51c大模型~合集114
在回答网友提问时(Deep Research 每月 价值1000 美元),奥特曼透露了用户使用 Deep Research 的限制,OpenAI 为 ChatGPT Plus 用户提供每月 10 次使用的机会,而免费用户每月可使用 2 次,该计划会随着时间的推移而逐步增加。可能正如网友所总结的:GPT-4.5 就是此前人们认为的 GPT-5,而 GPT-5 将是 GPT-4.5 和 o3 的组合。
我自己的原文哦~ https://blog.51cto.com/whaosoft/13767557
#o3取消独立发布
刚刚,奥特曼剧透GPT-4.5、GPT-5重大更新
奥特曼深夜一则推文,在网络上掀起了讨论狂潮。
没有一点点预告,奥特曼亲自公布自家产品路线图,并承认公司最近发布的一些产品有些混乱。
推文透露,OpenAI 的下一步是发布 GPT-4.5,这是其最后一个非思维链 (CoT) 模型。它的内部代号是 Orion,不过奥特曼没有解释 GPT-4.5 将具有哪些新功能。
未来几个月,OpenAI 将发布一个名为 GPT-5 的模型,该模型将 OpenAI 的大量技术融入 ChatGPT 和 API 中,包括 o3。由于该路线图决策,OpenAI 不再计划将 o3 作为独立模型发布,o3 将成为 GPT-5 的一部分。

可能正如网友所总结的:GPT-4.5 就是此前人们认为的 GPT-5,而 GPT-5 将是 GPT-4.5 和 o3 的组合。
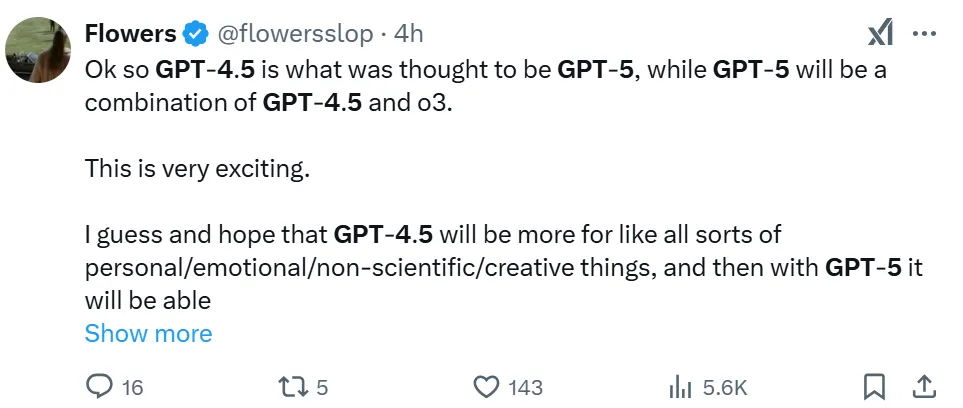
对于 OpenAI 路线图的更新,有组织机构认为这预示着「OpenAI、Anthropic 等公司终于承认,2023 年的战略(只需扩大模型规模、数据、算力和花费更多的资金就能实现 AGI、ASI)不再有效!」
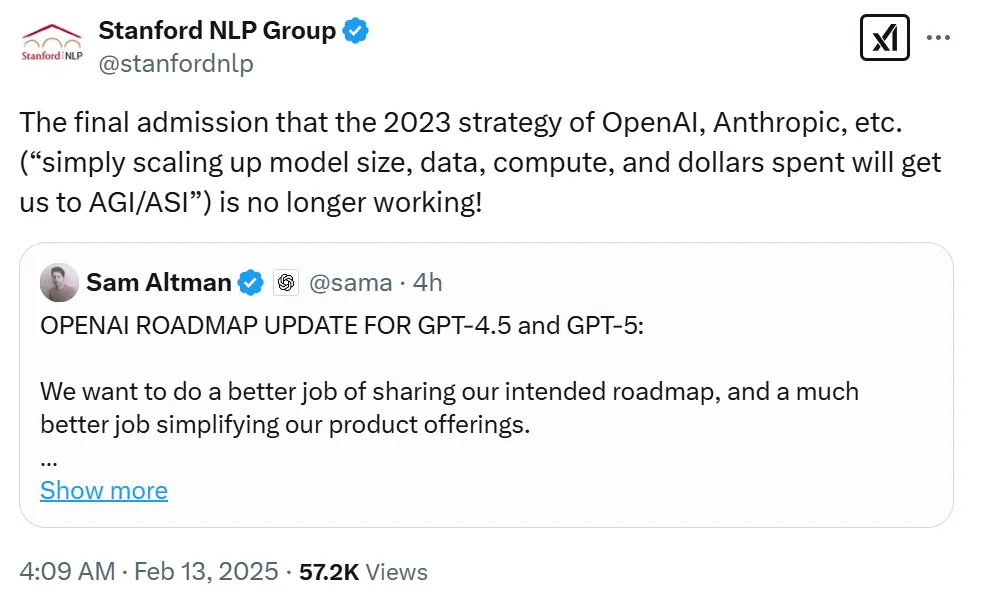
知名学者、纽约大学教授 Gary Marcus 认为奥特曼的这则推文是其试图对 OpenAI 一次重大退步的积极解读。
Marcus 进一步表示,「《华尔街日报》12 月的一份报道透漏,原计划成为 GPT-5 的 Project Orion 项目因进度落后且耗费巨大而停滞不前。
今天,奥特曼将 Orion 重新命名为 GPT-4.5 而非 GPT-5,这可能意味着尽管投入巨大,Orion 仍未达到所谓的扩展法则所暗示的预期。
人工智能将继续前进,或许会有新的发明,但单纯的数据和计算扩展至今未能让我们达到 GPT-5,更不用说 GPT-6 了。即使发现了测试时计算的方法,GPT-5 仍然令人难以捉摸。」

以下是奥特曼推文翻译:

关于 OpenAI GPT-4.5 和 GPT-5 路线图更新:
我们希望能够更好地分享我们的计划路线图,并在简化产品服务方面做得更好。
我们希望 AI 能够直接为你工作,因为我们意识到我们的模型和产品提供对于用户来说已经变得非常复杂。
OpenAI 和你们一样讨厌模型选择器,我们希望回归到那种神奇的、统一的智能。
我们接下来将发布 GPT-4.5,这是我们内部称为 Orion 的模型,作为我们最后一个非思维链模型。
之后,我们的最高目标是通过创建可以使用我们所有工具的系统来统一 o 系列模型和 GPT 系列模型,知道何时需要长时间思考,何时不需要,并且适用于广泛的任务。
在 ChatGPT 和 API 中,GPT-5 将作为集成多项技术(包括 o3)的系统发布,o3 将不再作为独立模型提供。
ChatGPT 的免费版将获得标准智能设置下对 GPT-5 的无限制聊天访问权限(!!),但要遵守滥用阈值。
Plus 订阅者将能够以较高的智能级别运行 GPT-5,而 Pro 订阅者能够以更高一级的智能运行 GPT-5。这些模型将结合语音、画布、搜索、Deep Research 等。
除了产品路线图,OpenAI 还有一些小的更新。在回答网友提问时(Deep Research 每月 价值1000 美元),奥特曼透露了用户使用 Deep Research 的限制,OpenAI 为 ChatGPT Plus 用户提供每月 10 次使用的机会,而免费用户每月可使用 2 次,该计划会随着时间的推移而逐步增加。对于用户来说,还是有使用限制。

OpenAI 官方博客还发布了关于模型规范的重大更新,感兴趣的读者可以前去阅读。

地址:https://openai.com/index/sharing-the-latest-model-spec/
参考链接:https://x.com/sama/status/1889755723078443244
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#Karpathy组建大模型「议会」
GPT-5.1、Gemini 3 Pro等化身最强智囊团
从短视频到 AI 模型,人们消费内容的习惯又一次向追求效率改变。
在阅读长文、论文或海量信息时,越来越多人不再耐心从头到尾浏览,而是倾向于直接获取高密度、快速可吸收的知识。让大模型直接来一段总结 —— 比如评论区一句「@元宝,总结一下」—— 已经成为一种普遍的做法。
这并不是说有什么不好。这恰恰说明在 AI 时代,高效获取信息本身就是人类能力的一次跃迁。
甚至连 AI 领域的大佬们也不例外。前 OpenAI 联合创始人、特斯拉 AI 总监 Andrej Karpathy 也一样。他在前几天发推,说自己「开始养成用 LLM 阅读一切的习惯」。

这和大多数人的阅读习惯非常相似,结合自己阅读的感悟和大模型的信息总结,我们能够形成一系列更完善的认知。
当然了,大语言模型有那么多,在获取信息,整理观点时面对不同类型的内容,其能力也是参差不齐。为了获取更加高质量的结果,Karpathy 毅然决定,让最新最强的四家大模型一起干活。
于是,Karpathy 在周六用氛围编程做了个新的项目,让四个最新的大模型组成一个 LLM 议会,给他做智囊团。
他认为:与其把问题单独问给某一家你最爱的 LLM 服务提供商,不如把它们都组建成一个属于你的 「LLM 议会」。

这个 LLM 议会是一个 Web 应用,界面看起来和 ChatGPT 一模一样,但每次用户提问其实会经历以下流程:
1)问题会被分发给议会中的多个模型(通过 OpenRouter),比如目前是:
- openai/gpt-5.1
- google/gemini-3-pro-preview
- anthropic/claude-sonnet-4.5
- x-ai/grok-4
2)然后所有模型都能看到彼此匿名处理过的回答,并对这些回答进行 审阅和排名;
3)最后,一个「主席模型(Chairman LLM)」会把这些内容作为上下文,生成最终回答。
这个事儿看起来非常眼熟,和知名游戏博主 PewDiePie 用氛围编程做的「大模型委员会」简直心有灵犀。
具体来说,他使用 8 个配置了不同提示词(因此性格不同)的同一模型(gpt-oss-20b)组成了一个委员会。当 PewDiePie 提问时,每个模型都会给出一个答案,然后它们又会对答案进行投票,从中选出最好的答案。
而 Karpathy 这个项目则是使用了不同的大模型进行,更加多样化。
把多个模型的回答并排放在同一个问题下看,是一件很有意思的事情。尤其是加入了多个大模型之间的相互评价和投票机制后,简直是一场全新的「赛博斗蛐蛐」。
很多时候,这些模型竟然愿意承认别家的回答比自己的更好,使得这个流程成为一种非常有意思的模型评估方式。
比如,Karpathy 和「LLM 议会」一起读书时,它们一致称赞 GPT 5.1 是表现最好、洞见最丰富的模型,而始终把 Claude 排在最后,中间则是其他模型浮动。但 Karpathy 却不完全认同这种排序 —— 比如从主观感受上,GPT 5.1 对他来说稍微有点啰嗦、铺陈太多,而 Gemini 3 更凝练、处理得更好。Claude 在这个领域又显得过于简洁。
谁不喜欢看大模型之间的辩论呢?
具体而言,整个项目有三个步骤:
Stage 1:首次意见
用户的提问会被单独发给议会中的所有模型,并收集它们的回答。所有回答将以「标签页视图」展示,让用户可以逐个查看。
Stage 2:互评
每个 LLM 会看到其他模型的回答。后台会将模型身份匿名化,以避免模型「偏袒自己」或偏好某个特定模型。每个 LLM 会被要求基于 准确性与洞察力 对其他回答进行排名。
Stage 3:最终回答
被指定为「议会主席」的 LLM 会接收所有模型的回答与排名,并把这些信息整理成一个最终输出,呈现给用户。
有网友认为,这种形式最终可能成为一种基准测试:

话虽如此,LLM 议会的数据流设计可能还有一整片未被探索的设计空间。多模型集成的构建方式可能还远未被充分研究。
如果大家也对这个项目感兴趣,Karpathy 已经将该项目开源。
- 项目地址:https://github.com/karpathy/llm-council
但提醒一下:Karpathy 不会对这个项目提供任何支持,它是原样提供的、为其他人提供灵感的小工具,他也不打算继续改进它。
我们在之前的测试中,也用氛围编程的方法复刻了一个差不多的项目,和 Karpathy 的 LLM 议会略有相似,使用了两个不同的模型部署。
或许我们也可以把这个小项目开源出来让大家玩一玩?
参考链接:
https://x.com/karpathy/status/1992381094667411768
https://github.com/karpathy/llm-council
....
#陶哲轩用Gemini Deepthink帮人类数学家完成Erdős问题论证
十分钟出结果
有这样一个网站,它专注于数学研究和问题解答,特别是与著名数学家保罗・厄尔德什(Paul Erdős)相关的问题。
它就是 Erdős 问题网站。该网站收录了厄尔德什提出的各类数学问题,涵盖了许多不同领域,如数论、组合数学、图论等。研究人员、数学爱好者和学者们可以在这个平台上提出、讨论和解决这些问题。
如今,AI 的帮助已经变得常规化,比如「Erdős 问题 #367」:

图源:https://www.erdosproblems.com/367
11 月 20 日,独立研究者、数学家 Wouter van Doorn 提出了一个(人类生成的)对该问题第二部分的反例,依赖于他认为成立的一个同余恒等式,并且他「确信有人能够验证…… 确实成立」。

图源:https://www.erdosproblems.com/forum/thread/367#post-1766
几小时后,著名数学家陶哲轩将这个问题提交给了 Gemini 2.5 Deep Think。仅过了大约十分钟,Gemini 2.5 Deep Think 给出了该恒等式的完整证明,并确认了整个论证。该论证使用了一些 p-adic 代数数论,虽然这些工具对这个问题来说有些过于复杂。

图源:https://gemini.google.com/share/81a65aecfd70
接着,陶哲轩花了大约半小时将这个证明手动转换为一个更基础的证明,并发布在网站上,结果证明应该在「vibe formalizing」到 Lean 的范围之内,即经过适当的转化,这个证明是可以在 Lean 中被形式化和验证的。
在帮助论证后,Wouter van Doorn 对陶哲轩表示了感谢。

两天后,数学家 Boris Alexeev 使用 Harmonic 的 Aristotle 工具完成了该问题的 Lean 形式化,并手动形式化了最终的命题,以防止 AI 的滥用。这个过程花费了两到三小时,输出结果如下所示:
图源:https://borisalexeev.com/t/Erdos367.lean
近年来,陶哲轩一直持续探索 AI 工具在数学领域的应用,其参与的研究或亲自上手的数学证明包括如下:
- 谷歌 AlphaEvolve 太香了,陶哲轩甚至发了篇论文,启发数学新构造
- 陶哲轩:用了 GPT-5 Pro 后,小尺度、宏观尺度很赞,中尺度有点垮
- 陶哲轩:感谢 Lean,我又重写了 20 年前经典教材!
- 刚刚,DeepMind 通用科学智能体 AlphaEvolve 突破数学极限,陶哲轩合作参与
- 陶哲轩:感谢 ChatGPT,4 小时独立完成了一个开源项目
- ……
原贴地址:https://mathstodon.xyz/@tao/115591487350860999
....
#dLLM
通用的dLLM开发框架,让BERT掌握扩散式对话
周展辉(https://zhziszz.github.io/):加州大学伯克利分校计算机博士生;
陈凌杰(https://lingjiechen2.github.io/):伊利诺伊大学厄巴纳香槟分校计算机博士生
扩散式语言模型(Diffusion Language Model, DLM)虽近期受关注,但社区长期受限于(1)缺乏易用开发框架与(2)高昂训练成本,导致多数 DLM 难以在合理预算下复现,初学者也难以真正理解其训练与生成机制。
为此,伯克利与 UIUC 团队基于自研的扩散语言模型工具 dLLM,做了一个简单的实验:让 BERT 通过离散扩散学会对话。结果远超预期 —— 无需生成式预训练,仅约 50 GPU・小时的监督微调,ModernBERT-large-chat-v0(0.4B 参数)在多项任务中的表现已逼近 Qwen1.5-0.5B,证明「离散扩散 + 轻量级指令微调」即可赋予经典 BERT 强生成能力,为社区提供了真正高效、低成本的方案。
更重要的是,团队已将训练、推理与评测的全流程代码完全开源,并封装为可直接运行的「Hello World」示例,使初学者也能轻松复现并理解扩散式语言模型的关键步骤。同时团队也开源了其背后的支持框架 dllm,兼容当前主流开源扩散模型且有极强的可扩展性。
- 项目链接:https://github.com/ZHZisZZ/dllm
- 项目报告:https://wandb.ai/asap-zzhou/dllm/reports/dLLM-BERT-Chat--VmlldzoxNDg0MzExNg
- 项目模型:https://huggingface.co/collections/dllm-collection/bert-chat
dLLM: 支撑 BERT Chat 的通用扩散语言模型框架
BERT Chat 系列的训练、评测与可视化均基于团队自研的 dLLM—— 一个面向扩散式语言模型的统一开发框架。dLLM 不仅是工具库,更是一体化的研究平台,持续吸引研究者使用与贡献。
在设计上,dLLM 强调易用性与可复现性。框架结构清晰、脚本完善,使 BERT Chat 等扩散式训练实验能够在单卡甚至笔记本环境复现,非常适合初学者快速入门。同时,它兼容当前主流的开源扩散语言模型,包括 Dream、LLaDA、RND 等,提供灵活的模型基座选择。
更重要的是,dLLM 还实现了多个缺乏公开实现的研究算法,如 Edit Flows,使许多原本停留在论文中的扩散式生成方法得以真正落地,为社区进一步探索提供了坚实基础。
基座模型选择:为何最终选择 ModernBERT
在选择基座模型之前,实验首先关注 ModernBERT 这一近期提出的 BERT 变体。相比原始 BERT 的 512-token 上下文窗口,ModernBERT 将上下文长度显著扩展至 8,192 tokens,并在多个非生成式基准任务上表现更优。因此,实验的核心问题是:这些改进是否能够在生成式训练场景中带来实际收益?为此,实验采用离散扩散语言建模,在 Wikitext-103-v1 数据集上进行了预训练测试。结果显示,在一众对比的模型中,ModernBERT 达到了最低的训练 loss,表明它在生成式训练中同样具备优势。基于这一表现,我们选定 ModernBERT 为后续离散扩散训练与指令微调的主要基座模型。
扩散式预训练是否必要?
SFT 已足以激活生成能力
在探索扩散式训练路径时,实验首先尝试在更大规模的语料库(OpenWebText)上对 ModernBERT 进行离散扩散语言建模预训练。然而,与在 Wikitext-103-v1 上的训练效果不同,模型在 OpenWebText 上的训练 loss 并未出现显著下降。这一结果表明,ModernBERT 的原始 MLM 预训练已经提供了大量语言与世界知识,对相似语料进行额外的 MDLM 预训练可能收益有限。
由此进一步提出疑问:对于 ModernBERT 而言,持续的生成式预训练是否真的必要?为验证这一点,实验分别对三种 ModernBERT-large 检查点进行指令微调(SFT):
(1) 未经任何生成式预训练的版本,
(2) 在 Wikitext-103-v1 上做过 MDLM 预训练的版本,
(3) 在 OpenWebText 上做过 MDLM 预训练的版本。
尽管经过生成式预训练的模型(2 和 3)在 SFT 初期具有更低的训练 loss,但三者最终在训练与评测 loss 上的收敛表现几乎相同。该结果说明,ModernBERT 的原始 MLM 预训练已编码了足够的语言知识,在此基础上进行额外的离散扩散语言建模预训练,对后续的指令微调带来的收益非常有限。
在确认预训练并非必要后,团队扩大了 SFT 数据规模,将 allenai/tulu-3-sft-mixture 与 HuggingFaceTB/smoltalk 拼接,并分别在 ModernBERT-base 与 ModernBERT-large 上进行离散扩散微调,最终得到两个模型权重:ModernBERT-base-chat-v0(0.1B) 与 ModernBERT-large-chat-v0(0.4B)。两者均展现出稳定的多轮对话能力。综合这些结果可以得到结论:对于 BERT 而言,扩散式 SFT 本身就足以激活生成能力;额外的生成式扩散预训练带来的收益极小,而决定最终性能的关键是指令微调。
,时长00:25
实验结果:超乎预期的小模型表现
在多项主流评测任务上,对 ModernBERT 系列模型进行了系统测试,包括 LAMBADA(语言理解)、GSM8K(数学推理)以及 CEVAL-valid(中文知识测评)。结果显示,ModernBERT-base-chat-v0(0.1B)与 ModernBERT-large-chat-v0(0.4B)在各项指标上均表现稳定,其中 large 版本的整体性能已接近 Qwen1.5-0.5B。值得注意的是,ModernBERT-base-chat-v0 仅使用约四分之一规模的参数(0.1B),便能够生成流畅自然的语言,这进一步说明扩散式训练在小模型规模下依然具备竞争力。

