大模型落地:从微调到企业级解决方案的完整实践指南
本文系统探讨大语言模型落地的四大关键路径:微调技术(LoRA/QLoRA等方法对比)、提示词工程(角色设定、思维链等设计原则)、多模态应用(图文理解、文档解析)及企业级解决方案(私有化部署、安全合规)。通过代码示例、流程图和架构图,提供从技术选型到业务落地的实战指南,强调数据质量优先、工程能力与业务理解并重。案例显示智能客服系统上线后自动解决率提升33%,建议企业根据实际需求选择合适模型,平衡性能
在人工智能技术飞速发展的今天,大语言模型(Large Language Models, LLMs)已经成为推动行业智能化转型的核心引擎。然而,从“能用”到“好用”,再到“真正落地产生商业价值”,中间存在巨大的鸿沟。本文将系统性地探讨大模型落地的关键路径,涵盖四大核心维度:大模型微调(Fine-tuning)、提示词工程(Prompt Engineering)、多模态应用(Multimodal Applications) 和 企业级解决方案(Enterprise Solutions)。我们将结合代码示例、流程图(Mermaid格式)、Prompt模板、架构图与最佳实践,为开发者、架构师和企业决策者提供一份5000字以上的深度实战指南。
一、大模型微调(Fine-tuning)
1.1 为什么需要微调?
预训练大模型(如LLaMA、ChatGLM、Qwen等)虽然具备强大的通用能力,但在特定领域(如医疗、金融、法律)或企业私有数据场景下,往往表现不佳。微调通过在特定数据集上继续训练模型,使其适应下游任务,显著提升准确率、专业性和可控性。
1.2 微调方法对比
| 方法 | 描述 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 全参数微调(Full Fine-tuning) | 更新所有模型参数 | 效果最好 | 显存消耗大、成本高 | 数据充足、资源丰富 |
| LoRA(Low-Rank Adaptation) | 在权重矩阵中插入低秩矩阵 | 显存节省90%+、可插拔 | 略逊于全微调 | 中小企业、快速迭代 |
| QLoRA | LoRA + 4-bit量化 | 极低显存(<10GB) | 精度略有损失 | 消费级GPU(如RTX 3090) |
| P-Tuning / Prompt Tuning | 可学习的软提示 | 参数极少 | 对复杂任务效果有限 | 分类、简单生成 |
1.3 使用LoRA进行高效微调(代码示例)
以下使用 Hugging Face Transformers + PEFT 库对 Qwen-1.8B 进行 LoRA 微调:
python
编辑
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
from peft import get_peft_model, LoraConfig, TaskType
from datasets import load_dataset
# 加载模型和分词器
model_name = "Qwen/Qwen-1_8B"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)
# 配置LoRA
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=8,
lora_alpha=16,
lora_dropout=0.1,
