基于局部重要性的注意力(LIA)ACCV2024
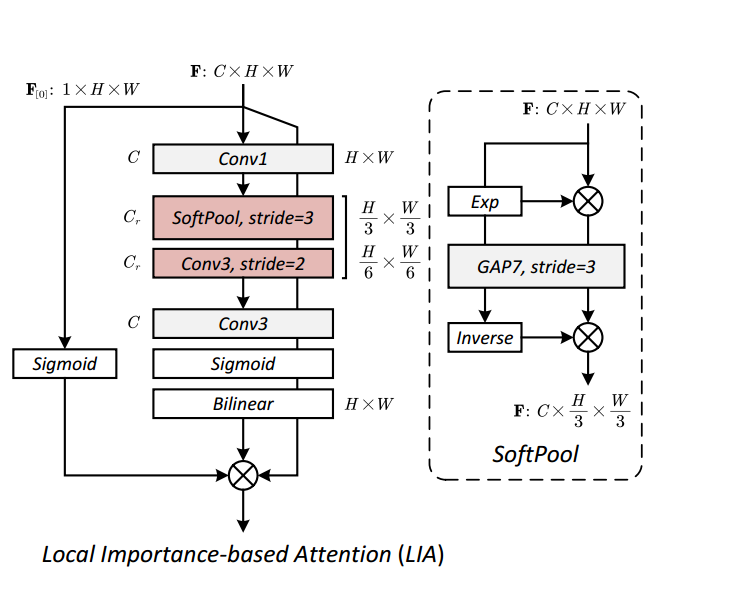
论文地址:https://openaccess.thecvf.com/content/ACCV2024/papers/Wang_PlainUSR_Chasing_Faster_ConvNet_for_Efficient_Super-Resolution_ACCV_2024_paper.pdf。# 对应公式 Eq. (4): A(X) = σ(X[0]) * ψ(σ(I(X))) * X。# ===
核心问题:性能与速度的矛盾
在图像处理中,注意力机制(Attention Mechanism)的作用是告诉模型:“哪些信息(比如图像的边缘、纹理等)更重要,需要被强化?”
-
“1阶交互”(低阶注意力,如通道注意力):
-
工作方式: 简单地计算每个通道(例如红色、绿色、蓝色通道)的平均重要性。
-
优点: 速度快,延迟低。
-
缺点: 交互简单,只考虑通道的全局信息,性能较弱,无法捕捉复杂的图像细节。
-
-
“2阶交互”(高阶注意力,如自注意力/Self-Attention):
-
工作方式: 计算特征图中每个像素(或区域)与其他所有像素之间的关系。
-
优点: 交互复杂、信息捕捉全面,性能很强。
-
缺点: 计算量大,延迟高(计算复杂度是输入尺寸的平方,即二次复杂度),在追求速度的超分辨率模型中不适用。
-
PlainUSR 的目标是: 既要像“2阶交互”那样捕捉复杂信息,又想保持“1阶交互”那样的超快速度。
LIA 的解决方案:低成本实现高阶交互
LIA 巧妙地设计了一种结构,实现了“鱼与熊掌兼得”:
| 机制 | 描述 | 效果 |
| “调制”输入特征 | LIA首先通过一个局部重要性图(Regional Importance Map)对输入特征进行加权或调制。这个图谱可以看作是初步筛选出特征图中哪些区域是重要的。 | 这一步引入了空间维度的信息,增强了模型对局部细节的关注,这是迈向“2阶交互”的关键一步。 |
| 引入通道门控机制 | 接着,它使用一个通道门控机制(Channel Gate)来控制特征的流动。这就像一个开关,决定哪些通道的信息应该被保留或放大。 | 这一步保留了传统“1阶交互”对通道重要性的判断能力。 |
| 最终结构 | 整个过程被设计成一个线性的、没有复杂矩阵乘法的结构,类似于传统的“1阶注意力”(通道注意力)。 | 实现了“2阶信息交互”(捕捉了更复杂、更局部的特征),但由于计算路径简单,保持了“1阶注意力”的低延迟特性。 |
简单来说就是: LIA 找到了一种数学上的捷径,在不使用复杂、耗时的“两两比较”操作(自注意力)的情况下,通过巧妙地结合空间加权和通道控制,实现了对重要特征的更精细的筛选和强化,从而在速度极快的情况下,提高了图像超分辨率的质量。




import torch
import torch.nn as nn
import torch.nn.functional as F
# 论文题目:PlainUSR: Chasing Faster ConvNet for Efficient Super-Resolution
# 论文地址:https://openaccess.thecvf.com/content/ACCV2024/papers/Wang_PlainUSR_Chasing_Faster_ConvNet_for_Efficient_Super-Resolution_ACCV_2024_paper.pdf
class SoftPooling2D(torch.nn.Module):
"""
软池化 (SoftPool) 实现。
对应论文中用于下采样并保留重要特征的操作 [cite: 142]。
公式:通过 softmax 加权求和来代替最大池化或平均池化。
"""
def __init__(self, kernel_size, stride=None, padding=0):
super(SoftPooling2D, self).__init__()
# 使用 AvgPool2d 来辅助计算区域内的求和(实际上是平均值,但分子分母相除后系数抵消)
self.avgpool = torch.nn.AvgPool2d(kernel_size, stride, padding, count_include_pad=False)
def forward(self, x):
# 1. 计算指数权重 e^x
x_exp = torch.exp(x)