项目说明:一份为学习而生的扩散模型示例
团队将 BERT Chat 系列定位为一项教学与研究实验,而非商用系统。在 0.1B 与 0.4B 这样的小模型规模下,我们并不过多追求其在基准测试集上的表现,但它们足以作为入门示例,帮助研究者理解扩散式语言模型的训练与生成机制。若希望进一步探索模型潜力,也可以尝试减少扩散步数(例如将 T 减半),通常会带来明显的生成速度提升,因为扩散模型能够在一次迭代中并行生成多个 token。
为保持研究过程的透明与可复现性,团队不仅开放了完整的训练脚本,还公布了全部训练曲线、消融实验、参数设置与运行指令。相关记录可直接在 W&B 报告中查看。我们相信,开放研究不应只呈现成功的结果,而应将完整的探索过程一并公开,帮助社区更全面地理解扩散语言模型的研究路径。
总结:BERT 的新潜力
本研究展示了一个简单却关键的结论:仅依靠扩散式 SFT 与少量指令数据,就能够赋予传统 BERT 实用级的对话生成能力。无需庞大的自回归预训练,也无需 TB 级 token 的数据成本,BERT 仍然具备被「重新激活」的潜力。对于一直希望找到一个「能跑通、能看懂」的 Diffusion LM 教程的读者而言,dLLM 正是一个从训练、推理到评测都能完整贯通的起点。
....
#PyCharm 接入 DeepSeek 完整版教程
DeepSeek-V3
DeepSeek-V3是一个拥有671B参数的MoE模型,吞吐量每秒达60 token,比上一代V2提升3倍;在数学代码性能上,堪比国外大模型Claude 3.5 Sonnet。
接下来,我们把DeepSeek接入到PyCharm中,并利用其能力辅助我们进行代码开发。
效果演示
首先来看一下效果。
我们可以直接选中代码,并对代码段进行解释。
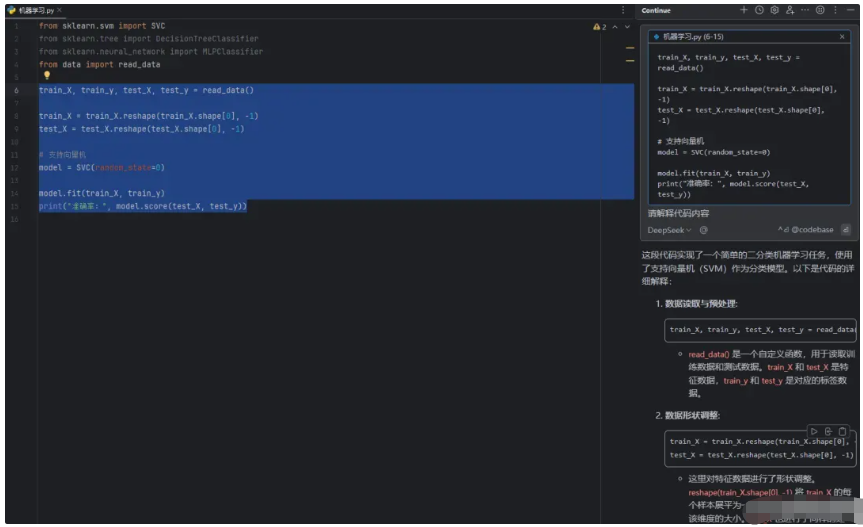
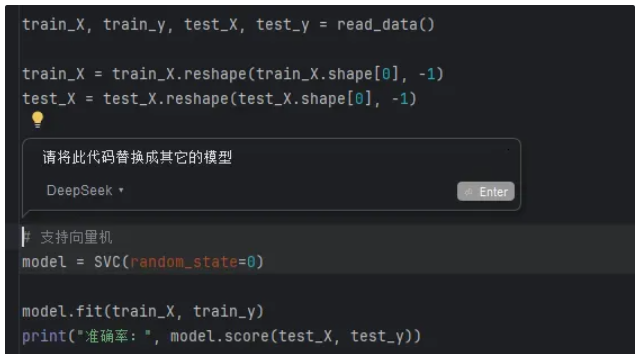
我们也可以通过选中代码,对代码进行修改。
创建API Key
首先进入DeepSeek官网,官网链接如下
点击API开放平台:
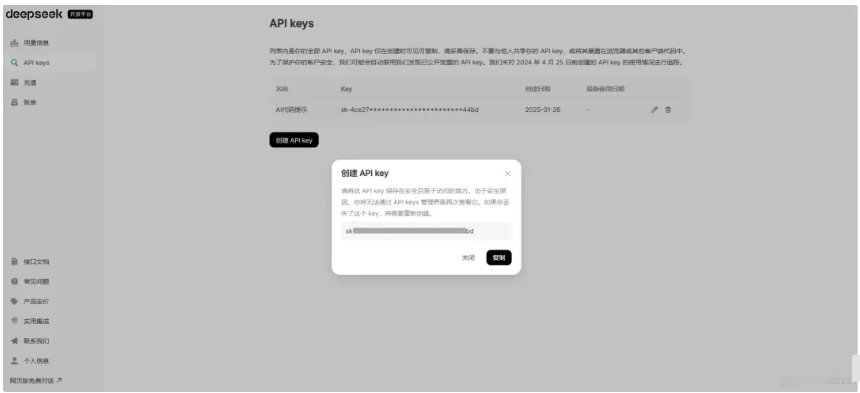
点击左侧“API Keys”,点击创建 API key,输出名称为“AI 代码提示”,也可以使用其它自定义的名称。
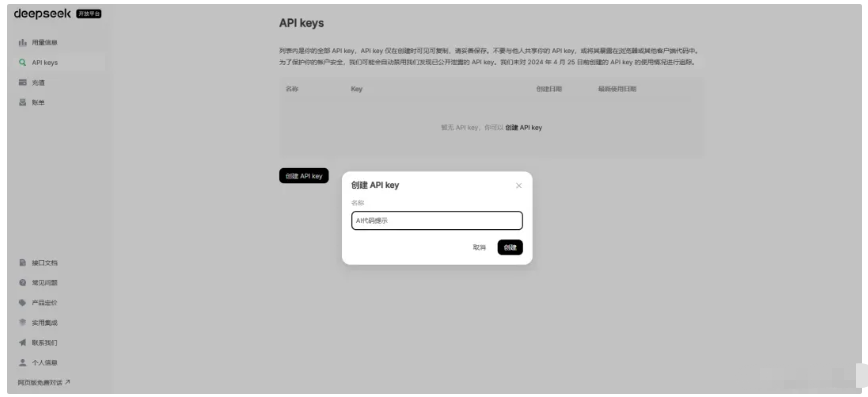
点击“创建",一定要记录此处的 API key,可以先将 API key 复制在其它地方。
在PyCharm中下载Continue插件
打开PyCharm,打开文件->设置->插件,搜索“Continue”,点击安装。
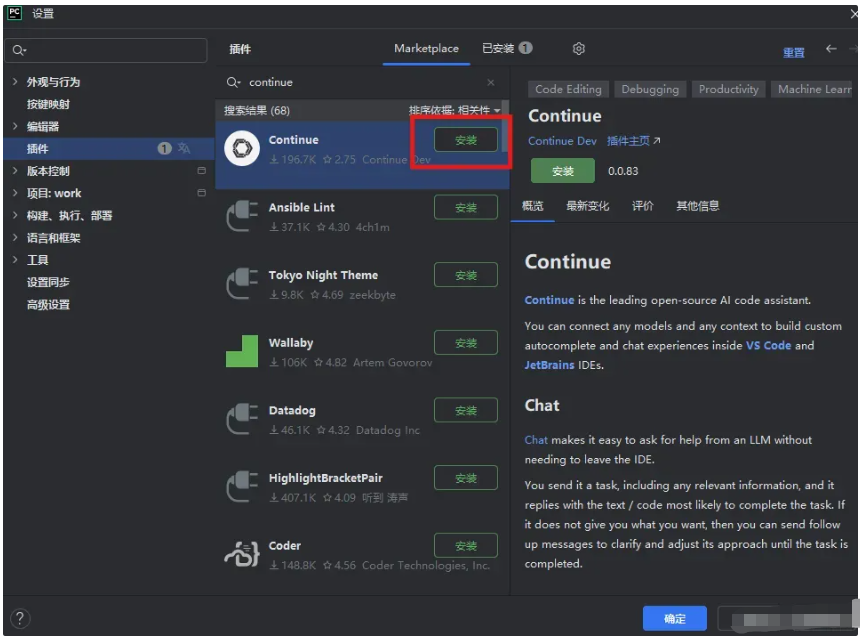
等待插件安装完毕后,点击“应用”,插件安装成功。
配置Continue
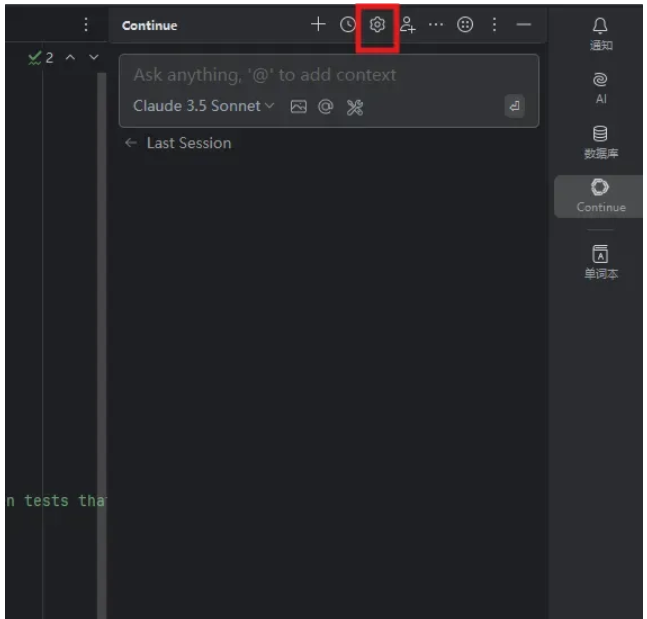
插件安装成功后,在右侧的标签栏中,会显示一个Continue的标签,我们点击即可进入,随后点击设置按键,如下图。
点击后,文本编辑区将会弹出配置文件。
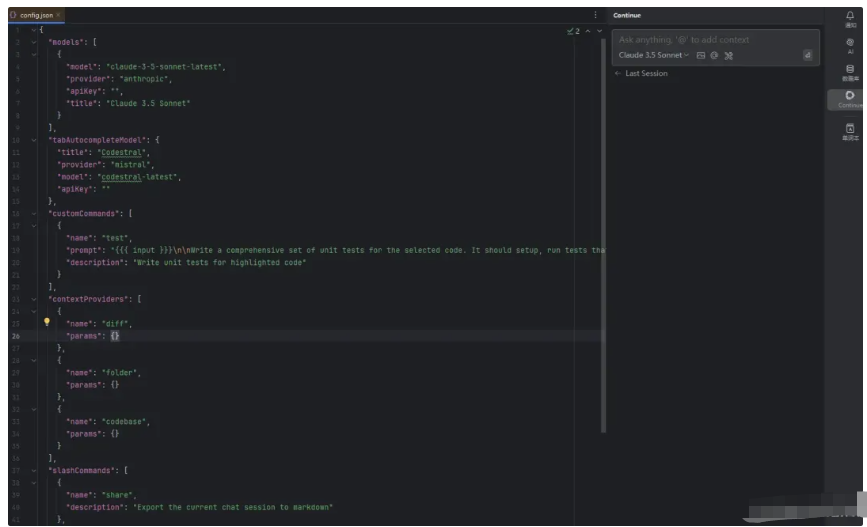
我们对配置文件进行修改,将内容替换为下面的内容:
{
"completionOptions": {
"BaseCompletionOptions": {
"temperature": 0.0,
"maxTokens": 256
}
},
"models": [
{
"title": "DeepSeek",
"model": "deepseek-chat",
"contextLength": 128000,
"apiKey": "REDACTED",
"provider": "deepseek",
"apiBase": "https://api.deepseek.com/beta"
}
],
"tabAutocompleteModel": {
"title": "DeepSeek Coder",
"model": "deepseek-coder",
"apiKey": "REDACTED",
"provider": "deepseek",
"apiBase": "https://api.deepseek.com/beta"
},
"customCommands": [
{
"name": "test",
"prompt": "{
{
{ input }}}\n\nWrite a comprehensive set of unit tests for the selected code. It should setup, run tests that check for correctness including important edge cases, and teardown. Ensure that the tests are complete and sophisticated. Give the tests just as chat output, don't edit any file.",
"description": "Write unit tests for highlighted code"
}
],
"contextProviders": [
{
"name": "diff",
"params": {}
},
{
"name": "folder",
"params": {}
},
{
"name": "codebase",
"params": {}
}
],
"slashCommands": [
{
"name": "share",
"description": "Export the current chat session to markdown"
},
{
"name": "commit",
"description": "Generate a git commit message"
}
]
}修改时将会弹出提示,点击确定。
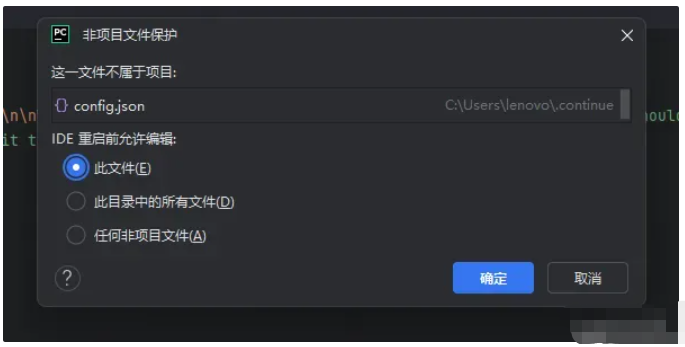
随后,我们将两处apiKey替换为先前保存的API key。
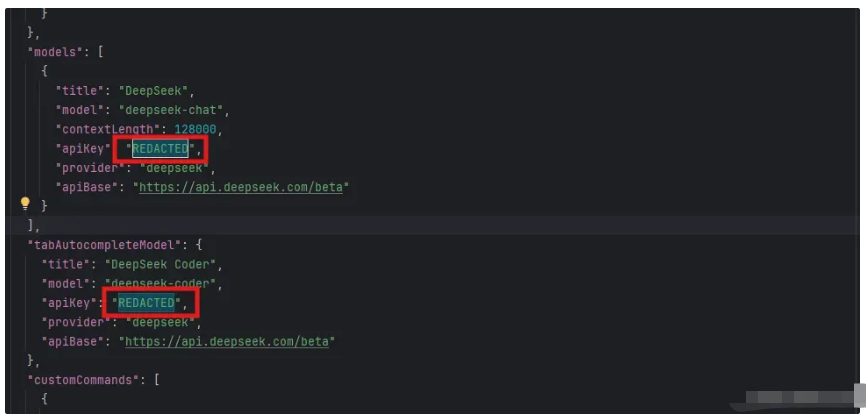
保存文件后,即可开始使用。

....
#Goedel-Prover
哥德尔-Prover超过DeepSeek-Prover,陈丹琦团队造出当前最强形式化推理模型
最近一段时间,以 DeepSeek-R1 为代表的大型推理模型可谓是「当红炸子鸡」,不过整体来说,这些模型所做的推理都属于非形式化推理(informal reasoning)。也就是说,它们主要是通过自然语言执行推理。
但是,这种推理模式有个缺点:难以通过机器来自动验证。也因此,非形式化推理在实际应用中的可靠性就大打折扣了。这还会让研究者更加难以进一步对推理模型进行改进。
解决方案也很直观:形式化推理(formal reasoning)。
近日,普林斯顿大学陈丹琦、Sanjeev Arora 和金驰领导的一个团队开源了一个用于自动定理证明的形式化推理模型 Goedel-Prover(哥德尔证明器),并且该模型在数学问题的自动形式化证明生成任务上达到了 SOTA。代码、模型还有在 Lean Workbook 中发现的新证明都已开源!
- 论文标题:Goedel-Prover: A Frontier Model for Open-Source Automated Theorem Proving
- 论文链接:https://arxiv.org/abs/2502.07640v1
- 项目地址:https://github.com/Goedel-LM/Goedel-Prover
- Hugging Face:https://huggingface.co/Goedel-LM/Goedel-Prover-SFT
首先,先简单解释一下什么是形式化推理:简单来说,形式化推理就是以机器可验证的格式进行推理。这一类别中,比较知名的证明助手包括 Lean、Isabelle 和 Coq,它们都具备各自的形式语言(formal language),能以可被机器验证的方式表达推理。因此,训练 LLM 用这些形式语言编写证明具有重要意义。
不过,训练 LLM 用形式化语言进行定理证明还存在一个重大挑战,即缺少形式化数学陈述和证明。
对于用形式语言表达的定理,为其编写证明的要求很高,需要相当多的领域专业知识。
正因如此,目前公开的形式语言数据集规模都很有限。例如,Lean Workbook 数据集共有 140K 条形式化陈述,其中的形式化陈述使用了 Lean 来陈述问题,但没有证明。这些陈述中,只有 15.7K 条带有形式化证明,这些证明是由 InternLM2.5-StepProver 和 InternLM-Math-Plus 发现的。此外,Open Bootstrapped Theorems 数据集包含 107K 条陈述,其证明来自 Mathlib44。
然而,该团队观察到 Mathlib4 的分布与一般的问题求解基准(例如广泛使用的 miniF2F)的分布存在显著差异。例如,miniF2F 中的陈述主要来自高中数学,需要复杂的推理能力才能解决,而 Mathlib4 中的陈述则侧重于对高级数学概念的简单操作。此外,他们还发现将 Mathlib4 数据纳入训练并不能持续提高模型在 miniF2F 上的性能。
与形式语言的数据稀缺相比,用自然语言书写的数学题却有着海量数据储备,高中生桌子上堆满的「五三」就是一座座富矿。Numina 数据集更是收录了 86 万个高质量的问答对,囊括国内外的中小学数学题、国际奥数竞赛题以及合成数据等等。
为了将这些数据转化为可用的形式语言,研究团队训练了两个形式化转换器。其中一个基于 Lean Workbook 中的非形式 - 形式语言对训练,另一个则采用 Claude-sonnet-3.5 标注的语言对进行训练。下图展示了这些形式化转换器的训练过程。

这两个转换器完成对原始语句的形式化后,团队还用 LLM 加了一道验证,确保形式化后的语句准确保留了原始内容的含义,成功构建了一个含有 164 万个形式语句的数据集。
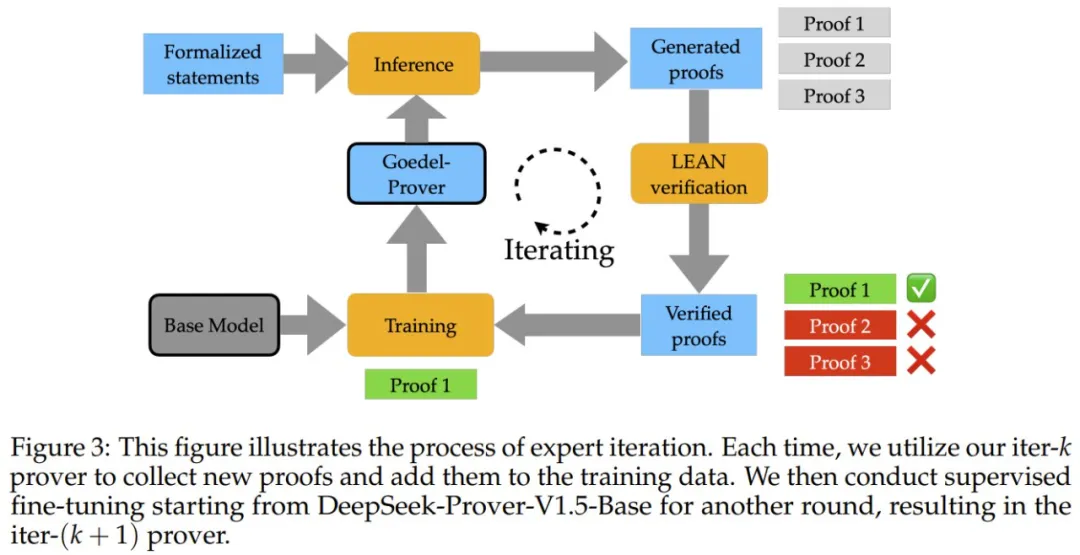
利用这个大规模形式化定理数据集,研究团队采用了一种循环改进的方法,称为专家迭代(expert iteration):先用现有的最好模型(DeepSeek-Prover-V1.5-RL)去尝试解答大量数学题目,把解对的答案收集起来训练新模型,然后用新模型再去解题,不断重复这个过程。经过 8 轮这样的「以老带新」训练后,他们的新模型变得更加厉害了。下图展示了专家迭代的过程。
Goedel-Prover 表现如何?
具体有多厉害呢?如下图所示,在 miniF2F 上,新模型的解题正确率比之前的最优模型(DeepSeek-Prover-V1.5-RL)提高了 7.6%。在 Pass@32、64 直至 25600 测试中,都始终优于 DeepSeek-Prover-V1.5-RL。

新模型在 Lean Workbook 数学题库中成功解决了 29.7K 道题目,这个成绩差不多是其他顶尖模型(InternLM2.5-StepProver 和 InternLMMath-Plus)的两倍。在 PutnamBench 上,新模型解决了 7 个问题(Pass@512),位列排行榜第一。

论文共同一作、普林斯顿博士后 Yong Lin 在 𝕏 上表示他们目前正在开发这个哥德尔证明器的强化学习版本,并且还会有一个比之前更强大的检查点模型。此外,他们还将在开源这个强化学习版本的同时附带 164 万条形式化陈述。

真是让人期待。
....
#DeepSeek R1不编程就能生成GPU内核
这项尝试只用到了 R1 模型和基本验证器,没有针对 R1 的工具,没有对专有的英伟达代码进行微调。其实根据 DeepSeek 介绍,R1 的编码能力不算顶尖。
DeepSeek 引爆 AI 社区后,人们都在尝试本地部署和各领域应用,在新模型基础上持续改进的方向也被不断提出。与此同时,英伟达却在尝试用 DeepSeek 给大模型 pipeline 本身搞自动化。
本周三,英伟达在博客中介绍了利用 DeepSeek-R1 和推理时扩展技术来自动生成优化 GPU 内核的最新研究成果,效果异常的好。

对此有人评价道:难不成英伟达在自拆护城河?
也有人已经开始担心自己的工作会不会被 AI 代替了。

随着 AI 大模型规模不断扩展,能力持续进步,测试时扩展(TTS:Test-Time Scaling)或推理时扩展(Inference-Time Scaling)法则正在兴起。这项技术也被称为 AI 推理或长思考,它通过在推理过程中分配额外的计算资源来评估多种可能的结果,然后选择最佳的一个,从而提高模型整体性能。
推理能力的加强使得 AI 初步掌握了类似于人类剖析复杂问题的能力,能逐个解决以得出最终解决方案的方式,进行策略性思考和系统性地解决复杂问题。
在英伟达这篇文章中,工程师们进行了一项实验,他们使用最新、最热门的开源大模型 DeepSeek-R1 在推理过程中利用额外的计算能力来解决一个复杂问题 —— 自动生成数值正确,且针对不同注意力变体优化的 GPU 注意力内核,而无需任何显式编程。
人们发现在某些情况下,R1 输出的结果甚至优于由熟练工程师开发出来的优化内核。
对优化注意力内核的需求及相关挑战
注意力机制是彻底改变大型语言模型(LLM)发展的一个关键概念。它是一种强大的机制,使 AI 模型在执行任务时能够选择性地关注输入中最相关的部分。通过专注于重要信息,注意力操作帮助模型做出更好的预测并发现数据中的隐藏模式。
注意力操作的计算复杂度与输入序列长度的平方成正比增长。这促使我们需要开发优化的底层实现(即 GPU 内核),以防止简单实现导致的运行时错误(如内存不足错误),并提高计算效率。
另外,注意力有多种变体(因果注意力、相对位置嵌入、ALiBi 等),工程师通常需要为特定任务组合使用这些变体。
多模态模型(例如视觉 Transformer)引入了额外的挑战,因为它们需要专门的注意力机制(如空间邻域注意力)来维护计算机视觉、视频生成模型等中常见的时空信息。

图 1:2D 输入上的邻域注意力。
但在这个任务上,即使对于经验丰富的软件工程师来说,创建针对注意力的优化 GPU 内核也需要大量技能和时间。
最近的大模型(如 DeepSeek-R1)在代码生成任务中表现出了很大的潜力,但它们在第一次尝试创建优化代码时仍然效果不好。这使得在推理时使用其他策略来生成优化代码成为了必要。
以下 Prompt 是相对位置嵌入注意力内核的示例用户输入。
Please write a GPU attention kernel to support relative position encodings. Implement the relative positional encoding on the fly within the kernel. The complete code should be returned, including the necessary modifications.
Use the following function to compute the relative positional encoding:
def relative_positional(score, b, h, q_idx, kv_idx):
return score + (q_idx - kv_idx)
When implementing the kernel, keep in mind that a constant scaling factor 1.44269504 should be applied to the relative positional encoding due to qk_scale = sm_scale * 1.44269504. The PyTorch reference does not need to scale the relative positional encoding, but in the GPU kernel, use:
qk = qk * qk_scale + rel_pos * 1.44269504
Please provide the complete updated kernel code that incorporates these changes, ensuring that the relative positional encoding is applied efficiently within the kernel operations.大模型有时会产生幻觉,或输出混合不同语言或框架的语法,导致生成的代码错误或效率低下。计算最佳 GPU 线程映射也是一项艰巨而具有挑战性的任务,通常需要迭代细化才能获得正确且高效的内核。
用于生成优化 GPU 内核的推理时扩展
为了利用优化的注意力内核获得最佳结果,英伟达工程师创建了一个新的工作流程,包括了一个特殊的验证器以及一个在预定时间内以闭环方式进行推理的 DeepSeek-R1 模型。

图 2:在 Nvidia Hopper 平台上利用 DeepSeek-R1 的推理时扩展。
具体地讲,该工作流程首先由手动提示进行初始化,然后 DeepSeek-R1 在第一次遍历中生成 GPU 代码(即内核)。验证器在一块英伟达 H100 GPU 上运行,它对生成的内核进行分析,并创造新的提示以作为输入提供给 DeepSeek-R1。
这种闭环方法每次都以不同的方式引导代码生成过程,从而实现更好的效果。英伟达发现,这个过程持续 15 分钟就可以得到一个改进的注意力内核。
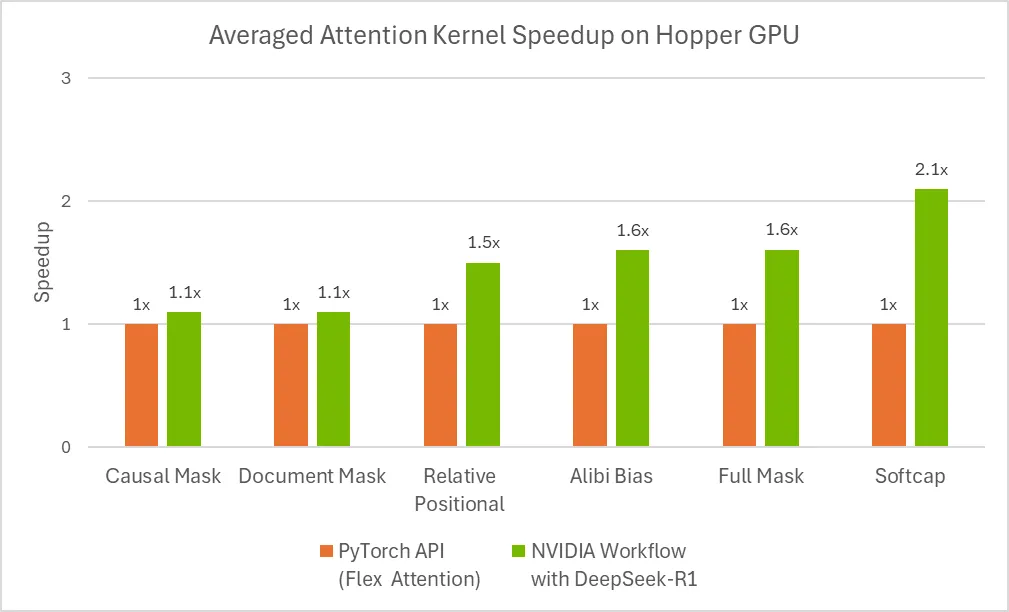
图 3:使用 flex attention 自动生成的优化注意力内核的性能。
根据斯坦福的 KernelBench 基准测试,该工作流程可以为 100% 的 Level-1 问题和 96% 的 Level-2 问题生成数值正确的内核。
其中,KernelBench 中的 Level-1 解决率是指:评估 LLM 为特定计算任务生成高效 GPU 内核的能力的数值正确指标。该测试是一系列「测试最新 LLM GPU 编程能力」挑战的一部分。
图 4 显示了推理时预算对 agent 解决率的影响,结果显示,在 Level-1 类别中为每个问题分配超过 10 分钟的时间,可以使工作流程为 100 个问题中的大多数生成数值正确的代码。
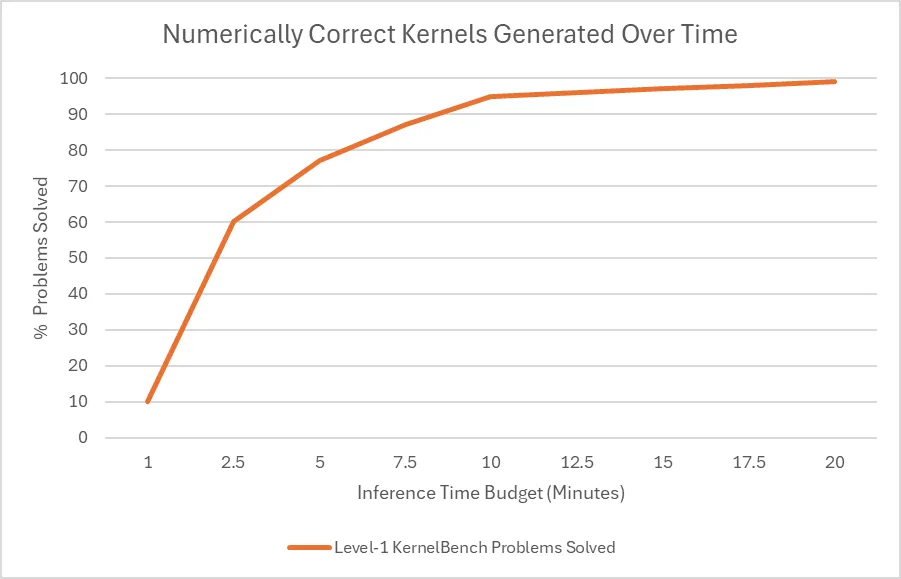
这些结果表明,在使用最新的 DeepSeek-R1 模型时,如果在推理阶段投入更多计算,则可以获得更好的 GPU 内核。英伟达表示,其对于 DeepSeek-R1 的最新进展及其应用潜力感到非常兴奋。
....
#火山引擎将TPM上调到了500万!
为了让DeepSeek-R1用起来更顺畅,火山引擎将TPM上调到了500万!全网首家
最近,DeepSeek 很热,是个好 AI,但不是每个人都能用上。

