【Python大数据+AI毕设实战】国内各省高校数据分析可视化系统、计算机毕业设计、包括数据爬取、Spark、数据分析、数据可视化、Hadoop、实战教学
【Python大数据+AI毕设实战】国内各省高校数据分析可视化系统、计算机毕业设计、包括数据爬取、Spark、数据分析、数据可视化、Hadoop、实战教学
🎓 作者:计算机毕设小月哥 | 软件开发专家
🖥️ 简介:8年计算机软件程序开发经验。精通Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等技术栈。
🛠️ 专业服务 🛠️
- 需求定制化开发
- 源码提供与讲解
- 技术文档撰写(指导计算机毕设选题【新颖+创新】、任务书、开题报告、文献综述、外文翻译等)
- 项目答辩演示PPT制作
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
大数据实战项目
PHP|C#.NET|Golang实战项目
微信小程序|安卓实战项目
Python实战项目
Java实战项目
🍅 ↓↓主页获取源码联系↓↓🍅
这里写目录标题
基于大数据的国内各省高校数据分析可视化系统-功能介绍
本课题设计并实现了一套《基于大数据的国内各省高校数据分析可视化系统》,该系统旨在运用现代大数据技术,对我国高等教育资源的宏观分布与内在结构进行深度挖掘与直观呈现。系统整体采用前后端分离架构,后端核心基于Python语言构建,并利用Django框架作为Web支撑,以处理业务逻辑与API接口。为了应对海量高校数据的处理挑战,系统引入了Hadoop生态中的Spark作为分布式计算引擎,通过Spark SQL对存储在HDFS上的结构化数据进行高效的聚合、筛选与关联分析,充分发挥了大数据框架在处理大规模数据集时的性能优势。前端界面则采用Vue.js框架结合ElementUI组件库进行开发,确保了用户交互的流畅性与界面的现代化。在数据可视化方面,系统深度集成了ECharts图表库,将经过Spark和Pandas库复杂分析后的结果,以多样化的动态图表形式(如地图热力图、柱状图、饼图、散点图等)进行展现。系统功能覆盖了高校资源的空间分布、自身属性结构、区域与类型交叉分析以及基于聚类算法的综合实力挖掘等多个维度,为理解中国高等教育的现状与格局提供了一个全面、动态且数据驱动的分析平台。
基于大数据的国内各省高校数据分析可视化系统-选题背景意义
选题背景
随着我国高等教育的蓬勃发展,高校数量与规模持续增长,形成了一个庞大且复杂的体系。公众、教育研究者以及政策制定者对于高等教育资源的分布情况、结构特征和发展趋势日益关注。然而,传统的信息获取方式往往依赖于零散的官方报告或单一的大学排名,这些方式难以全面、客观地揭示全国两千多所高校在地理空间、学科类型、办学层次等方面的内在关联与差异。