GPT-4o 下线 24 小时:3 类线上问题会集中爆发
摘要:OpenAI宣布自2026年2月13日起,ChatGPT产品将退役GPT-4o等旧模型,API和企业客户可延用至4月3日。官方解释退役原因为使用率低(仅0.1%)、新模型在风格控制和未成年人保护方面更优。这一变更要求测试从业者升级能力:建立模型生命周期测试体系,关注行为一致性而非仅功能正确性,应对风格配置组合爆炸,加强合规性验证。建议将模型迁移视为线上大版本发布,制定包含基线冻结、灰度监控、
关注 霍格沃兹测试学院公众号,回复「资料」, 领取人工智能测试开发技术合集
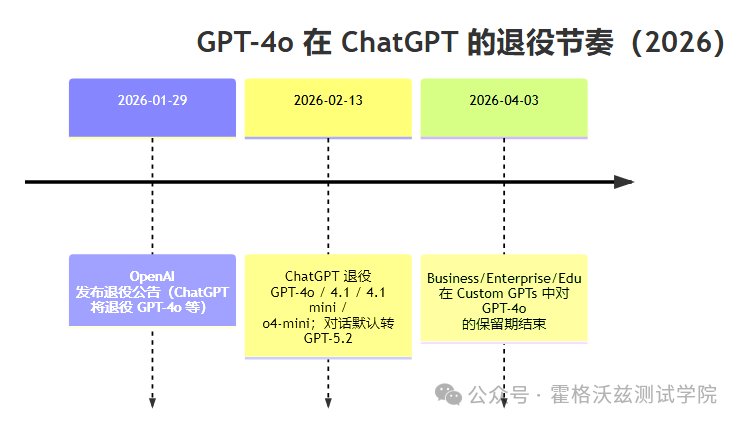
从 2026-02-13 起,ChatGPT 将在产品侧退役 GPT-4o 等旧模型;但 API 暂无变化,企业客户在 Custom GPTs 里还能多用一段时间。
目录
-
发生了什么:哪些模型退役、什么时候生效
-
为什么是现在:官方给出的理由,和背后的“质量含义”
-
对测试从业者有什么用:这件事本质上在逼你补齐哪些能力
-
迁移与验证清单:把“换模型”当一次线上大版本发布来做
-
三张工程图:时间线 / 迁移流 / QA 测试面
1) 发生了什么:哪些模型退役、什么时候生效

OpenAI 的官方口径很清晰:
-
2026-02-13 起,ChatGPT 内将退役:GPT-4o、GPT-4.1、GPT-4.1 mini、OpenAI o4-mini,以及此前已宣布的 GPT-5(Instant & Thinking)。
-
API 暂无变化:这些“在 ChatGPT 里退役”的模型,当前仍可通过 OpenAI API 使用(至少在这次公告里不变)。
-
企业侧延后:ChatGPT Business / Enterprise / Edu 在 Custom GPTs 里可以继续访问 GPT-4o 直到 2026-04-03,之后才算全量退役。
-
退役后,历史对话/项目会默认转到 GPT-5.2 继续。
2) 为什么是现在:官方理由 + “质量含义”
官方博客给的关键点有三个:
-
“大多数使用量已迁移”:OpenAI 说日常仍选 GPT-4o 的只剩 **0.1%**。
-
“个性/风格可控性补齐了”:他们强调 GPT-5.1/5.2 在“风格、温暖感、创意支持”等方面做了改进,并提供更多“响应风格控制”。
-
“未成年人保护加强”:提到多数市场对 18 岁以下用户做了年龄预测/保护策略。
这次退役不是“能力不够”,更像是“行为边界与风险成本”重新划线。也就是说——从现在起,你不能只测“准不准”,还得测“像不像、稳不稳、会不会跑偏”。
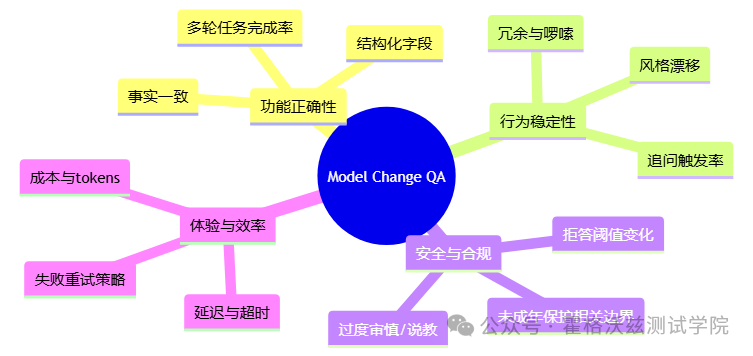
3) 对测试从业者有什么用:它在逼你补齐哪些能力
-
模型生命周期测试(Model Lifecycle QA):模型会退役、会切换、会分层(ChatGPT vs API vs 企业计划),你的用例和监控要能跟上节奏。
-
回归的核心从“功能”转到“行为”:同样的 Prompt,不同模型会给出“同样正确但风格不同”的输出;你的断言方式必须升级(不能全靠精确匹配)。
-
“个性/温暖”是可变参数:官方把“风格控制”当能力卖点,本质上意味着输出分布变宽——测试要覆盖“配置组合爆炸”。
