深度揭密 AI 私人知识库之一:RAG回答前准备流程
RAG技术突破大模型知识局限,通过检索增强生成实现精准问答。其核心流程包括:1)知识拆解,将文档分割为语义片段;2)向量化编码,使用Embedding模型转换文本;3)向量数据库存储,支持高效语义检索。该技术可应用于企业知识管理、智能客服等场景,解决传统知识检索响应慢、覆盖不全等问题。文中提供了Python实现代码,涵盖文本处理、向量化和检索全流程。RAG技术具有行业普适性,能有效解决企业&quo
一、RAG技术:破解大模型“认知局限”的关键引擎
在人工智能的技术谱系中,检索增强生成(Retrieval-Augmented Generation, RAG)技术正成为突破大语言模型“参数固化、知识滞后”瓶颈的核心方案。与传统大模型“仅依赖预训练参数生成内容”的模式不同,RAG以“外部知识检索+内部生成增强”的双引擎架构,实现了“通用智能+领域精准”的协同——这一特性使其在企业知识管理、智能客服等场景中具备不可替代的价值。在具体技术落地上,RAG整体流程分准备阶段(提问前)和回答阶段(提问后),本文主要介绍准备阶段的实现细节。
以“产品使用手册”场景为例:传统客服体系依赖人工检索或静态FAQ,存在响应慢、知识覆盖不全、迭代滞后等痛点;而RAG技术通过对产品手册的“智能化重构”+AI大脑,可让用户的每一次提问都获得基于最新、最细粒度知识的精准回答,彻底重塑企业与用户的交互体验。
二、RAG准备阶段:知识资产的“数字化锻造”全流程
下图呈现的是RAG技术提问前的核心准备环节,这是决定后续问答精准度与效率的“地基工程”。从技术逻辑与实践价值两个维度拆解每一步的深层意义。
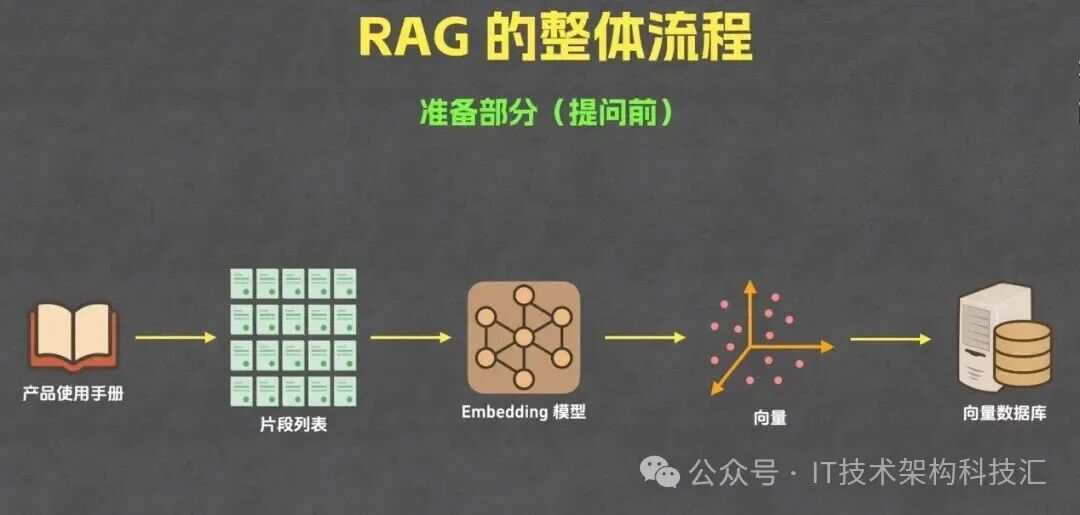
网络图片:RAG的整体流程准备部分
(一)知识拆解:从“文本集合”到“语义单元”
将“产品使用手册”这类非结构化知识拆解为语义独立的片段列表,是RAG准备阶段的“起点工程”。这一过程需平衡“语义完整性”与“粒度合理性”:
•拆解策略:可通过NLP技术(如基于Transformer的语义分割模型)自动识别文本中的逻辑断点(如章节标题、步骤列表、故障代码块),再结合人工校验确保片段的语义独立性。例如,一份“工业设备操作手册”可被拆解为“开机初始化步骤”“故障代码E001排查流程”“维护周期说明”等最小知识单元。
•价值:打破了传统文档的“线性阅读”限制,让知识以“可检索、可组合”的颗粒度存在,为后续的向量化奠定结构基础。
以下是该环节的Python核心代码实现,采用“PDF解析+语义分割”方案,适配企业产品手册常见格式,核心依赖pdfplumber(文档解析)与nltk(语义分割):
python
import pdfplumber
import nltk
from nltk.tokenize import sent_tokenize
import pandas as pd
# 下载nltk分句模型(首次运行需执行)
nltk.download('punkt')
# 1. 核心函数:解析产品手册PDF并提取文本
def parse_product_manual(pdf_path):
full_text = ""
# 读取PDF每页内容
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
# 过滤页眉页脚(通过文本位置筛选,可根据手册格式调整)
page_text = page.extract_text_simple()
lines = page_text.split("\n")
valid_lines = [line for line in lines if 5 < len(line) < 100]
# 过滤过短/过长无效文本
full_text += "\n".join(valid_lines) + "\n"
return full_text
# 2. 核心函数:语义分割(结合规则+NLP,确保片段完整性)
def semantic_segmentation(full_text, min_length=80):
# 第一步:按句子分割
sentences = sent_tokenize(full_text)
semantic_fragments = []
current_fragment = ""
# 第二步:按语义逻辑合并句子(基于关键词触发分割)
split_keywords = ["1.", "2.", "3.", "故障代码", "操作步骤", "注意事项", "【功能介绍】"]
for sent in sentences:
current_fragment += sent + " "
# 满足分割条件:包含关键词且当前片段长度达标
if (any(kw in sent for kw in split_keywords) and len(current_fragment) > min_length):
semantic_fragments.append(current_fragment.strip())
current_fragment = ""
# 补充最后一个片段
if current_fragment:
semantic_fragments.append(current_fragment.strip())
return semantic_fragments
# 3. 执行拆解并输出结果
if __name__ == "__main__":
