Hulu-Med:浙大、阿里等联合发布透明化通用多模态医疗开源大模型
Hulu-Med:首个透明化通用医疗视觉-语言模型 本文提出Hulu-Med,这是一个突破性的医疗AI模型,能够统一处理文本、2D/3D图像和视频等多种医疗数据。该模型基于1670万公开样本训练,覆盖12个解剖系统和14种成像模态,在30个基准测试中的27个超越开源模型,16个测试优于GPT-4o等专有系统。其创新包括: 统一架构设计:原生支持多模态医疗数据处理 高效训练:通过医学感知token压

Hulu-Med: A Transparent Generalist Model towards Holistic Medical Vision-Language Understanding
文章摘要
本文介绍Hulu-Med,首个透明化的通用医疗视觉-语言模型,能够统一处理医疗文本、2D/3D图像和视频。该模型在1670万公开样本上训练,覆盖12个解剖系统和14种成像模态,在30个医疗基准测试中的27个超越开源模型,16个超越专有系统如GPT-4o,为医疗AI提供完全可复现的解决方案。
【原文链接】https://t.zsxq.com/CSpyP
【代码地址】https://github.com/ZJUI-AI4H/Hulu-Med
一、引言:医学AI的统一愿景
1.1 临床决策的多模态本质
临床决策本质上是多模态的,需要整合自由文本病历、结构化记录和视觉输入(包括2D图像、3D扫描和视频)等多样化数据源,贯穿患者的整个诊疗过程。 临床医生必须随着时间推移综合这些信号,但当前的医疗AI系统仍然支离破碎且任务特定,导致效率低下和跨模态洞察的缺失。
1.2 现有医学VLM的局限性
尽管通用视觉-语言模型(VLM)发展迅速,但其在医疗领域的部署受到技术统一性和透明度方面的重大限制。 当前模型严重依赖指令微调来桥接预训练的视觉和语言编码器,虽然在特定任务上表现出色,但无法全面覆盖临床需求的完整范围,例如:
-
基于语言的诊断和医学报告任务
-
放射学和病理学中的2D/3D图像分析
-
内窥镜检查和手术中的复杂视频分析
更重要的是,这些专业医学AI工具的开发往往不透明,由专有数据集和非透明的数据管理流程主导,这阻碍了社区审查、可重复性,以及至关重要的临床应用。
1.3 Hulu-Med的创新突破
为克服这些局限,我们提出Hulu-Med——一个通用医学VLM,通过将文本、2D图像、3D体积数据和视频理解统一在单一架构中,实现全方位的多模态覆盖。
