【Python大数据+AI毕设实战】拉勾网计算机岗位招聘数据分析系统、Hadoop、计算机毕业设计、包括数据爬取、数据分析、数据可视化、机器学习、实战教学
【Python大数据+AI毕设实战】拉勾网计算机岗位招聘数据分析系统、Hadoop、计算机毕业设计、包括数据爬取、数据分析、数据可视化、机器学习、实战教学
🍊作者:计算机毕设匠心工作室
🍊简介:毕业后就一直专业从事计算机软件程序开发,至今也有8年工作经验。擅长Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等。
擅长:按照需求定制化开发项目、 源码、对代码进行完整讲解、文档撰写、ppt制作。
🍊心愿:点赞 👍 收藏 ⭐评论 📝
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
Java实战项目
Python实战项目
微信小程序|安卓实战项目
大数据实战项目
PHP|C#.NET|Golang实战项目
🍅 ↓↓文末获取源码联系↓↓🍅
这里写目录标题
基于大数据的拉勾网计算机岗位招聘数据分析系统-功能介绍
本系统是一个基于大数据技术的拉勾网计算机岗位招聘数据分析系统,旨在为即将步入职场的计算机专业学生提供一个数据驱动的决策参考工具。系统核心采用Python作为主要开发语言,并深度融合了Hadoop与Spark两大主流大数据框架,以应对海量招聘数据处理与分析的挑战。在数据处理层面,系统利用Spark的分布式计算能力,对从拉勾网采集的原始招聘数据进行高效的清洗、转换与预处理,包括但不限于重复数据剔除、非结构化文本字段(如薪资范围、职位名称、工作经验)的标准化与结构化,以及数据质量的校验。