手把手教你将神经网络部署到STM32:从模型训练到STM32CubeMX X-Cube-AI落地(附源码)
本文介绍了嵌入式人工智能与边缘计算的开发流程。首先通过Anaconda搭建Python环境,收集核素识别和机械臂质检两类数据。然后使用Keras训练轻量级CNN模型,并在PC端验证模型效果。接着通过STDeveloperCloud进行云端评估与优化,最后利用STM32CubeMX+X-CUBE-AI完成模型部署。文章以核素识别为例,详细展示了从数据预处理、模型训练到嵌入式实现的完整过程,并验证了识
嵌入式人工智能与边缘计算
随着物联网技术的演进,单纯的数据采集已无法满足需求。我们需要将 AI 算力下沉到设备端,这就是当下火热的 嵌入式人工智能 和 边缘计算 。本文将演示一套完整的开发流程:从原始环境下的数据采集开始,利用 Anaconda 进行环境管理,完成模型训练与 PC端验证,并通过 ST Developer Cloud 进行云端评估与优化,最终使用 STM32CubeMX + X-CUBE-AI 实现部署。
我将通过双案例贯穿全文:
-
n-分类(核素识别):基于多类别的 Excel 数据集。
-
图像异常检测(机械臂视觉质检):基于“50张正常+50张异常”的小样本数据集。
第一步:环境搭建 (Anaconda)
为了避免 Python 环境冲突,我们使用 Anaconda 管理依赖。
conda create -n stm32_ai python=3.8
conda activate stm32_ai
pip install tensorflow pandas numpy matplotlib pillow第二步:数据收集(至关重要)
2.1 文本数据:多 Excel 归类
场景:我们需要识别不同的放射性核素。
操作:假设我们收集了 3 类指令,分别存储在 3 个 Excel 文件中(Cs.xlsx, Co.xlsx, Am.xlsx)。

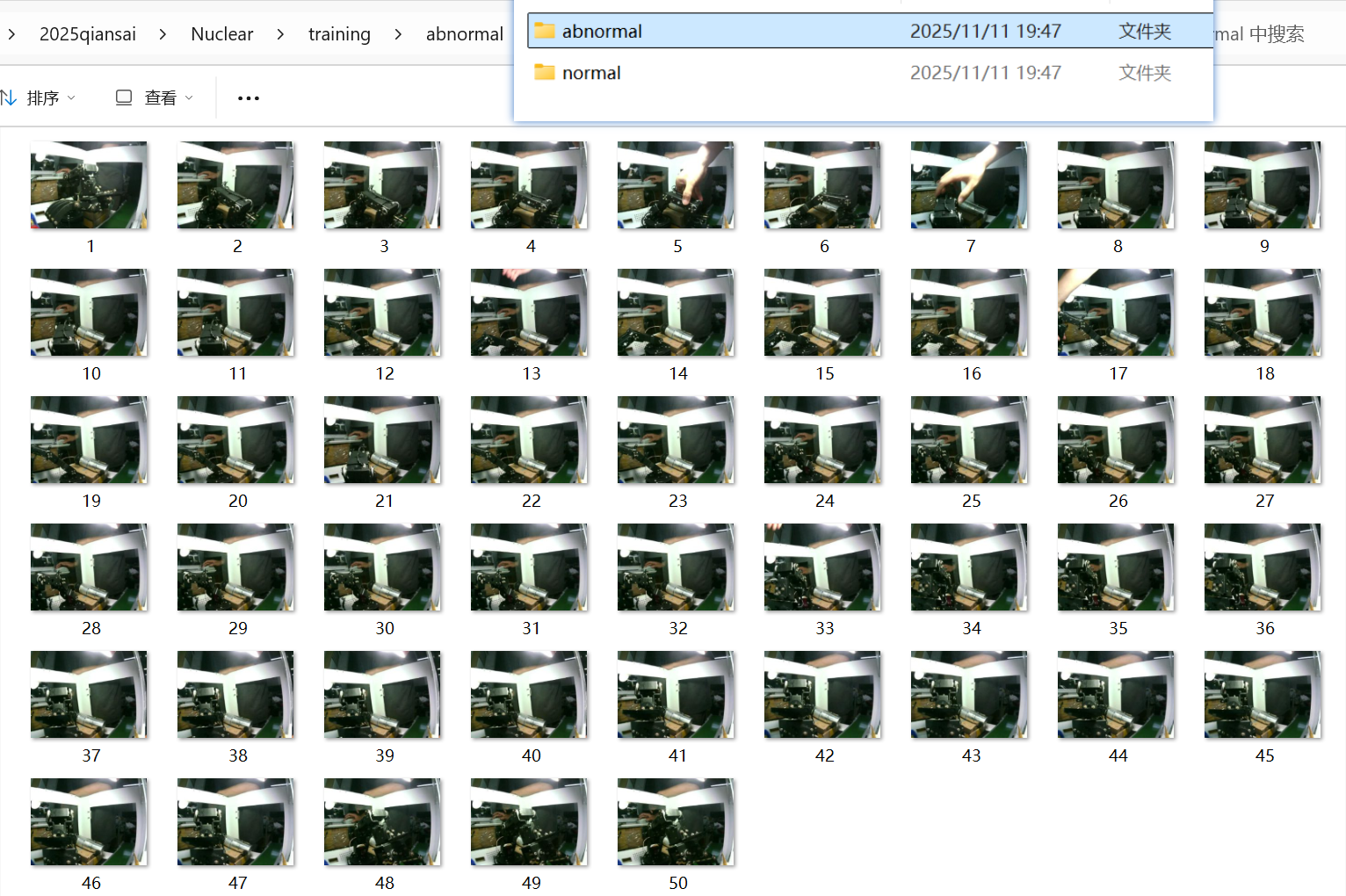