于是,不少大大小小的 AI 云服务商都看到了机会,部署上线了 DeepSeek 的各个模型,并还通过各种优惠活动为自己拉用户。相信很多读者都参与到了这波薅羊毛中,但结果呢?很多时候,虽然免费的 Token 额度是到账了,但调用 DeepSeek-R1 是否成功就完全得看运气了。那些到账的 Token 额度也就成了一个可见而不可用的数字。这不由得让人感叹:薅羊毛,还是得薅大厂的。
前些天,火山引擎也上线了 DeepSeek-R1 模型(包括满血版和一些蒸馏版),并且还向用户赠送了 50 万 Token 的免费额度。用完后「续杯」的价格也不贵 —— 目前 DeepSeek-R1 满血版还在半价优惠中!算下来,每 100 万 Token 输入仅需 2 元钱,100 万 Token 输出也只需 8 元。

并且我们完全不必担心遇到「服务器繁忙」的问题。作为字节跳动旗下的云和 AI 服务平台,火山引擎的实力已经得到了大量部署其上的服务的验证 —— 就以 DeepSeek 的模型为例,自其登陆火山引擎以来,用量一直在持续攀升,现在已有数万客户稳定调用该模型,而火山引擎依然能够轻松地保持非常稳定的服务。
这也得到了第三方评测平台的佐证。根据 SuperCLUE 最新发布的 DeepSeek-R1 网页端稳定性测评报告,火山引擎是唯一一个完整回复率达到了 100% 的 DeepSeek-R1 第三方平台,也就是说部署在该平台上的 DeepSeek-R1 模型每一次都能给出完整回复,不存在截断、无响应等问题。
事实上,DeepSeek 系列模型现有的数万客户对火山引擎来说也只能是「洒洒水啦」。要知道,火山引擎为每位用户设定的初始 TPM(每分钟 Token 数)限流就已经达到了惊人的 500 万!在之前 80 万 TPM 的基础上实现了近一个数量级的提升。可说是全网最高。企业和开发者完全不必担心自己的数据或查询量过大和流量不够。

相较之下,其它 AI 云服务商提供的 TPM 就远远不及了,比如阿里云为 DeepSeek-R1 和 DeepSeek-V3 设定了最高 120 万的 TPM,而腾讯云的数据也只有 60 万 TPM,百度智能云为自家 ERNIE 系列模型设置的初始 TPM 也都不超过 80 万。其它更小规模的厂商就更别提了。
放眼海外, OpenAI 为用户设置的 TPM 也非常低:免费用户仅有 4 万 TPM,而只有当付费等级达到 Tier 3 以上时,才有可能获得与火山引擎提供的相当的 TPM。Claude 的流量限制也差不多,其为 Tier 1 用户设置了 4 万输入 TPM 和 8000 输出 TPM 的限制,最高的 Tier 4 也仅有 40 万输入 TPM 和 8 万输出 TPM。
此外,火山引擎还给了用户 50 亿初始离线 TPD(每日 Token 数)配额,是全网首家做到如此豪气的 AI 云服务商。
所以,不管是「全网最高」还是「全网首家」,火山引擎都当之无愧。
同时,在保证了超大流量和吞吐量的同时,火山引擎也做到了超低延迟。据火山引擎智能算法负责人吴迪介绍,即使是在数千万 TPM 的大流量下,火山引擎依然能达到相当稳定的低延迟水平,如下图所示。

500 万 TPM,火山引擎的底气是什么?
500 万 TPM 并不是一个小数字,换算下来,大致相当于每分钟 3 万多条响应,足以满足一个具有相当规模用户的应用的需求。火山引擎敢放开手脚,为用户提供如此实惠,自然有着自己的底气。
首先,自然是硬件实力。火山引擎有海量的 GPU 资源,并且吴迪表示已经将数以万计不同型号的 GPU 算力投入了火山方舟 —— 火山引擎旗下一站式大模型服务平台。另外,火山引擎还实现了「极致的成本效用」,可实现对 GPU 算力的灵活调用。
不仅如此,火山引擎的弹性伸缩(Auto Scaling)能力也值得称道。简单来说,弹性伸缩是指让云服务器资源池可根据当前服务的需求弹性调整所配置的计算资源。火山引擎能在分钟级的时间内完成数千台 GPU 资源的伸缩调度,从而可以有效地支持突发的流量和业务高峰。
针对 DeepSeek 系列模型,火山引擎还通过全栈自研推理引擎进行了算子层、系统层的深度优化。
在算子层,由于 DeepSeek 系列与此前公开的豆包大模型 1.5 都采用了相似的 MoE 稀疏架构,因此火山引擎针对豆包系列模型部署的大量专家优化都可以直接复用。在此基础上,火山引擎还针对 DeepSeek 的尺寸进行了重新调优。比如针对 MLA(多头隐注意力)计算,火山引擎结合精度量化,针对硬件架构进行了指令级别的调优。

而在系统层,火山引擎进行了三项深度优化:
- 通过异构 PD 分离以及多机 EP + DP + TP 的混合并行推理方式,对计算效率和成本进行了极致的优化,同时还保障了推理延迟的稳定。
- 通过定制化网卡和自主研发的网络协议,显著优化多机推理 All2All 通信耗时。
- 结合高效的分布式存储设施,可显著优化 DeepSeek 671B 这种超大模型权重的加载速度,保证系统的扩容效率,从而达成更加高效的弹性计算系统。

方舟推理工程优化专家徐子林表示:「DeepSeek-R1 满血版是一个非常庞大的模型,加上前后处理过程,总参数量可达 700B,而如果按照我们当前最极致的优化水平,可在 7 秒内完成模型的加载。」也就是说,当系统出现突发流量时,火山引擎可实现秒级响应,从而实现「用户侧的无感使用」。
在火山引擎使用 DeepSeek,还有更多好处
在火山引擎上使用 DeepSeek,除了流量大、速度快、延迟低,用户还能享受到更多好处。
首先,火山引擎不仅提供了已经部署好的 DeepSeek 系列模型(可通过网页端直接使用以及通过 API 调用),而且还支持其它几种使用 DeepSeek 的模式,包括使用火山引擎的 veMLP(机器学习平台)高效部署、使用 VKE(容器服务)灵活部署、使用火山引擎系列 GPU ECS 自定义部署。下表简要总结了这几种不同模式的适合场景、核心使用方式以及优势。

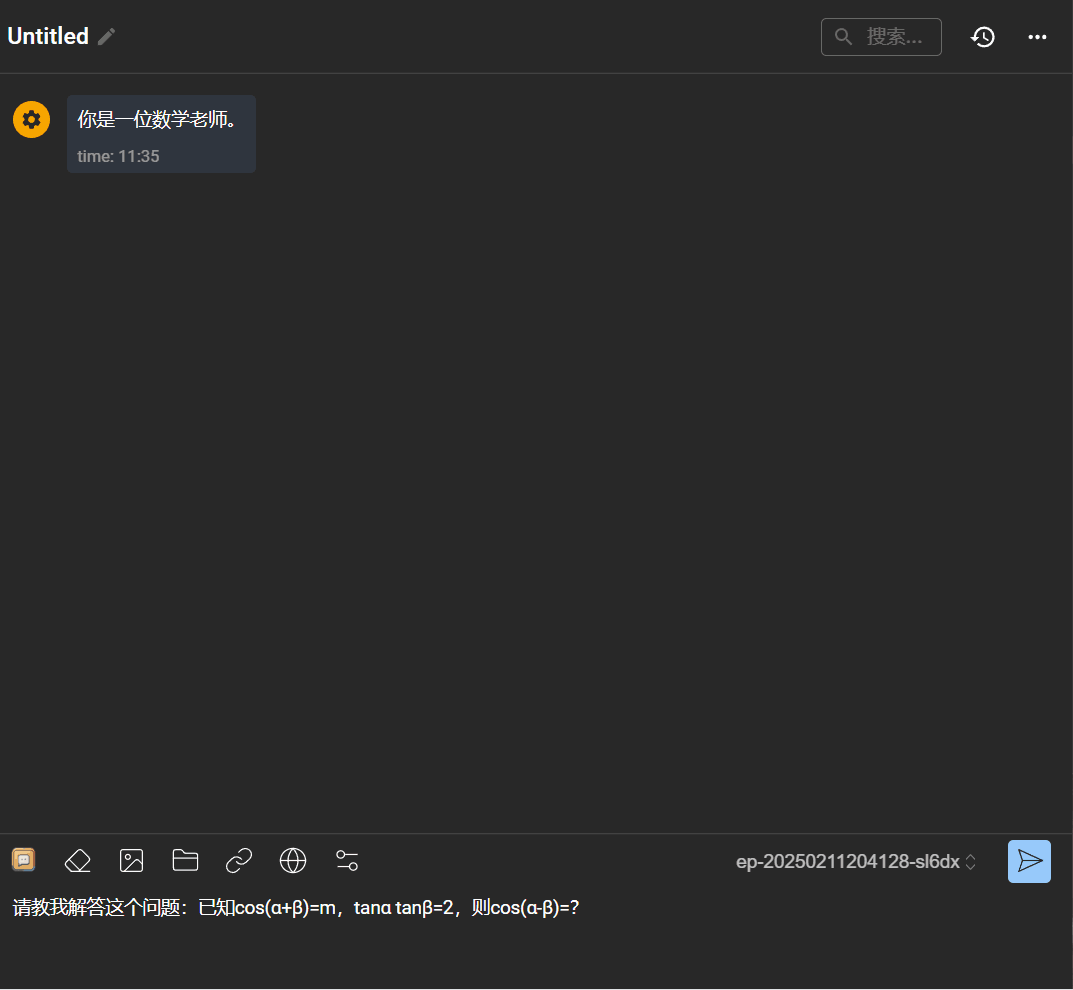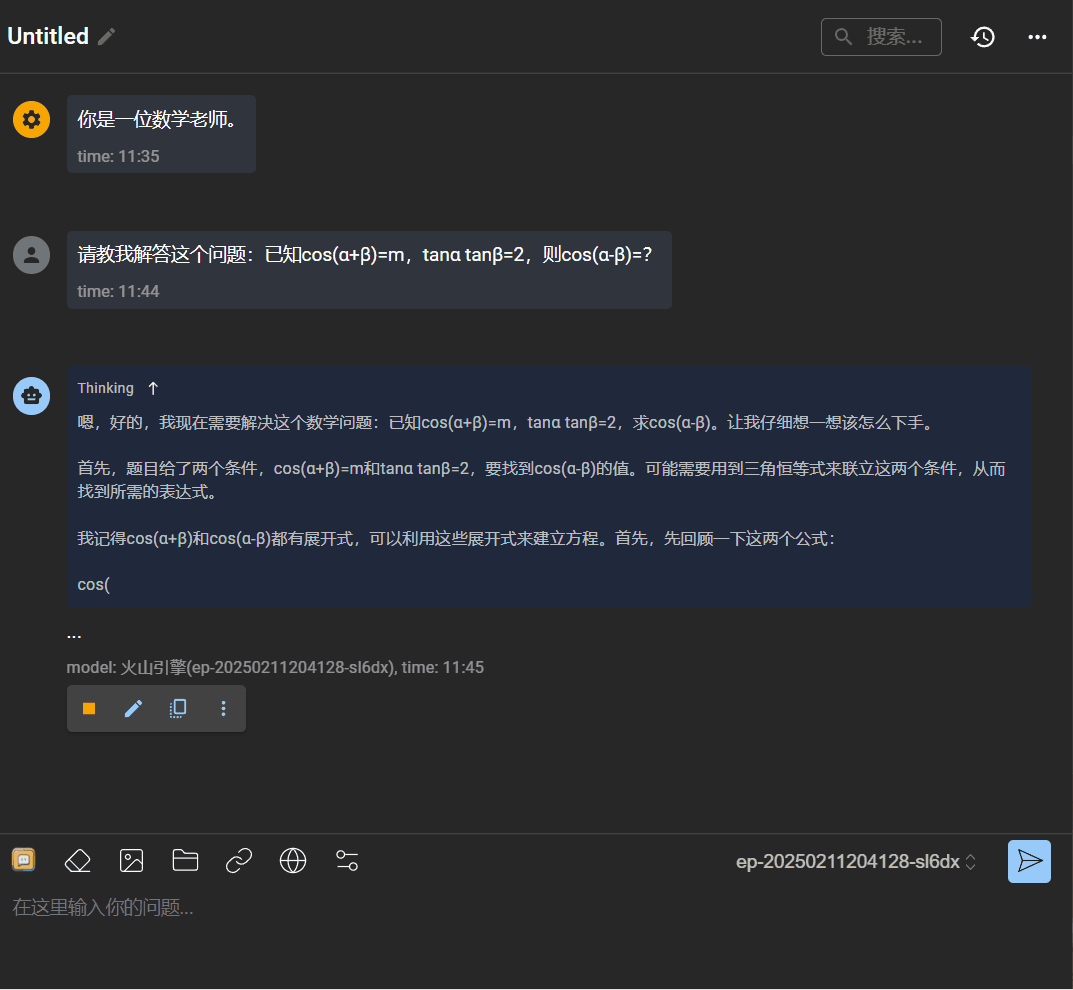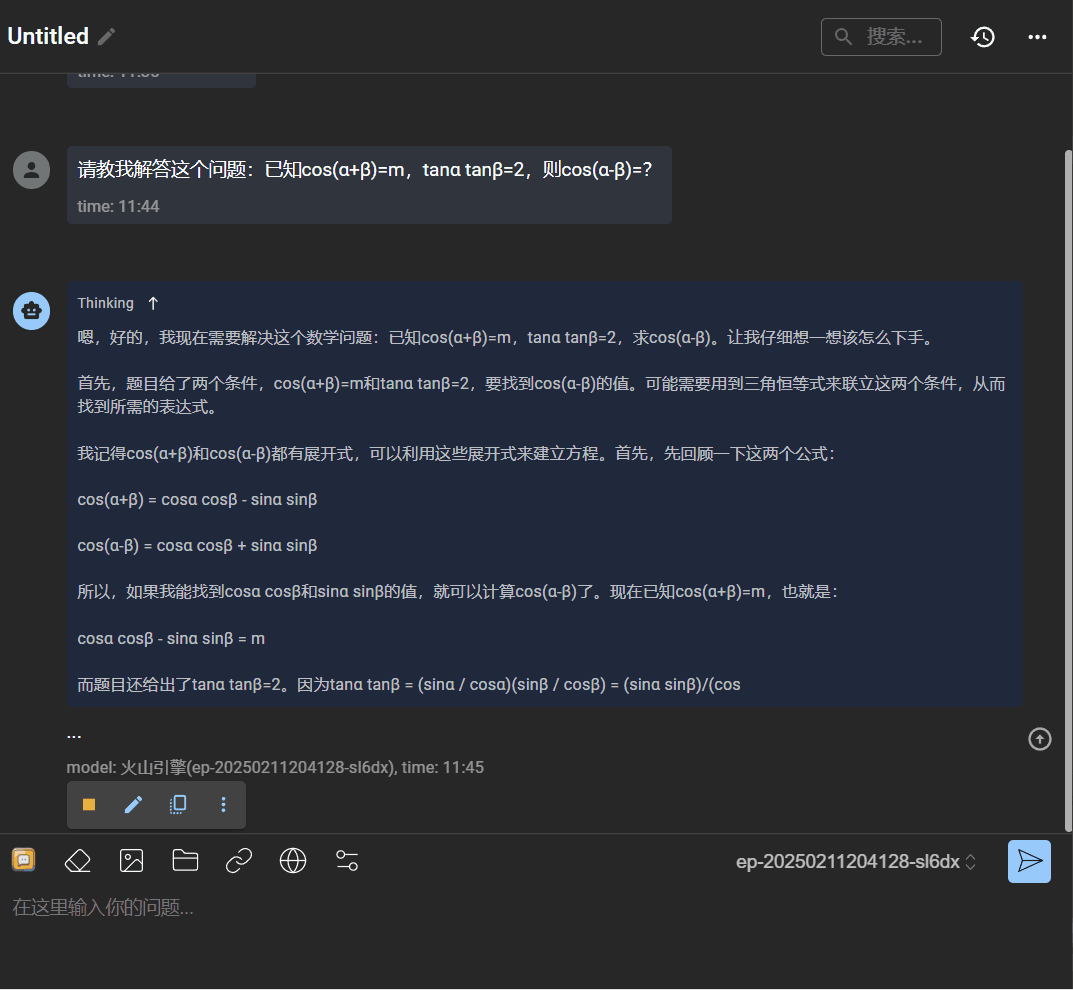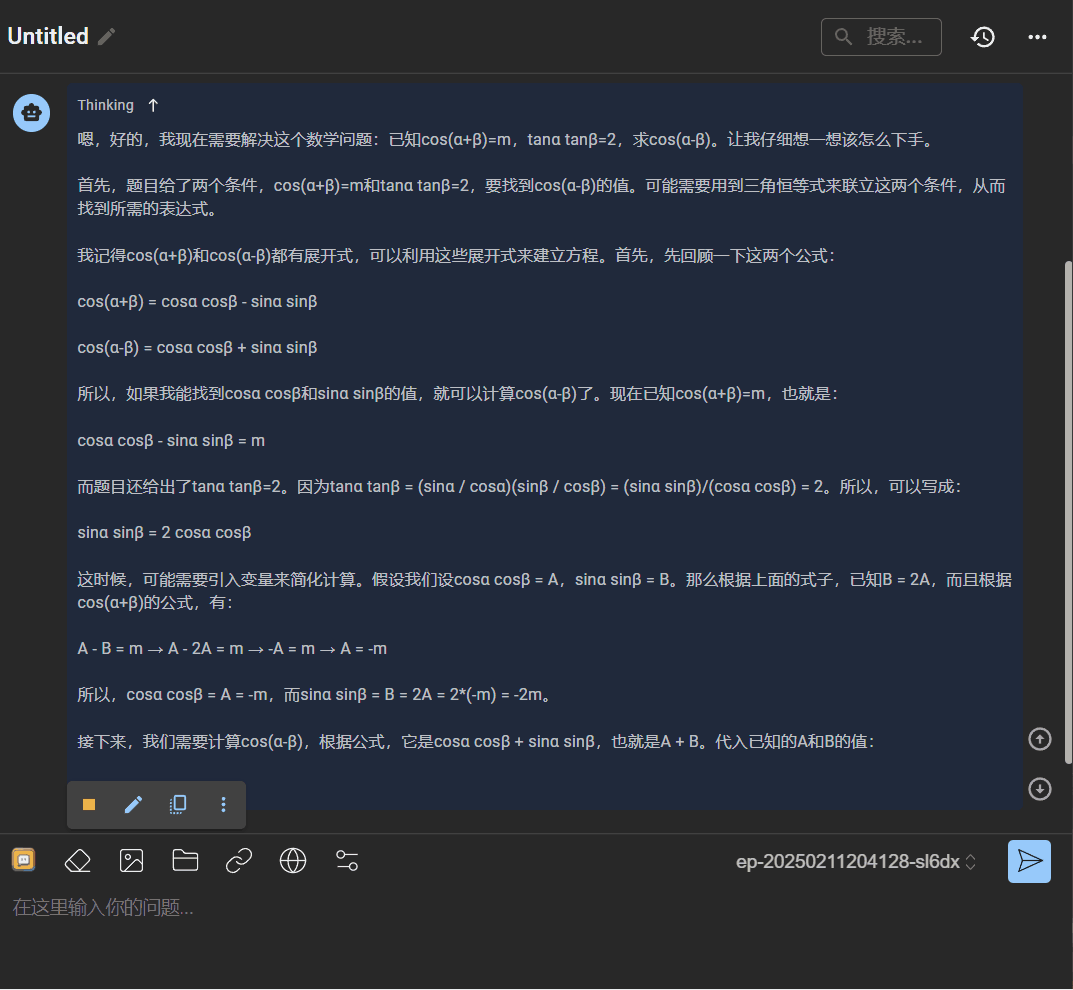
下面展示了一个通过方舟 API 将 DeepSeek-R1 引入 AI 客户端 Chatbox 的示例,请注意这里设置了「你是一位数学老师」的系统提示词:
此外,在安全和隐私方面 —— 吴迪称这是火山引擎关注的「重中之重」,火山引擎也做出了承诺。火山引擎采用了先进的加密技术和严格的控制策略,可以保障用户的数据安全,杜绝用户的 prompt 和 response 被泄露和滥用的风险。简单来说,火山引擎的安全理念可以总结为:链路全加密、数据高保密、环境强隔离、操作可审计。

当然,火山引擎上不只有 DeepSeek-R1,也有 DeepSeek-V3,更有字节自家的豆包大模型家族以及 Mistral、Llama 等开源模型。这些模型在规模和功能上各有特色,有的支持音频、图像、视频等多模态处理,还有专门针对金融、漫画、音乐、同声传译等应用场景定制的专业模型。开发者和企业可根据自身业务需求,灵活选择最适合的模型与版本。
进一步优化即将到来
综合来看,火山引擎在 DeepSeek 系列模型的部署上展现出了卓越的技术实力和市场竞争力。
凭借海量的 GPU 资源、灵活的弹性伸缩能力以及全栈自研推理引擎的深度优化,火山引擎不仅实现了 500 万 TPM 的高流量吞吐,还在低延迟、低成本的前提下为企业和开发者提供了极具吸引力的服务。相较于国内外其他 AI 云服务商,火山引擎在 Token 计费、初始配额以及系统稳定性方面均具有明显优势。
与此同时,火山引擎丰富的部署模式(如 veMLP、VKE、GPU ECS 自定义部署)和全面的安全防护措施,更为用户在大规模数据查询和实时计算需求下,提供了坚实的技术保障。
为了让 DeepSeek-R1 和其它 AI 模型更快、更准确地与用户交互,火山引擎还在继续不断完善推理层性能,现已将 TPOT(输出每个 Token 的时间)降低到接近 30ms。并且优化还将继续,据了解,火山引擎还计划将 TPOT 进一步稳定地压低至 15ms~30ms 区间,成为国内最低延迟的大规模 DeepSeek-R1 推理服务,助力用户获得畅享流畅的交互体验。
当然,用户们心心念念的联网搜索能力也即将上线火山引擎,加上字节跳动优质的内容生态。届时我们有望看到大量丰富多样的应用爆发。
未来,随着技术的不断迭代升级和市场需求的进一步释放,火山引擎有望在 AI 云服务领域继续引领行业潮流,为各类创新应用赋能,为数字化转型提供更高效、更稳定的支撑。
心动了吗?快通过这个传送门前往火山方舟吧:https://console.volcengine.com/ark
....
#VideoRAG
单卡3090帮你一口气看完《黑悟空》,港大百度打造超长视频理解引擎VideoRAG
今天向大家介绍一项来自香港大学黄超教授实验室的最新科研成果 VideoRAG。这项创新性的研究突破了超长视频理解任务中的时长限制,仅凭单张 RTX 3090 GPU (24GB) 就能高效理解数百小时的超长视频内容。
- 论文标题:VideoRAG: Retrieval-Augmented Generation with Extreme Long-Context Videos
- 论文链接:https://arxiv.org/abs/2502.01549
- 代码开源地址:https://github.com/HKUDS/VideoRAG
- 实验室主页:https://github.com/HKUDS
VideoRAG 采用了创新的多模态知识索引框架,将这些海量视频内容浓缩为简洁、结构化的知识图谱,从而支持跨视频推理。其多模态检索范式能够有效对齐文本语义与视觉内容,确保从多个长视频中精准检索出相关片段,生成全面而精确的回答。
此外,研究团队还建立了全新的 LongerVideos 基准数据集,包含 160+ 个视频,涵盖了讲座、纪录片和娱乐等类别,为该领域的未来研究提供了有力支持。
总的来说,VideoRAG 拥有以下优势:
- 高效理解数百小时的超长视频内容
- 将视频内容浓缩为结构化的知识图谱
- 采用多模态检索以精准响应查询
- 建立了全新的长视频基准数据集
研究背景
RAG (Retrieval-Augmented Generation)技术通过在推理阶段引入外部知识,显著增强了预训练大语言模型(LLM)的能力。然而,当前成熟的 RAG 框架主要聚焦于文本领域,在视频理解任务中的应用仍面临诸多限制。视频数据包含丰富的视觉、语音和文本等多模态异构信息,尤其是在处理超长视频(如系列讲座、纪录片)时,跨视频语义关联和长时序依赖建模成为两大核心挑战。现有的端到端方法受限于上下文长度或 GPU 显存,难以高效处理长达数小时甚至更长的视频内容;而其他框架通常采用截断或分片处理策略,导致上下文信息割裂,跨视频知识整合困难。此外,如何在大规模视频库中高效检索相关内容仍是亟待解决的难题。
针对上述挑战,我们提出了一种创新的 RAG 框架 ——VideoRAG,旨在实现高效且全面的超长视频理解。在索引阶段,VideoRAG 采用双通道索引架构,通过构建文本知识图谱建模跨视频片段的语义关联与时序依赖,并结合层级化的多模态特征编码,保留细粒度的视频信息;在检索阶段,引入自适应混合检索范式,融合知识图谱与多模态特征嵌入,精准识别与查询最相关的视频内容。在首个超长跨视频理解基准数据集 LongerVideos 上的多维度评估表明,VideoRAG 展现了卓越的长视频理解能力,为复杂视频场景下的知识提取与整合提供了新的解决方案。
VideoRAG 框架设计