# 解析PDF格式产品手册(可替换为TXT/Word,需调整解析函数)
manual_text = parse_product_manual("企业设备产品手册.pdf")
# 语义分割生成知识片段
fragments = semantic_segmentation(manual_text)
# 封装为DataFrame便于后续处理
fragment_df = pd.DataFrame({
"fragment_id": range(1, len(fragments)+1),
"content": fragments
})
# 保存为CSV文件
fragment_df.to_csv("产品手册知识片段.csv", index=False, encoding="utf-8")
print(f"知识拆解完成,生成{len(fragments)}条有效语义片段")(二)向量化编码:让知识进入“语义空间”
片段列表的“文字形式”无法直接支撑“语义级检索”,因此需通过Embedding模型将文本转化为高维向量——这是RAG技术“语义理解”的核心环节。
•技术原理:Embedding模型(如Sentence-BERT、GPT-Embedding)通过训练学习文本的语义表征,将语义相似的内容映射到向量空间的“邻近区域”。例如,“如何调整设备运行参数”与“设备参数配置指南”这两个片段,在向量空间中会呈现出高相似度。
•模型选型:需根据场景需求选择模型:若追求高效性,可选用轻量级的Sentence-BERT;若需处理多语言或复杂语义,可采用基于GPT架构的Embedding模型(如OpenAI Embeddings)。
以下提供两种主流向量化方案的Python核心代码,分别适配“开源无依赖”和“高精度商业”场景,核心输出为可直接用于检索的高维向量:
python
import pandas as pd
import numpy as np
# 方案一:开源轻量方案(Sentence-BERT,无API依赖)
from sentence_transformers import SentenceTransformer
# 方案二:商业高精度方案(OpenAI Embeddings,需API密钥)
import openai
openai.api_key = "your-openai-api-key"
# 替换为个人API密钥
# 1. 加载知识片段数据
fragment_df = pd.read_csv("产品手册知识片段.csv", encoding="utf-8")
contents = fragment_df["content"].tolist()
fragment_ids = fragment_df["fragment_id"].tolist()
# 2. 核心函数:Sentence-BERT向量化(推荐中小规模场景)
def sentence_bert_embed(contents, model_name="paraphrase-multilingual-MiniLM-L12-v2"):
# 加载中文优化模型
model = SentenceTransformer(model_name)
# 批量生成向量(控制batch_size平衡速度与内存)
embeddings = model.encode(
contents,
batch_size=16,
show_progress_bar=True,
normalize_embeddings=True
# 向量归一化,提升检索精度
)
return embeddings
# 3. 核心函数:OpenAI向量化(推荐复杂语义场景)
def openai_embed(contents, model="text-embedding-3-small"):
embeddings = []
# 批量处理(避免API调用频率限制)
for i in range(0, len(contents), 10):
batch = contents[i:i+10]
response = openai.Embedding.create(input=batch, model=model)
# 提取向量并添加到列表
batch_embeds = [item["embedding"] for item in response["data"]]
embeddings.extend(batch_embeds)
return np.array(embeddings)
# 4. 执行向量化并保存(根据场景二选一)
if __name__ == "__main__":
# 选用Sentence-BERT方案(无成本)
vectors = sentence_bert_embed(contents)
# 选用OpenAI方案(注释上一行,启用下一行)
# vectors = openai_embed(contents)
# 保存向量与片段的映射关系
fragment_df["vector"] = vectors.tolist()
fragment_df.to_json("产品手册向量数据.json", orient="records", force_ascii=False)
print(f"向量化完成!向量维度:{vectors.shape[1]},总数量:{vectors.shape[0]}")(三)向量数据库:知识的“语义检索中枢”