2.2 图像数据:小样本集构建
场景:机械臂抓取过程的异常检测。
操作:我们在实际产线上利用摄像头采集了图片,并人工筛
-
数据集结构:
-
/dataset/normal: 放 50 张机械臂正常工作的照片。
-
/dataset/abnormal: 放 50 张出现故障(如掉件、姿态错误)的照片。
-
这种50 vs 50的均衡数据集对于二分类问题非常关键,能避免模型产生偏见。
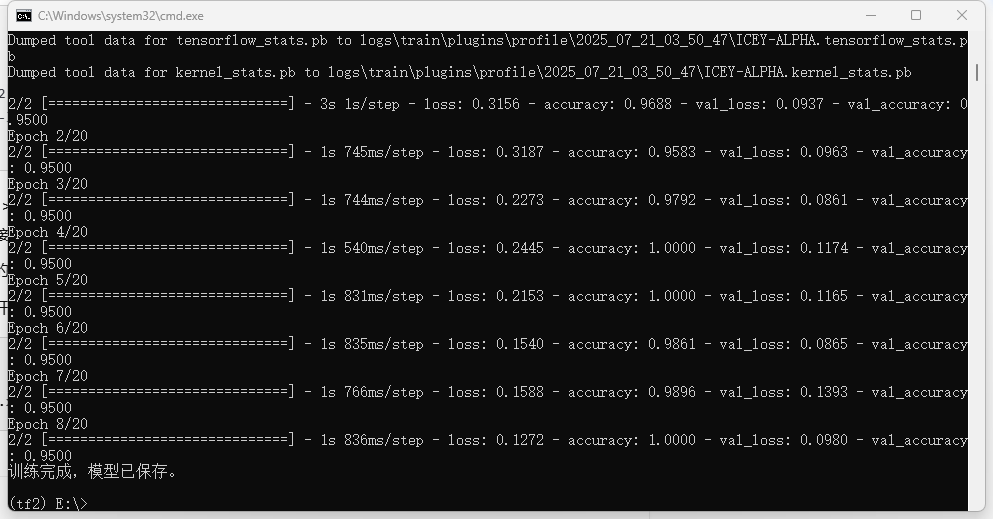
第三步:模型训练 (Keras)
此处以核素识别为例,搭建一个轻量级 CNN:
import os
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 加载谱图数据函数
def load_spectrum(file_path):
df = pd.read_excel(file_path, engine='openpyxl')
counts = df.iloc[:, 1].values
# 补齐/裁剪为1024维
if len(counts) < 1024:
counts = np.pad(counts, (0, 1024 - len(counts)), mode='constant')
elif len(counts) > 1024:
counts = counts[:1024]
# 归一化
spectrum = counts / np.sum(counts)
return spectrum
# 数据集目录,每个xlsx文件是一个核素类别
data_dir = "D:/Desk/2025qiansai/model_train./" # 当前目录,你可以改成 D:/Desk/2025qiansai/model_train 之类的绝对路径
X = []
y = []
label_map = {}
# 遍历所有Excel文件
for idx, filename in enumerate(os.listdir(data_dir)):
