxiv.2305.11206
- 关注数据质量的同时,也要关注数据的多样性
- 对齐的扩展定律并不一定只受数据的影响,从而更取决于在高质量回答的前提下存在多样性。
- 见原论文 Figure 5
- 数据说明:WIKI HOW 有高质量的回复,但所有提示都是“如何”的问题
- Unfiltered Stack Exchange:未经过筛选,包含多样化的提示和高质量的回答
2.2 模型选择?Base模型 v.s. Instruct模型 v.s. Chat模型选择
三者关系示意图:
-
Base模型(文本续写)–(指令微调)–> Instruct模型(遵循指令)–(对话优化)–> Chat模型(多轮对话)
-
Base泛化性能好,Instrcut执行能力强且精确,Chat交互自然且安全性高
-
Base不懂指令,输出混乱,Instruct不善于对话,Chat精确执行能力若
实际例子对比:
- 输入:写一首关于春天的诗
- Base模型(仅预训练):的方法有很多种…
- Instruct模型(Base+SFT):直接开始写诗…
- Chat模型(Instruct基础上,SFT+偏好对齐,如DPO/GRPO):您想要写什么诗?
选择建议:
- 研究和定制化微调:Base模型
- 明确的任务完成:Instruct模型
- 交互式应用和住手:Chat模型
2.3 总结
LLM 的监督微调是一个技术选择与资源约束的权衡过程:
- 全参微调:资源充足、追求极致效果
- PEFT方法:主流,Lora和Qlora性价比最高
- 数据质量 > 数据数量
- 模型选择:Base 研发,Instruct 做任务,Chat 做产品
2.4 快问快答
2.4.1 Q1:LoRA为什么推力时没有延迟
因为模型merge了,没有额外的矩阵运输
2.4.2 Q2:为什么PEFT不容易遗忘
因为 PEFT 冻结了大部分参数,而只微调了小部分参数,即使这些参数过拟合,原模型的通用能力也不受影响
2.4.3 PEFT何时不如全参微调
- 任务与预训练差距过大:预训练完全没学过
- 数据量非常充足(>50K):PEFT的参数量会形成瓶颈
2.4.4 如何评估微调效果?
见之前微调专题,三个维度:
- 任务指标:F1 BLEU
- 通用能力保留:如基于benchmark,MMLU这种,确保没有严重遗忘
- 实际业务效果:A/B test, 用户反馈,badcase分析
建议建立完整体系,不能只看单一指标
3 简述对于直接偏好优化(DPO)的理解
在传统强化学习对齐方法(如 RLHF)中,我们需要一个显式的奖励模型(RM),它是一个独立训练的神经网络,用于给每个回答打分(例如0-1分),然后用这个分数作为强化学习的奖励信号。
而 DPO/KTO/SimPO 等方法的核心思想是——不训练奖励模型,直接利用语言模型自身的输出概率,通过数学变换“隐式地”构造出一个奖励函数。
- DPO: Direct Preferenec Optimization
- 用偏好对直接训练模型,不需要奖励模型,不需要 RL
- KTO: Kahneman-Tversky Optimization
- 在DPO框架上加入行为经济学地损失甲醛,让模型更关注错误、线性化损失
