RoboAgent:Generalization and Efficiency in Robot Manipulation via Semantic Augmentations and Action
提出了一个能够在真实世界中进行多任务机器人操作、并且具备高样本效率和泛化能力的框架。通过语义场景增强快速扩增小规模机器人数据集训练一个多任务、语言条件控制的策略模型MT-ACT,能够吸收经过增强后的多模态数据。文章结合并改进了多个原本用于单任务策略的设计(例如,(动作块预测)、(时间聚合)),并证明这些方法在我们的多任务设置中仍然能显著提升性能。,对时间序列上的多个预测或数据进行整合处理,对预测动
|
序号 |
属性 | 值 |
|---|---|---|
| 1 | 论文名称 | RoboAgent |
| 2 | 发表时间/位置 | 2023 |
| 3 | Code | [RoboAgent: Towards Sample Efficient Robot Manipulation with Semantic Augmentations and Action Chunking](https://robopen.github.io/) |
| 4 | 创新点 |
1:数据增强,利用语义来增做数据增强,不改变指令和机器人轨迹。得到一个包含7500条数据的小规模数据,能够覆盖丰富的技能场景,提供模型泛化能力。 2:多任务动作块策略(MT-ACT: Multi-Task Action Chunking Transformer) 2.1生成式策略建模(CVAE + Transformer)。使用 CVAE 将动作序列编码为潜在风格向量 z。Transformer decoder 条件依赖 z 来生成动作。从而实现能够拟合多模态、具有随机性的轨迹,同时保证精度要求高的部分不被忽略。 2.2 语言条件(Task Embedding T)。使用预训练语言编码器获取任务描述 embedding,结合 FiLM conditioning,让图像特征可靠关注语言指令,避免多任务场景中的混淆。 2.3 动作块预测(Action Chunking)与时间聚合(Temporal Aggregation)。每个时间步预测 H 步连续动作(一个动作块),而不是单步预测。对重叠部分进行时间聚合,提高动作连续性和平滑性,减少误差累积。 2.4 多视角输入提升鲁棒性。结合四个摄像头视角,提高对场景变化、遮挡和干扰物的鲁棒性。提升在复杂环境下保持策略稳定和高性能的能力。 |
