AAAI2025 | 半监督分割 | ScaleMatch: 混合双尺度伪标签和尺度一致性学习实现半监督分割,代码开源!
AAAI2025 | 半监督分割 | ScaleMatch: 混合双尺度伪标签和尺度一致性学习实现半监督分割,代码开源!
AAAI2025 | 半监督分割 | ScaleMatch: 混合双尺度伪标签和尺度一致性学习实现半监督分割,代码开源!

论文信息
题目:ScaleMatch: Multi-scale Consistency Enhancement for Semi-supervised Semantic Segmentation
出版:AAAI2025
日期:2025-04-11
第一作者:Liang Lv
通讯作者: Lefei Zhang
单位:武汉大学
代码:https://github.com/lvliang6879/ScaleMatch
原文链接:https://ojs.aaai.org/index.php/AAAI/article/view/32631
一、总结
1.1 概述
-What is the problem
半监督语义分割 (S4) 旨在减少标注成本,但现有方法在标注数据不足时难以处理多尺度对象变化,导致模型对尺度敏感。
-What is the work
ScaleMatch旨在通过获取混合双尺度伪标签和尺度一致性学习(mixed dual-scale pseudo-label and scale consistency learning)来学习尺度不变特征。通过跨尺度交互融合 (CIF) 模块生成高质量伪标签,并结合图像级和特征级尺度一致性学习 (ISVC和FSVC) 来增强尺度不变性。
-Features of the work
- 跨尺度交互融合 (Cross-scale Interaction Fusion, CIF) 模块强制不同尺度视图之间的交互信息,从而实现更可靠的伪标签生成。
- ScaleMatch引入了可变尺度分支以利用尺度不变监督。它包括图像级尺度变化一致性 (Image-level Scale Variation Consistency, ISVC) 和特征级尺度变化一致性 (Feature-level Scale Variation Consistency, FSVC)。
-Results
ScaleMatch增强了模型在尺度变化下的泛化能力,在Pascal VOC和Cityscapes数据集上的各种划分协议下优于现有的最先进方法。
1.2 创新点
