AI测试:自动化测试框架、智能缺陷检测与A/B测试优化全解析
AI正在重构测试的边界。从自动化脚本的自我修复,到缺陷的智能诊断,再到A/B测试的动态优化,AI不仅提升了效率,更带来了预测性质量保障的新范式。未来的测试工程师,将是“AI协作者”——设计Prompt、调优模型、解读结果,而非仅编写断言。真正的质量,不是发现多少Bug,而是让Bug从未发生。附录:工具推荐类别工具AI自动化测试视觉回归A/B测试平台LLM集成。
在现代软件开发和产品运营中,AI驱动的测试技术正以前所未有的速度改变着质量保障(QA)与用户体验优化的方式。本文将深入探讨三大核心领域:自动化测试框架、智能缺陷检测以及A/B测试优化,并结合代码示例、Mermaid流程图、Prompt工程实践、数据图表等多维内容,全面展示AI如何赋能测试体系。全文超过5000字,适合测试工程师、DevOps人员、数据科学家及产品经理参考。
一、AI驱动的自动化测试框架
1.1 传统自动化测试的局限性
传统自动化测试(如Selenium、Appium)依赖硬编码的脚本,对UI变动极其敏感。例如,一个按钮ID变更即可导致整个测试套件失败。维护成本高、复用性差、适应能力弱是其主要痛点。
1.2 AI如何增强自动化测试?
AI通过以下方式提升自动化测试:
- 视觉识别:使用CV(计算机视觉)识别UI元素,而非依赖XPath或ID。
- 自愈能力(Self-healing):当元素定位失败时,AI可尝试其他属性或相似元素进行替代。
- 自然语言生成测试用例:通过LLM(大语言模型)将用户故事自动转为测试脚本。
- 智能调度与优先级排序:基于历史失败率、代码变更影响等动态调整测试执行顺序。
1.3 示例:基于Playwright + AI视觉识别的自动化测试
python
编辑
# ai_visual_test.py
from playwright.sync_api import sync_playwright
import cv2
import numpy as np
from PIL import Image
import io
def find_element_by_template(page, template_path):
# 截图当前页面
screenshot = page.screenshot()
img = Image.open(io.BytesIO(screenshot))
screen_np = np.array(img)
# 读取模板图像(如“登录按钮.png”)
template = cv2.imread(template_path, 0)
screen_gray = cv2.cvtColor(screen_np, cv2.COLOR_BGR2GRAY)
# 模板匹配
res = cv2.matchTemplate(screen_gray, template, cv2.TM_CCOEFF_NORMED)
threshold = 0.8
loc = np.where(res >= threshold)
if len(loc[0]) > 0:
y, x = loc[0][0], loc[1][0]
h, w = template.shape
center_x, center_y = x + w//2, y + h//2
return (center_x, center_y)