| 5 | 引用量 | 数据处理方面,采用了一个任务链的策略。利用cvar编码动作序列为潜在风格向量z。并利用transformer decoder生成动作序列(这个deoder就是MT-ACT) |

一:提出问题
实现一个能够在各种场景中操纵任意物体的通用机器人,是机器人的终极目标。但是当前数据集十分匮乏,而数据的采集需要大量的人工操作成本过于高昂。一个可行路径,是构建一种具有结构化能力框架的系统,使其能在合理的数据预算内实现广泛的泛化。
这里翻译的很抽象,结构化能力框架的系统:其实可以理解为一种可以把机器人技能、动作、数据、任务关系组织成“可学习、可复用、可组合”结构的系统,而不是杂乱无章地堆数据。让模型“学得有结构、有秩序”,而不是靠堆数据蛮力学习。
广泛的泛化:其实就是进一步提升泛化性。
本文提出一个高效的系统,用于训练能够熟练掌握多任务操控技能的通用agent,包含以下两个关键的机制:
1.语义增强(semantic augmentations):能够快速成倍扩增现有数据集;
2.动作表示(action representations):可在小规模但多样的多模态数据集上提取性能优异的策略,并避免过拟合。
稳定的任务条件输入机制和高表达能力的策略架构,使得agent能够根据语言指令,在全新情境中展现出多样化的技能组合。这篇文章关注的重点也是在给定的数据下,探索如何进一步提升agent的泛化能力。总的来说,主要从事了做了以下两个方面的贡献:
-
通过遥操作收集了 7500 条数据,确保了在不同场景中、不同技能的充分覆盖。 这些收集到的数据随后通过 语义增强 方法在离线阶段进行多样化扩展,而无需额外的人工或机器人代价,从而帮助模型在新情境中实现更好的泛化。
-
使用 MT-ACT 训练一个语言条件的操控策略模型。 MT-ACT 是一种能够处理多模态数据分布的多任务动作分块 Transformer。它利用机器人动作在时间上的相关性,通过预测 动作块(action chunks) 而不是逐步预测单个动作,使行为更平滑,并缓解在低数据模仿学习中常见的协变量偏移问题。
这里的协变量偏移的概念也很陌生,指的是训练时模型看到的状态(画面、位置、物体)和测试时实际遇到的状态不一样 , 导致模型越来越偏离专家轨迹,错得越来越严重。在模仿学习中,协变量就是机器人看到的状态,可能是摄像头画面,机械臂位置,关节夹角,语言指令等等。
二:解决方案
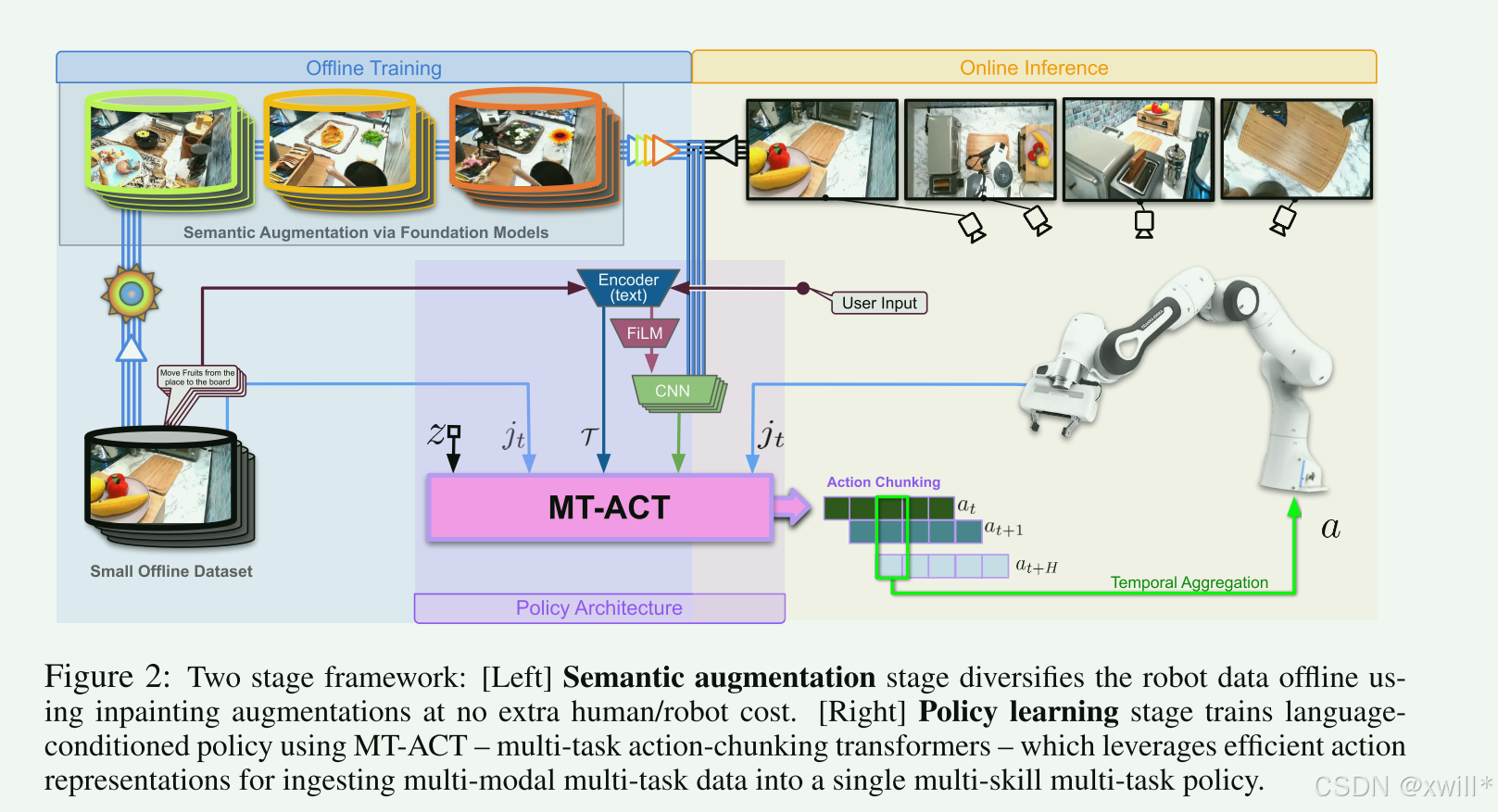