- 跨尺度交互融合模块:通过VRWKV-based Cross-scale Feature Interaction和Scale-Aware Gate,实现自适应多尺度伪标签融合,替代简单的平均融合。
- 双重尺度一致性学习:同时提出图像级尺度变化一致性和特征级尺度变化一致性,从不同层面增强尺度不变性。
- 高效多尺度训练机制:通过尺度变化分支而非多分辨率输入,显著降低计算开销。
训练策略创新:优化设计
- CIF模块的引入预热启动策略,避免训练早期低质量伪标签带来的噪声。
- CIF模块设计互补权重分配机制,确保多尺度融合的稳定性。
1.3 主要成就
- 揭示了当标注数据不足时,分割模型难以学习图像中的目标尺度变化
- 提出一种简单有效的S4框架ScaleMatch,以解决学习尺度变化的挑战
- ScaleMatch利用CIF模块自适应融合不同尺度视图的伪标签,提升伪标签质量。此外,ScaleMatch包含ISVC和FSVC以增强尺度不变性学习
- 在两个广泛认可的基准数据集PASCAL VOC和Cityscapes上的大量实验表明,所提出的ScaleMatch显著优于现有方法
1.4 核心思想
ScaleMatch通过跨尺度交互融合生成高质量伪标签,并结合图像级与特征级双重尺度一致性学习,使模型在标注数据有限时能够有效学习尺度不变特征,提升半监督语义分割的鲁棒性。
二、研究目标
- 现有方法在标注数据不足时难以处理多尺度对象变化,导致模型对尺度敏感
⟹\Longrightarrow⟹ ScaleMatch通过跨尺度交互融合来生成高质量伪标签,以充分挖掘不同尺度的信息。
- 融入多尺度输入会显著增加计算和内存负担
⟹\Longrightarrow⟹ 为充分利用多尺度信息而不大幅增加计算负担,ScaleMatch引入了可变尺度分支以利用尺度不变监督,使模型能够学习丰富的尺度信息,同时减轻多分辨率输入引起的GPU内存开销
三、研究的背景以及问题陈述
语义分割 (Semantic Segmentation, SS) 是一项密集预测任务,旨在为图像中的像素分配分类标签。它是计算机视觉中的基本任务,在多个领域扮演重要角色,包括自动驾驶、医学图像分析和遥感图像感知。深度学习算法在SS中取得了巨大成功,这得益于大规模精确像素标注数据集的支持。然而,与图像分类或目标检测相比,获取像素级标注既耗时又费力,极具挑战性。
为了减少对费力人工标注的依赖,半监督语义分割 (Semi-supervised Semantic Segmentation, S4) 方法被广泛研究,以利用有限标注数据和大量未标注数据来提升分割性能。
