AI语音助手
🎯 系统概述这是一个基于Web的智能语音对话助手系统,集成了先进的语音识别、自然语言处理和实时音频通信技术。系统通过生动的角色动画和情绪反馈,为用户提供沉浸式的语音交互体验。
🎯 系统概述
这是一个基于Web的智能语音对话助手系统,集成了先进的语音识别、自然语言处理和实时音频通信技术。系统通过生动的角色动画和情绪反馈,为用户提供沉浸式的语音交互体验。
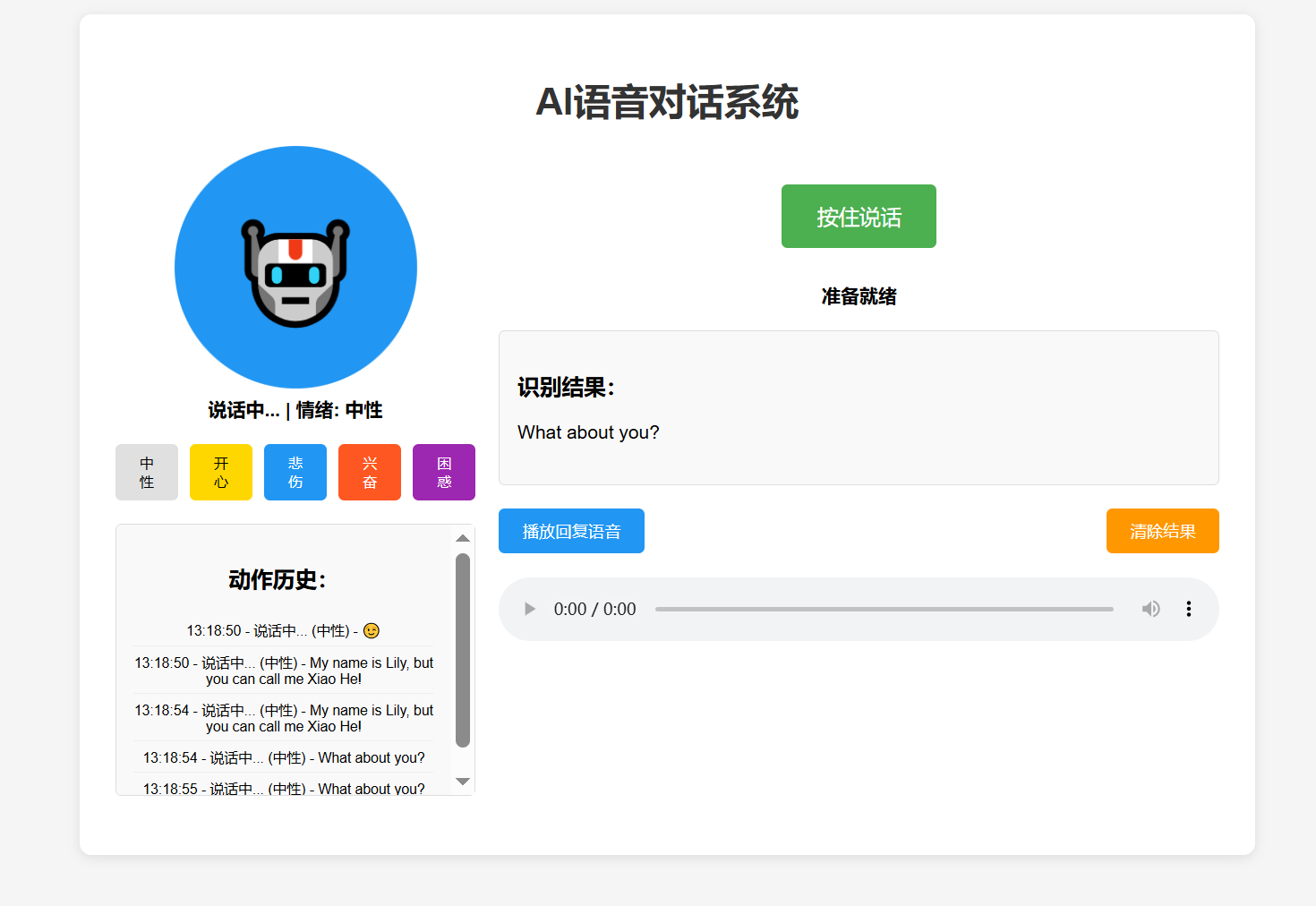
✨ 核心特性
1. 智能语音交互
-
🎤 实时语音输入与识别
-
🔊 高质量语音合成输出
-
⚡ 低延迟音频传输
-
🔒 端到端音频加密
2. 生动角色表现
-
🤖 四种交互状态:
-
🟢 待机状态 - 准备接收指令
-
🎧 聆听状态 - 接收用户语音输入
-
💭 思考状态 - 处理用户请求
-
🗣️ 说话状态 - 回复用户问题
-
-
😊 五种情绪模式:
-
😐 中性 - 常规交互
-
😊 开心 - 积极反馈
-
😢 悲伤 - empathetic响应
-
🎉 兴奋 - 热情回应
-
🤔 困惑 - 需要澄清
-
3. 先进技术架构
text
Web前端 (Flask) ←→ MQTT消息队列 ←→ AI语音服务
↓
音频处理引擎 (Opus + AES)
↓
实时UDP音频流
🛠️ 技术特色
音频处理
-
编码:Opus高效音频编码,支持16kHz采样率
-
加密:AES-128-CTR实时音频加密
-
传输:UDP低延迟音频流传输
-
兼容性:支持多种音频格式和设备
通信协议
-
MQTT:轻量级消息队列,用于控制信令
-
WebSocket:实时前端状态更新
-
RESTful API:系统配置和数据管理
智能特性
-
情绪识别:基于回复内容自动调整角色情绪
-
上下文理解:保持对话连贯性
-
多轮对话:支持复杂的交互场景
-
实时反馈:即时状态更新和动画效果
🎮 用户体验
交互流程
-
启动系统 → 角色进入待机状态
-
按住说话 → 角色切换至聆听状态
-
释放按钮 → 角色进入思考状态
