Linux【第一篇】 ——— 基础与常用命令操作详解
目录
userdel -r 指令(删除用户账户并彻底清理其相关文件)
ls 指令(列出当前工作目录(或指定目录)下的文件和子目录)
mkdir 指令(在当前工作目录(或指定路径)下创建新的目录(文件夹))
ls -a 指令(列出当前目录下所有文件和子目录,包括隐藏文件和隐藏目录)
ls -a -l 指令;ls -l -a 指令;ls -al 指令;ls -la 指令
ls -d 指令 和 ls -dl 指令(只显示指定目录本身的名称)
ls -alF 指令(以长格式显示当前目录下的所有文件和目录(包括隐藏内容))
rm -r 指令(删除指定的目录及其包含的所有子目录和文件)
rm -rf 指令(强制、递归地删除指定目录及其包含的所有子目录、文件)
rm -rf * 指令(强制、递归地删除当前目录下所有非隐藏的文件和目录)
echo 指令(输出字符串、变量值或空行);cat 指令(读取文件内容并打印到终端)
mv 指令(对文件或目录执行 重命名 操作)(把文件 / 目录 移动到指定位置)
echo > 指令 和 echo >> 指令(将字符串追加到文件末尾)
cat -b 指令(读取文件内容时,仅为非空白行添加连续行号)
cat -s 指令(读取文件内容时,将连续的多个空白行压缩为单个空白行)
date +%s 命令(输出当前系统时间对应的 Unix 时间戳)
date -d @时间戳 命令( 将指定的时间戳转换为系统本地时区的人类可读日期时间格式)
whereis 命令(快速查找指定指令、库文件或头文件的相关关联文件)
购买云服务器(以购买阿里云服务器为例)
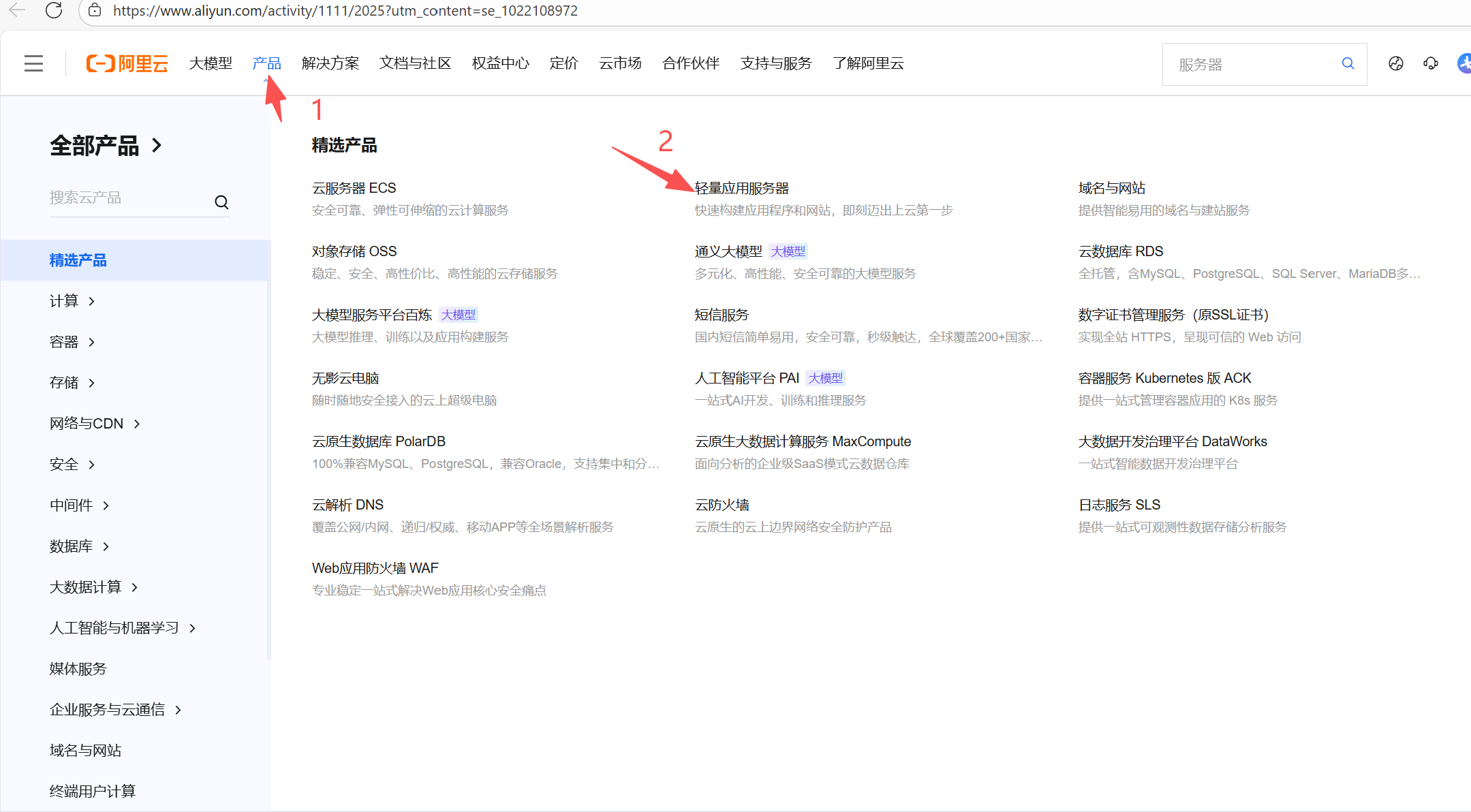
第一步
进入阿里云官网:https://www.aliyun.com/
第二步
1. 点击产品 ---> 2. 点击轻量应用服务器
第三步

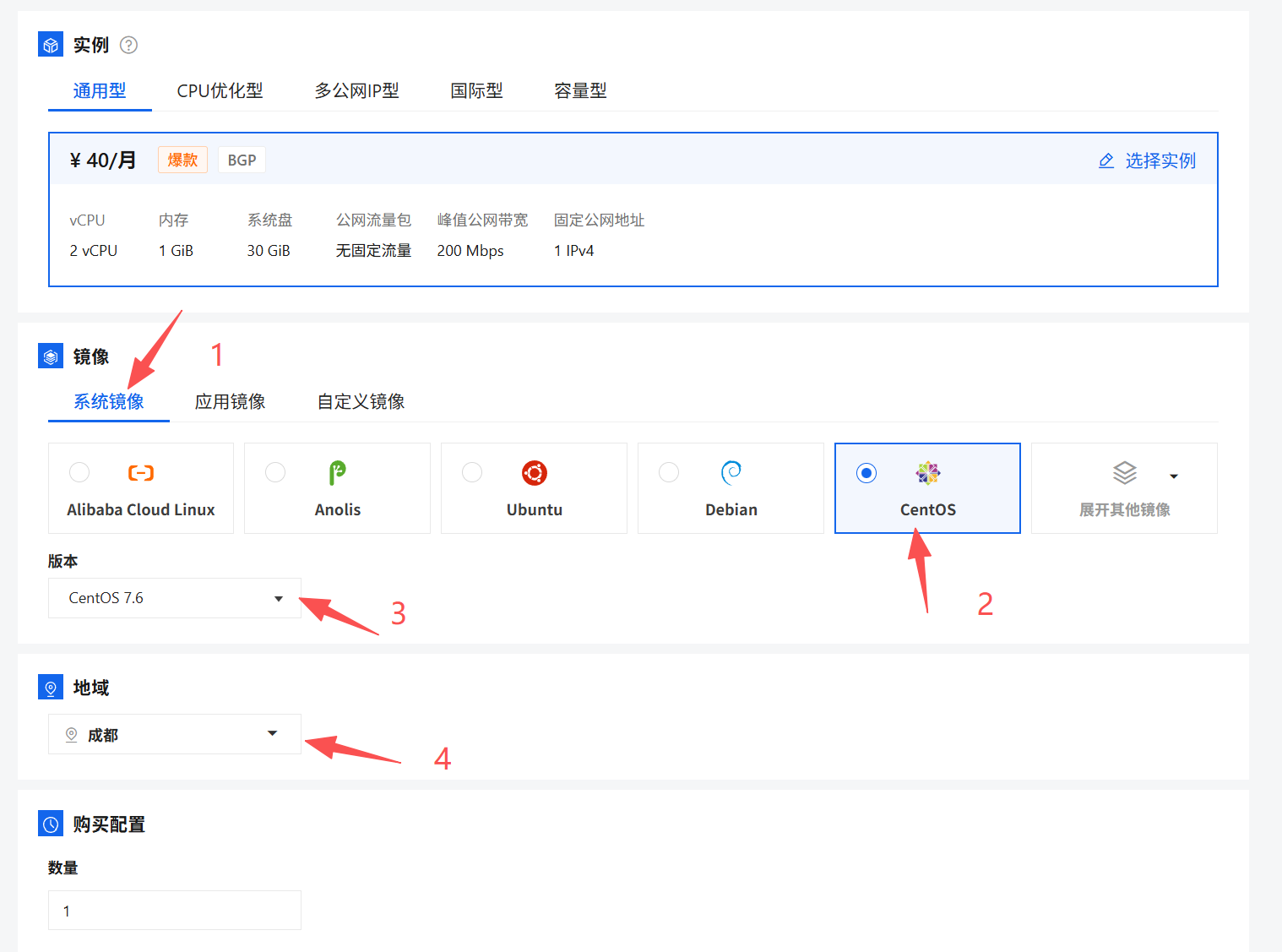
第四步
点击系统镜像 ---> 点击CentOS ---> 选择7.6版本 ---> 地域选择距离你家近的
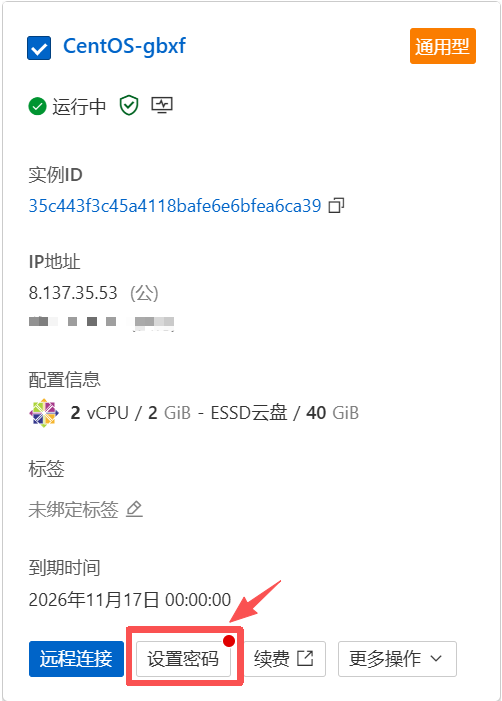
第五步
购买后记得设置密码
通过 xshell 登录自己的云服务器
第一步
进入 xshell 后输入:ssh root@你自己云服务器的公网IP
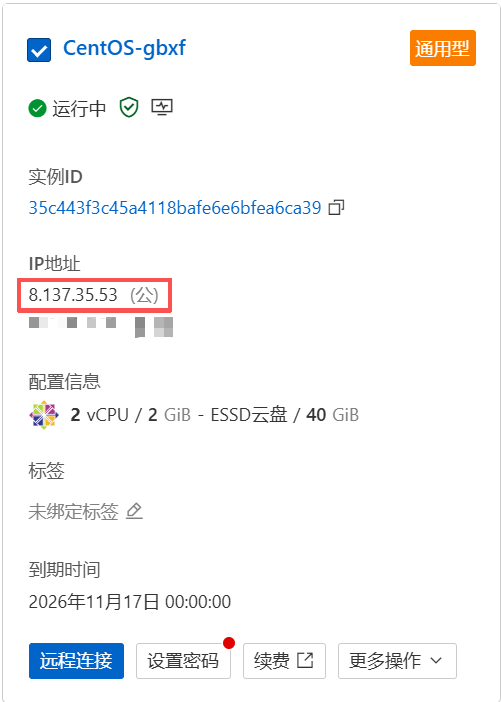
[C:\~]$ ssh root@你自己的云服务器公网IP
第二步
输入密码
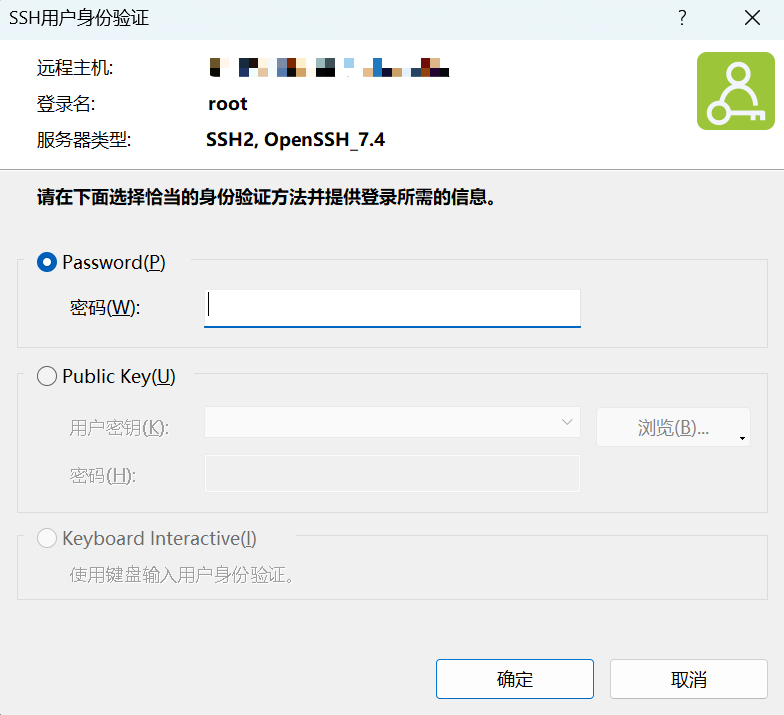
注意:在第一次登录的时候,在输入密码之前,会有一串乱码,下面有一个确认按钮,点击确认即可
adduser 指令(在系统中新增一个用户账户)
[root@iZ2vc15k23y9vpuyi3tiqzZ ~]# adduser obj1
adduser 的主要功能是在系统中新增一个用户账户,并自动完成一系列与用户相关的配置工作,无需用户手动执行多个底层命令。
- 创建用户账户:在系统中注册
obj1作为新用户,分配唯一的用户 ID(UID)。 - 创建同名用户组:自动创建一个与用户名相同的私有组(
obj1组),分配唯一的组 ID(GID),并将obj1用户加入该组。 - 创建家目录:在
/home目录下生成obj1的家目录(/home/obj1),用于存储该用户的个人文件和配置。 - 复制默认配置:将
/etc/skel目录下的默认配置文件(如.bashrc、.bash_logout等)复制到/home/obj1,确保obj1登录后有基本的 shell 环境。 - 设置默认 shell:默认将登录 shell 设为
/bin/bash(可通过配置文件修改默认值)。
passwd 指令(更新用户的认证密码)
[root@iZ2vc15k23y9vpuyi3tiqzZ ~]# passwd obj1
Changing password for user obj1.
New password:
BAD PASSWORD: The password fails the dictionary check - it does not contain enough DIFFERENT characters
Retype new password:
passwd: all authentication tokens updated successfully.
