性能实测!Redis 8.0向量库 vs Milvus/Pinecone,谁才是大模型RAG的性价比之王?
在大模型知识库开发领域,向量数据库的选择直接影响系统的性能、扩展性和开发效率。随着Redis 8.0推出Vector Set数据结构并增强向量搜索能力,开发者面临新的选择困境:是采用传统专用向量数据库(如Milvus、Pinecone),还是拥抱Redis这一“新晋”向量存储解决方案?本文将从技术架构、性能指标、成本效益和典型场景四个维度,为您提供一套完整的决策框架,帮助您在大模型知识库开发中做出
在大模型知识库开发领域,向量数据库的选择直接影响系统的性能、扩展性和开发效率。随着Redis 8.0推出Vector Set数据结构并增强向量搜索能力,开发者面临新的选择困境:是采用传统专用向量数据库(如Milvus、Pinecone),还是拥抱Redis这一“新晋”向量存储解决方案?本文将从技术架构、性能指标、成本效益和典型场景四个维度,为您提供一套完整的决策框架,帮助您在大模型知识库开发中做出最优选择。

一、Redis 8.0向量能力深度解析
Redis 8.0的向量支持并非简单功能叠加,而是从底层数据结构到查询引擎的全方位革新。其核心Vector Set数据类型由Redis创始人Salvatore Sanfilippo亲自设计,基于改进的Sorted Set结构扩展而来,支持存储高维向量(如768维的文本嵌入)并执行高效的相似性搜索。与传统的Sorted Set使用score进行排序不同,Vector Set通过内置的HNSW(Hierarchical Navigable Small World)算法实现近似最近邻搜索,在百万级向量库中Top 100近邻查询延迟可低至1.3秒(含网络往返)。
Redis向量搜索的技术实现包含三个关键层:
- 存储引擎:向量数据以紧凑格式存储在内存中,支持float32和int8两种精度,内存占用优化达40%;
- 索引层:默认采用HNSW算法,支持可配置的参数(如
efConstruction和M),平衡构建时间和查询精度; - 查询层:通过Redis Query Engine实现混合查询,支持向量相似度计算与标量过滤条件组合。
HNSW算法复杂度公式:
构建复杂度: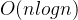
查询复杂度: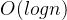
内存占用: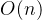
其中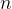 为向量数量。
为向量数量。
与独立向量数据库相比,Redis 8.0的独特优势在于亚毫秒级延迟和实时数据更新能力。传统向量数据库如Milvus的索引构建往往需要秒级甚至分钟级时间,而Redis的Vector Set支持增量更新,新插入向量立即可查,这对实时推荐、对话式AI等场景至关重要。此外,Redis原生支持的TTL(Time-To-Live)机制使其天然适合作为语义缓存层,缓存频繁查询的RAG结果,显著降低大模型API调用成本。
二、与传统向量数据库的对比分析
1.性能指标对比
通过基准测试数据对比Redis 8.0与主流向量数据库的关键指标:
| 数据库 | 查询延迟 | 写入吞吐 | 最大数据规模 | 索引构建时间 | 召回率@10 |
|---|---|---|---|---|---|
| Redis 8.0 | <1ms | 50K ops/s | 千万级 | 实时更新 | 0.92 |
| Milvus | 5-10ms | 10K ops/s | 百亿级 | 分钟级 | 0.98 |
| Pinecone | 10-20ms | 5K ops/s | 十亿级 | 秒级 | 0.95 |
| Elasticsearch | 10-30ms | 3K ops/s | 亿级 | 分钟级 | 0.90 |
| Chroma | 5-10ms | 1K ops/s | 百万级 | 秒级 | 0.85 |
从表中可见,Redis在低延迟和高吞吐场景具有明显优势,但在超大规模数据集(十亿级以上)和召回率指标上略逊于专用向量数据库。这种差异源于技术架构的不同选择:Redis优先保证实时性和简单性,而Milvus等系统通过更复杂的分布式架构和索引算法追求极限规模和精度。
2.功能特性对比
除基础向量搜索外,不同解决方案在高级功能上各具特色:
混合查询能力:
- Redis 8.0:支持向量搜索与JSON字段过滤组合,如“查找相似商品且价格<100元”
- Elasticsearch:提供关键词(BM25)与向量混合检索,通过公式组合两种分数:
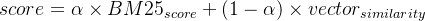
- Milvus:支持复杂的标量过滤表达式,如“人脸相似度>0.8且年龄在20-30岁之间”
多模态支持:
- Pinecone:专为多模态设计,支持文本、图像、音频的统一向量空间
- Weaviate:内置多种嵌入模型,自动处理不同模态的向量生成
- Redis:目前主要依赖外部模型生成向量,再存入Vector Set
扩展性与分布式:
- Milvus:原生分布式设计,计算与存储分离,支持K8s扩缩容
- Pinecone:全托管Serverless架构,自动弹性扩展
- Redis:集群模式下可水平扩展,但向量搜索性能随分片数增加可能下降
3.资源消耗与成本模型
向量数据库的成本构成复杂,需考虑计算资源、存储开销和运维人力三个方面:
内存占用:以存储1亿个768维(float32)向量为例
- 原始需求:1亿 x 768 x 4字节 ≈ 293GB
- Redis:启用压缩后约176GB9
- Milvus:使用IVF_PQ索引约88GB
- VSAG(蚂蚁优化算法):仅需29GB
计算资源:
- Redis:单核处理10K QPS约需8CU(1CU=1核CPU+8GB内存)
- Milvus:同等QPS下GPU加速需2卡T4,成本高但吞吐量提升10倍
- Pinecone:Serverless按查询计费,$0.10/1000次查询
总拥有成本(TCO)估算公式:
TCO = (内存成本 × 容量 + CPU成本 × 计算单元 + GPU成本 × 卡数) × 时间 + 运维人力成本
运维复杂度:
- Redis:成熟工具链,但向量功能较新,监控指标不全
- Milvus:分布式部署复杂,需专业团队维护
- Pinecone:免运维但失去控制权,不适合数据敏感场景
三、场景化选型策略
