差分进化(DE)算法求解置换流水车间调度问题PFSP
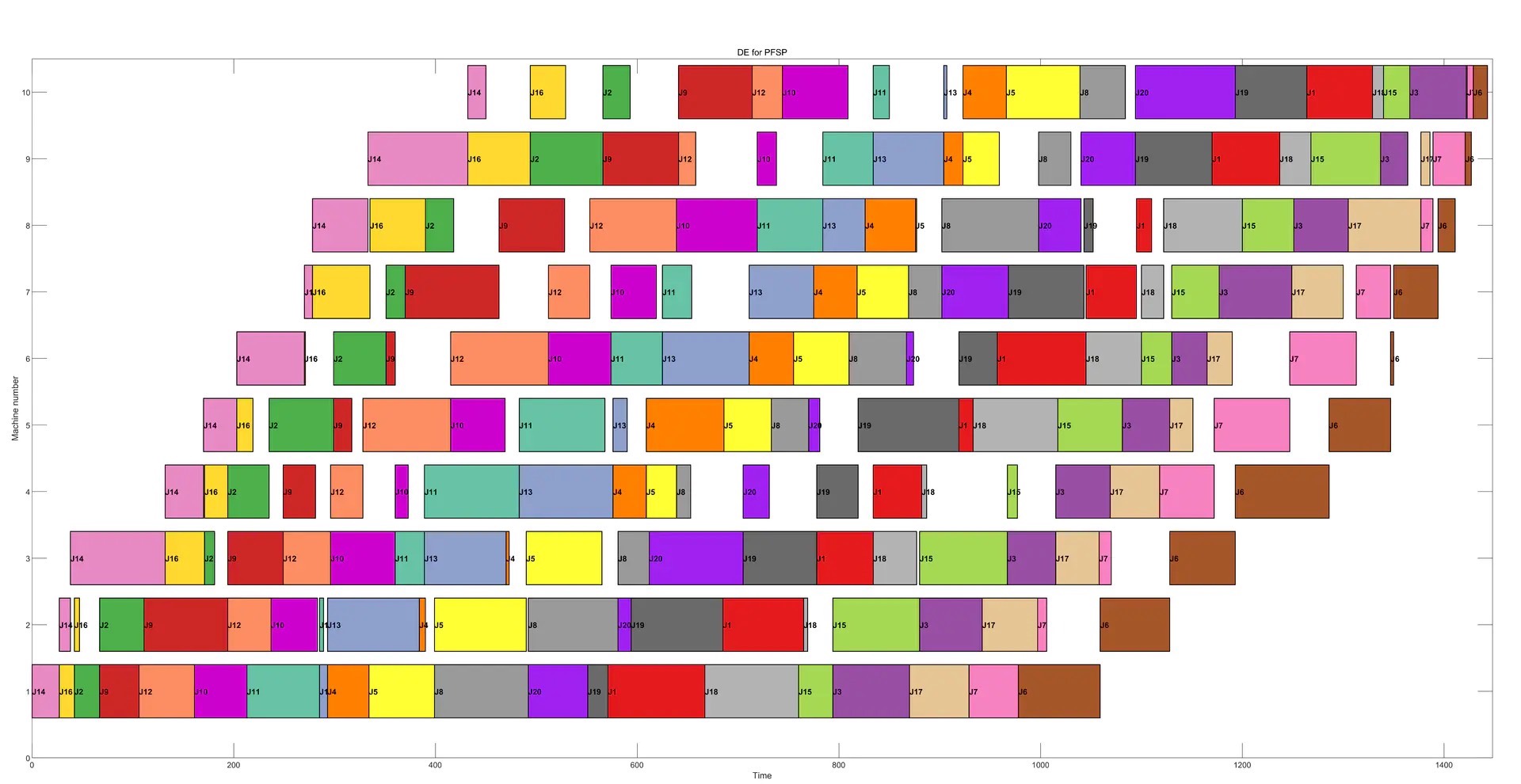
差分进化(DE)算法求解置换流水车间调度问题PFSP 其中:main.m是主函数运行即可;DE.m是算法的代码;color_selection用于获得甘特图的颜色配置;gantt_chart.m绘制甘特图;objective.m是目标函数,即计算Makespan;sorting.m根据调度方案计算每台机器任意时刻的加工信息(开始时间、结束时间、工件号、机器号), 用于绘制甘特图;调度测试集包括Car和Rec 输出结果包括:Makespan、工件排序、计算时间、最优适宜度收敛曲线、平均适宜度收敛曲线、甘特图 利用DE得到的20工件×10机器的调度结果甘特图演示如下(随机运行一次的结果):
最近在研究调度问题,发现差分进化(DE)算法在求解置换流水车间调度问题(PFSP)上有不错的表现,今天就来和大家分享一下相关的实现过程与结果。
一、整体框架
整个项目包含多个关键的.m文件,每个文件各司其职。
main.m
这是主函数,就像整个程序的指挥官,运行它就能启动整个求解流程。它会调用其他函数,协调各个部分的工作。虽然这里没有具体代码展示,但可以想象它内部大概是这样的逻辑:
% 初始化参数等操作
params = initialize_params();
% 调用DE算法
result = DE(params);
% 处理结果并输出
process_and_output(result);这里的initializeparams函数负责设置算法运行所需要的初始参数,比如种群大小、变异因子、交叉概率等等。DE函数就是调用核心的差分进化算法进行求解,而processand_output函数则负责处理得到的结果,并按照我们期望的格式输出,像Makespan、工件排序等。
DE.m
这是核心的算法代码文件,实现了差分进化算法的具体流程。简单来说,差分进化算法是一种基于群体的启发式搜索算法,通过种群个体之间的差分向量来产生新的个体,不断迭代寻找最优解。下面是一个简化版的DE算法核心代码片段及分析:
function [best_fitness, best_solution] = DE(pop_size, dim, lower_bound, upper_bound, max_generations, F, CR)
% 初始化种群
population = repmat(lower_bound, pop_size, 1) + repmat(upper_bound - lower_bound, pop_size, 1).* rand(pop_size, dim);
fitness = zeros(pop_size, 1);
for i = 1:pop_size
fitness(i) = objective(population(i, :));
end
[best_fitness, best_index] = min(fitness);
best_solution = population(best_index, :);
for gen = 1:max_generations
for i = 1:pop_size
% 选择三个不同的个体
r1 = randi([1, pop_size], 1);
while r1 == i
r1 = randi([1, pop_size], 1);
end
r2 = randi([1, pop_size], 1);
while r2 == i || r2 == r1
r2 = randi([1, pop_size], 1);
end
r3 = randi([1, pop_size], 1);
while r3 == i || r3 == r1 || r3 == r2
r3 = randi([1, pop_size], 1);
end
% 变异操作
