收藏!大模型在建筑设计领域的错误及RAG解决方案实战教程
摘要:针对大模型在建筑设计规范领域存在的信息陈旧、知识结构混乱等问题,本文提出基于RAG(检索增强生成)的解决方案。通过将《民用建筑设计统一标准》等规范文档处理为结构化文本,建立本地向量知识库,实现专业知识的精准检索与生成。系统采用分块策略保持语义连贯,结合提示工程确保回答准确标注条款来源,有效解决了大模型在垂直领域的幻觉问题,为建筑师提供可靠的智能规范查询工具。实验表明该方法显著提升了专业问答的
大模型在垂直领域如建筑设计规范中存在信息陈旧、缺乏结构化知识等问题。文章通过实例分析大模型错误原因,提出基于RAG(检索增强生成)的解决方案,详细介绍文档处理、向量化、知识库构建及智能问答系统的实现步骤,有效提升专业领域知识准确性,为建筑师提供智能对话式规范查询工具。
前言
大模型在训练时是包含了海量的建筑设计规范文件的,但是它在回答建筑设计专业问题时仍然会出较多错误。我向网页版Deepseek问了两个问题,它的回答都是错的:
问:无障碍厕所隔间的尺寸是多少?
Deepseek答:依据《无障碍设计规范》GB50763-2012,平面尺寸不应小于1.80m×1.50m
规范要求:实际在无障碍规范中,无障碍厕所不应小于1.8m×1.0m;在民用建筑统一标准中,无障碍厕所隔间不应小于1.5m×2.0m,隔间外开门时不应小于1.0m×1.8m。
问:单侧并列洗手盆或盥洗槽外沿至对面墙的净距不应小于多少?居住建筑洗手盆外沿至对面墙的净距不应小于多少?
Deepseek答:其外沿至对面墙(或障碍物)的净距,不应小于1.20m;居中建筑中不应小于0.7m
规范要求:单侧并列洗手盆或盥洗槽外沿至对面墙的净距不应小于1.25m;居住建筑洗手盆外沿至对面墙的净距不应小于0.6m。
通过以上两个问题反映了大模型在垂直领域中一些能力上的不足,比如:
1)信息陈旧与矛盾,训练时用的规范并非最新版
2)缺乏深度结构化知识,无法实现“章-节-条-款”定位
3)数据分布偏差,冷门知识缺失,例如网络上大家问的较多的规范问题,大模型就能回答的相对准确
4)大模型本质是概率生成,回答时候有一定概率产生幻觉
因此垂直领域的知识库的搭建,就显的非常必要了。

