python学习第四天(函数)
参数类型定义时语法调用时语法内部接收类型核心作用默认参数f(10)或f(10, 20)普通变量为参数提供默认值,简化调用可变位置参数元组 (tuple)接收任意数量的位置参数可变关键字参数字典 (dict)接收任意数量的关键字参数# 模块中的主程序入口# 当模块被直接运行时,执行以下代码main() # 例如调用主函数print("测试代码执行...")优点使模块具有 “双重身份”,增强代码的复用
函数的创建
定义函数指创建一个新的函数
调用函数指使用这个函数
def 函数名(参数):
代码块
return 返回值1.def是保留字,表示创建一个函数
2.函数名表示被定义的函数的名称,函数名可以由用户任意指定,但要遵守命名规则。
3.参数表示该函数可以接收到的数据
5.return用于将函数执行后的数据返回给调用函数
函数的调用
使用形式
函数名(参数)如果先写调用函数再写定义函数,代码程序将无法运行
函数的复用
函数的复用指的是在编程中,编写一个函数后,可以在程序的多个地方重复使用它,而不需要每次都重新编写相同的代码。
# 定义一个加法函数
def add(a, b):
"""返回两个数的和"""
return a + b
# 第一次使用:计算 10 和 20 的和
result1 = add(10, 20)
print(f"10 + 20 = {result1}") # 输出: 10 + 20 = 30
# 第二次使用:计算 5.5 和 3.3 的和
result2 = add(5.5, 3.3)
print(f"5.5 + 3.3 = {result2}") # 输出: 5.5 + 3.3 = 8.8
# 第三次使用:计算两个变量的和
x = 100
y = 200
result3 = add(x, y)
print(f"{x} + {y} = {result3}") # 输出: 100 + 200 = 300
# 第四次使用:在另一个表达式中使用
total = add(1, 2) + add(3, 4)
print(f"Total: {total}") # 输出: Total: 10return返回值
return语句用于将函数中的数据返回给调用函数
示例 1:返回一个计算结果
def add(a, b):
return a + b # 返回 a 和 b 的和
result = add(3, 5)
print(result) # 输出: 8
示例 2:返回一个布尔值
def is_even(n):
return n % 2 == 0 # 如果 n 是偶数,返回 True,否则返回 False
print(is_even(4)) # 输出: True
print(is_even(7)) # 输出: False
示例 3:提前返回(终止函数执行)
def check_age(age):
if age < 18:
return "未成年,禁止访问" # 提前返回,后面的代码不会执行
return "成年,允许访问"
message = check_age(16)
print(message) # 输出: 未成年,禁止访问
示例 4:返回多个值
会以元组形式返回
def get_user_info():
name = "Alice"
age = 25
return name, age # 本质上是返回一个元组 (name, age)
username, userage = get_user_info()
print(username) # 输出: Alice
print(userage) # 输出: 25
示例 5:没有显式返回值(默认返回 None)
def greet(name):
print(f"Hello, {name}!") # 没有 return 语句
result = greet("Bob")
print(result) # 输出: None
核心要点
return可返回任意类型的值(数字、字符串、列表、字典等)。- 函数中可以有多个
return,但只有第一个被执行的return会生效(后续代码终止)。 - 若函数没有显式写
return,默认返回None。
函数的参数
形参和实参
def 函数名(形参1,形参2,...):
代码块
return 返回值
函数名(实参1,实参2,...)1. 默认参数 (Default Arguments)
定义:在定义函数时,可以为参数指定一个默认值。当调用函数时,如果没有为这个参数提供值,它就会自动使用这个默认值。
语法:
def function_name(param1, param2=default_value):
# 函数体
示例:
def greet(name, message="Hello"):
print(f"{message}, {name}!")
# 只提供必须的参数
greet("Alice") # 输出: Hello, Alice!
# 提供所有参数,覆盖默认值
greet("Bob", "Good morning") # 输出: Good morning, Bob!
