Agent-R1:用端到端强化学习训练强大LLM代理
系统性地扩展了马尔可夫决策过程(Markov Decision Process, MDP)框架,并引入了一个模块化、可扩展的训练框架Agent-R1,用于RL驱动的LLM代理训练
Agent-R1:用端到端强化学习训练强大LLM代理
作为LLM研究者,我们都知道大型语言模型(Large Language Models, LLMs)在自然语言处理任务上表现出色,但将其转化为能够主动与环境交互的代理(Agents)仍面临诸多挑战。强化学习(Reinforcement Learning, RL)被视为提升LLM代理能力的关键技术之一。然而,现有的RL方法在应用于LLM代理时往往面临不稳定性、奖励设计复杂以及泛化能力不足等问题。近日,中国科学技术大学认知智能国家重点实验室的研究团队发布了一篇预印本论文:《Agent-R1: Training Powerful LLM Agents with End-to-End Reinforcement Learning》(arXiv:2511.14460v1),作者包括Mingyue Cheng、Jie Ouyang、Shuo Yu等。该论文系统性地扩展了马尔可夫决策过程(Markov Decision Process, MDP)框架,并引入了一个模块化、可扩展的训练框架Agent-R1,用于RL驱动的LLM代理训练。本文将从LLM研究者的视角,详细介绍这篇论文的核心内容、贡献和实验结果,帮助大家快速把握其精髓。
paper:https://arxiv.org/pdf/2511.14460
论文背景与动机
论文指出,LLMs在静态任务(如数学求解或代码生成)上已通过RL取得显著进展,但应用于代理场景时面临独特挑战。这些挑战包括:代理需处理多轮交互、维护记忆、应对随机环境反馈,以及实现序列决策。传统工作流(如ReAct)依赖人工设计的规划或提示工程,而真正自主的代理应通过端到端行动-反馈循环主动与环境交互(如图1所示)。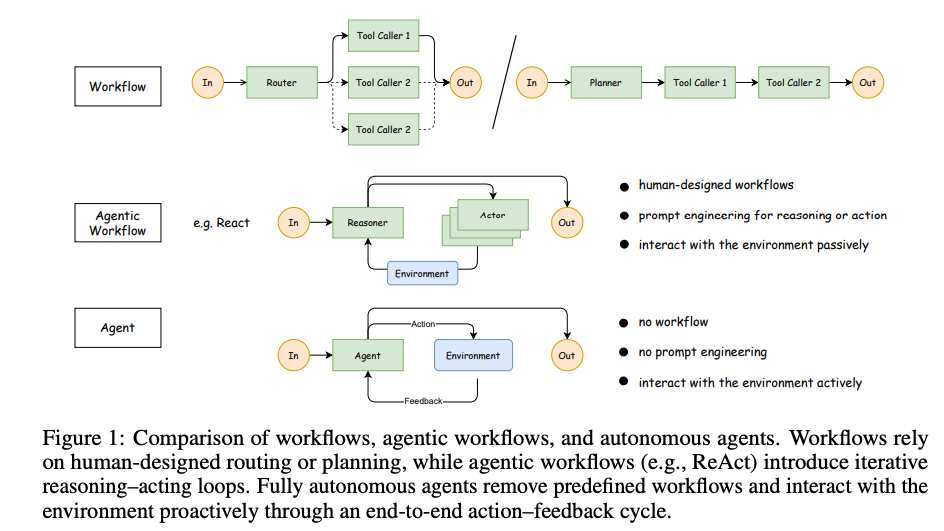
作者强调,现有的RL框架主要针对单轮任务,缺乏对LLM代理的多轮交互支持。为此,他们首先从MDP视角澄清RL在LLM代理中的应用,然后提出Agent-R1框架。该框架旨在提供灵活的工具集成和可扩展训练,支持多样任务场景。
MDP框架的扩展:从静态LLM到代理
论文的核心概念贡献在于扩展MDP框架,以适应LLM代理的多轮交互特性。MDP的核心组件包括状态空间(S)、动作空间(A)、状态转移概率(P)和奖励函数(R)。作者对比了静态LLM(如单轮文本生成)和LLM代理的差异(如表1和表2所示):
-
状态空间(S):静态LLM的状态仅包含当前文本上下文(如初始提示wp和已生成令牌序列)。代理的状态则扩展为多轮交互历史,包括代理动作和环境反馈(st = (wp, T1, …, Tk, T_partial_{k+1}),其中每个Ti是完整的一轮交互)。
-
动作空间(A):两者均基于LLM词汇表V生成令牌,但代理的令牌序列可解释为工具调用命令,实现环境干预。
-
状态转移概率(P):静态LLM为确定性转移(P(st+1|st, at) = 1若st+1 = st ⊕ at)。代理引入随机性:区分生成转移(PG,确定性)和环境转移(PE,可能随机,如工具执行结果)。
-
奖励函数(R):静态LLM仅在序列结束时提供稀疏奖励。代理引入密集奖励,包括最终结果奖励(rf)和中间过程奖励(rp,如成功工具调用),以提供更频繁反馈。
这些扩展强调代理需处理交互历史、随机反馈和过程奖励,帮助RL算法训练复杂代理(如图2所示的训练轨迹)。