- SIMPO: Simple Preference Optimization
- 把 DPO 再简化,不再需要 reference model、不需要 log-ratio,让优化更稳健
4 DPO相关问题
4.1 DPO针对RLHF做了哪些改进
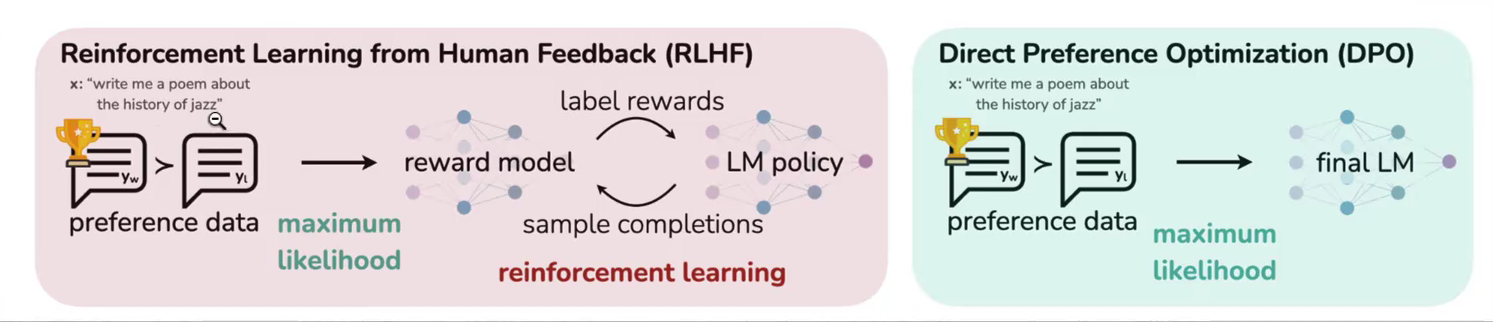
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
-
RLHF 算法包含奖励模型(reward model)和策略模型(Policy model,也称为演员模型,actor model),基于偏好数据以及强化学习不断迭代优化策略模型地过程
-
DPO 算法不包含奖励模型和强化学习过程,直接通过偏好数据进行微调,将强化学习过程直接转化为 SFT 过程,因此整个训练过程简单、高效、主要的改进之处体现在于损失函数。
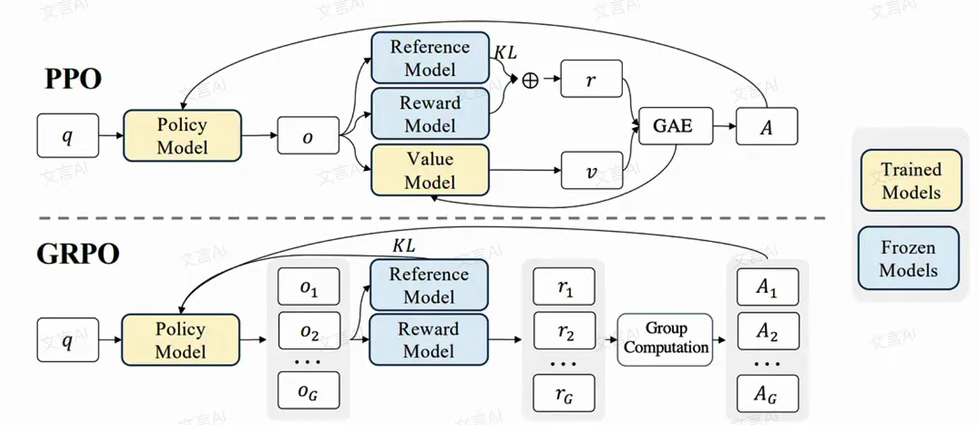
4.1.1 通过PPO进一步理解RLHF的过程
RLHF 常使用 PPO 作为基础算法,整体流程包含 4 个模型(Policy, Reference, Reward, Value, 具体图可以见 DeepseekMath那篇论文,之前的 PPO GRPO 笔记也有那张图),且通常训练过程中需要针对训练的 policy model 进行采样,因此训练起来,稳定性、效率、效果不易控制。
-
Policy Model(又称 Actor):输入一段上文,输出下一个 token 的概率分布,该模型需要训练,是我们最终得到的模型,输出下一个 token 即为 policy model 的行为
- 演员模型,待训练的模型,通常是 SFT 训练后的模型作为初始化
-
Value Model(又称 Critic):用于预估当前模型回复的总收益。该总收益不仅局限于当前 token 的质量,还需要衡量当前 token 对后续文本生成的影响。该模型需要训练。
- 作用是估计状态或状态动作对的长期价值,也称为状态值函数或动作值函数。
-
Reward Model:事先用偏好数据进行训练,用于对 Policy 模型的预测进行打分,评估模型对于当前输出的即时收益。
- 用于提供每个状态或状态动作对的即时奖励信号。
-
Reference Model:与 Policy MOdel 相同,但在训练过程中不进行优化更新,用于维持模型在训练中的表现,防止在更新过程中出现过大偏差。
- 参考模型,也是经 SFT 训练后的模型进行初始化,且通常与 actor 是一个模型,且模型冻结,不参与训练,其作用是在强化学习过程中,保障 actor 与 reference 的分布差异不宜过大。
DPO 算法仅包含 RLHF 中的两个模型,即 actor 和 reference,且训练过程中不需要进行数据采样
小结:DPO 的主要改进
-
RLHF 算法包含奖励模型和策略模型,基于偏好数据以及强化学习不断迭代优化策略模型的过程。
-
DPO 算法不包含奖励模型和强化学习过程,直接通过偏好数据进行微调,将强化学习过程直接转换为 SFT 过程,因此整个训练过程简单、高效,主要的改进之处体现在于损失函数。