if filename.endswith(".xlsx"):
file_path = os.path.join(data_dir, filename)
spectrum = load_spectrum(file_path)
X.append(spectrum)
y.append(idx)
label_map[idx] = filename # 映射类别标签和文件名
X = np.array(X)
y = np.array(y)
# 构建模型
model = keras.Sequential([
layers.Input(shape=(1024,)),
layers.Dense(512, activation='relu'),
layers.Dense(256, activation='relu'),
layers.Dense(len(label_map), activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(X, y, epochs=100)
# 保存模型
model.save("nuclear_model.h5")
model.save("nuclear_model.keras") # 使用 Keras 官方推荐的新保存格式
print("训练完成 ✅ 模型已保存为 nuclear_model.h5")
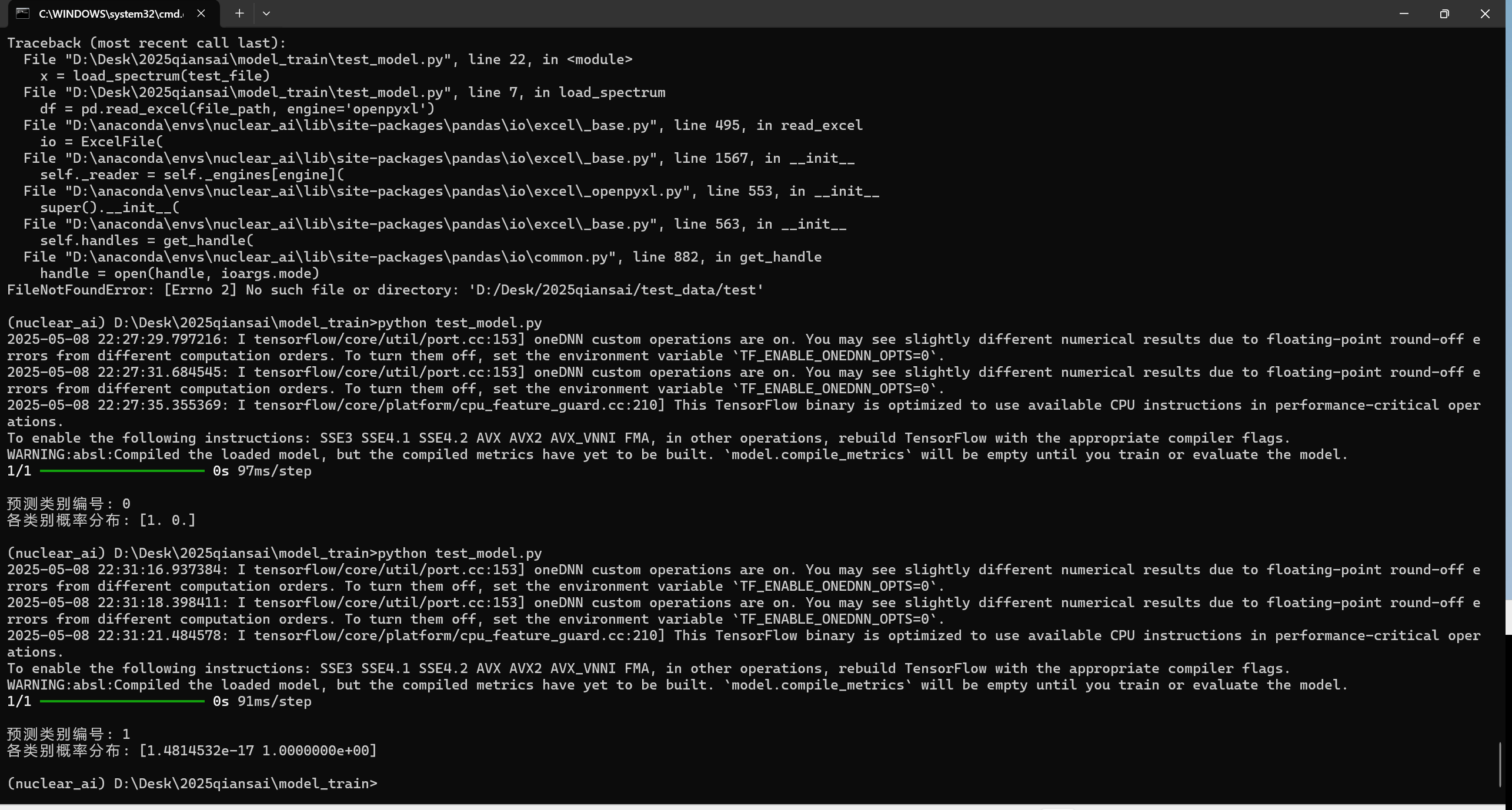
第四步:PC 端验证 (Re-test)
这一步绝不能省! 很多时候模型训练集表现很好,但实际预测全是错的。在部署到 STM32 之前,必须在 PC 上用从未见过的新数据进行测试。
import numpy as np
import pandas as pd
from tensorflow.keras.models import load_model
# 加载单个谱图样本并进行预处理
def load_spectrum(file_path):