-
AI回复 → 角色动画配合语音输出
-
情绪适配 → 根据内容自动调整表情
控制功能
-
🔄 重复播放AI回复
-
🧹 清除对话历史
-
🎭 手动调整角色情绪
-
📊 查看交互历史记录
🔧 系统要求
硬件要求
-
🎤 麦克风(语音输入)
-
🔊 扬声器/耳机(音频输出)
-
💻 现代Web浏览器
-
🌐 稳定的网络连接
软件依赖
-
Python 3.7+
-
Flask Web框架
-
PyAudio音频处理
-
Opus音频编解码器
-
MQTT客户端库
-
加密算法库
🚀 应用场景
个人助手
-
📅 日程管理和提醒
-
🔍 信息查询和搜索
-
🎵 音乐播放控制
-
📱 智能家居控制
教育娱乐
-
🎯 语言学习伴侣
-
🎮 互动游戏角色
-
📚 故事讲述助手
-
🧩 知识问答系统
专业应用
-
💼 会议记录助手
-
🏥 医疗问诊辅助
-
🛒 客服对话系统
-
🏨 酒店服务助手
🌟 独特优势
技术优势
-
🏎️ 高性能:优化的音频处理流水线
-
🔐 安全性:端到端加密通信
-
📱 跨平台:基于Web的通用访问
-
🔄 可扩展:模块化架构设计
用户体验
-
🎨 视觉反馈:生动的角色动画
-
😊 情感智能:自适应情绪响应
-
🔊 音质优秀:高清语音输入输出
-
⚡ 响应迅速:低延迟实时交互
🔮 未来发展
功能扩展
-
🌍 多语言支持
-
👥 多角色切换
-
🎨 自定义外观
-
📊 数据分析面板
技术升级
-
🧠 更强大的AI模型
-
🎵 背景音乐集成
-
📹 视频通话支持
-
☁️ 云端服务集成
这个AI语音助手系统将先进的人工智能技术与人性化的交互设计完美结合,为用户提供了一个智能、生动、可靠的语音交互伙伴。无论是日常助手任务还是专业的对话场景,都能提供卓越的用户体验。
系统下载地址
https://download.csdn.net/download/suny8/92380284?spm=1001.2014.3001.5503

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)