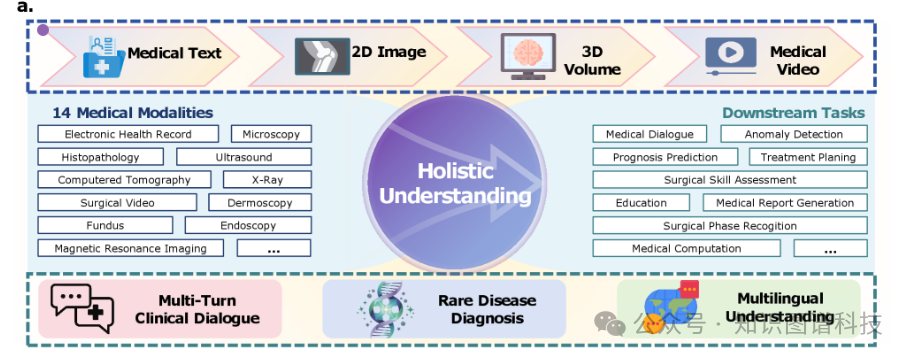
Hulu-Med构建于三大核心设计原则之上:
- 全方位覆盖
:统一处理文本、2D/3D图像和视频
- 规模化效率
:通过创新的token压缩策略实现高效训练
- 端到端透明性
:完全开放的数据、代码和模型参数
二、技术架构:统一的多模态设计
2.1 问题形式化
Hulu-Med被设计为能够处理异构输入并为各种临床任务生成文本响应的通用医学VLM。形式化地说,给定文本指令t和可选的视觉输入v∈{v₂D, v₃D, vvideo, ∅}(其中v可以是2D图像、3D体积、视频序列或缺失),模型生成文本响应y。
这一统一的形式化使Hulu-Med能够灵活处理各种输入配置:
- 纯文本查询
:用于医学知识推理和临床对话
- 视觉-语言任务
:医学图像/视频与文本指令结合,用于视觉问答、报告生成和诊断推理
- 交错多模态输入
:多种视觉模态(2D图像、3D体积、视频)和文本可以在单一上下文中任意交错
2.2 核心组件设计
Hulu-Med由四个核心组件构成:
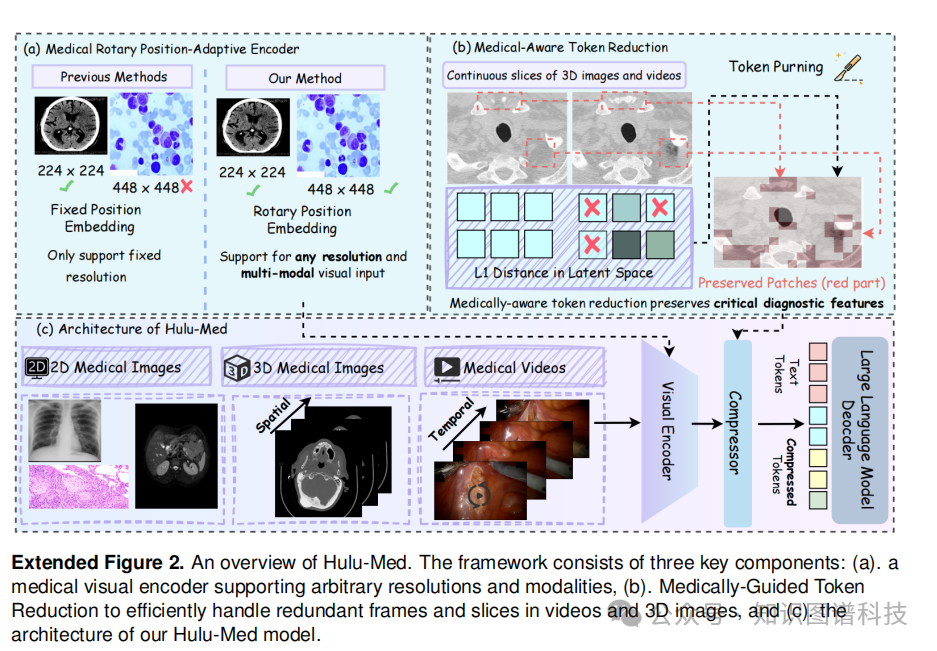
2.2.1 旋转位置自适应视觉编码器(Rotary Position-Adaptive Visual Encoder)
我们采用图像patch作为通用处理单元,使得2D图像、3D体积和视频能够作为可变长度的patch序列由单一编码器处理,无需针对特定模态的架构。 具体而言,我们改进了预训练的SigLIP模型,增强其2D旋转位置编码(RoPE)以扩展与3D和视频数据的兼容性。
2.2.2 多模态投影器与LLM解码器
投影层g(·)将视觉特征对齐到LLM的嵌入空间,然后语言模型解码器Φ(·)基于连接的token序列自回归生成响应。 为了展示可扩展性并应对不同的计算约束,我们开发了三个模型变体:
- Hulu-Med-7B
:基于Qwen2.5-7B
- Hulu-Med-14B
:基于Qwen3-14B
- Hulu-Med-32B
:基于Qwen2.5-32B
2.2.3 医学感知的Token压缩策略
为了高效管理3D和视频patch长序列带来的巨大计算需求,我们设计了医学感知的token缩减策略,实现了全面而高效的训练。该策略能够将视觉token减少约55%。
【Token压缩效果对比】