df = pd.read_excel(file_path, engine='openpyxl')
spectrum = df.iloc[:, 1].values # 假设第二列是计数值
spectrum = spectrum[:1024] # 截断到 1024
if len(spectrum) < 1024:
spectrum = np.pad(spectrum, (0, 1024 - len(spectrum)))
spectrum = spectrum / np.max(spectrum) # 归一化
return spectrum
# 加载模型
model = load_model("nuclear_model.h5")
# 你想测试的文件路径(请替换成你自己的)
test_file = "D:/Desk/2025qiansai/model_train/test_data/test.xlsx"
# 加载并准备数据
x = load_spectrum(test_file)
x = np.expand_dims(x, axis=0) # 添加 batch 维度
# 预测
prediction = model.predict(x)
predicted_label = np.argmax(prediction)
# 输出结果
print(f"\n预测类别编号: {predicted_label}")
print(f"各类别概率分布: {prediction[0]}")
第五步:ST Developer Cloud 云端优化与评估
在打开 CubeMX 之前,我们使用 ST Developer Cloud (STM32 AI Cloud) 对模型进行深度评估。这是 ST 推出的神器,可以在云端直接连接真实的开发板农场(Board Farm)进行测速。
-
上传模型:登录 ST Developer Cloud,上传 nuclear.h5。
-
基准测试 (Benchmark):
-
选择你的目标芯片(如 STM32F407 或 STM32H7)。
