大模型基础 | 大模型集成方法
大模型集成方法
集成学习是机器学习领域的重要研究方向之一,它是一种通过构建并结合多个学习器来解决单一问题的机器学习范式。这种方法的核心思想是通过组合多个模型的预测结果,以提升整体预测性能。集成学习通常能够显著提升模型的准确性和健壮性。通过组合多个模型,集成学习能够减少过拟合,降低模型的方差,从而在多种数据集上实现更好的泛化能力。
集成方法分类
输出集成
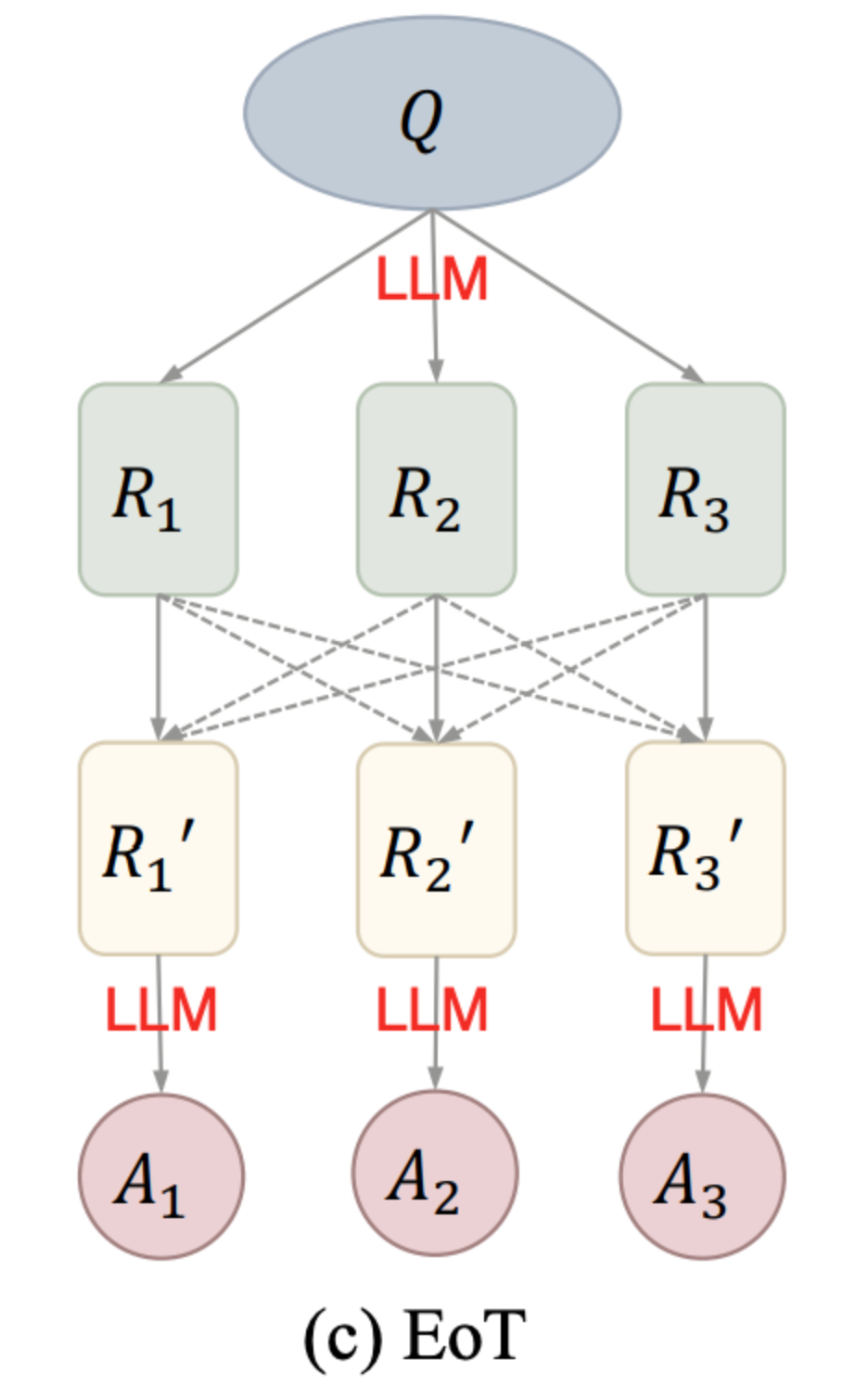
由《Exchange-of-Thought: Enhancing Large Language Model Capabilities through Cross-Model Communication》论文中提出的概念,如下图所示,一个模型可以借鉴其他模型的推理和思考过程,从而更好地解决问题。这可以提升模型的性能和准确性。
概率集成
概率集成与传统的机器学习融合相似,其中一种常见的策略是对模型预测的logits结果进行平均处理。大模型的概率集成可以在Transformer的词表输出概率层次进行融合。然而,需要注意的是,这样的操作要求其融合的多个原始模型的词表保持一致。
可以形式化地表示为:
给定 MMM 个模型,其logits输出为 z1,z2,…,zM\mathbf{z}_1, \mathbf{z}_2, \dots, \mathbf{z}_Mz1,z2,…,zM,且所有zi∈RV\mathbf{z}_i \in \mathbb{R}^Vzi∈RV(词表一致),则Logits平均集成可表示为:
