重磅:手把手教你把paddleocr-vl做成mcp使其在DIFY里运行
本文详解如何将国产顶尖多模态 OCR 模型 PaddleOCR-VL 封装为标准 MCP(Model Calling Protocol)服务,并通过自研的 HTTP-based MCP Client 接入 Dify 1.10,实现 AI Agent 在对话中自动识别并调用 OCR 能力。该方案已在某头部保险公司真实业务流程中落地,使用了当前最先进的“Agentic AI 原生”设计思想。

前言
在 2025 年,“AI Agent”已经从概念走向工程化落地。我们不再满足于大模型被动回答问题,而是期望它能主动感知环境、调用工具、执行任务——就像一个真正的数字员工。而要实现这一点,关键在于“能力可插拔”与“协议标准化”。
MCP(Model Calling Protocol)正是这样一种轻量、开放、面向 AI Agent 的服务调用协议。它允许 Agent 动态发现并调用外部工具,而无需硬编码逻辑。
过去一阵子里,我在“2025最前沿AI Agent讲武堂”专栏中陆续介绍了多种前沿 Agent 架构与工具集成方案。其中,PaddleOCR-VL 作为百度开源的多模态 OCR 模型,凭借其对复杂版式、表格、手写体甚至低质量图像的卓越识别能力,成为国内企业私有化部署 OCR 的首选。我们此前已讲解过其本地部署方法。但仅能本地运行远远不够——真正的智能,是在对话流中“按需调用”。
这次,我将分享一个来自一线生产环境(头部某巨型保险公司)的真实案例:如何将 PaddleOCR-VL 改造成符合 MCP 规范的服务端(MCP Server),再通过一个基于 Flask 实现的 HTTP MCP Client,将其无缝集成进 Dify 1.10 的 Agent 工作流中。
当用户上传一张包含关键信息的 PDF 或截图时,Agent 能自动判断需要 OCR,并通过 MCP 协议调度本地 OCR 引擎完成解析,最终将结构化文本融入后续推理。这不仅是技术整合,更是迈向“自主感知-决策-执行”闭环的关键一步。接下来,我会从原理出发,拆解这一架构的设计逻辑与必要性。
1. 为什么必须用 MCP?——AI Agent 时代的工具调用新范式
1.1 传统 OCR 集成方式的局限性
在 Dify 或类似低代码 Agent 平台早期版本中,若想引入 OCR 能力,常见做法包括:
- 硬编码在后端逻辑中:当检测到用户上传图片,直接调用 PaddleOCR-VL。这种方式耦合度高,无法复用于其他 Agent 或平台。
- 通过 Function Calling 注册工具:利用 LLM 的 function calling 能力定义一个
ocr_extract函数。但问题在于:- 函数定义需写死在 Agent 配置中,缺乏动态发现机制;
- 多个 Agent 若都需要 OCR,需重复注册;
- 无法跨语言、跨网络调用,扩展性差;
- 当 OCR 模型升级或切换为其他引擎(如腾讯 OCR、阿里 IDP),需修改 Agent 逻辑。
这些方法本质上仍是“以模型为中心”的旧思路,而非“以能力为中心”的 Agent 原生设计。
1.2 MCP 协议的核心价值
MCP 是一种轻量级、基于 JSON-RPC 风格的远程过程调用协议,专为 AI Agent 设计。其核心思想是:将每个外部工具抽象为一个独立的“能力服务”,Agent 通过标准接口发现、调用、组合这些服务。
MCP 具备以下特性:
- 解耦:Agent 与工具完全分离,工具可独立开发、部署、升级;
- 发现机制:Agent 可通过
/manifest接口获取服务支持的能力列表、参数说明、调用示例; - 标准化输入输出:所有调用遵循统一格式,便于日志、监控、重试等中间件处理;
- 跨平台兼容:只要实现 MCP Server 接口,任何语言(Python/Go/Java)写的工具均可被调用;
- 权限与安全隔离:可通过网关控制哪些 Agent 可访问特定 MCP 服务。
笔者在参与多个金融、保险类项目时深刻体会到:企业级 Agent 系统必须具备“能力即服务”(Capability as a Service)的架构。PaddleOCR-VL 作为敏感数据处理的关键环节,必须运行在内网,且不能暴露原始模型 API。MCP 正好提供了安全、规范、可审计的调用通道。
1.3 为何选择 HTTP + Flask 实现 MCP Client?
目前社区常见的 MCP Client 多为 SDK 形式(如 Python 包),需嵌入 Agent 主程序。但在 Dify 这类 SaaS 或私有化平台中,Agent 运行在平台内部,开发者无法直接修改其代码。
我们的解决方案是:构建一个独立的 HTTP 服务作为 MCP Client 中转层。具体流程如下:
- Dify 中的 Agent 配置一个“自定义工具”,指向我们的 Flask 服务(如
http://mcp-client:5000/call); - 当 Agent 决定调用 OCR 时,向该 URL 发送标准 MCP 请求;
- Flask 服务接收请求,解析目标 MCP Server 地址(如
http://paddleocr-mcp:8080),转发调用; - 获取结果后,按 Dify 要求的格式返回结构化文本。
这种设计的优势在于:
- ✅ 无需改动 Dify 源码:完全通过外部服务集成;
- ✅ 支持多 MCP Server 路由:未来可轻松接入 NLP、RPA、数据库查询等其他 MCP 服务;
- ✅ 便于调试与日志追踪:所有调用经过统一入口,可加埋点、限流、缓存;
- ✅ 符合微服务架构:各组件职责清晰,运维友好。
我在某保险公司知识库问答系统中落地此方案时,仅用两天就完成了从 PaddleOCR-VL 到 MCP Server 的封装,并通过该 Client 接入 Dify。上线后,客服 Agent 自动处理用户上传的保单截图、身份证照片、理赔表单,OCR 准确率超 92%,人工干预下降 70%。这让我坚信:MCP 不是炫技,而是工程落地的刚需。
1.4 为什么是 PaddleOCR-VL?