mutant = population(r1, :) + F * (population(r2, :) - population(r3, :));
% 边界处理
mutant = max(mutant, lower_bound);
mutant = min(mutant, upper_bound);
% 交叉操作
trial = zeros(1, dim);
jrand = randi([1, dim], 1);
for j = 1:dim
if rand <= CR || j == jrand
trial(j) = mutant(j);
else
trial(j) = population(i, j);
end
end
% 选择操作
trial_fitness = objective(trial);
if trial_fitness < fitness(i)
fitness(i) = trial_fitness;
population(i, :) = trial;
if trial_fitness < best_fitness
best_fitness = trial_fitness;
best_solution = trial;
end
end
end
end
end代码分析:
- 初始化种群:首先在指定的上下界内随机生成初始种群,并且计算每个个体的适应度,也就是调用
objective函数来计算每个调度方案对应的Makespan。 - 变异操作:从种群中随机选择三个不同的个体,通过它们之间的差分向量生成一个变异个体。变异因子
F控制了差分向量的缩放程度,它决定了搜索的步长大小。 - 交叉操作:变异个体与当前个体通过交叉概率
CR进行交叉,产生一个试验个体。这里通过随机选择一个维度jrand,确保试验个体至少有一个维度来自变异个体。 - 选择操作:比较试验个体和当前个体的适应度,如果试验个体更优,则更新当前个体及其适应度,同时更新全局最优解。
color_selection
这个文件用于获得甘特图的颜色配置。甘特图不同的任务或工件可能需要用不同颜色区分,它可能就是简单地定义了一个颜色数组之类的,比如:
function colors = color_selection(num_colors)
colors = hsv(num_colors);
end这里使用hsv函数生成num_colors种不同的HSV颜色空间下的颜色,适合用来区分甘特图中不同的工件。
gantt_chart.m
负责绘制甘特图。甘特图能直观地展示每个工件在不同机器上的加工时间顺序。绘制甘特图的代码比较复杂,这里只简单示意一下关键部分:
function gantt_chart(machine_info)
num_machines = size(machine_info, 1);
num_jobs = size(machine_info, 2);
figure;
hold on;
for i = 1:num_machines
for j = 1:num_jobs
start_time = machine_info{i, j}(1);
end_time = machine_info{i, j}(2);
job_id = machine_info{i, j}(3);
rectangle('Position', [start_time, i, end_time - start_time, 1], 'FaceColor', color_selection(num_jobs)(job_id, :));
text(start_time + (end_time - start_time) / 2, i, num2str(job_id));
end
end
xlabel('Time');
ylabel('Machine');
hold off;
end这段代码遍历每台机器上每个工件的加工信息(开始时间、结束时间、工件号),使用rectangle函数绘制甘特图中的矩形条表示加工时间段,并且给每个矩形条填充相应工件的颜色,同时在矩形条中间标注工件号。