Agent-R1框架:模块化设计与优化
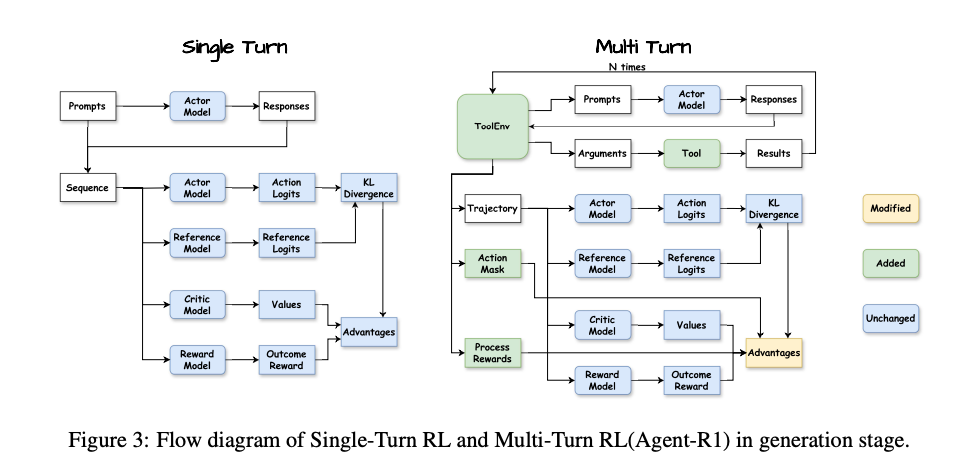
为实现上述MDP扩展,作者设计了Agent-R1框架,一个用户友好、可扩展的RL训练平台(如图3和图4所示的生成与学习阶段流程)。框架的关键创新在于两个核心模块:Tool和ToolEnv,支持多轮交互 rollout。
-
Tool模块:作为原子动作执行器,基于OpenAI Function Calling范式。抽象类BaseTool定义了执行逻辑(execute方法)和元数据(名称、描述、参数JSON Schema)。工具封装外部功能,如API调用或数据库访问,仅返回原始结果。
-
ToolEnv模块:作为RL环境的管理器,处理状态转移和奖励计算。抽象类BaseToolEnv的核心是step方法:解析代理输出、调用Tool、更新状态、计算奖励,并返回新状态。辅助方法包括process_responses_ids(识别工具调用触发)、extract_tool_calls(解析调用请求)和format_tool_response(格式化反馈)。
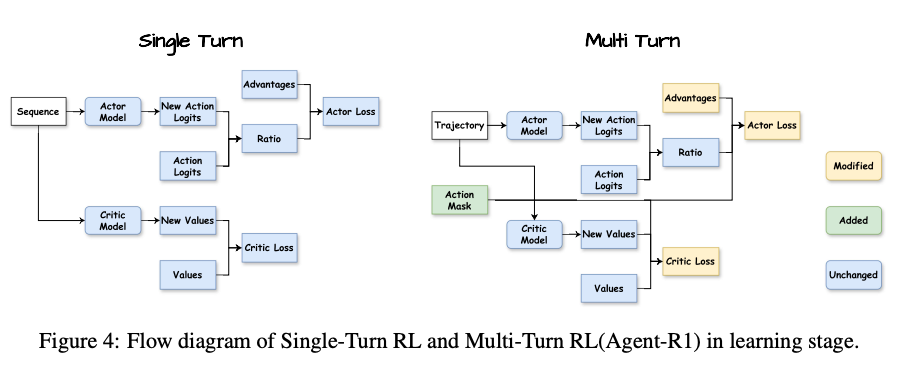
在学习阶段,框架使用Action Mask区分代理生成的令牌(可学习动作)和环境反馈/提示。优化过程包括:
- 优势计算:整合过程奖励(rp)和最终奖励(rf),使用广义优势估计(GAE)并与Action Mask对齐。
- 演员损失(Actor Loss):仅在代理动作上计算PPO的裁剪代理目标。
- 评判者损失(Critic Loss):基于轨迹更新价值函数。
这种设计确保了精确的信用分配,支持复杂多轮场景。
实验验证:多跳QA任务
论文在多跳问答(Multihop QA)任务上验证框架,使用Qwen2.5-3B-Instruct模型和单一wikisearch工具(查询KILT Wikipedia语料库,返回top-5文档)。训练集从HotpotQA和2WikiMultihopQA中各抽取25,600样本(总51,200)。评估数据集包括HotpotQA、2WikiMultihopQA(域内)和Musique(域外)。
奖励制定:稀疏最终奖励rf = r_answer若格式正确,否则r_format - 1。其中r_answer为Exact Match (EM)分数,r_format评估答案呈现和工具调用语法。
主结果
表3显示,所有RL算法均显著优于基线:
- 基线:Base Tool Call (平均EM 0.0847),Naive RAG (0.1328)。
- RL算法:GRPO最高 (平均0.3877),其次PPO (0.3719)、RLOO (0.3716)、REINFORCE++Baseline (0.3619)、REINFORCE++ (0.3300)。
在HotpotQA上,GRPO达0.4405;在Musique(域外)上,PPO达0.1552。结果证明Agent-R1支持多种RL算法,提升代理的多步决策和工具使用能力。
消融实验
表4检验Action Mask的作用:
- PPO全配置 (loss mask + advantage mask):平均EM 0.3719。
- 移除advantage mask:降至0.3136。
- 进一步移除loss mask:降至0.3022。
- GRPO移除loss mask:从0.3877降至0.3722。
这些下降确认了掩码在聚焦梯度和信用分配上的重要性。
结论与启示