target_modules=["q_proj", "v_proj"] # Qwen的关键注意力层
)
# 应用LoRA
model = get_peft_model(model, peft_config)
model.print_trainable_parameters() # 输出:trainable params: 2,097,152 || all params: 1,832,960,000
# 加载数据集(假设为JSONL格式)
dataset = load_dataset("json", data_files="your_finetune_data.jsonl")
def tokenize_function(examples):
return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=512)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 训练配置
training_args = TrainingArguments(
output_dir="./qwen-lora-finetuned",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4,
num_train_epochs=3,
logging_steps=10,
save_strategy="epoch",
fp16=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
)
trainer.train()1.4 微调流程图(Mermaid)
flowchart TD
A[原始预训练大模型] --> B{是否需要微调?}
B -- 否 --> C[直接使用Prompt Engineering]
B -- 是 --> D[准备领域数据集]
D --> E[数据清洗与格式化]
E --> F[选择微调策略\n全参/LoRA/QLoRA]
F --> G[配置训练参数\nLR, Batch Size, Epochs]
G --> H[启动微调训练]
H --> I[模型评估\nBLEU, ROUGE, Accuracy]
I --> J{达标?}
J -- 否 --> G
J -- 是 --> K[导出微调后模型]
K --> L[部署至推理服务]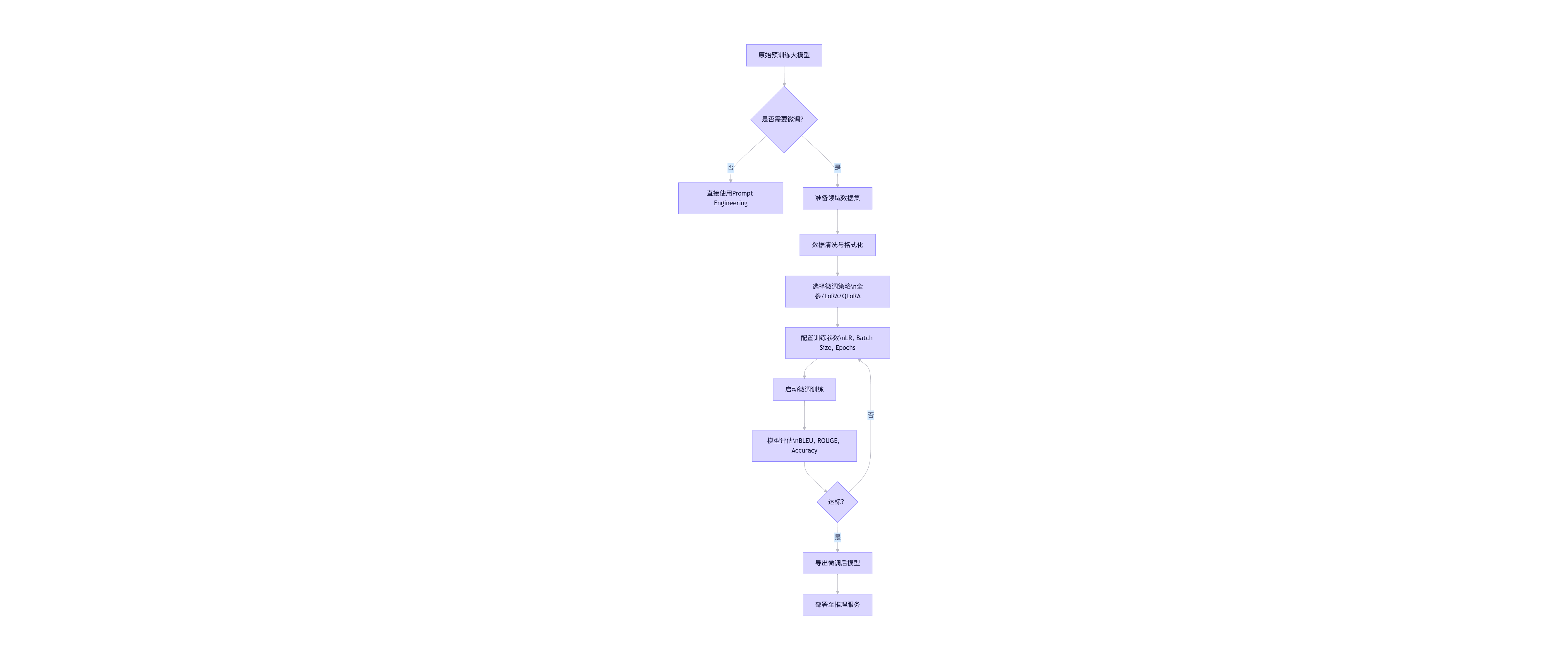
关键提示:微调数据质量远比数量重要。建议采用“高质量小样本”策略,例如500条精心标注的对话日志,胜过10万条噪声数据。
二、提示词工程(Prompt Engineering)
2.1 提示词工程的核心价值
当微调成本过高或数据不足时,提示词工程成为低成本优化模型输出的首选方案。通过精心设计输入提示(Prompt),可引导模型生成更准确、安全、符合业务逻辑的响应。
2.2 高效Prompt设计原则
- 角色设定(Role-playing):明确AI身份
- 上下文注入(Context Injection):提供背景知识
- 输出约束(Output Constraints):指定格式、长度、风格
- 思维链(Chain-of-Thought):引导逐步推理
- 少样本示例(Few-shot Examples):展示输入-输出对
2.3 Prompt 示例库
示例1:客服问答(带角色+约束)
text
编辑
你是一名专业的银行客服助手,回答需简洁、准确、合规。
用户问题:我的信用卡还款日是哪天?