[root@iZ2vc15k23y9vpuyi3tiqzZ ~]#
passwd 的主要作用是更新用户的认证密码(存储在 /etc/shadow 文件中,以加密形式保存),确保用户登录系统或执行需要权限的操作时的身份验证。
-
执行命令:
passwd obj1- 由于是
root用户,可直接指定用户名(obj1)修改其密码;普通用户执行passwd时不带参数,只能修改自己的密码。
- 由于是
-
提示信息:
Changing password for user obj1.- 明确当前操作是修改
obj1这个用户的密码。
- 明确当前操作是修改
-
输入新密码:
New password:- 系统提示输入新密码(输入时默认不显示明文,保障安全)。
-
密码复杂度警告:
BAD PASSWORD: The password fails the dictionary check - it does not contain enough DIFFERENT characters- 这是系统的密码策略检查警告:你输入的密码不符合 “复杂度要求”,具体原因是 “不同字符数量不足”(例如密码可能过于简单,如
111222或aaaaaa,重复字符过多)。 - 注意:这只是警告而非 “错误”,多数系统默认允许设置此类密码(仅提醒用户密码不安全),具体是否强制复杂度由系统配置(如
pam_cracklib模块)决定。
- 这是系统的密码策略检查警告:你输入的密码不符合 “复杂度要求”,具体原因是 “不同字符数量不足”(例如密码可能过于简单,如
-
确认新密码:
Retype new password:- 再次输入新密码以确认(防止第一次输入时的手误),两次输入必须一致才能生效。
-
操作成功:
passwd: all authentication tokens updated successfully.- 提示密码修改成功,
obj1的密码已更新为新输入的值。
- 提示密码修改成功,
userdel -r 指令(删除用户账户并彻底清理其相关文件)
[root@iZ2vc15k23y9vpuyi3tiqzZ ~]# userdel -r obj1
在 Linux 系统中,userdel -r 是用于删除用户账户并彻底清理其相关文件的命令,其中 -r 是关键选项,作用是 “移除用户的家目录及相关文件”。结合你的示例 userdel -r obj1,具体解释如下:
-
userdel基础作用:userdel是删除系统用户账户的底层命令,主要功能是从用户数据库文件(如/etc/passwd、/etc/shadow、/etc/group等)中移除指定用户(这里是obj1)的信息,使其无法再登录系统。 -
-r选项的作用:-r(全称--remove)是一个重要的附加选项,它会在删除用户账户的同时,自动清理该用户的家目录(默认/home/obj1)和邮件池(通常在/var/spool/mail/obj1)等关联文件,避免残留文件占用空间或导致安全隐患。
- 若不使用
-r(即userdel obj1),则仅删除用户账户信息,其家目录(/home/obj1)会被保留,需要手动删除。
ls 指令(列出当前工作目录(或指定目录)下的文件和子目录)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ls
核心作用:ls 是 “list” 的缩写,用于列出当前工作目录(或指定目录)下的文件和子目录。
简单来说,执行 ls 后,终端会显示当前目录中包含的可见文件(非隐藏文件)和子目录的名称。
pwd 指令(显示当前工作目录的绝对路径)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
核心作用:pwd 是 “print working directory” 的缩写,用于显示当前工作目录的绝对路径(从根目录/开始的完整路径)。
结合示例说明:执行 pwd 后输出 /home/ranjiaju,这表明当前终端的工作目录是用户 ranjiaju 的家目录,其绝对路径为 /home/ranjiaju。通过 pwd 可以清晰知道自己在系统文件结构中的具体位置。
mkdir 指令(在当前工作目录(或指定路径)下创建新的目录(文件夹))
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ mkdir test_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ls
test_1
核心作用:mkdir 是 “make directory” 的缩写,用于在当前工作目录(或指定路径)下创建新的目录(文件夹)。
示例中,执行 mkdir test_1 后,系统会在当前工作目录(即 /home/ranjiaju)中生成一个名为 test_1 的新目录。后续执行 ls 指令时,能看到 test_1 出现在列表中,表明该目录已成功创建。简单来说,mkdir 是用于创建新目录的基础指令。
cd 指令(切换当前工作目录)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cd test_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ pwd
/home/ranjiaju/test_1
核心作用:cd 是 “change directory” 的缩写,用于切换当前工作目录。
示例中,执行 cd test_1 后,当前工作目录从原本的 /home/ranjiaju 切换到了 test_1 目录(完整路径为 /home/ranjiaju/test_1)。后续执行 pwd 指令输出的路径也验证了这一点 —— 通过 cd 指令成功进入了指定的 test_1 目录。简单来说,cd 是用于在不同目录之间切换的基础指令。
touch 指令(创建新的空文件)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ mkdir test_1_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ mkdir test_1_2
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ touch test_1_3.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ ls
test_1_1 test_1_2 test_1_3.txt
核心作用:touch 指令主要用于创建新的空文件,也可用于更新已有文件的访问时间和修改时间。
示例中,执行 touch test_1_3.txt 后,系统在当前工作目录(/home/ranjiaju/test_1)中生成了一个名为 test_1_3.txt 的空文件。后续执行 ls 指令时,该文件出现在列表中,表明空文件已成功创建。简单来说,touch 是创建空文件的常用指令。
ls -l 指令(列出当前目录下文件和子目录的详细信息)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ ls
test_1_1 test_1_2 test_1_3.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ ls -l
total 8
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_1
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_2
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 17 23:06 test_1_3.txt
核心作用:ls -l 是 ls 指令的一种常用选项组合,其中 -l 表示 “长格式(long format)”,用于列出当前目录下文件和子目录的详细信息,包括文件类型、权限、所有者、大小、修改时间等。
结合示例说明:示例中执行 ls -l 后,输出包含以下信息:
- 第一行
total 8:表示当前目录下所有文件和子目录占用的磁盘块总数(此处为 8 块,每块通常为 4KB)。 - 后续每行对应一个文件或目录,以空格分隔多个字段,以
test_1_1为例:drwxrwxr-x:第一个字符d表示是目录(-表示普通文件),后面 9 个字符是权限(分属所有者、所属组、其他用户的读 / 写 / 执行权限);2:表示该目录的硬链接数;ranjiaju ranjiaju:分别是文件的所有者和所属组;4096:目录的大小(默认 4KB,是目录元数据占用的空间);Nov 17 23:05:最后修改时间;test_1_1:目录名称。
简单来说,ls -l 能比普通 ls 更详细地展示文件和目录的属性信息,方便查看权限、大小等关键内容。
ll 指令
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ ls -l
total 8
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_1
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_2
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 17 23:06 test_1_3.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ ll
total 8
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_1
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_2
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 17 23:06 test_1_3.txt
ll 指令 等价于 ls -l 指令
ls -a 指令(列出当前目录下所有文件和子目录,包括隐藏文件和隐藏目录)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ ls -a
. .. test_1_1 test_1_2 test_1_3.txt核心作用:ls -a 是 ls 指令的一种选项组合,其中 -a 是 “all” 的缩写,用于列出当前目录下所有文件和子目录,包括以 . 开头的隐藏文件和隐藏目录(普通 ls 指令默认不显示隐藏内容)。
结合示例说明:示例中执行 ls -a 后,输出包含 .、.. 以及可见的 test_1_1、test_1_2、test_1_3.txt。其中:
.代表当前目录(即test_1目录本身);..代表当前目录的父目录(即test_1的上一级目录/home/ranjiaju);这两个都是系统默认的隐藏目录,普通ls不会显示,而ls -a会将它们与其他可见内容一起列出,从而完整展示目录下的所有内容。
简单来说,ls -a 用于查看目录下的全部内容,包括通常隐藏的文件和目录。
ls -a -l 指令;ls -l -a 指令;ls -al 指令;ls -la 指令
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ ls -a -l
total 16
drwxrwxr-x 4 ranjiaju ranjiaju 4096 Nov 17 23:06 .
drwx------ 3 ranjiaju ranjiaju 4096 Nov 17 22:56 ..
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_1
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_2
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 17 23:06 test_1_3.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ ls -l -a
total 16
drwxrwxr-x 4 ranjiaju ranjiaju 4096 Nov 17 23:06 .
drwx------ 3 ranjiaju ranjiaju 4096 Nov 17 22:56 ..
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_1
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_2
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 17 23:06 test_1_3.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ ls -al
total 16
drwxrwxr-x 4 ranjiaju ranjiaju 4096 Nov 17 23:06 .
drwx------ 3 ranjiaju ranjiaju 4096 Nov 17 22:56 ..
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_1
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_2
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 17 23:06 test_1_3.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ ls -la
total 16
drwxrwxr-x 4 ranjiaju ranjiaju 4096 Nov 17 23:06 .
drwx------ 3 ranjiaju ranjiaju 4096 Nov 17 22:56 ..
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_1
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_2
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 17 23:06 test_1_3.txt
同为一个意思
以 . 开头的文件
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ mkdir .test_1_4
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ touch .test_1_5.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ ls
test_1_1 test_1_2 test_1_3.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ ls -a
. .. test_1_1 test_1_2 test_1_3.txt .test_1_4 .test_1_5.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ ls -al
total 20
drwxrwxr-x 5 ranjiaju ranjiaju 4096 Nov 17 23:32 .
drwx------ 3 ranjiaju ranjiaju 4096 Nov 17 22:56 ..
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_1
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_2
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 17 23:06 test_1_3.txt
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:31 .test_1_4
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 17 23:32 .test_1_5.txt
以 . 开头的文件是隐藏文件,所以只有用 ls 中的 -a 指令才能看到
cd .. 指令(将当前工作目录切换到上一级目录)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ pwd
/home/ranjiaju/test_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ cd ..
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cd ..
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ home]$ pwd
/home
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ home]$ cd ..
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ /]$ pwd
/
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ /]$ cd..
-bash: cd..: command not found
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ /]$ pwd
/
核心作用:cd .. 是 cd 指令的一种常用形式,其中 .. 是 Linux 中表示 “当前目录的父目录(上一级目录)” 的特殊符号,因此 cd .. 的作用是将当前工作目录切换到上一级目录。
结合示例说明:示例中多次执行 cd ..,每次执行后当前目录均向上一级移动:
- 初始目录为
/home/ranjiaju/test_1,执行cd ..后,切换到其父目录/home/ranjiaju; - 再执行
cd ..,切换到/home/ranjiaju的父目录/home; - 继续执行
cd ..,切换到/home的父目录(根目录)/。
这一系列操作验证了 cd .. 的功能:通过 .. 定位当前目录的上一级,再通过 cd 完成目录切换,是在目录层级中向上导航的基础指令。
ls -d 指令 和 ls -dl 指令(只显示指定目录本身的名称)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ pwd
/home/ranjiaju/test_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ cd ..
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ls test_1
test_1_1 test_1_2 test_1_3.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ls -d test_1
test_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ls -dl test_1
drwxrwxr-x 5 ranjiaju ranjiaju 4096 Nov 17 23:32 test_1
ls -d 指令
核心作用:ls -d 中 -d 是 “directory” 的缩写,其作用是只显示指定目录本身的名称,而不列出该目录内的文件或子目录(默认 ls 查看目录时会显示目录内的内容)。
结合示例说明:示例中执行 ls test_1 时,输出的是 test_1 目录内的内容(test_1_1、test_1_2、test_1_3.txt);而执行 ls -d test_1 时,仅输出 test_1 本身 —— 这正是 -d 的作用:聚焦于目录自身,不展开显示其内部内容。
ls -dl 指令
核心作用:ls -dl 是 -d 与 -l 选项的组合,其中 -d 确保只针对目录本身,-l 以长格式显示详细信息,因此 ls -dl 的作用是以长格式显示指定目录本身的详细属性(如权限、所有者、大小、修改时间等),而非目录内的内容。
结合示例说明:示例中执行 ls -dl test_1 后,输出 drwxrwxr-x 5 ranjiaju ranjiaju 4096 Nov 17 23:32 test_1,这串信息详细描述了 test_1 目录自身的属性(如权限 drwxrwxr-x、所有者 ranjiaju、大小 4096 等),而非其内部的文件或子目录 —— 这是 -d 限制对象为目录本身,-l 提供详细信息共同作用的结果。
ls -alF 指令(以长格式显示当前目录下的所有文件和目录(包括隐藏内容))
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ ls -alF
total 20
drwxrwxr-x 5 ranjiaju ranjiaju 4096 Nov 17 23:32 ./
drwx------ 3 ranjiaju ranjiaju 4096 Nov 17 22:56 ../
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_1/
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_2/
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 17 23:06 test_1_3.txt
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:31 .test_1_4/
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 17 23:32 .test_1_5.txt
核心作用:ls -alF 是 ls 指令与 -a、-l、-F 三个选项的组合,用于以长格式显示当前目录下的所有文件和目录(包括隐藏内容),并为不同类型的文件添加识别符号,是查看目录内容的常用复合指令。
各选项的作用
-a:即 “all”,显示所有文件和目录,包括以.开头的隐藏文件 / 目录(如.test_1_4、.test_1_5.txt)以及代表当前目录的.和父目录的..。-l:即 “long format”,以长格式显示详细信息,包括文件类型、权限(如drwxrwxr-x)、硬链接数、所有者、所属组、大小、修改时间等。-F:即 “classify”,为不同类型的文件添加识别符号(方便快速区分类型):目录后加/(如test_1_1/、.test_1_4/),普通文件后无符号(如test_1_3.txt、.test_1_5.txt),可执行文件后加*(示例中无此类文件)。
结合示例说明:示例中执行 ls -alF 后,输出同时体现了三个选项的效果:
- 因
-a,显示了.、..及隐藏的.test_1_4、.test_1_5.txt; - 因
-l,列出了每一项的权限、所有者、大小等详细属性(如drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 17 23:05 test_1_1/); - 因
-F,所有目录后都加了/(如test_1_1/、./),清晰区分了目录和文件。
整体来看,ls -alF 能全面、详细地展示目录中所有内容的信息及类型,是日常查看目录细节的高效指令。
cd ~ 指令(将当前工作目录切换到当前用户的家目录)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ pwd
/home/ranjiaju/test_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ ls
test_1_1 test_1_2 test_1_3.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ cd test_1_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1_1]$ pwd
/home/ranjiaju/test_1/test_1_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1_1]$ cd ~
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
核心作用:cd ~ 中 ~ 是 Linux 中表示 “当前登录用户的家目录” 的特殊符号,因此 cd ~ 的作用是将当前工作目录切换到当前用户的家目录。
结合示例说明:示例中,初始目录为 /home/ranjiaju/test_1/test_1_1(位于 test_1_1 子目录中),执行 cd ~ 后,通过 pwd 指令验证,当前目录切换到了 /home/ranjiaju—— 这正是当前登录用户 ranjiaju 的家目录。
简单来说,cd ~ 是快速返回当前用户家目录的便捷指令,无论当前处于哪个层级的子目录中,执行后都能直接回到家目录。
cd - 指令(将当前工作目录切换到上一次所在的目录)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ls
test_1 test_2
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cd test_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ pwd
/home/ranjiaju/test_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ cd -