Pensemble=Softmax(1M∑i=1Mzi) P_{\text{ensemble}} = \text{Softmax}\left( \frac{1}{M} \sum_{i=1}^{M} \mathbf{z}_i \right) Pensemble=Softmax(M1i=1∑Mzi)
混合专家模型(MoE)
作为集成学习领域的一种先进方法,MoE凭借其特有的稀疏化处理和分布式路由机制,在大模型时代资源消耗巨大的背景下熠熠生辉。
专家模型(Expert Models)
这种方法与集成学习有相似之处,其核心是为由众多独立专家网络构成的集合体创立一个协调融合机制。在这样的架构下,每个独立的网络(通常被称为"专家")负责处理数据集中的特定子集,并且专注于特定的输入数据区域。这种子集可能偏向于某种话题、某种领域、某种问题分类等,并不是一个显式的概念。
门控网络(Gating Network / Router Network)
面对不同的输入数据,一个关键的问题是系统如何决定由哪个专家来处理。门控网络(Gating network)也叫做路由(Router)就是为解决这一问题而设计的,它通过动态分配权重来确定各个专家的工作职责。在整个训练过程中,这些专家网络和门控网络会同步进行训练,并且这个过程是自动进行的,并不需要显式地手动操控。
MoE嵌入到Transformer中,用稀疏激活的"专家"子网络替代原有Transformer中前馈网络(FFN)层,从而在几乎不增加计算量的前提下,大幅扩展模型容量。用"稀疏激活的多个FFN专家"替换"单个Dense FFN",让模型"看起来很大,实际算得很少"。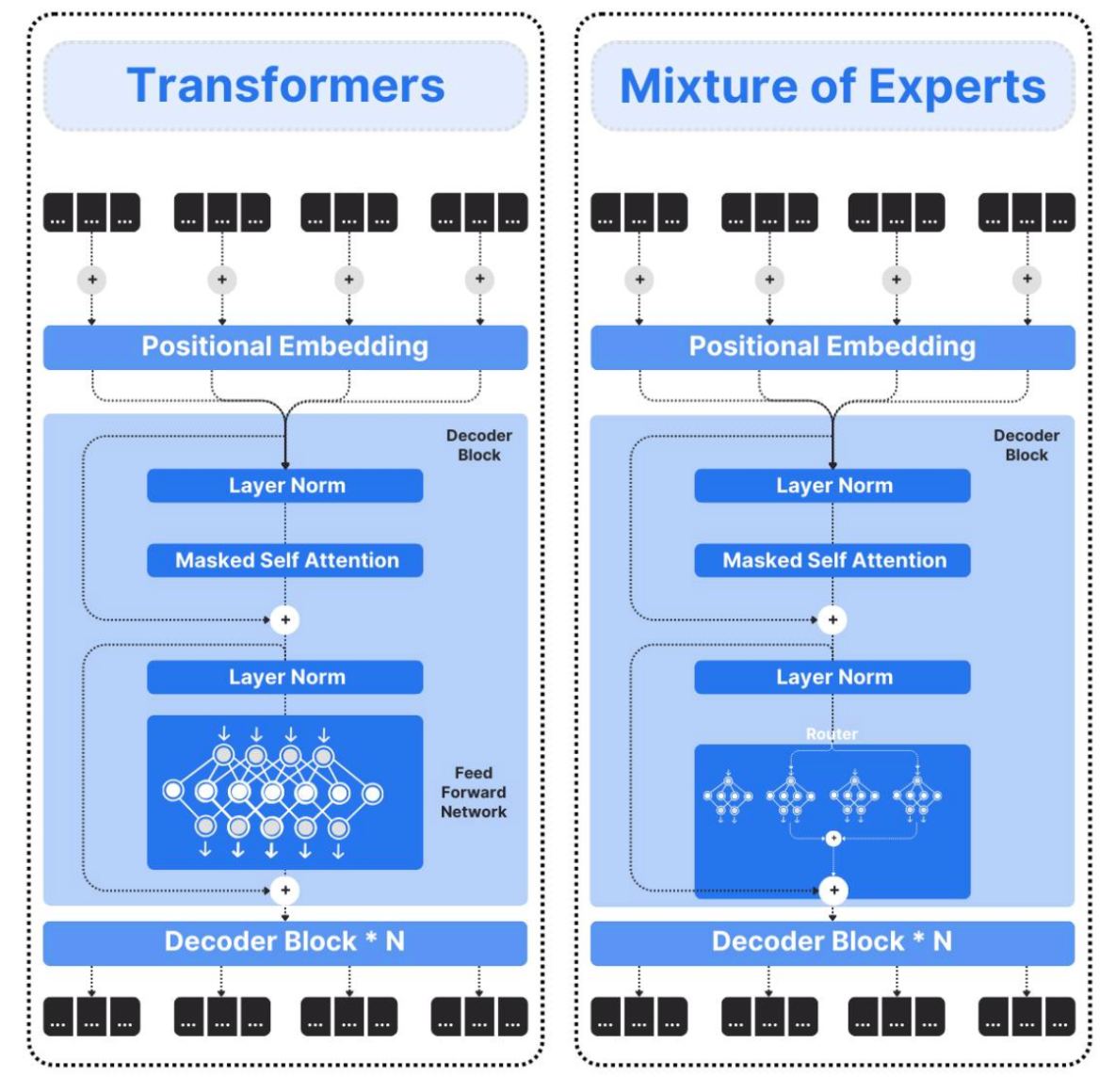
DeepSeekMoE创新