后端服务则基于强大的Django框架构建,负责响应前端请求、执行复杂的数据分析任务,并将Spark处理后的结果通过API接口进行暴露。前端界面采用现代化的Vue.js框架,并结合ElementUI组件库与ECharts可视化图表库,为用户呈现出直观、交互性强的数据分析结果。用户可以通过该系统清晰地洞察全国各城市的岗位需求分布与薪资水平、不同技术方向(如Java、Python、大数据)的热门程度与“钱景”、工作经验与学历对薪资的实际影响、热门公司招聘趋势以及企业提供的核心福利等十五个维度的深度分析,最终将复杂、零散的招聘信息转化为一目了然的商业洞察,从而为个人职业规划与技术学习路径选择提供坚实的数据支持。
基于大数据的拉勾网计算机岗位招聘数据分析系统-选题背景意义
选题背景
随着信息技术的飞速发展和数字化转型的深入,计算机行业已成为推动社会进步的核心引擎之一,随之而来的是日益激烈的人才竞争。对于数以百万计的计算机专业学生,尤其是即将毕业的大学生而言,如何从海量的招聘信息中精准定位适合自己的职业方向,成为他们面临的一大难题。传统的求职方式往往依赖于个人经验、学长学姐的零散建议或是浏览杂乱的招聘网站,这种方式不仅效率低下,而且容易形成信息茧房,导致对市场整体趋势的误判。拉勾网作为专注于互联网领域的招聘平台,沉淀了大量的计算机相关岗位数据,这些数据真实地反映了市场的需求脉搏。然而,这些原始数据是粗糙且非结构化的,普通用户难以直接从中挖掘出有价值的规律。因此,开发一个能够系统性地收集、处理并深度分析这些招聘数据的工具,就显得尤为迫切和必要。本项目正是在这样的背景下提出的,它试图利用大数据技术,将原始的招聘公告转化为结构化的知识,为迷茫的毕业生拨开云雾,看清市场的真实面貌。