在众多 OCR 方案中,PaddleOCR-VL 的优势尤为突出:
- 多模态理解能力:不仅能识别文字,还能理解版面结构(标题、段落、表格)、图文关系;
- 中文场景优化:针对发票、合同、证件等中文复杂文档训练,效果远超通用 OCR;
- 开源免费+可私有部署:无调用费用,数据不出内网,符合金融合规要求;
- 支持 ONNX/TensorRT 加速:推理速度快,适合高并发场景。
相比之下,商业 OCR API 虽简单,但存在数据泄露风险、调用成本高、定制能力弱等问题。而传统 Tesseract 等开源方案在复杂文档上表现不佳。PaddleOCR-VL 成为平衡效果、成本、安全的最佳选择。
笔者在测试中发现,对于一张模糊的手机拍摄保单照片,PaddleOCR-VL 能准确提取出“被保险人”、“保单号”、“生效日期”等字段,并保留表格结构;而其他 OCR 工具则出现大量乱码或漏识。这种能力,正是企业级 Agent 所需的“可靠视觉感知”。
2. 设计前的准备
我们依旧坚持使用AI原生并使用agentic flow来做这个设计。
2.1 环境准备
- nginix服务,可以把本地某一个目录暴露成如:http://localhost/mkcdn/这样的形式,并把需要ocr解析的pdf, 图片等放于此目录下;
- paddleocr-vl做成本地web服务,见我之前写得《paddleocr-vl全网唯一最全本地化布署教程》
- 一个基于python13的mcp server,在这个mcp server里可以调用paddleocr-vl的 web服务,传送pdf、图片用于解析;
- 一个使用flask做的mcp client,用于和dify通讯;
- dify,我这使用的是1.10;
2.1.1 mcp server及client环境准备
conda create -n py13 python=3.13 -y
conda activate py13
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"我们虚拟一个python13的环境,把uv和虚拟环境关联上。
uv init quickmcp新建一个mcp工程,我们会把server端和client端均放置于这个目录内。
- 修改:quickmcp里的.python-version
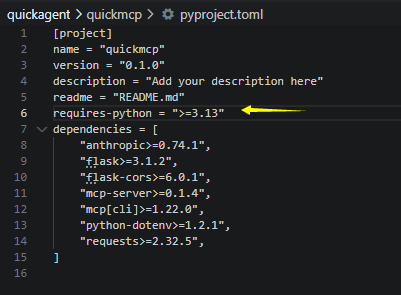
- 修改:quickmcp里的.project.toml
把里面的python version全部改成3.13

进入到quickmcp目录下运行
uv venv --python="D:\utility\miniconda3\envs\py13\python.exe" .venv于是每次记得在第1次运行前要做虚拟环境激活。
第1步:激活python13虚拟环境
conda activate py13第2步:激活quickmcp的uv虚拟环境
一定务必要进入到quickmcp目录下运行
.\.venv\Scripts\activate安装需要使用到的uv包
uv add mcp-server
uv add mcp
uv add mcp[cli]
uv add requests
npm install @modelcontextprotocol/inspector@0.8.0
uv add mcp anthropic python-dotenv
uv add flask flask-cors于是我们的mcp server以及client要编译和运行的包全部都全了。
2.2 具体流程
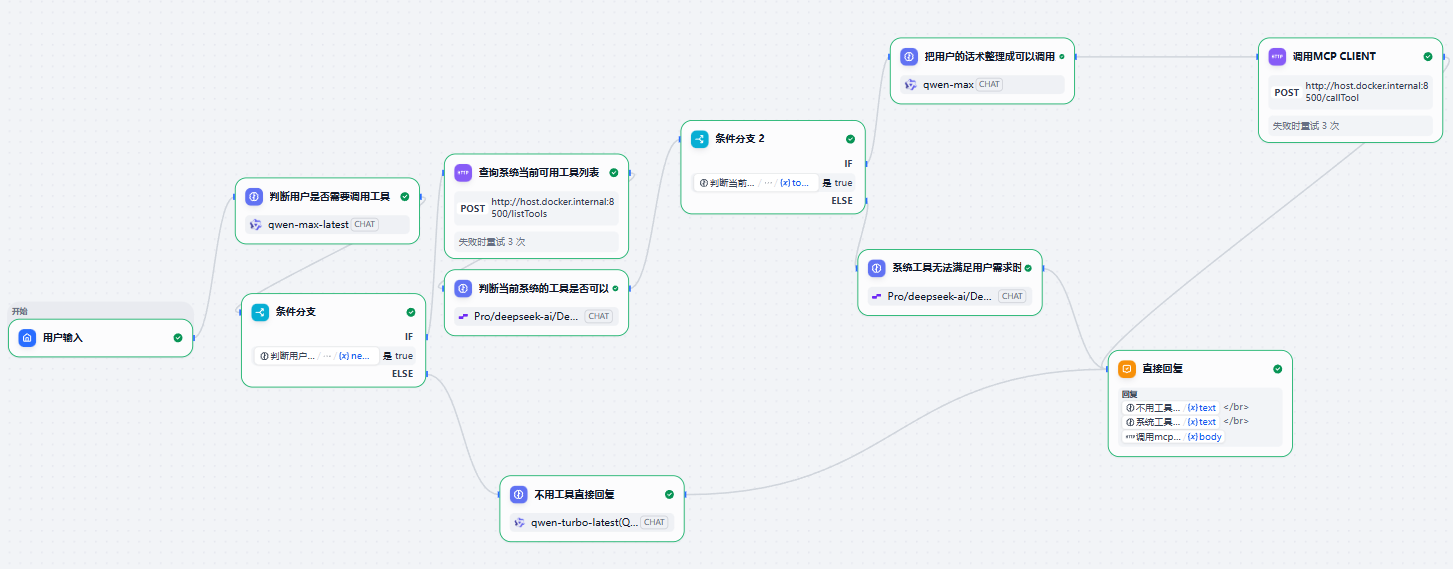
3. 全流程及代码详细解读
判断是否需要使用工具才能让对话继续的判断
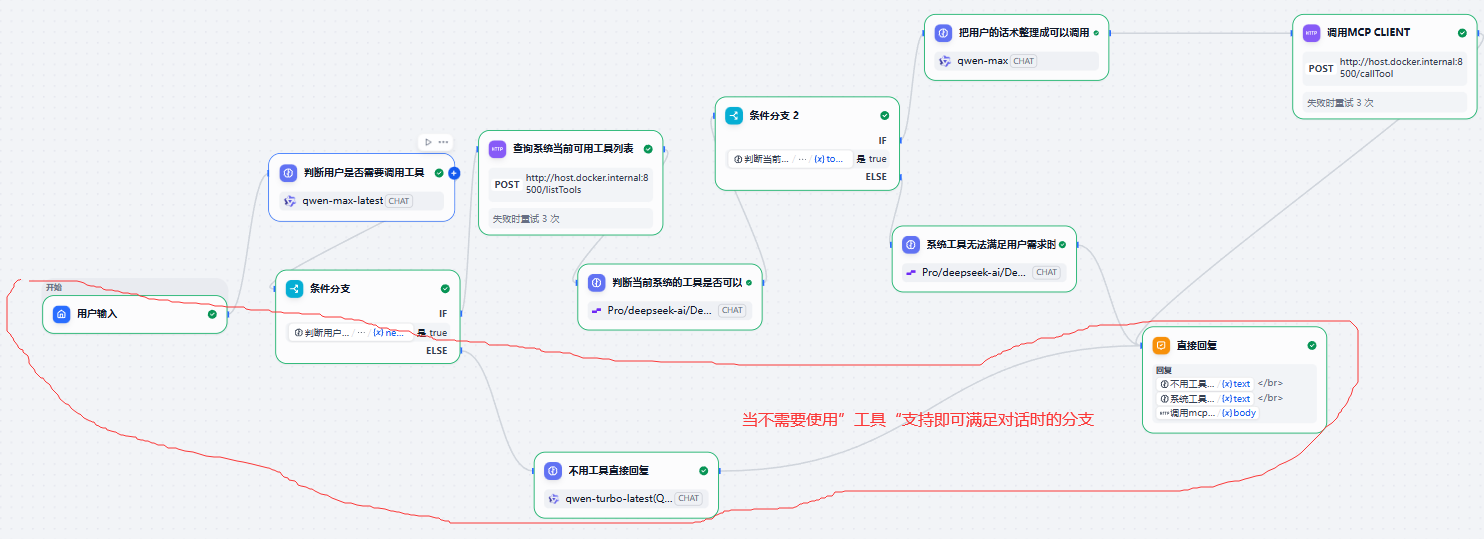
猫娘
系统猫娘-system role
#任务设定
1.你基于用户当前的输入看一下是否需要调用工具来辅助你完成。
2.你的返回是以这样的JSON Schema来返回:
{
"needCallTool": True-代表需要调用工具来辅助完成当前任务 false-代表不需要调用工具来辅助助完成当前任务
}用户猫娘-user role
{{#sys.query#}}返回内容
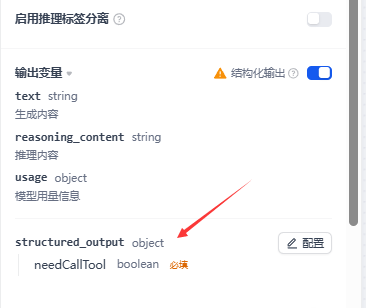
此时如果得到false,那么当前对话被判断成不需要使用工具,否则就会走:使用工具来辅助回答用户当前的提问这条分支。
我们顺着false往后走
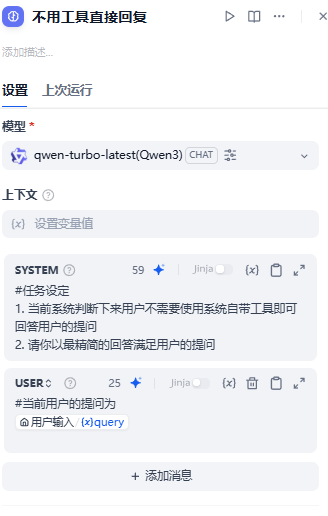
随后在这个节点后套上“消息输出”即可。
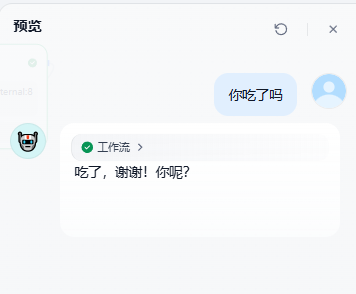
比如説用户当前输入的内容为:
你吃了吗?回答如下
当用户的提问需要使用工具才能继续逻辑分支设计
假设用户当前的提问需要使用到工具,此时就需要经历以下3步:
- 第1步-先确认当前系统工具支不支持用户提前的提问?