2025年初,DeepSeek火出了圈。凭借DeepSeek-V3与DeepSeek-R1的创新技术和卓越表现,DeepSeek迅速成为了行业内外的焦点。并且发表了论文《DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models》,公布了其DeepSeekMoE的架构,如下图所示: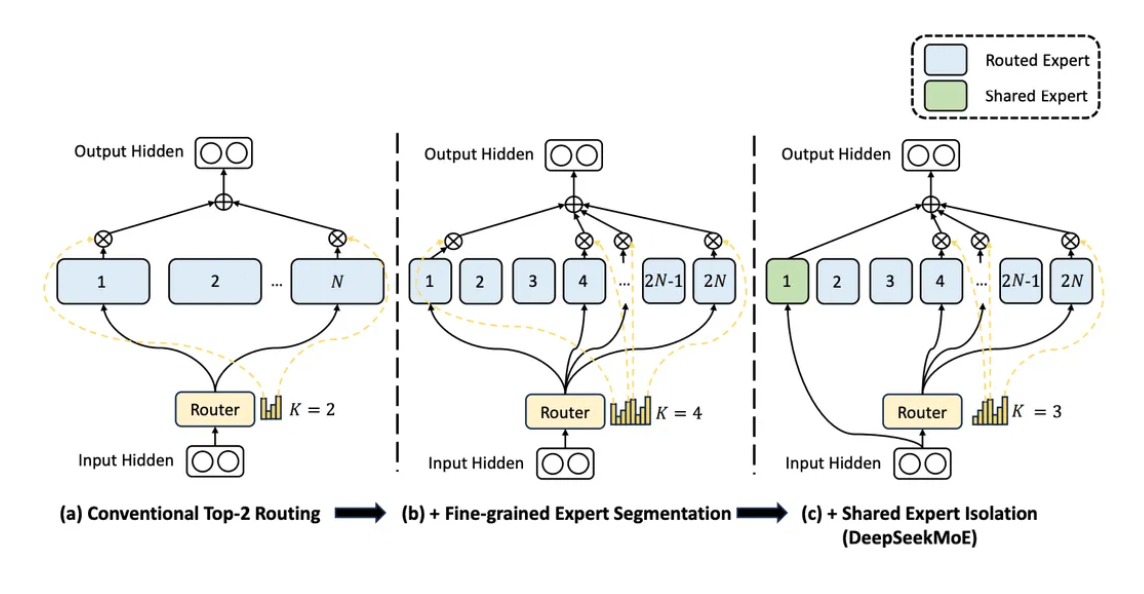
上图展示了DeepSeek在传统混合专家模型(MoE)架构(a)基础上进行的两项关键改进(b)和(c):
(a) 传统MoE架构:
该模块包含N个前馈网络(FFN)专家,每个专家擅长处理不同类型的数据特征。通过路由机制,系统根据输入特性动态选择K=2个最相关的专家进行处理,而非激活全部专家。模型总参数量由所有专家参数累加而成,而实际计算时仅使用被激活专家的参数。
(b) 专家细粒度化:
DeepSeek将原有N个专家进一步细分为m×N个微型专家,每个专家的隐藏层维度相应缩减至原来的1/m。在保持总参数量和激活参数量不变的前提下,通过激活m×K个微型专家,使模型能够以更精细的方式组合专家能力,增强了对复杂特征的适配灵活性。图中m设置为2,K为2。
© 共享专家:
该设计将专家划分为共享专家和路由专家两类。共享专家会处理所有输入数据,无需经过路由筛选,负责提取数据的通用特征;而路由专家则通过路由模块计算输入与各专家的匹配度,仅对最相关的数据进行处理。最终将两类专家的输出结果融合,形成模块的最终输出。这种架构使模型既能学习数据的共性特征,又能捕捉特异性模式,从而显著提升模型的泛化能力和场景适应性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)