选题意义
这个系统的意义,首先在于它能为计算机专业的应届毕业生提供非常实际的帮助。通过系统对全国岗位数量、城市薪资、技术栈热度等多维度数据的可视化呈现,学生们可以不再盲目地投递简历,而是能够根据数据清晰地了解到,比如“Python开发工程师”在上海和深圳的平均薪资差异有多大,或者“大数据分析师”岗位通常要求几年工作经验。这种数据驱动的决策方式,能让他们在职业规划的十字路口上,做出更明智、更符合市场趋势的选择,从而有效提升求职的成功率和满意度。从另一个角度看,本课题作为一项毕业设计,其价值在于完整地实践了一套大数据项目的开发全流程。它不仅仅是理论的应用,更是对从数据获取、清洗、存储,到利用Spark进行分布式计算分析,再到使用Django和Vue进行前后端开发的全栈技术能力的综合检验。通过完成这个项目,学生能够深刻理解大数据技术如何解决实际问题,极大地锻炼了工程实践能力和问题解决能力,为未来的职业生涯打下坚实的技术基础。当然,作为毕业设计,它的分析结果和模型可能还有优化的空间,但其核心的分析思路和实现框架,已经具备了相当的实用参考价值。
基于大数据的拉勾网计算机岗位招聘数据分析系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
基于大数据的拉勾网计算机岗位招聘数据分析系统-图片展示
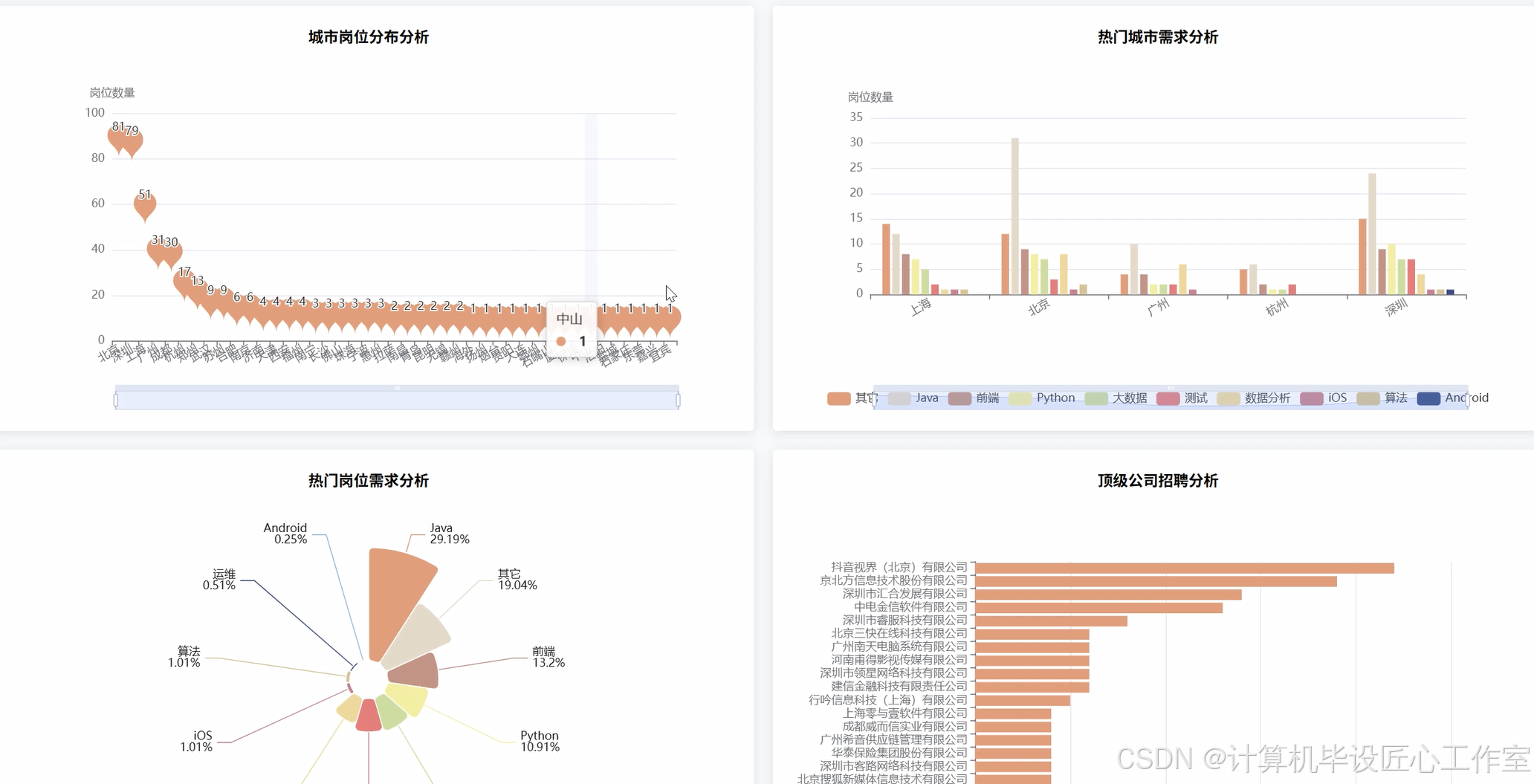
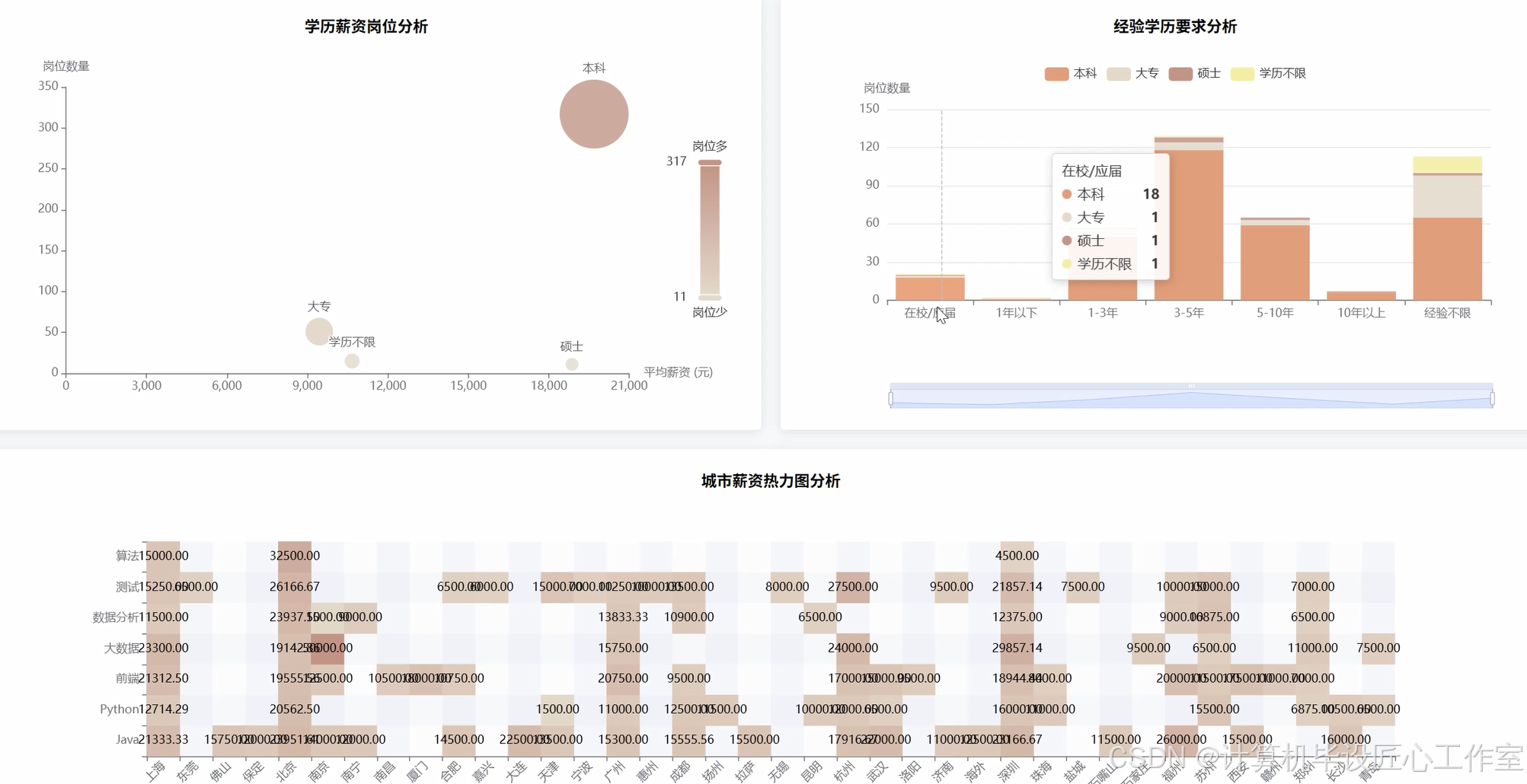
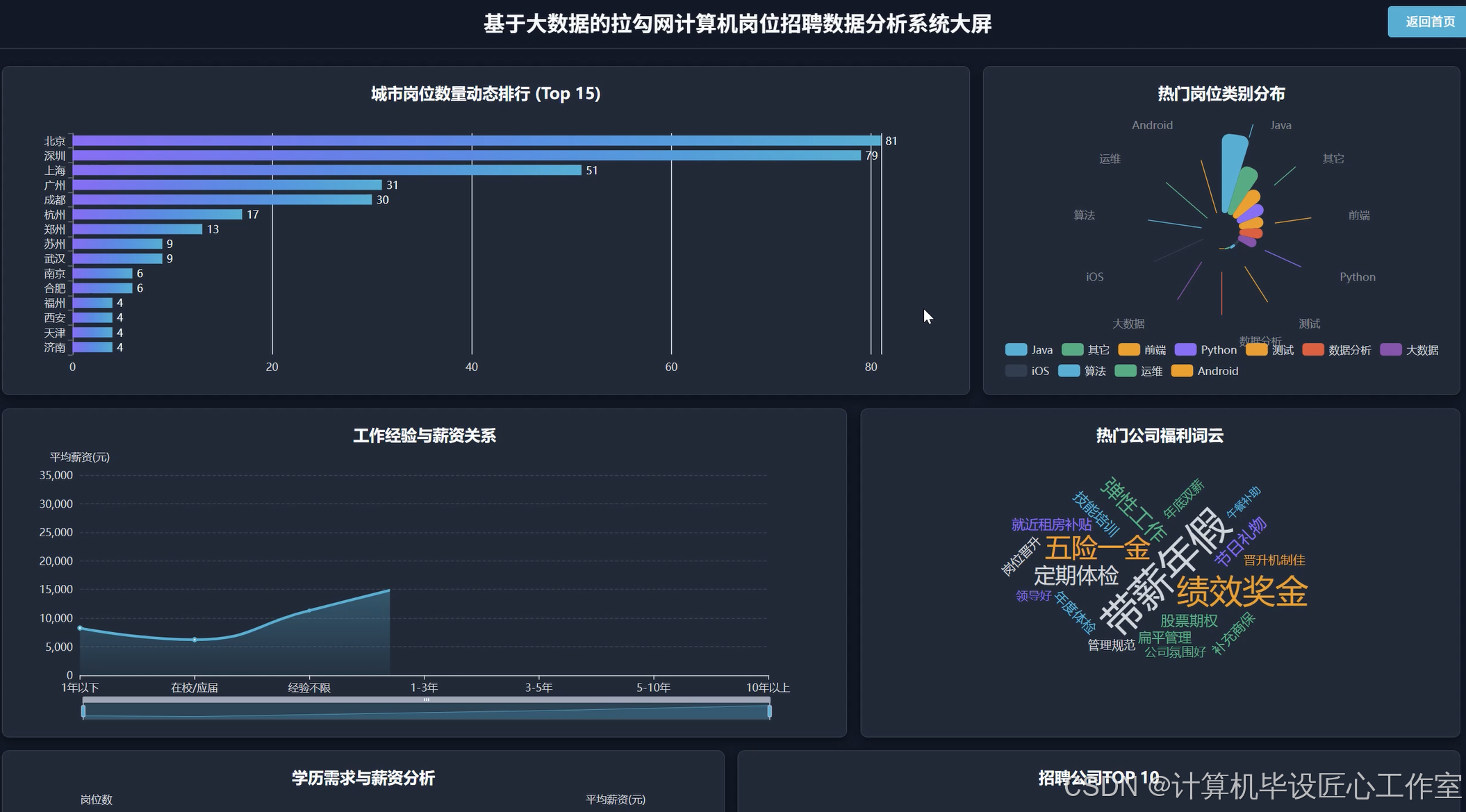