注意:带默认值的参数必须放在没有默认值的参数后面。
2. 可变参数 (Variable-length Arguments)
定义:当你不确定函数会接收多少个位置参数时,可以使用可变参数。它会将所有多余的位置参数收集到一个 ** 元组(tuple)** 中。
语法:
def function_name(*args):
# 函数体,args 是一个元组
示例:
def add_all(*args):
total = 0
for num in args:
total += num
return total
# 可以传入任意数量的参数
sum1 = add_all(1, 2, 3)
sum2 = add_all(10, 20, 30, 40, 50)
sum3 = add_all() # 也可以不传入参数,args 为空元组
print(sum1) # 输出: 6
print(sum2) # 输出: 150
print(sum3) # 输出: 0
*args 可以和普通参数一起使用,但必须放在普通参数后面。
3. 关键字参数 (Keyword Arguments)
定义:当调用函数时,你可以通过 关键字=值 的形式指定参数的名称,这样就不需要按照函数定义的顺序来传递参数了。
语法(调用时):
function_name(param1=value1, param2=value2)
示例:
def describe_pet(animal_type, pet_name):
print(f"I have a {animal_type} named {pet_name}.")
# 按照位置传递参数
describe_pet("dog", "Buddy") # 输出: I have a dog named Buddy.
# 使用关键字传递参数,顺序可以随意调换
describe_pet(pet_name="Mittens", animal_type="cat") # 输出: I have a cat named Mittens.
3.1 可变关键字参数 (Arbitrary Keyword Arguments)
定义:当你不确定函数会接收多少个关键字参数时,可以使用它。它会将所有多余的关键字参数收集到一个 ** 字典(dict)** 中。
语法:
def function_name(**kwargs):
# 函数体,kwargs 是一个字典
示例:
def build_profile(first_name, last_name, **kwargs):
profile = {"first": first_name, "last": last_name}
profile.update(kwargs) # 将 kwargs 中的内容更新到 profile 字典中
return profile
user_profile = build_profile(
"Albert",
"Einstein",
location="Princeton",
field="Physics"
)
print(user_profile)
# 输出: {'first': 'Albert', 'last': 'Einstein', 'location': 'Princeton', 'field': 'Physics'}
总结对比
| 参数类型 | 定义时语法 | 调用时语法 | 内部接收类型 | 核心作用 |
|---|---|---|---|---|
| 默认参数 | def f(a, b=5): |
f(10) 或 f(10, 20) |
普通变量 | 为参数提供默认值,简化调用 |
| 可变位置参数 | def f(*args): |
f(1, 2, 3, 4) |
元组 (tuple) | 接收任意数量的位置参数 |
| 可变关键字参数 | def f(**kwargs): |
f(x=1, y=2, z=3) |
字典 (dict) | 接收任意数量的关键字参数 |
函数的变量作用范围
函数的变量作用范围(Scope)指的是变量在程序中可以被访问的区域。主要分为局部变量和全局变量,某些语言还支持嵌套作用域(如 Python、JavaScript)。
在函数中使用全局变量且对全局变量赋值时,将会重新在函数内部创建一个新的局部变量,而不是直接使用全局变量,函数内部的变量和函数外部的变量只是名称相同,实际上并不是同一个变量
一、局部变量(Local Variable)
- 定义:在函数内部声明的变量,仅在函数内部可见和访问。
- 生命周期:从函数调用开始创建,函数执行结束后销毁。
- 示例(Python):
def func(): x = 10 # 局部变量,仅在 func 内部可用 print(x) # 输出:10 func() print(x) # 报错:NameError: name \'x\' is not defined(外部无法访问)
二、全局变量(Global Variable)
- 定义:在函数外部声明的变量,可在整个程序(包括多个函数)中访问。
- 注意:函数内部若要修改全局变量,需用
global关键字声明(否则会被当作局部变量重新定义)。 - 示例(Python):
x = 100 # 全局变量 def func1(): print(x) # 函数内部可直接访问全局变量(读取),输出:100 def func2(): global x # 声明要修改的是全局变量 x = 200 # 修改全局变量的值 func1() func2() print(x) # 输出:200(全局变量已被修改)
三、嵌套作用域(Enclosing Scope)
- 定义:在嵌套函数(函数内部再定义函数)中,内层函数可以访问外层函数的变量(非全局、非局部),外层变量称为 “自由变量”。
- 注意:内层函数若要修改外层变量,需用
nonlocal关键字声明(Python 特有)。 - 示例(Python):
def outer(): x = 10 # 外层函数的变量(嵌套作用域变量) def inner(): nonlocal x # 声明要修改的是外层函数的变量 x = 20 # 修改外层变量 print(x) # 输出:20 inner() print(x) # 输出:20(外层变量已被内层修改) outer()