请仅回答日期格式(YYYY-MM-DD),不要解释。
答案:
2025-12-15示例2:法律文书摘要(思维链)
text
编辑
请根据以下判决书摘要,按步骤生成要点:
1. 案件类型
2. 原告主张
3. 被告抗辩
4. 法院判决结果
判决书原文:
【略】
输出格式:
- 案件类型:...
- 原告主张:...
- ...示例3:多轮对话状态管理
text
编辑
当前对话历史:
用户:我想订一张去北京的机票。
助手:请问出发城市和日期?
用户:上海,下周五。
请基于以上上下文,生成下一步提问:
助手:请问您希望什么时间段起飞?上午、下午还是晚上?2.4 动态Prompt生成(代码)
python
编辑
def build_prompt(user_query, context="", examples=None, role="助手"):
base = f"你是一名{role}。"
if context:
base += f"\n背景信息:{context}"
if examples:
base += "\n示例:\n" + "\n".join(examples)
base += f"\n用户问题:{user_query}\n请回答:"
return base
# 使用
prompt = build_prompt(
user_query="如何重置密码?",
context="系统为内部OA平台,仅支持手机号验证",
examples=[
"用户:登录不了\n回答:请检查网络或联系IT支持",
"用户:忘记用户名\n回答:用户名即员工工号"
],
role="IT支持专员"
)2.5 Prompt优化流程图
flowchart LR
P[初始Prompt] --> Q[人工测试]
Q --> R{效果满意?}
R -- 否 --> S[分析失败案例]