Retrieval Augmented Generation,中文翻译为检索增强生成,是将信息检索与大模型生成结合的一种技术框架。模型生成答案时,会被强制要求基于检索到的最新、最相关的知识库文档片段来组织语言,而非依赖其内部可能过时或错误的信息,从而极大地降低其幻觉的概率。
实战解析
第一步:文档材料准备
我们在实际工作中的规范文档材料多种多样,有PDF、word等不同类型的文档。文档内容也并非全部都是有效信息,因此需要对文档的内容进一步处理。
本文选择将《民用建筑设计统一标准》GB 50352-2019这本建筑规范统一处理为markdown格式,规范中的表格则统一处理为html格式,方便文档切分及后续的文本向量转换。最终处理好的文件以TXT格式保存。
文档清洗是非常重要的一步,它将多余噪声清除,将非文本格式的内容转化为嵌入模型可识别的格式,为后续的工作打下一个坚实的基础。
第二步:设置API_KEY
直接将模型的APIKEY设置为环境变量,这样使用起来更方便,如将代码公开,APIKEY也不会暴露。
在本文中,文本向量化时使用的嵌入模型来自阿里百炼平台的"text-embedding-v1";在回答问题阶段则调用的是"deepseek"
DASHSCOPE_API_KEY = os.getenv('DASHSCOPE_API_KEY')
DEEPSEEK_API_KEY = os.getenv('DEEPSEEK_API_KEY')
第三步:文档向量化,并构建可检索的知识库
像上一篇文章一样,同样是需要将文档做向量化的表达。这是将TXT变为大模型可理解格式的关键一步。我们采用"分块"策略,将长文本切成有重叠的小段,既保持上下文,又方便精确检索。
本文是按照标题的层级结构进行分块的,这是针对规范类文档较为常用的一种分块策略,能较好的保持文档的语义连贯。
将分块的文本转换为向量之后,再利用FAISS创建一个本地的向量数据库保存转换后的向量,方便进行语义相似度的检索。
def process_txt_file(file_path: str, save_path: str = None) -> FAISS:
"""从txt文件创建向量存储"""
# 读取txt文件
text = Path(file_path).read_text(encoding='utf-8')
print(f"已读取文件: {file_path}, 文本长度: {len(text)} 字符")
# 创建文本分割器
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n#", "\n##", "\n###", "\n\n", "\n", "。"],
chunk_size=300,
chunk_overlap=60,
length_function=len,
)
# 分割文本
chunks = text_splitter.split_text(text)
print(f"文本被分割成 {len(chunks)} 个块。")
# 创建嵌入模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=DASHSCOPE_API_KEY,
)
# 创建知识库
knowledge_base = FAISS.from_texts(chunks, embeddings)
print("已从文本块创建知识库。")
# 保存向量数据库
if save_path:
os.makedirs(save_path, exist_ok=True)
knowledge_base.save_local(save_path)
print(f"向量数据库已保存到: {save_path}")
return knowledge_base
第四步:创建或加载向量数据库
首次运行以下函数,是调用嵌入模型将txt格式文件转换为向量格式并创建FAISS数据库。当本地已保存了相应向量数据库文件之后,再次运行以下函数,将加载已保存的向量数据库。
def create_or_load_knowledge_base() -> FAISS:
"""创建或加载向量数据库"""
# 文件路径和保存路径
txt_file_path = "./民用建筑设计统一标准GB50352-2019.txt"
vector_store_path = "./vector_store"
# 创建嵌入模型(创建和加载都需要)
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=DASHSCOPE_API_KEY,
)
# 检查向量数据库是否已存在
ifnot os.path.exists(vector_store_path):
print("向量数据库不存在,开始创建...")
# 创建向量数据库
knowledge_base = process_txt_file(
file_path=txt_file_path,
save_path=vector_store_path
)
print("向量数据库创建完成。")
else:
print("向量数据库已存在,开始加载...")
# 直接加载FAISS向量数据库
knowledge_base = FAISS.load_local(vector_store_path, embeddings, allow_dangerous_deserialization=True)
print(f"向量数据库已从 {vector_store_path} 加载。")
print("向量数据库加载完成。")
return knowledge_base
第五步:搭建智能问答
知识库就绪后,我们将其与大语言模型连接,形成完整的问答流水线。
当你向RAG系统提出了一个建筑设计规范问题,系统会先检索知识库,寻找语义最为相似的知识切片。然后系统会将系统提示词、找出的知识切片、你提出的问题整合在一起,再喂给大模型。最后大模型接收以上所有信息之后,再做出相应回答。
if __name__ == "__main__":
from langchain_openai import ChatOpenAI
# 创建或加载知识库
knowledgeBase = create_or_load_knowledge_base()
# 初始化语言模型
llm = ChatOpenAI(
model_name="deepseek-chat", # 或 "deepseek-coder" 根据你的需求
openai_api_key= DEEPSEEK_API_KEY,
openai_api_base="https://api.deepseek.com", # DeepSeek API地址
temperature=0.1,
max_tokens=2048
)
SYSTEM_PROMPT = """你是一个专业的建筑标准咨询助手,专门回答关于《民用建筑设计统一标准GB50352-2019》的问题。
重要要求:每次回答问题时,必须在答案中标明答案所依据的具体条款或章节的标题号(如:4.5.2、3.1.1等)。
如果答案涉及多个条款,需要分别注明每个条款的标题号。
回答格式要求:
1. 先直接回答问题
2. 然后标注标题号(如:依据标准第4.5.2条...)
请确保答案准确、专业,并严格依据提供的文本内容。"""
# 设置查询问题
query = "单侧并列洗手盆或盥洗槽外沿至对面墙的净距不应小于多少?"
if query:
# 执行相似度搜索,找到与查询相关的文档
docs = knowledgeBase.similarity_search(query, k=10)
# 构建上下文
context = "\n\n".join([doc.page_content for doc in docs])
# 构建提示
prompt = f"""{SYSTEM_PROMPT}
根据以下上下文回答问题:
{context}
问题: {query}
请按照要求的格式回答:"""
# 直接调用 LLM
response = llm.invoke(prompt)
answer = response.content
print("回答:")
print(answer)
print(f"模型名称: {llm.model_name}")
尝试向系统提问本文最开始提到的问题"单侧并列洗手盆或盥洗槽外沿至对面墙的净距不应小于多少?",可以看到deepseek给出了准确的回答,并给出条款的标题号。
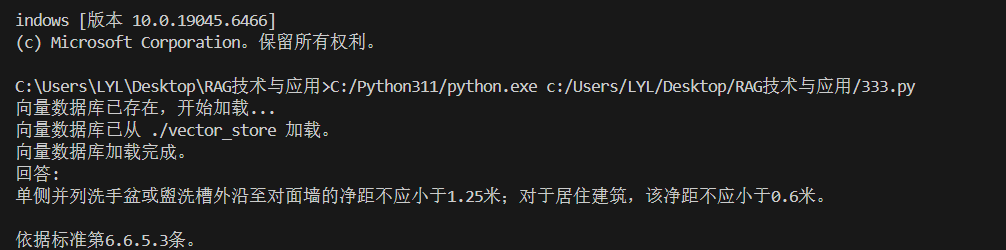
条款的标题号属于知识切片元数据的一种,本文可采用提示词的方式附在答案之后,是因为本文所使用的txt格式的规范文件已经转换为结构清晰的文件,并且在文档切片时也采用了以文章结构为主的切片策略。
结语
借助LangChain和RAG,我们将专业知识的获取方式从“手动翻阅”升级为“智能对话”。
建筑师在大多数场景下,并不能清晰的了解自己所需要查询的规范内容,尤其对于工作经验不足的新人。
但是他们可以提供具体的设计场景,让大模型理解具体使用环境,进一步帮助我们去翻阅资料。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
人工智能时代最缺的是什么?就是能动手解决问题还会动脑创新的技术牛人!智泊AI为了让学员毕业后快速成为抢手的AI人才,直接把课程升级到了V6.0版本。
这个课程就像搭积木一样,既有机器学习、深度学习这些基本功教学,又教大家玩转大模型开发、处理图片语音等多种数据的新潮技能,把AI技术从基础到前沿全部都包圆了!
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
课程还教大家怎么和AI搭档一起工作,就像程序员带着智能助手写代码、优化方案,效率直接翻倍!
这么练出来的学员确实吃香,83%的应届生都进了大厂搞研发,平均工资比同行高出四成多。
智泊AI还特别注重培养"人无我有"的能力,比如需求分析、创新设计这些AI暂时替代不了的核心竞争力,让学员在AI时代站稳脚跟。
课程优势一:人才库优秀学员参与真实商业项目实训
课程优势二:与大厂深入合作,共建大模型课程