核心规则(就近原则)
变量访问时,会优先在当前作用域查找,若找不到则向上一层作用域查找,直到全局作用域;若全局作用域仍找不到,则报错。
- 局部作用域 → 嵌套作用域(若有) → 全局作用域
变量为可变数据
在python中根据是否会改变内存恐慌可将数据分为可变数据和不可变数据,其中可变数据是指数据变化后不会改变内存空间。
当可变数据为全局变量时,在函数中对可变数据进行修改回改变全局变量
id()函数可以获取变量数据值所在的内存空间编号
id() 函数用于获取对象的唯一标识符,这个标识符是一个整数,可以理解为该对象在计算机内存中的地址。
语法
id(object)
- 参数:
object,可以是任何 Python 对象(整数、字符串、列表、字典等)。 - 返回值:一个整数,表示对象的唯一 ID。
核心特点
- 唯一性:在同一个程序运行期间,每个对象的 ID 都是唯一的,不同对象的 ID 不会重复。
- 暂时性:对象被销毁后,其 ID 可能会被后续创建的对象复用(但在同一时间点不会重复)。
- 与内存地址的关系:ID 本质上是对象在内存中的地址(对于 CPython 解释器,
id()直接返回对象的内存地址)。
示例代码
1. 基本类型对象的 ID
# 整数对象
a = 10
b = 10
print(id(a)) # 输出:140707243256848(具体值因系统和运行时而异)
print(id(b)) # 输出:140707243256848(与 a 相同,因为小整数会被缓存)
# 字符串对象
s1 = "hello"
s2 = "hello"
print(id(s1)) # 输出:140707243182768
print(id(s2)) # 输出:140707243182768(字符串常量池优化,相同字符串复用)
# 列表对象(可变类型)
lst1 = [1, 2, 3]
lst2 = [1, 2, 3]
print(id(lst1)) # 输出:140707243054592
print(id(lst2)) # 输出:140707243054720(不同对象,ID 不同)
2. 变量赋值与 ID 变化
x = [1, 2, 3]
print(id(x)) # 输出:140707243054848
# 变量 x 重新赋值为新列表
x = [4, 5, 6]
print(id(x)) # 输出:140707243054976(ID 改变,指向新对象)
# 变量引用传递
y = x
print(id(y)) # 输出:140707243054976(与 x 相同,指向同一个对象)
3. 函数参数传递与 ID
def func(obj):
print("函数内对象 ID:", id(obj))
lst = [1, 2, 3]
print("函数外对象 ID:", id(lst)) # 输出:140707243055104
func(lst) # 输出:函数内对象 ID:140707243055104(传递的是对象引用,ID 相同)
导入其它模块中的函数
在 Python 中,模块导入主要有以下几种方式,以 module_name.py 文件为例,其内容如下:
# module_name.py
def func1():
return "函数1"
def func2():
return "函数2"
variable = "模块变量"
1. 导入整个模块
语法:
import module_name
使用:通过 模块名.函数名/模块名.变量名 访问。
示例:
import module_name
print(module_name.func1()) # 输出:函数1
print(module_name.variable) # 输出:模块变量
2. 导入模块中的指定函数 / 变量
语法:
from module_name import func1, func2, variable
使用:直接使用函数名 / 变量名,无需加模块前缀。
示例:
from module_name import func1, variable
print(func1()) # 输出:函数1
print(variable) # 输出:模块变量
# print(func2()) # 报错:未导入
3. 导入模块中的全部函数 / 变量(不推荐)
语法:
from module_name import *
使用:直接使用所有函数和变量,但可能导致命名冲突。
示例:
from module_name import *
print(func1()) # 输出:函数1
print(func2()) # 输出:函数2
print(variable) # 输出:模块变量
缺点:
- 污染当前命名空间,可能覆盖已有变量 / 函数。
- 可读性差,无法清晰区分来源。
4. 导入模块并指定别名(推荐)
语法:
import module_name as mn
from module_name import func1 as f1
示例:
import module_name as mn
print(mn.func1()) # 输出:函数1
from module_name import func2 as f2
print(f2()) # 输出:函数2
优点:
- 简化代码,避免长模块名重复输入。
- 解决命名冲突。
__name__属性
在 Python 中,__name__ 是一个内置变量,用于表示当前模块的名称。它的核心作用是判断模块是 “被直接运行” 还是 “被导入到其他模块中运行”。
1. __name__ 的两种取值
- 当模块被直接运行时,
__name__的值为"__main__"。 - 当模块被导入到其他模块时,
__name__的值为模块本身的名称(即文件名,不带.py后缀)。
2. 示例说明
假设有两个文件:
module_a.pymodule_b.py
示例 1:模块被直接运行
module_a.py
print(f"模块 module_a 的 __name__ 值为: {__name__}")
if __name__ == "__main__":
print("模块 module_a 被直接运行了!")