早期的S4研究涵盖了从基于生成对抗网络的方法向一致性正则化框架的过渡。现有S4方法进一步考虑新的数据增强技术或多模型间的相互学习以提高性能。
尽管引入大量未标注数据有助于提升模型性能,但这些方法并非专门为SS任务设计,导致性能提升有限。
与图像分类相比,SS任务中的对象分割涉及不同图像间的多尺度变化。当前全监督分割模型可以通过学习大规模标注数据来处理此问题。
然而,对于S4模型,学习多尺度信息变得更具挑战性,因为标注数据稀缺。
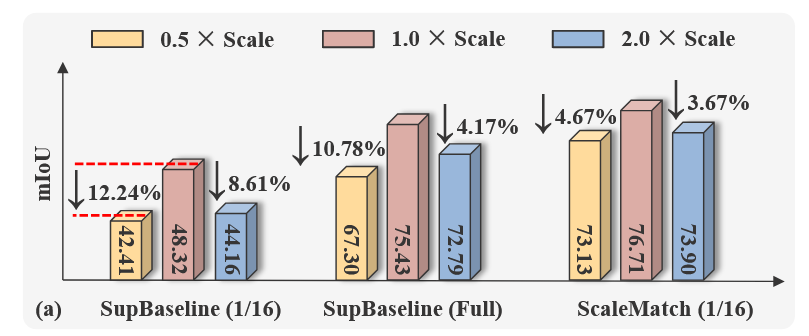
图1(a). Pascal VOC验证集中mIoU的比较,输入缩放因子为0.5、1.0和2.0
在全监督下使用1/16标记数据训练模型
在全监督下使用所有标记数据训练模型
使用ScaleMatch方法训练、使用1/16标记数据训练模型。
如图1(a)所示,当输入图像被缩放或放大两倍时,使用1/16标注数据训练的模型性能显著下降。相比之下,全监督训练的模型仅表现出轻微性能下降,并展示出对尺度变化的更强鲁棒性。这一现象表明,当标注数据不足时,S4模型对尺度变化敏感。
为解决上述问题,本研究将多分辨率输入融入弱到强一致性学习框架,以增强同一图像目标在不同尺度下的像素级语义一致性。基于此,一种直观解决方案是在S4中引入高分辨率和低分辨率分支,这一简单策略实现了显著性能提升。然而,融入多尺度输入会显著增加计算和内存负担。因此,为充分利用多尺度信息而不大幅增加计算负担,本文提出一种新颖且优雅的S4框架,ScaleMatch。
ScaleMatch设计了一个跨尺度交互融合 (Cross-scale Interaction Fusion, CIF) 模块来生成高质量伪标签。CIF模块结合Vision-RWKV以充分挖掘不同尺度的信息,为各种尺度预测生成空间激活图。通过自适应融合不同尺度的伪标签,CIF产生更准确的伪标签,进一步指导模型训练。
为进一步利用尺度一致性,本研究开发了图像-特征级一致性以促进模型学习。具体地,ScaleMatch在图像和特征级别引入可变尺度分支。分支的输出由伪标签监督,以确保图像级尺度变化一致性 (Image-level Scale Variation Consistency, ISVC) 和特征级尺度变化一致性 (Feature-level Scale Variation Consistency, FSVC)。该方法使模型能够学习丰富的尺度信息,同时减轻多分辨率输入引起的GPU内存开销。
四、研究方法详解
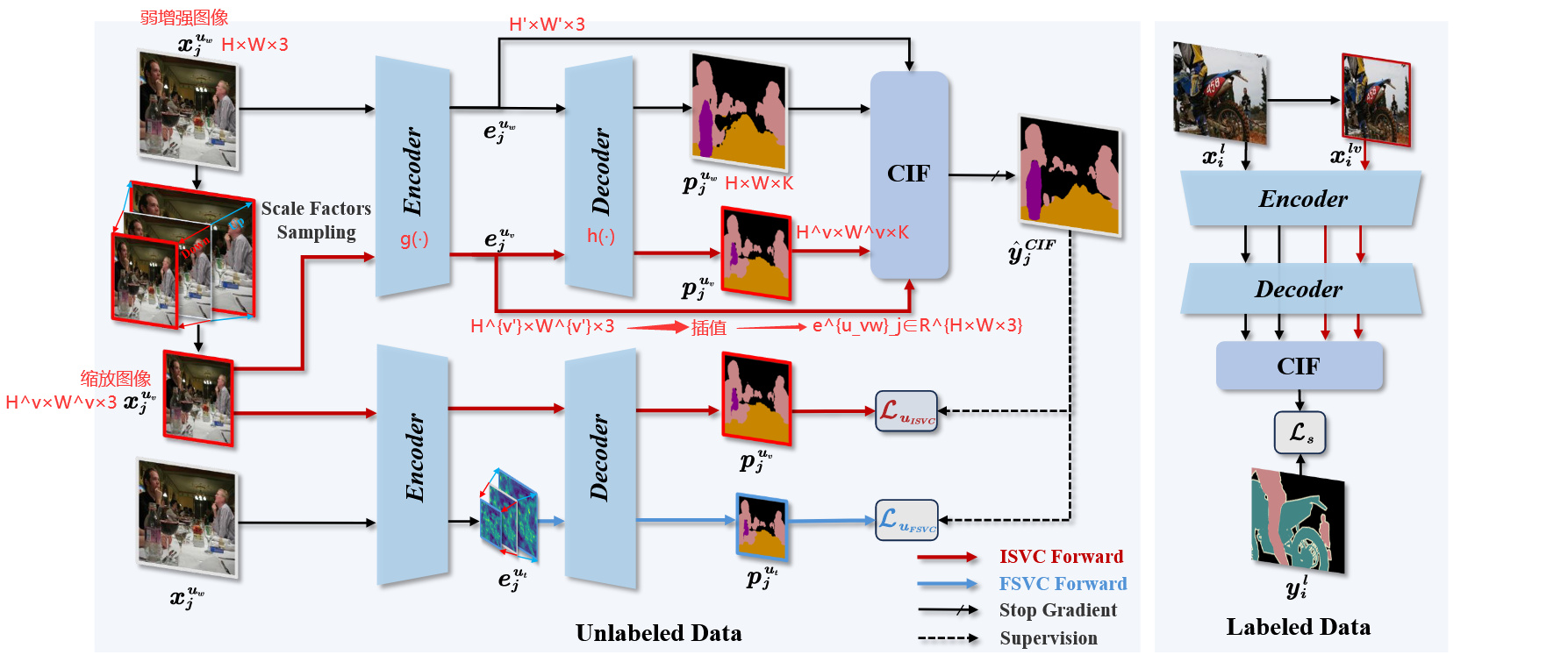