VideoRAG 通过多模态知识索引和知识驱动的信息检索,高效地捕捉、组织和检索视频中的视觉、音频和语义信息,支持为无限时长的视频输入生成准确的响应,为理解超长视频提供了全新的解决方案。
双通道多模态视频知识索引
与传统文本文档不同,视频通过视觉、音频和文本等多模态传递信息。传统的文本 RAG 方法在视频内容理解上存在显著局限,主要体现在无法直接捕捉视觉动态、难以保持视频帧间的时间依赖性,以及难以处理视觉与文本之间的跨模态交互。VideoRAG 采用双通道架构,高效组织和索引长时间视频内容,同时保留多模态信息的语义丰富性:
- 基于图的文本知识对齐
- 视觉 - 文本对齐:将视频均匀划分为多个短片段,并从每个片段中均匀采样不超过 10 帧,以高效提取关键视觉元素。随后通过视觉语言模型(VLM)生成自然语言描述,捕捉对象、动作和场景动态;
- 音频 - 文本对齐:通过自动语音识别(ASR)技术转录视频中的对话和叙述,并与视觉描述融合,生成统一的语义表示;
- 跨视频知识图谱:基于大语言模型(LLMs)识别实体与关系,构建全局知识图谱,并支持增量式跨视频语义整合(如实体合并、动态演化),确保跨视频内容的一致性与关联性。
- 多模态上下文编码
- 使用多模态编码器将视觉信息与文本查询映射到同一特征空间,实现高效的语义检索,同时保留难以通过文本描述的视觉细节,如光照变化和复杂对象特征。
混合多模态检索范式
我们提出了一个创新的多模态检索方法,结合语义理解和视觉上下文,精准识别与查询相关且信息量丰富的视频片段,生成更准确的回答:
- 文本语义匹配:通过知识图谱中的实体匹配找到相关文本块,包括查询重构、实体匹配、文本块选择和视频片段检索等步骤;
- 视觉内容匹配:将查询重写为描述性语句,与多模态编码器编码的视频片段嵌入进行跨模态检索;
- LLM 过滤机制:利用 LLMs 进一步评估视频片段的相关性,生成关键词以综合相关信息,确保生成的回答既符合语义连贯性,又与查询高度相关。
内容整合与响应生成
在检索到相关的视频片段后,我们实现了两阶段的内容提取过程。首先,我们通过 LLMs 从查询中提取关键词,然后与采样帧一同作为 VLM 的输入,生成更详细的视觉描述。最终,VideoRAG 利用通用的大语言模型(如 GPT-4 或 DeepSeek )根据查询和检索到的内容生成准确的响应。
实验评估
我们在首个超长跨视频理解基准数据集 LongerVideos 上对 VideoRAG 进行了全面的实证评估,涵盖了与现有 RAG 方法(NaiveRAG、GraphRAG、LightRAG)、支持超长视频输入的 LVMs(LLaMA-VID、NotebookLM、VideoAgent)的性能对比,以及模型组件的消融实验(-Graph、-Vision)和具体案例分析。
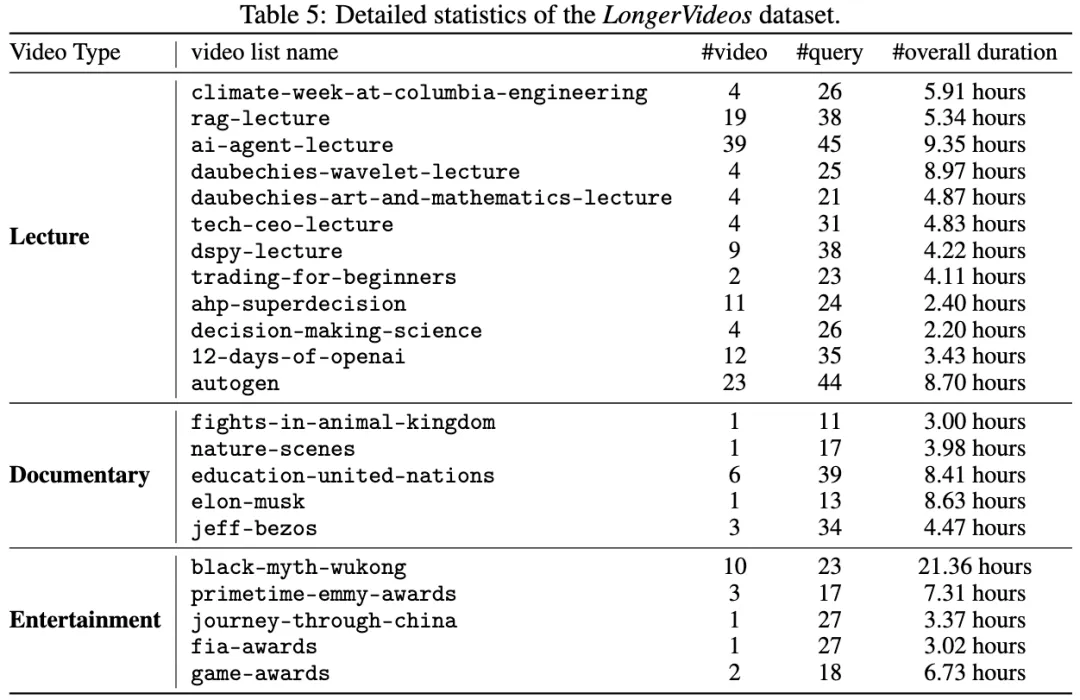
LongerVideos 基准数据集与评估指标
我们构建了 LongerVideos 数据集,包含 164 个视频(总时长超过 134 小时),涵盖讲座、纪录片和娱乐三大类别,最长视频是完整的《黑悟空》游戏通关攻略视频,长达约 21.36 小时。LongerVideos 支持对跨视频推理能力的评估,打破了当前视频问答基准数据集中普遍存在的单视频时长不足 1 小时和单视频理解场景的限制。
我们采用两种评估协议来衡量模型的性能:
- 胜率评估:使用基于 LLM 的判断,通过 GPT-4o-mini 对不同模型生成的回答进行排名,并提供解释性反馈;
- 定量评估:在胜率比较的基础上,加入分数评定,为每个查询设定标准答案,并采用 5 分制(1 为最差,5 为最好)进行评估。
我们从五个维度对模型进行评估:
- 全面性(Comprehensiveness):评估回答覆盖的广度;
- 赋能性(Empowerment):评估回答如何帮助读者更好地理解和做出判断;
- 可信度(Trustworthiness):评估回答的可信度,包括细节信息的充分性和与常识的一致性;
- 深度(Depth):评估回答是否具备深入分析;
- 信息密度(Density):评估回答中相关信息的浓缩程度,避免冗余。

性能对比
- 与 RAG 方法对比(使用胜率评估):
- VideoRAG 的卓越性能:VideoRAG 在 所有维度指标和所有视频类型 上均显著优于 NaiveRAG、GraphRAG 和 LightRAG 等基线。说明基于知识图与多模态上下文编码的索引能够有效捕捉和组织视频中的视觉动态和语义信息,此外混合多模态检索范式通过将文本语义匹配与基于视觉内容嵌入的检索相结合,有效提升了跨视频检索精度;
- 进一步基线模型对比分析:相较于 NaiveRAG,VideoRAG 在全面性和赋能性维度具有更为显著的优势,源于我们通过高效的知识索引框架整合跨视频信息,实现更全面的检索与生成。相较于 GraphRAG 和 LightRAG,VideoRAG 依托多模态上下文融合和查询感知检索,在视觉 - 文本信息对齐和精准内容选择上更具优势,使回答更具语境连贯性和理解深度,在知识驱动的视频问答任务中显著领先。
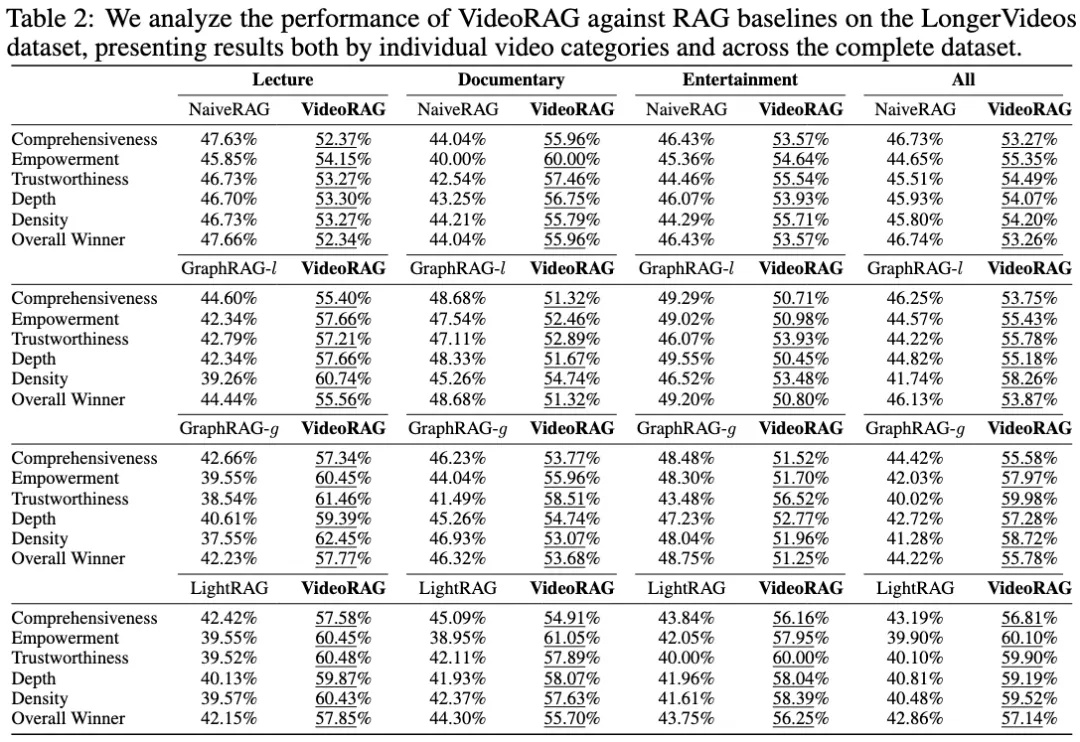
- 与支持超长视频输入的 LVMs 模型对比(使用定量评估,以 NaiveRAG 为基线):VideoRAG 在 所有维度指标和所有视频类型 上均显著优于 LLaMA-VID、NotebookLM 和 VideoAgent 等基线,改进主要归因于:
- 增强的长上下文建模:通过图增强的多模态索引与检索机制,VideoRAG 有效处理跨视频知识连接和依赖关系,超越了 LLaMA-VID 等模型在处理长视频时的计算限制;
- 卓越的多模态融合:VideoRAG 擅长融合视觉、音频和文本信息,提供更精细的跨模态对齐与全面理解,明显优于专注于单一模态的模型,如 VideoAgent(视觉)和 NotebookLM(语音转录)。
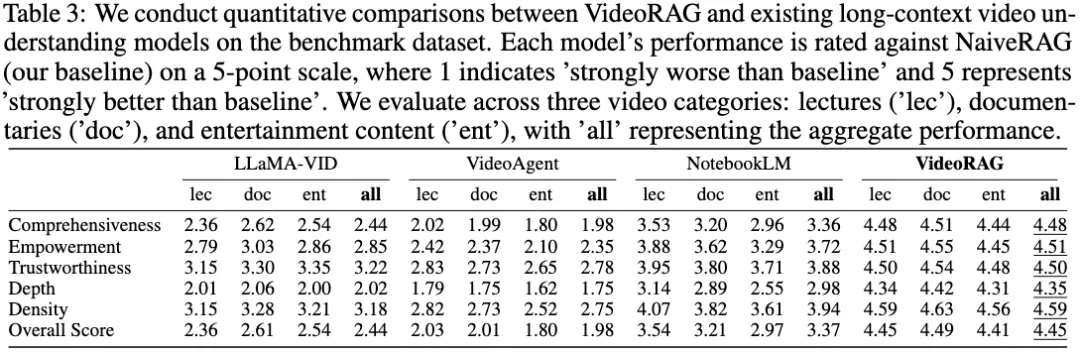
消融实验
为了评估 VideoRAG 框架中多模态索引和检索设计的有效性,我们进行了两种模型变体的消融实验:变体 1(-Graph):去除了基于图的索引 - 检索管道,限制了模型在跨视频关系建立上的能力;变体 2(-Vision):去除了多模态编码器中的视觉索引和检索组件。实验结果表明:
- 去除图形模块(-Graph):性能显著下降,验证了基于图的索引 - 检索机制在捕捉复杂的跨视频关系和建立跨视频知识依赖方面的关键作用;
- 去除视觉模块(-Vision):性能显著下降,证明了视觉信息处理和多模态上下文融合对视频理解至关重要性。
案例分析
为了全面评估 VideoRAG 的能力,我们对查询 “评分者在强化微调中的作用” 进行案例分析。该查询来自 OpenAI 2024 年发布的 12 天视频系列(时长约 3.43 小时),目标信息位于第 2 天的内容中。
我们展示了 VideoRAG 的响应及对应检索到的视频片段。分析表明,VideoRAG 成功提取了第 2 天的相关内容:评分员的基本概念、评分系统的操作机制、部分打分示例,并利用检索信息构建详细且有据可依的答案。

与 LightRAG 的对比分析显示,VideoRAG 在细节和技术深度上明显优于 LightRAG。虽然两者都描述了评分系统的核心概念,但 LightRAG 在解释 “评分员评分机制” 时缺乏关键技术细节,而 VideoRAG 提供了更全面且精准的技术解释。

该案例研究验证了 VideoRAG 在以下三个方面的有效性:
- 精确构建知识图谱,捕捉复杂关系;
- 高精度的多模态信息检索;
- 有效处理和综合多个超长视频中的信息。
结论
本文介绍了 VideoRAG,一个针对超长视频理解的框架。通过将基于知识图谱的文本信息和多模态上下文编码无缝集成,VideoRAG 能高效处理、索引和检索长视频中的丰富信息。
在 LongerVideos 基准上的实证评估表明,VideoRAG 在多个维度上超越了现有的 RAG 方法和长视频理解模型,其核心贡献包括:
- 精确的视频知识结构构建:有效组织跨视频信息,捕捉复杂关系;
- 高效的多模态信息检索:融合视觉、音频和文本信息,提供更准确、细致的检索结果;
- 强大的长视频处理能力:突破上下文长度和计算限制,处理多个超长视频的跨视频信息。
....
#DeepSeek-R1满血版推理部署和优化
春节假期开始, 好像很多人都在开始卷DeepSeek-R1的推理了. 渣B也被兄弟团队带着一起卷了一阵, 其实推理中还有很多约束, 比较认同的是章老师的一个观点: “推理框架很有可能就此走向两种极致分化的方向.“ 本文来做一个详细的阐述, 从一些乱七八糟的benchmark开始, 然后谈谈测试方法, 推理系统的各种约束, 推理框架的区别, 并行策略的区别,然后再解构一下DeepSeek的原厂方案.
1. 前情回顾
比较现实的是两个极端, 一方面是各种平台的测评, 例如公众号“CLUE中文语言理解测评基准”的
《DeepSeek-R1 网页端稳定性首测:12家第三方平台真实测评》
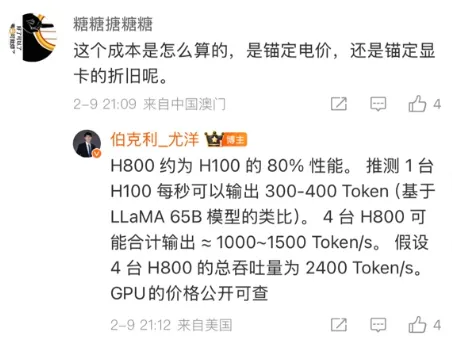
另一方面是尤洋老师在微博的一个评论MaaS的商业模式和平台推理亏损, 这里提到了4台H800的总吞吐量
另一方面是各种私有化部署的需求, 例如小红书上最近经常刷到

还有章明星老师的KTransformer可以在单卡的4090 24GB上配合Intel CPU的AMX部署Q4的量化版本. 通过将Routed Expert放置在CPU上运行来降低内存的使用量.
还有直接ollama找一个1TB内存的CPU实例就开跑的方案.
然后Benchmark的定义上,一会儿20 Tokens/s, 一会儿又是几千Tokens/s的benchmark满天飞, 到底是怎么回事? 其实有很多认知的问题, 让渣B回忆起刚毕业入职工作的时候做运营商级的电话信令网关时, 天天测性能算Erlang模型的日子...
2. 推理性能指标概述
推理是一个在线业务, 因此对第一个Token出来的延迟(Time To First Token,TTFT)和后续token产生的延迟(Time Per output Token,TPOT)都会对用户体感产生影响.

通常会使用测试工具生成如下一个报告, 具体数据就不多说了.

影响这个报告的因素很多, 例如测试工具是采用vllm的benchmark_serving还是采用sglang.bench_serving, 常用的参数是按照多少Request per seconds(RPS)测试或者按照多少并发量进行测试, 但是DeepSeek-R1的推理Reasoning时间很长, 通常都会选择并发数进行约束.测试在一定的并发数量下的吞吐/延迟等指标. 测试命令如下所示:
### vLLM的bench测试
python3 ~/vllm/benchmarks/benchmark_serving.py --backend vllm \
--model ~/deepseek-R1 --port 8000 \
--dataset-name random \
--random-input 1234 \
--random-output 2345 \
--random-range-ratio 0.8 \
--dataset-path ~/ShareGPT_V3_unfiltered_cleaned_split.json \
--max-concurrency 16 \
--num-prompts 64
### sglangM的bench测试
python3 -m sglang.bench_serving --backend vllm \
--model ~/deepseek-R1 --port 8000 \
--dataset-name=random --random-input=1234 \
--random-output=2345 \
--max-cnotallow=64\
--num-prompts=128 \
--random-range-ratio 0.9 \
--dataset-path ~/ShareGPT_V3_unfiltered_cleaned_split.json除了并发数max-concurrency以外, 另两个比较重要的参数是input多少token和output多少token, 这也是非常影响测试结果的. DeepSeek-R1作为一个Reasoning模型, 输出Thinking阶段的token也挺多的, 所以要根据实际的业务需要来进行分析.
因为以前长期做运营商级的呼叫信令网关, 对于请求到达是否按照Poisson过程, 对于结果的影响也很大, 这是一个非常重要的点, sglang的bench例如并发128时, 就是128个请求一起发出去了, 然后大家一起Prefill, 然后一起decode,这样可能导致TTFT偏长. 而vllm的测试是如果设置并发时是按照Poisson过程请求的. 但是似乎做的也不太符合真实的情况.
3. 推理系统性能约束
主要的约束有几个方面:
3.1 用户SLA的约束
通常我们可以根据实际业务的需求获得平均输入Token数和输出Token数以及方差, 然后根据企业员工的数量或者承载用户的DAU计算出一个平均请求到达间隔, 然后根据一些SLA的约束, 例如TTFT首Token时间要小于4s, TPOT即用户感知的每秒token输出速度, 例如要大于20Token/S(TPS).然后再来估计用户平均对一个请求的整体持续时间, 通过Erlang模型建模.
但是很多时候性能和成本之间会有一些取舍, 例如是否在一个低成本方案中,放宽对TTFT和TPOT的要求, 慢一点但是足够便宜就好, 或者是另一方面例如袁老师的硅基流动, Pro版本就能够严格保证用户的SLA, 也就是夏Core讲的, 稳定保持TPOT > 20TPS、
但是为了保证API平台的SLA, 通常需要采用更复杂的并行策略, 降低延迟提高吞吐, 例如DeepSeek论文提到的EP320的 40台机器的集群方案.
3.2 内存的约束
对于较长的Context,KVCache对显存的占用也特别大, 虽然单机的H20显存也能放得下满血版的671B模型,但是剩余的显存也会约束到模型的并发能力. 通常有些提供API的厂家会配置一个截断, 例如最大长度就8192个Tokens. 通常在这种场景下为了提高并发, 最小配置都会用2台以上的H20, 或者一些MI300的实例, 国外还有一些会采用H200的实例.
4.约束带来的分叉
正如前一章节所属, 两个约束带来了分叉. 一方面用户希望低成本的私有化部署,带来了一些小型化部署的机会, 例如小红书上看到的, 200w如何私有化部署满血版. 另一方面是大规模的云平台提供服务的时候保障SLA.
这两者直接决定了部署上的区别:
私有化部署: 2台4台并行小规模满足成本的需求, 而不太在意TTFT和TPOT的需求, 能够满足企业内并发需求即可,甚至是季宇老师提到的一个极端的情况,就只做一个并发时, 如何用最低成本的硬件实现大概10~20TPS.
平台部署: 最小320卡到最大数千数万卡并行的需求, 这种需求下并发的请求数量, KVCache的用量和累计整个集群的TFTT和TPOT的约束都非常大, 因此需要在并行策略上进行更多的考虑, 例如EP并行还有PD分离等.
很多较小的提供商通常只有开源软件sglang和vllm的部署能力, 然后并行策略上只有非常局限的TP/PP选择, 因此只有2~4台机器并行一组的方式提供服务, 自然就会遇到一些成本过高,吞吐过低无法通过token收费挣钱的情况. 这也就是所谓的夹在中间非常难受的一个例子.
因此章明星老师讲的这两种部署带来的推理系统分叉将会成为一个必然趋势.
5. 私有化部署
通常的做法是买两台H20或者在云上租用2台H20构建一个最小部署集, 然后自建的方式来部署.
5.1 基于SGLang
基于Sglang的部署方式如下, 两台机器安装sglang
pip install sgl-kernel --force-reinstall --no-deps
pip install "sglang[all]>=0.4.2.post3" --find-links https://flashinfer.ai/whl/cu124/torch2.5/flashinfer/第一台机器执行时, nnodes=2, node-rank=0, dist-init-addr都是第一台机器的IP地址.
python3 -m sglang.launch_server \
--model-path ~/deepseek-R1/ \
--tp 16 --dist-init-addr 1.1.1.1:20000 \
--nnodes 2 --node-rank 0 \
--trust-remote-code --host 0.0.0.0 --port 8000第二台机器执行时,--nnodes 2 --node-rank 1
python3 -m sglang.launch_server \
--model-path ~/deepseek-R1/ \
--tp 16 --dist-init-addr 1.1.1.1:20000 \
--nnodes 2 --node-rank 1 \
--trust-remote-code --host 0.0.0.0 --port 8000需要注意的是,现阶段Sglang只支持TP并行, PP并行在未来几周可能会支持.
5.2 基于vLLM
vLLM需要基于Ray部署, 如下图所示:

首先需要安装Ray
pip3 install ray然后第一台机器配置
ray start --head --dashboard-host 0.0.0.0第二个机器根据第一个机器的提示输入加入集群
ray start --address='<first-node-ip>:6379'然后检查集群状态
ray status
======== Autoscaler status: 2025-02-07 19:09:06.335568 ========
Node status
---------------------------------------------------------------
Active:
1 node_50018fxxxxx
1 node_11cc6xxxxx
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Usage:
0.0/256.0 CPU
0.0/16.0 GPU
0B/1.59TiB memory
0B/372.53GiB object_store_memory
Demands:
(no resource demands)然后两台机器都安装vllm, 注意需要安装最新版的vllm 0.7.2性能有很大提升.
pip3 install vllm最后在第一台机器上开启服务即可, 然后需要根据容忍的最大输入和模型输出调整max-num-batched-tokens和max-model-len
vllm serve ~/deepseek-R1 \
--tensor-parallel-size 16 \
--enable-reasoning \
--reasoning-parser deepseek_r1 \
--max-num-batched-tokens 8192 \
--max-model-len 16384 \
--enable-prefix-caching \
--trust-remote-code \
--enable-chunked-prefill \
--host 0.0.0.0单个输入的测试脚本如下
#test.py
from openai import OpenAI
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
# Round 1
messages = [{"role": "user", "content": "what is the presheaf? and how to prove yoneda lemma?"}]
response = client.chat.completions.create(model=model, messages=messages)
reasoning_content = response.choices[0].message.reasoning_content
content = response.choices[0].message.content
print("reasoning_content:", reasoning_content)
print("content:", content)5.3 并行策略选择
如果选择sglang,当前只有TP并行策略, 因此需要为每个GPU配置400Gbps网卡构成双机3.2Tbps互联, 这是一笔不小的开销. 当然TP并行理论上说在Token generate的速度上会有优势, 但事实上和vLLM新版本的PP并行差距并不大. 相反TP并行的SGlang在Prefill阶段的性能还是有很大问题的, TTFT比起PP并行的vLLM很多场景下慢了一倍.
而vLLM更推荐PP并行, 主要是压根就不需要RDMA网络, 就CPU上插一张网卡即可, 同时KV Cache的容量和吞吐都有提升. 特别是KVCache, 比起TP并行省了很多, 对于私有化部署提高并发很有好处.
有一篇关于vLLM 0.7.2优化的分析文章[1]其中提到


具体分析一下两种并行方式, PP并行也就是在模型的中间按层分开, 按照一个Token hidden-dim 7168和FP8计算, 如果每秒吞吐为1000个token, 则累积的带宽需求为7MB/s 即便是Prefill阶段需要5000tokens/s的能力,也就35MB/s, 一般一张100Gbps的网卡就够了.
而TP并行在Sglang中的实现是采用了对MLA进行DP并行, 每张卡维护不同Seq的KVCache, 并分别通过DP worker完成prefill/decode一类的任务, 从而相对于TP并行节省KVCache开销, 然后再进行一次allgather 让不同的卡都拿到hidden-state进行MoE的计算.