else:
print("模块 module_a 被导入到其他模块中了。")
运行 module_a.py 的输出:
plaintext
模块 module_a 的 __name__ 值为: __main__
模块 module_a 被直接运行了!
示例 2:模块被导入
module_b.py
# 导入 module_a
import module_a
print(f"\n模块 module_b 的 __name__ 值为: {__name__}")
运行 module_b.py 的输出:
plaintext
模块 module_a 的 __name__ 值为: module_a
模块 module_a 被导入到其他模块中了。
模块 module_b 的 __name__ 值为: __main__
3. 核心作用
__name__ 的主要用途是让模块既可以独立运行(作为脚本),又可以被其他模块导入(作为工具模块)。
典型场景:
- 在模块中编写测试代码,只有当模块被直接运行时才执行测试。
- 避免模块中的代码在被导入时自动执行(只在直接运行时执行)。
4. 常见用法总结
# 模块中的主程序入口
if __name__ == "__main__":
# 当模块被直接运行时,执行以下代码
main() # 例如调用主函数
print("测试代码执行...")
优点:
- 使模块具有 “双重身份”,增强代码的复用性和灵活性。
- 分离 “库代码” 和 “测试 / 演示代码”,保持模块的整洁。
函数的递归
函数递归是指函数在执行过程中调用自身的编程技巧,用于将复杂问题分解为规模更小的同类子问题,直到达到可直接求解的 “基线条件”(终止条件),再逐层返回结果,最终得到原问题的解。
一、递归的核心要素(必须满足)
- 基线条件(Base Case):递归终止的条件,当问题规模缩小到此时,直接返回结果,避免无限递归(导致栈溢出)。
- 递归步骤(Recursive Step):将原问题分解为规模更小的同类子问题,通过调用自身求解子问题,再组合子问题的结果得到原问题的解。
二、经典示例(简洁版)
示例 1:计算 n 的阶乘(n!)
- 定义:n! = n × (n-1) × (n-2) × ... × 1,且 0! = 1(基线条件)。
- 递归逻辑:n! = n × (n-1)!(将 n! 分解为 n 和 (n-1)! 的乘积,子问题规模更小)。
def factorial(n):
# 基线条件:n=0 或 n=1 时,直接返回 1
if n in (0, 1):