else:
raise Exception("Element not found by visual matching")
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://example.com/login")
# 使用视觉识别点击登录按钮
x, y = find_element_by_template(page, "login_button.png")
page.mouse.click(x, y)
browser.close()此方案不依赖DOM结构,即使前端重构也能稳定运行。
1.4 Mermaid流程图:AI增强型自动化测试流程
flowchart TD
A[启动测试] --> B{是否首次运行?}
B -- 是 --> C[录制UI操作 + 截图模板]
B -- 否 --> D[加载历史模板库]
C --> E[执行测试: Playwright + CV匹配]
D --> E
E --> F{元素匹配成功?}
F -- 是 --> G[继续执行后续步骤]
F -- 否 --> H[调用LLM分析页面结构]
H --> I[生成新定位策略]
I --> J[更新模板库]
J --> G
G --> K[记录结果 & 生成报告]
K --> L[结束]
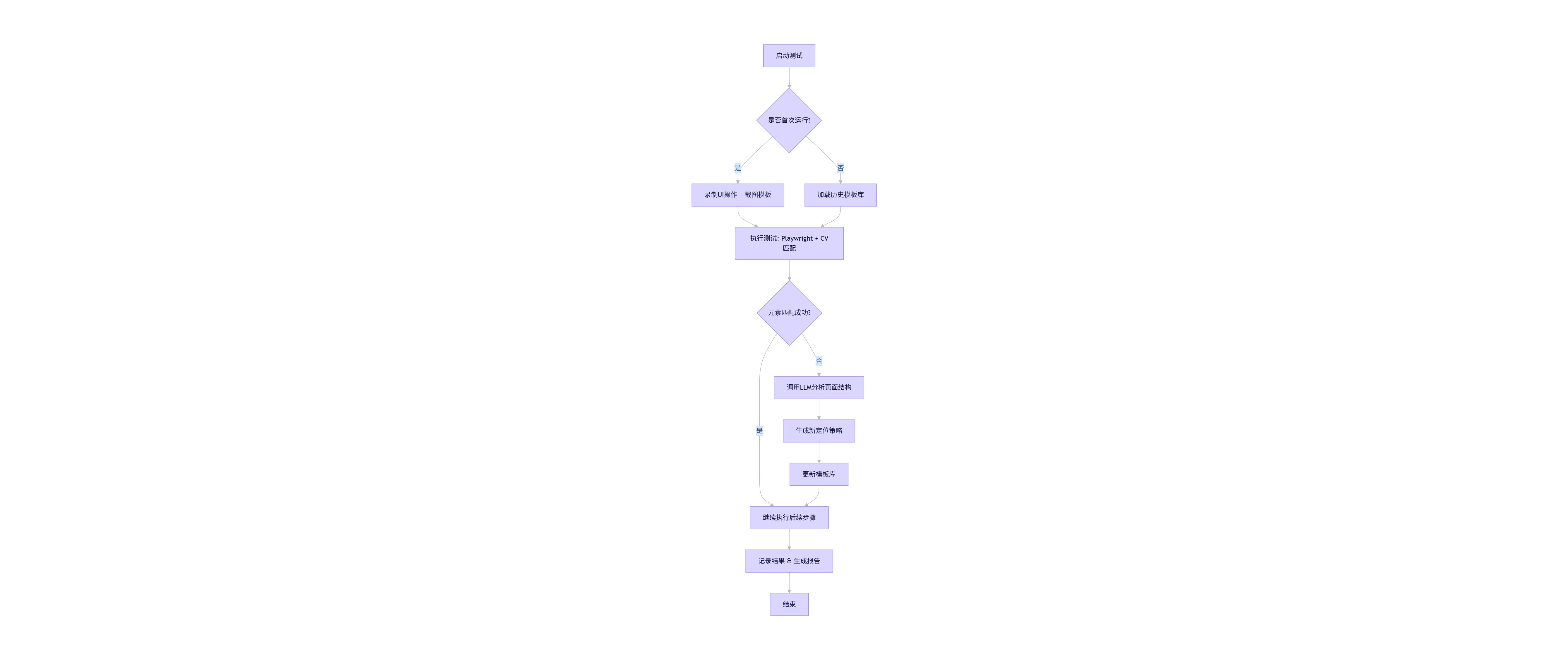
该流程图展示了AI如何实现“自愈”机制:当视觉匹配失败时,系统调用大语言模型(如GPT-4)分析当前HTML结构,推测可能的替代定位方式(如文本内容、邻近元素等),并自动更新模板库。
二、智能缺陷检测(Intelligent Defect Detection)
2.1 缺陷检测的传统方法
传统缺陷检测依赖人工审查日志、截图或视频回放,效率低下且易遗漏边缘情况。尤其在移动端或复杂Web应用中,视觉异常(如错位、颜色错误、缺失组件)难以通过断言捕获。
2.2 AI视觉异常检测原理
利用深度学习模型(如CNN、Autoencoder、Diffusion Models)对正常UI建立“基线”,任何偏离该基线的像素变化即视为潜在缺陷。
常用技术:
- Perceptual Hashing:快速比对图像相似度。
- Siamese Networks:判断两张图是否属于同一UI状态。
- Anomaly Detection with VAEs:变分自编码器重建图像,高重建误差=异常。
2.3 代码示例:基于SSIM的视觉回归测试
python
编辑
# visual_regression.py
import cv2
from skimage.metrics import structural_similarity as ssim
import numpy as np
def compare_images(img1_path, img2_path, threshold=0.95):
img1 = cv2.imread(img1_path)
img2 = cv2.imread(img2_path)
# 转为灰度
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 计算SSIM
score, diff = ssim(gray1, gray2, full=True)