objective.m
目标函数,即计算Makespan。Makespan是衡量调度方案优劣的一个重要指标,它表示完成所有工件加工所需的总时间。代码大概如下:
function makespan = objective(schedule)
% 根据调度方案计算每台机器上工件的加工时间等信息
machine_processing = calculate_machine_processing(schedule);
% 所有机器完成加工的最大时间就是Makespan
makespan = max(cellfun(@(x) x(2, end), machine_processing));
end这里先通过calculatemachineprocessing函数(可能在其他辅助文件中定义)根据调度方案计算每台机器上工件的加工情况,然后取所有机器完成加工时间中的最大值作为Makespan。
sorting.m
根据调度方案计算每台机器任意时刻的加工信息(开始时间、结束时间、工件号、机器号),用于绘制甘特图。这部分代码逻辑主要是根据给定的调度顺序,依次计算每个工件在每台机器上的加工时间点。例如:
function machine_info = sorting(schedule, processing_time)
num_machines = size(processing_time, 2);
num_jobs = length(schedule);
machine_info = cell(num_machines, num_jobs);
for i = 1:num_jobs
job_id = schedule(i);
for j = 1:num_machines
if j == 1
start_time = 0;
else
start_time = machine_info{j - 1, i}(2);
end
end_time = start_time + processing_time(job_id, j);
machine_info{j, i} = [start_time, end_time, job_id, j];
end
end
end代码分析:首先根据加工时间矩阵确定机器数量和工件数量,然后通过两层循环遍历每台机器和每个工件。对于第一个工件在第一台机器上,开始时间设为0,之后每个工件在每台机器上的开始时间依赖于前一台机器上该工件的结束时间,通过加上该工件在当前机器上的加工时间得到结束时间,将这些信息存入machine_info这个元胞数组中,方便后续绘制甘特图使用。
二、调度测试集与输出结果
调度测试集包括Car和Rec。最终输出结果非常丰富:
- Makespan:这是目标函数的值,反映了整个调度方案的优劣,值越小表示调度方案越优。
- 工件排序:也就是我们通过算法找到的最优或较优的调度顺序,这是实际应用中安排生产顺序的依据。
- 计算时间:可以通过记录算法开始和结束的时间戳来得到,反映算法的运行效率。
- 最优适宜度收敛曲线、平均适宜度收敛曲线:通过记录每一代的最优适应度和平均适应度,然后绘制曲线,可以直观地看到算法的收敛过程,了解算法是否稳定地朝着最优解收敛。
- 甘特图:前面已经介绍过它的绘制过程,能直观展示每个工件在每台机器上的加工顺序和时间分布。
三、甘特图演示
利用DE得到的20工件×10机器的调度结果甘特图演示(随机运行一次的结果)非常直观地展示了调度情况。从甘特图中可以清晰地看到每个工件在不同机器上的加工先后顺序以及时间占用,方便我们进一步分析调度方案是否合理,是否存在机器闲置时间过长等问题。
总的来说,通过这些文件的协同工作,利用差分进化算法有效地求解了置换流水车间调度问题,并且通过丰富的输出结果为我们提供了多维度分析调度方案的可能。希望这篇博文能给同样研究相关问题的小伙伴一些启发。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)