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cd -
/home/ranjiaju/test_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1]$ cd -
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cd -
/home/ranjiaju/test_1
核心作用:cd - 中 - 是 Linux 中表示 “上一个工作目录” 的特殊符号,因此 cd - 的作用是将当前工作目录切换到上一次所在的目录,实现两个目录之间的快速来回切换。
结合示例说明:示例中,操作流程清晰展示了 cd - 的功能:
- 初始目录为
/home/ranjiaju,执行cd test_1后切换到/home/ranjiaju/test_1; - 第一次执行
cd -,切换回上一个目录/home/ranjiaju; - 再次执行
cd -,又切换回之前的/home/ranjiaju/test_1; - 后续重复执行
cd -,始终在这两个目录之间来回切换。
这验证了 cd - 的核心功能:通过 - 记录并定位上一次的工作目录,快速实现两个目录间的切换,是提升操作效率的便捷指令。
cd / 指令(将当前工作目录切换到系统的根目录)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1_1]$ pwd
/home/ranjiaju/test_1/test_1_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_1_1]$ cd /
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ /]$ pwd
/
核心作用:cd / 中 / 是 Linux 系统中表示 “根目录” 的特殊符号(根目录是文件系统的最顶层目录,所有其他目录和文件都嵌套在其下),因此 cd / 的作用是将当前工作目录切换到系统的根目录。
结合示例说明:示例中,初始目录为 /home/ranjiaju/test_1/test_1_1(一个深层子目录),执行 cd / 后,通过 pwd 指令验证,当前目录切换到了 /—— 这正是系统的根目录。
简单来说,cd / 是直接切换到整个文件系统最顶层目录的指令,无论当前处于哪个层级的子目录中,执行后都能直接进入根目录。
安装 tree 命令的命令
[root@iZ2vc15k23y9vpuyi3tiqzZ ~]# yum install -y tree注意:必须使用 root 账号才能安装成功
tree 指令(以树形结构展示目录层级关系)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 8
drwxrwxr-x 5 ranjiaju ranjiaju 4096 Nov 17 23:32 test_1
drwxrwxr-x 3 ranjiaju ranjiaju 4096 Nov 18 14:07 test_2
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
├── test_1
│ ├── test_1_1
│ ├── test_1_2
│ └── test_1_3.txt
└── test_2
└── test_2_1
5 directories, 1 file
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree test_1
test_1
├── test_1_1
├── test_1_2
└── test_1_3.txt
2 directories, 1 file
tree . 指令
核心作用:tree 是用于以树形结构展示目录层级关系的指令,. 代表当前工作目录,因此 tree . 的作用是显示当前目录下所有子目录和文件的树形结构,直观呈现目录的嵌套关系。
结合示例说明:示例中,用户在 /home/ranjiaju 目录下执行 tree .,输出以 .(即当前目录 /home/ranjiaju)为根,展示了其下的 test_1 和 test_2 目录,以及这两个目录各自包含的子目录(如 test_1 下的 test_1_1、test_1_2)和文件(如 test_1 下的 test_1_3.txt),形成清晰的层级树状结构(用 ├──、└── 等符号表示层级),最后还统计了总目录数和文件数(“5 directories, 1 file”)。
tree test_1 指令
核心作用:tree test_1 中 test_1 是指定的目录名,因此该指令的作用是显示 test_1 目录下所有子目录和文件的树形结构,聚焦于该特定目录的层级关系。
结合示例说明:示例中执行 tree test_1 后,输出以 test_1 目录为根,仅展示其下的内容:子目录 test_1_1、test_1_2 和文件 test_1_3.txt,形成该目录专属的树形结构,并统计其下的目录数和文件数(“2 directories, 1 file”)。这与 tree . 不同,后者展示的是当前目录的整体结构,而 tree test_1 仅针对 test_1 目录进行展示。
mkdir -p 指令(递归创建多级嵌套目录)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 8
drwxrwxr-x 5 ranjiaju ranjiaju 4096 Nov 17 23:32 test_1
drwxrwxr-x 3 ranjiaju ranjiaju 4096 Nov 18 14:07 test_2
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
├── test_1
│ ├── test_1_1
│ ├── test_1_2
│ └── test_1_3.txt
└── test_2
└── test_2_1
5 directories, 1 file
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ mkdir -p test_3/test_3_1/test_3_2/test_3_3
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 12
drwxrwxr-x 5 ranjiaju ranjiaju 4096 Nov 17 23:32 test_1
drwxrwxr-x 3 ranjiaju ranjiaju 4096 Nov 18 14:07 test_2
drwxrwxr-x 3 ranjiaju ranjiaju 4096 Nov 18 14:56 test_3
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
├── test_1
│ ├── test_1_1
│ ├── test_1_2
│ └── test_1_3.txt
├── test_2
│ └── test_2_1
└── test_3
└── test_3_1
└── test_3_2
└── test_3_3
9 directories, 1 file
核心作用:mkdir -p 中 -p 是 “parents” 的缩写,用于递归创建多级嵌套目录。即当要创建的目录路径中包含不存在的父目录时,-p 会自动创建所有缺失的父目录,避免因父目录不存在而报错。
结合示例说明:指令 mkdir -p test_3/test_3_1/test_3_2/test_3_3 的目标是创建一条嵌套目录路径:test_3 → test_3_1 → test_3_2 → test_3_3。
由于初始状态下这些目录均不存在,-p 选项确保了系统会按层级依次创建所有目录:先创建 test_3,再在其下创建 test_3_1,接着在 test_3_1 下创建 test_3_2,最后在 test_3_2 下创建 test_3_3。
执行后,通过 ll 可见新增的 test_3 目录,通过 tree . 可验证完整的嵌套结构(test_3/test_3_1/test_3_2/test_3_3)已成功创建,说明 mkdir -p 高效完成了多级目录的递归创建。
rm 指令(删除文件或目录)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
├── test_1
│ ├── test_1_1
│ ├── test_1_2
│ └── test_1_3.txt
├── test_2
│ └── test_2_1
├── test_3
│ └── test_3_1
│ └── test_3_2
│ └── test_3_3
└── test_4.txt
9 directories, 2 files
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ rm test_4.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
├── test_1
│ ├── test_1_1
│ ├── test_1_2
│ └── test_1_3.txt
├── test_2
│ └── test_2_1
└── test_3
└── test_3_1
└── test_3_2
└── test_3_3
9 directories, 1 file
核心作用:rm 是 “remove” 的缩写,用于删除文件或目录,rm test_4.txt 则是针对指定的普通文件 test_4.txt 执行删除操作。
结合示例说明:示例中,初始目录下存在文件 test_4.txt(通过 tree . 可见其在根目录下)。执行 rm test_4.txt 后,再次通过 tree . 查看,test_4.txt 已从目录结构中消失,说明该文件被成功删除。
简单来说,rm test_4.txt 的作用是删除当前工作目录下名为 test_4.txt 的普通文件,执行后该文件将被移除。
rm -r 指令(删除指定的目录及其包含的所有子目录和文件)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
├── test_1
│ ├── test_1_1
│ ├── test_1_2
│ └── test_1_3.txt
├── test_2
└── test_3
└── test_3_1
└── test_3_2
└── test_3_3
8 directories, 1 file
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ rm -r test_2
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
├── test_1
│ ├── test_1_1
│ ├── test_1_2
│ └── test_1_3.txt
└── test_3
└── test_3_1
└── test_3_2
└── test_3_3
7 directories, 1 file
核心作用:rm -r 中 -r 是 “recursive”(递归)的缩写,该组合指令用于删除指定的目录及其包含的所有子目录和文件(普通 rm 指令无法直接删除目录,必须通过 -r 选项开启递归删除功能)。
结合示例说明:示例中,初始目录下存在 test_2 目录(通过 tree . 可见其为一个顶层目录)。执行 rm -r test_2 后,-r 选项确保系统会递归处理 test_2 目录:不仅删除目录本身,还会删除其内部可能包含的所有子目录和文件(示例中 test_2 可能为空,但指令仍能正常执行)。
再次通过 tree . 查看,test_2 目录已从目录结构中消失,说明该目录及其所有内容被成功删除。简单来说,rm -r test_2 是删除 test_2 目录及其中所有内容的指令。
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
├── test_1
│ ├── test_1_1
│ ├── test_1_2
│ └── test_1_3.txt
└── test_3
└── test_3_1
└── test_3_2
└── test_3_3
7 directories, 1 file
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ rm -r test_3
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
└── test_1
├── test_1_1
├── test_1_2
└── test_1_3.txt
3 directories, 1 file
结合示例说明:示例中,test_3 是一个包含多级子目录的目录(结构为 test_3/test_3_1/test_3_2/test_3_3)。执行 rm -r test_3 时,-r 选项会触发递归删除机制:从最内层的 test_3_3 开始,依次删除所有子目录(test_3_2、test_3_1),最后删除 test_3 目录本身,确保整个目录树被彻底移除。
执行后,通过 tree . 查看,test_3 及其所有子目录已从目录结构中消失,仅剩 test_1 目录,说明 rm -r test_3 成功删除了整个 test_3 目录树。
简单来说,rm -r test_3 是删除 test_3 目录及其所有嵌套内容的指令,适用于处理包含子目录的非空目录。
rm -rf 指令(强制、递归地删除指定目录及其包含的所有子目录、文件)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
└── test_1
├── test_1_1
├── test_1_2
└── test_1_3.txt
3 directories, 1 file
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ rm -rf test_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
0 directories, 0 files
核心作用:rm -rf 是 rm 指令与 -r(recursive,递归)和 -f(force,强制)两个选项的组合,用于强制、递归地删除指定目录及其包含的所有子目录、文件,且过程中不弹出任何确认提示。
各选项的作用
-r:开启递归删除模式,确保能删除非空目录(包括目录内的所有子目录和文件),否则普通rm无法删除目录。-f:开启强制删除模式,忽略不存在的文件 / 目录,且删除过程中不向用户弹出确认提示(如 “是否删除只读文件” 等),直接执行删除操作。
结合示例说明:示例中,test_1 是一个包含子目录(test_1_1、test_1_2)和文件(test_1_3.txt)的非空目录。执行 rm -rf test_1 时:
- 因
-r,系统会递归处理test_1内部的所有内容:先删除最内层的子目录和文件,再逐层删除外层目录,最终删除test_1本身; - 因
-f,整个过程不会出现任何确认提示(即使目录内有只读文件也会直接删除),操作更直接。
执行后,通过 tree . 查看,test_1 及其所有子目录、文件已完全消失,目录结构为空(“0 directories, 0 files”),说明 rm -rf test_1 成功强制删除了整个 test_1 目录树。
需要注意的是,rm -rf 操作具有高风险(删除后无法恢复),使用时需格外谨慎,避免误删重要文件或目录。
ls * 指令(匹配当前目录下所有 非隐藏的文件和目录)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 0
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 19 17:35 test_1.c
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 19 17:35 test_2.c
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 19 17:35 test_3.c
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 19 17:35 test_4.txt
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 19 17:35 test_5.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ls *
test_1.c test_2.c test_3.c test_4.txt test_5.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ls *.c
test_1.c test_2.c test_3.c
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ls *.txt
test_4.txt test_5.txt
一、ls * 指令
核心作用:* 匹配当前目录下所有 非隐藏的文件和目录(不匹配以 . 开头的隐藏内容),因此 ls * 等价于普通 ls 指令,用于列出当前目录下所有非隐藏的内容。
结合示例说明:示例中,当前目录下有 3 个 .c 后缀文件、2 个 .txt 后缀文件(均为非隐藏文件)。执行 ls * 后,输出所有这些文件(test_1.c test_2.c test_3.c test_4.txt test_5.txt),与 ll 指令显示的非隐藏文件列表完全一致,本质是通过 * 匹配所有非隐藏内容并列出。
二、ls *.c 指令
核心作用:*.c 是通配符组合,* 匹配 “任意前缀”,.c 是固定 “后缀”,整体含义是 匹配当前目录下所有以 .c 为后缀的非隐藏文件,因此 ls *.c 用于列出当前目录中所有 .c 类型的文件。
结合示例说明:示例中当前目录有 test_1.c、test_2.c、test_3.c 三个以 .c 为后缀的文件,*.c 精准匹配这三个文件(前缀 test_1、test_2、test_3 被 * 匹配,后缀固定为 .c)。执行 ls *.c 后,仅输出这三个文件,实现了按文件类型(.c 后缀)的快速筛选。
三、ls *.txt 指令
核心作用:与 ls *.c 逻辑一致,*.txt 中 * 匹配 “任意前缀”,.txt 是固定 “后缀”,整体含义是 匹配当前目录下所有以 .txt 为后缀的非隐藏文件,因此 ls *.txt 用于列出当前目录中所有 .txt 类型的文件。
结合示例说明:示例中当前目录有 test_4.txt、test_5.txt 两个以 .txt 为后缀的文件,*.txt 精准匹配这两个文件(前缀 test_4、test_5 被 * 匹配,后缀固定为 .txt)。执行 ls *.txt 后,仅输出这两个文件,同样实现了按 .txt 后缀筛选文件的效果。
总结
这三个指令的核心是利用 * 通配符的 “模糊匹配” 功能:
ls *:匹配所有非隐藏内容,等价于普通ls;ls *.后缀:匹配所有以指定后缀命名的非隐藏文件,是按文件类型快速筛选的常用操作。
rm -rf * 指令(强制、递归地删除当前目录下所有非隐藏的文件和目录)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
└── test_1
└── test_1_1
└── test_1_2
└── test_1_3
4 directories, 0 files
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ rm -rf *
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
0 directories, 0 files
核心作用:rm -rf * 是 rm -rf 与通配符 * 的组合,用于强制、递归地删除当前目录下所有非隐藏的文件和目录(* 匹配所有非隐藏内容,-r 递归删除目录及子内容,-f 强制无确认提示),是删除当前目录下所有可见内容的高效但高风险指令。
各核心组件的作用
rm:基础删除指令,用于移除文件或目录;-r(recursive,递归):开启递归删除模式,确保能删除非空目录及其包含的所有子目录、文件(无此选项则无法删除目录);-f(force,强制):强制删除,忽略不存在的内容,且不弹出任何确认提示(如 “是否删除只读文件”“是否删除非空目录” 等),直接执行删除;*(通配符):匹配当前目录下所有非隐藏的文件和目录(不匹配以.开头的隐藏内容),相当于 “当前目录下所有可见内容” 的快捷指代。
结合示例说明:示例中,当前目录下仅存在多级嵌套的非隐藏目录 test_1(结构为 test_1/test_1_1/test_1_2/test_1_3)。执行 rm -rf * 时:
- 通配符
*首先匹配到当前目录下唯一的非隐藏内容 ——test_1目录; -r选项触发递归删除:从最内层的test_1_3开始,逐层删除所有子目录(test_1_2、test_1_1),最终删除test_1目录本身;-f选项确保整个过程无任何确认提示,即使目录结构复杂也直接执行删除。
执行后,通过 tree . 查看,当前目录已无任何文件和目录(“0 directories, 0 files”),说明所有非隐藏内容被彻底删除。
rm -i 指令(删除文件前会向用户输出确认提示)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 0
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 19 19:34 test_1.c
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ rm -i test_1.c
rm: remove regular empty file ‘test_1.c’? n
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 0
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 19 19:34 test_1.c
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ rm -i test_1.c
rm: remove regular empty file ‘test_1.c’? y
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 0
各组件的作用
rm:基础删除指令,用于移除文件(默认无法直接删除目录);-i:开启 “交互模式”,删除文件前会向用户输出确认提示,只有用户输入确认指令(如y),才会执行删除;输入否定指令(如n),则取消删除;test_1.c:指定要删除的目标文件(当前目录下的普通空文件)。
结合示例分步说明:示例中两次执行 rm -i test_1.c,因用户不同回应产生不同结果,清晰体现了 -i 选项的交互特性:
-
第一次执行
rm -i test_1.c:系统弹出提示rm: remove regular empty file ‘test_1.c’?(意为 “是否删除普通空文件 ‘test_1.c’?”);用户输入n(no,否定),系统取消删除操作;执行ll验证,test_1.c仍存在,目录内容无变化。 -
第二次执行
rm -i test_1.c:系统再次弹出相同的确认提示;用户输入y(yes,确认),系统执行删除操作;执行ll验证,test_1.c已消失(目录显示total 0),文件被成功删除。
核心价值与总结
rm -i 的核心作用是 “防误删”—— 相比 rm(直接删除)、rm -f(强制无提示删除),-i 选项通过 “用户确认” 环节,给误操作提供了挽回机会,尤其适合删除重要文件时使用。
简单来说,rm -i test_1.c 就是 “在删除 test_1.c 文件前,让系统询问我是否确认删除,我同意才删,不同意就不删” 的安全指令。
man 指令(帮助查询工具)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ man ls
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ man man
核心作用:man 是 manual(手册)的缩写,是 Linux 系统中最核心的 帮助查询工具,用于查看指令、配置文件、系统调用、函数等的详细官方帮助手册 —— 手册中包含语法格式、选项含义、使用示例、注意事项等完整信息,是学习和排查 Linux 指令用法的 “必备工具”。
一、基本用法格式
man [要查询的对象]
- 查询对象可以是 指令(如
ls、rm、cd)、配置文件(如/etc/passwd)、系统函数 等; - 执行后会打开一个交互式的手册页面,支持翻页、搜索、退出等操作。
二、结合示例解释
示例中两个 man 指令的具体作用:
-
man ls:查询ls指令的帮助手册执行后会打开ls指令的完整手册,内容包括:ls的核心功能说明;- 所有支持的选项(如
-l、-a、-F、-d等)的详细含义(对应之前学习的ls -l、ls -a等组合); - 语法格式(如
ls [选项] [文件/目录]); - 示例用法、注意事项等。相当于 “
ls指令的官方说明书”,之前遇到的ls相关选项疑问,都能在其中找到答案。
-
man man:查询man指令本身的帮助手册执行后会打开man指令的帮助手册,说明man自己的用法:man的选项(如如何指定手册章节、如何搜索手册内容等);- 手册的章节分类(如第 1 章是用户指令、第 5 章是配置文件等,进阶知识);
- 交互式操作方法(如翻页、搜索、退出)。相当于 “
man工具的使用指南”,帮助用户更好地使用man查询其他内容。
三、手册页面的常用操作(关键!)