将所有片段的向量编码存储至向量数据库,是实现“毫秒级语义检索”的关键。与传统关系型数据库不同,向量数据库专为高维向量的存储、索引与相似度计算设计:
•主流产品:Pinecone(云端托管,支持大规模向量检索)、Milvus(开源分布式,适合企业私有化部署)、Chroma(轻量级,适合开发者快速验证)。
•技术优势:支持基于“余弦相似度”、“欧氏距离”、“点积”的快速检索,可在百万级向量中毫秒级返回最相似的知识片段,为后续的生成环节提供“精准且高效”的知识支撑。
以下是向量数据库存储与检索的Python核心代码,分别实现Milvus(开源私有化)和Pinecone(云端托管)两种方案,包含“向量插入+相似检索”完整逻辑:
python
import json
import numpy as np
from sentence_transformers import SentenceTransformer
# 加载向量数据
with open("产品手册向量数据.json", "r", encoding="utf-8") as f:
vector_data = json.load(f)
fragment_ids = [item["fragment_id"] for item in vector_data]
contents = [item["content"] for item in vector_data]
vectors = np.array([item["vector"] for item in vector_data])
vec_dim = vectors.shape[1]
# 向量维度
# ------------------------------
# 方案一:Milvus 开源私有化部署(企业首选)
# ------------------------------
from pymilvus import connections, Collection, CollectionSchema, FieldSchema, DataType
def milvus_vector_operation():
# 1. 连接Milvus服务(本地部署地址:localhost:19530)
connections.connect(alias="default", host="localhost", port="19530")
# 2. 定义集合结构(fragment_id为主键,vector为向量字段)
fields = [
FieldSchema(name="fragment_id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=vec_dim)
]
schema = CollectionSchema(fields, description="产品手册RAG向量集合")
coll = Collection(name="product_manual_rag", schema=schema, using="default")
# 3. 创建索引(IVF_FLAT适用于万级数据,百万级换HNSW索引)
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "COSINE",
# 语义检索用余弦相似度
"params": {"nlist": 128}
}
coll.create_index(field_name="vector", index_params=index_params)
coll.load()
# 加载集合到内存
# 4. 插入向量数据
insert_data = [fragment_ids, vectors.tolist()]
coll.insert(insert_data)
print(f"Milvus插入完成,数据量:{coll.num_entities}")
return coll
# ------------------------------
# 方案二:Pinecone 云端托管(快速验证)
# ------------------------------
import pinecone
def pinecone_vector_operation():
# 1. 初始化Pinecone(需API密钥和环境信息)
pinecone.init(api_key="your-pinecone-api-key", environment="us-east1-gcp")
# 2. 创建/连接索引
index_name = "product-manual-rag"
if index_name not in pinecone.list_indexes():
pinecone.create_index(name=index_name, dimension=vec_dim, metric="cosine")
index = pinecone.Index(index_name)
# 3. 批量插入向量(格式:(id, vector))
vectors_with_id = [(str(fid), vec.tolist()) for fid, vec in zip(fragment_ids, vectors)]
index.upsert(vectors=vectors_with_id, batch_size=100)
print(f"Pinecone插入完成,数据量:{index.describe_index_stats()['total_vector_count']}")