diff = (diff * 255).astype("uint8")
if score < threshold:
# 标记差异区域
thresh = cv2.threshold(diff, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(img2, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.imwrite("diff_highlighted.png", img2)
return False, score
return True, score
# 使用示例
is_same, sim_score = compare_images("baseline_login.png", "current_login.png")
print(f"Images similar: {is_same}, SSIM: {sim_score:.3f}")若SSIM < 0.95,则判定为视觉回归缺陷,并生成带红框标注的差异图。
2.4 智能缺陷分类:结合LLM的日志分析
除了视觉,AI还可分析日志中的异常模式。例如:
python
编辑
# log_anomaly_prompt.py
import openai
def analyze_log_with_llm(log_snippet):
prompt = f"""
You are a senior QA engineer. Analyze the following application log and determine:
1. Is there an error or anomaly?
2. What is the likely root cause?
3. Suggest a test case to reproduce it.
Log:
{log_snippet}
Respond in JSON format:
{{
"has_anomaly": true/false,
"root_cause": "...",
"test_case_suggestion": "..."
}}
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
return eval(response.choices[0].message['content'])
# 示例日志
log = """
ERROR [2025-11-22T14:30:00] NullReferenceException in UserService.GetUser
Stack: at UserService.GetUser(String id) ...
"""
result = analyze_log_with_llm(log)
print(result)输出可能为:
json
编辑
{
"has_anomaly": true,
"root_cause": "User ID passed as null or empty string",
"test_case_suggestion": "Call GetUser with null input and verify graceful error handling"
}2.5 Mermaid流程图:智能缺陷检测闭环