- 第2步-如果不支持或者缺少工具我们需要告诉用户不支持
- 第3步-如果支持才真正进入调用工具,如本案例内的paddleocr-vl
比如説,本例中我们只提供一种工具:ocr_files,用的是paddleocr-vl本地web服务,因此当用户如果这样提问时:
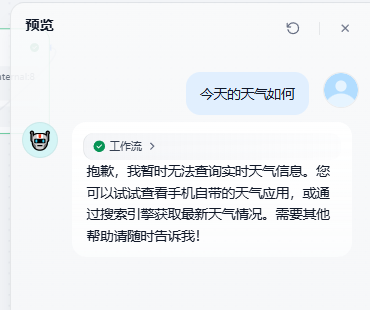
我们可以看到虽然逻辑分支走到了:确认用户是需要调用工具,但也会做一个检查,这个检查正是mcp协议里的listTools。
mcp server全代码-BatchOcr.py
import json
import sys
import os
import logging
from logging.handlers import TimedRotatingFileHandler, RotatingFileHandler
from datetime import datetime
from typing import Any, Dict, List
from pydantic import BaseModel, Field
import httpx
from mcp.server.fastmcp import FastMCP
from mcp.server import Server
import uvicorn
from starlette.applications import Starlette
from mcp.server.sse import SseServerTransport
from starlette.requests import Request
from starlette.responses import Response
from starlette.routing import Mount, Route
# 设置日志
log_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), "logs")
os.makedirs(log_dir, exist_ok=True)
# 当前日期的日志文件名
log_file = os.path.join(log_dir, f"BatchOcr_{datetime.now().strftime('%Y%m%d')}.log")
# 创建文件处理器:按天轮转,当文件大小超过50MB也会轮转
file_handler = RotatingFileHandler(
log_file,
maxBytes=50 * 1024 * 1024, # 50MB
backupCount=30, # 保留30个备份文件
encoding='utf-8'
)
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
# 创建控制台处理器
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
console_handler.setFormatter(logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
# 配置根日志记录器
logging.basicConfig(
level=logging.INFO,
handlers=[file_handler, console_handler]
)
logger = logging.getLogger("BatchOcr")
logger.info("日志系统初始化完成")
# 定义文件数据模型
class FileData(BaseModel):
"""单个文件的数据结构"""
file: str = Field(..., description="文件URL地址")
fileType: int = Field(..., description="文件类型: 0=PDF, 1=图片")
class OcrFilesInput(BaseModel):
"""OCR文件输入参数"""
files: List[FileData] = Field(..., description="要处理的文件列表")
# 初始化FastMCP对象
mcp = FastMCP("BatchOcr")
logger.info("FastMCP初始化完成")
@mcp.tool()
async def ocr_files(files: List[FileData]) -> str:
"""使用本地paddleocr-vl提取用户输入中的文件url进行批量或者单个扫描
Args:
files: 文件列表,每个文件包含file(URL)和fileType(0=PDF, 1=图片)字段。
示例: [{"file": "http://localhost/mkcdn/ocrsample/20251122/1.png", "fileType": 1}]
"""
logger.info(f"收到OCR请求,文件数量: {len(files)}")
# OCR服务地址
OCR_SERVICE_URL = "http://localhost:8080/layout-parsing"
# 存储所有OCR结果
all_text_results = []
# 逐个处理每个文件
for idx, file_data in enumerate(files):
try:
logger.info(f"正在处理第 {idx + 1}/{len(files)} 个文件: {file_data.file}, 类型: {file_data.fileType}")
# 调用本地OCR服务
ocr_payload = {
"file": file_data.file,
"fileType": file_data.fileType
}
async with httpx.AsyncClient(timeout=60.0) as client:
response = await client.post(
OCR_SERVICE_URL,
json=ocr_payload,
headers={
"Content-Type": "application/json",
"Connection": "keep-alive"
}
)
# 检查响应状态
if response.status_code != 200:
error_msg = f"OCR服务返回错误状态码 {response.status_code},文件: {file_data.file}"
logger.error(error_msg)
all_text_results.append(f"错误: {error_msg}")
continue
# 获取OCR服务返回的JSON数据
ocr_response = response.json()
# 提取block_content内容
text_blocks = []
if "result" in ocr_response and "layoutParsingResults" in ocr_response["result"]:
for layout in ocr_response["result"]["layoutParsingResults"]:
if "prunedResult" in layout and "parsing_res_list" in layout["prunedResult"]:
blocks = layout["prunedResult"]["parsing_res_list"]
# 提取所有block_content
for block in blocks:
block_content = block.get("block_content", "")
if block_content:
text_blocks.append(block_content)
if text_blocks:
# 将当前文件的所有block_content用换行连接
file_result = "\n".join(text_blocks)
all_text_results.append(file_result)
logger.info(f"成功处理文件 {idx + 1}: {file_data.file},提取到 {len(text_blocks)} 个文本块")
else:
logger.warning(f"文件 {file_data.file} 未提取到任何文本内容")
all_text_results.append(f"警告: 文件 {file_data.file} 未提取到文本内容")
except httpx.RequestError as e:
error_msg = f"调用OCR服务时发生网络错误,文件: {file_data.file},错误: {str(e)}"
logger.error(error_msg, exc_info=True)
all_text_results.append(f"错误: {error_msg}")
except Exception as e:
error_msg = f"处理文件时发生未知错误,文件: {file_data.file},错误: {str(e)}"
logger.error(error_msg, exc_info=True)
all_text_results.append(f"错误: {error_msg}")
# 将所有结果用换行符连接
final_result = "\n".join(all_text_results)
logger.info(f"批量OCR处理完成,共处理 {len(files)} 个文件")
# 返回结果(确保使用UTF-8编码)
return json.dumps({"result": final_result}, ensure_ascii=False)
def create_starlette_app(mcp_server: Server, *, debug: bool = False) -> Starlette:
"""Create a Starlette application that can server the provied mcp server with SSE."""