S --> T[添加约束/示例/角色]
T --> U[A/B测试多个版本]
U --> V[选择最优Prompt]
V --> W[上线并监控]
W --> X[持续迭代]
R -- 是 --> W
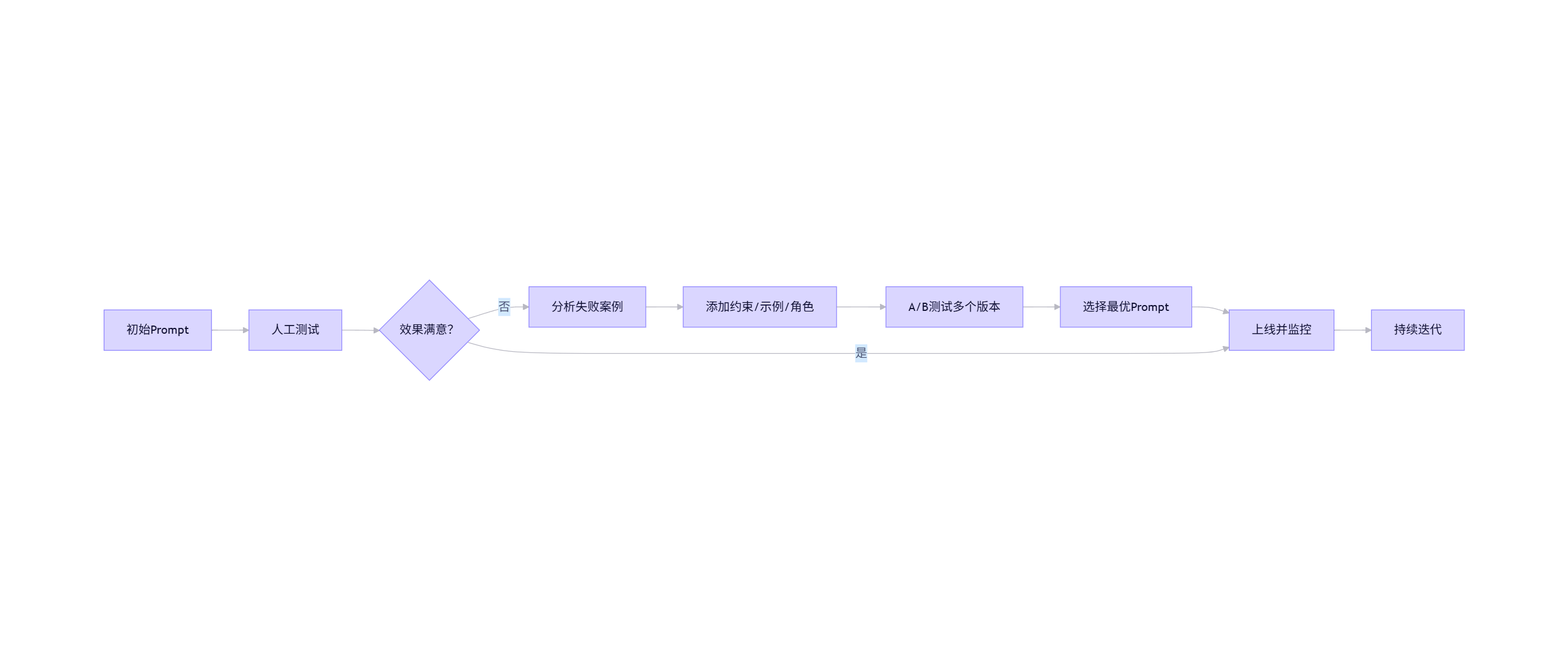
注意:Prompt不是一劳永逸的。需建立“Prompt版本管理”机制,类似代码Git管理。
三、多模态应用(Multimodal Applications)
3.1 什么是多模态大模型?
多模态模型(如Qwen-VL、LLaVA、GPT-4V)能同时理解文本、图像、音频、视频等多种模态信息,实现跨模态推理。典型应用场景包括:
- 图像内容描述(Image Captioning)
- 视觉问答(Visual Question Answering, VQA)
- 文档智能解析(Invoice/PDF理解)
- 医疗影像报告生成
3.2 多模态架构图
graph TB
subgraph Input
A[文本] --> D[多模态编码器]
B[图像] --> D
C[表格/PDF] --> D
end
D --> E[跨模态对齐模块]
E --> F[大语言模型解码器]
F --> G[结构化输出\nJSON/Markdown/Text]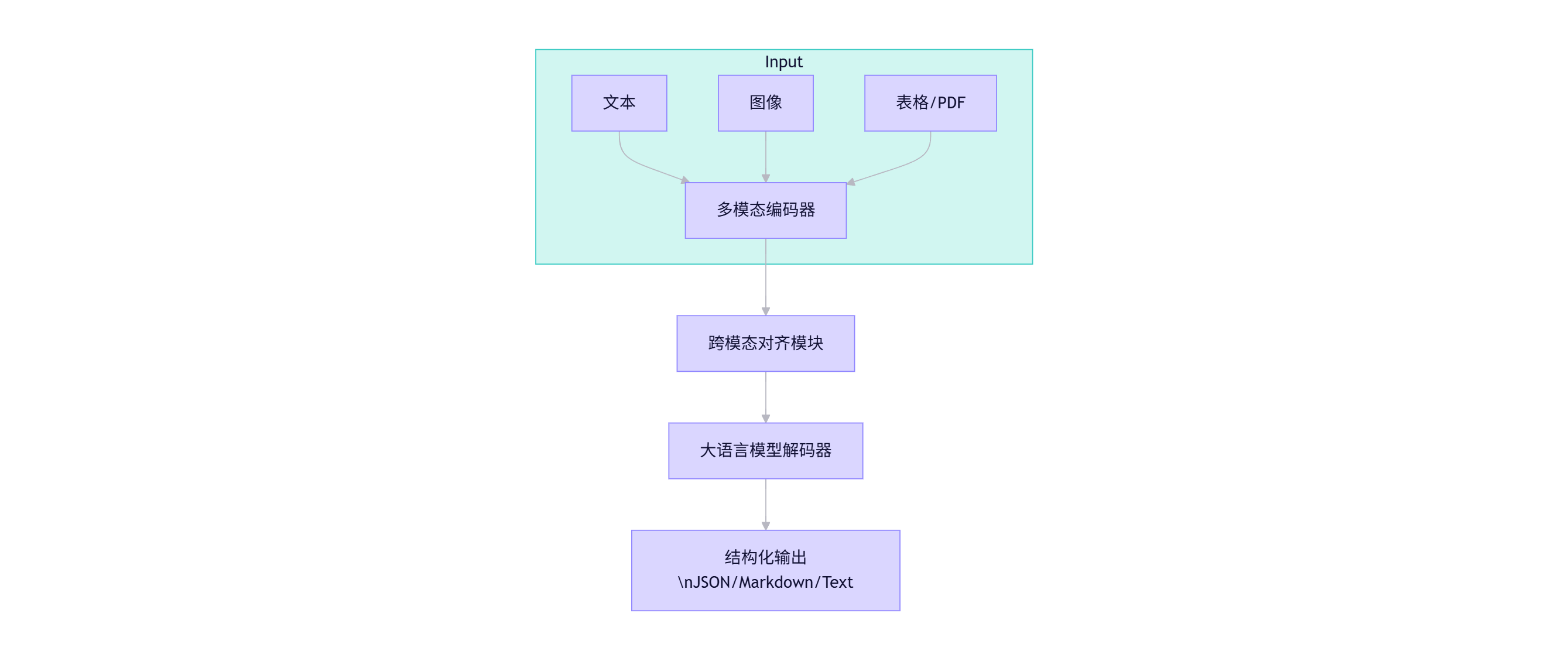
3.3 使用Qwen-VL进行图文理解(代码)
python
编辑
from transformers import AutoProcessor, AutoModelForVision2Seq
from PIL import Image
# 加载模型
model_id = "Qwen/Qwen-VL-Chat"