如图2所示,所提出的ScaleMatch包括三个部分:
- 跨尺度交互融合 (Cross-scale Interaction Fusion, CIF) 模块
- 图像级尺度变化一致性 (Image-level Scale Variation Consistency, ISVC)
- 特征级尺度变化一致性 (Feature-level Scale Variation Consistency, FSVC)
4.1 概述
在半监督语义分割 (Semi-supervised Semantic Segmentation, S4) 中,训练数据包括标注集和未标注集。标注集为 {xil,yil}Bi=1l\{x^l_i, y^l_i\}B^l_{i=1}{xil,yil}Bi=1l,其中,xil∈RH×W×3x^l_i∈R^{H×W ×3}xil∈RH×W×3是输入图像,yi∈RH×W×Ky_i∈R^{H×W×K}yi∈RH×W×K是包含K个类别的像素级标签。未标注数据为 {xju}Bj=1u\{x^u_j\}B^u_{j=1}{xju}Bj=1u.
根据FixMatch框架,每个未标注图像 xjux^u_jxju 首先经过弱增强 Aw(xju)A_w(x^u_j)Aw(xju) 得到弱增强图像 xjuwx^{u_w}_jxjuw。该弱增强图像随后通过强增强 As(xjuw)A_s(x^{u_w}_j)As(xjuw) 处理,得到强增强图像 xjusx^{u_s}_jxjus。半监督分割的损失函数为:

许多主流S4方法基于上述框架。然而,现有方法忽略了半监督场景下从极端尺度变化中学习的挑战。本文探索S4中的多尺度一致性,并利用尺度信息获取可靠伪标签。
4.2 Cross-scale Interaction Fusion
在语义分割任务中,多尺度推理显著增强分割结果。通过引入尺度变化分支并从不同分辨率获取预测,可以获得高质量伪标签。与传统跨尺度平均预测的方法不同,本文旨在利用为每个像素分配软权重的方式,为更准确的预测赋予更高权重,以生成精确伪标签。
为此,本文提出跨尺度交互融合模块(Cross-scale Interaction Fusion, CIF)。在训练期间,该模块使用不同分辨率的特征图来学习每个预测的空间激活图。
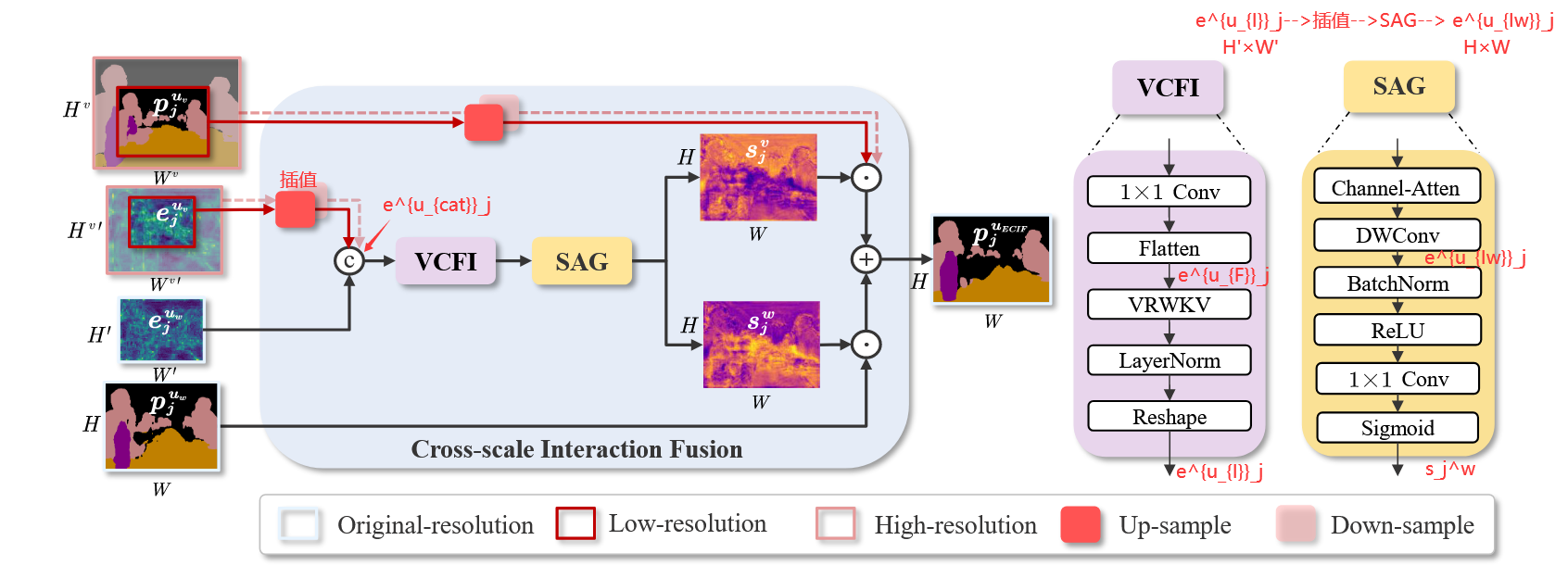
图3:CIF模块的详细信息。VCFI:基于VRWKV的跨尺度特征交互。SAG:尺度感知门。