面对如此海量且多维度的数据,如何进行有效的整合与深度分析,成为了一个亟待解决的课题。大数据技术的兴起为此提供了全新的解决思路,它能够从宏观尺度上处理和分析大规模数据集,挖掘出传统方法难以发现的隐藏模式和规律。因此,利用大数据技术对国内高校信息进行系统性分析,不仅是技术上的一次有益尝试,也顺应了信息化时代对教育领域进行精细化、数据化管理与研究的需求。
选题意义
本课题的实际意义在于,它为理解我国高等教育资源的宏观布局提供了一个直观且有力的数据探索工具。对于教育研究者和规划者来说,系统通过可视化图表清晰展示了顶尖高校(如985/211)的地理集聚效应、不同省份在公办与民办教育上的发展侧重,以及各类学科(如理工、师范、医药)的区域性优势,这些分析结果能够为教育资源的均衡发展、学科建设的政策调整提供有价值的参考视角。对于即将步入大学的高中生及其家长而言,该系统超越了简单的排名,提供了一个多维度了解全国高校概况的窗口,帮助他们更全面地认识不同地区和类型的高校特点。从计算机专业的实践角度看,本课题完整地演示了如何将Hadoop、Spark等大数据处理技术与Web开发、数据可视化相结合,构建一个完整的数据分析应用,这为计算机专业的学生提供了一个极具参考价值的综合实战案例,展示了如何运用前沿技术解决社会科学领域的实际问题,具有一定的学习价值和示范作用。