sse = SseServerTransport("/messages/")
async def handle_sse(request: Request):
logger.info("收到SSE连接请求")
logger.info(f"请求方法: {request.method}, 路径: {request.url.path}")
logger.info(f"请求头: {dict(request.headers)}")
try:
async with sse.connect_sse(
request.scope,
request.receive,
request._send, # noqa: SLF001
) as (read_stream, write_stream):
logger.info("SSE连接已建立,开始运行MCP服务器")
await mcp_server.run(
read_stream,
write_stream,
mcp_server.create_initialization_options(),
)
logger.info("MCP服务器运行完毕")
except Exception as e:
logger.error(f"SSE处理出错: {str(e)}", exc_info=True)
raise
# 返回空响应以避免Starlette报错
return Response()
return Starlette(
debug=debug,
routes=[
Route("/sse", endpoint=handle_sse),
Mount("/messages/", app=sse.handle_post_message),
],
)
def run_server():
"""直接运行SSE服务器"""
import argparse
parser = argparse.ArgumentParser(description='Run MCP SSE-based server')
parser.add_argument('--host', default='127.0.0.1', help='Host to bind to')
parser.add_argument('--port', type=int, default=8090, help='Port to listen on')
args = parser.parse_args()
mcp_server = mcp._mcp_server # noqa: WPS437
starlette_app = create_starlette_app(mcp_server, debug=True)
logger.info(f"Starting SSE server on {args.host}:{args.port}")
uvicorn.run(starlette_app, host=args.host, port=args.port)
if __name__ == "__main__":
run_server()
mcp server端代码全解读
上述代码提供了标准的mcp http方式的接入。
上述代码有一个工具,tool_name为:ocr_files,它接受一个这样的参数输入:
"tool_args": {
"files": [
{
"file": "http://localhost/mkcdn/ocrsample/20251122/1.png",
"fileType": 1
}
]
}然后会根据files:[]里的数组元素开始循环,每一次循环去访问本地的paddleocr-vl的ocr解析请求如:
curl --location --request POST 'http://localhost:8080/layout-parsing' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Content-Type: application/json' \
--data-raw '{
"file": "http://localhost/mkcdn/ocrsample/test-1.pdf",
"fileType": 0
}'然后把本地paddleocr-vl解析成功后的请求即:block_content里的值一个个累加在一起并最终以一个string(如以下返回格式)返回给到mcp-client端
{
"result": "ocr解析后的文字段落"
}mcp client端全代码-QuickMcpClient.py
这是一个标准的mcp client端并且它的入口是flask api,这是全网唯一真实环境的并且不是以示例代码中那种command窗口作为入口的例子,绝无仅有仅在此篇。此次我给出完整解决方案来给到需要学习和研究得各位读者。
import logging
from logging.handlers import RotatingFileHandler
import asyncio
import json
import os
from typing import Optional
from contextlib import AsyncExitStack
from datetime import datetime
import threading
from mcp import ClientSession
from mcp.client.sse import sse_client
from anthropic import Anthropic
from dotenv import load_dotenv
from flask import Flask, request, jsonify
from flask_cors import CORS
# 确保日志目录存在
log_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), "logs")
if not os.path.exists(log_dir):
os.makedirs(log_dir)
print(f"创建日志目录: {log_dir}")
# 当前日期的日志文件名
log_file = os.path.join(log_dir, f"QuickMcpClient_{datetime.now().strftime('%Y%m%d')}.log")
# 创建文件处理器:按天轮转,当文件大小超过50MB也会轮转
file_handler = RotatingFileHandler(
