YOLOv8【特征融合Neck篇·第22节】Progressive Feature Pyramid,一文搞懂它!
🏆 本文收录于 《YOLOv8实战:从入门到深度优化》,该专栏持续复现网络上各种热门内容(全网YOLO改进最全最新的专栏,质量分97分+,全网顶流),改进内容支持(分类、检测、分割、追踪、关键点、OBB检测)。且专栏会随订阅人数上升而涨价(毕竟不断更新),当前性价比极高,有一定的参考&学习价值,部分内容会基于现有的国内外顶尖人工智能AIGC等AI大模型技术总结改进而来,嘎嘎硬核。 ✨ 特惠福利
🏆 本文收录于 《YOLOv8实战:从入门到深度优化》,该专栏持续复现网络上各种热门内容(全网YOLO改进最全最新的专栏,质量分97分+,全网顶流),改进内容支持(分类、检测、分割、追踪、关键点、OBB检测)。且专栏会随订阅人数上升而涨价(毕竟不断更新),当前性价比极高,有一定的参考&学习价值,部分内容会基于现有的国内外顶尖人工智能AIGC等AI大模型技术总结改进而来,嘎嘎硬核。
✨ 特惠福利:目前活动一折秒杀价!一次订阅,永久免费,所有后续更新内容均免费阅读!
全文目录:
上期回顾
各位追求卓越的探索者们,大家好!👋 在我们上一期《YOLOv8【特征融合Neck篇·第21节】Feature Selective Anchor-Free,一文带你搞懂!》内容中,我们一起学习了一种旨在打破FPN“硬性分配规则”的、极具开创性的方法——FSAF (Feature Selective Anchor-Free)。
我们首先深入探讨了传统FPN架构中一个看似合理但实则死板的“潜规则”:检测器通常会根据物体的大小,将其硬性地分配给某个特定的金字塔层级来处理(例如,小物体归P3层,大物体归P5层)。这种基于先验知识的“手工分配”,限制了模型根据数据本身进行自适应学习的灵活性。我们打了一个比方:这就像一个公司的部门职责是固定的,一个“小项目”无论其性质多复杂,都必须由“基层部门”处理,这显然是不够智能的。
FSAF以其“在线特征选择(Online Feature Selection)”机制,优雅地解决了这个问题。它的核心思想可以总结为:
-
赋予选择权:FSAF为FPN的每一个层级都配备了一个轻量级的无锚框(Anchor-Free)预测分支。这意味着,对于同一个物体,我们现在可以同时在所有层级上得到它的预测结果。这相当于给了每个项目(物体)向所有部门(特征层级)提交方案的机会。
-
“用实力说话”:在训练过程中,对于一个给定的真实物体框(Ground Truth),我们会计算它在所有层级的Anchor-Free分支上产生的损失(分类损失+回归损失)。
-
动态分配:模型会自主地选择那个能够产生最低损失的层级,作为本次迭代中负责监督该物体的“最佳层级”。这个选择过程是完全数据驱动的,并且对于每一次输入都可能是不同的。最终,哪个部门的方案(预测)做得最好,这个项目就由它来负责。
通过这种“优胜劣汰”的动态分配机制,FSAF使得每一个物体都能自主地寻找到最适合自己的特征表示。一个细节丰富的大物体,可能会选择一个分辨率较高的低层特征;而一个需要广阔上下文来辅助识别的小物体,也可能破天荒地选择一个高层特征。
总而言之,FSAF通过引入一个并行的、可选择的Anchor-Free通路,极大地增强了FPN的灵活性和表征能力。它教会了我们,与其替模型做决定,不如创造一个机制,让模型自己去学习如何做决定。
那么,既然FSAF让物体可以“选择”最好的特征,一个新的问题随之而来:我们能否在物体进行选择之前,就让所有层级的特征本身变得更强、更优、更一致呢?今天,我们将要学习的Progressive Feature Pyramid,正是为了回答这个问题而来!准备好了吗?让我们进入特征“渐进增强”的全新领域!✨
摘要:
特征金字塔网络(FPN)及其变体(如PANet, BiFPN)通过单次或双向的特征融合路径,有效地整合了多尺度信息。然而,这些方法大多采用“一蹴而就”的融合策略,特征一旦生成,便直接用于后续预测,缺乏一个深度精炼的过程,导致不同层级特征间的语义鸿沟依然存在,融合效果有待提升。本文将以超万字的篇幅,深入剖析一种旨在通过多阶段、渐进式构建来提升特征质量的先进Neck架构——PFP(Progressive Feature Pyramid)。我们将从其核心的“渐进式增强”思想出发,详细解构PFP如何通过堆叠多个特征融合阶段,实现对金字塔特征的层次化、迭代式优化。文章还将探讨PFP中实现“自适应融合权重”的关键技术,如注意力机制的应用,并提供一个包含核心逻辑的PyTorch实现与详尽解析。通过本文,读者将深刻理解PFP如何通过“步步为营”的精炼策略,生成语义信息更丰富、尺度一致性更强的特征金字塔,从而在多个检测基准上取得显著性能提升。
一、引言:FPN“一次性融合”的局限性
大家好!今天,我们继续在特征金字塔的优化之路上深入探索。在过去的分享中,我们已经见证了从FPN的单向融合,到PANet的双向奔赴,再到BiFPN的加权交互,每一次演进都让特征融合的效率和效果迈上了新的台阶。
1.1 FPN/PANet的“一步到位”模式
然而,这些主流的Neck架构,在它们的顶层设计哲学上,都有一个共同的特点:它们都试图通过一个精心设计的、固定的融合路径,来一次性地完成从骨干特征到最终预测特征的转换。
无论是FPN的“自顶向下”,还是PANet的“先下后上”,整个信息融合过程就像一条预设好的流水线。特征原料从一端进去,经过一系列的加工(上采样、下采样、拼接、卷积),成品从另一端出来,然后直接送往检测头。这个过程是的、前馈的。
1.2 “一步到位”潜藏的问题:融合不充分
这种“一步到位”的设计虽然高效,但也带来了一个难以回避的问题:融合可能不充分。这并非危言耸听,而是由深度网络中特征的层级特性决定的。
1.2.1 难以逾越的“语义鸿沟”
让我们来思考一个具体场景:在FPN中,来自Backbone最高层C5的特征(经过1x1卷积后得到P5),拥有最强的语义信息(知道“这是一辆车”),但空间细节几乎丢失殆尽。而来自较低层C3的特征,则拥有丰富的空间细节(能看清车轮的轮廓),但语义信息较弱(只知道“这里有圆形和直线”)。
FPN试图通过 Upsample(P4) + P3 这样的操作来弥合这一“语义鸿沟(mantic Gap)”。但这真的足够吗?这更像是一次“物理混合”而非“化学反应”。一次简单的逐元素相加,很难让C3中的每一个像素都深刻理解到来自C5的全局语义,也很难让C5的语义概念精准地附着到C3的空间结构上。就好比让一位只懂艺术的CEO(P5)和一位只懂技术的工程师(C3)开一次短会就要求他们完美合作,这几乎是不可能的。
1.2.2 信息传递的“稀释效应”
信息在自顶向下的传递过程中,还存在“稀释效应(Dilution Effect)”。P5的强语义信息,首先要经过上采样,这个过程本身就可能造成信息的模糊;然后与P4融合生成新的P4;这个新的P4再经过上采样,与P3融合。
在这个链式传递中,源自P5的最纯粹的语义信息,每向下一层,就会被该层更强的、但也更“嘈杂”的空间信息所“稀释”。传递到最底层的P2时,最初的强语义信号可能已经变得相当微弱了。
1.3 PFP的破局之道:从“一次建成”到“分期精装”
面对这些问题,Progressive Feature Pyramid (PFP) 提出了一种全新的、颠覆性的构建范式。它的核心思想,可以用一个生动的比喻来解释:
传统的FPN/PANet就像是建筑队交付的“房”。房子的主体结构(骨干网络)和基础的水电管线(Neck)都已经铺设完毕,可以直接入住,但居住体验比较粗糙。
而PFP则像一个追求极致的“装修团队”。它认为“清水房”远未达到最佳状态。它会在这个基础上,进行:
- 第一期精装(Stage 1):对整个房子进行第一次全面的装修,比如墙面找平、铺设基础的地板和瓷砖。这对应PFP的第一个融合阶段,生成一个初步增强的特征金字塔。
- 第二期豪装(Stage 2):在第一期装修的基础上,进行更细致的打磨,比如墙面贴上壁纸、地板打蜡抛光、安装定制橱柜。这对应PFP的第二个融合阶段,对已经增强过的特征进行再增强。
- 第N期软装(Stage N):…以此类推,直到整个房子(特征金字塔)被打磨得尽善尽美。