2.3 三阶段渐进式训练
Hulu-Med采用渐进式三阶段训练课程:
阶段1:视觉-语言对齐(Vision-Language Alignment)
-
目标:建立医学视觉-语言对齐
-
训练数据:简洁的2D医学图像-标题对
-
可训练参数:仅视觉编码器和多模态投影器
阶段2:医学多模态预训练(Medical Multimodal Pre-training)
-
目标:在大规模长形式医学图像-标题对(2D图像)上进行持续训练
-
补充数据:混合通用数据
-
可训练参数:所有参数保持完全可训练
阶段3:混合模态指令微调(Mix-Modality Instruction Tuning)
-
目标:在广泛的多模态数据集上进行全面微调
-
覆盖范围:跨文本、2D、3D和视频模态的多样化下游任务
-
训练策略:LLM解码器、视觉编码器和多模态投影器保持完全可训练
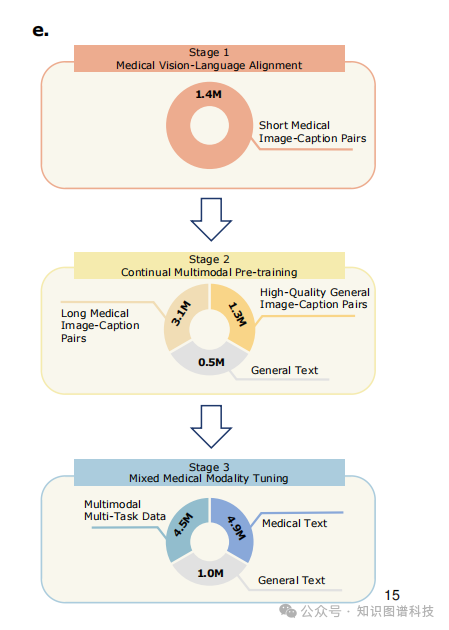
【图1e:三阶段训练流程图】
这一训练课程利用丰富的2D数据培养强大的视觉表示,使模型能够在相对较少的专门数据下在复杂的3D和视频任务上表现出色。
三、训练数据:史无前例的规模与多样性
3.1 数据集概览
为支持广泛的通用能力并促进透明度,我们策划了一个前所未有的1670万样本多模态数据集——据我们所知是最大的公开可用数据集——完全来源于开放资源并通过合成数据增强。
数据集构成:
- 900万
多模态医学样本
- 490万
医学文本问答对
- 130万
多模态通用样本
- 150万
通用文本问答对
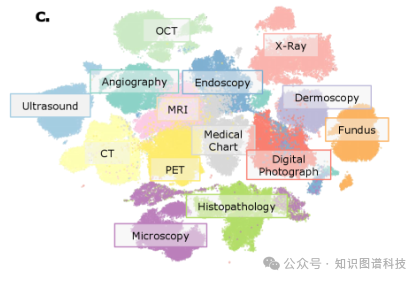
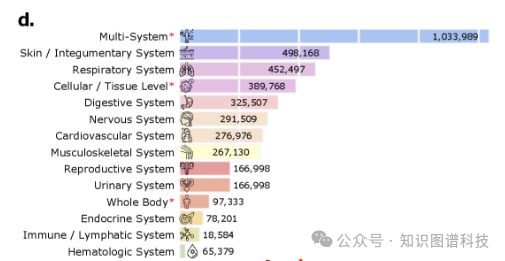
3.2 医学数据的广度与深度
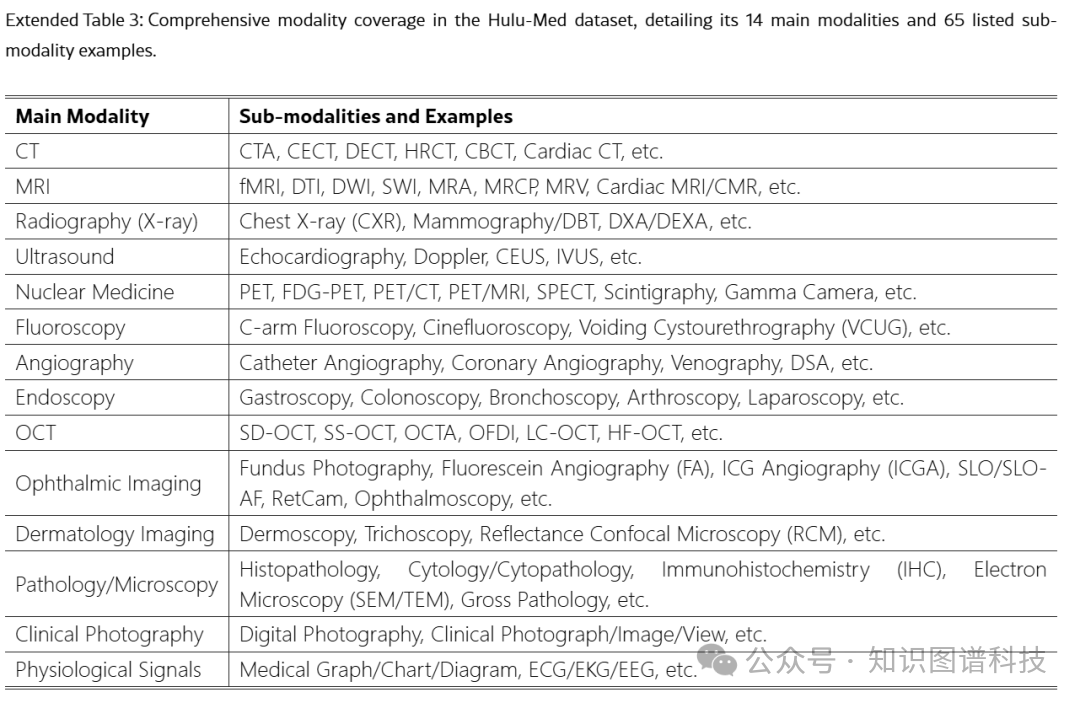
医学子集跨越12个主要解剖系统和14种不同成像模态,涵盖超过60种特定类型和广泛的临床任务,包括:
-
CT(计算机断层扫描)
-
MRI(磁共振成像)
-
X射线
-
内窥镜检查
-
组织病理学
-
超声
-
眼科成像(OCT、眼底照相)
-
皮肤镜检查
-
显微镜检查
3.3 五大合成数据管道
原始公开数据集通常存在模态覆盖有限、文本与视觉数据之间对齐不佳以及显著的长尾分布等问题,这些都会妨碍模型性能和泛化能力。为应对这些挑战,我们开发了五个专门的合成管道来生成高质量、指令对齐的视觉-文本对:
- 简短标题改写
:将简洁标题重写为详细描述
- 长形式医学图像标题生成
:生成新颖的长形式医学图像标题
- 医学VQA对构建
:构建医学视觉问答对
- 多语言思维链(CoT)推理数据
:生成多语言CoT推理数据
- 手术视频标注
:对手术视频进行标注
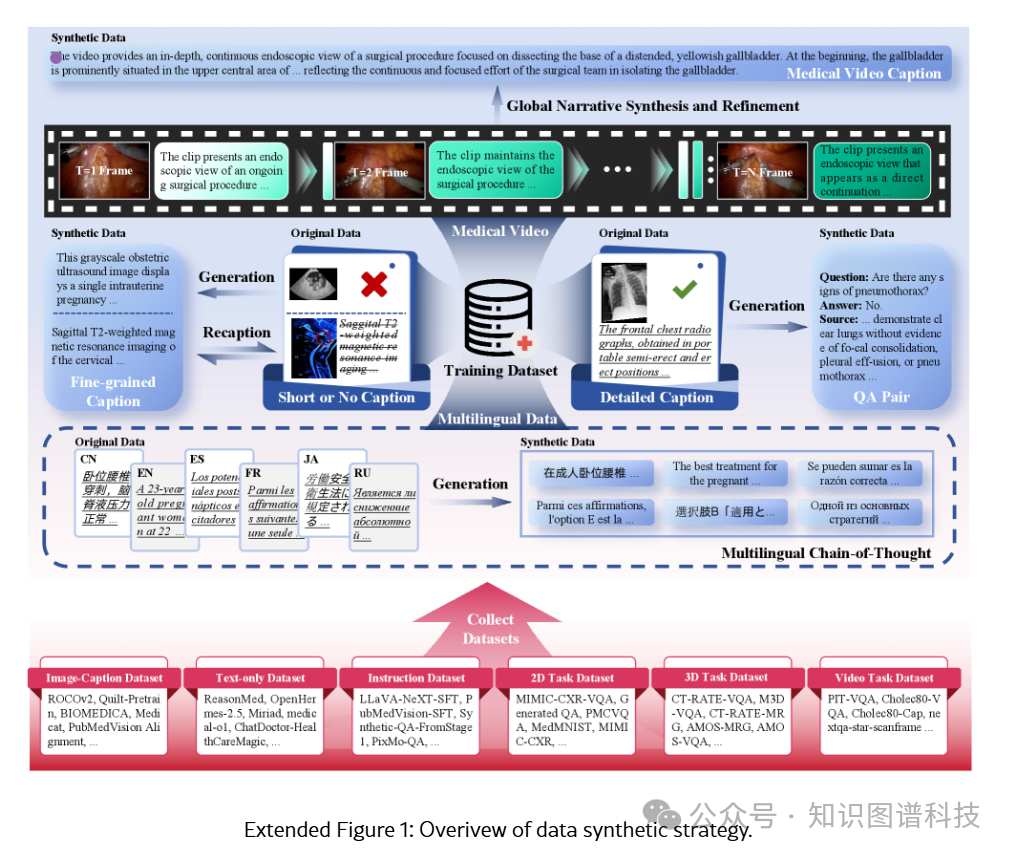
生成的合成数据在Hulu-Med的多阶段训练中发挥了关键作用。
四、性能评估:全面领先
4.1 评估协议
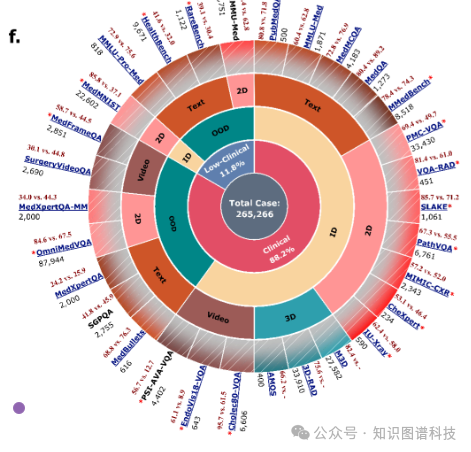
我们对Hulu-Med进行了跨30个不同基准的全面评估,涵盖语言、2D和3D图像以及视频模态,严格评估分布内(ID)和分布外(OOD)任务以评估泛化能力。
我们的比较包括46个最先进的模型:
- 领先的专有系统
:GPT-4.1、Claude Sonnet 4、Gemini-2.5-Flash
- 大规模通用VLM
:Qwen2.5VL-7B/72B、InternVL3-8B/38B
- 医学通用VLM
:Lingshu-7B/32B、MedGemma-4B、HuatuoGPT-V-7B/34B
- 专业医学基础模型
:M3D系列、RadFM、Surgical-LLaVA
4.2 2D医学视觉-语言理解
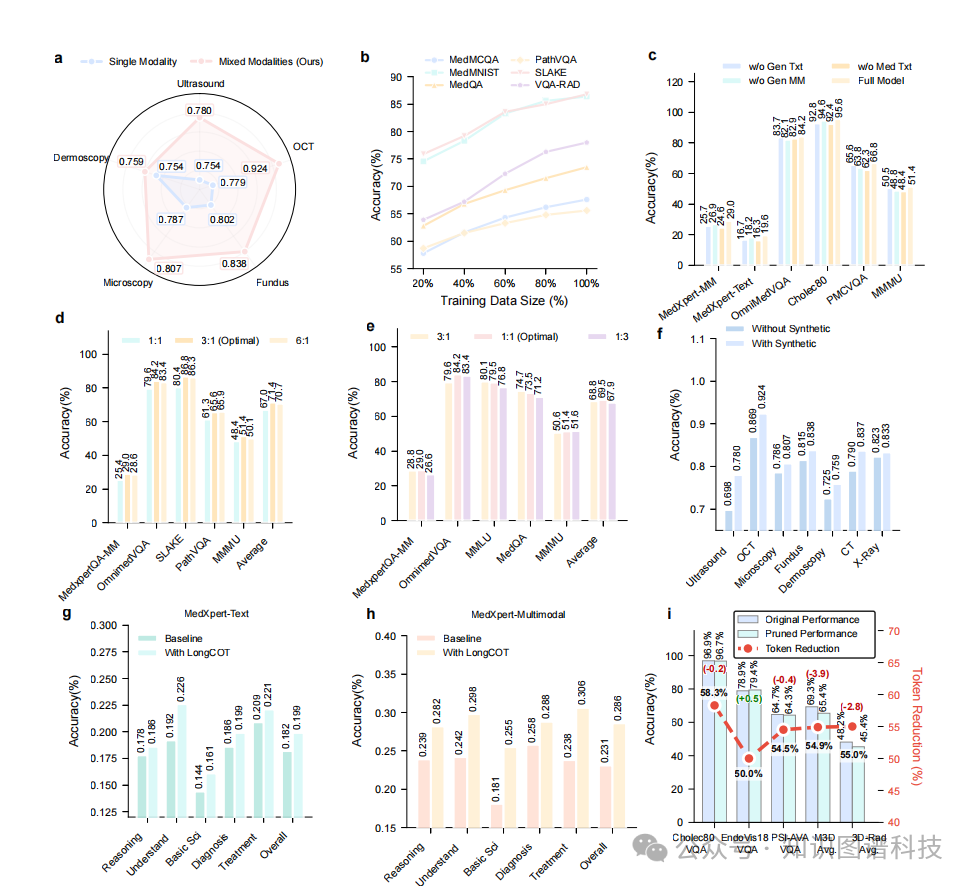
我们系统地评估了Hulu-Med在11个已建立基准上的2D医学图像理解能力,包括7个医学VQA数据集、3个医学报告生成(MRG)基准和MedMNIST分类任务。在这些基准中,Hulu-Med在11个基准中的10个超越了所有开源模型(医学或通用),同时在8个基准上也超越了领先的专有模型。
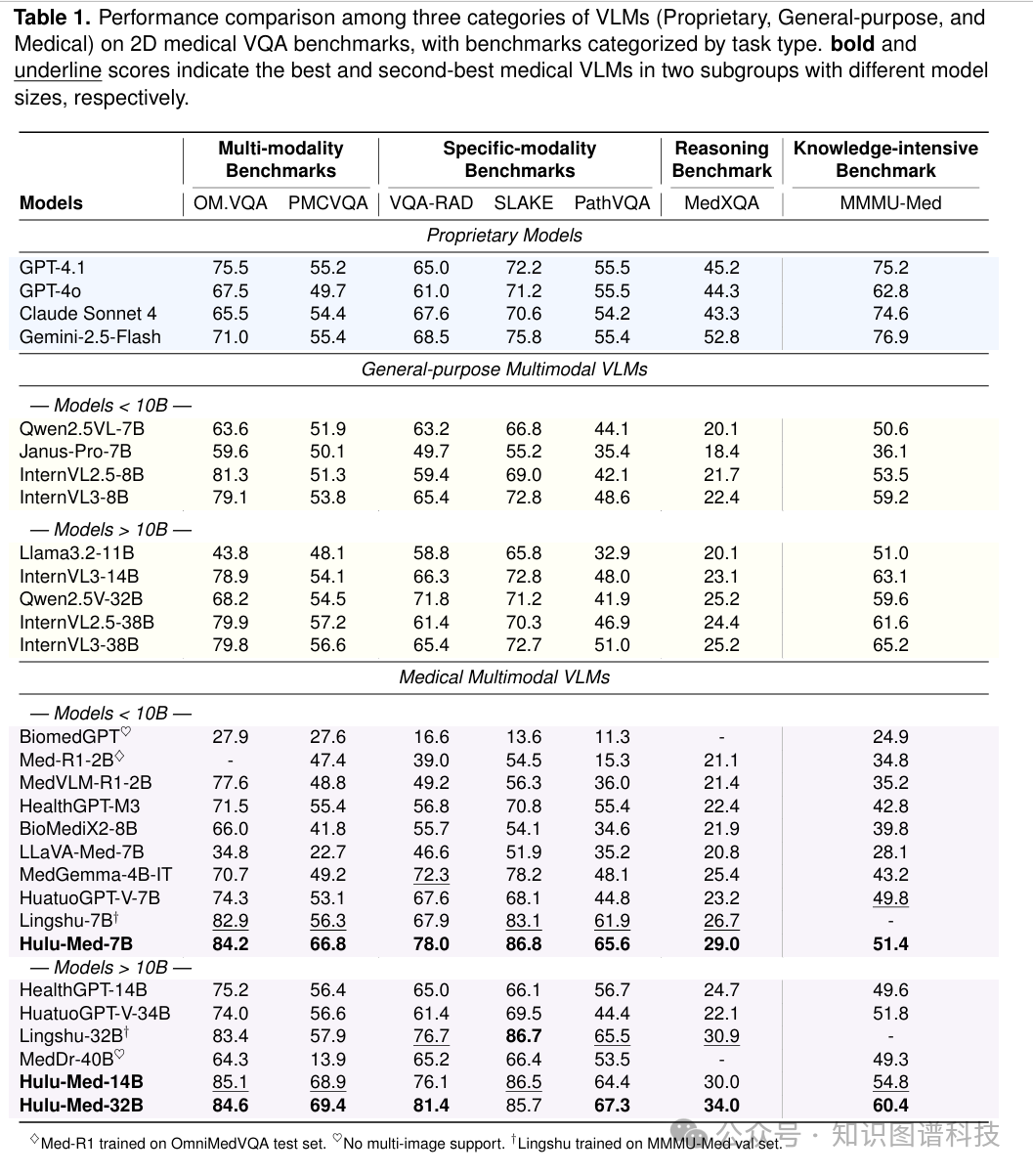
4.2.1 视觉问答(VQA)任务
VQA套件包括:
- 多模态理解
:OmniMedVQA、PMC-VQA
- 特定模态推理
:VQA-RAD、SLAKE、PathVQA
- 高级临床推理
:MedXQA
- 知识密集型任务
:MMMU-Med
Hulu-Med-7B/32B在多模态理解和特定模态推理基准上创造了新的最先进性能,跨越ID和OOD任务。