在有限数据量(预算)下,实现能够有效进行多任务学习的agent,策略主要包含两个阶段:
Semantic Augmentation(语义增强):通过在现有机器人数据上上创建多样的语义增强,成倍扩展已经收集的数据集。语义增强会将一个机器人示范重新“合成”多个示范。
Policy Learning(策略学习):在有限技能数据上学习稳健技能,它将先前仅限于单任务设定中的一些设计思想,扩展到含有多任务、多场景、多技能的大规模泛化操控任务中。提出一种基于语言条件输入的全新策略架构MT-ACT,用于训练能够从多模态数据集中恢复多种技能的稳健代理。采用 Conditional Variational Autoencoder(CVAE)来识别动作分布的不同模式,建模这些多模态、多任务并经过增强的数据集。从而使得能够基于 CVAE 的编码来训练一个高容量的 Transformer,从而有效捕捉增强数据集中的变化和依赖关系。此外,还利用了机器人动作具有时间相关性的特点。与逐步预测动作相比,预测“动作块(action chunks)”能产生更平滑的行为,并缓解低数据模仿学习中常见的协变量偏移问题。
在有限训练数据下,学到能在多种任务 & 多种场景中泛化的通用操控能力,MT-ACT 是实现这一目标的 策略网络(policy)
阶段 1:数据增强 = 让机器人“见过足够多”不需要新的数据,不需要机器人重新做一遍
阶段 2:策略学习 = 在小数据中学出“多种技能”
使用 CVAE 自动发现动作模式,比如,“抓起物体”、“平移移动”、“放下物体”,之后使用 Transformer学习这些模式之间的时序关系
使用动作块(Action Chunking)预测一段动作,而不是一帧动作,行为更稳定,大幅减少协变量偏移(错误不会每一步累积)
2.1Dataset (RoboSet)
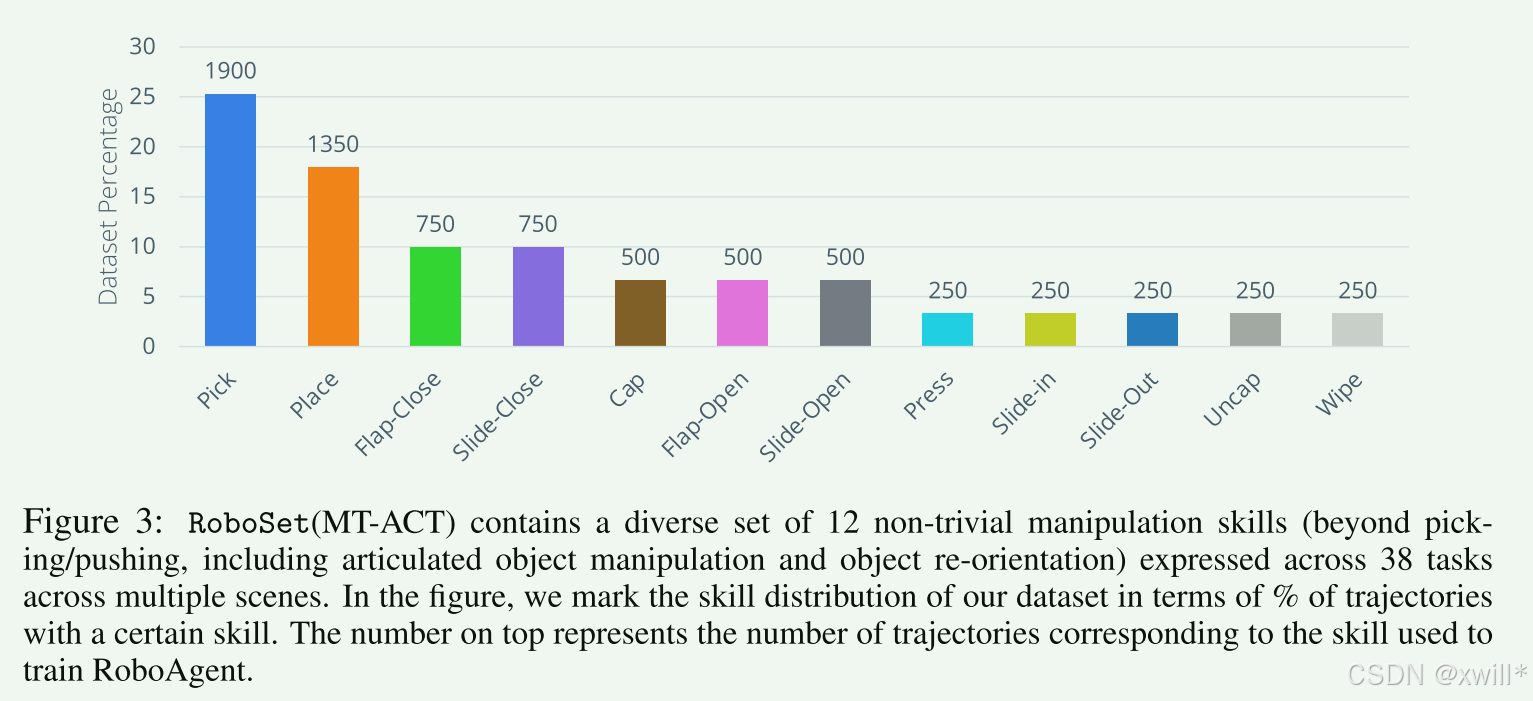
基于一个小但高度多样化的真实世界机器人数据集 RoboSet。通过确保覆盖不同的核心技能(能够在时间上相关的一系列动作,导致物体姿态(pose)产生合理变化的一段动作序列。例:打开或关闭可动结构的物体(开关门)),以保证捕获行为多样性。主要的工作也不是收集任务(每个技能都会在多个对象上进行实例化。我们将这种 (技能,物体) 的组合称为一个 任务),而是把任务设计成有结构、有逻辑、能按步骤串成一件完整的家务活动(例如清洁厨房)的任务序列。由于是专门用于多任务,且才采用动作分块和transformer策略的数据集,所以叫RoboSet(MT-ACT)。