PFP将特征金字塔的构建,从一个单阶段“建造”过程,转变为一个多的“渐进式精炼”过程。每一次精炼,都让特征变得更优质、更强大。
二、PFP核心原理:渐进式特征构建
PFP的实现方式非常直观,它将“大事化小,分步解决”的工程思想运用到了网络设计中。
2.1 核心思想:迭代式精炼 (Iterative Refinement)
PFP的核心在于迭代。它不满足于只进行一次特征融合,而是将融合操作重复多次。在每一次新的迭代中,它都以上一轮迭代产生的、已经得到初步增强的特征金字塔作为输入,对其进行新一轮的、更深层次的融合与增强。
这个过程就像一位画家画油画,他不会一笔就画出最终的颜色,而是会先铺一层底色(Stage 1),再在底色上叠加第二层颜色(Stage 2),再叠加高光和阴影(Stage 3),通过层层叠加,最终的作品才拥有丰富的色彩和深度。
2.2 PFP的宏观架构:堆叠的融合阶段
PFP的实现,就是将多个FPN(或PANet)式的融合模块(我们称之为 Fusion Stage)串联(stack)起来。
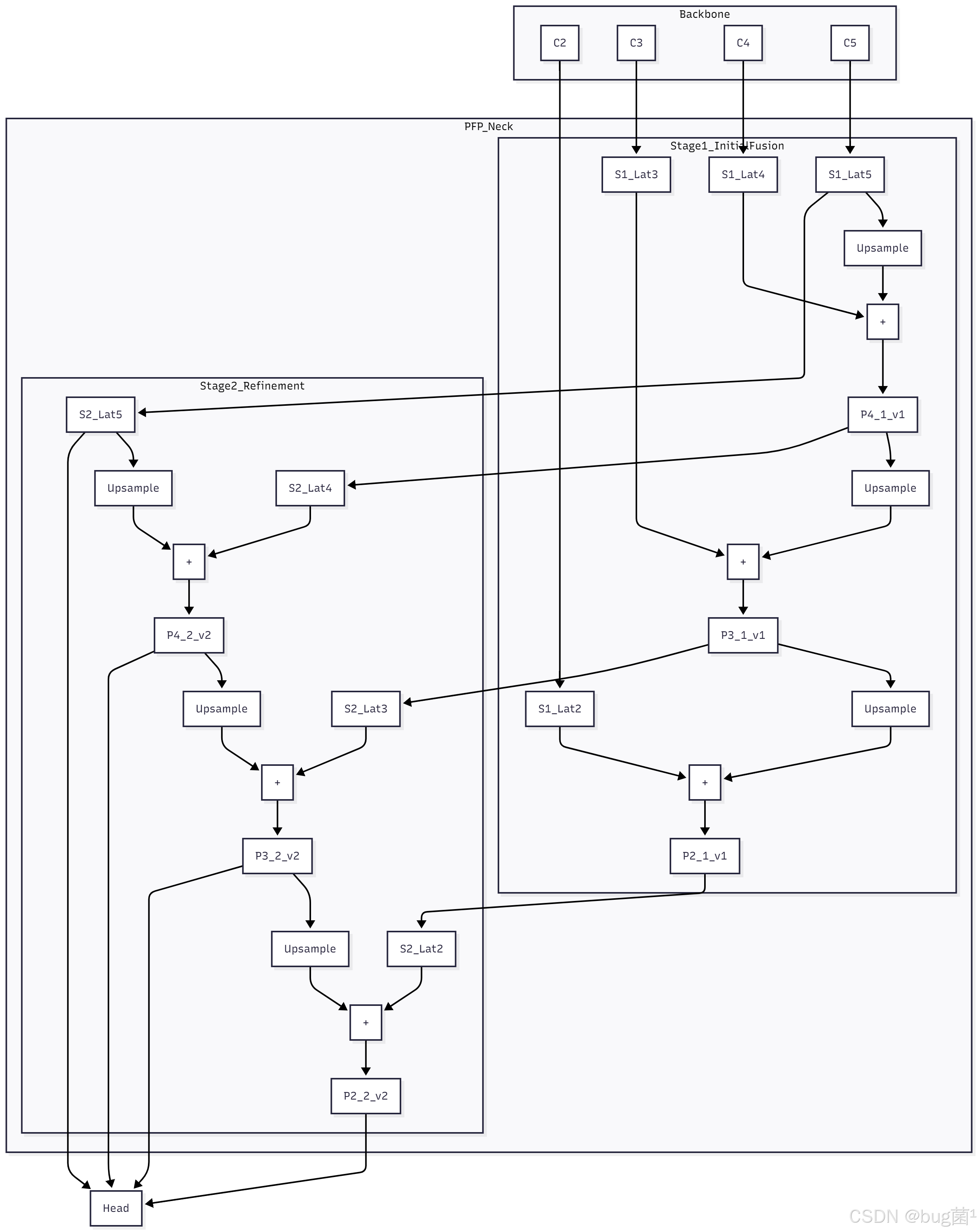
从图中可以看到:
- Stage 1:这是一个标准的FPN。它接收来自骨干网络的特征
C2-C5,经过一次自顶向下的融合,生成了第一版特征金字塔{P2_1, P3_1, P4_1, P5_1}。这可以看作是“清水房”建好了。 - Stage 2:它的输入,不再是原始的骨干特征,而是 Stage 1 的输出
{P2_1, P3_1, P4_1, P5_1}。它在这个已经初步融合过的特征金字塔之上,又进行了一次完整的自顶向下融合,最终生成了第二版、也是质量更高的特征金字塔{P2_2, P3_2, P4_2, P5_2}。这个最终产物才会被送往检测头。
2.3 层次化信息融合:每一阶段的“再思考”
PFP的强大之处在于,每一阶段的融合都是在前一阶段基础上的“再思考”。让我们聚焦于P3层特征的演变:
- 在 Stage 1:
P3_1是由C3和上采样后的P4_1融合而成。P4_1本身只融合了C4和C5的信息。这次融合是第一次跨越语义鸿沟的尝试,效果可能比较粗糙。 - 在 Stage 2:此时,与上采样后的
P4_2进行融合的,是P3_1!P3_1已经是一个“半成品”了,它比原始的C3懂更多的语义。而P4_2更是重量级,它是对P4_1(一个半成品)和P5_2(另一个深度融合的半成品)进行再融合的产物。
因此,Stage 2 中的 P3_1 + Upsample(P4_2),是一次更高质量、更高起点的融合。信息不再是“从零开始”混合,而是在一个已经比较优良的特征基础上进行精加工。
2.4 语义增强策略:信息滚雪球效应
通过这种渐进式的方式,信息在PFP中形成了“滚雪球”效应。每一次迭代,特征金字塔的整体质量都在提升,层级间的语义一致性都在增强。
想象一下P3层特征的“进化史”:
- 初始状态 (C3):只有较强的空间信息和中等强度的语义信息。
- Stage 1后 (P3_1):吸收了来自C4和C5的语义,语义变强,但可能与自身的空间细节结合得还不够完美。
- Stage 2后 (P3_2):
P3_1再次吸收了来自P4_2和P5_2的、已经经过一轮深度融合的、语义更强且更一致的信息。这一次的融合使得最终的P3_2不仅语义极强,而且与自身的空间细节结合得更紧密、更协调。
经过多轮“打磨”,最终输出的特征金字塔,其各个层级之间的语义鸿沟(Semantic Gap)被极大地弥合,尺度与语义的分布更加平滑和一致。
三、关键机制:自适应融合与质量评估
简单地堆叠FPN模块虽然能提升性能,但还不够“智能”。一个更精巧的PFP,会引入自适应融合机制。
3.1 为何需要自适应融合?
在Stage 2中,当我们将上一阶段的特征 P_i^1 与当前阶段正在融合的特征进行结合时,一个简单粗暴的相加(+)或拼接(Concat)可能不是最优的。
因为,经过Stage 1的融合后,P4_1 可能已经非常完美了,而 P3_1 可能还存在一些噪声。那么在Stage 2中,我们或许希望在生成 P3_2 时,能更多地依赖从 P4_2 传递下来的新信息,而在生成 P4_2 时,则更多地保留 P4_1 自身的优良特性。