4.2 DPO中数据如何构造?
- 偏好数据,可以表示为三元组(提示语 prompt,良好回答 chosen,一般回答 rejected)
- https://huggingface.co/blog/pref-tunign
- 数据内容:
Intel/orca_dpo_pairs,HuggingFaceH4/ultrafeedback_binarized
4.3 DPO的损失函数是什么?
4.3.1 公式直观理解
L DPO ( π θ ; π ref ) = − E ( x , y w , y l ) ∼ D [ log σ ( β log π θ ( y w ∣ x ) π ref ( y w ∣ x ) − β log π θ ( y l ∣ x ) π ref ( y l ∣ x ) ) ] \mathcal{L}_{\text{DPO}}(\pi_{\theta};\pi_{\text{ref}}) = -\mathbb{E}_{(x,y_w,y_l)\sim\mathcal{D}}\left[\log\sigma\left(\beta\log\frac{\pi_{\theta}(y_w|x)}{\pi_{\text{ref}}(y_w|x)}-\beta\log\frac{\pi_{\theta}(y_l|x)}{\pi_{\text{ref}}(y_l|x)}\right)\right] LDPO(πθ;πref)=−E(x,yw,yl)∼D[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))]
其中:(参考文献:Direct Preference Optimization: Your Language Model is Secretly a Reward Model, page 4)
- π θ \pi_\theta πθ:需要被优化的参数化策略,即模型本身
- π ref \pi_{\text{ref}} πref:参考策略,通常是 SFT 后的模型
- E ( x , y w , y l ) ∼ D \mathbb{E}_{(x,y_w,y_l)\sim\mathcal{D}} E(x,yw,yl)∼D:偏好数据集, x x x 为输入提示词
- σ \sigma σ:sigmoid 激活函数
- β \beta β:超参数,用于控制策略偏离参考策略的成都,实质上是控制 KL 散度的约束的强度
- 前一个 log \log log:偏好回复的隐式奖励
- 后一个 log \log log:非偏好回复的隐式奖励
4.3.2 公式解释
-
DPO 采用的是负对数似然损失。最小化这个损失函数,等价于最大化人类偏好数据集 D \mathcal{D} D 中观察到 y w y_w yw 优于 y l y_l yl 的概率 P ( y w ≻ y l ∣ x ) P(y_{w}\succ y_l|x) P(yw≻yl∣x)
-
核心优化目标:最小化 L DPO \mathcal{L}_{\text{DPO}} LDPO 需要最大化 log σ ( ⋅ ) \log\sigma(\cdot) logσ(⋅) 这一项。由于 σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是 Sigmoid 函数,输出范围是 ( 0 , 1 ) (0,1) (0,1),因此 log σ ( ⋅ ) \log\sigma(\cdot) logσ(⋅) 总是负值,要使损失最小,必须使 log σ ( ⋅ ) \log\sigma(\cdot) logσ(⋅) 的绝对值最小,即让 σ ( ⋅ ) \sigma(\cdot) σ(⋅) 尽可能接近 1 1 1
4.3.2.1 Sigmoid 函数的输入:隐式奖励差
Sigmoid 函数 σ \sigma σ 的输入项 S S S 是关键:
S = β log π θ ( y w ∣ x ) π ref ( y w ∣ x ) − β log π θ ( y l ∣ x ) π ref ( y l ∣ x ) S = \beta\log\frac{\pi_{\theta}(y_w|x)}{\pi_{\text{ref}}(y_w|x)}-\beta\log\frac{\pi_{\theta}(y_l|x)}{\pi_{\text{ref}}(y_l|x)} S=βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x)