打开 man 手册后,默认进入交互式视图,常用操作如下:
| 操作按键 | 功能描述 |
|---|---|
| 空格键 | 向下翻一页 |
b 键 |
向上翻一页 |
/关键词 |
向下搜索 “关键词”(如在 man ls 中输入 / -a,可快速定位 -a 选项的说明) |
n 键 |
跳转到下一个搜索结果 |
N 键 |
跳转到上一个搜索结果 |
q 键 |
退出手册页面(返回终端) |
四、总结
man 指令的核心价值是 “获取权威帮助”—— 当你不确定某个指令的语法、选项含义,或想了解更多用法时,无需额外查资料,直接用 man 指令名 就能获取完整、准确的官方说明。
示例中:
man ls是 “查ls怎么用”;man man是 “查man自己怎么用”;本质都是通过官方手册解决 “用法疑问”,是 Linux 系统中最基础、最实用的工具之一。
echo 指令(输出字符串、变量值或空行);cat 指令(读取文件内容并打印到终端)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 0
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 19 20:02 test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ echo "hello Linux"
hello Linux
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ echo "hello Linux" > test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 4
-rw-rw-r-- 1 ranjiaju ranjiaju 12 Nov 19 20:03 test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat test_1.txt
hello Linux
一、echo 指令
核心作用:echo 是 Linux 中用于 输出字符串、变量值或空行 的基础指令,默认将内容打印到终端屏幕,也可通过重定向符号(如 >)写入文件。
结合示例说明
示例中 echo 有两种典型用法,对应不同场景:
1. 直接输出字符串到终端
echo "hello Linux"
- 作用:将引号内的字符串
hello Linux直接打印到终端; - 执行结果:终端显示
hello Linux(字符串原样输出,引号仅用于界定字符串范围,输出时不包含引号)。
2. 重定向输出到文件(覆盖写入)
echo "hello Linux" > test_1.txt
- 核心逻辑:
echo输出的字符串不打印到终端,而是通过重定向符号>写入指定文件test_1.txt; - 关键细节:
>是 “覆盖重定向”—— 若文件已存在,会清空文件原有内容后写入新内容;若文件不存在,会自动创建该文件; - 示例验证:
- 执行前
test_1.txt是大小为 0 的空文件; - 执行后
ll显示文件大小变为 12 字节(hello Linux共 11 个字符 + 系统自动添加的换行符\n,合计 12 字节),说明字符串成功写入文件。
- 执行前
补充说明
- 字符串可加引号(单引号
'或双引号"),也可不加(如echo hello Linux),但当字符串包含空格、特殊符号(如$、*)时,建议加引号避免解析错误; - 除了固定字符串,
echo还可输出变量值(如echo $PATH输出环境变量 PATH 的内容)。
二、cat 指令
核心作用:cat 是 concatenate(连接)的缩写,基础用法是 读取文件内容并打印到终端,还可用于连接多个文件内容、创建简单文件等(示例中展示基础的 “查看文件内容” 用法)。
结合示例说明
cat test_1.txt
- 作用:读取
test_1.txt文件的全部内容,并将内容原样输出到终端; - 执行结果:终端显示
hello Linux,与echo写入文件的内容一致,验证了文件写入成功; - 核心价值:快速查看文件的文本内容,适合查看小型文本文件(大型文件更适合用
less或more指令翻页查看)。
补充常用用法
- 查看多个文件内容:
cat file1.txt file2.txt(依次输出 file1.txt 和 file2.txt 的内容); - 连接文件内容并写入新文件:
cat file1.txt file2.txt > newfile.txt(将两个文件内容合并后写入 newfile.txt); - 创建简单文件:
cat > newfile.txt(输入后按回车,再输入文件内容,最后按Ctrl+D结束输入,可快速创建小型文本文件)。
总结
| 指令 | 核心用途 | 示例对应效果 |
|---|---|---|
echo |
输出字符串(终端 / 文件) | 向终端打印或向文件写入内容 |
cat |
读取文件内容并输出到终端 | 查看 test_1.txt 中的写入内容 |
两者常配合使用:echo 负责 “生成内容”,cat 负责 “验证内容”,是 Linux 中处理小型文本的基础组合。
cp 指令(将文件或目录从一个位置复制到另一个位置)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 4
-rw-rw-r-- 1 ranjiaju ranjiaju 12 Nov 19 20:03 test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cp test_1.txt test_2.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 8
-rw-rw-r-- 1 ranjiaju ranjiaju 12 Nov 19 20:03 test_1.txt
-rw-rw-r-- 1 ranjiaju ranjiaju 12 Nov 19 20:21 test_2.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat test_2.txt
hello Linux
cp 指令核心作用
cp 是 copy(复制)的缩写,用于将文件或目录从一个位置复制到另一个位置,目标可以是新文件名(重命名复制)或指定目录(保留原名复制)。
cp test_1.txt test_2.txt将源文件 test_1.txt 复制为目标文件 test_2.txt,属于 “重命名复制”(在同一目录下生成新文件)。
- 若目标文件
test_2.txt不存在:自动创建该文件,复制源文件的全部内容(示例中test_1.txt的hello Linux被完整复制); - 若目标文件已存在:会直接覆盖原有内容(无默认确认提示,需谨慎);
- 示例验证:执行后
ll显示新增test_2.txt,大小与test_1.txt均为 12 字节,cat test_2.txt输出hello Linux,说明复制成功。
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 8
-rw-rw-r-- 1 ranjiaju ranjiaju 12 Nov 19 20:03 test_1.txt
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 19 20:41 test_2
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat test_1.txt
hello Linux
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cd test_2
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_2]$ cp ../test_1.txt ../test_2.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_2]$ pwd
/home/ranjiaju/test_2
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_2]$ cd ..
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 12
-rw-rw-r-- 1 ranjiaju ranjiaju 12 Nov 19 20:03 test_1.txt
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 19 20:41 test_2
-rw-rw-r-- 1 ranjiaju ranjiaju 12 Nov 19 20:42 test_2.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat test_2.txt
hello Linux
cp 指令核心作用(结合相对路径)
cp 是 copy(复制)的缩写,用于复制文件 / 目录,此处通过 相对路径 ../ 指定源文件和目标文件的位置,实现跨当前目录的文件复制,../ 代表 “当前目录的父目录”。
cp ../test_1.txt ../test_2.txt该指令是在 test_2 目录(当前工作目录)下执行的,核心是通过相对路径定位父目录(/home/ranjiaju)中的文件,完成复制操作:
../test_1.txt(源文件):../表示当前目录(test_2)的父目录(即/home/ranjiaju),因此源文件是父目录下已存在的test_1.txt;../test_2.txt(目标文件):同样通过../定位到父目录,目标是在父目录下创建新文件test_2.txt,并将源文件内容复制进去;- 执行逻辑:无论当前处于哪个子目录,只要通过
../正确定位到父目录,就能跨目录复制文件。示例中,用户在test_2目录下执行该指令,最终在父目录(/home/ranjiaju)中生成了test_2.txt,且cat test_2.txt输出hello Linux,与源文件内容一致,说明复制成功。
关键补充:相对路径 ../ 说明
../是 Linux 中的相对路径符号,用于表示 “当前工作目录的直接父目录”,可叠加使用(如../../表示父目录的父目录);- 示例中当前目录是
/home/ranjiaju/test_2,../直接指向/home/ranjiaju,因此指令等价于在父目录下执行cp test_1.txt test_2.txt,但无需切换到父目录即可完成操作,灵活便捷; - 若目标文件(
../test_2.txt)已存在,会直接覆盖其内容(无默认确认提示);若不存在,则自动在父目录中创建该文件并复制内容。
cp -r 指令(复制目录及其包含的所有嵌套子目录和文件)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
└── test_1
└── test_1_1
└── test_1_2
└── test_1_3
4 directories, 0 files
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cp -r test_1 test_2
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
├── test_1
│ └── test_1_1
│ └── test_1_2
│ └── test_1_3
└── test_2
└── test_1_1
└── test_1_2
└── test_1_3
8 directories, 0 files
cp 是 copy(复制)的缩写,-r 是 recursive(递归)选项,两者组合用于 复制目录及其包含的所有嵌套子目录和文件—— 默认 cp 指令无法直接复制目录,-r 选项会强制递归遍历目录结构,确保整个目录树被完整复制。
cp -r test_1 test_2该指令的核心是复制多级嵌套目录,具体逻辑如下:
- 源对象:
test_1是待复制的源目录,其下包含test_1_1/test_1_2/test_1_3多级子目录; - 目标对象:
test_2是复制后的目标目录,执行前不存在,因此系统会自动创建test_2目录; - 递归复制逻辑:
-r选项触发递归操作,从test_1的最内层子目录test_1_3开始,逐层复制所有子目录和文件(示例中目录为空,仅复制目录结构),最终在test_2下还原test_1的完整层级结构; - 示例验证:执行后
tree .显示test_2与test_1的目录结构完全一致(均为test_1_1/test_1_2/test_1_3),总目录数从 4 变为 8,说明整个目录树被成功复制。
关键补充说明
- 若目标目录已存在:
cp -r 源目录 已存在的目标目录会在已存在的目标目录下创建源目录的副本。例如cp -r test_1 ./test_dir/,会在test_dir目录下新增test_1子目录及所有内容; - 若目标目录不存在:自动创建目标目录,并将源目录的完整内容(包括内部所有子目录、文件)复制到新目录中(示例即此场景);
- 不可省略
-r:若直接执行cp test_1 test_2(无-r),系统会报错cp: omitting directory ‘test_1’(忽略目录test_1),因为默认cp仅支持复制文件。
mv 指令(对文件或目录执行 重命名 操作)(把文件 / 目录 移动到指定位置)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 8
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 19 22:20 test_1
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 19 22:20 test_22
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ mv test_22 test_2
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 8
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 19 22:20 test_1
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 19 22:20 test_2
mv 是 move(移动 / 重命名)的缩写,用于对文件或目录执行 重命名 操作,或把文件 / 目录 移动到指定位置,操作过程中不改变文件 / 目录的内容、权限和所有者信息,仅修改其路径或名称。
mv test_22 test_2该指令属于 “同一目录下的重命名操作”,核心逻辑如下:
- 源对象:
test_22是当前目录(/home/ranjiaju)下已存在的目录; - 目标对象:
test_2是重命名后的新名称,执行前该名称在当前目录下不存在; - 执行效果:系统直接将
test_22目录的名称修改为test_2,目录内的内容、权限(drwxrwxr-x)、创建时间等属性均保持不变; - 示例验证:执行前
ll显示test_22目录,执行后test_22消失,新增test_2目录,且两者的权限、大小完全一致,说明重命名成功。
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 8
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 19 22:20 test_1
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 19 22:20 test_2
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cd test_2
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_2]$ pwd
/home/ranjiaju/test_2
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_2]$ mkdir test_3
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_2]$ ll
total 4
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 19 22:26 test_3
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_2]$ mv test_3 ..
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_2]$ ll
total 0
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_2]$ ll ..
total 12
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 19 22:20 test_1
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 19 22:27 test_2
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 19 22:26 test_3
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_2]$ mv ../test_3 .
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test_2]$ ll
total 4
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 19 22:26 test_3
mv test_3 .. 指令核心作用
mv 是 move(移动)的缩写,.. 代表当前目录的父目录,该指令用于将当前目录下的 test_3 目录,完整移动到当前目录的父目录中,目录名称、内容、权限等属性均保持不变。
当前工作目录为 /home/ranjiaju/test_2(通过 pwd 验证),指令各部分逻辑如下:
test_3:源对象,是当前目录(test_2)下刚创建的空目录;..:目标位置,Linux 中固定表示 “当前目录的直接父目录”,此处即/home/ranjiaju;- 执行效果:系统将
test_2目录内的test_3,直接移动到父目录下,不改变test_3的任何属性; - 示例验证:执行后
ll显示当前目录(test_2)下无test_3(total 0),ll ..显示父目录新增test_3目录,说明移动成功。
mv ../test_3 . 指令核心作用
mv 用于移动文件 / 目录,../ 指向父目录,. 代表当前目录,该指令用于将父目录下的 test_3 目录,移动回当前工作目录(test_2)中,实现目录位置的 “回移”。
当前工作目录仍为 /home/ranjiaju/test_2,指令各部分逻辑如下:
../test_3:源对象,../先定位到父目录(/home/ranjiaju),再指定该目录下的test_3目录;.:目标位置,Linux 中固定表示 “当前工作目录”,此处即/home/ranjiaju/test_2;- 执行效果:从父目录找到
test_3,将其完整移动到当前目录,test_3的属性(权限、创建时间等)无任何变化; - 示例验证:执行后
ll显示当前目录(test_2)重新出现test_3目录(total 4),说明移动成功,相当于将之前移出的test_3移回原位置。
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
├── test_1
└── test_2
2 directories, 0 files
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ mv test_2 test_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree .
.