2.2Data Augmentation
真实世界场景多样,训练数据不可能包含所有的场景,因此,如果不增强数据,模型在新环境中会轻易崩溃(泛化差)。这篇文章采用的不是传统的想颜色,图像反转之类的增强,而是针对数据做语义增强(轨迹相同,场景不同;动作保持一致,改变视觉环境):
-
不修改机器人的动作轨迹
-
只修改图像中的“语义内容”,如换物体、换桌子材质、换背景颜色、换厨房布局、加障碍物、修改纹理
从而让模型学习到,“动作与语言指令才是关键,背景变化无所谓”。数据增强的一个关键就是要保持机器人动作轨迹不变,例如数据是一个机器人在真实世界做了一条轨迹(拿杯子),然后把这个轨迹复制很多分,之后只修改视觉的内容,而这个轨迹动作不改变(拿黄色杯子,蓝色杯子),从而极大的增强了模型在未见过场景下的鲁棒性。
那么如何做到自动化生成动作轨迹呢?本文采用的是两个增强模型,一个用来自动找出物体区域,用来生成 mask(无需人工)的SAM(Segment Anything),另一个是根据 mask + 文本提示(如 “replace with a green mug”)来生成新的内容的大型inpainting模型。这些增强就类似于把互联网海量图像/视频里的语义知识间接“注入”到机器人数据中(文中作者也拿了nlp和cv的海量预训练作类比了)。
2.3MT-ACT Architecture
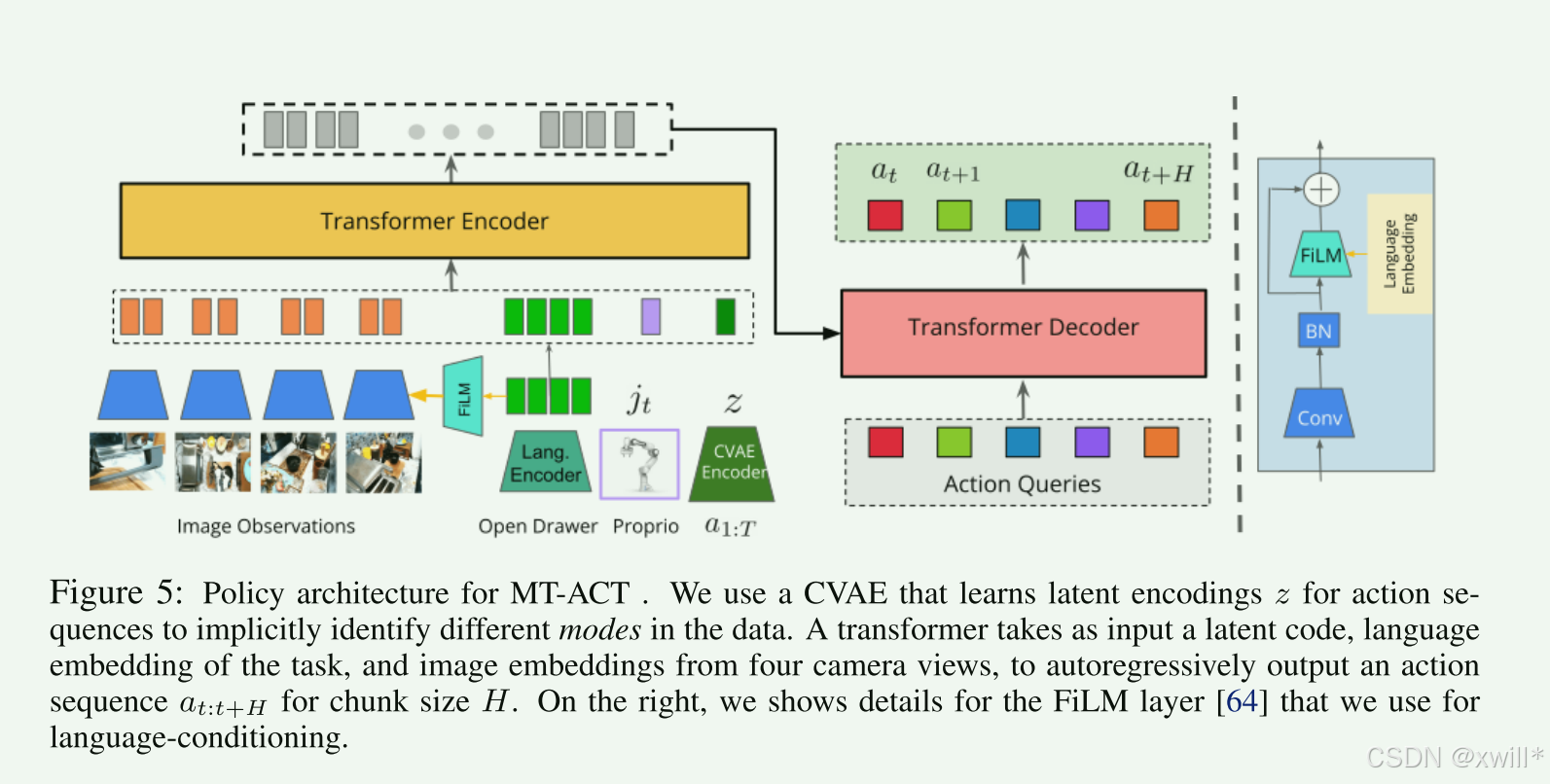
在机器学习中,扩大数据集的多样性和提升模型的规模是提升泛化能力的两个核心点。但是在现实世界中,由于成本的原因,极大的限制了可采集数据的规模,由于实时推理的需求,又极大限度的限制了模型的规模。在这个前提下,实现一在有限数据、有限模型大小的前提下,实现尽可能强的泛化能力,也就是MT-ACT。
MT-ACT 是一个具有足够容量的 Transformer,用来处理多模态、多任务的机器人数据集。为了更好的学习多模态数据,使用 CVAE,把动作序列编码成潜在风格向量 z。CVAE 的 decoder 就是 Transformer 策略模型,它依赖 z 来生成动作。这种把策略表示为生成模型的做法能很好地拟合多模态数据,不会忽略那些轨迹中精度要求高但又带随机性的部分。为了处理多任务数据,加入了一个预训练语言编码器,用来得到任务描述的 embedding T。