这个输入 S S S 实际上代表了偏好回答 y w y_w yw 和 非偏好回答 y l y_l yl 之间隐式奖励差。
等价地,可写为:
S = r ^ θ ( x , y w ) − r ^ θ ( x , y l ) S = \hat r_\theta(x, y_w) - \hat r_{\theta}(x, y_l) S=r^θ(x,yw)−r^θ(x,yl)
其中, r ^ θ ( x , y ) = β log π θ π ref \hat r_{\theta}(x, y)=\beta\log\frac{\pi_\theta}{\pi_{\text{ref}}} r^θ(x,y)=βlogπrefπθ 就是 DPO 中隐式定义的奖励函数。
4.3.2.2 最小化过程
要将损失 L DPO \mathcal{L}_{\text{DPO}} LDPO 最小化(即让 σ ( S ) \sigma(S) σ(S) 趋近于 1),模型 π θ \pi_\theta πθ 必须被调整,使得奖励差 S S S 趋近于一个足够大的正值。
- 当 S S S 是较大的正数时:表示 y w y_w yw 的隐式奖励远高于 y l y_l yl,此时:
- σ ( S ) ≈ 1 , log σ ( S ) ≈ 0 \sigma(S)\approx 1, \log\sigma(S)\approx 0 σ(S)≈1,logσ(S)≈0
- 损失 L DPO \mathcal{L}_{\text{DPO}} LDPO 接近 0,模型对当前的偏好对预测已正确,无需大幅更新
- 当 S S S 是负数或接近 0 时,表示模型错误地认为 y l y_l yl 地奖励更高,或两者奖励接近,此时:
- σ ( S ) \sigma(S) σ(S) 较小, log σ ( S ) \log\sigma(S) logσ(S) 是较大的负数
- 导致 L DPO \mathcal{L}_{\text{DPO}} LDPO 变大,产生较大的梯度,驱使模型更新参数
- 提升 y w y_{w} yw 的相对概率,降低 y l y_l yl 的相对概率。
直观理解:就是使得偏好对的奖励差异尽可能地大
4.3.3 公式中超参数 β \beta β 的作用?
β \beta β 控制 KL 散度约束的强度
- β \beta β 大:强约束,模型不能偏离 π ref \pi_{\text{ref}} πref 太远
- 优点:训练稳定,保持原有能力
- 缺点:可能学不到足够的偏好信息
- β \beta β 小:弱约束,允许更大的变化
- 优点:能更好地满足人类偏好
- 缺点:可能以往原有知识,模式崩溃
- 论文实际使用 β = 0.1 \beta=0.1 β=0.1 (默认) 和 0.5 0.5 0.5 (TL;DR摘要任务)
4.3.4 总结
DPO 损失函数地精妙之处在于:
- 隐式奖励建模:通过策略比值编码奖励
- 二元分类形式:简单的交叉熵损失
- 无需采样:直接计算,不需要 RL 采样
4.4 DPO 的微调流程是怎么样的?
4.4.1 微调流程

-
上图展示了 DPO 微调的大致流程,其中 Trained LM 即为策略模型,Frozen LM 即为参考模型,二者均是先进行 SFT 微调得到的模型进行初始化,其中 Trained LM 需要进行训练,Frozen LM 不参与训练。
-
两个模型分别针对 chosen 和 rejected 进行预测获取对应的得分,再通过 DPO 的损失函数进行损失计算,进而不断的迭代优化。
4.4.2 DPO 的缺点
-
由 loss 函数可知,其知识增加了 chosen 和 rejected 之间的差值,但是并未对其本身打分做 loss,可能会导致 chosen 和 rejected 都很小甚至是负数,但是他们的差距很大。
-
由于 chosen 的结果一般都比 rejected 的结果更长,所以经过 DPO 之后,可能会导致输出某些情况下的结果更长,不准确和重复的问题。
4.4.3 DPO 总结
-
将经过 SFT 后的模型本身作为奖励模型,但是参数不更新;
-
policy 模型也是本身,但是参数更新;
-
然后经过下面的 loss 函数去更新 policy 模型:
L DPO ( π θ ; π ref ) = − E ( x , y w , y l ) ∼ D [ log σ ( β log π θ ( y w ∣ x ) π ref ( y w ∣ x ) − β log π θ ( y l ∣ x ) π ref ( y l ∣ x ) ) ] \mathcal{L}_{\text{DPO}}(\pi_\theta;\pi_{\text{ref}}) = -\mathbb{E}_{(x,y_w,y_l)\sim\mathcal{D}}\left[\log\sigma\left(\beta\log\frac{\pi_{\theta}(y_w|x)}{\pi_{\text{ref}}(y_w|x)}-\beta\log\frac{\pi_{\theta}(y_l|x)}{\pi_{\text{ref}}(y_l|x)}\right)\right] LDPO(πθ;πref)=−E(x,yw,yl)∼D[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))]
5 KTO 相关问题
5.1 什么是 KTO
- 论文:2402.01306: KTO: Model Alignment as Prospect Theoretic Optimization
- 官方代码:https://github.com/ContextualAL/HALOs
- 模型:https://huggingface.co/collections/ContextualAI/archangel-65bd45029fa020161b052430
KTO 全称为Kahneman-Tversky Optimization(卡尼曼——特沃斯基优化),是一种基于行为经济学前景理论的 LLM 对齐技术。由斯坦福大学等机构的研究人员在 2024 年提出,论文已被 ICML 2024 接收。
KTO 的命名源自诺贝尔经济学奖得主丹尼尔·卡尼曼和阿莫斯·特沃斯基的前景理论,该理论揭示了人类在面对不确定事件时的决策偏差,尤其是损失厌恶(Loss Aversion)的心理特征。
5.1.2 KTO 训练的基本流程
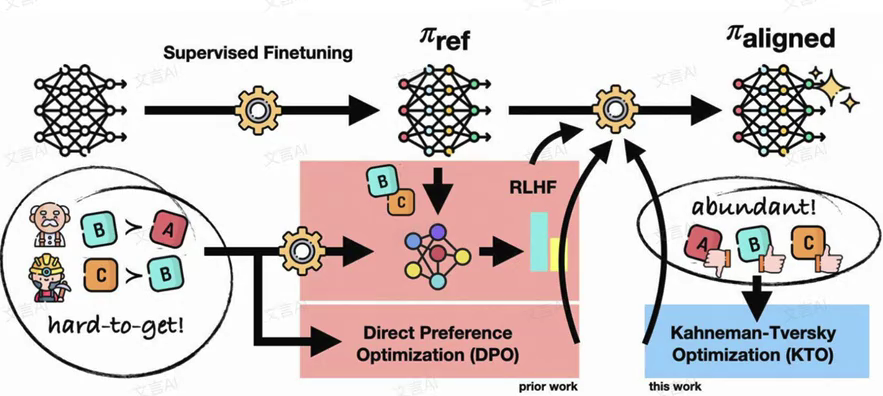
-
起点:SFT
- 从基础神经网络开始,通过 SFT 得到参考模型 π ref \pi_{\text{ref}} πref
-
传统路径的挑战:
- RLHF:一般需要多个模型;且需要hard-to-get(难以获取的)数据, A → B , C → B A\rightarrow B,C\rightarrow B A→B,C→B这种成对比较数据;
- DPO:简化模型;同样需要成对的偏好数据;
问题:需要人类标注者对两个回答进行比较,耗时耗力
- 创新突破:KTO
- 只需要二元反馈:好 / 不好;
- 数据需求革新:有 abundant(丰富的) 数据可以使用;A、B、C 等独立样本,不需要成对比较;
- 理论基础:基于 Kahneman-Tversky 的前景理论(Prospect Theory),即考虑人类对损失和收益的不对称感知
5.1.3 KTO 的核心优势
与传统的对齐方法(PPO, DPO)相比,KTO 的最大创新在于:只需要二元标签数据(好/坏),而不需要成对的偏好数据(A 优于 B)
特别适合那些希望利用自然用户反馈(而非专业标注)来改进模型的应用场景。
| 特性 | PPO | DPO | KTO |
|---|---|---|---|
| 数据需求 | prompt, response, reward 分数 | prompt, chosen, rejected 回答 | prompt, response, 好坏标签 |
| 训练复杂度 | 极高(需要多个模型) | 中等(需要偏好对) | 低(仅需二元标签) |
| 数据收集成本 | 高 | 中等 | 极低 |
| 主要优点 | 理论成熟 | 简单稳定 | 数据门槛最低,可利用大量现有反馈数据 |
5.2 关于 KTO 中的数据问题
在 KTO 中,其数据格式的核心特点是不再依赖成对的偏好数据,而是使用二进制信号(desireable / undesirable)
5.2.1 核心数据格式:二进制反馈
与 DPO 等方法需要A比B好的偏好对 ( x , y w , y l ) (x,y_w,y_l) (x,yw,yl)不同,KTO 只需要一个输出是好还是不好
数据集中,KTO_TAG 一般为 True / False
5.2.2 数据配比的灵活性