return 1
# 递归步骤:n! = n × (n-1)!
return n * factorial(n - 1)
# 测试
print(factorial(5)) # 输出:120(5×4×3×2×1)
示例 2:斐波那契数列(第 n 项)
- 定义:斐波那契数列前两项为 0、1,后续每项 = 前两项之和(F (n) = F (n-1) + F (n-2))。
- 基线条件:F(0)=0,F(1)=1。
def fibonacci(n):
# 基线条件:n=0 返回 0,n=1 返回 1
if n == 0:
return 0
elif n == 1:
return 1
# 递归步骤:F(n) = F(n-1) + F(n-2)
return fibonacci(n - 1) + fibonacci(n - 2)
# 测试
print(fibonacci(6)) # 输出:8(数列:0,1,1,2,3,5,8)
示例 3:计算列表元素之和(递归实现)
- 基线条件:列表为空时,和为 0。
- 递归步骤:列表和 = 第一个元素 + 剩余元素的和(子问题:规模减 1 的列表)。
def list_sum(lst):
# 基线条件:空列表和为 0
if not lst:
return 0
# 递归步骤:第一个元素 + 剩余列表的和
return lst[0] + list_sum(lst[1:])
# 测试
print(list_sum([1, 2, 3, 4])) # 输出:10(1+2+3+4)
三、递归的优缺点
优点:
- 代码简洁直观,能自然表达分治思想(如斐波那契、阶乘等数学问题)。
- 无需手动编写循环,减少代码冗余。
缺点:
- 递归调用会创建新的函数栈帧,若递归深度过大(如 n=10000 的阶乘),会导致 栈溢出(RecursionError)。
- 部分场景存在重复计算(如斐波那契数列的递归实现,会多次计算 F (n-2)、F (n-3) 等),效率较低(可通过 memoization 优化)。
匿名函数lambda
函数名 = lambda 参数:函数内代码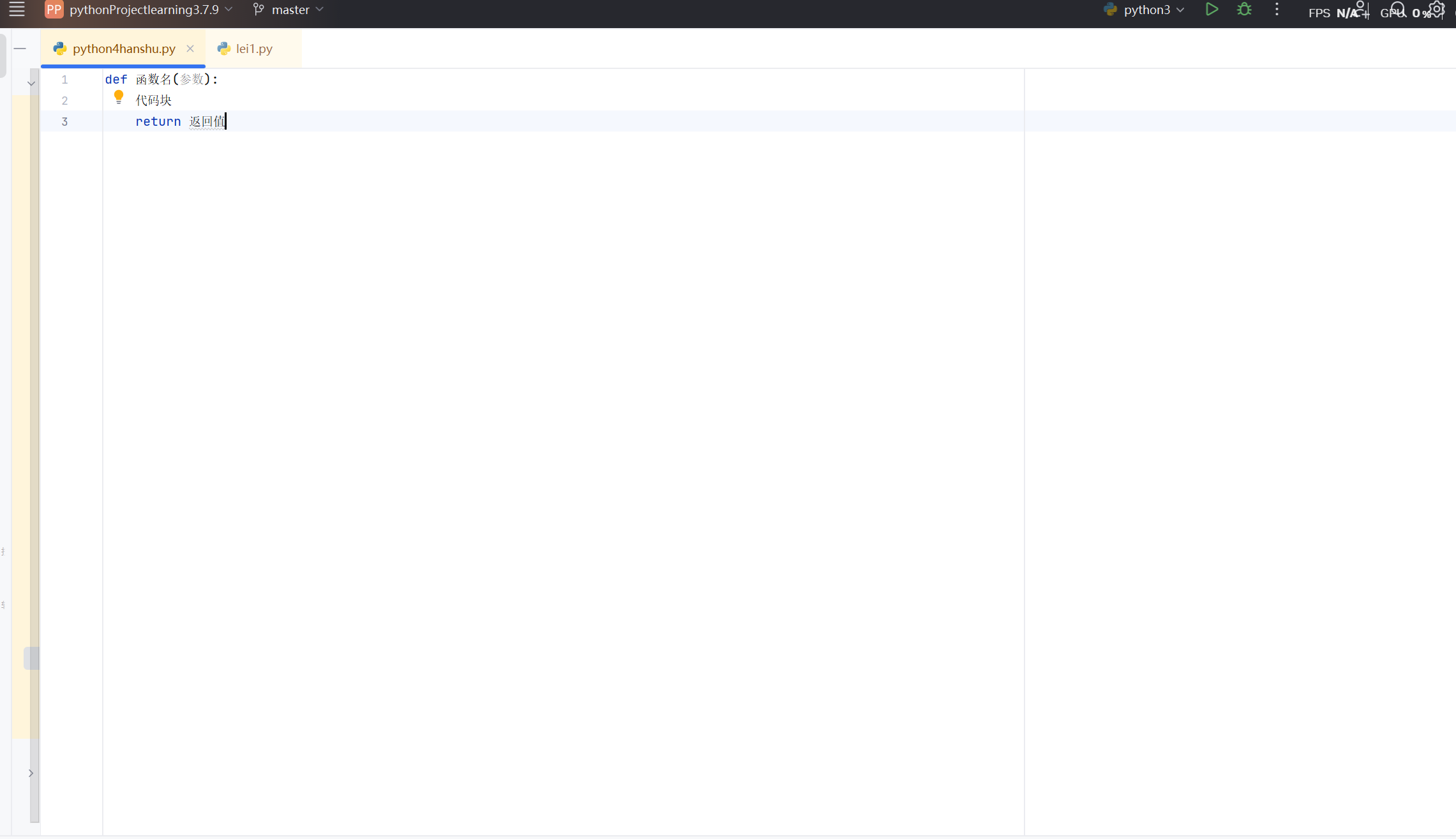
等效为
def fun1(x,y):
return y+x
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 41
41 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)