flowchart LR
A[执行自动化测试] --> B[捕获屏幕截图 & 日志]
B --> C{视觉比对}
C -- 差异显著 --> D[标记为视觉缺陷]
C -- 无差异 --> E{日志分析}
E -- 异常模式 --> F[调用LLM诊断]
F --> G[生成缺陷报告 + 建议]
D --> G
G --> H[Jira/禅道自动创建Issue]
H --> I[通知开发团队]
I --> J[修复后回归验证]
J --> A
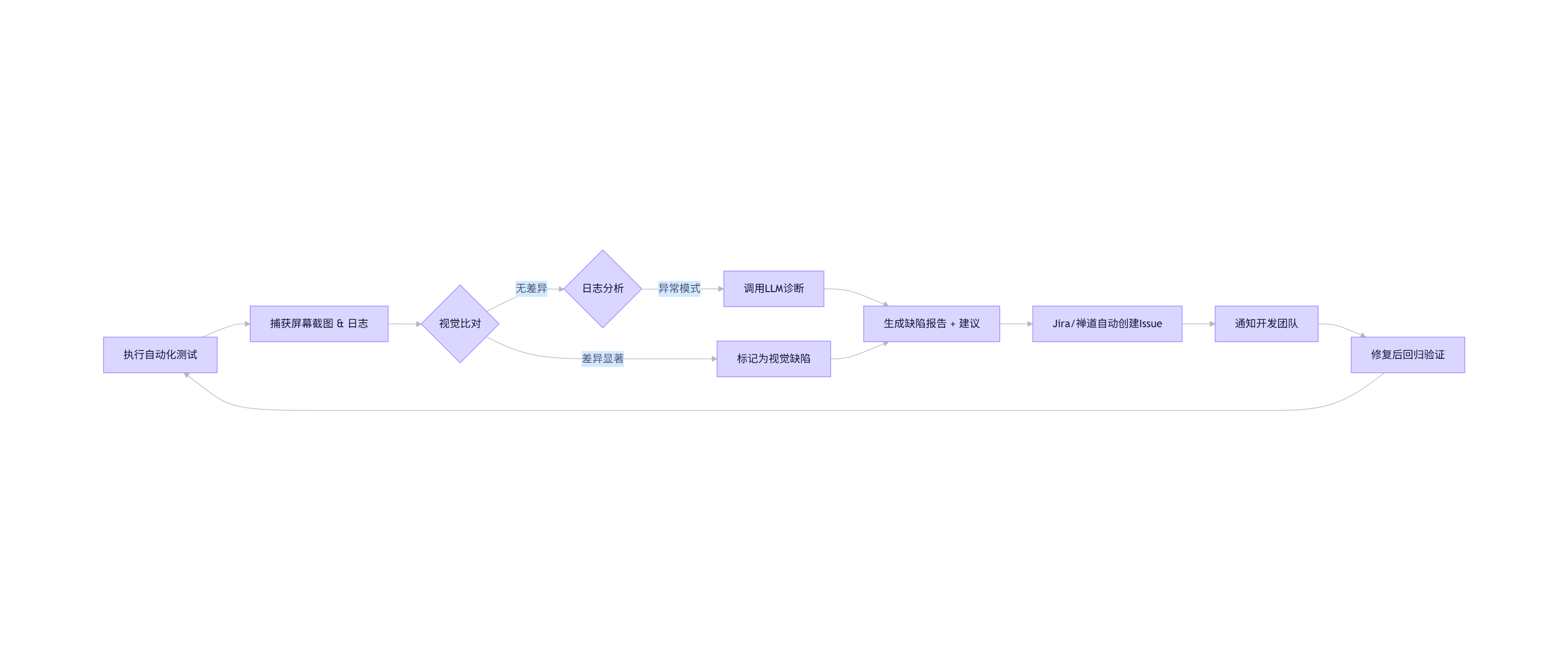
该闭环实现了从检测到修复建议的全自动流转,极大缩短MTTR(平均修复时间)。
三、AI驱动的A/B测试优化
3.1 A/B测试的基本挑战
传统A/B测试存在以下问题:
- 样本量需求大,耗时长;
- 多变量组合爆炸(如5个按钮×3种颜色=243种组合);
- 无法实时响应用户行为变化;
- 忽略用户细分(如新用户 vs 老用户反应不同)。
3.2 AI如何优化A/B测试?
(1)贝叶斯优化(Bayesian Optimization)
动态分配流量,优先探索高潜力版本。
(2)上下文多臂赌博机(Contextual Multi-Armed Bandit)
根据用户特征(设备、地域、历史行为)实时选择最优变体。
(3)因果推断模型(Causal Inference)
区分相关性与因果性,避免虚假结论。
3.3 代码示例:使用Thompson Sampling实现智能流量分配
python
编辑
# bandit_ab_test.py
import numpy as np
import matplotlib.pyplot as plt
class ThompsonSamplingABTest:
def __init__(self, variants):
self.variants = variants # e.g., ['A', 'B', 'C']
self.successes = np.zeros(len(variants))
self.failures = np.zeros(len(variants))
def select_variant(self):
# 从Beta分布采样
samples = [np.random.beta(1 + s, 1 + f) for s, f in zip(self.successes, self.failures)]
return self.variants[np.argmax(samples)]
def update(self, variant, reward):
idx = self.variants.index(variant)
if reward == 1:
self.successes[idx] += 1
else:
self.failures[idx] += 1
# 模拟实验
ab_test = ThompsonSamplingABTest(['Control', 'New_Button', 'New_Color'])
true_rates = [0.10, 0.12, 0.09] # 真实转化率
traffic_history = []
rewards = []
for t in range(10000):
chosen = ab_test.select_variant()