log_file,
maxBytes=50 * 1024 * 1024, # 50MB
backupCount=30, # 保留30个备份文件
encoding='utf-8'
)
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
# 创建控制台处理器
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
console_handler.setFormatter(logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
# 配置日志
logging.basicConfig(
level=logging.INFO,
handlers=[console_handler, file_handler]
)
logger = logging.getLogger("QuickMcpClient")
# 创建 Flask 应用
app = Flask(__name__)
CORS(app) # 启用跨域支持
class MCPClient:
def __init__(self):
# Initialize session and client objects
self.session: Optional[ClientSession] = None
self.exit_stack = AsyncExitStack()
self.anthropic = Anthropic()
self._streams_context = None
self._session_context = None
self._loop = None
self._loop_thread = None
async def connect_to_sse_server(self, base_url: str):
"""Connect to an MCP server running with SSE transport
Args:
base_url: Base URL of the server (e.g., http://127.0.0.1:8090)
"""
try:
# SSE client expects base_url + /sse for GET and base_url + /messages for POST
# Based on BatchOcr.py implementation
logger.info(f"正在连接到 MCP 服务器: {base_url}")
# Store the context managers so they stay alive
self._streams_context = sse_client(url=base_url)
streams = await self._streams_context.__aenter__()
self._session_context = ClientSession(*streams)
self.session: ClientSession = await self._session_context.__aenter__()
# Initialize
logger.info("正在初始化会话...")
await self.session.initialize()
# List available tools to verify connection
logger.info("连接成功,会话已初始化")
return True # 添加返回值,表示连接成功
except Exception as e:
logger.error(f"连接服务器时出错: {str(e)}", exc_info=True)
return False # 连接失败时返回False
async def get_tools_list(self):
"""获取工具列表并返回JSON格式"""
try:
if not self.session:
logger.error("会话未初始化,请先连接到服务器")
return None
logger.info("正在获取工具列表...")
response = await self.session.list_tools()
tools = response.tools
# 调试:查看 tool 对象的属性
if tools:
logger.info(f"Tool 对象的所有属性: {dir(tools[0])}")
logger.info(f"Tool 对象类型: {type(tools[0])}")
if hasattr(tools[0], '__dict__'):
logger.info(f"Tool 对象内容: {tools[0].__dict__}")
# 使用json.dumps格式化工具列表,indent参数控制缩进
tools_json = json.dumps(
{"tools": [{"name": tool.name,
"description": tool.description,
"inputSchema": tool.inputSchema if hasattr(tool, 'inputSchema') and tool.inputSchema else None}
for tool in tools]},
indent=4,
ensure_ascii=False
)
logger.info(f"获取到 {len(tools)} 个工具")
logger.info(f"工具详细信息:\n{tools_json}")
return json.loads(tools_json)
except Exception as e:
logger.error(f"获取工具列表时出错: {str(e)}", exc_info=True)
return None
async def call_tool(self, tool_name: str, tool_args: dict):
"""动态调用 MCP 工具
Args:
tool_name: 工具名称
tool_args: 工具参数(字典格式)
Returns:
工具执行结果
"""
try:
if not self.session:
logger.error("会话未初始化,请先连接到服务器")
return None