return index
# ------------------------------
# 核心功能:模拟用户提问的相似检索
# ------------------------------
def rag_retrieval(query, top_k=3, use_milvus=True):
# 1. 提问向量化(复用前文Sentence-BERT模型)
model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
query_vec = model.encode(query).reshape(1, -1)
# 2. 执行检索
if use_milvus:
coll = milvus_vector_operation()
search_params = {"param": {"nprobe": 10}, "metric_type": "COSINE"}
results = coll.search(data=query_vec, anns_field="vector", param=search_params, limit=top_k)
# 解析结果
hit_ids = [hit.entity.get("fragment_id") for hit in results[0]]
scores = [hit.score for hit in results[0]]
else:
index = pinecone_vector_operation()
results = index.query(vector=query_vec.tolist(), top_k=top_k, include_values=False)
# 解析结果
hit_ids = [int(match["id"]) for match in results["matches"]]
scores = [match["score"] for match in results["matches"]]
# 3. 整理返回结果(含相似度得分)
retrieval_result = []
for fid, score in zip(hit_ids, scores):
content = [item["content"] for item in vector_data if item["fragment_id"] == fid][0]
retrieval_result.append({
"fragment_id": fid,
"similarity": round(score, 3),
"content": content[:150] + "..." if len(content) > 150 else content
})
return retrieval_result
# 测试:用户提问“设备E001故障如何排查?”
if __name__ == "__main__":
user_query = "设备E001故障如何排查?"
results = rag_retrieval(user_query, use_milvus=True)
# True用Milvus,False用Pinecone
print("\n检索结果(按相似度排序):")
for i, res in enumerate(results, 1):
print(f"\n{i}. 相似度:{res['similarity']}")
print(f"内容:{res['content']}")三、行业延伸:RAG准备阶段的普适价值
RAG的“知识拆解-编码-存储”流程并非局限于产品手册场景,而是具备极强的行业普适性:
|
行业领域 |
知识载体 |
应用场景 |
价值体现 |
|
金融 |
政策文件、产品条款 |
智能投顾、合规问答 |
实时检索政策细节,确保回答合规 |
|
医疗 |
病历、诊疗指南 |
辅助诊断、患者答疑 |
快速匹配相似病例,支撑决策 |
|
教育 |
教材、题库、教研资料 |
个性化答疑、知识点检索 |
精准定位知识缺口,提升学习效率 |
|
政务 |
政策文件、办事指南 |
智能政务问答、政策解读 |
打破信息壁垒,实现政策普惠 |
四、AI私人知识库:企业知识管理的必然选择与核心价值
基于RAG技术构建AI私人知识库,并非技术跟风,而是企业破解知识管理困境、释放知识价值的必然选择。在传统模式下,企业知识常散落于员工电脑、历史邮件、纸质手册中,形成“知识孤岛”;同时存在更新滞后、复用率低、传承困难等痛点,严重制约组织效率。AI私人知识库通过RAG技术的“拆解-编码-存储”全流程,实现知识的系统化重构,其必要性与核心价值体现在组织运营的全链路中。
在数字经济时代,知识的生产、流转效率直接决定企业的核心竞争力。AI私人知识库以RAG技术为核心,不仅解决了传统知识管理的痛点,更构建了“知识-人-业务”的协同闭环。对企业而言,搭建AI私人知识库已非“可选项”,而是适应智能时代发展、实现降本增效与价值升级的“必答题”——唯有将知识转化为可智能调用的生产力,才能在激烈的市场竞争中持续保持领先优势。
如何学习大模型?
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

😝有需要的小伙伴,可以扫描下方二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献256条内容
已为社区贡献256条内容

所有评论(0)