-
合规与未成年策略会改变边界:你会看到更多“阈值型变化”(拒答、改写、降级),这类最容易引发线上投诉和舆情。
4) 迁移与验证清单:把“换模型”当一次线上大版本发布来做
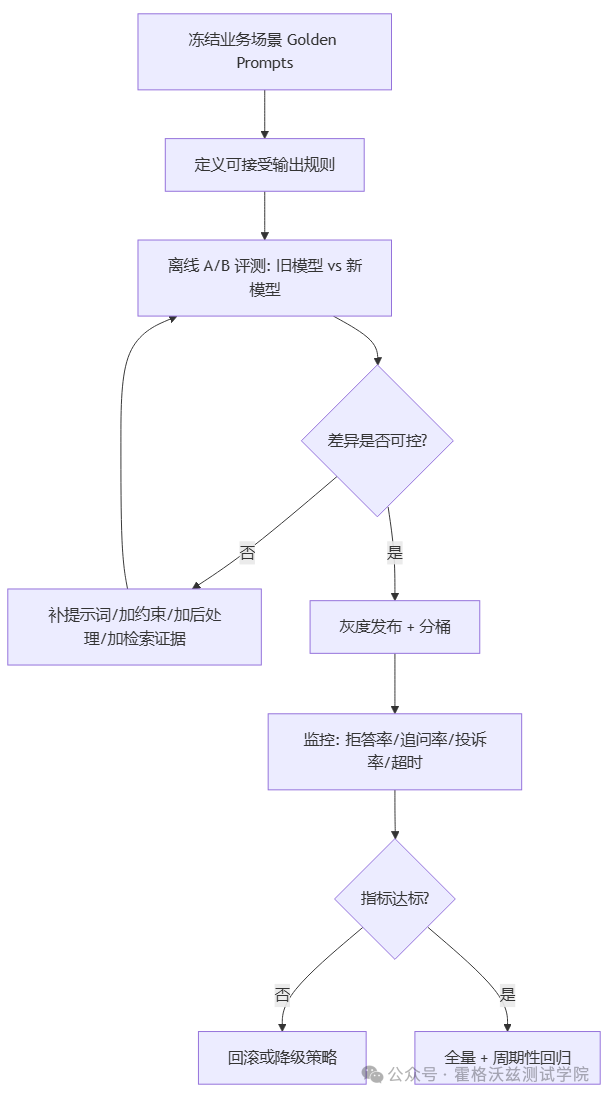
下面这份清单,按“上线前—灰度—上线后”来跑,基本能把坑踩完:
A. 上线前(冻结基线)
-
固化 Golden Prompts:高频业务场景(咨询、总结、代码、检索、客服、审核)各选 20–100 条
-
固化 Golden Outputs 的判定规则:
-
允许同义改写,但要求关键信息不丢
-
关键字段(数值、结论、风险提示、引用)必须可抽取并一致
-
-
做一次 模型 A/B 离线评测:4o vs 5.2(或你将切换的目标模型)
-
明确 不可接受变化:例如拒答率上升、幻觉率上升、结构化字段缺失、关键术语漂移
B. 灰度期
-
灰度流量 + 分桶:新模型先吃低风险请求
-
监控四件事:
-
失败率/超时
-
拒答率/安全改写率
-
用户二次追问率(“你没回答我的问题”)
-
投诉与人工转接率
-
-
对“长尾灾难样本”做回灌:把线上坏例子加入 Golden Prompts
C. 上线后
-
建立 Prompt/配置变更审计(谁改了、改了什么、影响了哪些用例)
-
每周跑一次 回归套件(别等到用户替你做测试)
-
给产品准备一份“用户可解释的变更说明”:减少“感觉变冷/变啰嗦/变保守”的误解成本
5) 三张工程图
1:ChatGPT 侧退役时间线
2:一次“换模型”的标准迁移流
3:模型变更的 QA 测试面(你该测什么)
把“模型退役”当成一次行业级的回归演练
这次 GPT-4o 在 ChatGPT 的退役,官方信息本身并不复杂;复杂的是它提醒你:大模型不是一个“永远稳定的依赖项”,它更像一个会持续变更的运行时环境。
对测试从业者来说,这反而是好消息:当行业从“谁更强”卷到“谁更可控、可测、可回归”,测试的含金量会重新上升——而且是工程含金量,不是嘴炮含金量。
关于我们
霍格沃兹测试开发学社,隶属于 测吧(北京)科技有限公司,是一个面向软件测试爱好者的技术交流社区。
学社围绕现代软件测试工程体系展开,内容涵盖软件测试入门、自动化测试、性能测试、接口测试、测试开发、全栈测试,以及人工智能测试与 AI 在测试工程中的应用实践。
我们关注测试工程能力的系统化建设,包括 Python 自动化测试、Java 自动化测试、Web 与 App 自动化、持续集成与质量体系建设,同时探索 AI 驱动的测试设计、用例生成、自动化执行与质量分析方法,沉淀可复用、可落地的测试开发工程经验。
在技术社区与工程实践之外,学社还参与测试工程人才培养体系建设,面向高校提供测试实训平台与实践支持,组织开展 “火焰杯” 软件测试相关技术赛事,并探索以能力为导向的人才培养模式,包括高校学员先学习、就业后付款的实践路径。
同时,学社结合真实行业需求,为在职测试工程师与高潜学员提供名企大厂 1v1 私教服务,用于个性化能力提升与工程实践指导。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献202条内容
已为社区贡献202条内容

所有评论(0)