基于大数据的国内各省高校数据分析可视化系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
基于大数据的国内各省高校数据分析可视化系统-图片展示

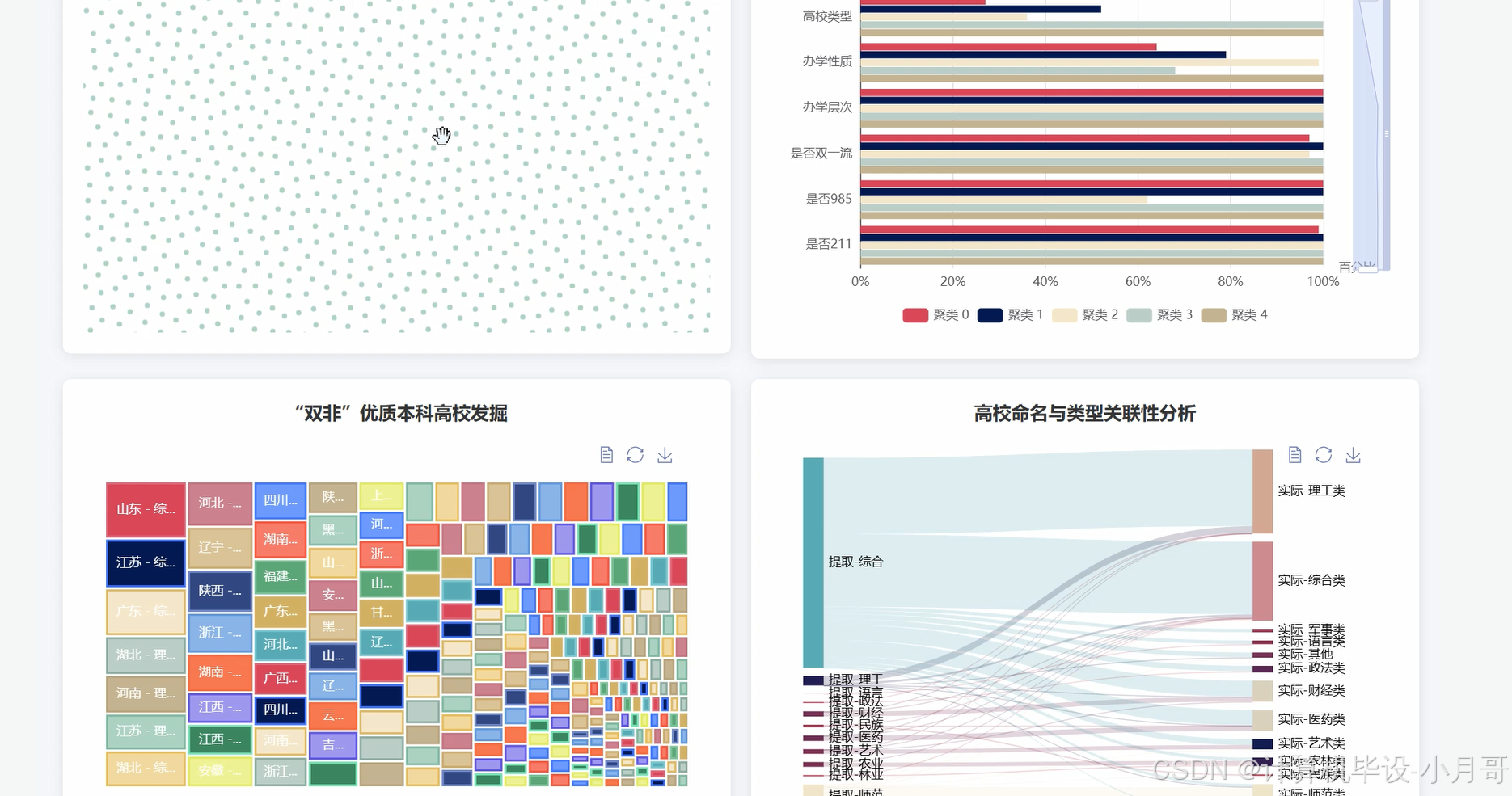
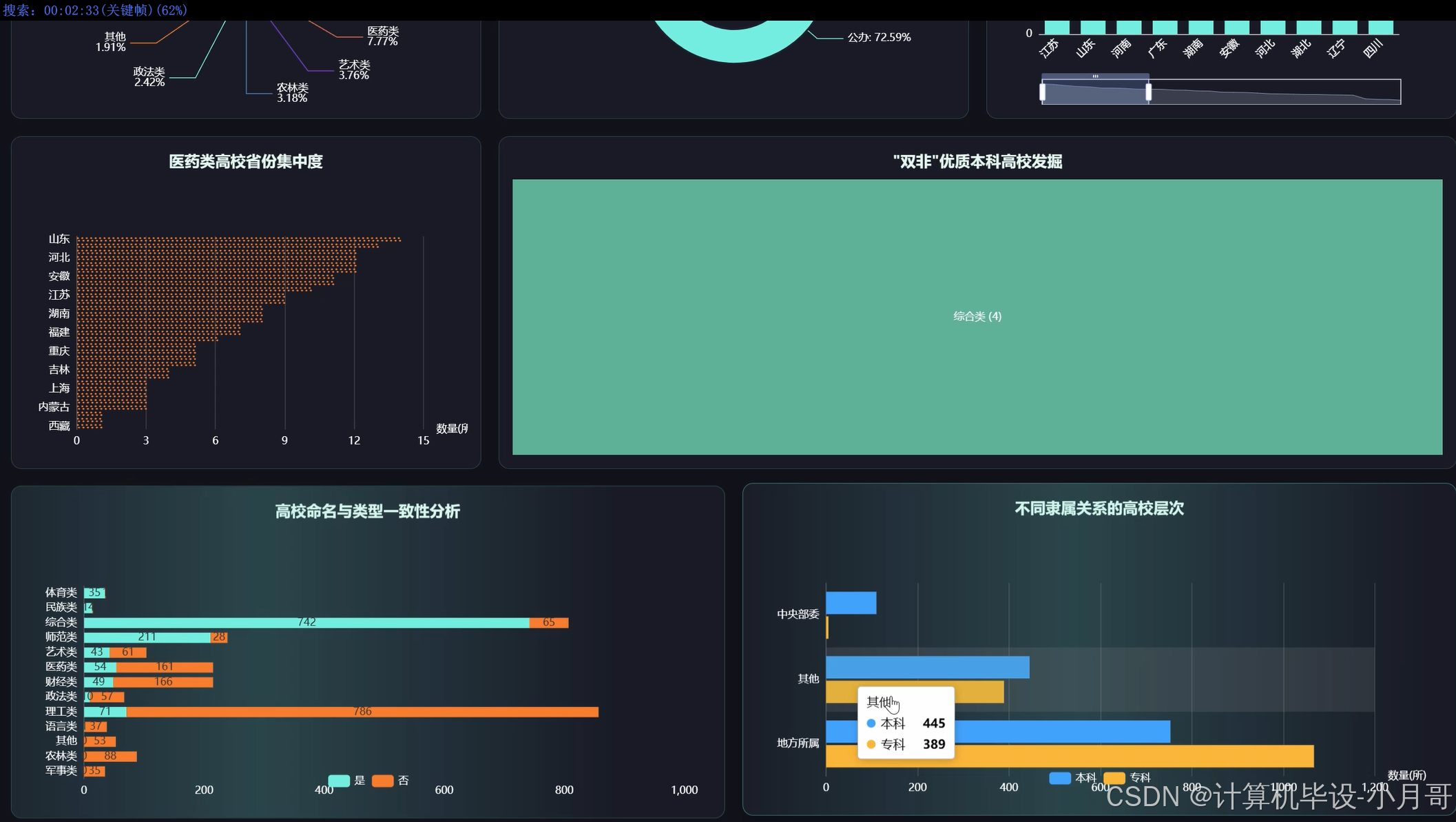
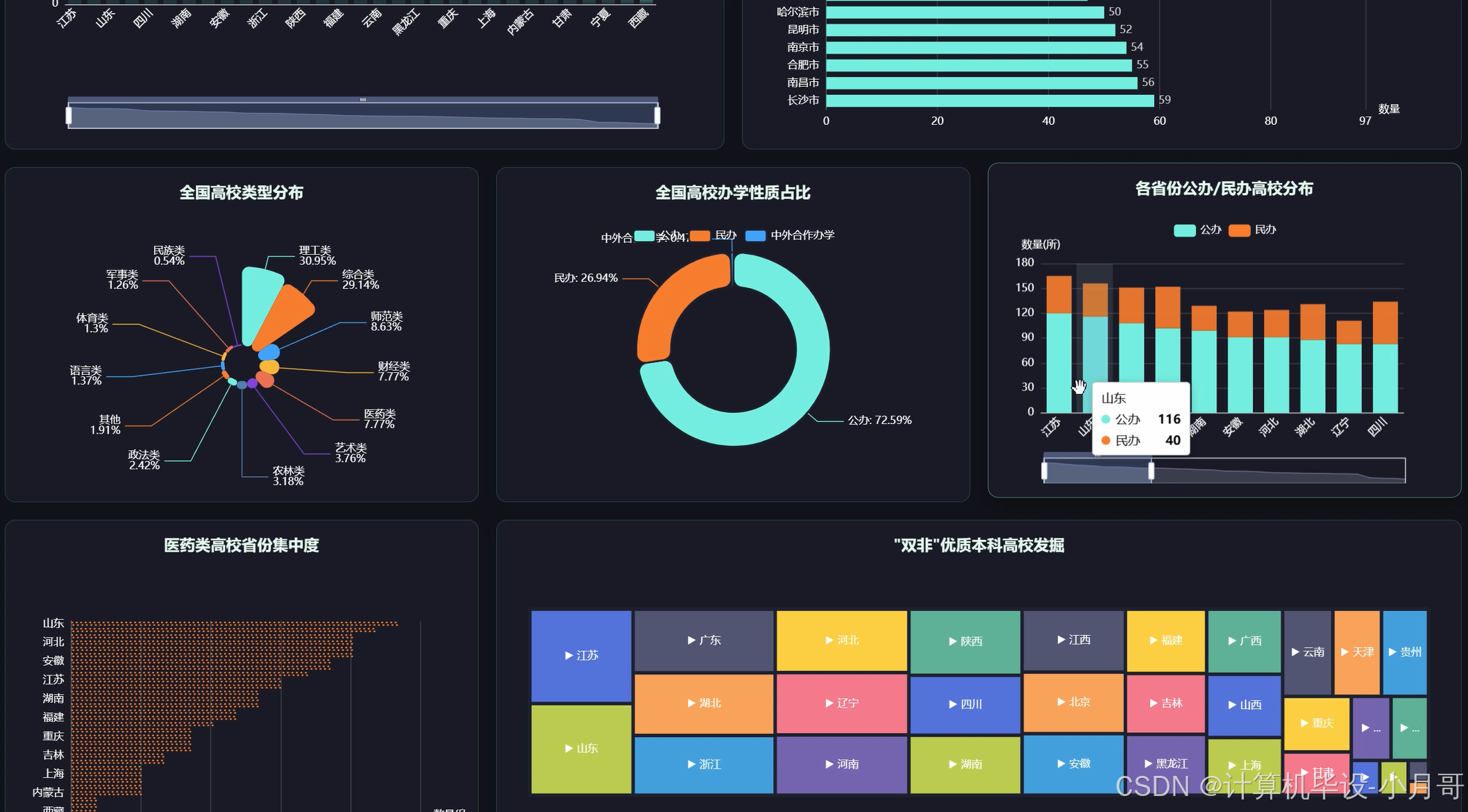
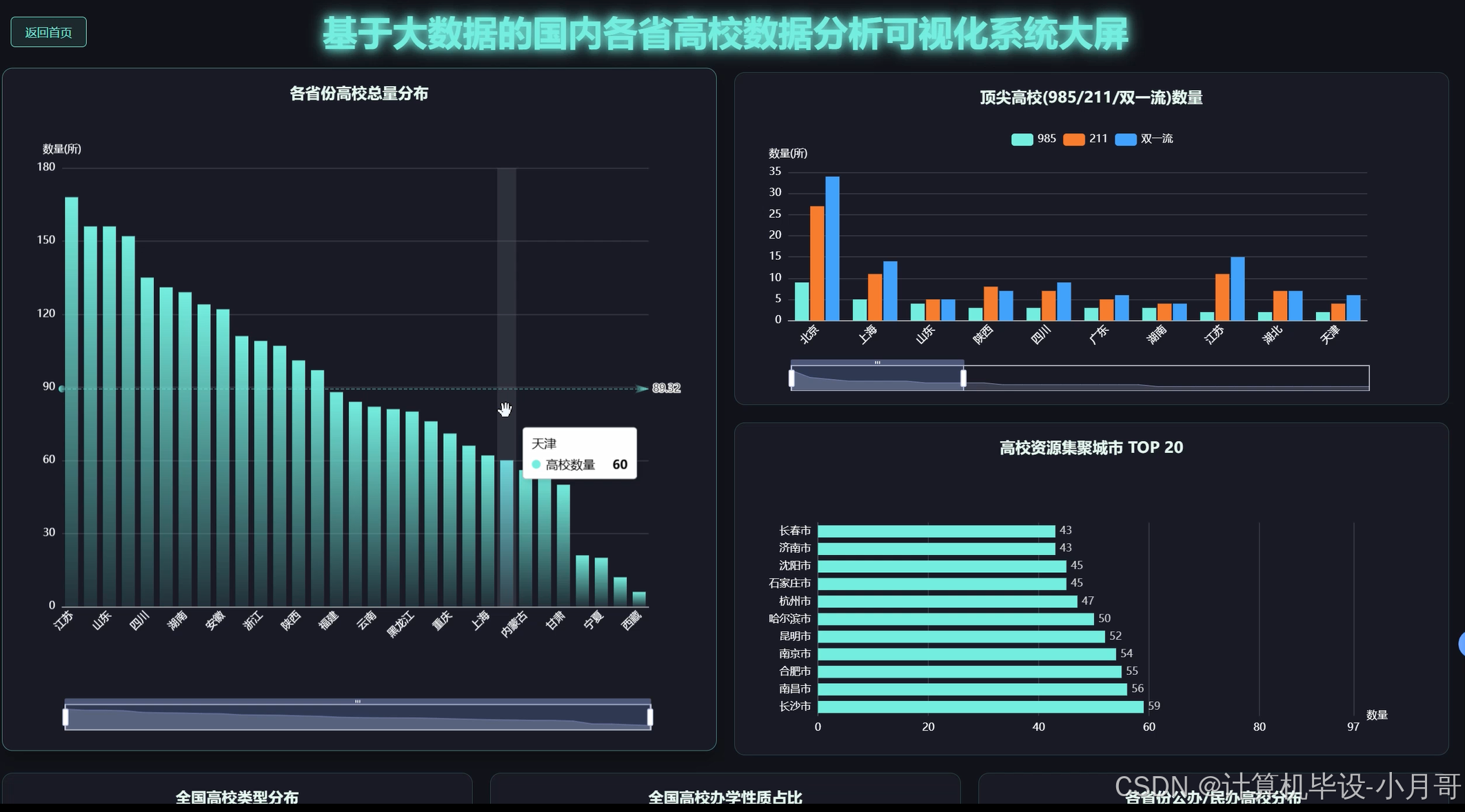
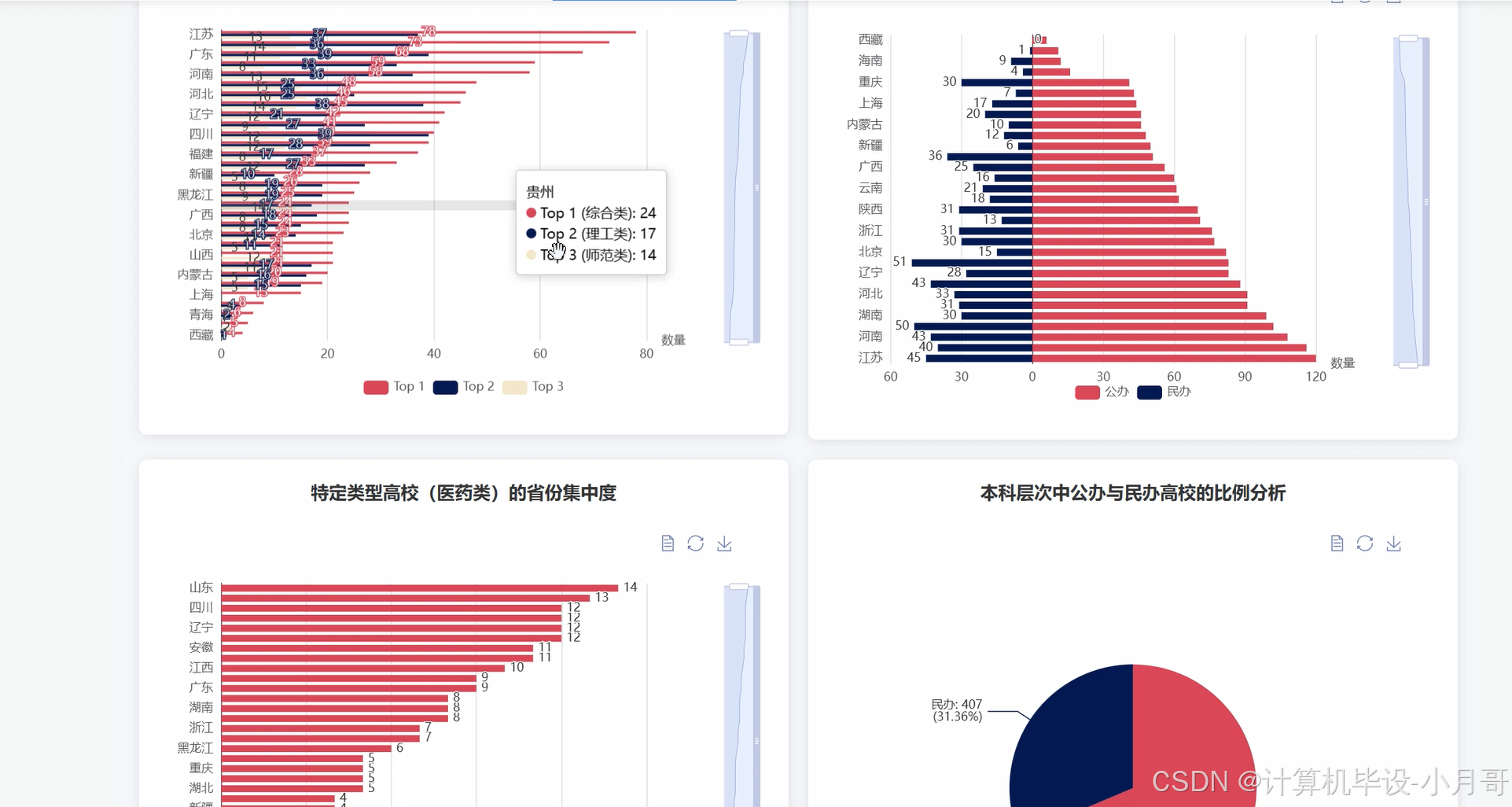
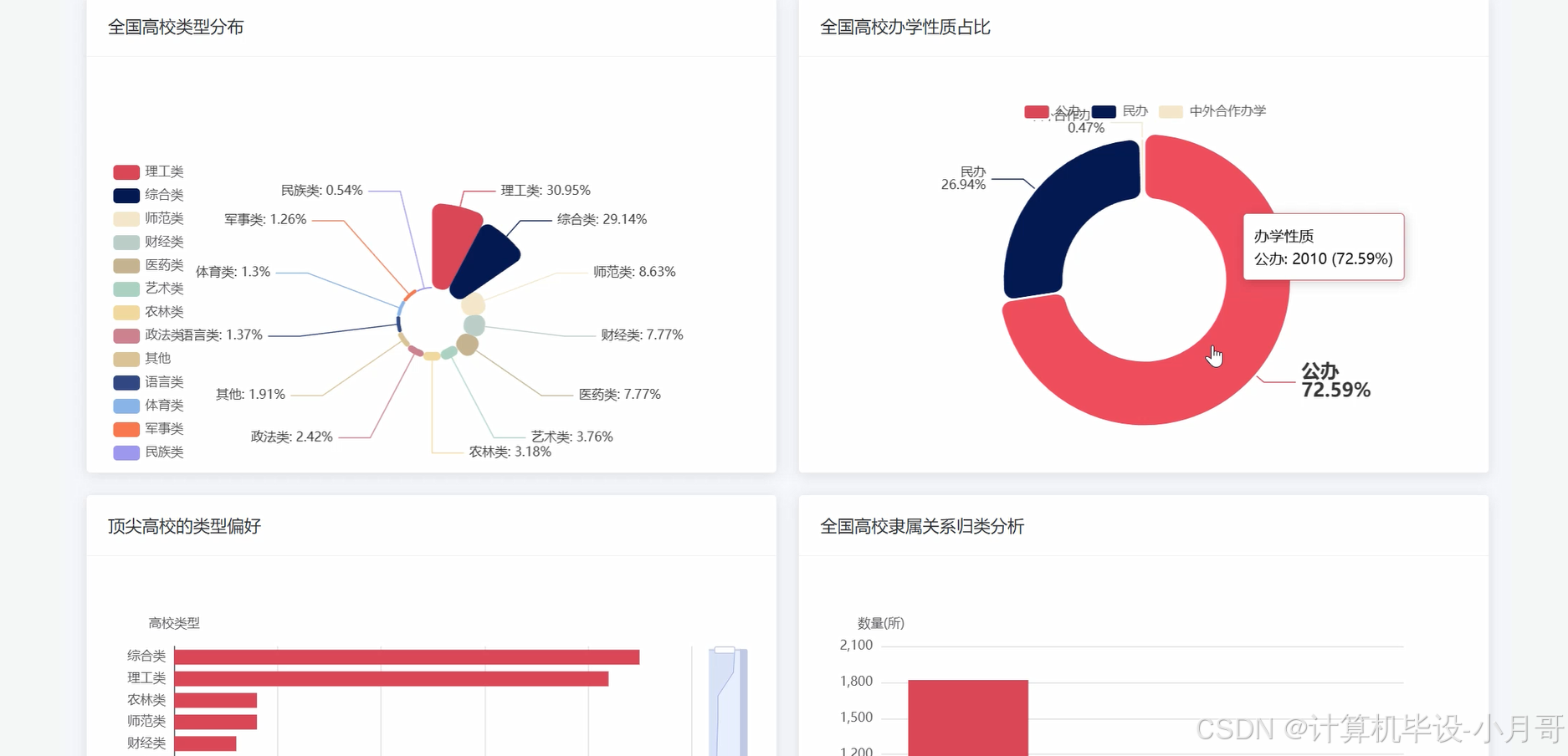
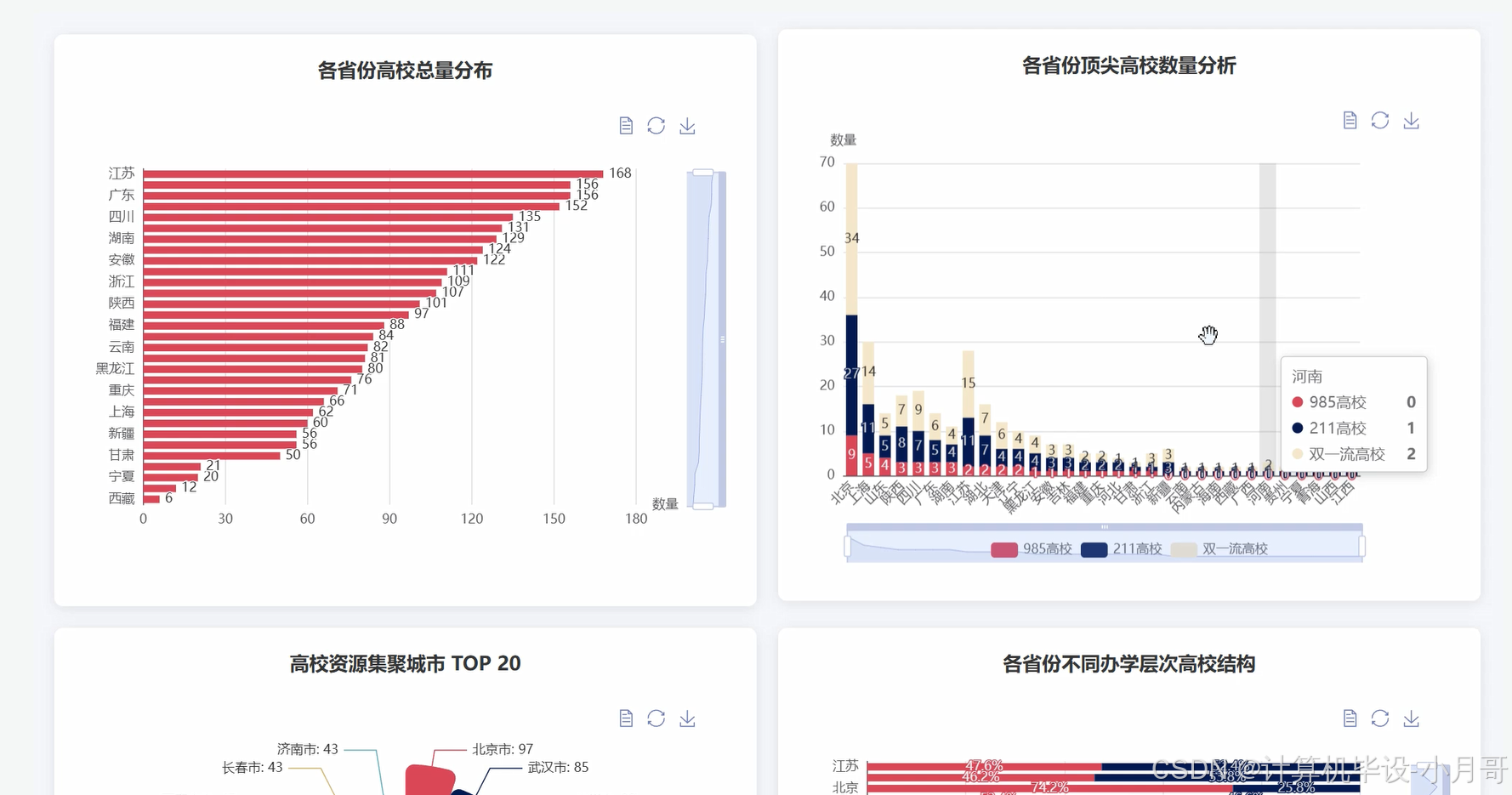
基于大数据的国内各省高校数据分析可视化系统-代码展示
# 核心功能1:各省份高校总量分布分析
def analyze_university_distribution_by_province(spark, file_path):
df = spark.read.csv(file_path, header=True, inferSchema=True)
province_counts_df = df.groupBy("省份").count().withColumnRenamed("count", "高校数量")