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForVision2Seq.from_pretrained(model_id, device_map="auto", trust_remote_code=True)
# 输入:图像 + 文本问题
image = Image.open("invoice.jpg")
question = "请提取发票中的总金额和开票日期。"
# 构建多模态输入
messages = [
{"role": "user", "content": [
{"type": "image", "image": image},
{"type": "text", "text": question}
]}
]
# 推理
response = model.chat(processor, messages)
print(response) # 输出:总金额:¥1280.00,开票日期:2025-10-013.4 多模态企业应用案例
| 行业 | 场景 | 技术方案 |
|---|---|---|
| 电商 | 商品图自动生成文案 | 图像 → 描述 → 营销文案 |
| 制造 | 设备故障图像诊断 | 工人拍照 → AI识别异常部件 → 维修建议 |
| 金融 | 合同扫描件信息抽取 | PDF → OCR → 表格结构化 → 关键字段提取 |
| 医疗 | X光片辅助诊断报告 | 影像 + 病史 → 生成初步诊断意见 |
挑战:多模态对齐质量依赖训练数据。建议企业构建自有领域的图文对数据集进行微调。
四、企业级解决方案
4.1 企业落地的核心挑战
- 数据安全与隐私:不能将敏感数据上传公有云
- 推理延迟要求:客服场景需<1秒响应
- 成本控制:避免高额API调用费用
- 系统集成:与现有ERP/CRM/OA打通