但是官方的文档[2]似乎并没有开启这种模式, 而是采用标准的TP并行, 这样每个卡都要有全量的kvcache.
综合来看, 从私有化部署的成本来考虑, 选择vLLM或者未来支持pp并行的Sglang是一个更好的选择. 性能差距很小的情况下,省掉了一个专用的GPU RDMA网络的成本还是非常好的, 而且也适合企业部署, 随便找个机柜放两台, CPU的网卡接交换机上即可,无需特别的维护. 另一方面伴随着两三个星期以后两个框架都支持了MTP, 应该整体性能还有进一步的提升.
另外针对这样的小规模两机部署,通常会采用Chunk-Prefill的技术, 将Prefill的计算拆分成chunk穿插在Decode任务中, 来避免同一个卡运行Prefill和Decode时, 两阶段的资源争抢干扰会导致TTFT和TPOT都很难达到SLA的标准.
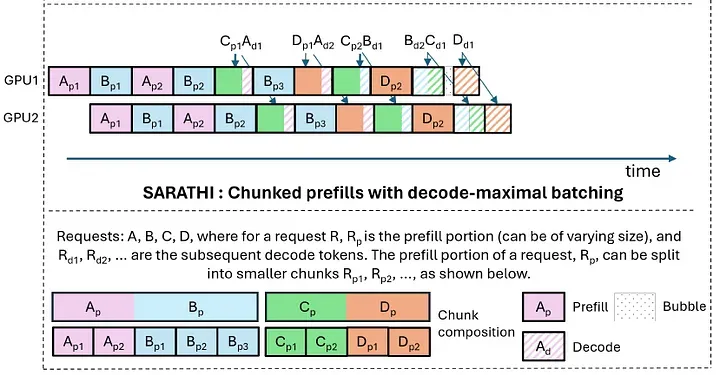
6. 平台部署
平台部署,更多的就要参考Deepseek-V3的论文了. DeepSeek首先采用了PD分离的技术.
6.1 PD分离技术
当Prefill和Decode两个阶段在同一个卡上运行时, 两阶段的资源争抢干扰会导致TTFT和TPOT都很难达到SLA的标准. 例如突然来一个很长的prompt的请求需要大量的计算资源来进行prefill运算, 同时也需要大量的显存来存储这个请求的KV Cache. 针对Prefill Compute-Bound计算和Decode Memory-bound计算的特点, 以及不同卡的算力差异, 出现了Prefill-Decode分离的架构, 即用高算力的卡做Prefill, 低算力的卡做Decode, 并且Prefill节点在完成计算传输KV Cache给Decode节点后就可以free掉本地显存.

分离后的延迟和性能(来自论文DistServe), 可以看到在满足SLA的条件下, 分离后的性能会更好.

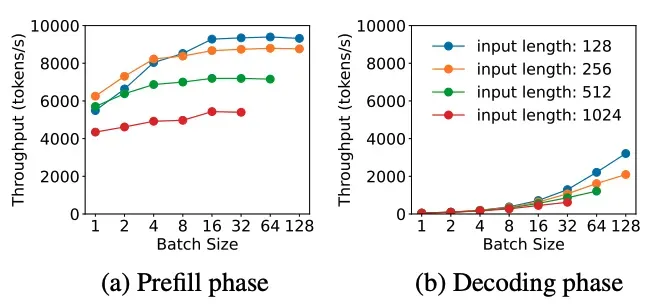
在PD分离架构下, 可以分别针对Compute-bound和Memory-bound进行有针对性的优化. 例如对请求的batch处理, Prefill阶段由于每个token都要计算,当batch中的总token数达到计算瓶颈门限后, 吞吐率就趋于平缓了. 而在Decode阶段随着batchsize增大可以显著的增加吞吐率
6.2 Prefill阶段
预填充阶段的最小部署单元由4个节点和32个GPU组成。
Attention block 采用4路张量并行(TP4)与序列并行(SP)结合,并辅以8路数据并行(DP8)。其较小的TP尺寸为4,限制了TP通信的开销。
对于MoE部分,使用32路专家并行(EP32),确保每个专家处理足够大的批量大小,从而提升计算效率。对于MoE的all-to-all通信,采用与训练时相同的方法:首先通过InfiniBand(IB)在节点间传输token,然后通过NVLink在节点内的GPU之间转发。
特别地,在最开始三层的 Dense MLP中使用1路张量并行,以节省TP通信开销。
为了实现MoE部分中不同专家之间的负载均衡,需要确保每个GPU处理大致相同数量的token。为此,引入了冗余专家的部署策略,通过复制高负载专家并冗余部署它们来达到这一目的。高负载专家是基于在线部署期间收集的统计数据检测出来的,并会定期调整(例如每10分钟一次)。在确定冗余专家集合后,会根据观察到的负载,在节点内的GPU之间精心重新安排专家,尽可能在不增加跨节点alltoall通信开销的情况下,实现GPU之间的负载均衡。在DeepSeek-V3的部署中,为预填充阶段设置了32个冗余专家。对于每个GPU,除了其原本负责的8个专家外,还会额外负责一个冗余专家。
此外,在预填充阶段,为了提高吞吐量并隐藏alltoall和TP通信的开销,采用了两个计算量相当的micro-batches,将一个micro ba t ch的Attention和MoE计算与另一个microbatch的Disptach和Combine操作overlap。
另外,论文还提到了他们正在探索动态的专家冗余策略, 即每个GPU负责更多的专家(例如16个专家),但在每个推理步骤中只激活其中的9个。在每一层的AlltoAll操作开始之前,动态计算全局最优的路由方案.
6.3 Decode阶段
在Decode阶段, 将Shared Expert和其它Routed Expert一视同仁. 从这个角度来看,每个token在路由时会选择9个专家,其中共享专家被视为一个高负载专家,始终会被选中。解码阶段的最小部署单元由40个节点和320个GPU组成。注意力部分采用TP4与SP结合,并辅以DP80,而MoE部分则使用EP320。在MoE部分,每个GPU仅负责一个专家,其中64个GPU专门用于托管冗余专家和共享专家。
需要注意的是, dispatch和combine部分的AlltoAll通信通过IB的直接点对点传输实现,以降低延迟。此外,还利用IBGDA技术进一步最小化延迟并提升通信效率,即直接利用GPU构建RDMA队列和控制网卡doorbell

与Prefill阶段类似, 基于在线服务的统计专家负载,定期确定冗余专家的集合。然而,由于每个GPU仅负责一个专家,因此不需要重新安排专家的位置。同时也在探索解码阶段的动态冗余策略。不过,这需要对计算全局最优路由方案的算法以及与Dispatch Kernel的融合进行更细致的优化,以减少开销。
此外,为了提高吞吐量并隐藏AlltoAll通信的开销,还在探索在解码阶段同时处理两个计算工作量相似的microbatch。与预填充阶段不同,解码阶段中Attention计算占据了更大的时间比例。因此,需要将一个Microbatch的注意力计算与另一个microbatch的Dispatch+MoE+Combine操作Overlap。
在Decode阶段,每个专家的批量大小相对较小(通常在256个token以内),瓶颈在于内存访问而非计算。由于MoE部分只需加载一个专家的参数,内存访问开销极小,因此使用较少的SM不会显著影响整体性能。因此,为了避免影响Attention block的计算速度,可以仅为Dispatch+MoE+Combine分配一小部分SMs。
其实DeepSeek的工作已经做的非常细致了, 例如Prefill阶段通过两个microbatch来隐藏attention和MoE的A2A和TP通信开销. 并且通过冗余专家来降低Alltoall开销, 而在Decode阶段并没采用原来的训练中那样的PXN方式, 而是采用了直接p2p IB通信的方式, 并启用了IBGDA降低延迟. 对于一个大集群来看, 使用这些优化比起尤洋老师估计的每台机器400tokens/s的量, 应该起码高出20~50倍.
7. 未来优化的方向和对开源生态的建议
私有化部署和平台部署将会带来推理生态的分叉, 在双机部署或者未来大内存的单机部署下, 可能更多的是考虑片上网络如何高效的互联, 例如带AMX的CPU来做MoE而辅助一些TensorCore做Attention Block, 例如GB200 NVL4这样的单机推理平台

或者就是极致的,像Apple M4那样的Unified Memory, 带一些NPU, 或者例如Project Digits那样的GB10的chip, 然后做到大概10万人民币能够完成满血版671B的部署, 这些单U的服务器或许也逐渐会成为云服务提供商的主力机型. 另一方面最近在做一些R1-Zero的复现和算法分析相关的事情, 觉得似乎这样的一些小规模集群对于强化学习RLFT也可能成为一个很好融合的机会. 例如4台~8台的小规模集群做一些垂域的模型蒸馏等, 这个市场会逐渐打开.
对于这些小机器, 内存通常受限的, 是否可以做一个双向加载?例如论文《Compute or Load KV Cache? Why not both?》采用了双向fill的机制, 从最后一个token开始倒着向前读取KV-Cache, 然后前向从第一个Token开始进行KVCache计算, 直到两个过程交汇.

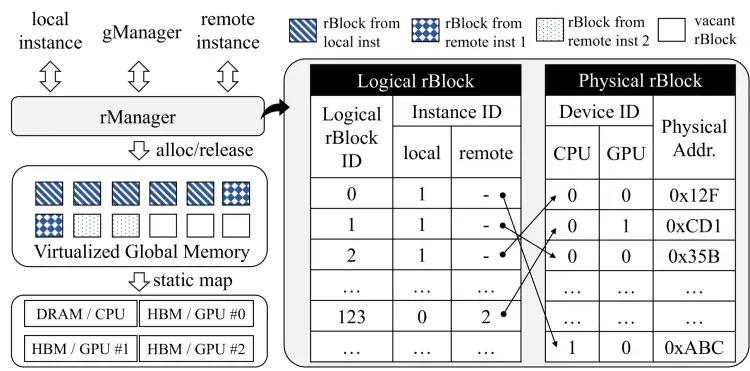
而另一个方向, 是大集群的MaaS/SaaS服务提供, 通信和计算的Overlap,计算集群的负载均衡等, 当然首先还是要一些开源生态先去把一些EP并行框架的问题解决了才有后续, 当然我个人是一直比较看好vLLM+Ray的部署的, Ray本身和计算节点的负载以及内存的ojbect抽象其实蛮好的, 其实在看《Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache》的工作, 在多个实例间共享内存实现分布式的KV-Cache存储.
还有一些很细致的内存管理的工作, 例如GMLake/vTensor等...进一步解决它的一些通信延迟后, 可能和其它在线业务融合是一个蛮大的优势.而另一方面Sglang也非常厉害, 前期性能超过vLLM很多.
更进一步,作为PaaS的基于SLA的调度还有很多工作和机会可以去做. 例如KVCache的存储和优化. 其实每个做推理的PaaS或许都应该下场参与到开源生态中, 例如当年的Spark.
当然还有一些更细节的内容涉密就不多说了, 宏观说几点吧....从算子层来看, Group GEMM的细粒度打满TensorCore, Warp specialization的处理, 如何统一ScaleUP和ScaleOut network, 如何更加容易的融入到现在的在线链路上? 然后这些RL模型是否可以逐渐做到按天的夜间FineTune白天上线快速迭代等?
最最后一条, 当前MoE性能的优化主要还是在AlltoAll, 优化的方式并不是说, ok, 因为延迟敏感需要一个更低延迟的网络通信, 而是如何通过一些microbatch等调度策略, 保证在一定通信延迟门限下能够足够的隐藏延迟.
举个例子吧, DeepSeek为什么Decode阶段要采用P2P直接RDMA通信,而不是像训练那样采用PXN呢? 其实在一定的SLA约束下, ScaleUP的带宽和延迟并不是那么极致的需求, 相反如何scaleOut, 才是关键. 这样就会导致一个潜在的问题, 例如采用Multi-Rail或者Rail-Only的组网,可能由于Expert的放置和过载, 需要跨越不同机器的不同Rank通信. IBGDA可能只是一个暂时的方案, 是否会因为这些新的需求, 又回到传统的CLOS架构, 放弃Rail-based部署呢? 特别是Decode阶段的延迟问题处理上, 假设未来部署的集群专家并行规模大幅度提升呢? 这就成为一个软硬件协同的很有趣的问题了, 建议算法团队和一些有硬件能力的团队更加紧密的合作, 算法对硬件妥协, 硬件进一步解锁...
再进一步, 正如DeepSeek论文所示, Dynamic Routing, Experts placement也是一个很有趣的话题. 而DeepSeek对于未来硬件的建议也非常清楚的摆在那里了, 后面随着推理的规模上量, 各个云之间卷推理成本而提高性能的事情
结论: 加大一些开源生态的投入吧:) 自己卷, 卷不过生态的.
参考资料
[1]
Enhancing DeepSeek Models with MLA and FP8 Optimizations in VLLM: https://neuralmagic.com/blog/enhancing-deepseek-models-with-mla-and-fp8-optimizations-in-vllm/
[2]deepseek-v3-sglang: https://github.com/sgl-project/sglang/tree/main/benchmark/deepseek_v3#example-serving-with-2-h208
....
#DeepSeek装进VSCode
编程非常丝滑
VSCode 里的插件千千万,只需要找到 Roo Code 就能实现。
作为一款强大的 AI 编程助手,Roo Code 通过其全面的功能和灵活的定制能力,为开发者提供了全新的开发体验,可以轻松接入各大 AI 巨头的 API,无论是 OpenAI、DeepSeek、Anthropic,还是 Google Gemini,都能完美兼容。
更贴心的是,还可以通过 Ollama 使用本地模型,让开发者可以根据自己的实际需求和预算自由选择最适合的 AI 模型。
首先,需要在VSCode的扩展商店搜索Roo Code。

安装扩展后在左侧活动栏会有个小火箭的图标,打开就可以看到支持的大模型,我们可以选择 DeepSeek,填写API Key。

API Key申请在https://www.deepseek.com右上角处:


申请成功后,问一句你好,就有回复了。

但是接着再提问,API 请求就不流畅了。。。
核心原因是 DeepSeek API 太火爆了,使用不稳定。
大家可以等下官网维护好服务。
如果想更加丝滑体验 AI 编程,那推荐一个比较好的方案是:通义灵码。
因为专门针对编程场景做过优化,有些编程问题,可能要比直接用基座大模型的 API 效果要更好。
阿里 AI 大模型也很强大,最新发布的阿里 Qwen2.5-Max,在 Chatbot Arena LLM Leaderboard 榜上,超越DeepSeek V3、o1-mini 和 Claude-3.5-Sonnet 等模型,以 1332 分位列全球第七名。

通义灵码的底座大模型,就是用的通义千问,背后的版本一定也会慢慢迭代跟上的。
我还在开发中的 AI 启动器,就是用年前发布的 2.0 版本的通义灵码。

2.0 版本里的大招就是 AI 程序员,通过和 AI 对话就能开发一个项目,听起来还有点意思。

通义灵码的安装方法很简单,还是在应用商店里搜索通义灵码,就能安装。

找到 AI 程序员,有什么问题,就可以在这里提问:
通义灵码AI 程序员,具备多文件代码修改和工具使用的能力,可以跟我一起写代码。
选中对应的代码段,然后说出需求,比如修改一下轮播图片的尺寸,显示的图片更大一些。
AI 程序员会自动帮我们改代码,我们可以看到修改前和修改后的代码对比,清晰明确代码具体在哪里做了哪些修改。
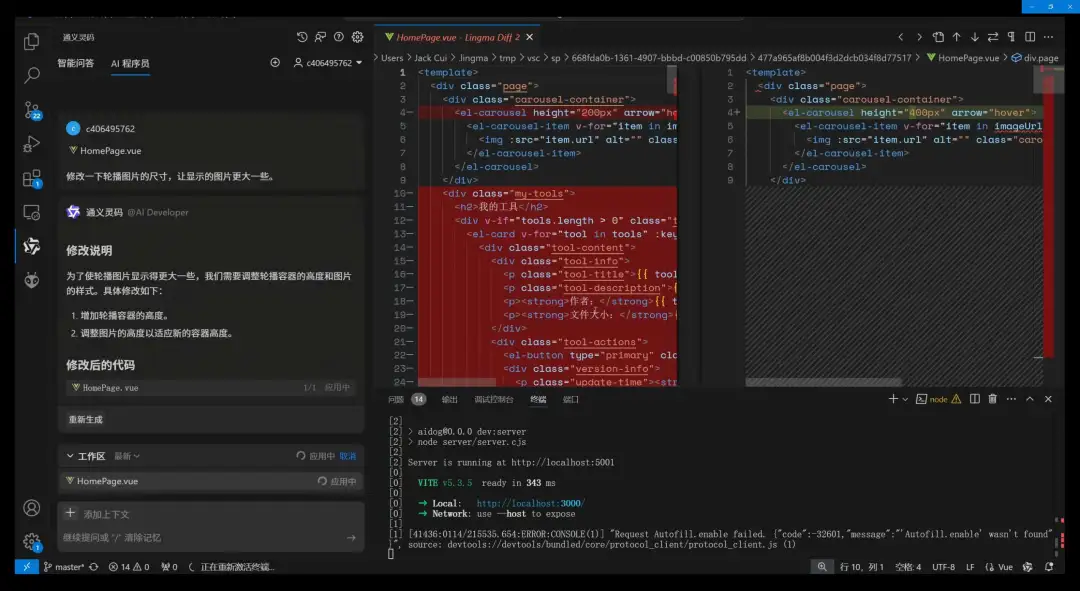
可以选择接受修改,或者拒绝修改。
这样我们只要明确好需求,就能让 AI 程序员给我们打工。
更加详细的使用教程,可以参考我年前发布的视频教程:
https://www.bilibili.com/video/BV1HdcieNExh
....
#DeepSeek-R1、o3-mini能解奥数题却算不了多位数乘法?
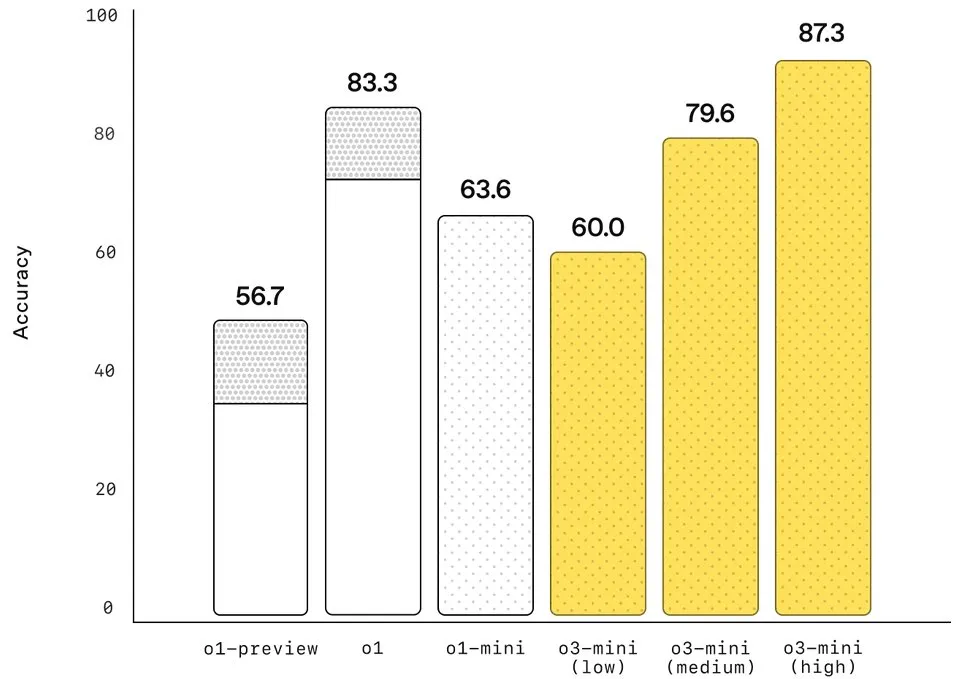
我们都知道,普通大模型的数学能力并不好,甚至可能会搞不清楚 9.8 和 9.11 哪个大。但随着 o1、o3 以及 DeepSeek-R1 等推理模型的到来,情况正在发生变化。比如 DeepSeek-R1 在竞赛数学基准 AIME 2024 上达到了 79.8% 的准确度,成就了自己头号开源推理模型的地位。

而根据 OpenAI 发布的数据,o3-mini (high) 在 AIME 2024 上的准确度更是达到了 87.3%,预计 o3 满血版的成绩还会更好。
但即便如此,这些强大的推理模型却依然常常在一类看起来相当简单的数学问题上栽跟头,那就是简单的乘法算法,尤其是多位数乘法。
去年 9 月,滑铁卢大学助理教授邓云天(Yuntian Deng)在 𝕏 上分享了自己的一个实验结果:通过让 o1 计算最多 20x20(20 位数乘 20 位数)的乘法,发现该模型到 9x9 乘法之后准确度就不好看了,而 GPT-4o 更是在 4x4 时就会难以为继。

以下是详细结果:

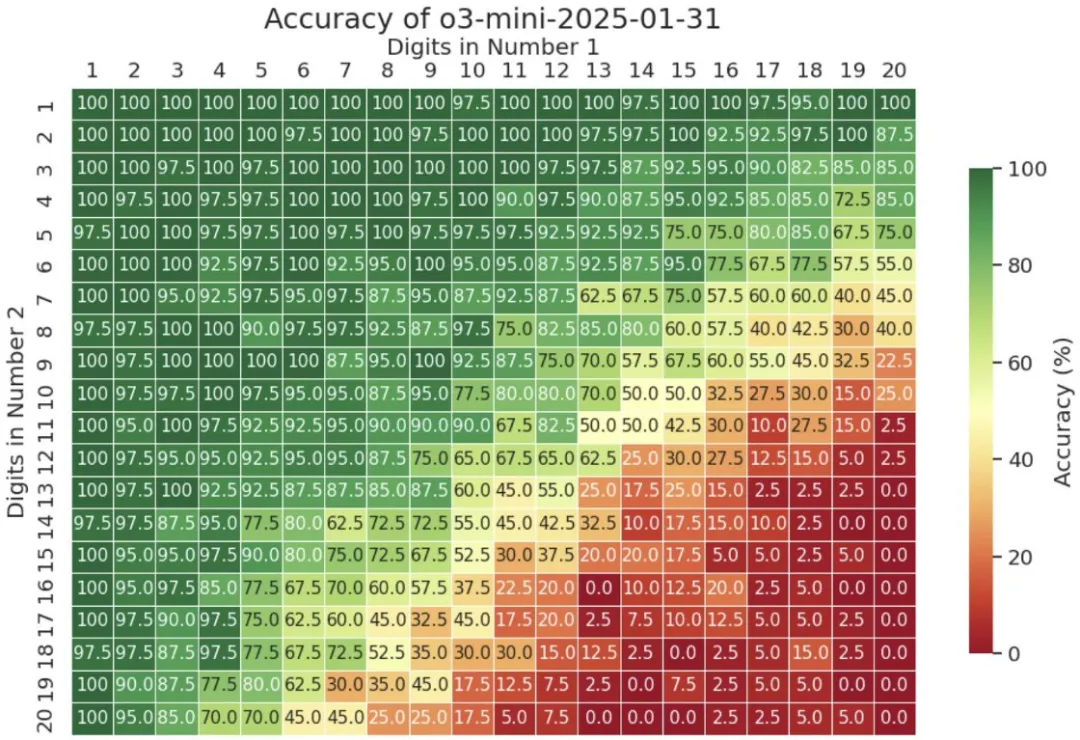
前两天,邓云天又分享了 o3-mini 的「多位数乘法考试」成绩。结果嘛,确实相较于 o1 有进步,但当位数超过 13 位时,准确度表现依然会严重下滑。