这就需要网络能够自主地、动态地学习一个权重,来决定在融合时,不同来源的特征应该占多大的“话语权”。
3.2 引入注意力:让网络学会“权衡”
**注意力机制(Attentionechanism)**是实现自适应融合的完美工具。我们可以在融合的关键节点插入一个轻量级的注意力模块。这个模块的任务,就是分析输入特征的“质量”,然后为不同的特征源生成一个权重。
例如,在Stage 2的融合点:
P i 2 = C o n v ( f a d a p t i v e ( P i 1 , U p s a m p l e ( P i + 1 ) ) ) P_i^2 = Conv( f_adaptive( P_i^1, Upsample(P_{i+1}^) ) ) Pi2=Conv(fadaptive(Pi1,Upsample(Pi+1)))
其中 f_adaptive 就是自适应融合函数,它可以是一个简单的加权求和:
f a d a p t i v e ( A , B ) = w A ⋅ A + w B ⋅ B f_adaptive(A, B) = w_A · A + w_B · B fadaptive(A,B)=wA⋅A+wB⋅B
而权重 ( w A , w B w_A, w_B wA,wB) 就可以由一个注意力模块根据 A 和 B 的内容动态生成。
3.3 一个典型的自适应融合模块设计
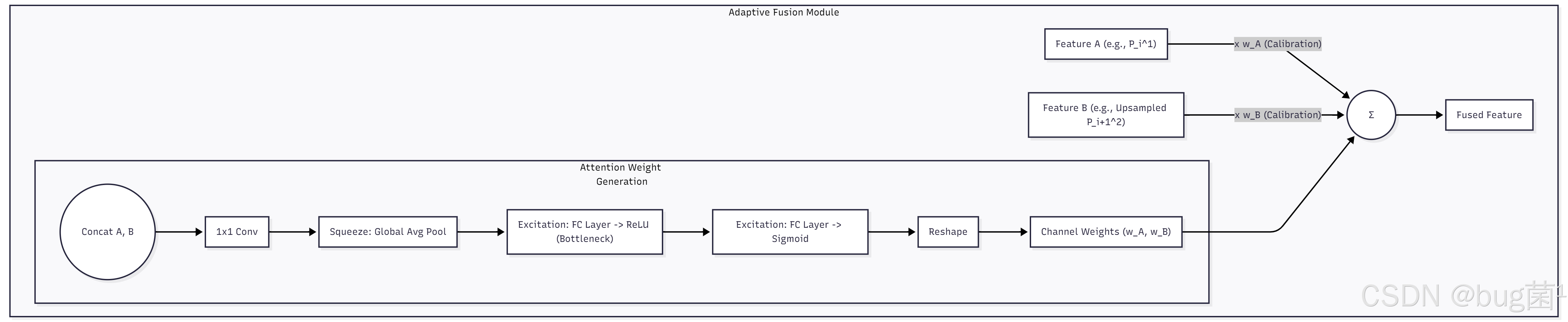
这个模块借鉴了SENet和BiFPN的思想,通过全局平均池化来捕捉全局的通道信息,然后通过两个全连接层来学习通道之间的非线性依赖,最终生成每个通道的融合权重。
四、PFP架构变体与实现细节
PFP是一个高度灵活的框架,可以有多种不同的实现方式。
4.1 输入源的选择:是否重用骨干特征?
在我们的基础架构中,Stage 2 的输入完全来自于 Stage 1。但一种常见的变体是,在每一个精炼阶段,都重新引入原始的骨干特征。
例如,在Stage 2中,用于生成 P4_2 的横向连接输入,可以是 Concat(C4, P4_1),然后再通过1x1卷积进行降维。这样做的好处是,可以防止在多轮迭代中,原始的、最纯粹的空间细节信息被“冲刷”掉,保证了特征的多样性,相当于在每次精装修时,都回头参考一下最初的建筑图纸,防止偏离方向。
4.2 融合路径的选择:FPN vs. PANet
PFP的基础融合单元(Fusion Stage)不一定非得是FPN。我们完全可以用一个更强大的PANet(包含自顶向下和自底向上两条路径)作为基础单元。这样,一个两阶段的PFP,其内部就包含了整整四条信息融合路径,信息交互会变得空前地充分。当然,这样做的计算成本也会相应地大幅增加。
五、PyTorch从零实现与代码解析
理论的魅力终须代码的支撑。💻 让我们来实现一个简化但包含核心思想的PFPNet。我们将使用FPN作为基础融合单元,并省略复杂的自适应权重模块,以突出其“渐进式”的核心结构。
5.1 基础融合单元:FPNStage 模块
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import List, Dict
# 假设我们有一个基础的Conv模块
class Conv(nn.Module):
# Standard convolution block
def __init__(self, c1, c2, k=1, s=1, p=0, act=True):
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, p, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.ReLU(inplace=True) if act else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class FPNStage(nn.Module):
def __init__(self, in_channels_list: List[int], out_channels: int):