如图3所示,CIF模块包括两个关键组件:基于Vision-RWKV的跨尺度特征交互和尺度感知门 (VRWKV-based Cross-scale Feature Interaction (VCFI) and the Scale-Aware Gate (SAG))。
VCFI。具体地,本文首先设置一组尺度因子 V=[v1,v2,...,vn]V = [v_1, v_2, . . . , v_n]V=[v1,v2,...,vn]. 在每次训练迭代中,从V中随机采样:
v=Sample(V) v=Sample(V) v=Sample(V)
获得尺度因子 vsv_svs 后,使用v对弱增强图像 xjuw∈RH×W×3x^{u_w}_j∈R^{H×W×3}xjuw∈RH×W×3进行插值:
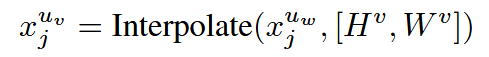
其中插值使用双线性插值,HvH^vHv和HwH^wHw表示按因子v缩放的高度和宽度,xjuv∈RHv×Wv×3x^{u_v}_j∈R^{H^v×W^v×3}xjuv∈RHv×Wv×3表示缩放后的图像。
接下来,将弱增强图像 xjuwx^{u_w}_jxjuw 和缩放图像 xjuvx^{u_v}_jxjuv 输入编码器 g(⋅)以提取各自的特征图 ejuw∈RH′×W′×3e^{u_w}_j∈R^{H'×W'×3}ejuw∈RH′×W′×3 和 ejuv∈RHv′×Wv′×3e^{u_v}_j∈R^{H^{v'}×W^{v'}×3}ejuv∈RHv′×Wv′×3。
然后,将 ejuwe^{u_w}_jejuw 和 ejuve^{u_v}_jejuv 输入解码器 h(⋅)并生成预测概率图 pjuw∈RH×W×Kp^{u_w}_j∈R^{H×W×K}pjuw∈RH×W×K和 pjuv∈RHv×Wv×Kp^{u_v}_j∈R^{H^v×W^v×K}pjuv∈RHv×Wv×K
同时,为促进不同尺度特征图之间的交互,将 ejuve^{u_v}_jejuv 插值以匹配 ejuwe^{u_w}_jejuw 的维度
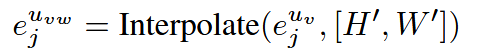
由于xjvx_j^vxjv 的分辨率变化,需要根据不同尺度因子选择上采样或下采样插值,如图3中的红色方块所示。接下来拼接两个特征图:
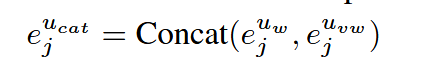
拼接后的特征图 ejucate^{u_{cat}}_jejucat 随后输入VCFI模块进行特征交互计算:

其中 Conv1×1 层压缩通道维度,Flatten展开特征以进行计算, ejuFe^{u_{F}}_jejuF 表示展开后的特征,VRWKV指Vision-RWKV层,用于以线性复杂度捕获全局信息。 ejuIe^{u_{I}}_jejuI 表示交互后的特征,在LayerNorm后重塑为原始输入特征图的维度。
SAG。接下来,将 ejuIe^{u_{I}}_jejuI 插值到的 xjuwx^{u_w}_jxjuw 原始分辨率。缩放后的 ejuIwe^{u_{Iw}}_jejuIw 随后输入SAG模块以获得空间激活图,可表示为:
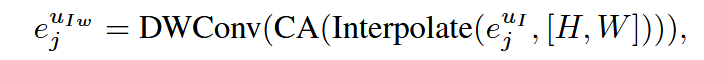
其中使用深度可分离卷积和通道注意力以促进通道间信息交换并为重要通道分配更大权重:
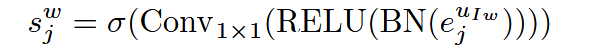
此处,空间激活图 sjws_j^wsjw 对应 xjuwx^{u_w}_jxjuw ,使用Conv1×1 生成。该图通过Sigmoid函数 σ映射到范围 (0,1)作为门函数。对于 sjvs_j^vsjv 的空间激活图,有 sjv=1−sjws_j^v=1-s_j^wsjv=1−sjw 。
最终可以获得最终预测概率图 pjuwp_j^{u_w}pjuw 和 pjuvwp_j^{u_{vw}}pjuvw :
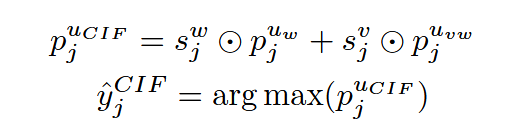
其中 pjuvw∈RH×W×Kp_j^{u_{vw}}∈R^{H×W×K}pjuvw∈RH×W×K 是 pjuvp_j^{u_v}pjuv 插值的结果, ⊙表示逐元素乘积。
最终,融合伪标签 y^kCIF\hat{y}_k^{CIF}y^kCIF 用作监督信号以指导模型在未标注数据上的学习。值得注意的是,CIF也用于标注数据的监督训练,其中使用真实标签监督并更新CIF参数,计算过程与上述相同。
4.3 Scale-variation Consistency Learning
为进一步解决因标注数据有限而导致语义分割模型学习目标尺度变化的挑战,ScaleMatch强制要求同一图像的多尺度视图在分割预测中保持像素级语义一致性,即尺度变化一致性学习。为避免合并多分辨率输入所导致的内存开销,本文引入尺度变化分支。这些分支通过持续改变其输入或特征分辨率来确保多尺度不变性。为丰富同一目标在不同尺度下的表示,本研究采用不同级别的尺度变化一致性作为正则化手段,包括图像级尺度变化一致性 (Image-level Scale Variation Consistency, ISVC) 和特征级尺度变化一致性 (Feature-level Scale Variation Consistency, FSVC)。