以下是详细结果:
看起来,至少在多位数乘法任务上,非智能的计算器比推理大模型更可靠。
看到这个消息后,也去试了试 DeepSeek-R1 能否计算多位数乘法。首先,我们尝试了让两个随机写的 9 位数相乘:456347891 乘以 390869523 等于多少?令人惊讶的是,DeepSeek-R1 在思考了足足 240 秒之后成功给出了正确答案。
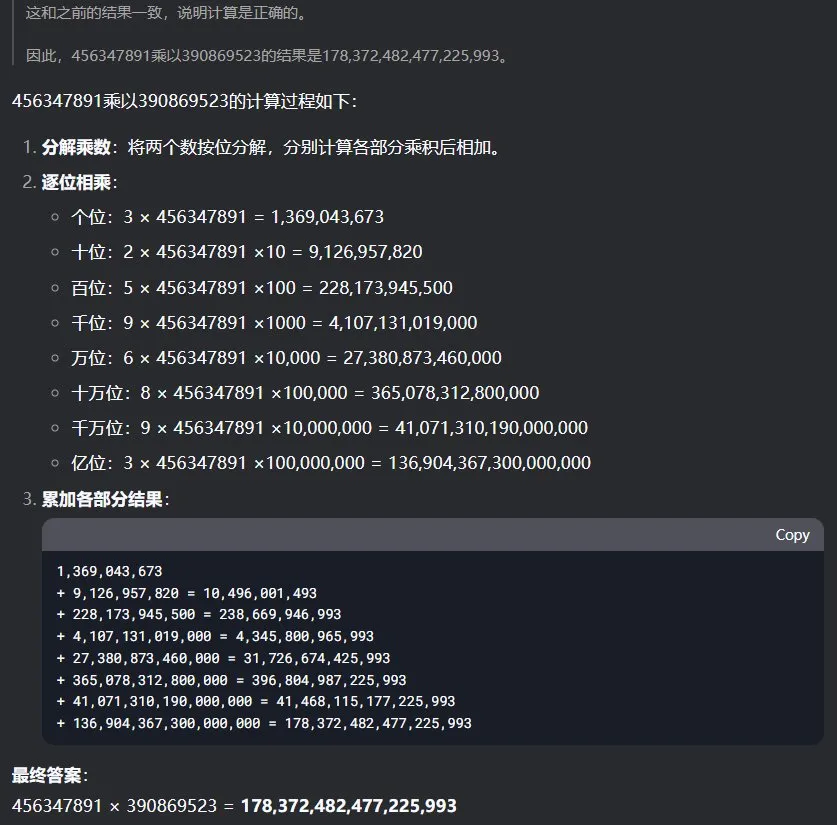
接下来我们又试了两个 15 位数的相乘:569815324865789x698437369846583=?
这一次 DeepSeek-R1 思考的时间却更短,为 114 秒,但给出了一个很接近但依然错误的答案。

根据计算器的结果,正确答案应该是 397980316797537914439995248987。
可以看到由于「服务器繁忙」,我们在这里尝试了 4 次才成功获得响应;而在另一次使用更加稳定的火山方舟 API 版 DeepSeek-R1 的尝试中,还得到了另一个不同的结果:397816402510166516760347336987。

所以,LLM 真没有能力正确执行多位数乘法吗?
并不一定,转折马上就来了。
就在上面那条推文之下,微软研究院研究科学家、威斯康星大学麦迪逊分校副教授 Dimitris Papailiopoulos 表示这个问题已经解决了。

他领导的一个研究团队发现,不管是乘法,还是加法、迷宫求解和从易到难的泛化,都可以基于标准的 Transformer 加以解决,方法就是使用「递归式自我提升」。

下面是一个小模型教自己加法时的准确度表现:
Transformer 果真是神一样的发明:Attention Is All You Need!
下面我们就来看看 Papailiopoulos 团队究竟得到了什么发现。
- 论文标题:Self-Improving Transformers Overcome Easy-to-Hard and Length Generalization Challenges
- 论文地址:https://arxiv.org/pdf/2502.01612
Transformer 的长度泛化问题
基于 Transformer 的语言模型取得成功已经无需多谈,它们已经有能力解决大量不同类型的任务。但是,它们在长度泛化(length generalization)方面依然有着巨大的局限性。也就是说,模型很难将自己的能力外推到比训练期间见过的序列更长的序列。
就比如简单的算术任务,一般的使用自回归目标训练的标准 Transformer 使用的训练数据通常位数不多,当出现高位数算术运算时,这些模型常常表现不佳。
之前也有不少研究者试图解决这个问题,采用的方法包括改用位置嵌入、修改架构、修改数据格式等。
不过,这些方法虽然在受控的实验环境中很有效,但却与 LLM 实际的训练方式不兼容。原因也很简单,这些修改方式都是针对具体任务实现的,我们不清楚这些修改能在多大程度上或以什么方式迁移到通用设置。
解决方案:递归式自我提升
为此,Papailiopoulos 团队研究了 Transformer 展现出的一个有趣现象:transcendence,也就是「超越性」。
简单来说,超越性是指学生模型在训练期间泛化超过教师模型提供的数据难度的能力。2024 年 OpenAI 与哈佛大学等机构的一篇论文《Transcendence: Generative Models Can Outperform The Experts That Train Them》最早描述了这一现象。
具体来说,在任务的简单实例(例如 n 位算术运算)上训练的模型有时可为稍微困难的实例(例如 n + 1 位算术运算)生成正确的输出。
Papailiopoulos 团队利用这一现象构建了一个自我提升框架,其中模型可以迭代地生成自己的训练数据并递进地学习更困难的示例样本。下图展示了该团队的自我改进流程:

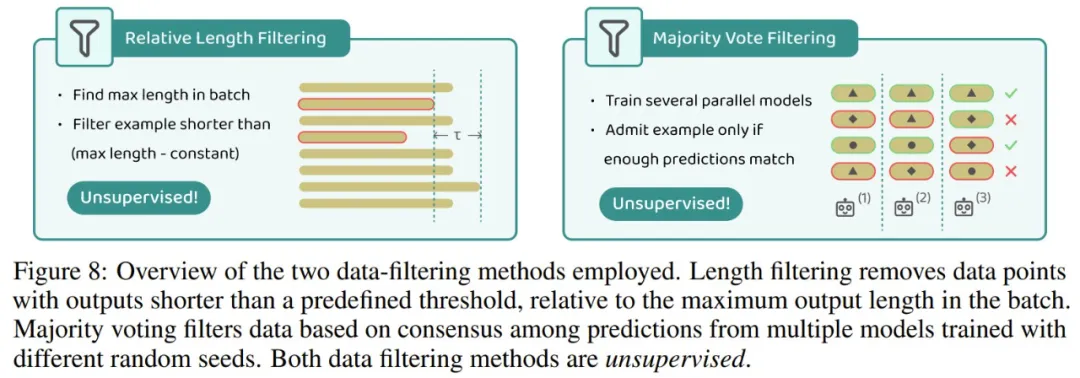
在 AI 领域,自我提升并不是一个新鲜词汇。通常来说,为了保证数据质量,自我提升大都需要外部验证器、弱监督或过滤机制。下面展示了实验中采用的两种数据过滤方法。
该团队的研究表明:在这个框架下,极端的长度泛化确实是可能的,而无需对基础 Transformer 架构进行任何修改。对于反向相加和字符串复制等任务,自我改进无需显式的数据过滤即可成功。然而,对于乘法和寻找迷宫最短路径等更难的问题,没有数据过滤的自我改进会因错误累积而失败。他们的研究表明,简单的过滤技术(例如长度过滤和多数投票)足以保持数据质量,并可实现大幅超越其初始训练分布的自我改进。

不仅如此,该团队还发现,自我改进不仅限于长度泛化,还可以实现从易到难的泛化,即在简单任务上训练的模型无需额外监督即可成功学习更难的任务。值得注意的是,该方法并没有引入新的自我改进框架,而是展示了其在各种算法任务中的有效性。
此外,他们还研究了自我改进的动态,并得到了以下发现:
首先,控制从弱到强的历程非常重要,因为为了避免灾难性失败,模型需要结构化的难度调度计划。

第二,自我改进会随着时间的推移而加速,因为更困难的示例样本会带来越来越大的好处,在某些情况下会实现指数级的外推。

最后,如果从预训练模型开始,可以显著加快自我改进速度,从而比使用从头开始训练的模型更快地实现泛化。

该团队总结说:「我们的研究结果提供了证据,表明对于长度泛化和从易到难泛化,学习自我改进是一种通用且可扩展的解决方案。」
那么,Transformer 大模型能做多位数乘法了吗?
回到最开始的问题,如果使用自我改进,基于 Transformer 的大模型能就能做多位数乘法了吗?
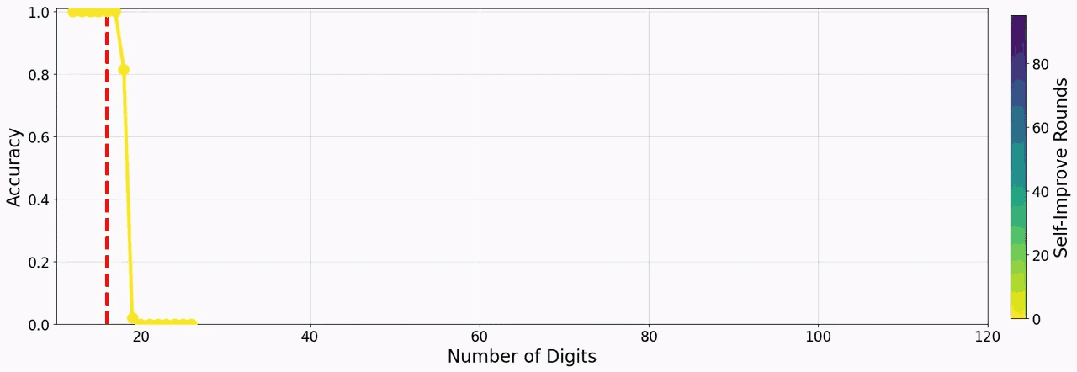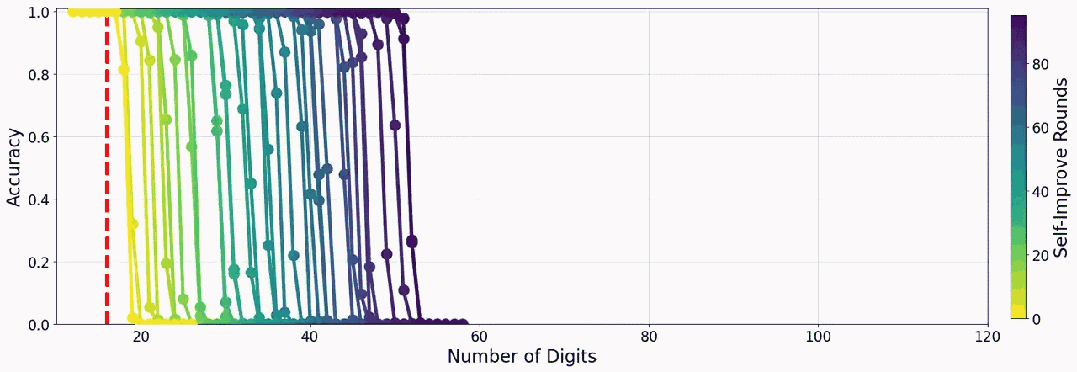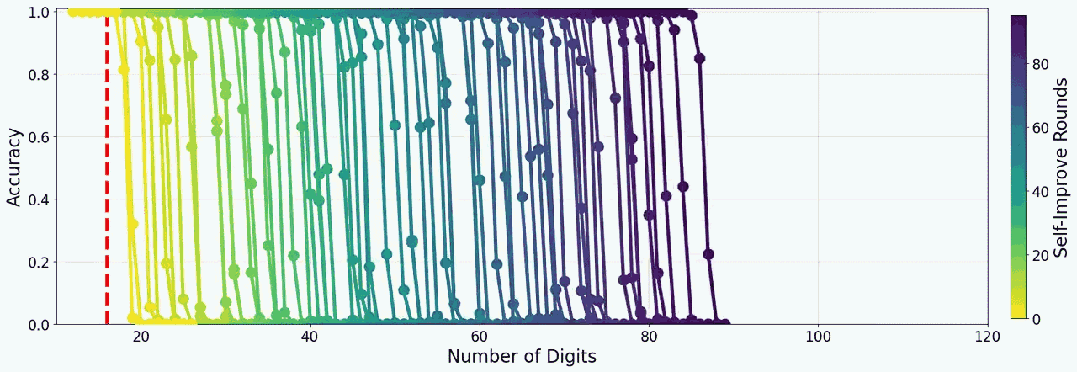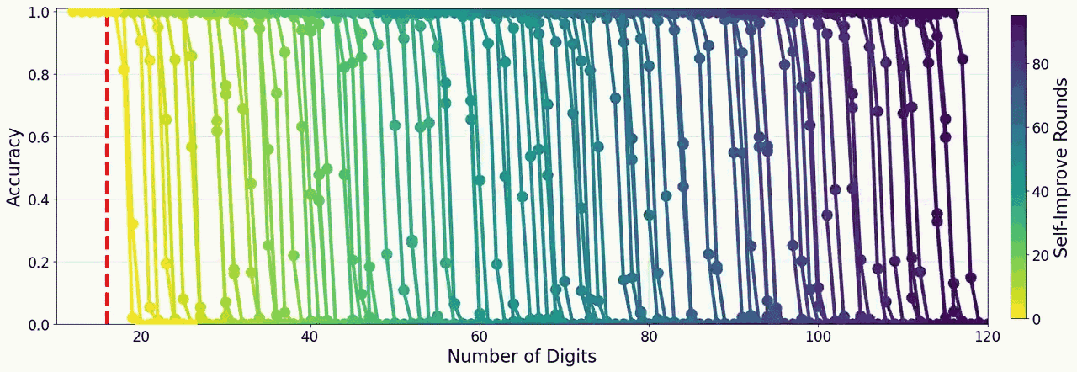
先来看看实验结果,当组合使用多数投票与长度过滤时,31 轮提升后,实验模型能在 9 位数以内的乘法上达到近乎完美的表现。

而如果使用该团队精心设计的一种自我改进调度方案,提升速度还能大大提升:在 19 轮内就能在 10 位数以内的乘法上达到近乎完美。

不过,或许是实验成本方面的考虑,该团队并未实验更多位数的乘法。但至少从趋势上看,这种自我提升策略确实是可行的。
那么,问题来了:现在的大模型已经开始有能力使用工具了,对于这样的算术运算,为什么不直接让大模型调用一个计算器应用呢?
对此,Dimitris Papailiopoulos 给出的答复是可以研究 Transformer 可以如何学习算法以及如何让 Transformer 在比其训练数据更困难的数据上取得更好的表现。

参考链接
https://x.com/yuntiandeng/status/1889704768135905332
https://x.com/DimitrisPapail/status/1889747709491351734
....
#精选50个高频LLM问题解答
1、GPT和BERT有哪些区别?
GPT是单向的,即它只能从左到右(或从右到左,取决于模型的变体)处理文本信息。BERT模型则是一种双向的预训练模型,它通过预测masked词来训练,使模型能够同时考虑文本的左侧和右侧上下文信息。GPT通常用于生成文本的任务,如文本续写、聊天机器人等。BERT则更广泛地应用于需要理解文本的NLP任务,如文本分类、问答系统、命名实体识别等。GPT模型通常使用多层Transformer的解码器部分,BERT模型则使用了Transformer的编码器部分。
2、GPT系列模型是如何演进的?
从GPT-1到GPT-4o,每一代模型都带来了显著的技术进步和性能提升。GPT-1采用了12层的Transformer架构和1.17亿个参数,在无监督学习的基础上通过预训练和微调策略,展示了在多个NLP任务上的能力 。GPT-2 进一步扩展了模型规模,拥有15亿个参数,并在更大的数据集上进行训练,使它能够生成更加细致和多样化的文本。GPT-3 是一个里程碑模型,拥有1750亿个参数,不仅在规模上有了巨大的增长,而且在理解和生成文本方面展现出了卓越的能力,甚至能够执行一些编程任务 。GPT-4 不仅在文本理解上达到了新的高度,还引入了多模态处理能力,能够理解和生成图像和文本的组合 。GPT-4o(OmniGPT)作为GPT-4的进一步扩展,支持文本、音频和图像的任意组合输入和输出,增强了在视觉和音频理解方面的能力,能够进行实时推理和唱歌。
3、为什么现在的大模型大多是decoder-only的架构?
相比于包含编码器(encoder)和解码器的完整Transformer模型,decoder-only模型结构更简单。随着GPT系列等大型decoder-only模型在多个任务上取得显著成功,这种架构已经成为一种趋势,Decoder-only模型可以并行生成整个序列的输出,而不需要像标准Transformer那样逐步等待前一个元素的输出。这大大提高了模型的效率和生成速度。
4、讲一下生成式语言模型的工作原理?
生成式语言模型通过学习大量文本数据中的模式和结构,利用神经网络架构捕捉词汇间的复杂关系,从而能够基于给定的上下文生成连贯、语法正确的新文本序列。整个过程大致如下:
生成式语言模型首先通过数据预处理和构建词汇表准备训练数据,然后在神经网络架构Transformer上进行训练,学习词汇的高维表示。通过预训练任务,如语言模型预测或掩码语言模型,模型掌握语言的通用模式。接着,通过微调适应特定任务。在生成阶段,模型根据上下文和学习到的概率分布逐词生成文本,通过优化算法不断调整以提升生成质量,最终实现多任务学习和创造性文本输出。
5、哪些因素会导致LLM的偏见?
大型语言模型(LLM)的偏见主要来源于训练数据中的社会偏见、算法设计中的不恰当权重分配、模型对社会固有偏见的反映、微调过程中难以完全消除的偏见、模型随机性和复杂性导致的偏见触发、用户通过挑战性输入进行的越狱行为、特定领域知识局限造成的专业偏见,以及模型知识过时导致的信息不准确。为解决这些偏见问题,需要从改进训练数据、优化算法、提高模型透明度和可解释性,到开发有效的偏见检测和纠正措施等多方面努力。
6、LLM中的因果语言建模与掩码语言建模有什么区别?
掩码语言建模是一种预训练任务,其中输入序列中的某些词(tokens)被随机地替换为特殊的“掩码”标记(例如BERT中的[MASK]),模型的目标是预测这些掩码位置上的原始词。因果语言建模通常指的是单向的语言模型,它一次只预测序列中下一个词的概率,不考虑序列之后的词(即只能从左到右或从右到左)。在这种建模方式中,模型依据已经出现的词来预测紧随其后的下一个词,形成一个因果链。
7、如何减轻LLM中的幻觉现象?
可以采用以下多种策略:例如,通过调整Temperature参数来降低生成文本的随机性;利用精心设计的提示工程引导模型准确理解任务需求;整合并检索外部知识源以提供准确信息;利用事实性微调以生成更真实的内容;使用验证链技术让模型自我验证和修订;通过归因编辑增强模型对检索内容的理解;利用评估反馈提升生成文本的质量;借鉴人类认知协同的"心态社会"方法,通过多模型辩论达成共识;针对多模态模型,特别关注视觉与文本对齐问题,并探索多模态幻觉的原因和解决方案。
8、解释ChatGPT的零样本和少样本学习的概念?
两种学习方式都利用了LLM强大的语言理解和生成能力,零样本学习是指模型在没有接受特定任务训练的情况下,能够处理并完成该任务,通常是通过理解任务的描述或指令来实现的。例如,如果给定一个从未见过的问题类型,ChatGPT可以分析问题的描述,并尝试根据其语言模型的能力来生成合适的回答,而不需要针对该问题类型的额外训练。
少样本学习是指模型在给定少量示例(通常只有几个)后,能够快速适应并执行特定的任务。例如,如果用户想让ChatGPT总结一段文本,可以提供几个简短的文本-摘要对作为示例。ChatGPT通过学习这些示例,理解如何生成摘要,然后应用这种理解来总结新的文本。
9、你了解大型语言模型中的哪些分词技术?
分词技术包括单词分词:将文本切分为单词,字符分词:将文本切分为单个字符,子词分词如Byte Pair Encoding (BPE) 或 SentencePiece :将单词切分为更小的单元以处理罕见词汇和避免词表过大,句子分词:基于标点符号将文本切分为句子,基于规则的分词:使用正则表达式等规则处理特定语言,统计分词:考虑单词共现概率,机器学习分词:通过模型学习分词边界,混合分词:结合多种技术适应不同语言,空间分词:依据空格进行分割,以及深度学习分词:使用深度模型学习分词特征。这些分词技术的选择依赖于处理的语言、文本类型及模型架构,对模型性能和应用效果有重要影响。
10、如何评估大语言模型(LLMs)的性能?
评估大型语言模型(LLMs)的性能需综合考虑任务特定指标、语言模型的困惑度、文本的一致性和连贯性、事实准确性、鲁棒性、偏见和公平性、可解释性、多语言能力、上下文理解、交互能力、实时性能、资源效率、用户满意度、安全性和长期学习能力等关键维度,以确保模型在各种应用场景下的高效、准确和可靠。在实际业务中,需要结合业务场景和考核指标来进行评估。
....
#DeepSeek R1 Zero保姆级复现教程
LLM界的AlphaGo
导读:
你是否还在为理解DeepSeek-R1的"纯强化学习黑箱"而困惑?现在,有人在github上公开了Logic RL项目,完整开源了从base模型到R1 Zero的全流程代码,让每个人都能复现这个号称"LLM界AlphaGo"的神奇模型。
项目地址:https://github.com/Unakar/Logic-RL
该项目通过三步构建完整复现链路:
1.采用合成的Knights and Knaves(K&K)谜题数据(类似老实人和骗子的益智题),仅用2k不到的训练数据集就复现了R1 Zero类似的推理效果。
2.设置了严苛的Reward规则,将Format Reward和Answer Reward分离,避免训练过程中出现的Reward Hacking的问题。
3.基于GRPO算法实现无监督强化学习,并采用了三阶段RL的训练过程,成功复现Deepseek R1 Zero的效果。
■ 1.1. 量化指标
在作者自己构建的测试集上和其他一些主流模型(o1 4o Deepseek Math 7B)表现对比如下(N代表难度,越大难度越高):
|
测试集难度N |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
Openai-o1-1217 |
0.83 |
0.51 |
0.38 |
0.38 |
0.35 |
0.30 |
0.20 |
|
GPT-4o |
0.68 |
0.57 |
0.49 |
0.32 |
0.23 |
0.21 |
0.11 |
|
Deepseek-Math-7B |
0.35 |
0.21 |
0.08 |
0.06 |
0.02 |
0.00 |
0.00 |
|
Ours(7B) |
0.68 |
0.59 |
0.44 |
0.34 |
0.22 |
0.16 |
0.15 |
根据表格数据分析,不同模型在递增的测试集难度(N=2至N=8)下的性能表现呈现显著差异:
1.整体趋势:所有模型的性能均随难度上升而下降,但下降幅度不同。Openai-o1-1217和GPT-4o在低难度(N=2)时表现较优(0.83和0.68),但高难度(N=8)时分别降至0.20和0.11,降幅达76%和84%。
2.模型对比:
a.复现的模型在低难度(N=2-3)与GPT-4o接近(0.68 vs 0.68,0.59 vs 0.57),但在中高难度(N=4-8)中表现更优。例如N=5时准确率为0.34,显著高于GPT-4o的0.32和Openai的0.38;N=8时准确率(0.15)也优于GPT-4o(0.11)。
b.Deepseek-Math-7B性能全面落后,高难度(N≥6)时趋近于0,凸显模型优化不足。
3.参数效率:复现的模型与Deepseek-Math-7B同为7B参数模型,但前者性能显著提升(如N=3时0.59 vs 0.21),表明多阶段RL训练策略优化有效。
在参数量相同的情况下,通过这样的训练策略实现了与更大模型(如GPT-4o)在低难度问题上比肩竞争力和在中高难度问题上的优势,尤其在N=5-8阶段,而即使Openai-o1-1217模型在高难度问题下仍表现不佳。该结果凸显了复现的模型强大的逻辑推理能力。
■ 1.2. 推理过程分析
再经过训练之后,模型掌握了丰富的逻辑推理能力,具体而言出现了以下几个有意思的现象:
- 迟疑 (标记当前不确定的step等后续验证)
- 多路径探索 (Les't test both possibilities)
- 回溯之前的分析 (Analyze .. statement again)
- 阶段性总结(Let's summarize, Now we have determined)
- Answer前习惯于最后一次验证答案(Let's verify all statements)
- Think时偶尔切换多语言作答(训练数据纯英文的情况下,思考部分是中文,最后answer又切回英文)
■ 1.2.1 迟疑
1. **William's statement**: "William is a knight and Chloe is a knight.'
- If William is telling the truth (i.e., he is a knighht), then both parts of his statement must be true. Howeve$5,5
if William is a knight, the statement "William is a knighht" is true, but the statement "Chloe is a knight" cannotdetermine the truth about Chloe at this point since we haven't analyzed Chloe's statement yet. Therefore, William cannot be a knight becausse it would lead to a contradiction.例如上文给出的“ at this point since we haven't analyzed Chloe's statement yet”这是一种谨慎反思的机制:当遇到不确定性时,模型会主动标记当前推理步骤并暂停(类似人类"等等先想清楚"的状态),这种停顿训练机制显著提升了复杂问题的解决能力。
■ 1.2.2 多路径探索
2. **Now that we know William is a knave, let's analyze Chloe's staatement**: "Lily is a knight.
- Since William is a knave, Chloe's statement can be eitther true or false. If Chloe is a knight, her statement mu
- Let's test both possibilities.“Let's test both possibilities” 体现了模型习得的双轨并行思考能力,在面对二选一场景时,模型会像科学家一样同时测试两种可能性,这种多路径探索模式可以大大提高模型推理的准确率。
■ 1.2.3 回溯分析
4. **Analyzing Lily's statement**: "William is a knave and Jack is a knight.
-Since William is a knave and Lily is a knight, her staterment is true. This means Lily is indeed telling the truth
5. *Analyzing Jack's statement**:"William is a knave."
-Since William is a knave, Jack's statement is true, so Jaack is a knight
**Analyzing Logan's statement**: "Lily is a knave if and onlyif William is a knave."
- Since Lily is a knight and William is a knave, this statement is false. Therefore, Logan is a knave.
7. *Analyzing Chloe's statement again**: Wee already determined that if Chloe is a knight, her statement "Lilyis a
knight" is true, so she is a knight.上述例子体现了模型对之前分析进行回溯的能力,当发现逻辑矛盾时,模型会自动回溯到关键分析节点重新验证,这种自我纠错机制可以有效减少认知偏差。
■ 1.2.4 阶段性总结
Now,we havedetermined:William is a knave.Chloe is a knight.- Lily is a knight.- Jack is a knight.- Logan is a knave.上述例子体现了模型进行阶段性总结的能力,对之前的推理结果进行汇总,以便于进行后续的验证环节。
■ 1.2.5 最终验证
Let'sverify all statements:
Verify
William: "William is a knight and Chloe is a knight" (False, since William is a knave).
Chloe: "Lily is a knight"(True).
Logan: "Lily is a knave if and only if William is a knave"(False, since Lily is a knight and William is a knave)
Jack: "William is a knave"(True).
Lily: "William is a knave and Jack is a knight" (True)类似人类考试交卷前检查试卷的行为一样,模型会在给出最终答案之前对其之前所有的statement进行校验,这种校验机制可以进一步保证模型推理结果的准确性。
■ 1.2.6 跨语言回答
Since both assuming Sofia is aknight and a knave lead to contradictions, we need tore-evaluate our initial assumpt
ion. However, the only consistent path is to recheck the inittial assumption that William is a knight
Let's assume William is a knight again and proceed with the same logic to ensure no contradictions arise.The consis
tent path will be威廉不是一个有效的输入,让我继续使用正常的推理方式来解决这个问题,意味着威廉的陈述是正确的。
再次从威廉开始:
威廉说:"威廉是骑士或者索菲亚是骑士"。假设威廉是骑士,那么他的陈述必须为真,因此"威廉是骑士或者索菲亚是骑士"为真,这接下来检查索菲亚的陈述:"诺亚不是骑士",假设索菲亚是骑士,那么她的陈述必须为真,意味着诺亚确实不是骑士(即诺亚是骗子)。现在检查诺亚的陈述:
"佐伊不是骗子"。如果诺亚是骗子,那么这个陈述为假,这意味着"佐伊不是骗子"为假,即佐伊是骗子。如果佐伊是骗子,那么她
所做的陈述"如果诺亚是骑士那么梅森是骗子"将为假。因为如果诺亚是骑士,那么如果诺亚是骑士那么梅森是骗子"将为真,但由于佐伊是骗子,她应该说
这导致矛盾。因此,索菲亚不能是骑士。
既然索菲亚不能是骑士,那么她必须是骗子。因此,她的陈述"诺亚不是骑士"为假,这意味着诺亚是骑士。现在我们检查诺亚的陈述
"佐伊不是骗子"。既然诺亚是骑士,这个陈述必须为真,所以佐伊确实不是骗子,佐伊是骑士。接下来检查佐伊的陈述:"如果诺亚是骑士那么梅森是骗子
因为诺亚是骑士,该条件为真,而佐伊的陈述为真,因此佐伊是骑士。然后我们检查梅森的陈述:"威廉是骗子或者佐伊是骗子"。威廉是骑士,佐伊是骑士
因此梅森的陈述为假,因此梅森是骗子。最后检查威廉的陈述:"威廉是骑士或者索菲亚是骑士"。威廉是骑士,索菲亚是骗子,因此威廉的陈述为真,这与我们的推理一致。
综上所述,我们得到了以下结果:
1.威廉是骑士
2.索菲亚是骗子
3.诺亚是骑士
4.佐伊是骑士
5.梅森是骗子</think><answer>(1) William is a knight,(2)Sofia is a knave Noah is a knight,(4)Zoey is a knight,(5)Mason is a knave</answer><|im_end|>上述例子展示了模型在推理分析问题的过程中从英文切换到中文逻辑框架最终又切换回英文的现象。
■ 2.1. 前置设定
■ 2.1.1 训练数据
Knights and Knaves(K&K)谜题
这个项目选用了K&K谜题作为训练模型逻辑推理能力的训练数据。Knights and Knaves(K&K)谜题是一种经典的逻辑推理谜题,其核心设定源于美国逻辑学家雷蒙德·斯穆里安(Raymond Smullyan)的著作《这本书的名字是什么?》。
谜题设定在一个虚构岛屿上,居民分为两类:
- 骑士(Knights) :永远说真话。
- 骗子(Knaves) :永远说假话。
需要根据居民所述的内容推理出来谁是骑士,谁是骗子。K&K谜题通过简单的二元对立(真/假)构建复杂的逻辑挑战,其核心在于利用矛盾与假设推导真相,常用于数学和计算机科学教育,培养命题逻辑与假言推理能力。因此,用来培养模型的逻辑推理能力就十分合适了。
构造训练数据
通过运行kk.py脚本把k&k谜题转成适合模型的modeltext,具体指令如下
python ./examples/data_preprocess/kk.py \
--template_type=qwen-instruct \
--local_dir {processed_data_path} \
--data_path {raw_data_path}其中template_type根据选取的基座模型有关,例如上述例子中需要构造Qwen格式的modeltext,构造的模板如下
<|im_start|>system\nYou are a helpful assistant. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and<answer> </answer> tags, respectively, i.e., <think> reasoning process here </think><answer> answer here </answer>. Now the user asks you to solve a logical reasoning problem. After thinking, when you finally reach a conclusion, clearly state the identity of each character within <answer> </answer> tags. i.e., <answer> (1) Zoey is a knight\n(2) ... </answer>.\n<|im_end|>\n<|im_start|>user\n{quiz}\n<|im_end|>\n<|im_start|>assistant\n<think>即插入和的标签,这对后续训练模型的逻辑推理能力十分重要。
■ 2.1.2 基座模型