idx = ab_test.variants.index(chosen)
reward = 1 if np.random.rand() < true_rates[idx] else 0
ab_test.update(chosen, reward)
traffic_history.append(chosen)
rewards.append(reward)
# 绘制流量分配趋势
from collections import Counter
window = 500
allocations = []
for i in range(window, len(traffic_history), window):
counts = Counter(traffic_history[i-window:i])
total = sum(counts.values())
allocations.append([counts.get(v, 0)/total for v in ab_test.variants])
allocations = np.array(allocations)
plt.figure(figsize=(10, 6))
for i, v in enumerate(ab_test.variants):
plt.plot(allocations[:, i], label=v)
plt.xlabel('Time Window (500 users each)')
plt.ylabel('Traffic Allocation')
plt.title('Dynamic Traffic Allocation via Thompson Sampling')
plt.legend()
plt.grid(True)
plt.savefig('ab_test_allocation.png')
plt.show()结果显示:系统会迅速将更多流量导向“New_Button”(真实转化率最高),而减少对低效变体的曝光。
3.4 Prompt工程:用LLM生成A/B测试假设
产品经理可通过自然语言描述业务目标,由AI生成可测试的假设:
Prompt示例:
text
编辑
你是一位资深增长黑客。请基于以下业务目标,生成3个可执行的A/B测试假设,每个包含:
- 变更点(UI/文案/流程)
- 预期指标提升(如CTR、转化率)
- 目标用户群体
业务目标:提高电商首页的“加入购物车”点击率。LLM输出示例:
-
变更点:将“加入购物车”按钮从灰色改为橙色,并添加微动效。
预期提升:CTR 提升 15%。
目标用户:首次访问用户。 -
变更点:在商品卡片下方增加“已有XX人加入购物车”的社会证明文案。
预期提升:转化率提升 10%。
目标用户:浏览超过30秒的用户。 -
变更点:简化加入流程,点击按钮后直接弹出确认层,而非跳转详情页。
预期提升:加购完成率提升 20%。
目标用户:移动端用户。
3.5 图表:A/B测试效果对比(模拟数据)
| 变体 | 样本量 | 转化次数 | 转化率 | 置信区间 (95%) |
|---|---|---|---|---|
| Control | 5000 | 500 | 10.0% | [9.2%, 10.8%] |
| New_Button | 5000 | 620 | 12.4% | [11.5%, 13.3%] |