-
系统会生成详细的报告:推理时间 (ms)、RAM 占用、Flash 占用。
-
(此处重点截图:展示云端生成的饼图或柱状图,特别是参数比重分析,看哪一层网络占用的内存最大)。
-
-
优化建议:如果模型太大,云端工具会建议进行 8-bit 量化 (Quantization)。量化后模型体积通常能缩小 4 倍,且精度损失极小。
-
下载优化后的模型:下载优化好的 .h5 或 .tflite 文件。

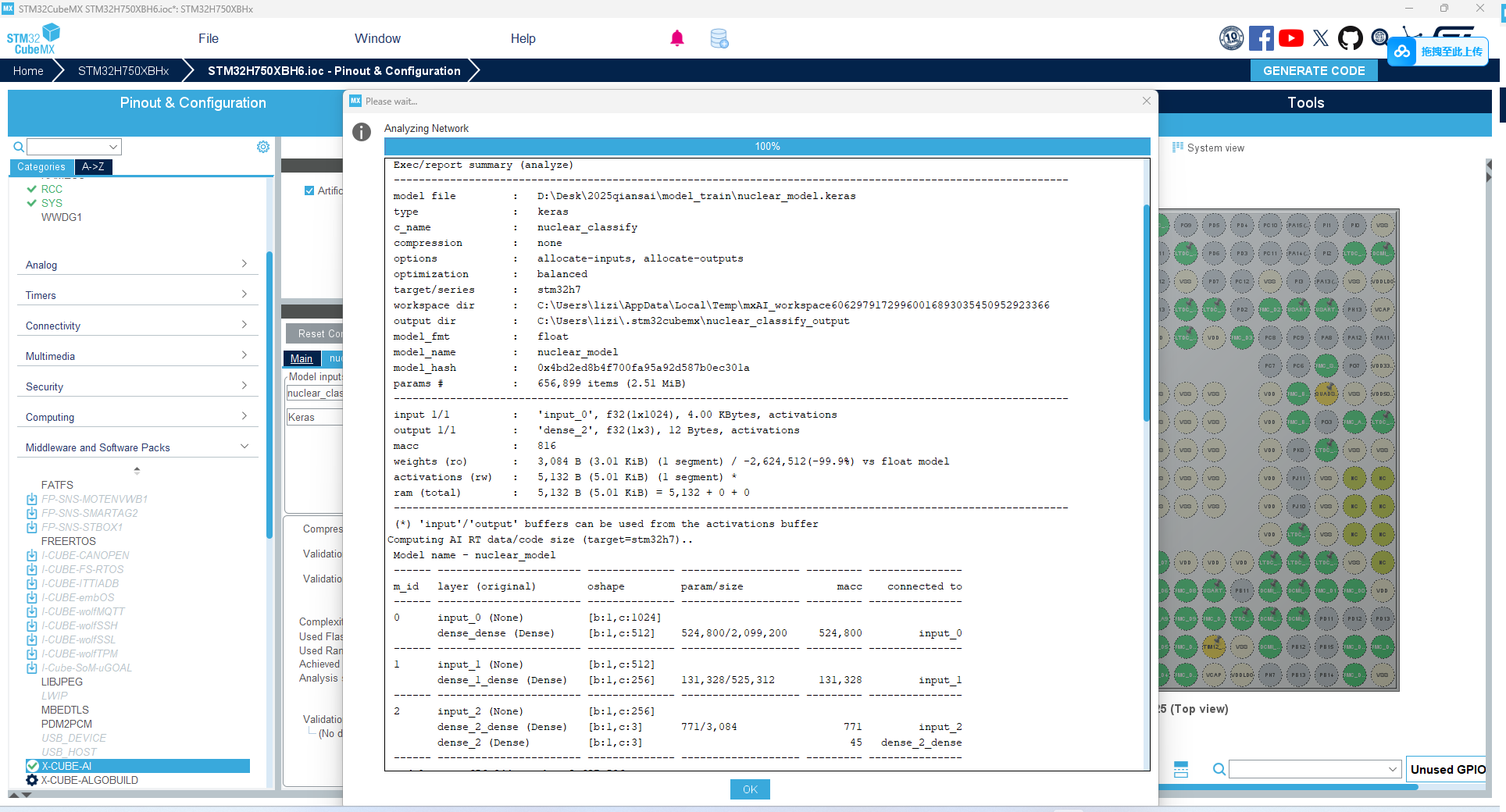
第六步:STM32CubeMX X-CUBE-AI 部署
拿到经过云端验证的模型后,我们开始本地部署。
-
配置 X-CUBE-AI:
-
CubeMX -> Software Packs -> Enable X-CUBE-AI。
-
导入模型。点击 Analyze,此时看到的资源占用应该和云端分析的一致。
-
-
硬件配置:
-
开启 CRC (必须)。
-
开启 UART (用于输出结果)。
-
配置摄像头接口 (DCMI) 或准备好测试数据的数组。
-
-
生成代码。
第七步:代码落地与效果实测
/* 包含标准库 */
#include <stdio.h>
#include <string.h>
#include "app_x-cube-ai.h"
#include "ai_datatypes_defines.h"
/* 定义输入输出缓冲区 (由 X-CUBE-AI 生成) */
/* 假设模型输入层是 energy_spectrum_input,长度为 N (如 256 或 1024) */
ai_float in_data[AI_NETWORK_IN_1_SIZE];
ai_float out_data[AI_NETWORK_OUT_1_SIZE]; // 长度为3 (Am, Cs, Co)
/* 模拟从 ADC/MCA 获取的原始能谱数据 (整数数组) */
/* 实际项目中,这里的数据来自你的传感器驱动 */