└── test_1
└── test_2
2 directories, 0 files
mv 是 move(移动)的缩写,当目标对象是 已存在的目录 时,该指令用于将源目录(test_2)完整移动到目标目录(test_1)内部,成为目标目录的子目录,不改变源目录的内容、权限等属性。
指令具体逻辑与示例验证
- 源对象:
test_2是当前目录(/home/ranjiaju)下已存在的空目录; - 目标对象:
test_1是当前目录下已存在的目录(非文件),这是触发 “移动入目录” 行为的关键; - 执行规则:
mv指令的核心判断逻辑 —— 若目标是已存在的目录,无论源对象是文件还是目录,都会将源对象 “移入” 该目标目录,而非重命名; - 示例效果:执行前
tree .显示test_1和test_2是同级顶层目录;执行后tree .显示test_2已成为test_1的子目录(结构为test_1/test_2),总目录数仍为 2,说明仅改变了test_2的存放位置,目录本身及内容(此处为空)未发生任何变化。
which 指令(查找指定指令对应的可执行文件路径)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ which ls
alias ls='ls --color=auto'
/usr/bin/ls
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ which ll
alias ll='ls -l --color=auto'
/usr/bin/ls
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ which pwd
/usr/bin/pwd
which 是 Linux 中用于 查找指定指令对应的可执行文件路径 的工具,同时会自动显示该指令是否存在系统别名(alias),仅查找系统环境变量 PATH 中配置的目录下的可执行文件,不包含内置指令、自定义脚本(未加入 PATH)等。
which ls 执行结果解释
输出内容分为两部分,清晰展示 ls 指令的实际执行逻辑:
alias ls='ls --color=auto':表示系统为ls指令设置了别名,实际执行ls时,等同于执行ls --color=auto(--color=auto选项用于自动为文件 / 目录添加颜色区分,提升可读性);/usr/bin/ls:表示ls指令的原始可执行文件路径,该文件是系统预装的核心工具,存放于/usr/bin/(系统标准可执行文件目录)下。
which ll 执行结果解释
ll 并非 Linux 原生指令,而是 ls 指令的别名,输出结果体现这一本质:
alias ll='ls -l --color=auto':明确ll是ls -l --color=auto的简化别名(-l选项用于以长格式显示文件 / 目录详情,即ll等价于ls -l);/usr/bin/ls:说明ll最终依赖的可执行文件仍是ls的原始文件,ll仅为简化输入的 “快捷方式”,无独立可执行文件。
which pwd 执行结果解释
输出仅显示 /usr/bin/pwd,说明两个关键信息:
pwd指令未设置任何系统别名,执行时直接调用原始可执行文件;- 其可执行文件路径为
/usr/bin/pwd,同样存放于系统标准可执行文件目录,是系统预装的基础工具。
alias 指令(创建自定义指令别名)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ls -a -l -F
total 36
drwx------ 5 ranjiaju ranjiaju 4096 Nov 20 14:45 ./
drwxr-xr-x. 4 root root 4096 Nov 17 00:36 ../
-rw------- 1 ranjiaju ranjiaju 1594 Nov 19 20:32 .bash_history
-rw-r--r-- 1 ranjiaju ranjiaju 18 Oct 31 2018 .bash_logout
-rw-r--r-- 1 ranjiaju ranjiaju 193 Oct 31 2018 .bash_profile
-rw-r--r-- 1 ranjiaju ranjiaju 231 Oct 31 2018 .bashrc
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 20 14:45 test_1/
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 20 14:45 test_2/
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 20 14:45 test_3/
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ alias test_cmd='ls -a -l -F';
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ test_cmd
total 36
drwx------ 5 ranjiaju ranjiaju 4096 Nov 20 14:45 ./
drwxr-xr-x. 4 root root 4096 Nov 17 00:36 ../
-rw------- 1 ranjiaju ranjiaju 1594 Nov 19 20:32 .bash_history
-rw-r--r-- 1 ranjiaju ranjiaju 18 Oct 31 2018 .bash_logout
-rw-r--r-- 1 ranjiaju ranjiaju 193 Oct 31 2018 .bash_profile
-rw-r--r-- 1 ranjiaju ranjiaju 231 Oct 31 2018 .bashrc
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 20 14:45 test_1/
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 20 14:45 test_2/
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 20 14:45 test_3/
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ alias test_cmd=' ';
alias 是 Linux 中用于 创建自定义指令别名 的工具,可将复杂的命令(含选项、参数)简化为简短的自定义名称,执行该别名时,等同于执行其对应的原始命令,核心目的是简化重复输入、提升操作效率。
alias test_cmd='ls -a -l -F' 指令解释
这是创建别名的标准语法,结构为 alias 自定义别名='原始命令及选项',各部分逻辑如下:
alias:创建别名的关键字,触发别名定义操作;test_cmd:自定义的别名名称,可自由命名(需符合命名规范,不与系统原有指令冲突);'ls -a -l -F':别名对应的原始命令,需用单引号或双引号包裹(避免特殊符号解析错误),此处是ls指令加三个选项的组合(-a显示隐藏文件、-l长格式显示、-F为目录加/标记);- 执行逻辑:定义完成后,终端中输入
test_cmd,系统会自动替换为ls -a -l -F并执行。
test_cmd 执行效果验证
示例中执行 test_cmd 后,输出结果与直接执行 ls -a -l -F 完全一致(均显示当前目录下所有文件 / 目录,含隐藏文件、长格式详情、目录加 / 标记),说明别名已成功关联原始命令,执行别名等价于执行原始复杂命令,达到了简化输入的目的。
关键补充说明
- 别名的有效期:直接用
alias 别名='命令'创建的是 临时别名,仅在当前终端会话中有效,关闭终端或切换用户后,别名会自动失效; - 查看别名:
- 输入
alias:列出当前终端中所有已定义的别名(含系统默认别名,如之前which ll看到的ll='ls -l --color=auto'); - 输入
alias 别名(如alias test_cmd):仅查看指定别名对应的原始命令;
- 输入
- 删除别名:输入
unalias 别名(如unalias test_cmd),可删除已创建的别名,删除后执行该名称会提示 “命令未找到”; - 永久别名:若需别名永久生效,需将
alias 别名='命令'写入用户配置文件(如~/.bashrc或~/.bash_profile),保存后执行source ~/.bashrc使配置立即生效(重启终端也会自动加载)。
alias test_cmd=' '; 指令详细解释
语法结构仍为 alias 自定义别名='原始内容',但核心差异在于 “原始内容” 为空,各部分逻辑如下:
alias:创建别名的关键字,触发别名定义操作;test_cmd:自定义的别名名称,占用该名称作为指令快捷方式;' ':单引号内是别名对应的 “原始内容”,此处仅为一个空格(无任何可执行命令、选项或参数),本质是 “空命令”;;:命令结束符,用于明确标记该alias指令执行完毕,可选但符合 Shell 命令书写规范。
执行 test_cmd 的效果
当在终端输入 test_cmd 并回车时,系统会执行其对应的 “空命令”:
- 终端无任何输出结果,也不会执行任何文件操作、目录变更等有效行为;
- 等价于直接在终端输入一个空格后回车,仅触发一次空执行,无实际功能。
echo > 指令 和 echo >> 指令(将字符串追加到文件末尾)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 0
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 20 15:15 test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ echo "hello" > test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat test_1.txt
hello
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ echo "hello Linux" > test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat test_1.txt
hello Linux
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ echo "hello Linux" >> test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat test_1.txt
hello Linux
hello Linux
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ >test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat test_1.txt
echo "hello Linux" >> test_1.txt 指令核心作用
echo 输出字符串,>> 是 追加重定向符号,该指令用于将字符串 hello Linux 追加到 test_1.txt 文件末尾,不会覆盖文件原有内容,仅在尾部新增内容。
指令各部分逻辑与示例验证:
echo "hello Linux":生成字符串hello Linux,默认应打印到终端;>>:追加重定向符号,功能是 “将输出内容添加到文件末尾”,区别于>(覆盖文件原有内容);test_1.txt:目标文件,执行前已包含一行hello Linux(通过echo "hello Linux" > test_1.txt写入);- 执行效果:字符串被追加到文件尾部,文件内容变为两行
hello Linux; - 示例验证:执行后
cat test_1.txt输出两行相同字符串,说明内容未被覆盖,仅新增,验证追加成功。
>test_1.txt 指令核心作用
单独使用 重定向符号 > 加文件名,用于 快速清空目标文件内容,使文件变为大小为 0 的空文件,不删除文件本身,仅重置其内容。
指令逻辑与示例验证:
- 语法特性:
>符号单独使用时,无需搭配echo等输出指令,直接指向文件即可触发 “清空” 行为; - 执行原理:系统会打开
test_1.txt文件,截断其所有原有内容(无论文件之前有多少行数据),仅保留空文件结构; - 示例验证:执行前
test_1.txt含两行字符串,执行后cat test_1.txt无任何输出,ll显示文件大小回归 0 字节,说明文件内容已被清空,文件本身仍存在。
cat -n 指令(读取文件内容并输出到终端)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 4
-rw-rw-r-- 1 ranjiaju ranjiaju 60 Nov 20 15:28 test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat test_1.txt
hello Linux
hello Linux
hello Linux
hello Linux
hello Linux
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat -n test_1.txt
1 hello Linux
2 hello Linux
3 hello Linux
4 hello Linux
5 hello Linux
cat 是读取文件内容并输出到终端的基础指令,-n(number,行号)是其常用选项,两者组合用于 读取文件内容的同时,为每一行内容添加连续的行号(从 1 开始),直观展示文件的行结构,方便查看行分布或定位特定行。
cat -n test_1.txt 指令详细解释
cat:核心功能是读取目标文件的全部内容,默认原样输出到终端;-n:开启行号显示功能,会自动为文件中每一行(非空行)添加连续递增的数字编号,行号与内容之间用制表符分隔,格式清晰;test_1.txt:指定要读取并添加行号的目标文件,示例中该文件包含 5 行重复的hello Linux字符串。
示例执行效果验证
执行前 cat test_1.txt 仅输出 5 行字符串,无行号标识;执行 cat -n test_1.txt 后:
- 每一行内容前都新增了行号(
1到5),行号左对齐显示,与文本内容明确分隔; - 行号从 1 开始连续编号,不会跳过任何非空行(示例中无空白行,若有空白行,
-n不会为空白行编号,仅对有内容的行计数); - 输出结果既保留了文件原始内容,又通过行号直观体现了文件共 5 行,实现了 “内容 + 行号” 的同步展示。
cat -b 指令(读取文件内容时,仅为非空白行添加连续行号)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 4
-rw-rw-r-- 1 ranjiaju ranjiaju 75 Nov 20 15:33 test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat -n test_1.txt
1 hello Linux
2 hello Linux
3 hello Linux
4
5
6
7 hello Linux
8 hello Linux
9 hello Linux
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat -b test_1.txt
1 hello Linux
2 hello Linux
3 hello Linux
4 hello Linux
5 hello Linux
6 hello Linux
cat 是读取文件内容并输出到终端的基础指令,-b(blank,空白行)是其行号相关选项,两者组合用于 读取文件内容时,仅为非空白行添加连续行号,空白行(无任何字符的行)不编号且不占用行号,仅原样显示空白。
cat -b test_1.txt 指令详细解释
cat:核心功能是读取test_1.txt的全部内容,包括非空行和空白行,确保内容完整输出;-b:开启 “非空白行编号” 功能,仅对包含有效内容的行分配连续行号(从 1 开始),完全空白的行不添加行号,也不会占用行号序列;test_1.txt:目标文件,包含 3 行hello Linux、3 行空白行、3 行hello Linux,共 9 行结构。
示例执行效果验证
结合文件结构和输出结果,核心逻辑体现如下:
- 前 3 行非空行:被依次编号为
1、2、3,行号与内容对应; - 中间 3 行空白行:无任何行号标识,仅显示空白,不占用行号(区别于
cat -n虽不编号但行号连续递增); - 后 3 行非空行:行号延续前 3 行的序列,编号为
4、5、6,而非从 7 开始(因中间空白行未占用行号); - 输出结果清晰区分有效内容行和空白行,仅突出有效内容的行数分布,与
cat -n形成明确差异(cat -n输出行号为 1、2、3、7、8、9,空白行虽不编号但行号连续)。
cat -s 指令(读取文件内容时,将连续的多个空白行压缩为单个空白行)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 4
-rw-rw-r-- 1 ranjiaju ranjiaju 75 Nov 20 15:33 test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat -n test_1.txt
1 hello Linux
2 hello Linux
3 hello Linux
4
5
6
7 hello Linux
8 hello Linux
9 hello Linux
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat -s test_1.txt
hello Linux
hello Linux
hello Linux
hello Linux
hello Linux
hello Linux
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cat -sn test_1.txt
1 hello Linux
2 hello Linux
3 hello Linux
4
5 hello Linux
6 hello Linux
7 hello Linux
cat 是读取文件内容并输出到终端的基础指令,-s(squeeze,压缩)是空白行处理选项,两者组合用于 读取文件内容时,将连续的多个空白行压缩为单个空白行,单个空白行保持不变,不改变非空白行的内容和顺序,让输出更整洁。
cat -s test_1.txt 指令详细解释
cat:核心功能是完整读取test_1.txt的所有内容,包括非空行和空白行,确保内容不遗漏;-s:开启 “连续空白行压缩” 功能,仅针对 2 个及以上连续的空白行 生效 —— 将其合并为 1 个空白行,单个空白行不处理;test_1.txt:目标文件,原始结构为 “3 行非空行 + 3 个连续空白行 + 3 行非空行”,共 9 行。
示例执行效果验证
结合文件原始结构和输出结果,核心逻辑如下:
- 原始中间 3 个连续空白行:被
-s选项压缩为 1 个空白行,不再显示多余空行; - 非空行内容:3 行
hello Linux前后各一组,内容、顺序完全不变,未受压缩操作影响; - 输出对比:相比直接
cat test_1.txt(中间显示 3 个空白行),cat -s输出中间仅 1 个空白行,文件结构更简洁,无冗余空行干扰阅读。
less 指令(分页查看文件内容)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cnt=1; while [ $cnt -le 1000 ]; do echo "hello Linux $cnt"; let cnt++; done > test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ less test_1.txt
// 通过 less 指令进入 test_1.txt 后
// 1. 可以上下翻动
// 2. 可以在下方输入 /xxx ,如 /500 ,就会直接跳转到对应的 test_1.txt 对应的第 500 行
// 3. 可以在下方输入 ?xxx ,如 ?300 ,就会从第 500 行向前跳转到第 300 行