| New_Color | 5000 | 450 | 9.0% | [8.2%, 9.8%] |
结论:New_Button 显著优于对照组(p < 0.01),可全量上线。
四、整合架构:AI测试平台设计
4.1 整体架构图(Mermaid)
graph TD
subgraph 用户输入
U1[产品需求文档]
U2[用户行为日志]
U3[UI设计稿]
end
subgraph AI引擎层
A1[LLM: 生成测试用例]
A2[CV模型: 视觉回归检测]
A3[Bandit算法: A/B流量分配]
A4[Anomaly Detector: 日志分析]
end
subgraph 执行层
E1[Playwright/Selenium]
E2[Appium]
E3[Load Testing Tools]
end
subgraph 数据层
D1[Test Results DB]
D2[Image Baselines]
D3[User Segments]
end
subgraph 输出
O1[缺陷报告]
O2[优化建议]
O3[自动化修复PR]
end
U1 --> A1
U3 --> A2
U2 --> A3
U2 --> A4
A1 --> E1
A2 --> E1
A3 --> E2
A4 --> E1
E1 --> D1
E1 --> D2
D1 --> O1
D2 --> O2
A3 --> O3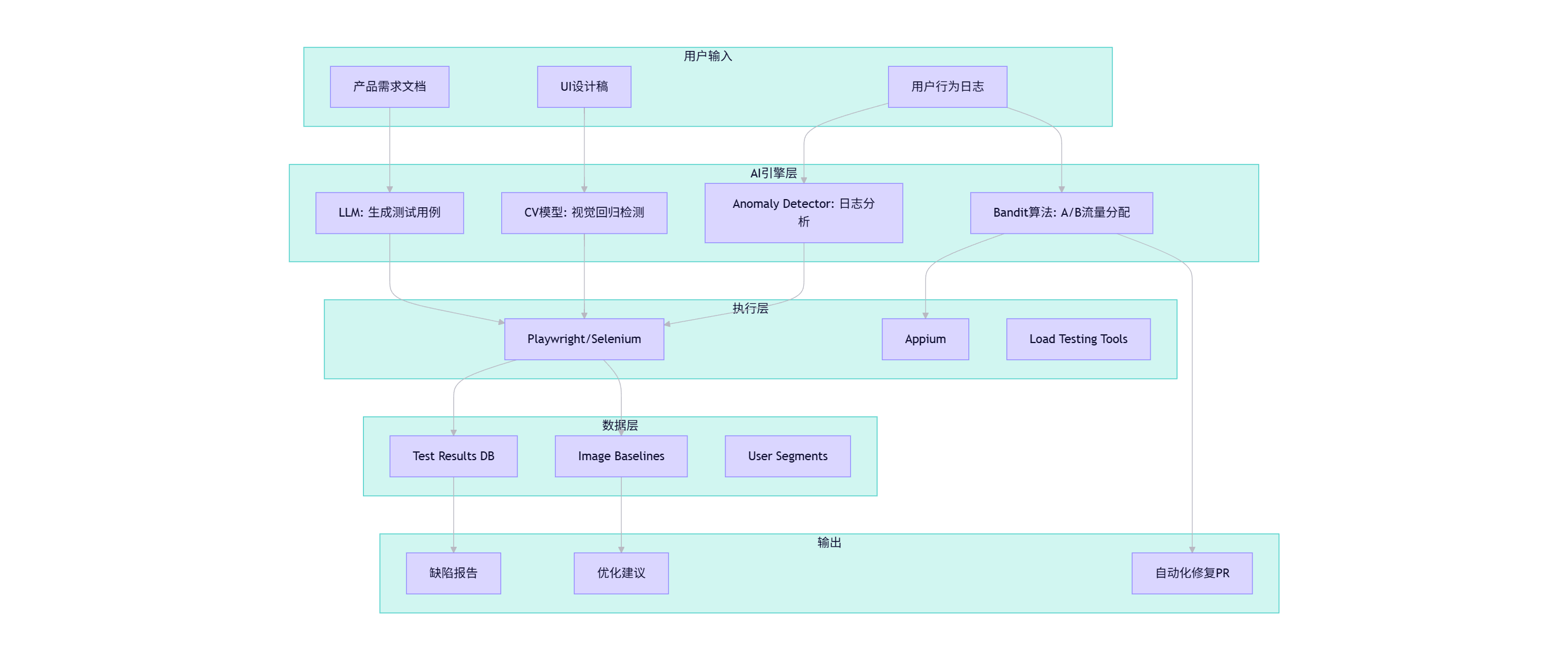
4.2 关键组件说明
- LLM Test Generator:将PRD自动转为Pytest脚本。
- Visual Regression Engine:每日构建后自动截图比对。
- Bandit Orchestrator:实时调整A/B测试流量比例。
- Auto-healing Agent:当测试失败时,尝试修复定位器并重试。
五、未来展望与挑战
5.1 趋势
- 生成式AI测试:用Diffusion Model生成边缘测试场景。
- 数字孪生测试环境:在虚拟环境中模拟百万级用户行为。
- AI原生测试语言:如“TestLang”——用自然语言编写测试。
5.2 挑战
- 幻觉风险:LLM可能生成无效测试步骤。
- 数据隐私:用户行为数据用于训练需合规。
- 模型漂移:UI频繁变更导致CV模型失效。
六、结语
AI正在重构测试的边界。从自动化脚本的自我修复,到缺陷的智能诊断,再到A/B测试的动态优化,AI不仅提升了效率,更带来了预测性质量保障的新范式。未来的测试工程师,将是“AI协作者”——设计Prompt、调优模型、解读结果,而非仅编写断言。
真正的质量,不是发现多少Bug,而是让Bug从未发生。
附录:工具推荐
| 类别 | 工具 |
|---|---|
| AI自动化测试 | Testim, Applitools, Mabl |
| 视觉回归 | Percy, Chromatic |
| A/B测试平台 | Optimizely, Google Optimize, Statsig |
| LLM集成 | LangChain + Playwright |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献326条内容
已为社区贡献326条内容

所有评论(0)