在MedXQA上,Hulu-Med-7B/32B超越了所有可比规模的开源VLM(低于和高于10B参数),尽管仍落后于专有模型(例如,Hulu-Med-32B的34%对比GPT-4.1的45.2%)。我们将这一性能差距主要归因于MedXQA基于文本的推理需求,这有利于具有更强大LLM的模型。
4.2.2 医学报告生成(MRG)
我们在三个标准基准上评估了Hulu-Med——MIMIC-CXR、CheXpert和IU X-ray——使用传统的自然语言指标(BLEU、ROUGE、METEOR)和面向临床的RaTEScore。
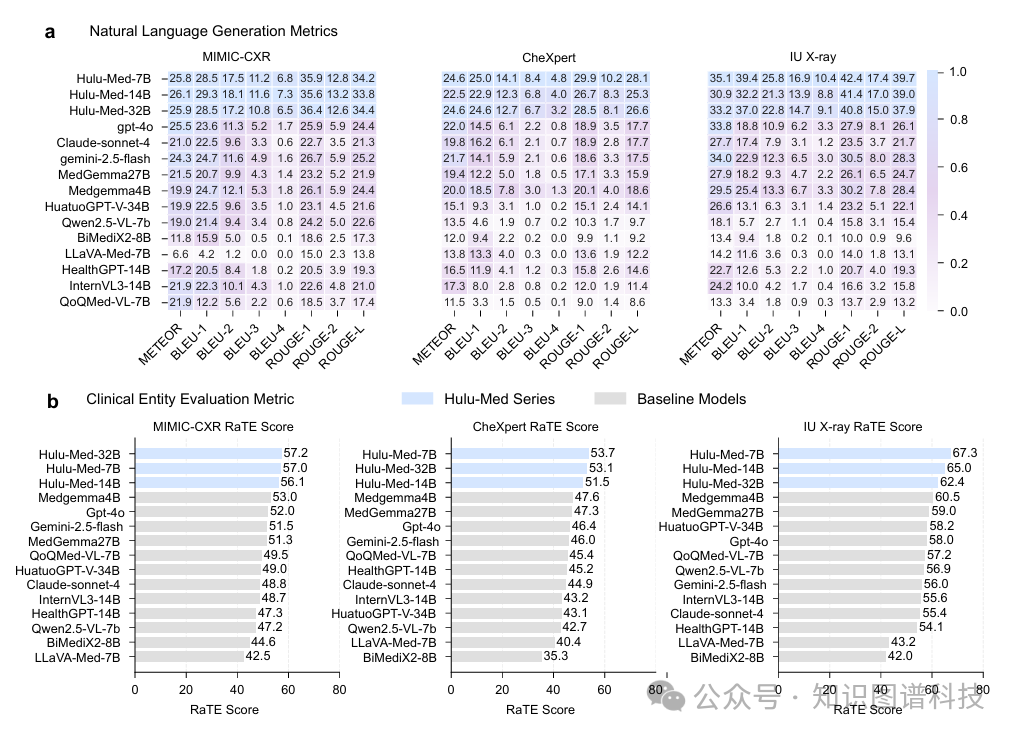
所有Hulu-Med变体都创造了新的最先进结果。值得注意的是,Hulu-Med-7B在MIMIC-CXR上达到了57.0的RaTEScore,大幅超越MedGemma-4B/27B(RaTEScore 51.3)。 这一改进具有临床意义,因为经过认证的放射科医生评估,MedGemma的分数对应于81%的报告导致相同或更优的临床决策。
有趣的是,我们的结果进一步揭示,更大的模型规模并不保证MRG性能的提升:Hulu-Med-7B偶尔超越其32B对应版本,这与MedGemma观察到的趋势相呼应。这强调了领域特定预训练对于MRG等专业任务的重要性。
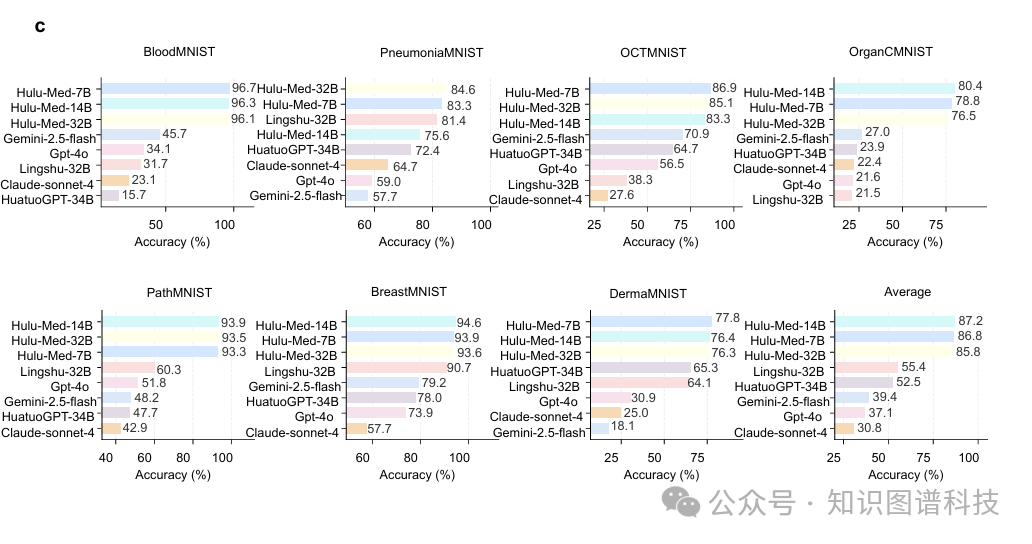
4.2.3 MedMNIST-2D分类
Hulu-Med在MedMNIST-2D基准上进一步验证了2D医学图像理解能力,该基准跨越7个不同领域。Hulu-Med达到了超过85%的领先平均准确率,远远超越所有基线——包括GPT-4o等专有模型(准确率低于40%)。
4.3 3D医学视觉-语言理解
我们系统地评估了Hulu-Med在VQA和MRG基准上的3D医学图像理解能力,包括M3D、3D-RAD和AMOS-MM。
4.3.1 3D VQA任务
在3D VQA任务上,Hulu-Med在开放式和封闭式问答方面都实现了最先进的性能。
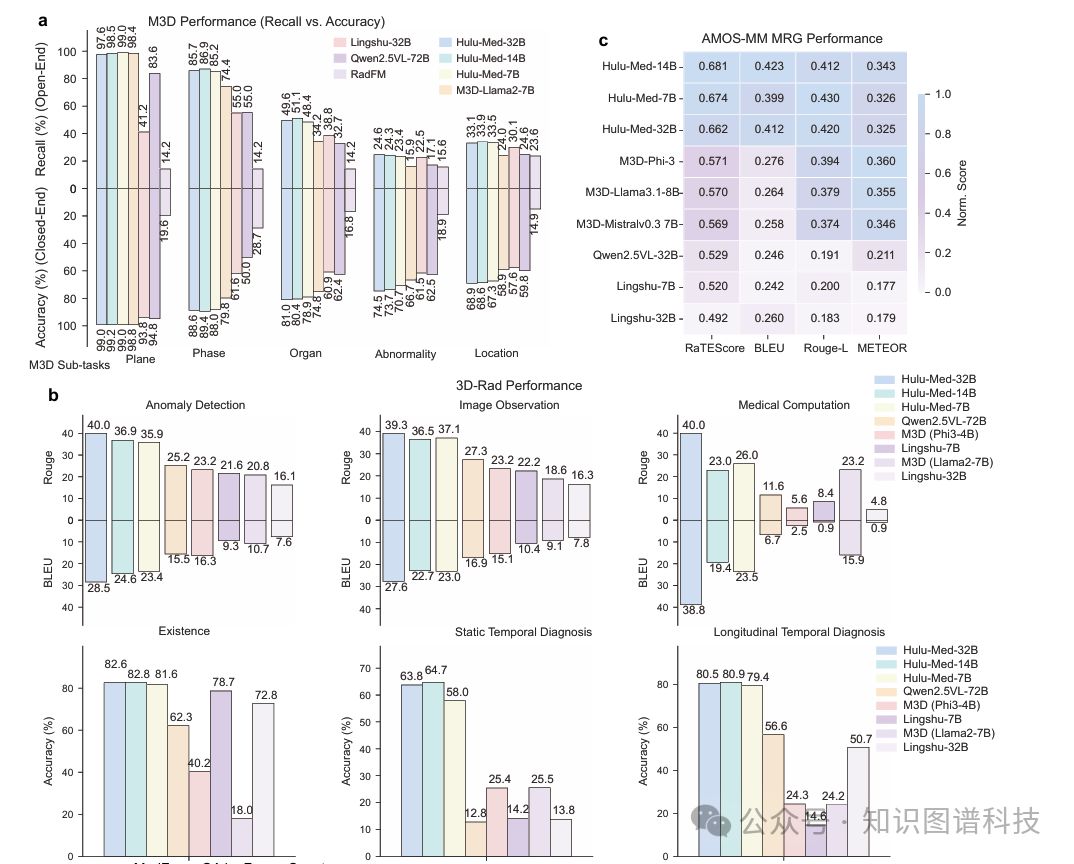
在M3D基准(评估解剖理解)上,Hulu-Med超越了所有专业3D模型和通用VLM。Hulu-Med在3D-RAD基准的复杂3D推理任务上进一步表现出色。
性能优势在需要多步推理的挑战性任务上尤为明显,例如涉及生物标志物特征(例如大小、厚度和形状)的问题以及静态/纵向时间诊断。Hulu-Med-7B在纵向时间诊断任务上超越最佳基线22.8%——这是一项需要全面理解多个时间点疾病进展的任务。