// 4. 输入 q 按钮退出less 指令核心作用less 是 Linux 中 分页查看文件内容 的交互式工具,支持上下翻页、精准搜索、行跳转等操作,核心优势是 “按需加载内容”—— 无需一次性读取整个文件(尤其适合大型文件),占用内存少,是查看大文件的首选工具。
less test_1.txt 指令详细解释
less:分页查看工具的核心命令,启动后进入交互式视图,支持多种快捷键操作;test_1.txt:目标文件,示例中是含 1000 行内容的大型文件(通过循环指令生成),直接用cat查看会一次性输出所有内容,难以阅读,less可解决此问题;- 执行效果:启动后进入文件内容的分页视图,默认显示文件开头部分,底部会显示当前查看进度(如
test_1.txt lines 1-24/1000),等待用户通过快捷键操作。
核心交互式操作详解
- 1. 上下翻动:
- 向上翻页:按
b键(back)或PageUp键; - 向下翻页:按空格键或
PageDown键; - 逐行上下:按
k键(向上)、j键(向下)或方向键 ↑↓,灵活控制阅读节奏。
- 向上翻页:按
- 2. 向下搜索(/xxx):
- 输入
/+ 关键词(如/500),按回车,less会从当前位置向后搜索包含 “500” 的内容,直接跳转到第一处匹配行(示例中即第 500 行hello Linux 500); - 搜索后按
n键(next),跳转到下一处匹配结果;按N键,跳转到上一处匹配结果。
- 输入
- 3. 向上搜索(?xxx):
- 输入
?+ 关键词(如?300),按回车,less会从当前位置(如第 500 行)向前搜索包含 “300” 的内容,直接跳转到第一处匹配行(即第 300 行hello Linux 300); - 同样支持
n键(继续向前匹配)、N键(向后匹配),与/xxx搜索方向相反。
- 输入
- 4. 退出视图:
- 按
q键(quit),直接退出less交互式视图,返回终端命令行,不影响文件本身。
- 按
head 指令(快速查看文件开头部分内容)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ pwd
/home/ranjiaju
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 16
-rw-rw-r-- 1 ranjiaju ranjiaju 15893 Nov 20 17:12 test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ head test_1.txt
hello Linux 1
hello Linux 2
hello Linux 3
hello Linux 4
hello Linux 5
hello Linux 6
hello Linux 7
hello Linux 8
hello Linux 9
hello Linux 10
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ head -5 test_1.txt
hello Linux 1
hello Linux 2
hello Linux 3
hello Linux 4
hello Linux 5
head 是 Linux 中 快速查看文件开头部分内容 的指令,默认显示文件前 10 行,可通过选项指定显示行数,无需加载整个文件,适合快速预览文件开头信息(尤其对大文件高效)。
head test_1.txt 指令解释
- 这是
head的默认用法,未指定行数时,系统自动显示目标文件前 10 行内容; - 示例中
test_1.txt是含 1000 行的大文件,执行后仅输出hello Linux 1到hello Linux 10,快速呈现文件开头结构,避免内容刷屏; - 核心优势:无需读取文件全部内容,执行速度快,占用资源少。
head -5 test_1.txt 指令解释
-5是行数指定选项,等价于-n 5(-n是number的缩写,明确指定显示行数);- 指令作用:仅显示
test_1.txt的前 5 行内容,示例中输出hello Linux 1到hello Linux 5,按需精准控制显示行数; - 语法扩展:指定任意行数的格式为
head -n 数字 文件名或head -数字 文件名(如head -20 test_1.txt显示前 20 行)。
tail 指令(快速查看文件末尾部分内容)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tail test_1.txt
hello Linux 991
hello Linux 992
hello Linux 993
hello Linux 994
hello Linux 995
hello Linux 996
hello Linux 997
hello Linux 998
hello Linux 999
hello Linux 1000
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tail -5 test_1.txt
hello Linux 996
hello Linux 997
hello Linux 998
hello Linux 999
hello Linux 1000
tail 是 Linux 中 快速查看文件末尾部分内容 的指令,默认显示文件最后 10 行,可通过选项指定显示行数,无需加载整个文件,适合快速获取文件尾部关键信息(尤其对大文件高效)。
tail test_1.txt 指令解释
- 这是
tail的默认用法,未指定行数时,系统自动显示目标文件最后 10 行内容; - 示例中
test_1.txt含 1000 行内容,执行后仅输出hello Linux 991到hello Linux 1000,快速呈现文件尾部结构,避免冗余内容刷屏; - 核心优势:仅读取文件末尾数据,执行速度快,占用资源少,无需加载整个大文件。
tail -5 test_1.txt 指令解释
-5是行数指定选项,等价于-n 5(-n是number的缩写,明确指定显示行数);- 指令作用:仅显示
test_1.txt的最后 5 行内容,示例中输出hello Linux 996到hello Linux 1000,按需精准控制尾部显示行数; - 语法扩展:指定任意尾部行数的格式为
tail -n 数字 文件名或tail -数字 文件名(如tail -15 test_1.txt显示最后 15 行)。
管道符 “|”
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ head -520 test_1.txt | tail -21
hello Linux 500
hello Linux 501
hello Linux 502
hello Linux 503
hello Linux 504
hello Linux 505
hello Linux 506
hello Linux 507
hello Linux 508
hello Linux 509
hello Linux 510
hello Linux 511
hello Linux 512
hello Linux 513
hello Linux 514
hello Linux 515
hello Linux 516
hello Linux 517
hello Linux 518
hello Linux 519
hello Linux 520
通过 管道符 | 连接 head 和 tail 两个指令,实现 “精准提取文件中间特定行区间” 的功能 —— 最终提取 test_1.txt 中第 500 行到第 520 行的内容(共 21 行),核心逻辑是 “先截取前 N 行,再从截取结果中截取后 M 行”,高效定位大文件的中间内容。
指令拆解与协同逻辑该指令是 “前指令输出作为后指令输入” 的典型管道用法,需按顺序拆解两部分及管道符的作用:
-
第一部分:
head -520 test_1.txt- 功能:读取
test_1.txt的 前 520 行内容(-520表示取前 520 行,等价于-n 520); - 输出去向:因后面跟了管道符
|,这 520 行内容不会直接显示在终端,而是作为 “临时输入” 传递给后面的tail指令,而非写入文件。
- 功能:读取
-
管道符
|的核心作用- 是 Linux 中 “指令协同” 的关键符号,功能是 将前一个指令的标准输出,直接作为后一个指令的标准输入;
- 相当于搭建了一条 “临时数据通道”,避免中间生成临时文件,简化操作且提升效率。
-
第二部分:
tail -21- 功能:读取管道传递过来的 “前 520 行内容”,并提取其中的 最后 21 行(
-21表示取输入内容的后 21 行,等价于-n 21); - 输入来源:并非直接读取
test_1.txt,而是接收head -520传递的 520 行数据; - 最终输出:这 21 行内容会显示在终端,即示例中
hello Linux 500到hello Linux 520的结果。
- 功能:读取管道传递过来的 “前 520 行内容”,并提取其中的 最后 21 行(
行号计算逻辑(验证结果合理性)示例输出是第 500 行到第 520 行,共 21 行,计算逻辑如下:
- 前 520 行的 “最后 21 行”,起始行号 = 520(前 N 行的末尾) - 21(后 M 行) + 1 = 500 行;
- 结束行号 = 520 行(前 N 行的末尾);
- 因此最终提取的是 500~520 行,与示例输出完全一致,验证了指令逻辑的正确性。
安装 man 指令的指令
[root@iZ2vc15k23y9vpuyi3tiqzZ ~]# yum install -y man-pages
安装 nano 指令的指令
[root@iZ2vc15k23y9vpuyi3tiqzZ ~]# yum install -y nano
date 命令(显示或设置系统当前日期与时间)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ date +%Y-%m-%d_%H:%M:%S
2025-11-22_14:11:11
date 是 Linux 中用于 显示或设置系统当前日期与时间 的基础指令,默认按系统预设格式输出,通过 + 符号可自定义日期时间的显示格式,灵活适配日志命名、脚本计时等多种场景。
date +%Y-%m-%d_%H:%M:%S 指令详细解释该指令是 date 结合 自定义格式模板 的常用用法,核心是通过 + 后紧跟的格式占位符,定义日期时间的输出样式,各部分逻辑如下:
date:核心命令,用于获取系统当前的日期和时间数据;+:格式指定符,必须紧跟date后,用于声明后续内容是自定义格式模板(无+则按系统默认格式输出);- 格式占位符与分隔符:模板
%Y-%m-%d_%H:%M:%S由 “占位符” 和 “自定义分隔符” 组成,对应输出2025-11-22_14:11:11:%Y:4 位完整年份(如 2025,区别于%y表示 2 位年份,如 25);%m:2 位月份(01-12,不足两位补 0,如 11 代表 11 月);%d:2 位日期(01-31,不足两位补 0,如 22 代表 22 日);_:自定义分隔符,用于区分 “日期” 和 “时间”,可替换为空格、-等任意字符;%H:24 小时制小时(00-23,如 14 代表下午 2 点,区别于%I表示 12 小时制);%M:2 位分钟(00-59,注意是大写 M,小写%m是月份,避免混淆);%S:2 位秒数(00-59);
- 执行效果:系统按模板顺序拼接日期时间数据,输出
年-月-日_时:分:秒格式的字符串,示例中结果为2025-11-22_14:11:11,完全匹配模板定义。
date +%s 命令(输出当前系统时间对应的 Unix 时间戳)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ date +%s
1763792034
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ date +%s
1763792037
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ date +%s
1763792039
date 用于获取系统当前日期时间,+%s 是其专用格式占位符,该指令的核心功能是 输出当前系统时间对应的 Unix 时间戳—— 即从 Unix 纪元时间(1970-01-01 00:00:00 UTC,协调世界时) 到当前时刻的 总秒数,是一种机器可直接计算、无时区 / 格式歧义的时间表示方式。
date +%s 指令详细解释
date:核心命令,获取系统当前的时间数据(包含日期、时间、时区等信息);+:格式指定符,声明后续内容为自定义时间格式(无+则按系统默认格式输出);%s:Unix 时间戳专用占位符(s 代表 seconds,秒),是date指令中唯一用于输出时间戳的格式符,功能是将当前时间转换为 “纪元时间到当前的总秒数”;- 示例验证:用户三次执行该指令,输出结果分别为
1763792034、1763792037、1763792039,数字依次递增 3 秒、2 秒,完全匹配 “秒级计数” 的特性 —— 每间隔 1 秒,时间戳数值加 1,直观体现了时间戳随实际时间实时递增的规律。
关键补充说明
- 时间戳的本质:
- 无时区依赖:Unix 时间戳以 UTC 为基准,无论当前系统时区是 CST(中国标准时间)还是其他时区,同一时刻的时间戳全球统一(例如中国时区比 UTC 快 8 小时,但时间戳计算仍以 UTC 起始点为准,避免时区混淆);
- 无格式歧义:不同于
2025-11-22 14:11:11这类人类可读格式,时间戳是纯数字,机器可直接进行加减运算(如计算时间差),无格式解析错误风险。
- 与人类可读格式的区别:
date +%Y-%m-%d_%H:%M:%S:输出人类易读的 “年 - 月 - 日_时:分: 秒” 格式,适合直观查看;date +%s:输出纯数字时间戳,适合机器计算、跨系统传输或精确计时,不适合直接阅读。
- 反向转换(实用扩展):若需将时间戳转回人类可读格式,可执行
date -d @时间戳(@是时间戳标识),例如:- 输入
date -d @1763792034,会输出对应时区的可读时间(如Sat Nov 22 14:13:54 CST 2025),方便验证时间戳对应的实际时刻。
- 输入
- 精度说明:
%s输出的是 “秒级” 时间戳,若需毫秒级精度,部分 Linux 系统支持date +%s%N(%N表示纳秒,取前 3 位即为毫秒),例如1763792034123(末尾 3 位是毫秒)。
核心用途
- 脚本中的时间差计算:例如在脚本开始时记录时间戳
start=$(date +%s),结束时记录end=$(date +%s),通过$((end - start))直接得到脚本执行的总秒数,精准计时; - 日志的唯一时间标识:在日志文件名或日志内容中嵌入时间戳(如
error_$(date +%s).log),避免同名日志覆盖,且能精确排序(按数字大小即可对应时间先后); - 跨系统时间同步:不同系统、不同时区的设备,可通过时间戳快速对齐时间(无需处理时区转换、格式差异);
- 程序开发中的时间存储:数据库、代码中存储时间戳,占用空间小、查询和计算效率高(如筛选 “近 24 小时的数据”,直接用当前时间戳减 86400 即可)。
date -d @时间戳 命令( 将指定的时间戳转换为系统本地时区的人类可读日期时间格式)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ date +%s
1763792290
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ date +%Y-%m-%d_%H:%M:%S -d @1763792290
2025-11-22_14:18:10
date 是处理日期时间的核心指令,-d(date parse,解析)是日期解析选项,@ 是 Unix 时间戳的专用标识,该指令的核心功能是 将指定的 Unix 时间戳(1763792290)转换为系统本地时区的人类可读日期时间格式,是 date +%s(时间戳输出)的反向操作,解决 “时间戳看不懂” 的问题。
指令详细拆解与逻辑指令各部分各司其职,共同完成 “时间戳→可读时间” 的转换,具体如下:
date:核心命令,负责执行时间格式转换与输出;-d:关键选项,作用是 “解析后续指定的日期 / 时间字符串”,支持多种格式(如时间戳、2025-11-22这类日期字符串、+1day这类相对时间),此处专门用于解析时间戳;@1763792290:解析的目标内容,格式为@+时间戳数字:@:必须紧跟-d后的关键标识,明确告诉date后面的数字是 Unix 时间戳(而非普通数字日期,如1763792290若不加@,会被误认为是 “年月日” 格式的无效数字);1763792290:待转换的 Unix 时间戳,对应 “1970-01-01 00:00:00 UTC” 到当前时刻的总秒数;
- 执行逻辑:系统先通过
@识别时间戳,再计算该秒数对应的本地时间(示例中系统时区为 CST 中国标准时间),最终输出可读格式,示例中转换结果为2025-11-22_14:18:10。
示例验证与关联说明
- 正向与反向联动:用户先通过
date +%s得到时间戳1763792290,再用date -d @1763792290将其转回可读时间,两者形成 “输出→验证” 的闭环,说明转换准确无误; - 格式灵活扩展:示例中额外加了
+%Y-%m-%d_%H:%M:%S自定义输出格式,若不加该格式,系统会按默认格式输出(如Sat Nov 22 14:18:10 CST 2025),可根据需求调整格式(如date -d @1763792290 +%m/%d/%Y输出11/22/2025)。
find -name 指令(递归搜索文件 / 目录)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ find ~ -name *
/home/ranjiaju
/home/ranjiaju/.lesshst
/home/ranjiaju/.bash_history
/home/ranjiaju/.bash_profile
/home/ranjiaju/.bash_logout
/home/ranjiaju/.bashrc
/home/ranjiaju/test
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ find ~ -name test
/home/ranjiaju/test
find 是 Linux 中 递归搜索文件 / 目录 的核心工具,~ 指定搜索起始目录(当前用户家目录),-name 是 “按文件名 / 目录名匹配” 的筛选选项,三者组合用于 从家目录开始,递归查找所有文件名 / 目录名符合指定匹配规则的对象(包括子目录下的内容),支持精确匹配和模糊匹配。
指令参数拆解(通用逻辑)
find:搜索命令的核心关键字,功能是 “递归遍历指定目录下的所有文件和子目录”,默认会遍历目录树的所有层级;~:搜索起始目录,代表当前用户的 家目录(即/home/ranjiaju),find会从该目录开始,向下递归搜索所有子目录;-name:筛选条件选项,全称 “name match”,作用是 “仅保留文件名 / 目录名与后续匹配模式一致的对象”,默认区分大小写(如test和Test视为不同名称);- 匹配模式:
-name后紧跟的内容(如*或test),是筛选的核心规则,支持通配符(*、?等)和精确匹配。
两个示例的具体解释
1. find ~ -name * 指令解释
- 匹配模式
*:*是 Linux 通配符,代表 “匹配任意长度的任意字符(包括空字符)”,即 “所有名称”; - 搜索逻辑:从家目录(
/home/ranjiaju)开始,递归遍历所有文件和子目录,由于*匹配所有名称,因此会列出家目录下 所有文件、隐藏文件、目录(包括一级目录和子目录,但示例中家目录下无深层子目录,仅列出一级内容); - 示例输出验证:结果包含家目录本身(
/home/ranjiaju)、隐藏文件(.lesshst、.bash_history等)、普通目录(test),完全符合 “匹配所有对象” 的逻辑,无任何筛选遗漏。
2. find ~ -name test 指令解释
- 匹配模式
test:无通配符,属于 精确匹配,仅匹配 “文件名 / 目录名完全等于test” 的对象(区分大小写,不匹配Test、test123等); - 搜索逻辑:从家目录开始递归搜索,仅保留名称为
test的文件或目录,示例中家目录下恰好有一个名为test的目录(无其他同名对象),因此仅输出该目录路径; - 示例输出验证:结果仅为
/home/ranjiaju/test,与精确匹配规则一致,排除了所有名称不相同的对象,体现了-name精确筛选的特性。