uint32_t raw_spectrum_data[AI_NETWORK_IN_1_SIZE];
/*
* 核心任务:核素识别
* 入参:采集到的原始计数值数组
*/
void AI_Radionuclide_Process_Task(uint32_t *pRawData)
{
printf("Starting Spectrum Analysis...\r\n");
/* --- 步骤 1: 数据预处理 (Normalization) --- */
/* 神经网络对数值范围敏感,通常需要归一化到 0.0 ~ 1.0 之间 */
/* 方法A:除以最大值 (Min-Max Scaling) */
/* 方法B:除以总计数 (Total Count Normalization) -> 常用 */
float max_count = 0.0f;
// 1.1 找到最大值 (为了归一化)
for (int i = 0; i < AI_NETWORK_IN_1_SIZE; i++) {
if ((float)pRawData[i] > max_count) {
max_count = (float)pRawData[i];
}
}
// 1.2 填充输入 Buffer (防止除0错误)
if (max_count == 0.0f) max_count = 1.0f;
for (int i = 0; i < AI_NETWORK_IN_1_SIZE; i++) {
// 将整数计数转为浮点,并归一化
in_data[i] = (ai_float)pRawData[i] / max_count;
}
/* --- 步骤 2: 执行 AI 推理 --- */
// 调用 X-CUBE-AI 引擎
ai_error err = ai_network_run(network, &ai_input, &ai_output);
if (err.type != AI_ERROR_NONE) {
printf("AI Inference Error: %d\r\n", err.type);