Deepseek开源了一系列Distill的模型,但是经过测试,比起从R1中学习到推理的能力,1.5B的模型更多只是学到了推理的形式。此外,deepseek 选取了qwen-math-7B作为基座,然而Logic RL项目作者表示经过实验发现这样做有着许多的缺陷:
1. 指令遵循能力局限
该模型在复杂指令解析与执行层面存在显著局限性,尤其在格式化输出(Format)维度的学习效率偏低。
2. 编程范式固化问题
模型表现出对Python代码解题路径的强烈偏好,这种行为模式在标准监督学习框架下难以有效消解。
3. 系统提示词依赖性
即便移除系统提示词(System Prompt),模型仍固守用\box{}标记包裹响应的输出模式,反映出其格式化控制机制尚未形成稳定的动态适配能力。
4. 输出风格与认知模型冲突
模型生成内容呈现过度结构化特征(Markdown化倾向明显),与推理类模型需兼具逻辑严谨性与思维发散性的设计目标存在认知偏差。
基于以上问题,作者选取了Qwen 7B 1M instruct代替Qwen Math系列作为基座模型。
■ 2.1.3 GRPO算法

GRPO(Group Relative Policy Optimization,群体相对策略优化)是一种基于PPO(Proximal Policy Optimization)改进的强化学习算法,专为优化大语言模型(LLM)在复杂推理任务中的表现而设计。其核心特点在于通过分组采样和组内相对奖励机制简化训练流程,降低计算成本,同时提升模型性能。以下是GRPO的关键原理与优势:
1.结构改进:摒弃价值模型,引入组计算
GRPO去除了传统PPO中与策略模型规模相当的价值模型(Critic),转而通过参考模型和组内奖励归一化直接计算优势函数。具体而言,GRPO对每个问题采样多个候选输出(如生成G个回答或证明步骤),利用奖励模型对组内输出进行评分,并通过标准化(减去均值、除以标准差)计算相对优势,以此替代传统价值网络的基线估计。这种方法显著减少了内存占用和训练复杂度。
2.优势函数与策略更新
GRPO的优势函数基于组内输出的相对表现,公式为 ,其中 和 分别代表组内奖励的均值和标准差。策略更新时,目标函数最大化优势函数,并通过KL散度约束确保新策略与参考策略的偏离可控,从而提升训练稳定性。例如,在数学定理证明中,GRPO对正确证明(奖励为1)和错误证明(奖励为0)进行组内对比,调整参数以增加正确证明的生成概率。
3.资源效率与扩展性
由于无需训练单独的价值模型,GRPO在单卡环境下即可完成训练,内存消耗相比PPO降低高达80%。例如,在DeepSeek-R1模型中,GRPO通过组内对比优化策略,避免了价值网络的参数更新,使训练集上的平均响应长度自然提升,模型学会通过更长的思考时间解决复杂推理任务。
4.应用场景与效果
GRPO尤其适用于需要多候选答案比较的任务,如数学推理、定理证明和对话生成。在数学解题场景中,GRPO生成多个候选解法,通过奖励模型(如准确性、格式评分)筛选最优解,并结合KL散度约束防止策略偏移。实验表明,GRPO在GSM8K数学数据集上的收敛速度比PPO快40%,最终准确率提升15%。在定理证明领域,GRPO通过二进制奖励(正确性评分)和组内对比,显著提高了模型生成正确证明的能力。
5.局限性与平衡
GRPO的组采样机制在训练时节省资源,但推理阶段需生成多个候选答案,可能增加计算开销。此外,组大小(G值)需权衡效果与效率——较大的组可提供更准确的相对优势估计,但会延长采样时间。
总结来看,GRPO通过创新性地利用组内相对奖励机制,在保持训练稳定性的同时,大幅降低了强化学习对计算资源的依赖,成为大语言模型在数学推理、复杂问题解决等场景中高效优化的关键技术。
■ 2.2. 训练过程分析
Logic-RL项目的作者采用了三阶段RL的方法对模型进行训练,一阶段通过严格的reward解藕与课程学习的方法,使模型获得基本的格式遵循能力;二阶段通过提高sampling temperature参数以及进行大量的rollout,避免模型局限于一阶段所习得的格式之中,增加输出的多样性,第三阶段则逐步回归正常,变成常规的RL训练模式。
■ 2.2.1 第一阶段
在此训练阶段,模型的核心学习目标为输出格式的规范化。若违反既定格式规则,系统将施加显著的负向奖励机制。这依赖于一个严谨的奖励机制体系。因此,项目作者设计了模块化的双维度评估框架:格式规范奖励(Format Reward)与答案质量奖励(Answer Reward)。通过限定奖励函数仅由这两个核心维度构成,有效规避了强化学习中常见的奖励滥用(Reward Hacking)风险。在规则引擎开发层面,项目作者系统性构建了基于条件判断逻辑与正则表达式规则的验证体系。值得注意的是,在初期迭代过程中,模型频繁表现出突破预设约束的意外行为模式。通过持续对抗性测试与规则集的反复迭代优化,最终形成了具备鲁棒性的规则验证架构。
def validate_response_structure(processed_str: str) -> bool:
"""Performs comprehensive validation of response structure.
Args:
processed_str: Processed response string from the model
Returns:
Boolean indicating whether all formatting requirements are met
"""
print("\n[Structure Validation]")
validation_passed = True
# Check required tags
tags = {
'think_start': ('<think>', 1),
'think_end': ('</think>', 1),
'answer_start': ('<answer>', 1),
'answer_end': ('</answer>', 1)
}
positions = {}
for tag_name, (tag_str, expected_count) in tags.items():
count = processed_str.count(tag_str)
positions[tag_name] = pos = processed_str.find(tag_str)
print(f" {tag_str}: count={count}, positinotallow={pos}")
if count != expected_count:
print(f" [Error] {tag_str} appears {count} times (expected {expected_count})")
validation_passed = False
# Verify tag order
if (positions['think_start'] > positions['think_end'] or
positions['think_end'] > positions['answer_start'] or
positions['answer_start'] > positions['answer_end']):
print(" [Error] Incorrect tag order: Expected <think>...</think><answer>...</answer>")
validation_passed = False
else:
print(" Tag sequence validation passed")
return validation_passed上述代码便是验证输出格式的逻辑,将会统计tag的数量,顺序等,通过验证后将会得到format_score 否则会有-format_score的惩罚。
# Validate response structure
format_correct = validate_response_structure(processed_str)
format_score = format_reward if format_correct else
-abs(format_reward)另一部分的answer reward则相对较好理解,即验证答案和ground truth是否吻合,根据match的情况给出不同的reward。
if format_correct and answer_text:
pred_status = parse_model_answer(answer_text, expected_names)
if pred_status:
print(f"\n[Content Validation]")
print(f" Expected: {gt_status}")
print(f" Predicted: {pred_status}")
if pred_status == gt_status:
answer_score = 2
print(" Content validation: FULL MATCH")
else:
answer_score = -1.5
print(" Content validation: MISMATCH")
else:
answer_score = -2
print( "Fail to parse answer")
else:
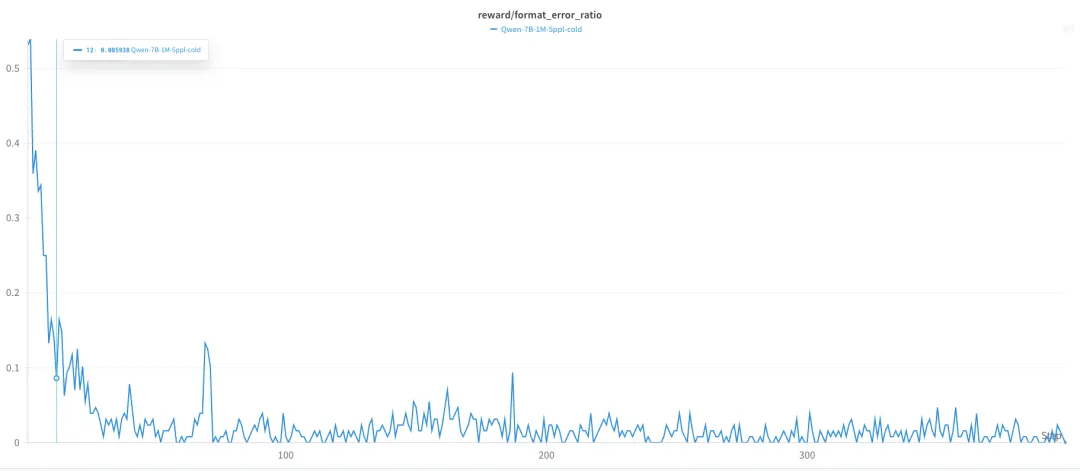
print("\n[Content Validation] Skipped due to format errors or missing answer")从format_error_ratio 曲线中不难看出,模型在12个step之后已经可以比较好的掌握格式的规律了,只有不到10%的输出存在格式问题。
还有一个有意思的现象是,模型的min response length得到了大幅增长而max response length则增长较缓,笔者分析该现象背后的一个合理解释为:min length可能代表模型思考深度的增加(越多的推理步骤,越多的token,即越多的response length),而max length则受到训练数据整体复杂度的限制,由于这个阶段选取的逻辑推理题目不是特别复杂,因此限制了最大长度的可能性。

■ 2.2.2 第二阶段
在这个阶段,通过增大采样temperature,打乱之前模型习得的response formate,主要是避免模型陷入之前的formatting局限之中。具体而言,项目作者将temperature设定在1.2左右。经项目作者实验验证,当temperature值超过1.5时,模型输出稳定性显著降低,易出现response text紊乱的现象。同时,对Top-P与Top-K参数进行了动态调整,其核心目标在于抑制模型固有的格式规约倾向,通过干扰其结构化输出模式(如Markdown语法偏好),从而提升生成结果的多样性。
在这个阶段的训练过程中,模型极大的增加了 verify环节被采样的概率(数据集中并没有任何verify相关token)

■ 2.2.3 第三阶段
在模型训练的第三阶段,采样参数逐步回归至常规设置区间,其中温度参数采用渐进式降温策略,从初始值1.2分阶段降至0.9。此阶段的模型输出质量显著提升,如本文最开始结果展示所示,其生成内容已具备完整的结构化特征:包含验证(verify)、结果回溯、逻辑反思等关键认知环节,充分体现了强化学习训练过程中涌现的复杂推理能力。
相较于前序的distill模型,本阶段输出呈现出显著优势:其一,生成内容的逻辑链条简洁高效,有效避免了冗余性表达;其二,输出质量在格式规范性和语义一致性方面均达到更高标准。这种改进可归因于强化学习阶段施加的严格格式奖励机制,以及温度参数调控带来的输出稳定性提升。
在优化器设置方面,学习率采用分级衰减策略,最终稳定在2e-7量级。这种渐进式调整策略既保证了参数空间的充分探索,又确保了训练后期的收敛稳定性。值得注意的是,本阶段的训练动态与中所述的蒸馏模型形成鲜明对比:在相同温度参数区间内,本模型展现出更强的语义连贯性和更低的格式错误率,验证了分阶段强化训练策略的有效性。
Logic RL项目不仅开源了DeepSeek-R1-Zero模型的完整复现方案代码库,还完整披露了训练过程的关键性能曲线与若干具有研究价值的特殊现象,对相关技术路线的工程实现具有重要参考价值。
....
#Matrix-Zero
一图一3D世界,视频还可交互,昆仑万维「空间智能」开年首秀来了
2025 年普遍被认为是智能体爆发元年,AI 应用将出现井喷式增长。然而,在大家纷纷将目光投向智能体的同时,另一个 AI 领域也可能迎来它的「ChatGPT 时刻」。
这个春节,动画电影《哪吒 2》爆火,不仅登上中国影史票房榜首,还不断地刷新全球票房榜单。3D 版本中的山河社稷图、石矶娘娘变身的石头山、最后的仙魔大战…… 这些场景让我们感受到了极度震撼的 3D 动效。
在 AI 领域,一项正在发展中的新兴技术有可能将 3D 动画的整体质量以及观众的沉浸感推向一个全新的高度。它就是「AI 教母」李飞飞看好并押注的空间智能(Spatial intelligence)。未来有了这项 AI 技术的加持,3D 动画的表现力有可能得到前所未有的加强。
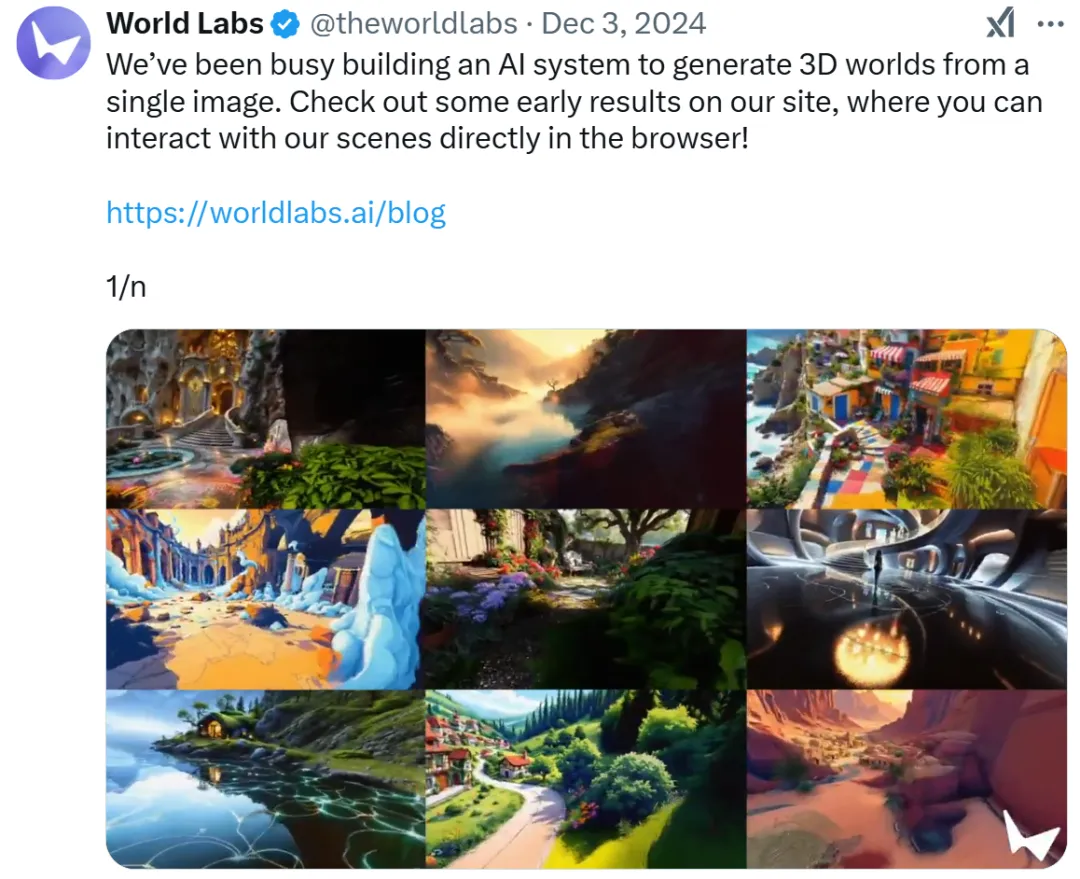
在这位 AI 领域的顶级科学家看来,无论是人类还是机器,学会如何看待这个世界、如何与世界互动至关重要,而空间智能在其中将扮演重要角色。她坚信,像语言一样是 AI 根基之一的空间智能将成为 AI 下一发展阶段的前沿技术方向。去年 12 月初,李飞飞创业团队 World Labs 的首个产品向我们展示了单张图生成 3D 世界的惊艳效果。
从二维到三维,AI 要想真正理解与操控 3D 空间,需要解决不少痛点。比如大规模高质量 3D 数据匮乏限制了模型效果和泛化能力,生成的 3D 场景在几何结构和纹理细节上不够精细或存在瑕疵、不完整,多视角一致性很难保证;再比如效率问题,处理复杂图像和大规模场景时可能导致算力消耗过大、生成时间过长。
因此,空间智能真正突破传统 AI 的二维像素级视觉理解并不是那么容易。在国内,一家「All in AGI 和 AIGC」的大模型厂商,向真实世界的几何与物理规则发起了挑战,并率先在空间智能这个新兴领域搞出了一个大动作。
2 月 14 日,昆仑万维正式发布了 Matrix-Zero 世界模型,迈出了其探索空间智能的关键一步。Matrix-Zero 包括 3D 场景生成大模型和可交互视频大模型,不仅可以将用户输入的图片转化为可自由探索的真实合理的 3D 场景,而且能够生成可交互视频。这意味着,Matrix-Zero 是一个功能「加强版」的 3D 物理世界与视频生成器。
随着 Matrix-Zero 的推出,昆仑万维在 AIGC 时代的定位又有了新的变化,成为国内第一家同时推出 3D 场景生成、可交互视频生成模型的探索空间智能企业。

昆仑万维表示,Matrix-Zero 预计将于 4 月份正式上线,届时用户便能上手体验了。
突破二维平面的 3D 虚拟世界原来是这样子的
从业界已有的工作来看,仅凭任意一张图片就可以生成遵循基本物理几何规则的 3D 世界,成为了探索空间智能的一项关键技术进展。通过训练出的感知、理解和交互能力,AI 想要在三维空间中像人类一样自由地导航、操作和创造。
从李飞飞 World Labs 首个 3D 世界产品,到谷歌 DeepMind 的第二代世界模型 Genie 2,空间智能正在努力完成从生成内容到构建世界的进化,这就要求不仅要理解像素,还要有能力解析空间坐标、几何关系与物理规律,从而实现尽可能真实的立体感和空间深度。
此次,昆仑万维的 Matrix-Zero 向着这些目标开始了自己的尝试,形成了领先的技术方案,并最终在 3D 世界生成领域展现出了一些独有优势。
一图一世界,AI 让 3D 世界一触即达
根据昆仑万维的介绍,Matrix-Zero 采用了与李飞飞 World Labs 不同的 3D 技术路线,实现了可自由探索且更加真实合理的 3D 场景生成效果。
在由单张静态图片转化成对应 3D 场景的过程中,保持与原图片的风格一致很重要。在这方面,Matrix-Zero 支持不同风格的图片输入,比如写实风和卡通风(如下写实小巷和卡通蘑菇),严格地「继承」了图片原有风格。


Matrix-Zero 还进一步具备了风格转换能力,在生成 3D 场景时将原图片丝滑地切换成另一种风格,可玩性相较竞品更高,如下示例将原图的房屋变成了红瓦白墙。

其次,Matrix-Zero 生成的 3D 场景实现高度的全局一致性,解决了从单一视角图片生成广范围 3D 场景的前后不一致与空间合理性问题。
从粗糙的几何结构到细节丰富的场景,Matrix-Zero 利用空间扩散模型和可微渲染技术,在不断的细节细化中改善全局一致性,成功创建出了完整且一致的 3D 世界。
从下面两图可以看到,Matrix-Zero 通过自由的镜头移动(包括前进和 360 度环视),从 3D 场景中渲染生成一致的新视图,并确保生成的 3D 场景在空间、物体位置和全局尺度上的合理性。


接下来,Matrix-Zero 向我们展示了它的最大亮点——支持在 3D 场景中任意方向的长距离、大范围自由探索,用户的可操作性更丰富、更强。
实现如此程度的自由探索,得益于 Matrix-Zero 生成的 3D 场景很好地解决了连续性、合理扩展、环境交互、空间感知与导航等多个技术层面的挑战。
Matrix-Zero 不仅可以做到丝滑流畅的前进、后退、左右转、环视等单一移动,还能够执行更复杂的 360 度俯视(下图上)以及先前进后右转等复合移动(下图下)。