province_counts_df = province_counts_df.orderBy("高校数量", ascending=False)
pandas_df = province_counts_df.toPandas()
return pandas_df.to_json(orient='records')
# 核心功能2:不同省份的主流高校类型分析
def analyze_main_university_type_per_province(spark, file_path):
df = spark.read.csv(file_path, header=True, inferSchema=True)
from pyspark.sql.window import Window
from pyspark.sql.functions import row_number, col
province_type_counts = df.groupBy("省份", "类型").count()
window_spec = Window.partitionBy("省份").orderBy(col("count").desc())
ranked_types = province_type_counts.withColumn("rank", row_number().over(window_spec))
top_types_per_province = ranked_types.filter(col("rank") <= 2)
result_df = top_types_per_province.select("省份", "类型", "count").orderBy("省份", "rank")
pandas_df = result_df.toPandas()
return pandas_df.to_json(orient='records')
# 核心功能3:基于高校核心特征的聚类分析
def perform_university_clustering(spark, file_path):
df = spark.read.csv(file_path, header=True, inferSchema=True)
from pyspark.ml.feature import StringIndexer, OneHotEncoder, VectorAssembler
from pyspark.ml.clustering import KMeans
df_filtered = df.na.drop(subset=["类型", "公或民办", "本或专科"])