为了减轻误差累计问题,并获得时间连续的平滑机器人动作,每个时间步预测未来 H 步的动作(一个 action chunk),并对重叠部分进行时间聚合。为了进一步提升对场景变化和遮挡的鲁棒性,MT-ACT结合了四个摄像头的视角。使用 FiLM conditioning,让图像特征可靠地关注语言指令,从而避免场景中有多个可能任务时产生混淆。编码后的 token 送入 Transformer 的 decoder,最终输出当前时间步的动作 chunk(H 个动作)。
CVAE 的作用:
encoder:把动作序列压成风格向量 z
decoder(Transformer):在不同 z 下生成不同的动作模式
保留每条示范的“风格”,而不是平均掉,从而能够生成更自然、更稳定的动作序列。CVAE(Conditional Variational Autoencoder) 是一种条件变分自编码器,核心思想是将原始数据(这里是动作序列)映射到一个 潜在空间(latent space),在潜在空间中,数据可以被表示为 概率分布。生成时,从潜在空间采样 z,然后通过 decoder 生成新的动作序列。
这里的z表示潜在风格向量(latent style vector),动作序列在潜在空间的表示。同一个任务或场景,不同演示可能动作略有不同(速度、抓取方式、轨迹弯曲程度等),z 可以表示这种“动作风格”或随机性。例如:同样的“拿杯子”动作,z 会编码高抬臂、低抬臂等不同风格。类似于一种个性标签,或者硕士风格模式。
FiLM conditioning:FiLM = Feature-wise Linear Modulation,用语言 embedding T 去控制视觉 token 的激活方式。意思是:
“打开抽屉” → 模型强制关注抽屉区域
“擦拭桌面” → 强制关注桌面位置
否则非常容易受到场景中其他物体的干扰,例如当:
有抽屉
有杯子
有门
有需要擦的台面
模型会混淆到底执行哪一个。FiLM 让视觉特征受语言引导,这是多任务场景的核心。
CVAE + Transformer 结合成 MT-ACT:MT-ACT 不是一个普通的 Transformer,它就是 CVAE 的 decoder,本质上是一个 “条件生成模型”(MT-ACT 的主体(Transformer)就是 CVAE 的 decoder)。
CVAE Encoder(动作序列 → latent z),将动作的多模态性压进低维空间,避免 Transformer 难以直接拟合多样动作。