1.实时性优先场景
典型场景:在线推荐系统、对话式AI、欺诈检测
推荐方案:Redis 8.0 + 语义缓存层
优势分析:
- 亚毫秒延迟满足实时交互需求
- TTL机制自动淘汰过期特征,如用户短期兴趣变化
- 与现有缓存架构无缝整合,降低系统复杂度
实施建议:
- 热数据驻留Redis,冷数据归档至Milvus/Pinecone
- 使用混合查询过滤敏感内容,如“相似商品但排除竞品”
- 监控
vector_search_qps和avg_response_time指标
实时推荐系统架构示例:
用户请求 → Redis实时特征检索 → 召回Top100 → 精排模型 → 返回结果
↑
特征更新流(Kafka)
2.超大规模知识库
典型场景:企业文档检索、跨模态搜索、视频去重
推荐方案:Milvus分布式集群 + Redis前端缓存
优势分析:
- 百亿级向量支持,计算存储分离架构
- 多索引支持(HNSW/IVF/DiskANN),适应不同查询模式
- GPU加速显著提升批量搜索吞吐
实施建议:
- 按业务分片,如不同产品线使用独立collection
- 热分片配置HNSW索引,冷分片使用DiskANN降低内存占用
- 写入批量化为100-1000条/批次,提高吞吐
分片策略公式:
shard_key = hash(vector_id) % shard_count // 均匀分布
或
shard_key = business_unit // 业务局部性
3.快速迭代与原型开发
典型场景:创业公司MVP、学术研究、算法验证
推荐方案:Chroma(本地开发)→ Pinecone(生产部署)
优势分析:
- Chroma零依赖,
pip install即可开始 - Pinecone一键托管,免去运维负担
- 两者API相似,迁移成本低
实施建议:
- 开发环境使用Chroma+SentenceTransformers快速验证
- 生产环境切换Pinecone,利用命名空间隔离测试数据
- 通过
recall@k指标评估不同嵌入模型效果
原型验证代码示例:
# Chroma本地开发
client = chromadb.Client()
collection = client.create_collection("prototype")
collection.add(embeddings=embeds, documents=docs)
# 迁移至Pinecone
pinecone.init(api_key="xxx")
index = pinecone.Index("production")
index.upsert(vectors=zip(ids, embeds))
4.混合检索需求场景
典型场景:电商搜索、日志分析、合规审查
推荐方案:Elasticsearch + 向量插件
优势分析:
- 关键词与语义搜索无缝融合
- 成熟的分析功能(聚合、分组、统计)
- 与现有ELK栈兼容,学习曲线平缓
实施建议:
- 先使用BM25获取初步结果,再用向量搜索扩展召回
- 自定义评分公式平衡两种相关性:
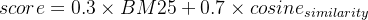
- 对高维向量启用
index: true提升搜索效率
四、迁移与演进路径
1.从传统方案过渡到Redis 8.0