图像级尺度变化一致性。使用来自CIF模块的伪标签 y^kCIF\hat{y}_k^{CIF}y^kCIF 来监督输出 pjuvwp_j^{u_{vw}}pjuvw,计算图像级尺度变化一致性损失,其公式为:
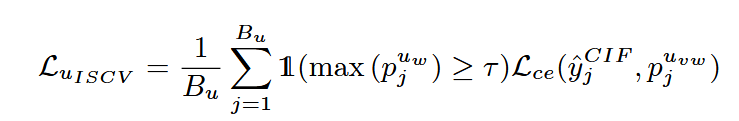
特征级尺度变化一致性。为构建更广泛的扰动空间,UniMatch利用对弱增强图像特征的扰动取得了显著成果。基于这一发现,本文进一步对弱增强图像的特征引入尺度变化以增强尺度变化一致性学习。研究保留了UniMatch中使用的特征随机丢弃扰动,并预定义一组特征图的尺度变化因子 T=[t1,t2,...,tn]T = [t_1, t_2, . . . , t_n]T=[t1,t2,...,tn] 并采样一个因子t。随后根据因子t对特征图进行插值:
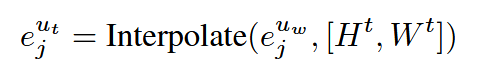
缩放后的特征图 ejute^{u_{t}}_jejut 被输入网络解码器 h(⋅),产生相应输出 pjutp^{u_{t}}_jpjut 。该输出随后通过插值对齐回原始分辨率,得到 pjutwp^{u_{tw}}_jpjutw,以计算特征级尺度变化一致性损失:
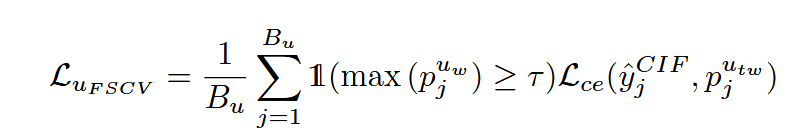
因此,总体损失函数为:
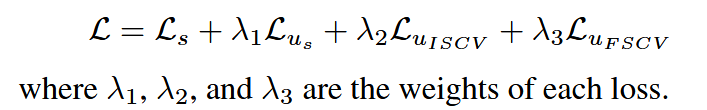
五、实验与分析
5.1 数据集
在两个广泛使用的数据集Pascal VOC 2012和Cityscapes上进行实验
- Pascal VOC 2012是一个语义分割基准数据集,包含1,464张高质量标注图像用于训练,1,449张图像用于评估。此外,在增强版Pascal VOC 2012数据集上进行实验,该数据集包含来自SBD的粗略标注图像,总计10,582张训练图像。
- Cityscapes专为城市街景语义分析设计,包含2,975张高分辨率图像用于训练,500张图像用于验证,主要覆盖城市环境中的19个类别。
使用各种划分协议评估两个数据集。
5.2 实验环境
采用DeepLabV3+作为网络架构,并使用在ImageNet上预训练的ResNet-101作为骨干网络。
对于Pascal数据集,使用SGD优化器,初始学习率为0.001,权重衰减为1e-4,裁剪尺寸为321x321或513x513,批量大小分别为16和8,总训练轮数为80,置信度阈值τ为0.95。
