AI Agent | 也说说上下文工程(Context Engineering)
摘要 上下文工程(CE)是优化大模型交互效果的系统化方法,相比提示词工程(PE)具有四大优势:结果更稳定可重复、扩展性更强、具备状态记忆能力、用户操作负担更低。CE包含五大模块:动态检索、记忆系统、工具使用、提示工程和上下文更新机制,不同场景可灵活组合。以AI编程助手为例,CE通过显式配置文件(编码规范等)和隐式交互信息(代码片段、对话历史)的智能组合,显著提升代码生成质量。CE代表了AI开发范式
AI Agent | 也说说上下文工程(Context Engineering)
导读
前面AI知识点 | 都2025年了,还需要打磨提示词能力吗?讲到提示词作为用户和大模型的桥梁,已经作为工程化管理的手段之一,是为提示词工程(Prompt Engineering, 下文简称PE)。然而为了让大模型生成内容效果更好,业界对喂给大模型的内容进一步提高了管理的颗粒度,是为上下文工程(Context Engineering,下文简称CE)。
本篇来聊聊上下文工程,包括CE和PE的区别、CE主要有哪些模块,从CI Coding视角看如何落地CE。
Why:从CE和PE的区别来看为什么需要CE?
大模型好比受过高等教育的大学生,在具体业务场景落地大模型好比大学生作为新人入职公司,要让新人成为合格员工并做出实质性的工作贡献往往需要导师的带教。如果你作为新人的导师,用PE方式该怎么交代工作?即你每次都要整理本次工作要求,收集项目及组织的流程规范、汇总近期的工作反馈等信息。导师每次措辞稍后差错可能新人交出的结果就会不一样。
但如果用CE方式呢?导师工作将大大减轻,按板块依次调取对应内容。你每次交代的事情清晰且可控。最关键的是即使换了别的新人该做法依然有效且可重复。换句话说PE更强调人的作用(是一种human-in-the-loop),下限没保障,CE更强调系统的作用(是一种system-in-the-loop),下限有保障,上限也更高。
CE和PE主要有以下4种区别:
1. CE方式更稳定、可重复
提示词工程依赖手动调整措辞,微小变化可能导致结果大幅波动,存在脆弱性和不可复现性;上下文工程通过标准化模板、变量定义、语义约束等方法,将交互逻辑固化为可复用规则,减少结果不确定性,实现从 “玄学” 到 “可控科学” 的转变。
2. CE方式可扩展性
提示词工程是手动迭代优化,面对大量用户、多样化用例或边缘情况时,难以批量适配,扩展性极差;上下文工程聚焦多场景、高并发需求,通过状态管理、动态参数注入、场景化配置等能力,可支撑复杂系统的规模化运行,无需为每个场景重复优化指令。
3. CE方式有状态、可连续、有记忆
提示词工程本质是单轮对话的“一次性”交互设计,缺乏状态管理能力,无法处理长对话、多步骤任务(如流程化审批、多轮咨询);上下文工程核心具备状态存储与调用能力,能记忆历史交互信息、维护任务进度,适配需要连续决策的复杂交互场景。