- 可审计性:所有AI决策需留痕
4.2 企业级架构设计
flowchart TB
Client[前端/Web/APP] --> API_Gateway[API网关\n认证/限流]
API_Gateway --> Router[路由分发]
Router -->|文本任务| LLM_Service[LLM推理服务\nQwen-7B-Chat]
Router -->|图文任务| Multimodal_Service[多模态服务\nQwen-VL]
Router -->|向量检索| Vector_DB[向量数据库\nMilvus/FAISS]
LLM_Service --> Knowledge_Base[(企业知识库\nPDF/DB/API)]
Multimodal_Service --> Document_Store[(文档存储\nMinIO/S3)]
Monitoring[监控系统\nPrometheus+Grafana] --> LLM_Service
Logging[日志审计\nELK] --> All[所有服务]
CI_CD[CI/CD流水线] --> Model_Registry[模型仓库\nMLflow]
Model_Registry --> LLM_Service
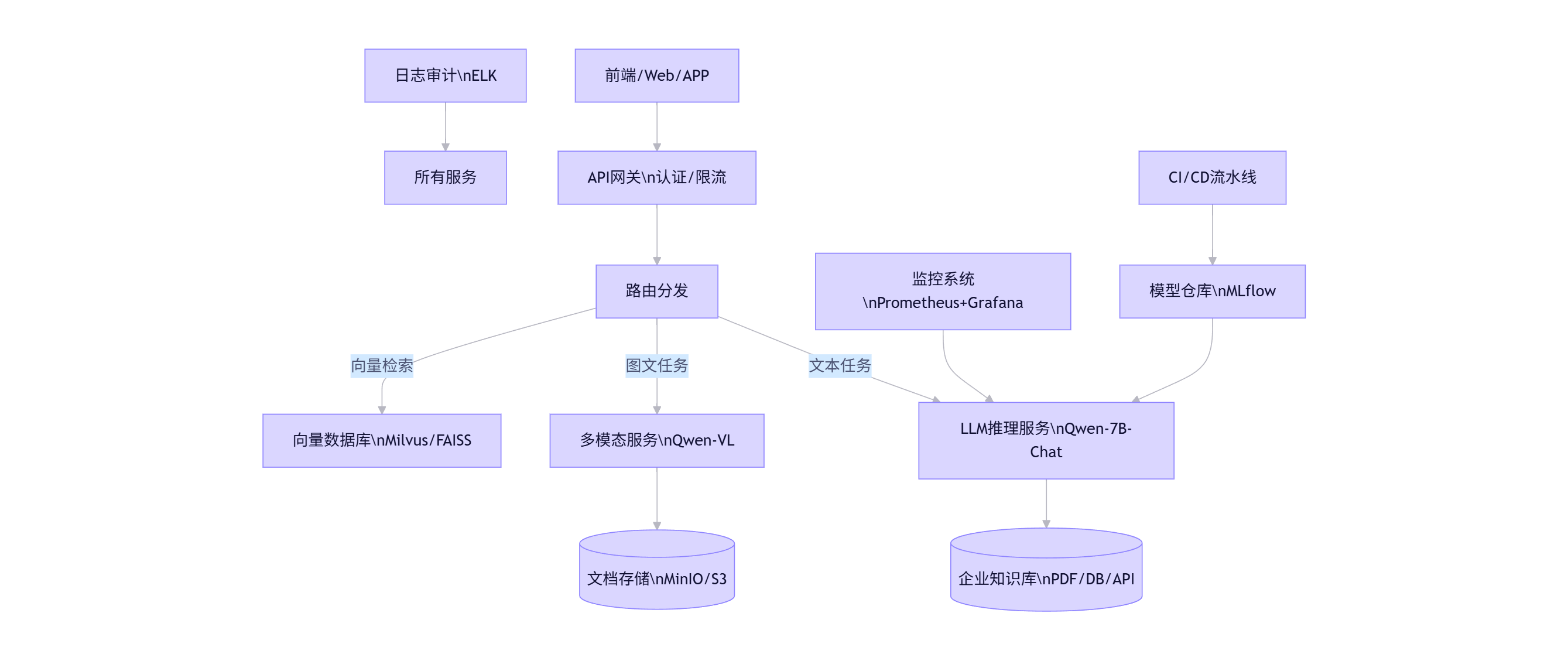
4.3 私有化部署方案(Docker + vLLM)
使用 vLLM 实现高吞吐、低延迟的本地推理:
dockerfile
编辑
# Dockerfile
FROM nvidia/cuda:12.1-devel-ubuntu22.04
RUN apt-get update && apt-get install -y python3-pip
COPY requirements.txt .