4.3.2 3D医学报告生成
对于AMOS-MM基准上的3D MRG任务,所有Hulu-Med变体在传统自然语言生成指标(BLEU、ROUGE-L)上展现出领先性能,并在面向临床的RaTEScore上表现出明显优势,强调了模型从体积扫描生成全面且临床准确的放射学报告的能力。
4.4 医学视频理解
我们在多帧时间推理和手术视频分析上评估了Hulu-Med变体。
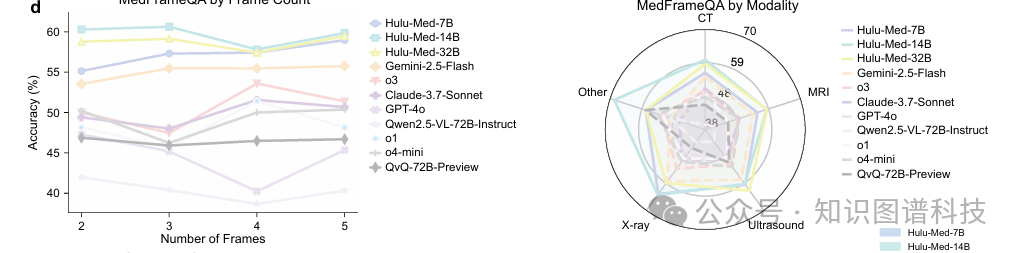
4.4.1 多帧时间推理
对于多帧时间推理,我们在MedFrameQA上评估零样本性能——即没有任何任务特定的训练或微调。在这种OOD设置下,Hulu-Med显著超越了原始研究中报告的领先专有模型,随着帧数增加实现了更高的准确率和更低的方差。
这种在不断增长的时间复杂性下的稳定性凸显了Hulu-Med强大的时间推理能力。雷达图进一步展示了Hulu-Med跨模态的统一理解能力。
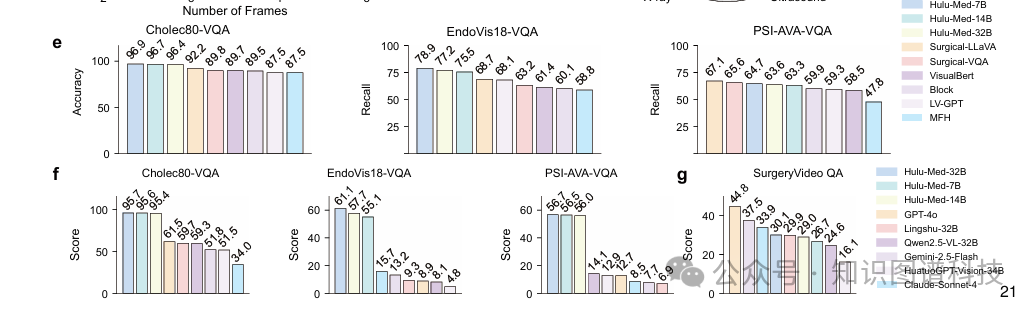
4.4.2 专业手术视频分析
在专业手术视频基准测试中——包括Cholec80-VQA、EndoVis18-VQA和PSI-AVA-VQA——我们将Hulu-Med与专有系统、通用和医学VLM以及手术视频基础模型进行了对比。
Hulu-Med在Cholec80-VQA和EndoVis18-VQA上的准确率和召回率均超越了视频基础模型,并在PSI-AVA-VQA上提供了竞争性结果——尽管一些基线模型是专门为视频数据定制的。 对于缺乏报告定量指标的VLM基线,我们使用ChatGPT-4o-latest作为自动评判,结果显示Hulu-Med在三个基准测试中始终超越所有基线。
4.4.3 教育视频理解的OOD挑战
此外,SurgeryVideoQA呈现了一个独特的OOD挑战,该数据集来自教育视频内容,整合了医学图像、图表和叙述性解释——与传统手术录像不同。
在这个挑战性基准上,Hulu-Med-32B领先所有开源模型,达到30.1%的分数,超越了其他专业医学VLM如Lingshu-32B(29.9%),而专有模型如GPT-4o达到了最高分44.8%。
总体而言,Hulu-Med在这个复杂的、以教育为重点的基准测试中展现出竞争性表现,同时在专业手术视频分析方面保持了强大优势。这些结果证明了统一架构在处理从实时手术场景到结构化教育内容等多样化视频任务方面的有效性。