对于已使用其他向量数据库的系统,迁移至Redis 8.0需分阶段进行:
并行运行阶段:
- 保持原有向量库作为主存储
- 将热点数据同步到Redis Vector Set
- 查询时先访问Redis,未命中则回源
流量切换阶段:
- 逐步提高Redis查询比例(如10%→50%→100%)
- 监控
cache_hit_rate和p99_latency - 针对长尾查询优化HNSW参数(增加
efSearch)
完全迁移阶段:
- 验证召回率差异(Redis vs 原系统)
- 迁移剩余冷数据,停用原集群
- 实施监控告警(如
vector_memory_usage)
迁移验证指标:
召回率差异 = |recall_redis - recall_original| / recall_original
延迟降低比 = (latency_original - latency_redis) / latency_original
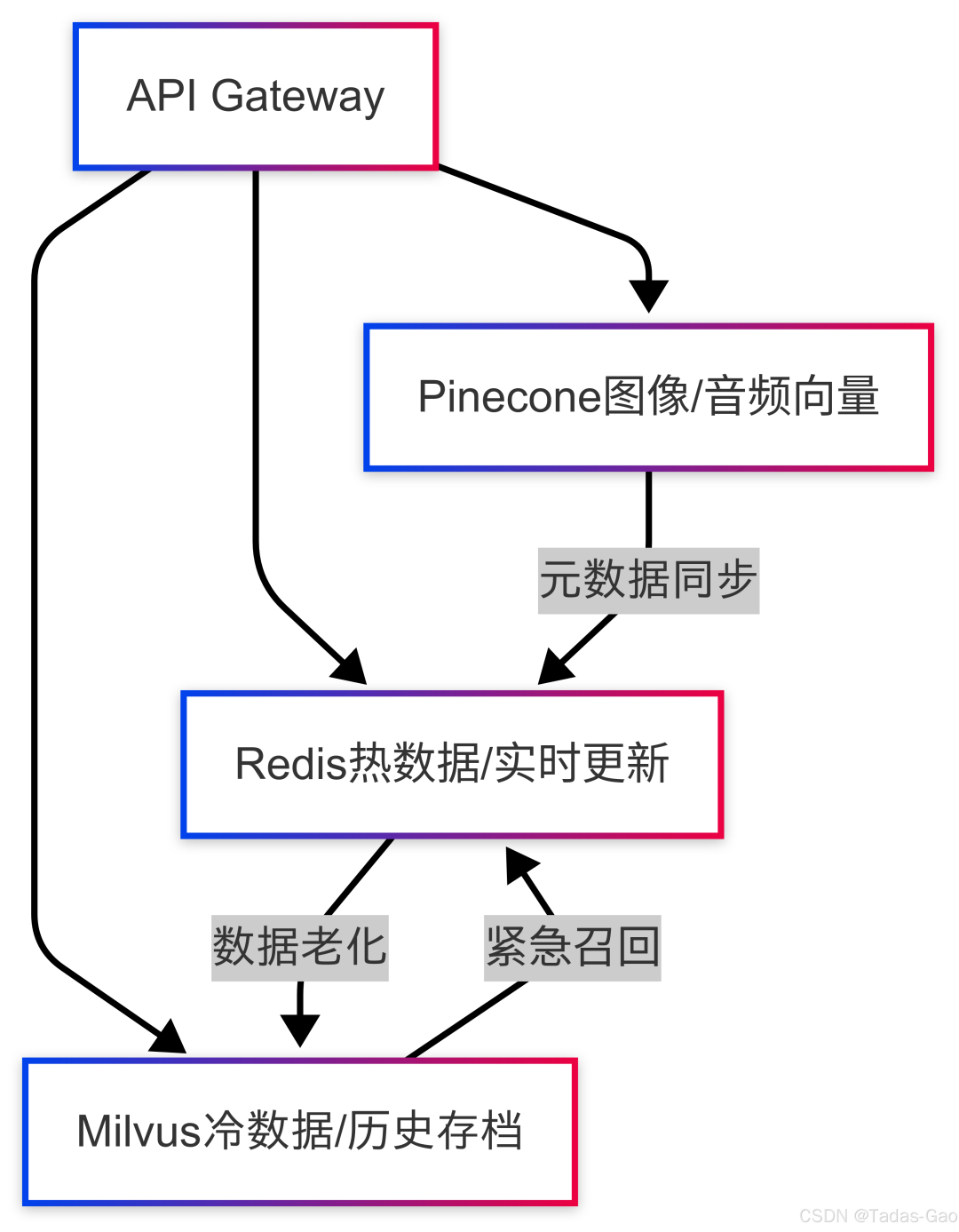
2.从Redis扩展至专业向量数据库
当Redis无法满足增长需求时,可平滑演进至分布式方案:
容量不足时:
- 先启用Redis集群模式分散数据
- 对低重要性数据启用量化压缩(float32→int8)
- 最终迁移至Milvus分布式集群
查询复杂时:
- 简单查询保留在Redis
- 复杂混合查询路由到Elasticsearch
- 通过API网关统一入口
多模态需求时:
- 文本向量保留在Redis
- 图像/音频向量存储在Pinecone多模态索引
- 应用层统一结果排序
分层存储架构示例:
五、未来趋势与选型前瞻
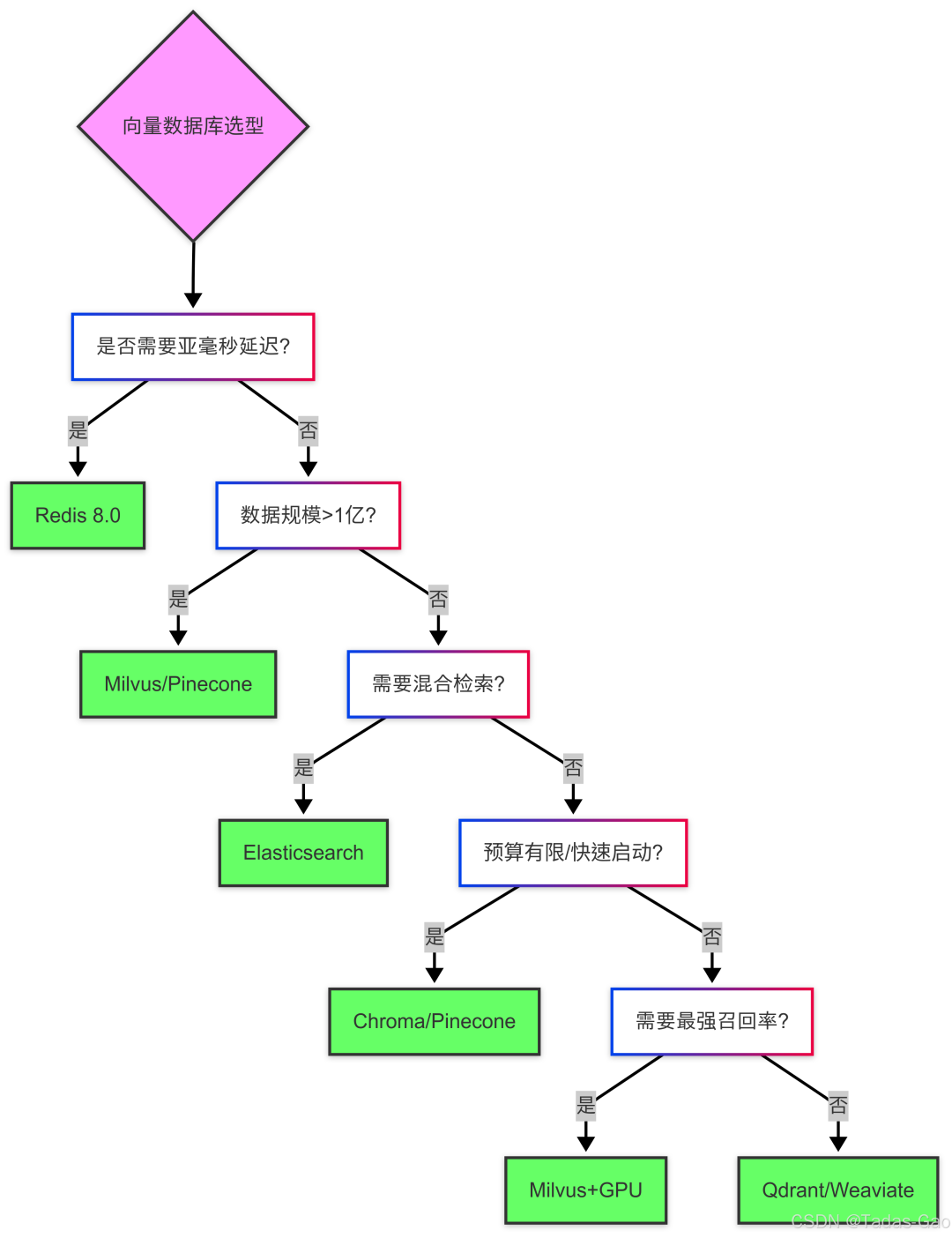
向量数据库技术仍在快速发展,几个可能影响选型决策的趋势值得关注:
- 统一查询语言:类似SQL的标准化向量查询语法出现,减少锁定风险
- 智能压缩:如VSAG的10倍压缩比技术普及,大幅降低成本
- 边缘计算:轻量级向量数据库(如Qdrant)在端侧部署成为可能
- Redis生态扩展:预计Redis将增强分布式向量搜索和GPU支持
- 多模态LLM:需要数据库原生支持跨模态联合检索
选型决策树:
无论选择何种技术栈,建议通过抽象层(如Repository模式)封装向量操作,保持系统灵活性,以应对快速演进的技术。定期重新评估选型(如每6个月),确保与业务需求持续匹配。
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
- 系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
- 高效有序的学习路径:避免无效学习,节省时间,提升效率。
- 完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
- 持续学习能力:Al技术日新月异,保持学习是关键。
- 跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
- 解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献209条内容
已为社区贡献209条内容

所有评论(0)