KTO 对数据格式的要求非常宽松,尤其体现在处理不平衡数据的能力上:
-
无需 1:1 配比:DPO要求正负样本成对出现,严格为 1:1
-
支持极度不平衡数据:即使数据中正负样本比例严重失调(例如期望样本和非期望样本的比例为 1:10),KTO 也能通过调整超参数 λ D \lambda_D λD 和 λ U \lambda_U λU 来正常训练,且性能依然能匹配在平衡数据上训练的 DPO
- λ D \lambda_D λD:对正样本的损失权重
- λ U \lambda_U λU:对负样本的损失权重
-
推荐的权重比例:
λ D × n D λ U × n U ∈ [ 1 , 3 2 ] \frac{\lambda_D\times n_D}{\lambda_U\times n_U}\in[1,\frac32] λU×nUλD×nD∈[1,23]
其中 n ⋅ n_\cdot n⋅ 表示正负样本的数量
具体操作逻辑:
- 固定一端,调整另一端:比如通常固定 λ U = 1 \lambda_U=1 λU=1,然后根据样本比例调整 λ D \lambda_D λD
- 这种公式设计的直觉在于,让模型对于正负样本具有不同的敏感性,原论文指出这种设计是能够保证在不均衡数据集上的训练效果的。
具体 CODE 可以参考 TRL 源码
- trl/experimental/kto/kto_trainer.py
- trl/examples/scripts/kto.py
5.3 KTO 的损失函数是什么?
KTO 的默认损失函数定义为针对单个样本 ( x , y ) (x,y) (x,y)的期望值:
L KTO ( π θ , π ref ) = E x , y ∼ D [ λ y − v ( x , y ) ] L_{\text{KTO}}(\pi_\theta,\pi_{\text{ref}})=\mathbb{E}_{x,y\sim D}[\lambda_y-v(x,y)] LKTO(πθ,πref)=Ex,y∼D[λy−v(x,y)]
其中:
- λ y \lambda_y λy:当 y y y是期望输出时取 λ D \lambda_D λD,非期望输出时取 λ U \lambda_U λU
- v ( x , y ) v(x,y) v(x,y)时价值函数,它根据样本是期望的还是非期望的分为两种情况:
- 当 y y y是期望输出时: v ( x , y ) = λ D σ ( β ( r θ ( x , y ) − z 0 ) ) v(x,y)=\lambda_D\sigma(\beta(r_\theta(x,y)-z_0)) v(x,y)=λDσ(β(rθ(x,y)−z0))
- 当 y y y是非期望输出时: v ( x , y ) = λ U σ ( β ( z 0 − r θ ( x , y ) ) ) v(x,y)=\lambda_U\sigma(\beta(z_0-r_\theta(x,y))) v(x,y)=λUσ(β(z0−rθ(x,y)))
为了方便理解,可以将公式拆解为以下几个关键概念:
- 隐式奖励 r θ ( x , y ) r_\theta(x,y) rθ(x,y):计算方式为 log π t h e t a ( y ∣ x ) π ref ( y ∣ x ) \log\frac{\pi_theta(y|x)}{\pi_{\text{ref}}(y|x)} logπref(y∣x)πtheta(y∣x),代表了当前模型 π θ \pi_\theta πθ相对于参考模型 π ref \pi_{\text{ref}} πref在该样本上的进步成都。
- 参考点 z 0 z_0 z0:这是 KTO 的灵魂。前景理论认为人类是根据参考点来感知得失的,在 KTO 中, z 0 z_0 z0被定义为模型与参考模型之间的 KL 散度估计值。
- 在minibatch通过错位匹配(mismatched pairs)来估算,这样可以获得更具代表性的参考点,避免使用样本本身带来的偏差。
- 非对称权重 λ D , λ U \lambda_D,\lambda_U λD,λU:这两个参数用于控制模型对收益何损失的敏感度。通过调整这两个值,KTO可以处理数据不平衡问题。
- 参数 β \beta β:用于控制风险厌恶(Rist aversion)程度。 β \beta β越大,价值函数越快达到饱和,意味着模型对偏离参考模型的行为更加谨慎。
5.3.1 什么是错位匹配?