课程优势三:海外高校学历提升

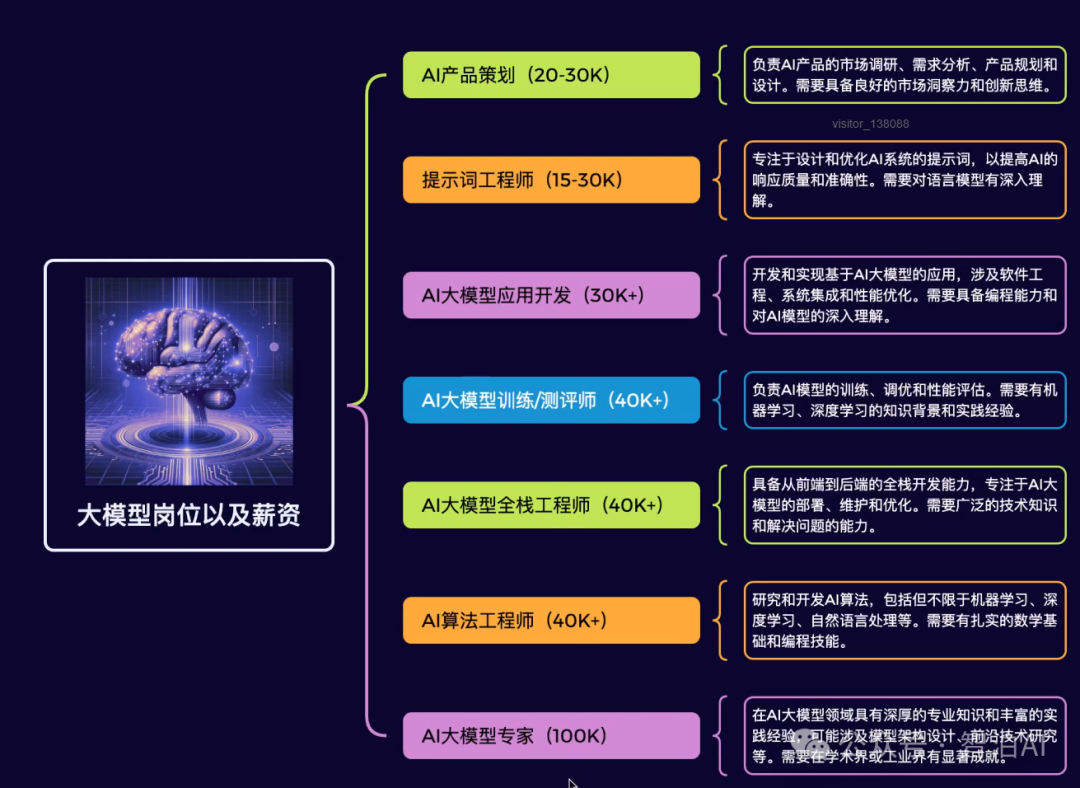
课程优势四:热门岗位全覆盖,匹配企业岗位需求
如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
·应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
·零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
·业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
重磅消息
人工智能V6.0升级两大班型:AI大模型全栈班、AI大模型算法班,为学生提供更多选择。

由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【最新最全版】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
来智泊AI,高起点就业
培养企业刚需人才
扫码咨询 抢免费试学
⬇⬇⬇

AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献405条内容
已为社区贡献405条内容

所有评论(0)