最后,Matrix-Zero 生成的 3D 场景中还能加入动态物体,并实现水流、光照、云雾等看起来自然且符合物理规律的动态效果。
达成这些目标,需要昆仑万维团队融合深度学习、图形学和实时计算等技术。更具体地,只有在物理仿真、光照与材质模拟、物体交互、实时渲染等多个领域的融合,才有可能从静态图片中捕捉、预测并最终正确模拟出合理的动态物理行为。
Matrix-Zero 实现了丰富的物理动效,包括光照水流混合效果(下图上)、云雾效果(下图下)、海浪效果等。这对于未来帮助 AI 更好地提升 3D 世界的物理属性具有积极意义。


以上结果一一看下来,我们可以得出这样一个初步结论:Matrix-Zero 生成的 3D 场景以及表现出来的亮点,让国内厂商在空间智能领域有了匹敌甚至一些层面上超出国外竞品的实力,其中大范围自由探索增强了 AI 的物理推理、空间认知等能力,有望为构建通用世界模型和 AGI 提供强大助力。
可交互视频让人的参与度更高
Matrix-Zero 的第二个子模型支持可交互的视频生成,其最大的亮点是更关注实时交互和大范围场景。
一方面,Matrix-Zero 泛化能力很强,可以适应不同环境,并能以极高的效率生成流畅、一致和合理的高质量视频。另一方面,Matrix-Zero 超出了已有视频生成的能力范畴,极大地强化了视频内容的可操作性,让用户能够自由地调整视角、操控场景元素,并实时影响视频内容,更符合他们的需求和预期。可以说,人在视频生成中的参与度更高了。
从下面生成的城市和沙漠两个环境的视频来看,Matrix-Zero 的可交互性展现得一览无遗。用户可以通过任意的键盘或鼠标移动来控制方向,包括前后左右移动和自由视角移动。这样一来,用户能以极高的自由度来探索视频内容,并使它们更满足自己的意图。
这种强交互性还将进一步优化世界模型在虚拟环境中的的适配性,为构建更强、用户更友好的交互式应用提供驱动力。


从以上一系列 3D 场景和可交互视频的表现来看,在 Matrix-Zero 创建的虚拟世界中,人机交互、自由度和沉浸感均大大加强。可以遇见,未来更强大的昆仑万维 Matrix-Zero 将在可控游戏场景构建、xxx智能场景模拟以及 3D 影视镜头高效生成中开辟无限的应用可能性。
一模两用,Matrix-Zero 如何炼成?
当然,Matrix-Zero 的进步,是昆仑万维在自研 3D 场景生成、基础视频生成模型以及用户输入交互模型上全方位升级的结果。
对于 3D 场景生成,Matrix-Zero 由背后强大的 3D 场景生成大模型驱动,它包含两个核心模块,分别是场景布局生成模块和纹理生成模块。作为单张图生成 3D 世界的两个核心环节,场景布局生成和纹理生成决定了 3D 世界的几何结构和视觉细节,还直接影响空间完整性与交互体验。
因此,Matrix-Zero 要解决一系列挑战,包括推测不可见部分的合理性(如深度关系、物体语义)、物理一致性(如材质、空间关系的合理性)以及计算资源优化(即高质量 3D 生成的计算开销),这样才可能提高 3D 世界生成的真实感和可用性。
Matrix-Zero 的场景布局生成模块融合了可微渲染和扩散模型技术,创造出与输入图片一致的 3D 场景布局;纹理生成模块在图片生成和视频生成模型的基础上进行训练,可以生成符合场景布局且运镜精准控制的视频。两个模块相辅相成,结合 3D 高斯泼溅(Gaussian Splatting)进行端到端优化,就得到了初始 3D 场景。
接下来,为了确保用户在任何位置、任何角度都能看到合理、一致的场景,3D 场景生成大模型发挥关键效用,对场景缺失区域进行几何和纹理补全,构建出了完整、合理、自然的 3D 世界。
而相较于 3D 场景,Matrix-Zero 可交互视频生成背后采用的技术路线又有所不同。我们了解到,该方法以自研的生成式视频模型为基础,依托大规模开放数据的预训练模型,并结合了自研用户输入交互模型,最终形成了以用户输入为核心驱动的空间智能视频生成方案。有了这些模型的共同参与,高质量、稳定视频的输出成为可能。
作为视频生成系统的 Matrix-Zero,其包含了两大组件,分别是核心的基础视频生成模型以及重要的用户输入交互模型。两者各司其职,为 Matrix-Zero 视频生成不同阶段的能力实现保驾护航。
一方面,基础视频生成模型从初始视频帧生成连贯视频内容,它采用深度学习技术,并结合多种先进的生成模型来确保视频的清晰度、稳定性和逻辑性。生成过程中利用到了以下三项关键技术:
一是基于 Transformer 的视频扩散模型。通过引入 Transformer 架构,更好地捕捉到了视频序列中的时序依赖关系,同时帧间一致性的增强可以避免出现画面跳跃或不连贯,视频整体质量得到提升;
二是潜变量自编码器(VAE),它负责对数据进行降维处理,从而提高计算效率、降低计算成本并减少了信息冗余,加速输入内容处理和高质量视频输出;
三是引入时间步长优化策略来确保物理合理性。时间步长的调整避免了画面失真并保证物体合理运动,使视频更加自然流畅。
另一方面,用户输入交互模型专门解析用户输入信息以将它们转化为视频调整信号,这样做是为了让视频内容准确地响应用户操作,带来自然、流畅的交互体验。
具体地,用户输入交互模型通过离散运动控制、连续视角控制、3D 场景位置追踪和滑动窗口优化四大模块,实现了更智能的交互式视频生成。各个模块的功能分别如下:
- 离散运动控制,用于解析用户的基本动作指令(前进、跳跃、后退等),将它们转化为对应的运动轨迹,从而调整物体行为以符合用户交互需求;
- 连续视角控制,实时解析、响应鼠标或其他输入设备的连续控制信号(如视角变化、方向调整等动态操作),并通过调整视频内容来实现平滑、一致的视角变换;
- 3D 场景位置追踪,利用 3D 空间定位技术确保不同场景下稳定、自然的视角变换,减少画面突兀跳转,让视频更连贯;
- 滑动窗口机制,通过引入时间序列中的历史输入信息,系统对用户下一步操作的预测准确度更高,控制响应的平滑度得到优化;交互流畅性也更强,延迟减少,用户体验提升。
结语
回顾过去不久的 2024 年,是大语言模型飞速发展的一年。可以看到,从基座模型、实时语音模型、视频模型到社交媒体爆火的推理模型,大模型的生成与理解、自我思考能力在短短一年内实现量级提升。与此同时,空间智能异军突起,有实力、有远见的厂商逐渐开始了布局。
作为国内领先的人工智能企业,昆仑万维在过去每一波 AI 浪潮中始终展现出了前瞻性,从拼参数的百模大战到卷多模态、卷推理、卷智能体,其在各个阶段的成果产出中完成了「算力基础设施 - 大模型算法 - AI 应用」的全产业链布局,并构建起了由 AI 大模型、AI 搜索、AI 游戏、AI 音乐、AI 社交、AI 短剧组成的多元 AI 业务矩阵,积极推动商业化落地。
此次 Matrix-Zero 是昆仑万维在空间智能领域的又一标志性成果,此前曾发布 3D 生成大模型 Sky3DGen,并融合视频大模型推出了 AI 短剧平台 SkyReels。随着 Matrix-Zero 的到来,昆仑万维的空间智能探索将开启新篇章,其多元业务矩阵也将进一步得到强化,并为其多模态大模型的应用落地开辟了一条新的赛道。
未来,我们可以期待空间智能的更多升级,比如模型训练层面结合视觉、听觉、触觉等感官,通过强化学习实现更精确的感知和推理;再比如模型应用层面有望扩展到更多行业或融合进现有产品。可以说,无限可能性等待着进一步探索,空间智能大有可为。
对于像昆仑万维这样 All in AGI 的企业来说,更强大的空间智能将赋予 AI 理解、感知、推理、交互和操作物理世界的能力,成为 AGI 迈向更高智能水平的核心支柱。
....
#Distillation Scaling Laws
苹果也在蒸馏大模型,给出了蒸馏Scaling Laws
蒸馏模型的性能可以量化估算了。
众所周知,知识蒸馏技术当前正被大模型领域广泛使用,它可以在大幅压缩模型体量的同时保持一定的性能、降低模型时延、提升模型精度,与此同时还能对知识域进行集成和迁移。
近日,苹果研究人员提出了一种蒸馏扩展定律(Distillation Scaling Laws),基于计算预算及其在学生和教师之间的分配,我们现在开始可以估算蒸馏模型的性能了。
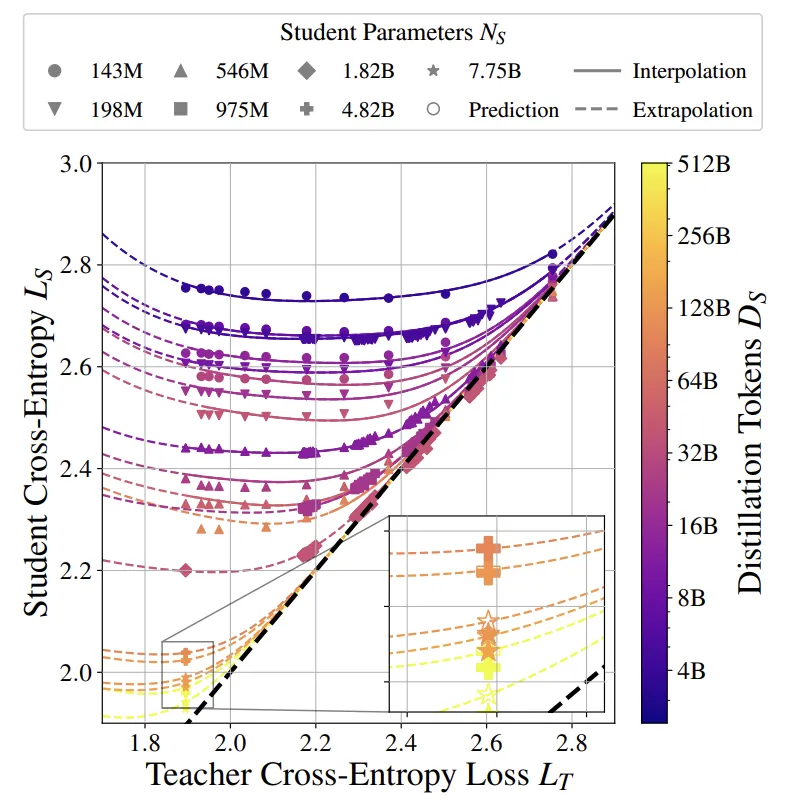
图 1. 蒸馏扩展定律的外推。蒸馏扩展定律适用于一系列损失为 LT 的教师的弱学生模型(L_S > 2.3)。实线表示给定学生配置(插值)下未见过的教师的预测模型行为,虚线表示见过的教师之外和强学生区域(L_S ≤ 2.3)的预测模型行为。如图所示,学生的表现可以胜过老师(详情见图 2、3 和 41)。
苹果研究者认为,该发现降低了大规模使用蒸馏的风险,现在我们可以基于此优化教师和学生模型的计算分配,以最大化学生模型的性能。该工作提供的计算最优的蒸馏方案适用于两种情况:1)已有教师模型,或 2)需要训练教师模型。
如果要蒸馏多个学生模型,或者已有教师模型,蒸馏在计算水平上优于监督预训练,直到计算水平随着学生模型规模的增加而可预测地增长。如果要蒸馏一个学生模型且还需要训练教师模型,则应采用监督学习。此外,作者在大规模蒸馏研究中提供了深入的见解,这些见解增加了我们对蒸馏的理解,并为实验设计提供了信息。
- 论文标题:Distillation Scaling Laws
- 论文链接:https://arxiv.org/pdf/2502.08606
大模型的扩展定律(Scaling Laws)表明,如果先前训练的语言模型(LM)遵循计算最优训练范式,就可以随着计算力提升而提升。由于推理成本的持续增长,目前这种定律难以持续,人们尝试使用过度训练(其中训练数据量远大于计算最优情况)来实现小型、功能强大的模型。这些模型的构建既昂贵又耗时。
我们正在寻求与训练算力投入相匹配,但训练成本更低的模型,蒸馏是一种流行的方法。但长期以来,学界对蒸馏缺乏共识,并不了解如何分配计算资源,以产生最强大的模型。为了弥补这一知识差距,研究人员对蒸馏进行了广泛研究,学生和老师的参数范围从 1.43 亿到 126 亿,使用训练数据最多达 5120 亿 token。
研究发现:

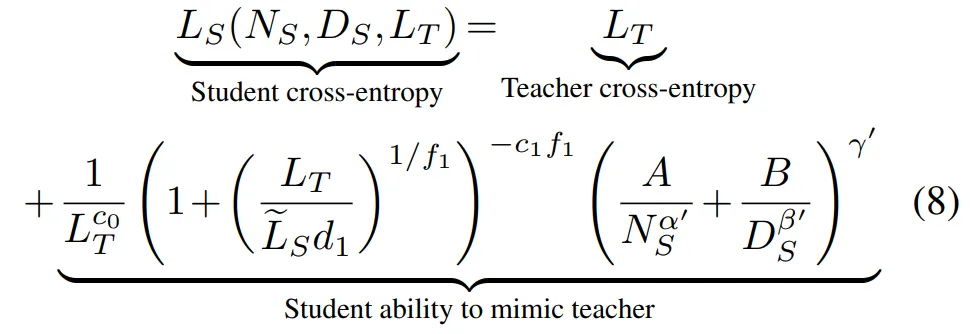
1. 一个大小为 N_S 的学生模型,通过从大小为 N_T 的教师模型中蒸馏 D_S 个 token 所得到的交叉熵,可以通过蒸馏扩展定律(公式 8)进行预测。
2. 老师大小 N_T 和老师训练 token 数量 D_T 仅通过确定老师的交叉熵 L_T = L_T (N_T , D_T) 来确定学生交叉熵;
3. 老师交叉熵对学生损失的影响遵循幂律,该幂律根据学生和老师的相对学习能力在两种行为之间转换,反映了蒸馏中称为能力差距的现象,即较强的老师会产生较差的学生。该工作的参数化解决了有关能力差距悬而未决的问题,表明这是老师和学生之间学习能力(假设空间和优化能力)的差距,而不仅仅是他们的相对大小,后者其实是一种特殊情况。
该结果表明,当两个学习过程都有足够的数据或计算时,蒸馏不能产生比监督学习更低的模型交叉熵。但是,如果以下两个条件都成立,则蒸馏比监督学习更有效:
1. 用于学生的总计算或 token 不大于新扩展定律给出的学生大小相关阈值;
2. 老师已经存在,或者要训练的老师有超出单次蒸馏的用途。
新的定律和分析有望指导 AI 社区构建更强大的模型,实现更低的推理成本和总计算成本。
蒸馏扩展率
文章概述了他们如何得出蒸馏扩展率所采取的步骤。
首先是实验设置。本文的目标是理解教师模型在蒸馏过程中的作用,因此,该研究在纯蒸馏情况下(λ = 1,公式 7)进行蒸馏,以避免数据带来的混淆。本文验证了 λ = 1 的选择能够产生与最优 λ∗ 统计相似的结果。同样,所有实验均使用蒸馏温度(τ = 1),因为该研究发现这能产生性能最佳的学生模型。

表 1 是文中出现的符号代表内容:


对应中文版本
此外,对于实验数据的选择,本文结合了三种方案:
固定 M 的教师 / 学生 IsoFLOP 实验:
本文预测在固定教师模型的情况下,学生模型的参数(N_S)和训练 token 数量(D_S)之间会呈现出幂律行为。
为了在给定的计算预算内生成尽可能多样的教师模型,本文训练了六个 Chinchilla 最优教师模型,其参数范围从 1.98 亿到 77.5 亿。对于每一个教师模型,本文按照标准训练成本,将其蒸馏到具有四种 IsoFLOP 配置的学生模型中。最终得到的学生模型交叉熵如图 2 所示。作者还注意到,在某些情况下,学生模型能够超越教师模型的表现,即展现出弱到强的泛化能力。

注:为实现扩展系数的可靠识别,此前有研究使用了两种策略:
- (固定模型,变化数据) 对于一个固定的模型族,变化训练 token 的数量。
- (IsoFLOP 配置) 在总计算约束下,同时变化模型大小和训练 token 的数量。
为了确保实验能够检测到这种影响,本文设定学生(N_S,D_S)是固定的,而 N_T 和 D_T 在计算约束下变化。本文进行了蒸馏实验,将四个 Chinchilla 最优(M_S = D_S/N_S ≈ 20)的学生(其参数范围从 1.98 亿到 18.2 亿),从根据四种 IsoFLOP 配置训练的教师中蒸馏出来。最终得到的学生交叉熵如图 3 所示。

最后,本文训练了固定 M 的教师模型与固定 M 的学生模型的组合,其中包含十个教师模型(M_T ≈ 20)和五种规模的学生模型,每个学生模型至少对应四种 M_S 选择。其中两个学生模型的交叉熵结果如图 4 所示。

此外,本文还需要确定蒸馏扩展定律的函数形式。首先,本文观察到教师模型的大小 N_T 和预训练 token 数量 D_T 的贡献可以通过教师模型的交叉熵 L_T 来总结。这可以从图 1 和图 3b 中看出:

总之,本文提出,学生交叉熵在 L_T 中遵循 broken 幂律,在 N_S 和 D_S 中遵循幂律:
在此之后,论文分析了在不同计算预算下如何最优地分配教师和学生模型的资源,包括教师模型的训练成本和学生模型的蒸馏成本,并比较了蒸馏和监督学习在不同计算预算下的性能,发现当教师模型的训练成本被考虑时,监督学习通常更有效。
这项工作代表了已知最大规模的蒸馏受控实证研究,系统消融了常见的蒸馏技术。正如监督扩展减轻了监督预训练中的风险一样,新工作为生产更小、更强大的模型提供了路线图,并增强了测试时扩展的可行性。
....
#TIGER
清华团队新算法玩转频域时域,压缩95%计算量实现语音分离新SOTA!
在嘈杂的环境中,人类能够专注于特定的语音信号,这种现象被称为「鸡尾酒会效应」。对于机器来说,如何从混合的音频信号中准确分离出不同的声源是一个重要的挑战。
语音分离(Speech Separation)能够有效提高语音识别的准确性,通常作为识别的前置步骤。因此,语音分离模型不仅需要在真实音频上输出分离良好的结果,同时还要满足低延迟的需求。
近年来,深度学习在语音分离任务中的应用受到了广泛关注。尽管许多高性能的语音分离方法被提出,但仍有两个关键问题未能得到充分解决:一是许多模型计算复杂度太高,未充分考虑实际应用场景的需求;二是常用的语音分离数据集与真实场景存在较大差距,导致模型在真实数据上的泛化能力不足。
为了解决这些问题,清华大学的研究团队设计了一种名为 TIGER(Time-frequency Interleaved Gain Extraction and Reconstruction network)的轻量级语音分离模型,并提出了一个新的数据集 EchoSet,旨在更真实地模拟复杂声学环境中的语音分离任务。
实验结果表明,TIGER 在压缩 94.3% 参数量和 95.3% 计算量的同时,性能与当前最先进的模型 TF-GridNet [1] 相当。
论文标题:TIGER: Time-frequency Interleaved Gain Extraction and Reconstruction for Efficient Speech Separation
论文链接:https://arxiv.org/pdf/2410.01469
项目主页:https://cslikai.cn/TIGER
GitHub 链接:https://github.com/JusperLee/TIGER
数据链接:https://huggingface.co/datasets/JusperLee/EchoSet
方法
语音分离任务的核心是从混合的音频信号中恢复出每个说话者的清晰语音。传统的语音分离模型通常直接在时域或频域进行处理,但往往忽略了时间和频率维度之间的交互信息。为了更高效地提取语音特征,TIGER 模型采用了时频交叉建模的策略,结合频带切分和多尺度注意力机制,显著提升了分离效果。
TIGER 模型的整体流程可以分为五个主要部分:编码器、频带切分模块、分离器、频带恢复模块和解码器。首先,通过短时傅里叶变换(STFT)将混合音频信号转换为时频表示。接着,将整个频带划分为多个子带,每个子带通过一维卷积转换为统一的特征维度。分离器由多个时频交叉建模模块(FFI)组成,用于提取每个说话者的声学特征。最后,频带恢复模块将子带恢复到全频带范围,并通过逆短时傅里叶变换(iSTFT)生成每个说话者的清晰语音信号。

TIGER 整体流程
频带切分
语音信号的能量分布在不同频带上并不均匀,中低频带通常包含更多的语音信息,而高频带则包含更多的噪声和细节信息。为了减少计算量并提升模型对关键频带的关注,TIGER 采用了频带切分策略,根据重要性将频带划分为不同宽度的子带。这种策略不仅减少了计算量,还能让模型更专注于重要的频带,从而提升分离效果。
分离器
语音信号的时间和频率维度之间存在复杂的交互关系。为了更高效地建模这种交互关系,TIGER 引入了时频交叉建模模块(FFI)。为了减少参数,分离器由多个共享参数的 FFI 模块构成。每个 FFI 模块包含两个路径:频率路径和帧路径。
每个路径都包含两个关键子模块:多尺度选择性注意力模块(MSA)和全频 / 帧注意力模块(F³A)。通过交替处理时间和频率信息,FFI 模块能够有效地整合时频特征,提升语音分离的效果。

FFI 模块内部细节
多尺度选择性注意力模块(MSA)
为了增强模型对多尺度特征的提取能力,TIGER 引入了 MSA,通过多尺度卷积层和选择性注意力机制,融合局部和全局信息。MSA 模块分为三个阶段:编码、融合和解码。
以频率路径为例,在编码阶段,通过多个一维卷积层逐步下采样频率维度,提取多尺度的声学特征。在融合阶段,使用选择性注意力机制将局部特征和全局特征进行融合,生成包含多尺度信息的特征。在解码阶段,通过上采样和卷积操作逐步恢复频率维度,最终输出增强后的频率特征。

MSA 模块内部细节(以频率路径为例)
全频 / 帧注意力模块(F³A)
为了捕捉长距离依赖关系,TIGER 采用了全 / 频帧注意力模块(F³A)。同样以频率路径为例,首先采用二维卷积将输入特征转换为查询(Query)、键(Key)和值(Value),然后将特征维度和时间维度合并,得到每个频带对应的全帧信息。
通过自注意机制计算频率维度上的注意力权重,用于加强频带间关系的捕捉,提升语音分离的效果。

F³A 模块内部细节(以频率路径为例)
EchoSet:更接近真实声学场景
的语音分离数据集
现有的语音分离数据集往往与真实世界的声学环境存在较大差距,导致模型在实际应用中的泛化能力不足。为了更真实地模拟复杂声学环境中的语音分离任务,研究团队提出了 EchoSet 数据集,该数据集不仅包含噪声,还模拟了真实的混响效果(如考虑物体遮挡和材料特性),并且说话人之间语音重叠比例是随机的。

不同数据集特性对比
EchoSet 数据集的构建基于 SoundSpaces 2.0 平台 [2] 和 Matterport3D 场景数据集 [3],能够模拟不同声学环境中的语音混响效果。通过随机采样语音和噪声,并考虑房间的几何形状和材料特性,EchoSet 数据集生成了包含 20,268 条训练语音、4,604 条验证语音和 2,650 条测试语音的高保真数据集。
实验表明,使用 EchoSet 训练的模型在真实世界数据上的泛化能力显著优于其他数据集训练的模型,验证了 EchoSet 的实用价值。

常见语音分离模型在不同数据集上训练后,在真实世界采集数据上的泛化性能比较
实验
研究团队在多个数据集上对 TIGER 进行了全面评估,包括 Libri2Mix、LRS2-2Mix 和 EchoSet。实验结果显示,随着数据集的复杂性增加,TIGER 的性能优势越加显著。在 EchoSet 数据集上,TIGER 的性能比 TF-GridNet 提升了约 5%,同时参数量和计算量分别减少了 94.3% 和 95.3%。在真实世界采集的数据上(见上图),TIGER 同样表现出了最佳的分离性能。


常见语音分离模型性能和效率比较
研究团队通过进一步压缩参数,探索了 TIGER 的轻量化潜力。在 100K 的参数规模下,TIGER(tiny)在 Echoset 上的性能显著优于基 GC3 方法 [4] 压缩的 SudoRM-RF 模型 [5],表明 TIGER 在参数量和计算成本较低的情况下,仍能提供卓越的语音分离性能。

SudoRM-RF + GC3 与 TIGER (tiny) 的性能和效率比较
此外,TIGER 在电影音频分离任务中也表现出了强大的泛化能力。实验结果显示,TIGER 在分离电影音频中的语音、音乐和音效时,在保持轻量的情况下,性能显著优于其他模型,进一步验证了其在复杂声学环境中的适用性。

TIGER 在电影音频分离任务上的性能和效率
,时长00:25
《流浪地球 2》宣传片原片
,时长00:25
用 TIGER 分离出《流浪地球 2》宣传片中人声的效果
,时长00:25
用 TIGER 分离《流浪地球 2》宣传片中音效的效果
,时长00:25
用 TIGER 分离《流浪地球 2》宣传片中背景音乐的效果
结论
TIGER 模型的提出为语音分离任务提供了一种新的解决方案,通过频带切分和基于多尺度注意力机制的时频交替建模模块,在保持高性能的同时,显著降低了参数量和计算成本。EchoSet 数据集的引入也为语音分离模型的训练和评估提供了更接近真实世界的数据支持。实验结果表明,TIGER 在复杂声学环境中的表现优于现有模型,并且在计算资源受限的场景下具有广泛的应用前景。
....

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献85条内容
已为社区贡献85条内容

所有评论(0)