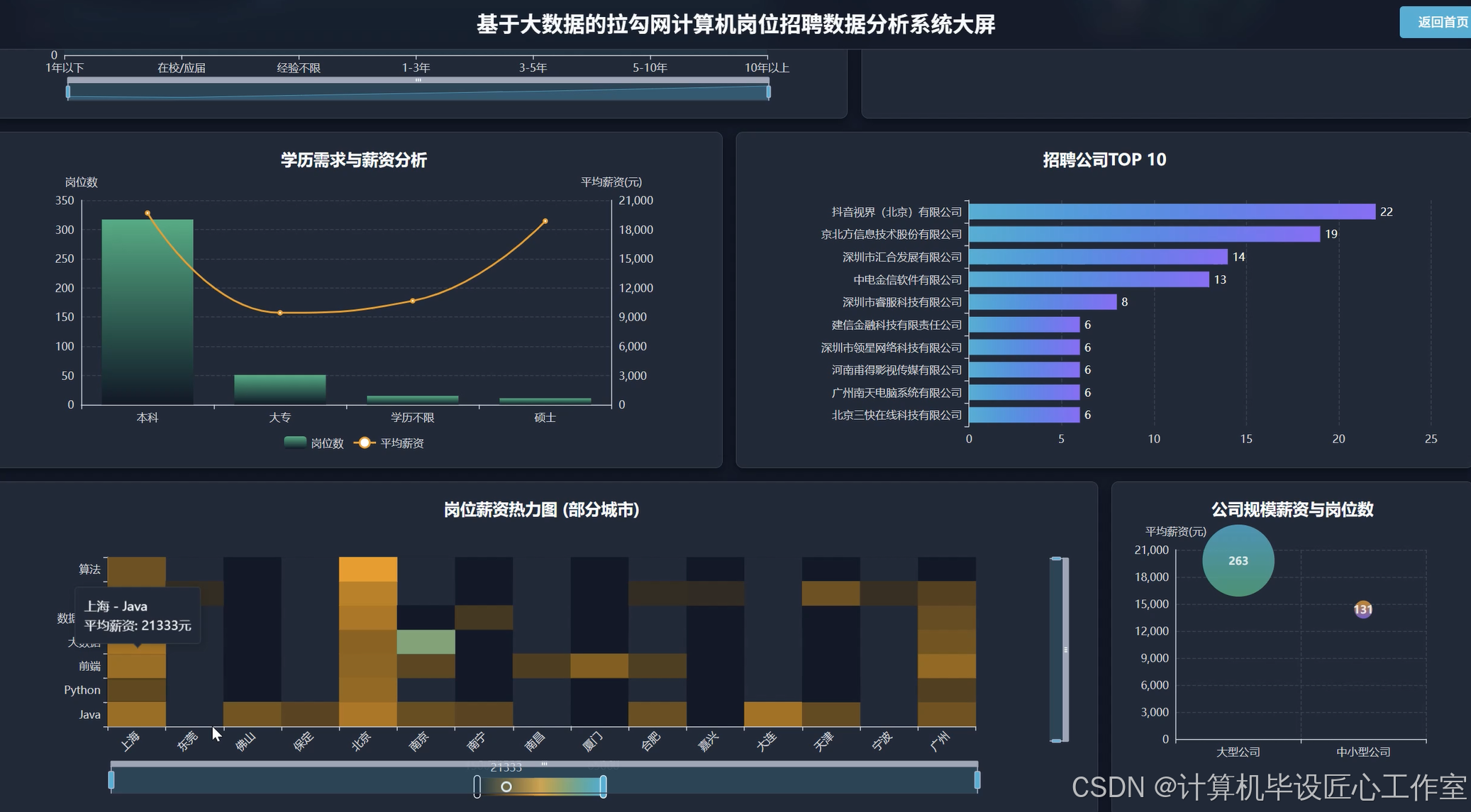
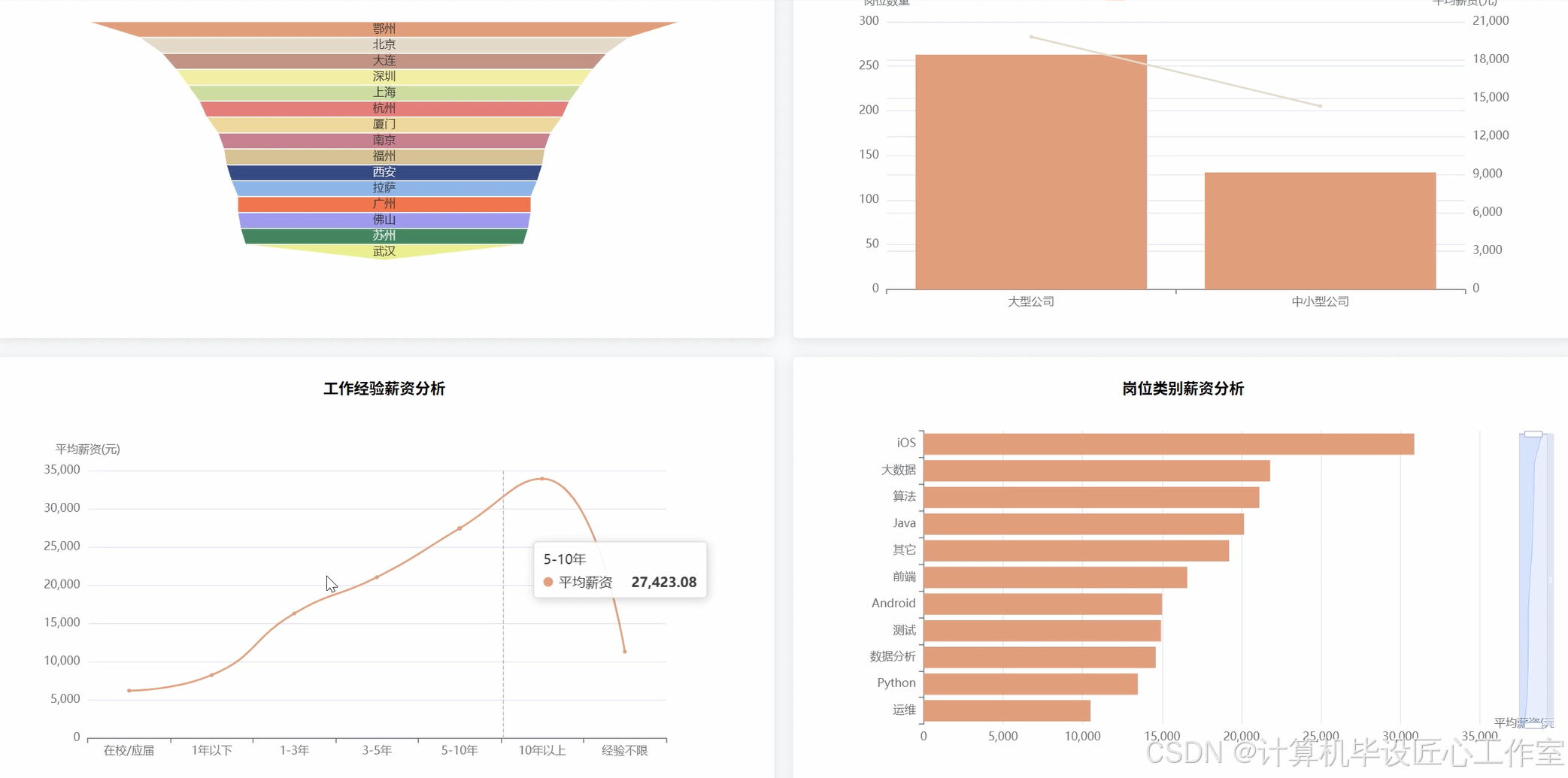
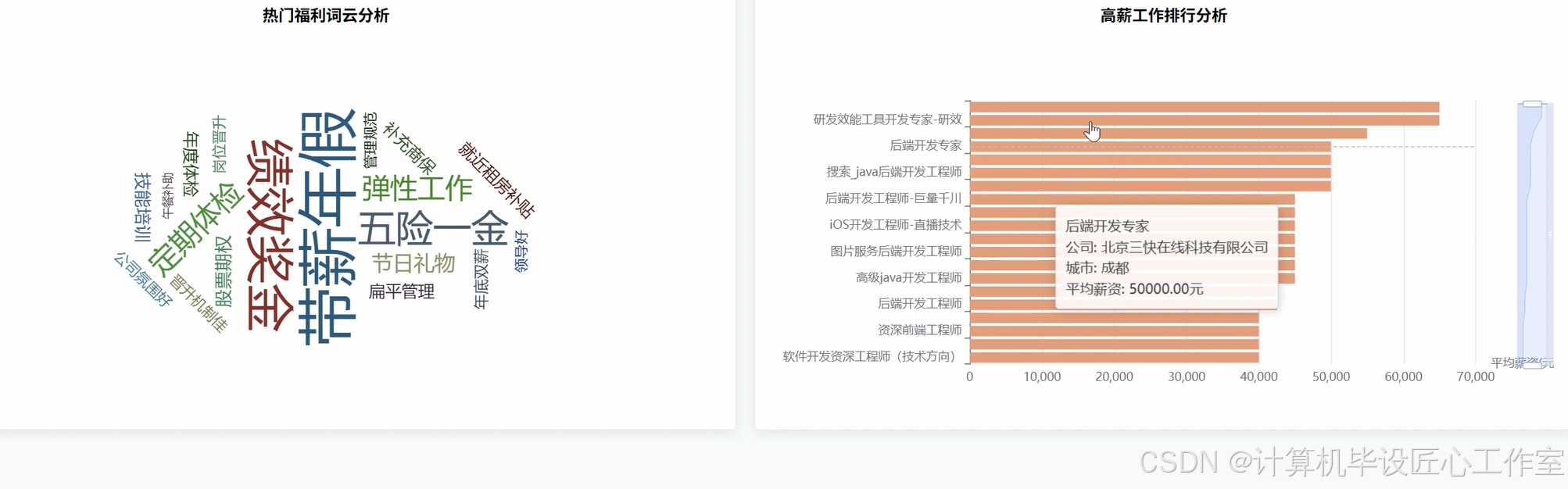
基于大数据的拉勾网计算机岗位招聘数据分析系统-代码展示
# 假设 spark 会话已通过 SparkSession.builder.appName("LagouAnalysis").getOrCreate() 创建
# from pyspark.sql import functions as F
# 核心功能1: 不同城市计算机岗位平均薪资对比分析
def analyze_avg_salary_by_city(df):
# 使用正则表达式提取薪资范围中的最低和最高值,例如 "15k-25k" -> "15", "25"
df_salary = df.withColumn("min_salary", F.regexp_extract(F.col("money"), r"(\d+)-\d+k", 1).cast("int"))
df_salary = df_salary.withColumn("max_salary", F.regexp_extract(F.col("money"), r"\d+-(\d+)k", 1).cast("int"))
# 过滤掉薪资格式不正确或为空的行
df_salary = df_salary.filter((F.col("min_salary") > 0) & (F.col("max_salary") > 0))