4. CE方式负担小
提示词工程将构建详尽指令的负担完全交给用户,需用户具备专业技巧才能产出有效结果,门槛高且不适合自主运行的系统;上下文工程通过封装交互逻辑、预设场景模板、自动补全上下文,降低用户操作负担,让非专业用户也能通过简单输入触发复杂任务,实现“系统替用户扛重”。
小结一下:
上下文工程与提示词工程的核心差异体现在 “稳定性、扩展性、状态管理、用户依赖” 四个维度,前者是系统化解决复杂场景的“工程化方案”,后者是单轮优化指令的“技巧性操作”。
CE本质上是对PE的优化,即如何在固定的上下文窗口内,固定的token量,最大化给出有用的有相关性的“信号”,反过来说就是最小化不相关的“噪声”,从而让大模型理解的更到位、更有效。
What:CE的主要模块
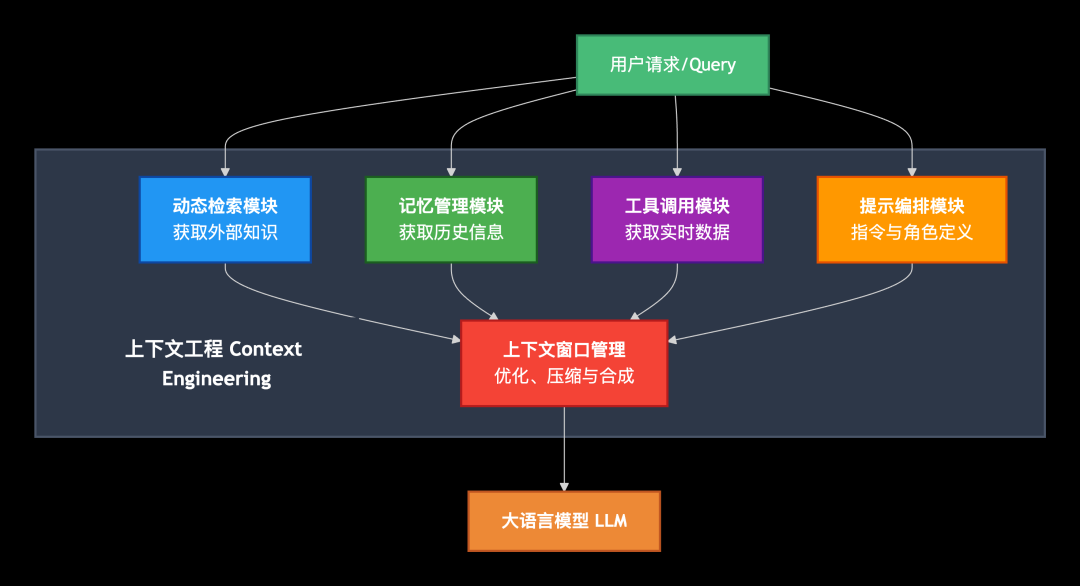
如下图所示,好的CE包括下列5个模块:
- 动态检索:动态获取企业内外部知识。详情将在下次单篇展开。
- 记忆:包括短期记忆(历史对话)、长期记忆(用户偏好及画像等)。详情将在下次单篇展开。
- 工具使用:告知大模型当前智能体依赖的外部工具信息,让大模型帮忙决策是否要访问、如何访问这些工具。详见AI工程 | MCP是怎么跟大模型交互的?
- 提示工程:提示词基本内容,包括用户问题、任务指令、任务示例及规则、模型响应格式定义等。详见前文AI知识点 | 都2025年了,还需要打磨提示词能力吗?
- 上下文整体更新模块:用户和大模型长时间交互后,上下文内容膨胀,需要保证上下文内容的灵活更新汰换。
小结一下:
记住CE的目的只有一个:不提高成本的前提下取得最好的大模型生成效果。CE的这5个模块不是必须的,不同的项目侧重点不一样,比如AI客服场景重依赖相关的企业知识库于是会花力气建设动态检索模块,业务流程复杂的场景依赖的外部工具多于是花力气建设MCP工具模块,有些场景没有冷启动的长期记忆数据,可能在上线后依据用户短期记忆的积累逐渐形成长期记忆,亦或者对话轮数少的场景先不考虑上下文的压缩合成。总之不同场景对不同模块的建设必要性和先后性不尽相同,需根据业务来调整技术路线和方向。
How:案例分析之AI Coding Agent里的CE
协助编程是近几年市面上非常活跃的一个智能体落地场景,这些AI Coding Agent产品大多具备代码补全、代码编写、bug修复、任务规划等能力。比较知名的有:Github的Copilot、Anthropic的Claude、Anysphere的Cursor、字节的Trae、百度的秒搭、阿里云的魔搭等。
为了让Coding Agent生成出更高质量的编码,上下文工程的架构设计是非常关键的环节。如何在每次代码生成前喂给大模型最贴切的上下文信息?