logger.info(f"正在调用工具: {tool_name}")
logger.info(f"工具参数: {json.dumps(tool_args, ensure_ascii=False, indent=2)}")
# 调用 MCP session 的 call_tool 方法
result = await self.session.call_tool(tool_name, tool_args)
logger.info(f"工具 {tool_name} 执行成功")
logger.info(f"执行结果: {result}")
return result
except Exception as e:
logger.error(f"调用工具 {tool_name} 时出错: {str(e)}", exc_info=True)
raise
async def cleanup(self):
"""Properly clean up the session and streams"""
try:
if hasattr(self, '_session_context') and self._session_context:
await self._session_context.__aexit__(None, None, None)
if hasattr(self, '_streams_context') and self._streams_context:
await self._streams_context.__aexit__(None, None, None)
self.session = None
self._session_context = None
self._streams_context = None
logger.info("清理完成")
except Exception as e:
logger.error(f"清理时出错: {str(e)}")
def _start_event_loop(self):
"""在独立线程中启动事件循环"""
asyncio.set_event_loop(self._loop)
self._loop.run_forever()
def run_async(self, coro):
"""在事件循环中运行协程"""
if self._loop is None:
self._loop = asyncio.new_event_loop()
self._loop_thread = threading.Thread(target=self._start_event_loop, daemon=True)
self._loop_thread.start()
future = asyncio.run_coroutine_threadsafe(coro, self._loop)
return future.result(timeout=30) # 30秒超时
# 全局 MCP 客户端实例
mcp_client = MCPClient()
@app.route('/listTools', methods=['POST'])
def list_tools():
"""
获取 MCP 服务器的工具列表
请求体示例:
{
"base_url": "http://127.0.0.1:8090/sse" # 可选,如果已连接则不需要
}
"""
try:
data = request.get_json(force=True, silent=True) or {}
base_url = data.get('base_url')
# 如果提供了 base_url 且尚未连接,则先连接
if base_url and not mcp_client.session:
logger.info(f"尝试连接到服务器: {base_url}")
success = mcp_client.run_async(mcp_client.connect_to_sse_server(base_url=base_url))
if not success:
return jsonify({
"status": "error",
"message": "连接到 MCP 服务器失败"
}), 500
# 检查会话是否已建立
if not mcp_client.session:
return jsonify({
"status": "error",
"message": "未连接到 MCP 服务器,请提供 base_url 参数"
}), 400
# 获取工具列表
tools_data = mcp_client.run_async(mcp_client.get_tools_list())
if tools_data is None:
return jsonify({
"status": "error",
"message": "获取工具列表失败"
}), 500
return jsonify({
"status": "success",
"data": tools_data
}), 200
except Exception as e:
logger.error(f"处理 listTools 请求时出错: {str(e)}", exc_info=True)
return jsonify({
"status": "error",
"message": str(e)
}), 500
@app.route('/callTool', methods=['POST'])
def call_tool():
"""
动态调用 MCP 工具
请求体示例:
{
"base_url": "http://127.0.0.1:8090/sse", # 可选,如果已连接则不需要
"tool_name": "ocr_files",
"tool_args": {
"files": [
{
"file": "http://localhost/mkcdn/ocrsample/20251122/1.png",
"fileType": 1
}
]
}
}
"""
try:
data = request.get_json(force=True, silent=True)
if not data:
return jsonify({
"status": "error",
"message": "请求体不能为空"
}), 400
# 获取参数
base_url = data.get('base_url', 'http://127.0.0.1:8090/sse') # 默认值