whereis 命令(快速查找指定指令、库文件或头文件的相关关联文件)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ whereis ls
ls: /usr/bin/ls /usr/share/man/man1/ls.1.gz /usr/share/man/man1p/ls.1p.gz
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ whereis string.h
string: /usr/include/string.h /usr/share/man/man3/string.3.gzwhereis 是 Linux 中用于 快速查找指定指令、库文件或头文件的相关关联文件 的工具,核心特点是 “搜索预设系统目录”(非全系统递归),仅返回与目标相关的关键文件(可执行文件、头文件、手册页等),不包含无关文件,搜索速度远快于 find,且功能比 which 更全面。
其核心定位是:查找 “系统级标准文件” 的完整关联资源,而非零散的用户自定义文件,默认搜索目录包括 /bin、/usr/bin、/usr/include、/usr/share/man 等系统预设路径(存储可执行程序、头文件、帮助手册的标准目录)。
指令语法与参数逻辑
基础语法:whereis [目标名称]
whereis:搜索关键字,触发预设目录的关联文件查找;- 目标名称:需查找的指令名、文件名(可省略后缀,如
string.h可简写为string),系统会自动匹配相关关联文件; - 默认查找范围:可执行文件(
-b选项单独指定)、源文件(-s选项单独指定)、手册页(-m选项单独指定),不加选项时默认返回这三类中存在的文件。
两个示例的详细解释
1. whereis ls 输出解析
输出:ls: /usr/bin/ls /usr/share/man/man1/ls.1.gz /usr/share/man/man1p/ls.1p.gz
ls::表示当前查找的目标名称(指令ls);/usr/bin/ls:ls指令的 可执行文件路径(系统标准可执行文件目录,与which ls输出的路径一致);/usr/share/man/man1/ls.1.gz:ls指令的 用户级手册页(man page):man1表示 “用户指令类手册”(1 是 man 手册的章节号,对应普通指令);ls.1.gz是压缩后的手册文件,执行man ls时会读取该文件;
/usr/share/man/man1p/ls.1p.gz:ls指令的 POSIX 标准手册页(1p章节对应 POSIX 标准指令规范),补充用户级手册之外的标准说明;- 核心逻辑:
ls是系统内置指令,whereis快速定位其可执行文件和两类手册页,覆盖 “执行 + 查阅帮助” 的核心需求。
2. whereis string.h 输出解析
输出:string: /usr/include/string.h /usr/share/man/man3/string.3.gz
string::whereis自动忽略.h后缀,按核心名称string匹配(因string.h是 C 语言标准头文件,其关联的手册页以string命名);/usr/include/string.h:string.h头文件的 标准存储路径(/usr/include是系统级头文件的默认目录,编译 C/C++ 程序时会自动在此目录查找头文件);/usr/share/man/man3/string.3.gz:string.h对应库函数的 手册页:man3表示 “库函数类手册”(3 是 man 章节号,对应 C 标准库函数);- 执行
man 3 string可查看string.h中包含的库函数(如strcpy、strlen)的使用说明;
- 核心逻辑:
string.h是系统标准头文件,whereis定位其 “编译依赖的头文件路径” 和 “库函数帮助手册”,满足开发编译、查阅接口的需求。
grep 指令(文本搜索与筛选)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ cnt=1; while [ $cnt -le 1000 ]; do echo "hello Linux $cnt"; let cnt++; done > test_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ grep '99' test_1.txt
hello Linux 99
hello Linux 199
hello Linux 299
hello Linux 399
hello Linux 499
hello Linux 599
hello Linux 699
hello Linux 799
hello Linux 899
hello Linux 990
hello Linux 991
hello Linux 992
hello Linux 993
hello Linux 994
hello Linux 995
hello Linux 996
hello Linux 997
hello Linux 998
hello Linux 999
grep 是 Linux 中 文本搜索与筛选的核心工具,全称 “Global Regular Expression Print”(全局正则表达式打印),核心功能是 在指定文件(或输入流)中,按 “字符串” 或 “正则表达式” 匹配行,并输出所有包含匹配内容的完整行,支持精准筛选、模糊匹配、批量搜索等场景,是日志分析、数据处理的必备工具。
grep '99' test_1.txt 指令详细拆解
指令结构:grep [匹配模式] [目标文件],各部分逻辑与示例结合如下:
grep:搜索关键字,触发文本匹配与筛选操作;'99':匹配模式(此处为 “固定字符串匹配”,非正则表达式),表示 “筛选所有包含连续字符99的行”;- 单引号的作用:固定匹配模式的字面含义,避免
99被 Shell 解析为特殊字符(若匹配模式含正则元字符,单引号可确保其按正则规则生效);
- 单引号的作用:固定匹配模式的字面含义,避免
test_1.txt:目标文件,即待搜索的文本文件(示例中是含 1000 行hello Linux X的文件);- 执行逻辑:
grep逐行读取test_1.txt的内容,检查每行是否包含字符串99,若包含则输出该行完整内容,不包含则跳过。
示例输出逻辑验证
示例中输出 19 行含 99 的内容,匹配规则清晰可查:
- 直接以
99结尾的行:hello Linux 99(第 99 行),行中含99; - 中间含
99的行:hello Linux 199、299、…、899(共 8 行),数字部分包含99; - 以
99开头的多位数行:hello Linux 990、991、…、999(共 10 行),数字前两位为99; - 核心规律:只要行中存在 连续的
99字符(无论在数字的开头、中间、结尾),都会被匹配并输出,且输出的是 “完整行”(而非仅匹配的99字符),符合grep“按行匹配” 的本质。
grep -n 指令;grep -v 指令;grep -i 指令;
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ cat test_1.txt
hello Liunx
hello Liunx
hello Liunx
abc
Abc
ABC
1233455
6783
789
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ grep 'Liunx' test_1.txt
hello Liunx
hello Liunx
hello Liunx
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ grep -v 'Liunx' test_1.txt
abc
Abc
ABC
1233455
6783
789
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ grep -n 'Liunx' test_1.txt
1:hello Liunx
2:hello Liunx
3:hello Liunx
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ grep -n '' test_1.txt
1:hello Liunx
2:hello Liunx
3:hello Liunx
4:
5:abc
6:Abc
7:ABC
8:
9:1233455
10:6783
11:789
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ grep 'abc' test_1.txt
abc
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ grep -i 'abc' test_1.txt
abc
Abc
ABC
三者均是 grep 命令的 筛选增强选项,用于在 “按模式匹配行” 的基础上,添加 “行号显示”“反向匹配”“忽略大小写” 的功能,适配更精细的文本筛选场景。以下结合示例逐个详解:
一、grep -n 指令:匹配行 + 显示行号
核心作用
在输出匹配模式的行的同时,在每行前添加对应的行号(从 1 开始连续编号),便于快速定位匹配内容在文件中的位置。
选项含义
-n:全称 --line-number(行号),告诉 grep 不仅要输出匹配行的内容,还要标注该行在文件中的绝对行号。
示例解析
-
grep -n 'Liunx' test_1.txt- 匹配模式:查找含字符串
Liunx的行; - 输出结果:
1:hello Liunx、2:hello Liunx、3:hello Liunx; - 逻辑:文件中
Liunx仅在第 1-3 行出现,-n为这三行添加行号前缀(1:「行号 + 冒号」),直接定位匹配内容的位置。
- 匹配模式:查找含字符串
-
grep -n '' test_1.txt(特殊场景:空字符串匹配)- 匹配模式:空字符串
''是特殊匹配规则 ——匹配文件中所有行(包括空白行)(因为任何行都包含 “空字符串”); - 输出结果:行号从 1 到 11,覆盖文件所有行(包括第 4、8 行空白行,标注为
4:、8:); - 用途:快速查看文件的总行数、空白行的位置,相当于 “带行号的全文件内容输出”。
- 匹配模式:空字符串
补充说明
- 行号规则:从文件第一行开始连续编号,无论该行是内容行还是空白行;
- 核心用途:日志查错(定位错误行号)、代码查找(定位函数 / 变量所在行)。
二、grep -v 指令:反向匹配(输出不匹配的行)
核心作用
反向筛选:输出 “不包含” 匹配模式的所有行,相当于 “排除含指定内容的行”,保留剩余所有行(包括空白行)。
选项含义
-v:全称 --invert-match(反向匹配),反转 grep 的匹配逻辑 —— 不输出匹配行,而是输出所有不匹配的行。
示例解析
grep -v 'Liunx' test_1.txt
- 匹配模式:排除含字符串
Liunx的行; - 原始文件:前 3 行是
hello Liunx,后续是空白行、abc相关行、数字行; - 输出结果:排除了前 3 行,保留了剩余的所有内容(包括第 4、8 行空白行,以及
abc、数字行); - 对比验证:与
grep 'Liunx' test_1.txt的输出完全互补,清晰体现 “反向筛选” 的逻辑。
补充说明
- 空白行处理:若空白行不包含匹配模式,会被
grep -v保留(示例中空白行不含Liunx,因此输出); - 核心用途:过滤日志中的冗余内容(如排除 “info” 级日志,只看错误)、提取文件中除指定内容外的所有数据。
三、grep -i 指令:忽略大小写匹配
核心作用
匹配模式时 不区分英文字母大小写,即 A 和 a、B 和 b 视为同一字符,扩大匹配范围,避免因大小写差异遗漏结果。
选项含义
-i:全称 --ignore-case(忽略大小写),取消匹配模式与文件内容的大小写敏感对比。
示例解析
-
grep 'abc' test_1.txt(无-i,默认大小写敏感)- 匹配模式:仅匹配小写
abc; - 输出结果:仅
abc一行(文件中Abc、ABC因大小写不同,不匹配)。
- 匹配模式:仅匹配小写
-
grep -i 'abc' test_1.txt(加-i,忽略大小写)- 匹配模式:
abc不区分大小写,等价于匹配abc、Abc、ABC、aBc等所有大小写组合; - 输出结果:
abc、Abc、ABC三行全部匹配输出; - 核心逻辑:
-i让匹配规则 “不挑大小写”,适合不确定目标内容大小写的场景。
- 匹配模式:
安装 zip 和 unzip 命令的命令
[root@iZ2vc15k23y9vpuyi3tiqzZ ~]# sudo yum install zip unzip -y
zip 命令;unzip 命令(文件 / 目录压缩和解压)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 4
drwxrwxr-x 3 ranjiaju ranjiaju 4096 Nov 22 21:38 test
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ cd test
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ ll
total 4
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 22 21:40 test_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ tree test_1
test_1
├── test_1_1.txt
├── test_1_2.c
└── test_1_3.h
0 directories, 3 files
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ zip -r test_1.zip test_1
adding: test_1/ (stored 0%)
adding: test_1/test_1_2.c (stored 0%)
adding: test_1/test_1_3.h (stored 0%)
adding: test_1/test_1_1.txt (stored 0%)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ ll
total 8
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 22 21:40 test_1
-rw-rw-r-- 1 ranjiaju ranjiaju 672 Nov 22 21:49 test_1.zip
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ mv test_1.zip ..
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ ll
total 4
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 22 21:40 test_1
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ test]$ cd ..
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 8
drwxrwxr-x 3 ranjiaju ranjiaju 4096 Nov 22 21:49 test
-rw-rw-r-- 1 ranjiaju ranjiaju 672 Nov 22 21:49 test_1.zip
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ unzip test_1.zip
Archive: test_1.zip
creating: test_1/
extracting: test_1/test_1_2.c
extracting: test_1/test_1_3.h
extracting: test_1/test_1_1.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 12
drwxrwxr-x 3 ranjiaju ranjiaju 4096 Nov 22 21:49 test
drwxrwxr-x 2 ranjiaju ranjiaju 4096 Nov 22 21:40 test_1
-rw-rw-r-- 1 ranjiaju ranjiaju 672 Nov 22 21:49 test_1.zip
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree test_1
test_1
├── test_1_1.txt
├── test_1_2.c
└── test_1_3.h
0 directories, 3 fileszip 是 Linux/Unix 系统中常用的 文件 / 目录压缩工具,用于创建标准 ZIP 格式的压缩包(跨平台兼容,Windows/macOS 均可识别),支持单个文件、多级目录的压缩,还能灵活控制压缩模式、是否保留原文件等。
核心功能创建 ZIP 格式压缩包,可压缩单个文件、递归压缩目录(包含子目录和内部文件),支持添加文件到已有压缩包、更新压缩包内容等。
基本语法
zip [选项] 压缩包名称 要压缩的文件/目录
选项:可选,控制压缩行为(如递归、静默模式等);压缩包名称:必选,指定生成的压缩包文件名(通常以.zip为后缀,便于识别);要压缩的文件/目录:必选,可指定单个文件、多个文件(用空格分隔)或目录。
关键细节(结合操作示例)代码中的压缩命令:
zip -r test_1.zip test_1
- 核心选项
-r:recursive(递归)的缩写,压缩目录时必须添加,否则zip只会压缩目录本身(空目录),不会包含目录内的文件(如示例中的test_1_1.txt、test_1_2.c等); - 命令含义:将当前目录下的
test_1目录(含其内部所有文件)压缩为test_1.zip压缩包; - 输出解读:
adding: test_1/ (stored 0%):表示添加test_1目录,stored 0%是因为目录本身无实际数据,采用 “存储模式”(未压缩,直接保留结构);- 后续
adding: test_1/test_1_2.c (stored 0%)等:由于示例中的文件可能为空或无压缩空间,zip同样采用存储模式,若文件有实际内容,会显示具体压缩率(如deflated 75%表示压缩后体积减少 75%)。
其他实用选项(补充)
| 选项 | 功能 | 示例 |
|---|---|---|
-q |
静默模式(quiet),不输出压缩过程信息,仅显示错误 | zip -qr test_1.zip test_1(后台压缩,无输出) |
-m |
压缩后删除原文件 / 目录(move),仅保留压缩包 | zip -mr test_1.zip test_1(压缩后删除原 test_1 目录) |
-u |
更新压缩包(update),仅添加新文件或修改过的文件到已有压缩包 | zip -u test_1.zip test_1/new_file.txt(向现有压缩包添加新文件) |
-d |
从压缩包中删除指定文件 | zip -d test_1.zip test_1/test_1_3.h(删除压缩包内的 test_1_3.h) |
-9 |
最高压缩级别(1-9,1 最快压缩率最低,9 最慢压缩率最高,默认 6) | zip -r9 test_1.zip test_1(高压缩率压缩,适合文本文件) |
典型使用场景
- 压缩单个文件:
zip doc.zip report.pdf(将report.pdf压缩为doc.zip); - 压缩多个文件:
zip pics.zip photo1.jpg photo2.png(将两个图片文件压缩为一个包); - 递归压缩目录(核心场景):
zip -r project.zip my_project(压缩项目目录及所有子文件,便于传输 / 备份); - 更新压缩包:
zip -ur project.zip my_project/new_feature.c(向已有压缩包添加新开发的文件)。
unzip 是 Linux/Unix 系统中配套 zip 的 ZIP 压缩包解压工具,用于提取 ZIP 格式压缩包内的文件 / 目录,支持查看压缩包内容、指定解压目录、覆盖已有文件等灵活操作,同样跨平台兼容所有标准 ZIP 包。
核心功能提取 ZIP 压缩包内的文件 / 目录,可查看压缩包清单(不解压)、指定解压路径、选择性解压部分文件,支持处理带中文名称的压缩包(需配合编码选项)。
基本语法