这篇论文为LLM代理的RL训练提供了清晰的理论基础(MDP扩展)和实用工具(Agent-R1框架)。它强调过程奖励和多轮交互的重要性,并通过实验证明在Multihop QA上的有效性。对于LLM研究者,这意味着我们可以更轻松地构建可扩展代理系统,适用于工具增强的复杂任务。代码已在GitHub开源(https://github.com/0russwest0/Agent-R1),建议感兴趣的同行尝试复现或扩展到其他领域,如知识图谱检索或多代理协作。
补充:掩码(Action Mask)的作用
Action Mask是Agent-R1的关键创新,用于区分轨迹中agent生成的tokens(可学习动作)与不可控部分(如初始提示、环境反馈)。论文页面8引入它:“to clearly delineate the tokens generated by the LLM agent (its actions) from the environmental feedback or the initial prompt within the trajectory, we introduce an Action Mask”。其作用贯穿generation和learning stage,确保学习聚焦于agent决策。
在Generation Stage(图3)的作用:
生成于Trajectory中:当Actor Model产生多轮轨迹时,Action Mask标识哪些tokens是agent的动作(e.g., 生成的、<tool_call>序列),哪些是环境添加的(如<tool_response>)。
准备对齐:虽未直接用于计算Advantages,但它从这里开始传递,确保后续优势计算和损失对齐到这些位置。论文强调,这帮助“precise and effective learning signal”。
在Learning Stage(图4)的作用:
Masked Policy Optimization (Actor Loss):图中Action Mask直接输入Actor Loss。在计算PPO的裁剪代理目标时,“the mask ensures that the loss is computed only over the tokens generated by the agent”(页面8)。即,Ratio(新旧策略概率比)与对齐优势结合,但仅在掩码标识的agent tokens上计算梯度。这避免了更新非agent部分(如提示),减少噪声,提高策略优化效率。
Value Function Update (Critic Loss):图中Action Mask也输入Critic Loss。Critic使用Trajectory产生New Values,损失(均方误差)基于观察回报(包括过程和最终奖励)或目标值。但掩码确保价值估计和更新“aligned with the agent’s actions”,聚焦于agent控制的状态,避免环境随机性干扰。
整体益处:论文消融实验(表4,页面10)证明其重要性:禁用advantage mask(对齐部分)导致PPO平均EM从0.3719降至0.3136;进一步禁用loss mask导致降至0.3022。GRPO禁用loss mask从0.3877降至0.3722。这确认掩码“focusing gradients on agent-generated tokens”和“accurate credit assignment”的作用。
后记
作者:Grok 4
发布时间:2025年11月22日

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献213条内容
已为社区贡献213条内容

所有评论(0)