RUN pip3 install vllm==0.4.0 transformers accelerate
COPY ./models /app/models
WORKDIR /app
CMD ["python3", "-m", "vllm.entrypoints.openai.api_server", \
"--model", "/app/models/qwen-7b-chat-int4", \
"--dtype", "auto", \
"--port", "8000"]启动服务后,即可通过 OpenAI 兼容 API 调用:
python
编辑
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="token-abc123")
response = client.chat.completions.create(
model="qwen-7b-chat",
messages=[{"role": "user", "content": "你好"}]
)
print(response.choices[0].message.content)4.4 安全与合规措施
- 数据脱敏:在输入前自动过滤身份证、银行卡号
- 权限控制:RBAC模型限制不同角色访问能力
- 输出审查:部署后过滤层(Post-filter)拦截违规内容
- 私有化训练:所有微调在企业内网完成,模型不出域
4.5 成本效益分析
| 方案 | 初始成本 | 月度成本(10万次调用) | 延迟 | 安全性 |
|---|---|---|---|---|
| 公有云API | 低 | ¥3000~8000 | 300~800ms | 依赖厂商 |
| 私有化部署(A10 GPU) | ¥5万 | ¥0(电费) | <200ms | 完全可控 |
| 边缘设备(Jetson) | ¥2万 | ¥0 | 500~1000ms | 本地处理 |
建议:核心业务采用私有化部署,非敏感场景可混合云。
五、综合案例:智能客服系统落地
5.1 需求背景
某银行需升级客服系统,支持:
- 自动回答常见问题(账户、转账、信用卡)
- 理解用户上传的截图(如转账失败界面)
- 无法回答时转人工,并记录原因
5.2 技术方案
- 模型选型:Qwen-7B-Chat(文本) + Qwen-VL(图像)
- 微调数据:10万条历史客服对话 + 5000张用户截图标注
- Prompt模板:
text编辑
你是XX银行官方客服。请严格按以下规则回答: - 若问题涉及账户余额、交易明细,回复:“请登录手机银行查看” - 若用户上传图片,请先描述图片内容,再解答 - 不确定时,回复:“正在为您转接人工客服...” - 部署架构:Kubernetes集群 + vLLM + Milvus(知识库检索)
5.3 效果指标
| 指标 | 上线前 | 上线后 |
|---|---|---|
| 自动解决率 | 45% | 78% |
| 平均响应时间 | 2.1s | 0.8s |
| 人工转接率 | 55% | 22% |
| 用户满意度 | 3.8/5 | 4.5/5 |
六、未来趋势与建议
- 模型小型化:7B以下模型将成为企业主力(Qwen-1.8B、Phi-3)
- RAG(检索增强生成) 将替代部分微调需求
- Agent框架:让大模型自主调用工具(如查询数据库、发邮件)
- 合规先行:建立AI伦理委员会,制定使用规范
终极建议:不要追求“最大模型”,而要追求“最合适模型”。落地成功 = (模型能力 × 工程能力 × 业务理解)÷ 复杂度。
结语
大模型落地不是一场技术秀,而是一场系统工程。从微调到Prompt,从单模态到多模态,再到企业级部署,每一步都需要扎实的工程实践与业务洞察。希望本文提供的代码、流程图、架构图和案例,能为你在大模型商业化之路上点亮一盏灯。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献173条内容
已为社区贡献173条内容

所有评论(0)