return;
}
/* --- 步骤 3: 解析结果 (寻找最大概率) --- */
int predicted_class = -1;
float max_prob = 0.0f;
// 遍历输出数组 (Size = 3)
for (int i = 0; i < AI_NETWORK_OUT_1_SIZE; i++) {
// out_data[i] 代表是第 i 种核素的概率
if (out_data[i] > max_prob) {
max_prob = out_data[i];
predicted_class = i;
}
}
/* --- 步骤 4: 业务逻辑与报警 --- */
// 设定置信度阈值 > 80% 才确认为识别成功
if (max_prob > 0.8f) {
switch (predicted_class) {
case 0:
printf("Result: [Am-241] Detected! (Prob: %.2f)\r\n", max_prob);
break;
case 1:
printf("Result: [Cs-137] Detected! (Prob: %.2f)\r\n", max_prob);
break;
case 2:
printf("Result: [Co-60] Detected! (Prob: %.2f)\r\n", max_prob);
HAL_GPIO_WritePin(LED_RED_Port, LED_RED_Pin, GPIO_PIN_SET);
break;
default:
break;
}
} else {
printf("Result: Background / Unknown Source.\r\n");
}
}
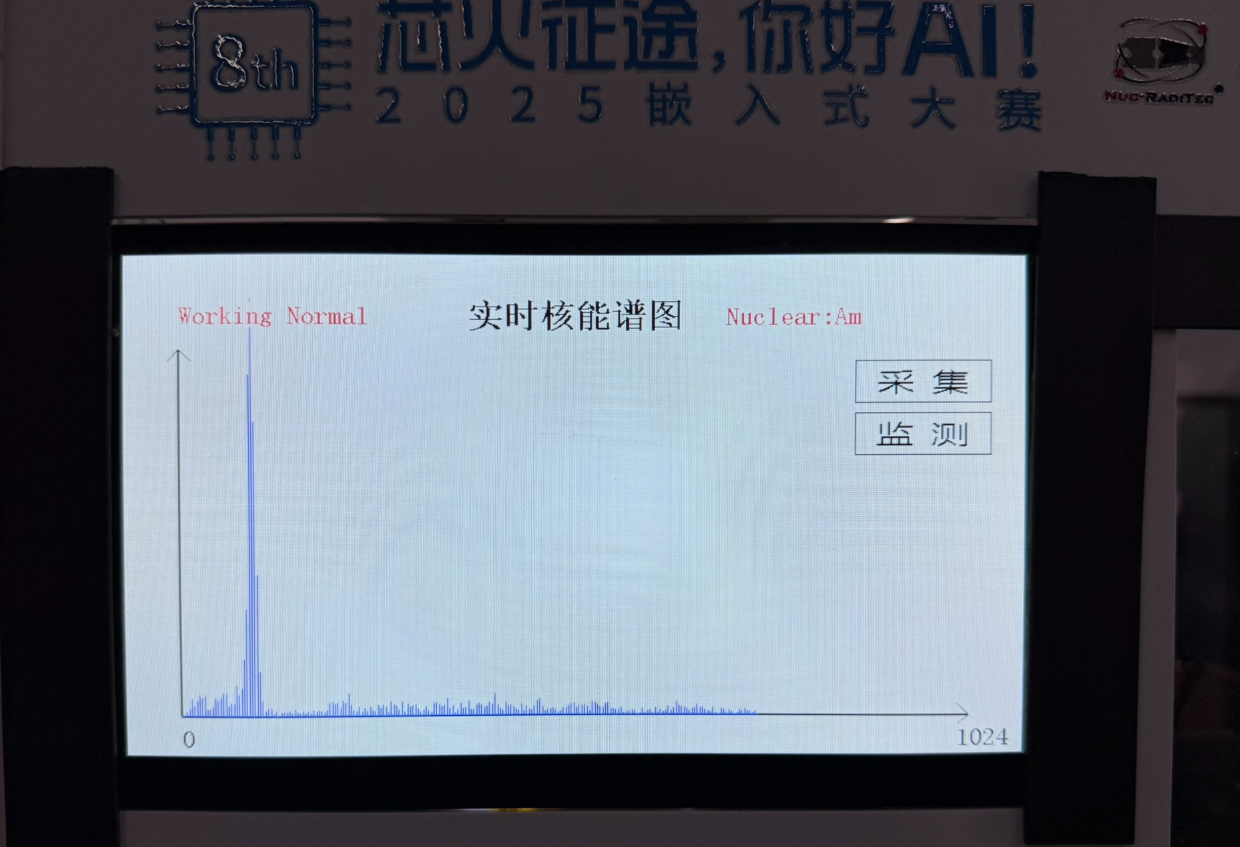
如上图所示,识别效果极佳!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)