indexer_type = StringIndexer(inputCol="类型", outputCol="type_index")
indexer_owner = StringIndexer(inputCol="公或民办", outputCol="owner_index")
indexer_level = StringIndexer(inputCol="本或专科", outputCol="level_index")
df_indexed = indexer_type.fit(df_filtered).transform(df_filtered)
df_indexed = indexer_owner.fit(df_indexed).transform(df_indexed)
df_indexed = indexer_level.fit(df_indexed).transform(df_indexed)
encoder = OneHotEncoder(inputCols=["type_index", "owner_index", "level_index"], outputCols=["type_vec", "owner_vec", "level_vec"])
df_encoded = encoder.fit(df_indexed).transform(df_indexed)
assembler = VectorAssembler(inputCols=["type_vec", "owner_vec", "level_vec"], outputCol="features")
df_assembled = assembler.transform(df_encoded)
kmeans = KMeans(featuresCol="features", k=5, seed=42)
model = kmeans.fit(df_assembled)
clustered_df = model.transform(df_assembled)
result_df = clustered_df.select("大学", "省份", "类型", "prediction")
pandas_df = result_df.toPandas()
return pandas_df.to_json(orient='records')
基于大数据的国内各省高校数据分析可视化系统-结语
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
大数据实战项目
PHP|C#.NET|Golang实战项目
微信小程序|安卓实战项目
Python实战项目
Java实战项目
🍅 ↓↓主页获取源码联系↓↓🍅

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)