"""
单个FPN融合阶段 (Single FPN Fusion Stage)
这是构成PFP的基础单元
Args:
in_channels_list (List[int]): 输入的多层级特征的通道数列表
For Stage 1, this is from backbone.
For Stage >1, this is from the previous stage.
out_channels (int): FPN输出的统一通道数
"""
super(FPNStage, self).__init__()
self..out_channels = out_channels
# 横向连接 (Lateral Connections)
# 它的作用是将输入特征的通道数统一out_channels
self.lateral_convs = nn.ModuleList()
for in_channels in in_channels_list:
self.lateral_convs.append(Conv(in_channels, out_channels, k=1))
# Top-Down路径中用于平滑特征的3x3卷积
# 在FPN论文中, 这个卷积用于消除上采样带来的混叠效应
self.fpn_convs = nn.ModuleList()
for _ in in_channels_list:
self.fpn_convs.append(Conv(out_channels, out_channels, k=3, p=1))
def forward(self, inputs: List[torch.Tensor]) -> List[torch.Tensor]:
# inputs: 列表形式的特征图, 例如 [C3, C4, C5] or [P3_prev, P4_prev, P5_prev]
# 1. 对所有输入特征进行横向连接 (1x1 conv), 得到初始的P_i
# 这是自顶向下路径的起点
laterals = [conv(x) for conv, x in zip(self.lateral_convs, inputs)]
# 2. 自顶向下进行融合 (Top-down pathway)
# 我们从最高层特征(列表的最后一个元素)开始, 逐级向下融合
for i in range(len(laterals) - 1, 0, -1):
# 获取下一层(更低层)的空间尺寸
prev_shape = laterals[i-1].shape[2:]
# 将当前层(更高层)的特征上采样, 然后与下一层特征逐元素相加
laterals[i-1] = laterals[i-1] + F.interpolate(laterals[i], size=prev_shape, mode='nearest')
# 3. 对融合后的所有层级特征进行3x3卷积以平滑和提炼
outputs = [conv(x) for conv, x in zip(self.fpn_convs, laterals)]
return outputs
5.2 核心架构:PFPNet 模块
class PFPNet(nn.Module):
def __init__(self,
backbone_channels: List[int], # 骨干网络输出的通道数列表
neck_channels: int, # Neck中统一的通道数
num_stages: int = 2): # PFP的阶段数
"""
Progressive Feature Pyramid Network
Args:
backbone_channels (List[int]): 来自骨干网络的多尺度特征通道数, e.g., [512, 1024, 2048] for ResNet C3,C4,C5
neck_channels (int): Neck中所有特征图的统一通道数, e.g., 256
num_stages (int): 精炼阶段的数量. num_stages=1 等价于一个标准的FPN.