CVAE Decoder = Transformer policy(z + 图像 + 状态 + 任务 → 动作 chunk)
其实就是通过CVAE生成策略后,一起丢进Transformer去解码。
三:实验
-
MT-ACT 在大量视觉操控任务上的定量和定性表现如何?能否泛化到新的任务、物体和环境?
-
语义数据增强是否能提升模型对噪声/干扰物的鲁棒性?
-
语义增强是否能帮助策略泛化到包含新物体的新场景?
-
MT-ACT 的策略架构是否具有高效率和高性能?
-
Action chunking(预测多步动作)是否能带来更平滑的轨迹和更高成功率?
四:总结
提出了一个能够在真实世界中进行多任务机器人操作、并且具备高样本效率和泛化能力的框架。整个框架基于:
-
通过语义场景增强快速扩增小规模机器人数据集
-
训练一个多任务、语言条件控制的策略模型 MT-ACT,能够吸收经过增强后的多模态数据。
文章结合并改进了多个原本用于单任务策略的设计(例如,action chunking(动作块预测)、temporal aggregation(时间聚合)),并证明这些方法在我们的多任务设置中仍然能显著提升性能。
temporal aggregation,对时间序列上的多个预测或数据进行整合处理,对预测动作在时间维度上做“汇总/平均/平滑”。在机器人控制里,它通常指:
模型每次预测一个动作序列(action chunk)
不是直接执行每个动作,而是对相邻时间步的动作做 平滑、平均或加权处理
以减少噪声、抖动或突变,让机器人动作更连续、自然
公开了目前规模最大的真实机器人操作数据集之一,包含超过 12 种技能,并覆盖多个厨房环境。
但是,仍然存在一定的局限性,包括:
1. 所有任务仅由单个技能组成 没有处理需要多个技能连贯组合的长时任务(long-horizon tasks),在将来也可以尝试实现自动将多个技能组合成复杂任务链条。(例如:打开柜子 → 取出物品 → 放到锅里 → 打开炉子,这样的任务需要 skill composition。)
2. 没有探索语言泛化能力
直接使用预训练语言编码器(如 CLIP text encoder),没有做针对性的优化或适配。因此对指令表述略微变化可能不够鲁棒,无法处理未见过的语言模板,可能理解不了更复杂的语言组合。在将来也可以探索更灵活、更可适配的语言条件模块,例如语言微调、多模态对齐、结构化语言规划等。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)