对于Cityscapes数据集,使用AdamW优化器,初始学习率为0.00005,权重衰减为1e-2,裁剪尺寸为801x801,批量大小为4,总训练轮数为240,置信度阈值τ为0。
尺度因子V为[0.25, 0.5, 1.5, 2.0],T为[0.75, 1.0, 1.25],各损失函数的权重λ1、λ2、λ3分别设置为0.25、0.25和0.5。
所有实验中,使用PyTorch框架实现所提方法,并在四张NVIDIA RTX 4090 GPU(每张24GB显存)上进行计算。
5.3 评估方法
平均交并比mIoU
5.4 研究结果

图4, Pascal VOC验证集上的可视化验证
图4中的可视化结果证明,通过尺度变化一致性学习,ScaleMatch在不同尺度对象上相比现有方法具有更好的分割性能。
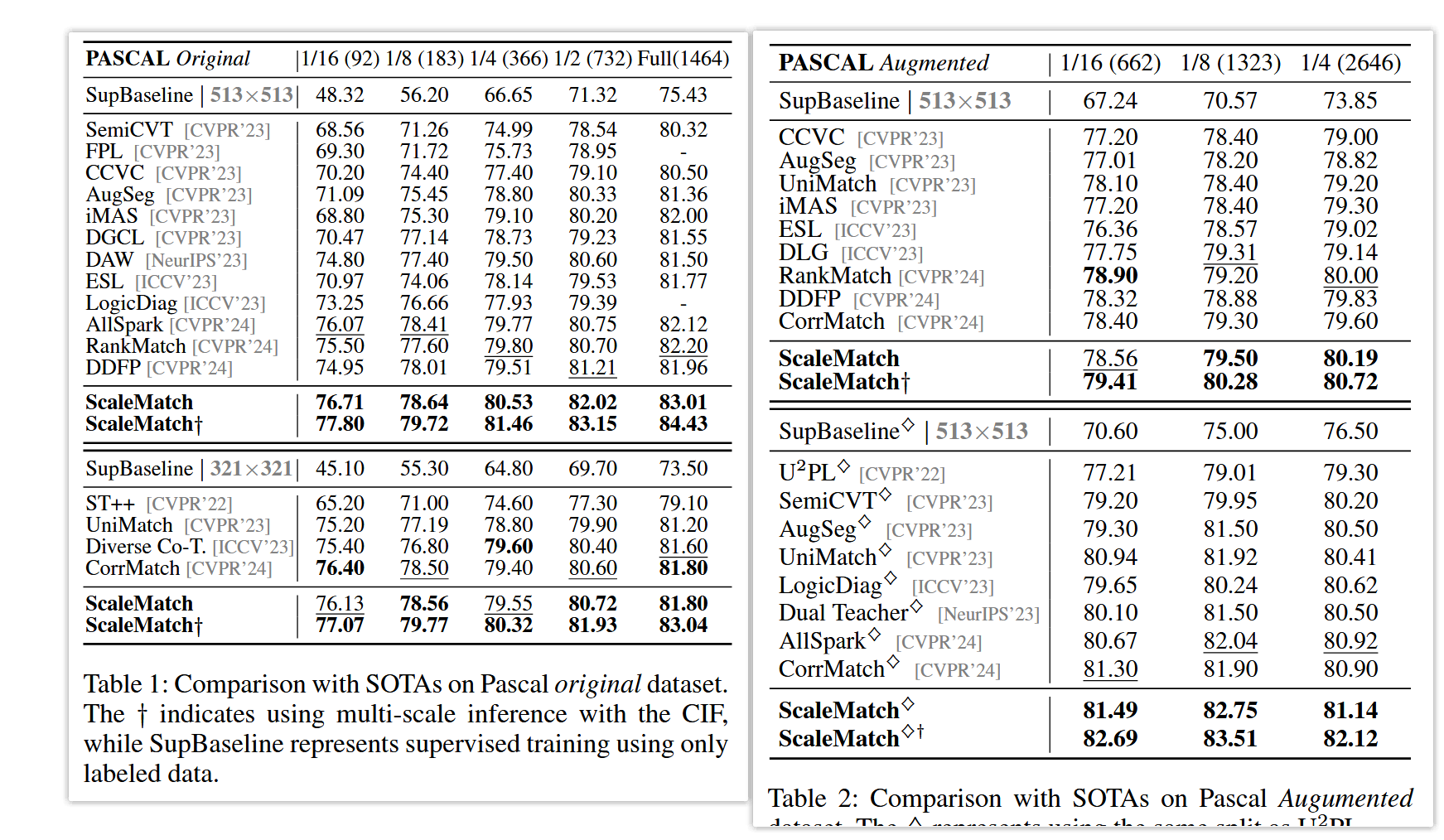
表1和表2分别展示了本文方法与其他最先进方法在Pascal VOC 2012原始数据集和增强数据集上的性能。
与无SSL训练的SupBaseline方法相比,ScaleMatch仅使用少量标注图像即实现更高性能。此外,在513和321分辨率下的大多数实验划分中,ScaleMatch均表现出最先进性能。具体地,在Pascal原始数据集上,所提方法在各划分下分别优于现有SOTA方法0.64%、0.23%、0.73%、0.81%和0.81%。为进一步利用CIF模块提供的强大多尺度特征融合能力,对每个实验设置进行基于CIF的多尺度推理(结合0.5倍和2.0倍尺度),记为†。结果表明,在推理过程中集成多尺度融合进一步提升了模型的分割性能。
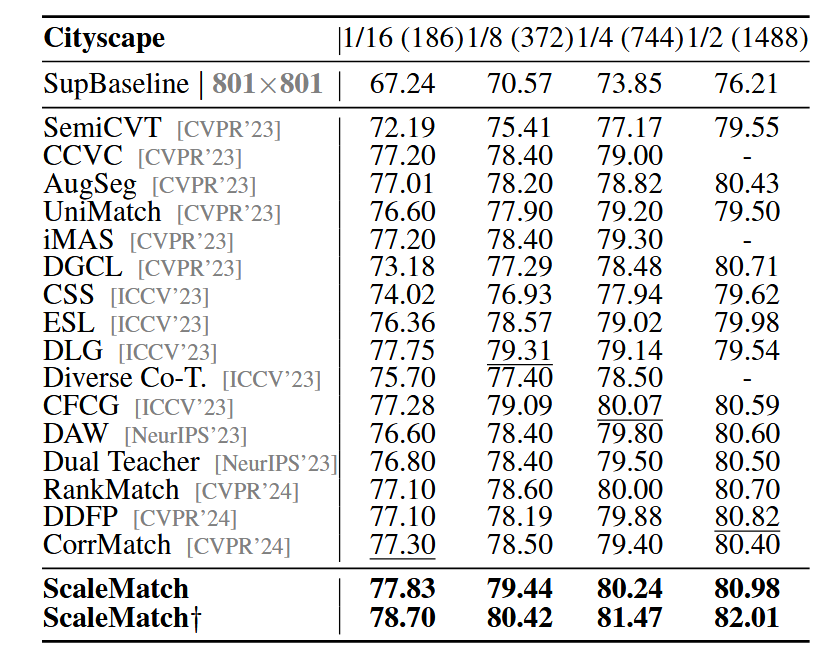
表3比较了本文方法与其他方法在Cityscapes验证集上的性能。
尽管街景复杂,本文方法在不同划分下均表现优异。在相同划分协议下,ScaleMatch显著优于现有SOTA方法,分别提升0.53%、0.13%、0.17%和0.16%。
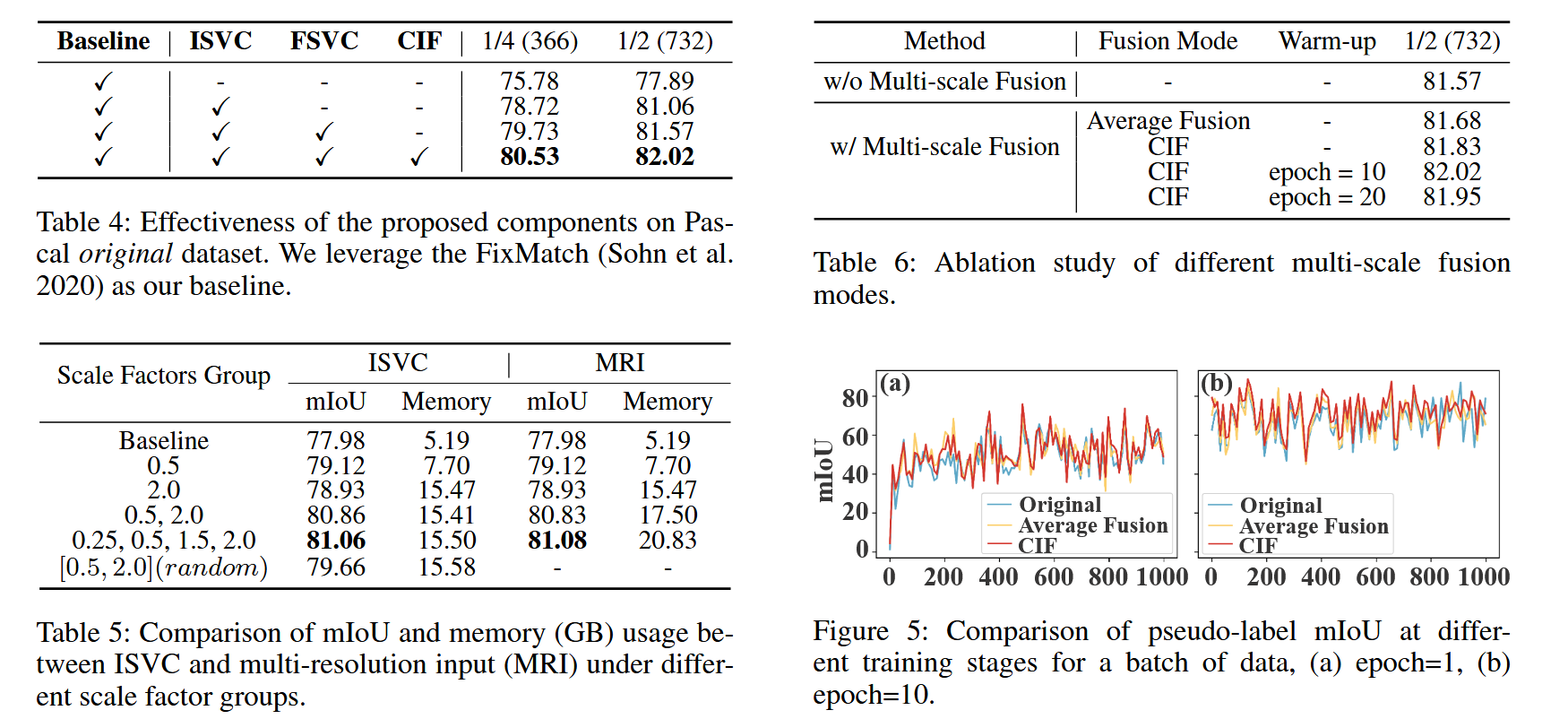
消融实验
由于训练早期模型性能较差,直接使用CIF融合多尺度预测可能降低伪标签质量(如图5所示,第1个epoch时CIF结果不如原始伪标签)。因此,预热策略选择从第10个epoch启动CIF,此时模型已初步收敛,伪标签可靠性提升,CIF能更有效地发挥融合作用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)