"""
super(PFPNet, self).__init__()
assert num_stages >= 1, "Number of stages must be at least 1."
self.num_stages = num_stages
# 使用nn.ModuleList来存储所有渐进式阶段
self.stages = nn.ModuleList()
# --- Stage 1 ---
# 第一个阶段的输入通道数由骨干网络决定
self.stages.append(FPNStage(backbone_channels, neck_channels))
# --- Refinement Stages (Stage 2 onwards) ---
# 从第二个阶段开始, 输入通道数已经被前一阶段统一为 neck_channels
for _ in range(num_stages - 1):
# 构建后续阶段的输入通道列表, 此时所有层级的通道数都是neck_channels
stage_input_channels = [neck_channels] * len(backbone_channels)
self.stages.append(FPNStage(stage_input_channels, neck_channels))
def forward(self, backbone_features: List[torch.Tensor]):
"""
PFPNet的前向传播
Args:
backbone_features (List[torch.Tensor]): 来自骨干网络的多尺度特征 [C3, C4, C5, ...]
Returns:
List[torch.Tensor]: 经过渐进式精炼后的最终特征金字塔
"""
# 将骨干特征作为第一个阶段的初始输入
current_features = backbone_features
# 核心逻辑: 循环通过每个精炼阶段
# 每个阶段的输出, 都成为下一个阶段的输入
for stage in self.stages:
current_features = stage(current_features)
# 返回最后一个阶段的输出, 这是最精炼的特征
return current_features
5.3 代码逐行解析
5.3.1 FPNStage 代码解析
-
__init__(...):self.lateral_convs: 定义了一系列的1x1卷积。它的作用是将输入的多尺度特征(无论是来自Backbone还是上一级PFP Stage)的通道数,统一到out_channels,便于后续的相加操作。self.fpn_convs: 定义了一系列的3x3卷积。在FPN的原始论文中,这个卷积被用来对相加融合后的特征进行处理,以消除上采样可能带来的混叠(aliasing)效应,起到平滑和提炼特征的作用。
-
forward(self, inputs):laterals = [...]: 首先,所有输入都通过各自的横向连接,完成通道对齐。for i in range(...): 这是经典的FPN自顶向下融合循环。从最高层(列表末尾)开始,将当前层laterals[i]上采样到i-1层的尺寸,然后与i-1层的特征laterals[i-1]逐元素相加。这个操作不断地将高层语义信息“注入”到低层。outputs = [...]: 最后,所有经过融合的laterals特征,再通过各自的3x3卷积进行最终的处理,得到该阶段的输出。
5.3.2 PFPNet 代码解析
-
__init__(...):self.stages = nn.ModuleList(): PFPNet的核心就是这个模块列表,它将存储我们所有的FPNStage。- Stage 1: 第一个
FPNStage比较特殊,它的输入通道数是由backbone_channels定的,因为它直接与骨干网络对接。 - Refinement Stages: 从第二个阶段开始,所有的
FPNStage的输入通道数都是一样的,即neck_channels,因为它们的输入都来自于前一个FPNStage的输出,通道数已经被统一了。代码[neck_channels] * len(backbone_channels)优雅地创建了这个通道列表。
-
forward(self, backbone_features):current_features: 这个变量是整个渐进式过程的核心。它在循环开始前,被初始化为骨干网络的输出。for stage in self.stages:: 这是PFPNet最精彩的部分。一个简单的for循环,就完美地体现了“渐进式”的思想。current_features = stage(current_features): 在每一次循环中,我们将current_features(上一阶段的输出)送入当前stage进行处理,然后用处理后的结果覆盖掉current_features。- 循环结束后,
current_features中存储的就是最后一个阶段精炼出的、质量最高的特征金字塔。
5.4 使用示例与验证
if __name__ == '__main__':
# 模拟一个类似ResNet50的骨干网络从C3, C4, C5输出的特征
# 通道数分别为 [512, 1024, 2048]
backbone_channels = [512, 1024, 2048]
# 模拟输入数据, Batch Size = 4
mock_c3 = torch.randn(4, backbone_channels[0], 80, 80)