tool_name = data.get('tool_name')
tool_args = data.get('tool_args', {})
# 验证必须参数
if not tool_name:
return jsonify({
"status": "error",
"message": "缺少必须参数: tool_name"
}), 400
# 如果提供了 base_url 且尚未连接,则先连接
if base_url and not mcp_client.session:
logger.info(f"尝试连接到服务器: {base_url}")
success = mcp_client.run_async(mcp_client.connect_to_sse_server(base_url=base_url))
if not success:
return jsonify({
"status": "error",
"message": "连接到 MCP 服务器失败"
}), 500
# 检查会话是否已建立
if not mcp_client.session:
return jsonify({
"status": "error",
"message": "未连接到 MCP 服务器,请提供 base_url 参数"
}), 400
# 调用工具
result = mcp_client.run_async(mcp_client.call_tool(tool_name, tool_args))
# 处理结果
if result is None:
return jsonify({
"status": "error",
"message": f"调用工具 {tool_name} 失败"
}), 500
# 解析 result 对象
result_data = {}
if hasattr(result, 'content'):
# MCP 返回的 result 通常包含 content 属性
content = result.content
if isinstance(content, list) and len(content) > 0:
# content 是一个列表,取第一个元素
first_content = content[0]
if hasattr(first_content, 'text'):
# 如果是 TextContent,提取 text 字段
result_text = first_content.text
try:
# 尝试解析为 JSON
result_data = json.loads(result_text)
except json.JSONDecodeError:
# 如果不是 JSON,直接返回文本
result_data = {"text": result_text}
else:
result_data = {"content": str(first_content)}
else:
result_data = {"content": str(content)}
else:
result_data = {"raw": str(result)}
return jsonify({
"status": "success",
"data": result_data
}), 200
except Exception as e:
logger.error(f"处理 callTool 请求时出错: {str(e)}", exc_info=True)
return jsonify({
"status": "error",
"message": str(e)
}), 500
@app.route('/', methods=['GET'])
def index():
"""根路径,用于测试 Flask 是否正常运行"""
return jsonify({
"message": "QuickMcpClient Flask Server is running",
"endpoints": ["/health", "/listTools", "/callTool"]
}), 200
@app.route('/health', methods=['GET'])
def health_check():
"""健康检查接口"""
return jsonify({
"status": "ok",
"connected": mcp_client.session is not None
}), 200
if __name__ == "__main__":
load_dotenv()
logger.info("启动 QuickMcpClient Flask 服务器...")
app.run(host='0.0.0.0', port=8500, debug=True)
mcp client端代码解读
- 整个代码提供了get请求方式的health,用于查看mcp client是否活着;
- listTools,这是标准的mcp协议中的listTools接口,用于返回系统当前提供了哪些“工具”列表以及它们的元数据即:metadata。
- callTool-通过mcp client去执行mcp server上的工具。
在继续讲流程前先把mcp server和mcp client运行起来
运行mcp server
python BatchOcr.py --host 127.0.0.1 --port 8090
运行mcp client
python QuickMcpClient.py
下面继续讲流程
接着 “当用户的提问需要使用工具才能继续逻辑分支”
如何判断当前系统提供的“工具集”满足用户当前的提问?
正是用到了mcp client里的listTools。来看流程设计
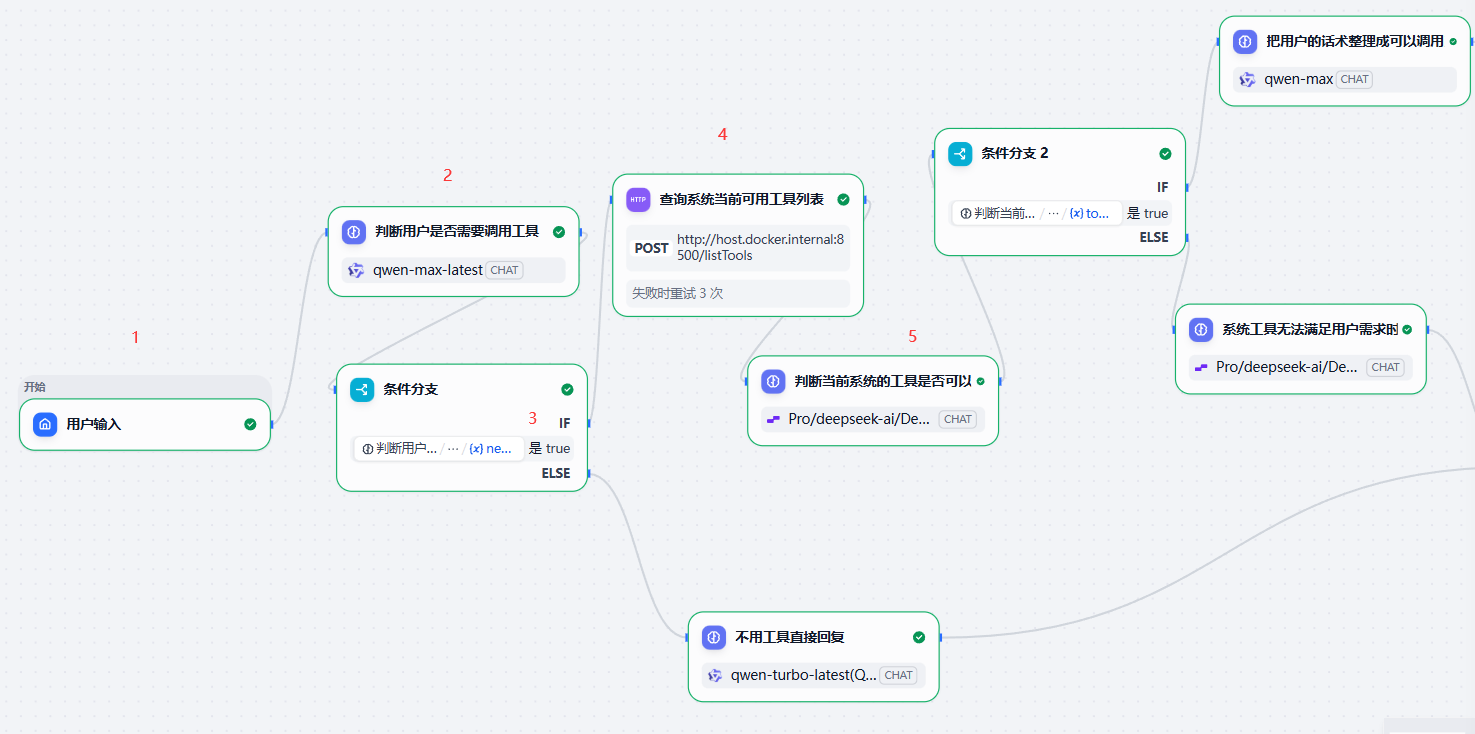
看第“4”步中,我们恰恰call的是mcp client里的listTool
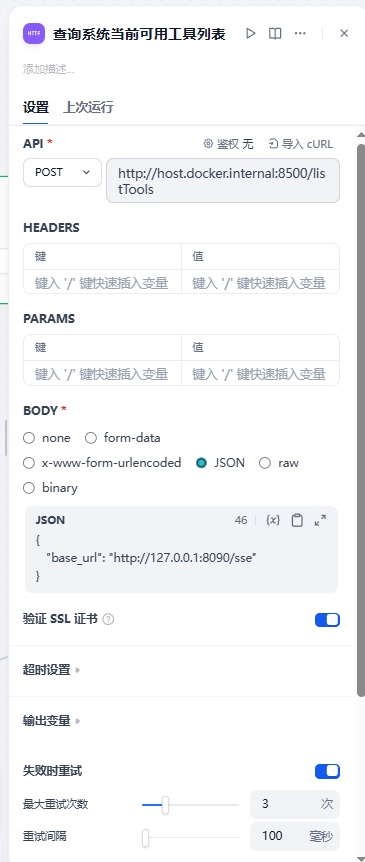
接着它的返回值把这个返回值类似如下报文:
{
"data": {
"tools": [
{
"description": "使用本地paddleocr-vl提取用户输入中的文件url进行批量或者单个扫描\n\nArgs:\n files: 文件列表,每个文件包含file(URL)和fileType(0=PDF, 1=图片)字段。\n 示例: [{\"file\": \"http://localhost/mkcdn/ocrsample/20251122/1.png\", \"fileType\": 1}]\n",