# 计算平均薪资
df_salary = df_salary.withColumn("avg_salary", (F.col("min_salary") + F.col("max_salary")) / 2)
# 按城市分组,计算每个城市的平均薪资
city_salary_avg = df_salary.groupBy("area").agg(F.round(F.avg("avg_salary"), 2).alias("城市平均薪资"))
# 按平均薪资降序排列
city_salary_avg_sorted = city_salary_avg.orderBy(F.col("城市平均薪资").desc())
return city_salary_avg_sorted
# 核心功能2: 主要计算机岗位分类需求量分析
def analyze_job_category_demand(df):
# 定义职位关键词映射
keywords = ["Java", "Python", "前端", "大数据", "AI", "测试", "运维", "Go", "C++"]
# 使用when和otherwise函数根据job_name中的关键词创建新的分类列
df_job = df.withColumn("job_category", F.when(F.col("job_name").rlike("Java"), "Java")
.when(F.col("job_name").rlike("Python"), "Python")
.when(F.col("job_name").rlike("前端|web"), "前端")
.when(F.col("job_name").rlike("大数据|Hadoop|Spark|Flink"), "大数据")
.when(F.col("job_name").rlike("AI|人工智能|机器学习|深度学习"), "AI")
.when(F.col("job_name").rlike("测试|QA"), "测试")
.when(F.col("job_name").rlike("运维|DevOps|SRE"), "运维")
.otherwise("其他"))
# 过滤掉无法分类的"其他"职位
df_job_filtered = df_job.filter(F.col("job_category") != "其他")
# 按职位分类分组,统计每个分类的岗位数量
job_demand_count = df_job_filtered.groupBy("job_category").agg(F.count("job_name").alias("岗位需求量"))
# 按需求量降序排列
job_demand_sorted = job_demand_count.orderBy(F.col("岗位需求量").desc())
return job_demand_sorted
# 核心功能3: 工作经验与薪资关系分析
def analyze_salary_by_experience(df):
# 首先,复用薪资处理逻辑计算出平均薪资
df_salary = df.withColumn("min_salary", F.regexp_extract(F.col("money"), r"(\d+)-\d+k", 1).cast("int"))