mock_c4 = torch.randn(4, backbone_channels[1], 40, 40)
mock_c5 = torch.randn(4, backbone_channels[2], 20, 20)
backbone_feats = [mock_c3, mock_c4, mock_c5]
# 初始化一个2阶段的PFPNet, Neck的统一通道数为256
pfp_neck = PFPNet(backbone_channels=backbone_channels, neck_channels=256, num_stages=2)
print("="*20 + " PFPNet 结构 " + "="*20)
print(f"渐进阶段数量 (num_stages): {pfp_neck.num_stages}")
print(f"Stage 1 输入通道: {[c for c in backbone_channels]}")
print(f"Stage 2 输入通道: {[256] * len(backbone_channels)}")
print(f"Neck 输出通道: 256")
# 执行前向传播
final_pyramid_features = pfp_neck(backbone_feats)
# Unpack the final features
p3_out, p4_out, p5_out = final_pyramid_features
print("\n" + "="*20 + " 形状验证 " + "="*20)
print(f"输入 C3 形状: {mock_c3.shape}")
print(f"输入 C4 形状: {mock_c4.shape}")
print(f"输入 C5 形状: {mock_c5.shape}")
print("-" * 50)
print(f"最终输出 P3 形状: {p3_out.shape}")
print(f"最终输出 P4 形状: {p4_out.shape}")
print(f"最终输出 P5 形状: {p5_out.shape}")
# 验证输出形状
assert p3_out.shape == (4, 256, 80, 80)
assert p4_out.shape == (4, 256, 40, 40)
assert p5_out.shape == (4, 256, 20, 20)
print("\nPFPNet 运行成功! ✅")
六、性能分析与讨论
6.1 精度提升:深度精炼的威力
PFP的效果是显著的。在多个公开数据集和检测任务上,相比于基线的FPN或PANet,增加一到两个精炼阶段的PFP,通常能带来1-2 mAP点的稳定提升。
这种提升尤其体现在对困难样本的检测上,例如小物体、被遮挡的物体或类别易混淆的物体。因为这些样本恰恰最需要更深度的、更一致的语义信息来辅助识别,而这正是PFP的“拿手好戏”。第一遍融合可能还不足以区分它们,但经过第二、第三遍的“反复琢磨”,网络就能够捕捉到更具判别力的细微特征。
6.2 与相关工作的对比
- vs. DetectoRS (RFP):两者都采用了迭代/递归的思想,但作用的粒度不同。DetectoRS的RFP是一个宏观的递归,它将整个“Backbone+Neck”作为一个单元进行迭代,并将Neck的输出反馈给Backbone的输入。PFP则是一个微观的迭代,它只在Neck内部进行特征的迭代精炼,不涉及对Backbone的反馈。因此,PFP的计算成本通常远低于DetectoRS,是一种更“经济实惠”的迭代增强方案。
- vs. GiraffeDet:GiraffeDet致力于解决空间上的长距离依赖问题,通过一个全局融合模块,让所有层级“一步到位”地进行信息交换。而PFP致力于解决深度上的融合不充分问题,通过时间(计算步骤)上的堆叠,让信息“滚雪球”式地逐步增强。两者的切入点不同,但目标都是获得更高质量的特征金字塔。
6.3 计算成本的权衡
PFP的性能提升并非“免费的午餐”。每增加一个精炼阶段,就相当于增加了一整个FPN(或PANet)的计算量和参数量。如果一个FPN Neck的计算量是 X,那么一个 N 阶段的PFP Neck的计算量粗略地就是 N * X。
因此,PFP提供了一个非常灵活的精度-权衡旋钮。对于需要高精度的场景,可以使用2-3个阶段的PFP;而对于追求速度的场景,可以使用1个阶段(即退化为标准FPN),或者使用一个更轻量级的基础融合单元。
七、总结与展望
今天,我们一同深入探索了PFP——渐进式特征金字塔的精妙世界。我们了解到,PFP通过将传统的“一次性”特征融合过程,转变为一个多阶段、迭代式的精炼过程,成功地解决了标准FPN中融合不充分、语义鸿沟难以弥合的问题。
PFP的核心在于其“步步为营”的设计哲学。它不追求一步到位,而是通过层次化的信息融合,让特征金字塔在每一轮新的迭代中都“站在上一轮的肩膀上”,实现语义信息的“滚雪球”式增强。结合自适应融合机制,PFP能够智能地、高效地打造出语义更一致、内容更协调的顶级特征金字塔。
PFP的成功,再次印证了在深度学习架构设计中,“迭代”和“精炼”是两种极其强大且有效的思想。它为我们未来设计更强大的特征融合网络,提供了一条清晰且可行的路径。
感谢大家的全情投入与深度思考!希望今天的分享能点亮你心中新的灵感火花。我们下期再见!👋
下期预告:精彩继续 ✨
在过去的几期中,我们探讨的特征融合方法,无论是加权、拼接还是迭代,都主要集中在像素值的变换上。我们默认了一个前提:待融合的特征在空间上是对齐的。但如果一个物体因为姿态变化、扭曲或旋转,导致其在特征层面的“形状”也发生了变化,我们该怎么办?