通过文件传递显示上下文
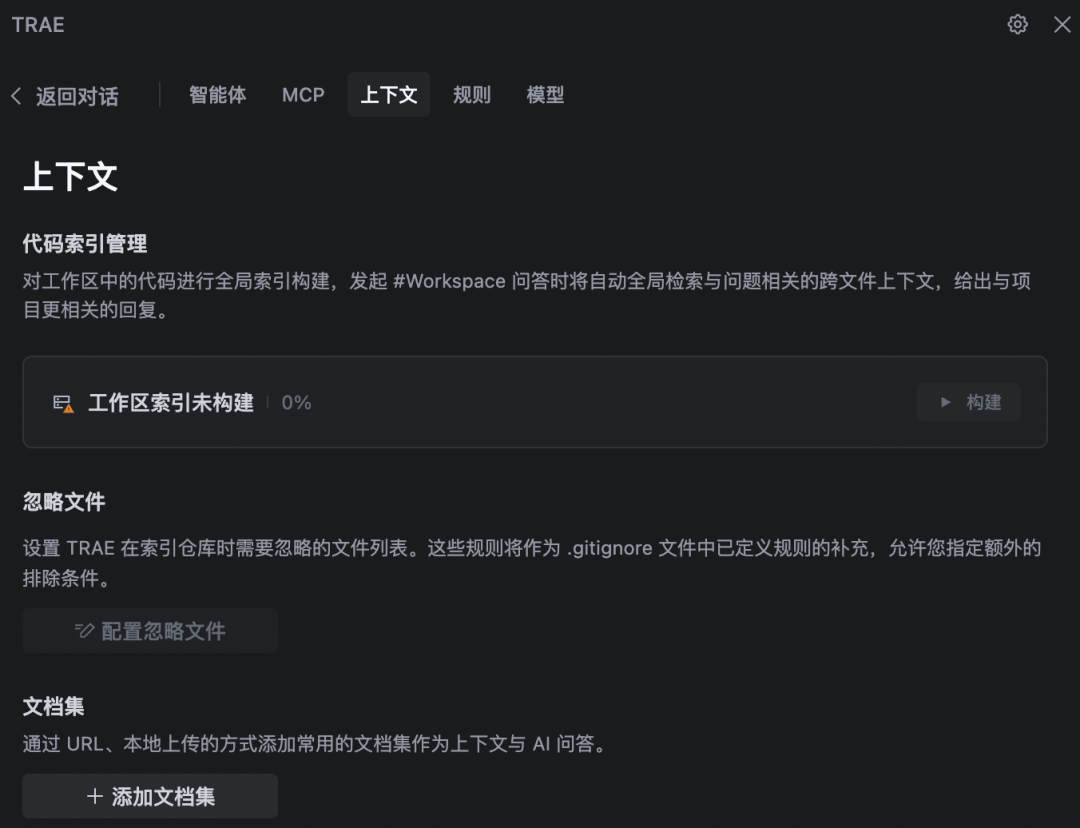
绝大部分Coding Agent产品都采用预置专门的文件让用户来填充自己的编程要求,比如项目架构约定、代码风格和规范。Coding Agent每次都会把这些持久化的配置信息喂给大模型。用户可以直接编辑文件如Claude里的CLAUDE.md文件、也可以通过界面做配置。
比如Trae里把这些显示的上下文划分为智能体(任务列表、运行方式、依赖的其他智能体)、MCP(依赖的工具)、上下文(依赖的代码文件、文档)、规则(编码规范)、模型(基础大模型规格)。
动态组装隐式上下文
另一类上下文是隐式的,也非常影响编码的质量。比如用户在与Coding Agent交互时的界面信息:用户当前编辑的代码文件,高亮出来的一段代码、用户在对话框里明确指向的某段代码等等。还有一类是用户和Coding Agent对话过程中产生的历史对话。
上下文信息按组织结构分层
显示的上下文往往还需要区分个人、项目、全局。可能用user_rules.md、project_rules.md等不同的文件进行隔离保存。

小结一下
从上面可以看出Coding Agent里的CE工作流程大概是:收集显示或隐式的上下文信息,起到降低噪音提高信号的作用,然后用模板化方式拼接各模块上下文,每次在调用大模型后刷新上下文。这个大部分Agent产品里的CE并无二致。关键是CE里的各部分信息的设计,包括在哪个层次上结构抽象?如何暴露给用户参与编写?如何动态选用?
持久化上下文信息相当于给大模型配备了长期记忆和行为指南,充当了项目和用户的大脑,使Coding Agent不会因时间或任务切换而遗忘先前约定。这种跨任务的一致性延续大大减少了人工提醒的负担。这在复杂项目中尤其关键,因为项目的编写需要跨越一个时间周期,期间会有产品需求设计调整,代码审核和重构。这极大提升了AI作为编程助手的实用性,使其真正在长期项目中发挥价值。
随着Coding Agent的普及,作为研发人员在不远的将来,可能将要花很多精力来编写项目的上下文文件,如同现在编写项目的README和编码规范一样。
结语
上下文工程CE的兴起并非简单地为旧概念换上新标签,而是AI开发范式的根本性转变。CE不仅是关于提供上下文,更是关于如何策划和塑造上下文,在AI Agent时代,掌握上下文工程就是掌握了让AI真正发挥价值的钥匙。
最近这几年,经济形式下行,IT行业面临经济周期波动与AI产业结构调整的双重压力,很多人都迫于无奈,要么被裁,要么被降薪,苦不堪言。但我想说的是一个行业下行那必然会有上行行业,目前AI大模型的趋势就很不错,大家应该也经常听说大模型,也知道这是趋势,但苦于没有入门的契机,现在他来了,我在本平台找到了一个非常适合新手学习大模型的资源。大家想学习和了解大模型的,可以**点击这里前往查看**

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)