# 2. 计算权重的局部平均 (分母部分: sum(e^x)/N)
x_exp_pool = self.avgpool(x_exp)
# 3. 计算加权特征的局部平均 (分子部分: sum(x * e^x)/N)
x = self.avgpool(x_exp * x)
# 4. 相除得到软池化结果 (分子/分母),N 被抵消
return x / x_exp_pool
class LocalAttention(nn.Module):
'''
LIA: 基于局部重要性的注意力 (Local Importance-based Attention) [cite: 134]
对应论文中的 Fig. 2 和 Eq. (4)。
'''
def __init__(self, channels, f=16):
super().__init__()
# === 中间分支:生成局部重要性图 (Importance Map) ===
self.body = nn.Sequential(
# 1. 通道压缩:对应 Fig.2 中的 "Conv1" [cite: 140]
nn.Conv2d(channels, f, 1),
# 2. 软池化下采样:对应 Fig.2 中的 "SoftPool, stride=3" [cite: 142]
# 这里的 stride=3 大幅减少了尺寸,增大了感受野
SoftPooling2D(7, stride=3),
# 3. 卷积下采样:对应 Fig.2 中的 "Conv3, stride=2" [cite: 141]
# 进一步提取特征并缩小尺寸
nn.Conv2d(f, f, kernel_size=3, stride=2, padding=1),
# 4. 特征变换:对应 Fig.2 中的 "Conv3" (下方那个) [cite: 141]
nn.Conv2d(f, channels, 3, padding=1),
# 5. 激活函数:对应 Fig.2 中的 "Sigmoid" [cite: 139]
# 生成 0-1 之间的重要性权重
nn.Sigmoid(),
)
# === 左侧分支:门控机制 (Gate) ===
# 对应 Eq. (4) 中的 σ(X[0])
self.gate = nn.Sequential(
nn.Sigmoid(),
)
def forward(self, x):
''' 前向传播 '''
# === 1. 计算门控值 (Gate) ===
# 注意:这里只取了输入的第 1 个通道 (x[:, :1]) 作为门控依据
# 论文中提到这样做是为了极致的轻量化 (Simplicity)
g = self.gate(x[:,:1].clone())
# === 2. 计算重要性图并上采样 (Importance Map) ===
# self.body(x) 生成低分辨率的重要性图 I(X)
# F.interpolate 对应 Fig.2 中的 "Bilinear" [cite: 145],将其放大回原始尺寸
w = F.interpolate(self.body(x), (x.size(2), x.size(3)), mode='bilinear', align_corners=False)
# === 3. 最终融合 (Modulation) ===
# 对应公式 Eq. (4): A(X) = σ(X[0]) * ψ(σ(I(X))) * X
# 即:原始输入 * 重要性图 * 门控值
return x * w * g
if __name__ == '__main__':
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 初始化模块,假设输入通道数为 32
block = LocalAttention(channels=32).to(device)
# 创建一个随机输入张量 (Batch_Size=1, Channels=32, Height=256, Width=256)
input = torch.rand(1, 32, 256, 256).to(device)
# 前向传播
output = block(input)
print(f"Input shape: {input.shape}")
print(f"Output shape: {output.shape}") # 形状应保持不变

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)