df_salary = df_salary.withColumn("max_salary", F.regexp_extract(F.col("money"), r"\d+-(\d+)k", 1).cast("int"))
df_salary = df_salary.filter((F.col("min_salary") > 0) & (F.col("max_salary") > 0))
df_salary = df_salary.withColumn("avg_salary", (F.col("min_salary") + F.col("max_salary")) / 2)
# 标准化工作经验要求,创建新的分类列
df_exp = df_salary.withColumn("exp_category", F.when(F.col("job_exp").rlike("在校|应届"), "应届生")
.when(F.col("job_exp").rlike("1-3年"), "1-3年")
.when(F.col("job_exp").rlike("3-5年"), "3-5年")
.when(F.col("job_exp").rlike("5-10年"), "5-10年")
.when(F.col("job_exp").rlike("10年以上"), "10年以上")
.when(F.col("job_exp").rlike("不限"), "经验不限")
.otherwise(None))
# 过滤掉工作经验为空的行
df_exp_filtered = df_exp.filter(F.col("exp_category").isNotNull())
# 按工作经验分类分组,计算每个经验段的平均薪资
exp_salary_avg = df_exp_filtered.groupBy("exp_category").agg(F.round(F.avg("avg_salary"), 2).alias("经验段平均薪资"))
# 自定义排序,使经验等级按逻辑顺序排列
exp_salary_avg_sorted = exp_salary_avg.withColumn("sort_order", F.when(F.col("exp_category") == "应届生", 1)
.when(F.col("exp_category") == "1-3年", 2)
.when(F.col("exp_category") == "3-5年", 3)
.when(F.col("exp_category") == "5-10年", 4)
.when(F.col("exp_category") == "10年以上", 5)
.otherwise(6)).orderBy("sort_order")
return exp_salary_avg_sorted.drop("sort_order")
基于大数据的拉勾网计算机岗位招聘数据分析系统-结语
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
Java实战项目
Python实战项目
微信小程序|安卓实战项目
大数据实战项目
PHP|C#.NET|Golang实战项目
🍅 主页获取源码联系🍅

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)