-
在KTO的实际训练中,程序会选取一个minibatch,假设大小为 m m m,包含样本对 { ( x 1 , y 1 ) , . . . , ( x m , y m ) } \{(x_1,y_1),...,(x_m,y_m)\} {(x1,y1),...,(xm,ym)}
-
所谓的错位匹配,是指在计算参考点时,并不计算当前输入 x i x_i xi与其对应标签 y i y_i yi的奖励,而是将当前输入 x i x_i xi与minibatch中另一个样本的输出 y j y_j yj(例如 j = i + 1 j=i+1 j=i+1)强行配对
-
计算公式为:
z ^ = max ( 0 , 1 m ∑ i = 1 m log π θ ( y j ∣ x i ) π ref ( y j ∣ x i ) ) \hat z=\max\left(0,\frac1m\sum_{i=1}^m\log\frac{\pi_\theta(y_j|x_i)}{\pi_{\text{ref}}(y_j|x_i)}\right) z^=max(0,m1i=1∑mlogπref(yj∣xi)πθ(yj∣xi))
5.3.1.1 为什么要避开样本本身?
根据KTO的论文指出,直接使用训练集中的原配对样本 ( x i , y i ) (x_i,y_i) (xi,yi)来计算 z 0 z_0 z0会带来巨大的统计偏差:
- 标签的极端性:训练数据中的输出 y i y_i yi通常时经过人工或模型筛选的,它们要么时极其优秀的回答(期望的),要么时存在明显错误的回答(非期望的)
- 不具有代表性的奖励值:由于这些 y i y_i yi具有典型的正负倾向,计算出的隐式奖励往往是极端的。
- 偏差后果:如果用这些极端的奖励值去平均,得出的 z 0 z_0 z0参考点将不再代表模型的平均表现,而会向极端值偏移(其实就是方差太大了),从而导致模型无法正确判定什么是真正的收益或损失。
5.3.1.2 为什么错位匹配更具有代表性?
-
摒弃暴露分布:通过将 x i x_i xi与 y j y_j yj错配,计算出的奖励值更能反映模型在处理随机、非针对性输入时的基础偏好水平,这更接近定义上的 KL 散度 K L ( π θ ∣ π r e f ) KL(\pi_\theta|\pi_{ref}) KL(πθ∣πref),即整个模型的分布偏移量。
-
模拟可用性启发法:KTO论文指出,这种做法在心理上是合理的,人类在判断一个事物的概率或价值时,往往会受到近期接触到的信息的影响,即使这些信息与当前任务并不直接相关。在minibatch内进行错位匹配,模拟人类近期记忆(整个批次的反馈)建立预期基准的过程
5.3.2 KTO中,通过损失函数优化的过程
损失总是越小越好。
训练过程通过调整损失值,相对于参考模型(ref_model),提高被标注为 desirable 的回答的概率,压低被标注为 undesirable 的概率。
整个调优过程中,loss 并不是衡量预测误差,而是一个基于对数概率比的偏好约束函数。它直接决定了梯度更新的而方向。
- 好样本:梯度推动模型倾向于生成该回答
- 坏样本:梯度推动模型倾向于远离该行为
同时通过参考点以及KL约束,比卖你模型偏离原始能力太远。
总结:KTO的loss本质上时一个带符号的对数概率比约束,它通过最小化损失,让模型在保持接近ref_model的前提下,系统性地增加人类偏好的行为,减少人类不偏好的行为。
5.4 KTO 算法的优缺点
5.4.1 KTO 的主要优点
- 标注成本低:只需要对单一输出进行二元标注,比需要配对偏好数据的数据量少得多,标注更快更便宜
- 数据效率高:无需严格配对,可用常规标注或弱监督数据直接训练
- 计算简单:相比DPO等配对方法,在训练时计算较轻(减少交叉对比概率计算),训练速度常更快。
- 对不平衡数据更鲁棒:对好样本稀少的场景,损失厌恶机制有助于模型减少不可取输出。
- 适用资源有限场景:特别适合预算紧张,数据稀缺,快速迭代调优的场景
减少交叉对比概率计算的说明:KTO不再像DPO那样在同一个prompt下对多个候选输出进行成对log-prob差分何reference的对比,而是将偏好信号直接作用在单个样本的对数概率上,从而显著减低forward次数,显存占用和训练复杂度
5.4.2 KTO 的潜在缺点
- 捕捉偏好粗糙:只能区分二元层次的好坏,无法捕捉细粒度偏好细节
- 依赖标签质量:标签噪声会显著影响优化小郭,因为模型学习的只是总体可取性,而非精细偏好
- 损失函数中的权重 λ \lambda λ,阈值等超参数设定对训练稳定性与效果敏感
- 对基础能力提升有限:如果训练数据本身事实准确性不高,模型可能会学习错误模式
5.4.3 什么情况下选择 KTO 而非 DPO?