五、纯文本医学推理:超越视觉的卓越表现
5.1 标准医学基准测试
我们在八个医学文本理解基准上评估了Hulu-Med,评估其在复杂推理、文本理解和医学考试方面的能力。 此外,我们还在具有挑战性的现实世界任务上评估了模型的泛化能力,包括多语言推理(MMedBench)、罕见病诊断(RareBench)和真实临床对话(HealthBench)。
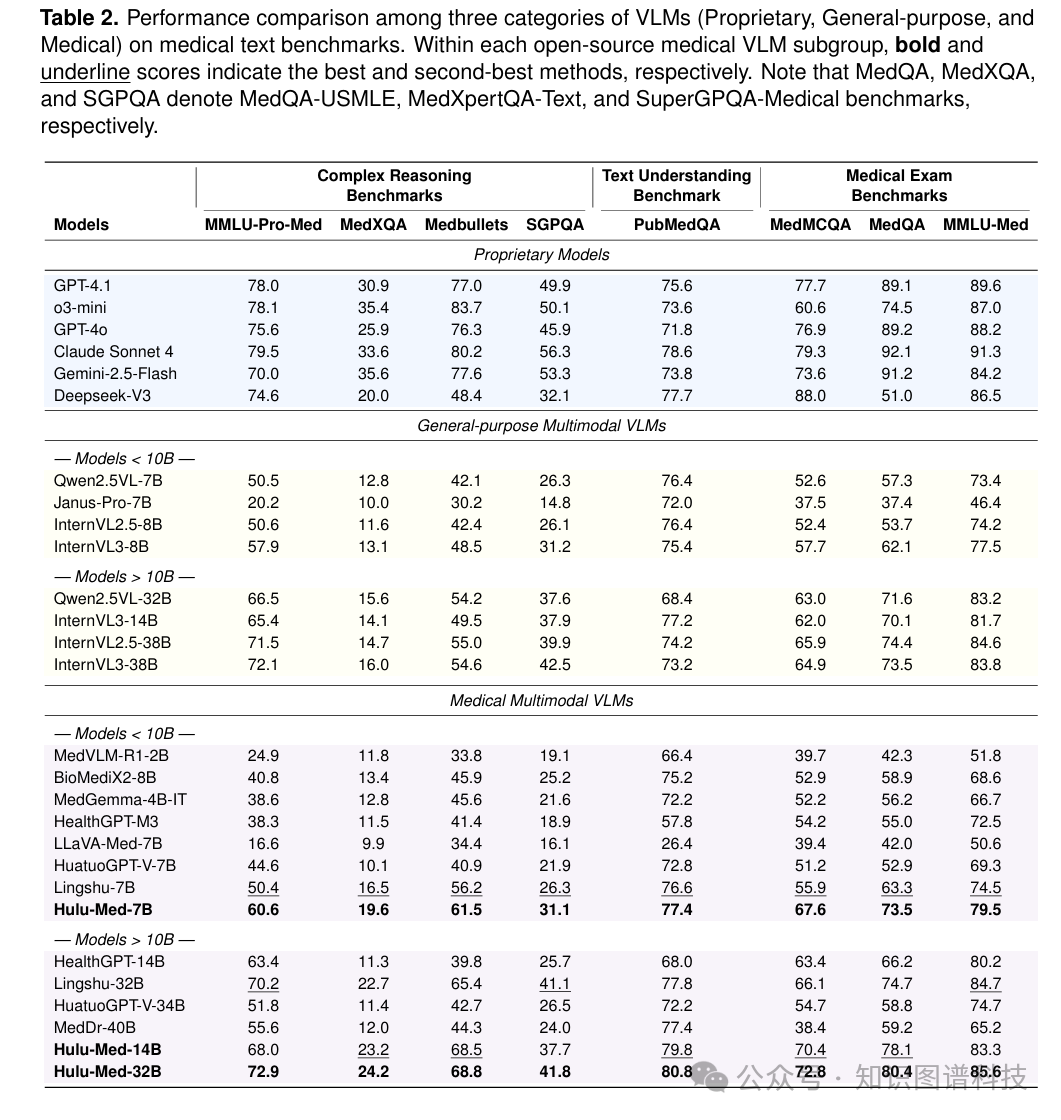
5.1.1 开源模型中的最先进性能
Hulu-Med相比之前的开源系统实现了显著提升。与Lingshu-7B(10B参数以下最强的医学VLM基线)相比,Hulu-Med-7B在MMLU-Pro-Med上提升10.2分,MedXQA上提升3.1分,Medbullets上提升5.3分,SGPQA上提升4.8分,MedMCQA上提升11.7分,MedQA上提升10.2分,MMLU-Med上提升5.0分。
对于更大的模型,Hulu-Med-32B同样超越Lingshu-32B,在MMLU-Pro-Med上提升2.7分,Medbullets上提升3.4分,MedMCQA上提升6.7分,MedQA上提升5.7分。
值得注意的是,Hulu-Med即使与更大的开源模型相比也具有竞争力:Hulu-Med-7B达到58.9%的平均准确率,超越InternVL3-8B(52.9%)6.0个百分点,而Hulu-Med-32B达到65.9%,超越InternVL3-38B(60.1%)5.8个百分点。 对三次独立运行的统计测试证实了这些改进;Hulu-Med在七个基准测试上表现出卓越性能(p < 0.001)。
5.1.2 与专有模型的竞争力
Hulu-Med-32B在PubMedQA上达到最先进性能,超越包括Claude Sonnet 4、DeepSeek-V3、GPT-4.1和Gemini 2.5 Flash在内的专有系统。 这种在生物医学文献理解方面的优势可能反映了在持续预训练中使用的大量PubMed内容。
在MMLU-Pro-Med等复杂推理基准上,Hulu-Med-32B超越了Gemini 2.5 Flash,并大幅缩小了与顶级模型(包括Claude Sonnet 4和GPT-4.1)的差距。 更广泛地说,Hulu-Med-32B在八个基准测试中的平均准确率为65.9%,超越DeepSeek-V3(59.8%)6.1个百分点,并在2.0个百分点内接近o3-mini(67.9%),总体上展现出与专有系统的竞争性表现。