"inputSchema": {
"$defs": {
"FileData": {
"description": "单个文件的数据结构",
"properties": {
"file": {
"description": "文件URL地址",
"title": "File",
"type": "string"
},
"fileType": {
"description": "文件类型: 0=PDF, 1=图片",
"title": "Filetype",
"type": "integer"
}
},
"required": [
"file",
"fileType"
],
"title": "FileData",
"type": "object"
}
},
"properties": {
"files": {
"items": {
"$ref": "#/$defs/FileData"
},
"title": "Files",
"type": "array"
}
},
"required": [
"files"
],
"title": "ocr_filesArguments",
"type": "object"
},
"name": "ocr_files"
}
]
},
"status": "success"
}甩给到它后面的一个LLM节点,让AI根据用户当前的提问来判断系统提供的工具是不是可以用于辅助用户当前的提问?同时也返回true/false。
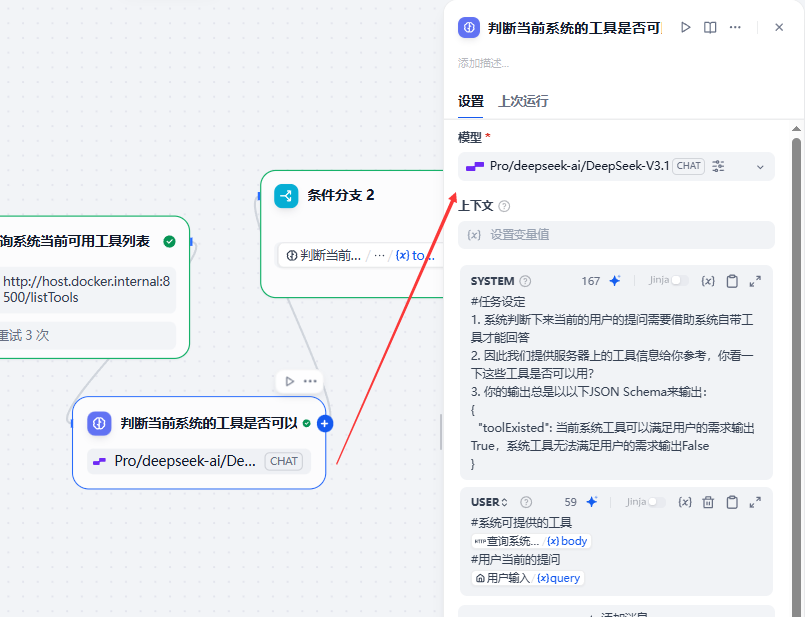
判断当前系统的内置工具是否可以满足用户的请求-系统猫娘
#任务设定
1. 系统判断下来当前的用户的提问需要借助系统自带工具才能回答
2. 因此我们提供服务器上的工具信息给你参考,你看一下这些工具是否可以用?
3. 你的输出总是以以下JSON Schema来输出:
{
"toolExisted": 当前系统工具可以满足用户的需求输出True,系统工具无法满足用户的需求输出False
}判断当前系统的工具是否可以满足用户的请求-用户猫娘
#系统可提供的工具
{{#1763894641406.body#}}
#用户当前的提问
{{#sys.query#}}在这个判断后加一个条件分支,此时就可以做到:
- 如果系统提供的工具集足以满足用户当前的提问,那么调用工具。
- 如果系统提供的工具集无法满足用户当前的提问,那么就拟一条话述和用户say sorry。
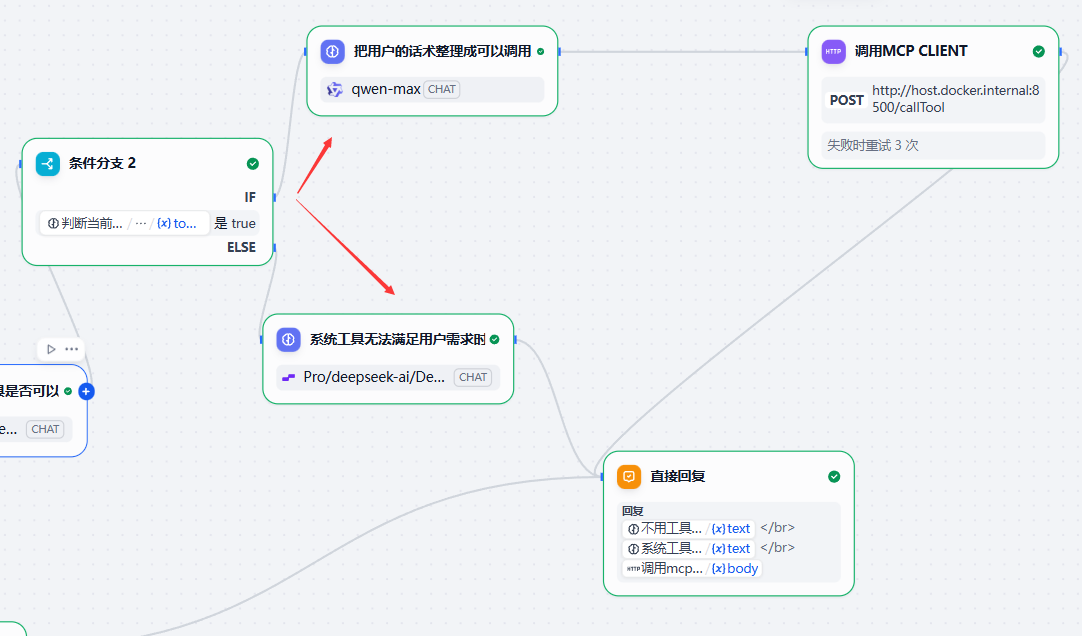
系统提供的工具无法满足用户当前的回答的设计
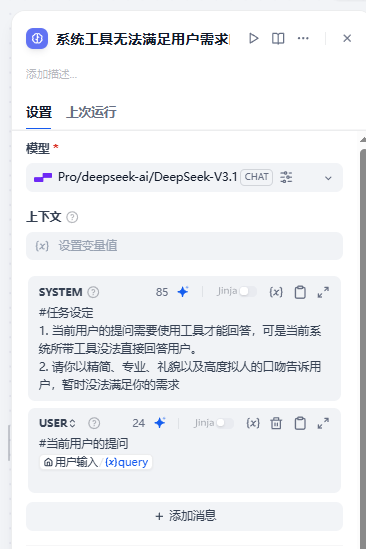
#任务设定
1. 当前用户的提问需要使用工具才能回答,可是当前系统所带工具没法直接回答用户。
2. 请你以精简、专业、礼貌以及高度拟人的口吻告诉用户,暂时没法满足你的需求系统提供的工具可以满足用户当前的回答的设计
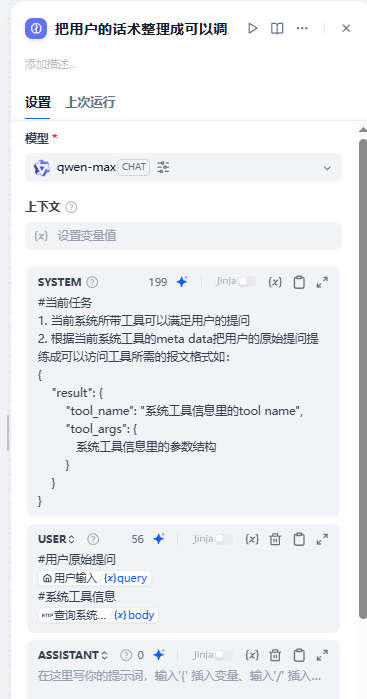
#当前任务
1. 当前系统所带工具可以满足用户的提问
2. 根据当前系统工具的meta data把用户的原始提问提练成可以访问工具所需的报文格式如:
{
"result": {
"tool_name": "系统工具信息里的tool name",
"tool_args": {
系统工具信息里的参数结构
}
}
}#用户原始提问
{{#sys.query#}}
#系统工具信息
{{#1763894641406.body#}}然后我们可以看到,这个输出它就是一个标准的用于call_tool(tool_name, tool_args)的格式了。
接着我们call mcp。
call mcp节点
它是一个http client节点
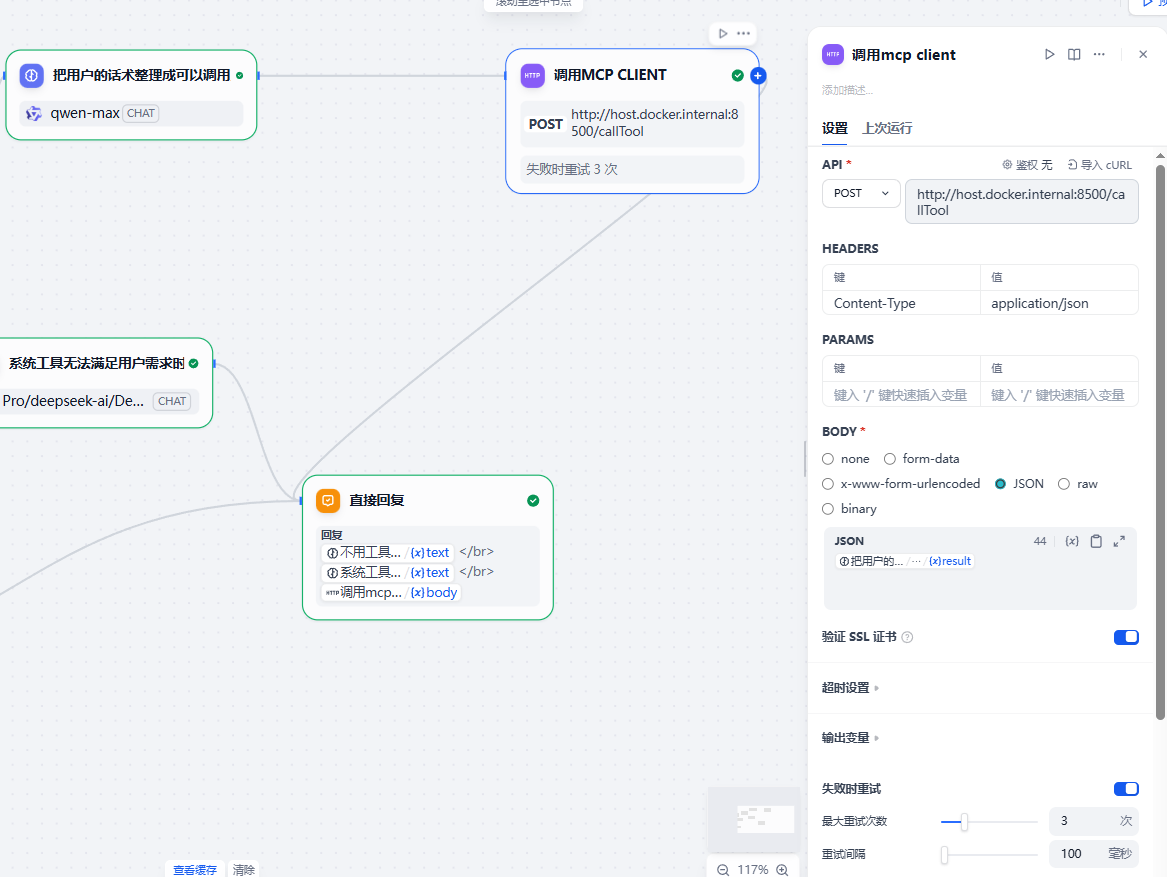
然后把返回接入到:直接回复节点中去。
运行效果
用户提问:
http://localhost/mkcdn/ocrsample/下test-1.png以及test-1.pdf这2个文件需要做一下ocr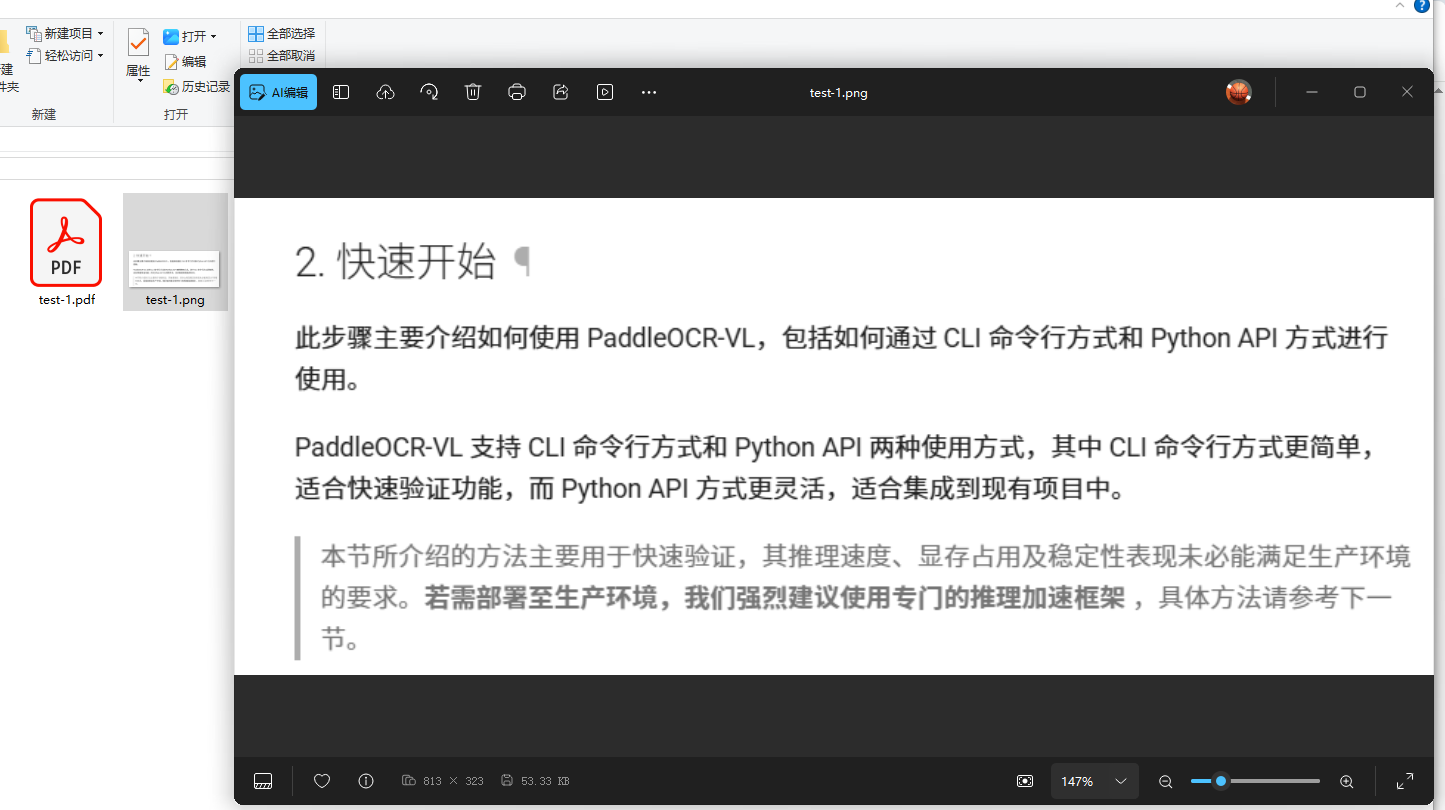
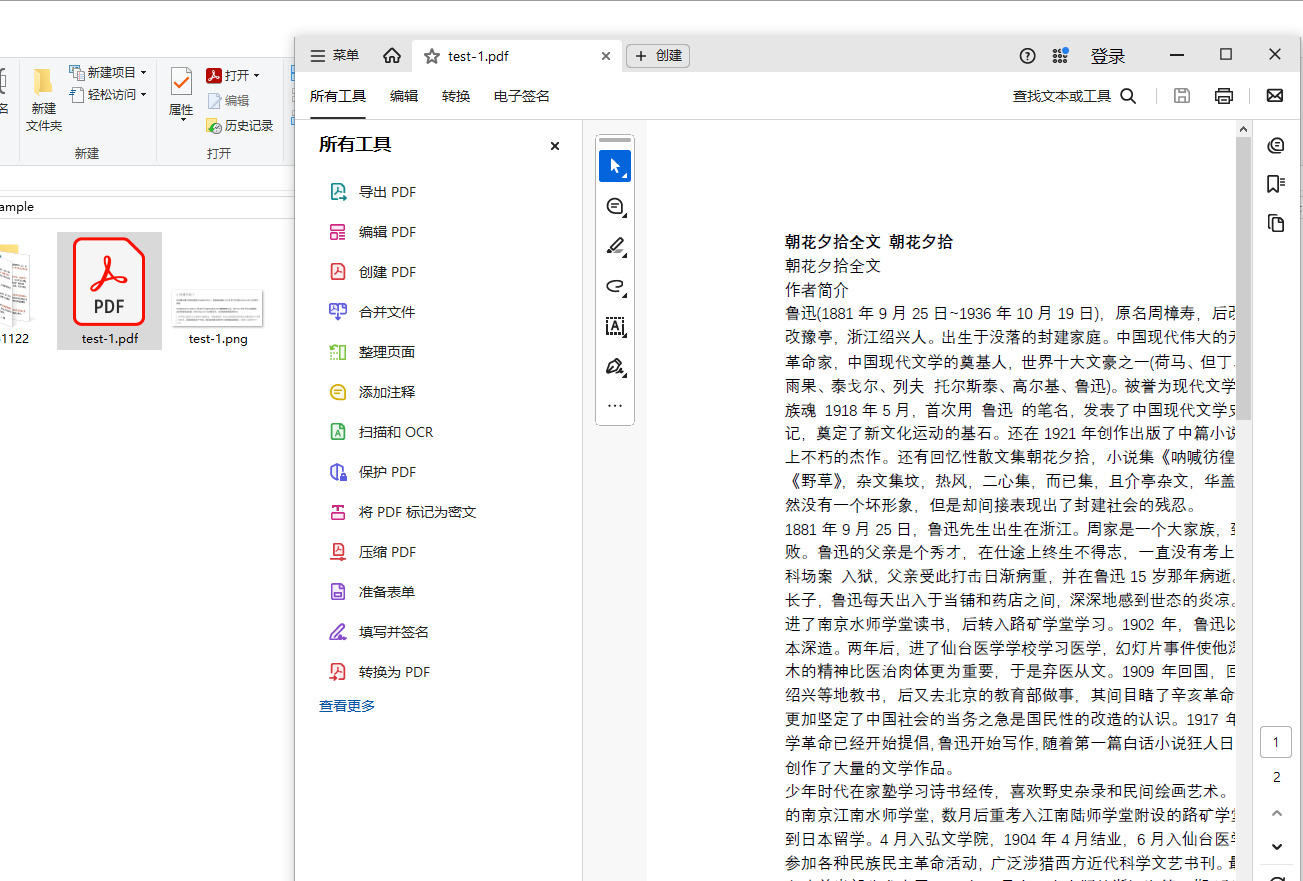
2.1秒内,AI即把test-1.pdf(朝花夕拾)以及test-1.png(paddleocr-vl简介)这两个文件全部解析完成并合并输出如下图所示。
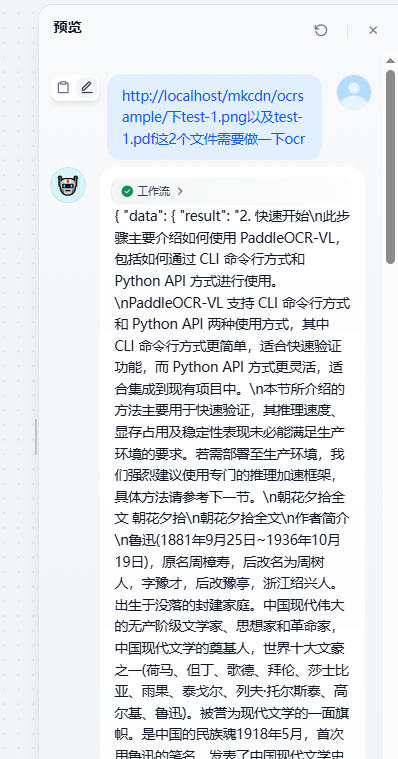
完美!!!
结语
当我们在 2025 年谈论 AI Agent,真正重要的不是它能回答多少问题,而是它能否像人类一样,在面对一张图片、一份文档、一个未知任务时,主动寻找工具、调用能力、解决问题。将 PaddleOCR-VL 封装为 MCP 服务并接入 Dify,看似只是一个技术集成步骤,实则代表了一种思维转变:从“功能堆砌”走向“能力编织”。
我曾在一个深夜调试这段集成代码,当 Dify 的聊天窗口里第一次自动弹出“正在为您扫描保单内容……”,几秒后准确返回结构化信息时,那种震撼至今难忘。这不是魔法,这是工程。是我们用协议、接口、服务一点点搭建起的数字世界的“感官系统”。
未来的 Agent,将拥有无数这样的“感官”:OCR 是眼睛,TTS 是嘴巴,RPA 是双手,知识图谱是记忆。而 MCP,就是连接这一切的神经。愿我们不仅是使用者,更是建设者。
课后作业
由于这是一篇通篇用AI原生的Agentic Flow,所以它的输入、工具选择全部是由AI自行决定的。因此我们可以在此流程中再植入一个DeepSeek OCR工具,只需要改动mcp server端代码,其它什么都不需要动,这正是体现了mcp 的热插拨特点的一种设计。
当植入了这个DeepSeek OCR工具后,我们就可以这样提问了:
http://localhost/mkcdn/ocrsample/下test-1.png以及test-1.pdf这2个文件,
用deepseek ocr做一下解析。这个作业就留给各位自行去动手练习了。
结束今天的分享!希望大家喜欢!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献126条内容
已为社区贡献126条内容

所有评论(0)