优先使用 KTO 的场景:
- 数据格式限制:只有二元标注,无法获取配对偏好数据
- 数据质量问题:
- 数据中存在高噪声数据
- 标注者偏好有传递性违反(A>B, B>C, 但C>A)
- 正负样本极不均衡(KTO可容忍90%正样本缺失)
- 训练流程简化:
- 无法或不想先做SFT(KTO可单独使用)
- 避免DPO不做SFT时的幻觉对话问题
优先使用DPO的场景:
- 数据噪声低且传递性好
- 已有高质量的配对偏好数据
经验规则:实际公开数据集多为噪声大,KTO通常匹配或超越DPO表现
6 SimPO 相关问题
6.1 介绍一下什么是 SimPO
- paper: SimPO: Simple Preference Optimization with a Reference-Free Reward
- 代码:https://github.com/princeton-nlp/SimPO
6.1.1 SimPO 提出解决的问题
SimPO 是一种轻量化的人类偏好优化算法,由普林斯顿大学研究团队提出,它是对传统 DPO 算法的改进
传统 RLHF 流程存在以下问题:
- 训练复杂:需要额外的 Reward Model
- 超参敏感:PPO 调优难度大
- 不稳定:训练可能出现 reward hacking 或 训练崩溃
尽管 DPO 极大简化了 RLHF 流程 但仍存在两个核心问题:
- 参考模型依赖性:需维护一个冻结的参考模型(SFT Checkpoint),导致:
- 存储开销增加(需要保留两个模型);
- 若 SFT 模型质量较差,会限制 DPO 上限(garbage in, garbage out)
- 多阶段训练耦合性强,不利于迭代
- 缺乏显式质量控制,DPO 仅要求 log π θ ( y w ) > log π θ ( y l ) \log\pi_{\theta}(y_w)>\log\pi_{\theta}(y_l) logπθ(yw)>logπθ(yl),但不约束差距大小,可能导致模型勉强选对,而非显著更好
SimPO 的设计动机正是为了解决上述两点:
- 通过消去 π r e f \pi_{ref} πref,实现单模型端到端优化
- 引入 γ > 0 \gamma>0 γ>0,强制拉开正负样本的 log-prob 差距,提升生成结果的绝对质量
SimPO 旨在简化偏好优化流程,直接基于模型输出的概率进行偏好对齐,无需训练独立奖励模型
6.1.2 SimPO 的 loss 函数
DPO的损失:
L DPO ( π θ ; π ref ) = − E ( x , y w , y l ) ∼ D [ log σ ( β log π θ ( y w ∣ x ) π ref ( y w ∣ x ) − β log π θ ( y l ∣ x ) π ref ( y l ∣ x ) ) ] \mathcal{L}_{\text{DPO}}(\pi_{\theta};\pi_{\text{ref}}) = -\mathbb{E}_{(x,y_w,y_l)\sim\mathcal{D}}\left[\log\sigma\left(\beta\log\frac{\pi_{\theta}(y_w|x)}{\pi_{\text{ref}}(y_w|x)}-\beta\log\frac{\pi_{\theta}(y_l|x)}{\pi_{\text{ref}}(y_l|x)}\right)\right] LDPO(πθ;πref)=−E(x,yw,yl)∼D[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))]
SimPO 的损失(paper p.4):
KaTeX parse error: Expected '\right', got '}' at position 164: …{\theta}(y_w|x)}̲-\frac{\beta}{|…
注意这两个 β \beta β是不一样的,这个DPO各个参数的说明上面有写,SimPO中的 β \beta β用于控制经过长度归一化后的平均对数概率。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)