六、结论
Hulu-Med展示了医疗视觉-语言模型在实现全面、统一和透明的多模态理解方面的突破性进展。通过创新的架构设计和系统化的数据整合,该模型解决了当前医疗AI领域面临的核心挑战:模态分离、数据不透明和计算效率低下的问题。
我们的全面评估表明,统一架构在30个公共基准测试中的27个上超越了现有开源模型,并在16个基准上优于GPT-4o等专有系统 。Hulu-Med首次实现了在单一架构中原生处理文本、2D图像、3D体积和视频的能力,彻底解决了医疗AI领域长期存在的模态融合挑战 。通过医学感知的token减少策略,模型成功减少了高达55%的3D和视频输入冗余,显著提升了跨模态处理效率 。
值得强调的是,Hulu-Med完全基于1670万个公开数据样本和透明的工作流程开发,涵盖12个主要解剖系统和14种医学影像模式 。这种完全透明的开发方式有效缓解了专有系统中固有的隐私和版权问题,为构建可信赖、可定制的医疗AI模型提供了重要范例 。我们公开发布所有数据管道、训练代码和模型参数,确保完全可重复性,为临床应用建立了可信赖的基础 。
然而,我们认识到Hulu-Med仍是一个研究性基础模型,而非即刻可用的临床决策工具。它的核心价值在于证明了系统地整合公共数据是实现最先进医学VLM的可行途径,为开放科学和可重复研究树立了典范 。未来的关键方向包括整合基因组和分子数据以实现真正的多尺度疾病理解、利用大规模强化学习增强临床推理能力,以及通过专科模型集成和多智能体系统进行更严格的临床验证 。
随着医疗AI技术的不断演进和与临床专业知识的深度融合,我们期待Hulu-Med为构建更安全、更有效、更以患者为中心的智能医疗系统铺平道路,最终推动精准医疗和个性化诊疗的实现。
欢迎加入「知识图谱增强大模型产学研」知识星球,获取最新产学研相关"知识图谱+大模型"相关论文、政府企业落地案例、避坑指南、电子书、文章等,行业重点是医疗护理、医药大健康、工业能源制造领域,也会跟踪AI4S科学研究相关内容,以及Palantir、OpenAI、微软、Writer、Glean、OpenEvidence等相关公司进展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)