下一期,我们将进入一个全新的维度——空间维度的变换。我们将要学习的 SFT (Spatial Feature Transform),是一种旨在让网络学会对特征图本身进行几何变换的强大技术。
我们将一同揭开SFT的神秘面纱:
- 特征也需要“变形”? 什么是空间变换网络(STN)?SFT是如何借鉴其思想的?
- 学习变换:SFT是如何根据输入内容,动态地预测出用于平移、缩放、旋转的仿射变换参数的?
- “对齐了再融合”:将SFT应用在特征融合中,如何通过主动地将一个特征图进行空间上的“扭转”和“校准”,来更好地与另一个特征图对齐,从而实现更高质量的融合?
- 这对于处理非刚变的物体(如行人、动物)会带来怎样的奇效?
如果你对如何让网络突破简单的像素值计算,学会“摆弄”和“校准”特征图的空间结构充满好奇,那么下一期的SFT,绝对会颠覆你对特征融合的认知!敬请期待!😉
希望本文所提供的YOLOv8内容能够帮助到你,特别是在模型精度提升和推理速度优化方面。
PS:如果你在按照本文提供的方法进行YOLOv8优化后,依然遇到问题,请不要急躁或抱怨!YOLOv8作为一个高度复杂的目标检测框架,其优化过程涉及硬件、数据集、训练参数等多方面因素。如果你在应用过程中遇到新的Bug或未解决的问题,欢迎将其粘贴到评论区,我们可以一起分析、探讨解决方案。如果你有新的优化思路,也欢迎分享给大家,互相学习,共同进步!
🧧🧧 文末福利,等你来拿!🧧🧧
文中讨论的技术问题大部分来源于我在YOLOv8项目开发中的亲身经历,也有部分来自网络及读者提供的案例。如果文中内容涉及版权问题,请及时告知,我会立即修改或删除。同时,部分解答思路和步骤来自全网社区及人工智能问答平台,若未能帮助到你,还请谅解!YOLOv8模型的优化过程复杂多变,遇到不同的环境、数据集或任务时,解决方案也各不相同。如果你有更优的解决方案,欢迎在评论区分享,撰写教程与方案,帮助更多开发者提升YOLOv8应用的精度与效率!
OK,以上就是我这期关于YOLOv8优化的解决方案,如果你还想深入了解更多YOLOv8相关的优化策略与技巧,欢迎查看我专门收集YOLOv8及其他目标检测技术的专栏《YOLOv8实战:从入门到深度优化》。希望我的分享能帮你解决在YOLOv8应用中的难题,提升你的技术水平。下期再见!
码字不易,如果这篇文章对你有所帮助,帮忙给我来个一键三连(关注、点赞、收藏),你的支持是我持续创作的最大动力。
同时也推荐大家关注我的公众号:「猿圈奇妙屋」,第一时间获取更多YOLOv8优化内容及技术资源,包括目标检测相关的最新优化方案、BAT大厂面试题、技术书籍、工具等,期待与你一起学习,共同进步!
🫵 Who am I?
我是计算机视觉、图像识别等领域的讲师 & 技术专家博客作者,笔名bug菌,CSDN | 掘金 | InfoQ | 51CTO | 华为云 | 阿里云 | 腾讯云 等社区博客专家,C站博客之星Top30,华为云多年度十佳博主,掘金多年度人气作者Top40,掘金等各大社区平台签约作者,51CTO年度博主Top12,掘金/InfoQ/51CTO等社区优质创作者;全网粉丝合计 30w+;更多精彩福利点击这里;硬核微信公众号「猿圈奇妙屋」,欢迎你的加入!免费白嫖最新BAT互联网公司面试真题、4000G PDF电子书籍、简历模板等海量资料,你想要的我都有,关键是你不来拿。

-End-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献62条内容
已为社区贡献62条内容

所有评论(0)