unzip [选项] 压缩包名称 [要解压的文件(可选)]
选项:可选,控制解压行为(如指定目录、静默模式等);压缩包名称:必选,指定要解压的 ZIP 包路径;要解压的文件:可选,默认解压全部文件,也可指定单个 / 多个文件(用空格分隔,需写压缩包内的相对路径)。
关键细节(结合操作示例)代码中的解压命令:
unzip test_1.zip
- 无额外选项时,
unzip的默认行为:- 在当前目录下创建与压缩包内根目录同名的文件夹(示例中为
test_1),并将所有文件解压到该目录中; - 保留原始文件的目录结构(压缩包内
test_1/下的文件,解压后仍在test_1/目录下);
- 在当前目录下创建与压缩包内根目录同名的文件夹(示例中为
- 输出解读:
Archive: test_1.zip:确认解压的压缩包名称;creating: test_1/:创建解压后的目录;extracting: test_1/test_1_2.c等:提取压缩包内的文件到对应目录。
其他实用选项(补充)
| 选项 | 功能 | 示例 |
|---|---|---|
-l |
查看压缩包内容(list),不解压,显示文件名、大小、修改时间 | unzip -l test_1.zip(查看 test_1.zip 内的所有文件清单) |
-d |
指定解压目录(directory),目录不存在会自动创建 | unzip test_1.zip -d ./backup(将文件解压到当前目录的 backup 文件夹) |
-q |
静默模式(quiet),不输出解压过程信息 | unzip -q test_1.zip(后台解压,无输出) |
-o |
覆盖模式(overwrite),解压时直接覆盖已有文件,不提示 | unzip -o test_1.zip(覆盖当前目录下已存在的 test_1 目录及文件) |
-n |
不覆盖模式(never overwrite),解压时跳过已有文件,不提示 | unzip -n test_1.zip(保留现有文件,只解压不存在的文件) |
-O UTF-8 |
指定编码(解决中文文件名乱码) | unzip -O UTF-8 chinese.zip(解压含中文文件名的压缩包,避免乱码) |
典型使用场景
- 直接解压到当前目录:
unzip test_1.zip(如示例操作,快速提取所有内容); - 查看压缩包内容(不解压):
unzip -l test_1.zip(确认压缩包内是否有需要的文件); - 指定解压目录(避免文件混乱):
unzip test_1.zip -d ./temp(解压到temp目录,便于后续清理); - 覆盖已有文件:
unzip -o test_1.zip(更新文件时,无需手动删除旧文件); - 解压部分文件:
unzip test_1.zip test_1/test_1_1.txt(仅提取压缩包内的test_1_1.txt文件)。
总结(zip & unzip)
zip核心用法:创建 ZIP 压缩包,压缩目录必须加-r选项,常用zip -r 压缩包名 目录;unzip核心用法:解压 ZIP 压缩包,默认解压到当前目录,指定目录用-d,查看内容用-l;- 两者搭配是 Linux 下文件备份、传输的常用组合,跨平台兼容性强,满足日常压缩 / 解压需求。
示例中的操作完整演示了 “压缩目录 → 移动压缩包 → 解压还原” 的流程,完美覆盖了 zip 和 unzip 的核心使用场景,日常工作中只需掌握 -r(zip)、-d(unzip)、-l(unzip)三个选项,就能应对大部分场景。
tar 命令(归档与压缩工具)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 4
drwxrwxr-x 3 ranjiaju ranjiaju 4096 Nov 22 21:49 test
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 23 13:08 test.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tar -czf code.tgz test test.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 8
-rw-rw-r-- 1 ranjiaju ranjiaju 250 Nov 23 13:09 code.tgz
drwxrwxr-x 3 ranjiaju ranjiaju 4096 Nov 22 21:49 test
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 23 13:08 test.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tar -tzf code.tgz
test/
test/test_1/
test/test_1/test_1_2.c
test/test_1/test_1_3.h
test/test_1/test_1_1.txt
test.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ rm -rf test test.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 4
-rw-rw-r-- 1 ranjiaju ranjiaju 250 Nov 23 13:09 code.tgz
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tar -xzf code.tgz
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ ll
total 8
-rw-rw-r-- 1 ranjiaju ranjiaju 250 Nov 23 13:09 code.tgz
drwxrwxr-x 3 ranjiaju ranjiaju 4096 Nov 22 21:49 test
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Nov 23 13:08 test.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ tree test
test
└── test_1
├── test_1_1.txt
├── test_1_2.c
└── test_1_3.h
1 directory, 3 files
tar 是 Linux/Unix 系统中最核心的 归档与压缩工具,默认仅完成 “归档”(将多个文件 / 目录打包成单个归档文件,不压缩),配合压缩算法选项(如 gzip、bzip2)可同时实现归档 + 压缩,支持保留文件权限、时间戳、目录结构,是备份、传输文件 / 项目的首选工具。
核心功能
- 归档(打包):将多个文件、多级目录合并为单个
.tar归档文件; - 压缩:结合
gzip/bzip2等算法,生成.tar.gz(简写.tgz)、.tar.bz2等压缩归档文件; - 解压 / 提取:从归档 / 压缩文件中还原原始文件 / 目录;
- 查看:不解压的情况下,查看归档文件内的内容清单。
基本语法
tar [选项组合] 归档文件名 要处理的文件/目录 # 归档/压缩(如 -czf)
tar [选项组合] 归档文件名 # 查看/解压(如 -tzf、-xzf)
- 选项组合:
tar选项可无分隔符组合(如-czf等价于-c -z -f),核心选项顺序建议固定(f必须放在最后,紧跟归档文件名); - 归档文件名:指定生成或待处理的归档文件(压缩时常用
.tgz/.tar.gz后缀标识 gzip 压缩,.tar.bz2标识 bzip2 压缩); - 要处理的文件 / 目录:归档 / 压缩时指定,可多个(空格分隔),支持目录递归。
关键细节(结合操作示例)代码中的第一个 tar 命令(归档 + 压缩):
tar -czf code.tgz test test.txt
- 选项拆解:
c:create(创建归档文件),表示本次操作是 “打包 / 压缩”;z:采用gzip算法压缩,生成的.tgz(等价.tar.gz)是 Linux 最常用的压缩归档格式;f:file(指定归档文件名),必须紧跟归档文件名(如code.tgz),不能放在其他选项前;
- 命令含义:将当前目录下的
test目录(含其子目录和所有文件)、test.txt文件,通过 “归档 + gzip 压缩” 生成code.tgz压缩包; - 特性说明:
tar默认保留原文件 / 目录(示例中执行后test和test.txt仍存在),仅生成压缩包,不会删除源文件。
代码中的第二个 tar 命令(查看归档内容):
tar -tzf code.tgz
- 选项拆解:
t:list(列出归档内容),表示 “不解压,仅查看文件清单”;z:因为归档文件是 gzip 压缩的(.tgz),需用z选项解析压缩格式;f:指定要查看的归档文件名code.tgz;
- 输出解读:列出
code.tgz内的所有内容,包含完整目录结构(test/→test/test_1/)和文件(test_1_2.c等、test.txt),验证归档内容是否完整。
代码中的第三个 tar 命令(解压归档文件):
tar -xzf code.tgz
- 选项拆解:
x:extract(提取文件),表示 “解压 / 还原归档内容”;z:解析 gzip 压缩格式;f:指定要解压的归档文件名code.tgz;
- 命令含义:将
code.tgz内的所有文件 / 目录,还原到当前目录下; - 特性说明:解压后完全保留原始目录结构(
test目录及内部test_1子目录)、文件权限(如drwxrwxr-x)和时间戳,与压缩前一致(示例中test目录的修改时间仍为 Nov 22 21:49)。
其他实用选项(补充)
| 选项 | 功能 | 示例 | |
|---|---|---|---|
-v |
verbose(详细模式),显示归档 / 解压过程(文件名、路径) | tar -czvf code.tgz test test.txt(打包时显示每个文件的处理信息) |
|
-j |
采用 bzip2 算法压缩 / 解压,生成 .tar.bz2 格式(压缩率比 gzip 高,速度慢) |
tar -cjf code.tar.bz2 test test.txt(归档 + bzip2 压缩) |
|
-C |
指定解压目录(解压时使用),目录不存在会报错 | tar -xzf code.tgz -C ./backup(将内容解压到当前目录的 backup 文件夹) |
|
--exclude |
归档时排除指定文件 / 目录(支持通配符) | tar -czf code.tgz test test.txt --exclude "test/*.c"(打包时排除 test 目录下的 .c 文件) |
|
-p |
保留文件的原始权限(默认已保留,仅特殊场景需显式指定) | tar -xzf code.tgz -p(强制保留所有文件权限) |
|
-f - |
输出到标准输出(配合管道符,用于跨服务器传输) | `tar -czf - test | ssh user@server "tar -xzf - -C /data"`(本地打包后直接传输到远程服务器并解压) |
总结tar 的核心价值是 “归档 + 灵活压缩”,兼顾功能强大与易用性,核心选项组合需牢记:
- 归档 + 压缩:
tar -czf 压缩包名 目标文件/目录(gzip 格式,常用); - 查看内容:
tar -tzf 压缩包名; - 解压还原:
tar -xzf 压缩包名(默认当前目录)/tar -xzf 压缩包名 -C 目标目录; - 拓展:
-j替换-z可切换为 bzip2 压缩,-v显示详细过程,--exclude排除无用文件。
示例中的操作完整覆盖了 “备份(打包压缩)→ 验证(查看内容)→ 恢复(删除源文件后解压)” 的核心流程,正是 tar 最常用的场景,其保留目录结构、权限的特性,让它成为 Linux 系统备份与文件传输的 “标配工具”。
bc 命令(高精度计算工具)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ bc
bc 1.06.95
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
1+2
3
8*9
72
400%8
0
quit
bc 是 Linux/Unix 系统中轻量且强大的 高精度计算工具,本质是命令行交互式计算器,支持整数、浮点数运算,还能处理表达式、逻辑判断、变量定义等,精度可自定义,适合日常简单计算、脚本中的数值运算等场景。
核心功能支持整数 / 浮点数的加减乘除、取余、幂运算等基本算术操作,可自定义小数精度,支持表达式计算、变量赋值,还能通过选项调用数学函数(如正弦、对数),兼顾简单计算与复杂数值处理。
基本语法
bc [选项] # 进入交互模式(默认方式)
bc [选项] <<< "计算表达式" # 非交互模式(直接执行计算并输出结果)
- 选项:可选,用于控制计算行为(如加载数学库、静默模式等);
- 交互模式:直接输入
bc回车即可进入,输入表达式后回车实时返回结果,需手动退出; - 非交互模式:通过重定向(
<<<)或管道传递计算表达式,无需进入交互环境,适合脚本中批量执行计算。
关键细节(结合操作示例)代码中的第一步:输入 bc 命令进入交互模式
bc
- 执行后会显示 bc 的版本信息和版权声明,随后进入交互界面(等待用户输入计算指令),此时处于 “边输入边计算” 的交互式状态,输入的每一条表达式都会即时运算并输出结果。
代码中的计算操作:
1+2:整数加法运算,bc 对整数运算默认无精度损失,直接返回准确结果3;8*9:整数乘法运算,支持任意长度的整数运算(即使是超大位数整数,也不会溢出,保持高精度),返回结果72;400%8:取余运算(%是 bc 中的取余运算符),表示 “400 除以 8 后的余数”,因 400 能被 8 整除,故返回0,取余运算仅对整数有效,浮点数取余需先通过scale设置精度。
代码中的退出命令:
quit
- 在 bc 交互模式中,输入
quit并回车是标准退出方式,会直接返回系统命令行;若需强制终止,也可使用Ctrl+C快捷键。
其他实用选项(补充)
| 选项 | 功能 | 示例 |
|---|---|---|
-l |
加载数学库(library),启用三角函数(sin/cos)、对数(log)、平方根(sqrt)等,默认小数精度 scale=20 |
bc -l(进入交互模式后,输入 sqrt(25) 输出 5.00000000000000000000) |
scale=N |
自定义小数精度(N 为小数位数),默认 scale=0(浮点数运算默认取整),仅在交互模式或表达式中生效 |
交互模式输入 scale=3; 7/3(返回 2.333,保留 3 位小数) |
-q |
静默模式(quiet),进入交互模式时不显示版本和版权信息,界面更简洁 | bc -q(直接进入干净的交互界面,无多余输出) |
<<< "表达式" |
非交互模式执行单条 / 多条表达式(多表达式用分号分隔) | bc <<< "10^3; scale=2; 15/4; 8%3"(依次返回 1000、3.75、2) |
[tab] 键
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ whi //双击tab键
which while whiptail
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ which //单击tab键
Tab 键是 Linux 命令行中 最高效的操作辅助键,核心功能是 命令 / 路径 / 文件名的自动补全,无需手动输入完整内容,既能减少拼写错误,又能大幅提升操作效率,是命令行使用的 “必备技巧”。
核心作用
- 命令补全:输入命令的前几个字符后,按 Tab 键自动补全完整命令(若唯一匹配);若有多个匹配项,双击 Tab 键列出所有可选命令;
- 路径 / 文件名补全:输入目录、文件的前几个字符后,按 Tab 键自动补全完整路径 / 文件名(支持相对路径、绝对路径);
- 参数补全(部分命令支持):部分系统命令(如
apt、git)支持按 Tab 键补全后续参数或选项。
关键细节(结合操作示例)代码中的第一个操作:输入 whi 后双击 Tab 键
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ whi //双击tab键
which while whiptail
- 原理:系统会搜索
PATH环境变量(存储命令所在目录的变量)中,所有以whi开头的可执行命令; - 结果:找到 3 个匹配命令(
which、while、whiptail),因此双击 Tab 键时,系统会列出所有匹配项,供用户选择(后续可继续输入命令的后续字符缩小范围,再按 Tab 补全)。
代码中的第二个操作:输入 which 后单击 Tab 键
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ ~]$ which //单击tab键
- 原理:
which是完整且唯一的命令(无其他以which开头的命令),按 Tab 键时系统判断无需补全(命令已完整); - 结果:无额外输出,光标仅停留原地,此时可直接输入命令的参数(如
which ls查找ls命令的路径)。
补全规则(通用场景)
- 唯一匹配时:单击 Tab 键直接补全。例如输入
ec后按 Tab,若系统中只有echo命令以ec开头,会自动补全为echo; - 多个匹配时:单击 Tab 键无反应,双击 Tab 键列出所有匹配项。例如输入
g后双击 Tab,会列出git、grep、gcc等所有以g开头的命令; - 无匹配时:单击 / Tab 键均无反应,提示输入的前缀无对应命令 / 路径(需检查输入是否正确,如是否漏输字符、路径是否存在);
- 路径补全示例:输入
cd /ho后按 Tab,系统会自动补全为cd /home/(若/home目录存在);输入cat tes后按 Tab,若当前目录有test.txt文件,会补全为cat test.txt。
[Ctrl R] 键
(reverse-i-search)`rm': rm -rf test_1.txt
(reverse-i-search)`rm -rf t': rm -rf test test.txtCtrl+R 是 Linux 命令行(Bash 终端)中 历史命令反向搜索快捷键,核心作用是快速查找并复用之前执行过的命令,无需手动输入完整命令(尤其适合长命令、参数复杂的命令),是提升命令行操作效率的核心技巧之一。
核心功能从命令历史记录中 “反向”(从最近执行的命令往更早的命令)搜索匹配关键词的命令,实时显示匹配结果,支持快速选中执行或编辑后执行,避免重复输入长命令 / 复杂命令。
基本用法
- 触发搜索:在命令行空白处,按下
Ctrl键和R键的组合(Ctrl+R),终端会显示(reverse-i-search)提示符,进入反向搜索模式; - 输入关键词:在提示符后输入要搜索的命令关键词(如
rm、tar等),系统会实时匹配 “最近执行过的、包含该关键词” 的命令; - 选中命令:匹配到目标命令后,直接按回车键即可执行该命令;若需修改命令,按左 / 右方向键可退出搜索模式,进入命令编辑状态;
- 退出搜索:若未找到目标命令或不想执行,按
Esc键或Ctrl+G键,可退出搜索模式,返回命令行初始状态。
关键细节(结合操作示例)代码中的第一个搜索操作:
(reverse-i-search)`rm': rm -rf test_1.txt
- 触发过程:用户按下
Ctrl+R进入反向搜索模式,输入关键词rm; - 匹配逻辑:系统从 “最近执行的命令” 开始检索,找到第一个包含
rm关键词的命令rm -rf test_1.txt,并在终端显示匹配结果(格式为(reverse-i-search)关键词 ': 匹配到的完整命令 '); - 后续操作:此时按回车键会直接执行
rm -rf test_1.txt,按方向键可编辑该命令(如修改文件名)。
代码中的第二个搜索操作:
(reverse-i-search)`rm -rf t': rm -rf test test.txt
- 触发过程:用户在第一个搜索的基础上,继续输入关键词
rm -rf t(补充更多字符缩小范围); - 匹配逻辑:关键词越详细,匹配越精准 —— 补充
t后,系统匹配到包含 “rm -rf t” 片段的最近命令rm -rf test test.txt,避免了多个包含rm的命令混淆(如第一个示例中的rm -rf test_1.txt和第二个示例的rm -rf test test.txt); - 核心优势:通过补充关键词,可快速定位到目标命令,无需在多个匹配项中切换。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)