以低成本定制大模型,进而高效适配新任务的技术思路 - 低秩适应的设计
flyfish
以低成本定制大模型,进而高效适配新任务的技术思路 - 低秩适应的设计
flyfish
LoRA:大语言模型的低秩适应 Low-Rank Adaptation of Large Language Models
当我们对语言模型进行微调时,会修改模型的底层参数。为了让这一概念更具体,我们可以将微调带来的参数更新用如下公式表示:
W f t = W p t + Δ W W_{\mathbf{ft}} = W_{\mathbf{pt}} + \Delta W Wft=Wpt+ΔW
W f t W_{\mathbf{ft}} Wft:微调后权重
W p t W_{\mathbf{pt}} Wpt:预训练权重
Δ W \Delta W ΔW:权重更新
LoRA 的思想是通过低秩分解来对模型参数的这种更新进行建模,在实践中通过一对线性投影来实现。LoRA 保持大语言模型(LLM)的预训练层固定,向模型的每一层注入一个可训练的秩分解矩阵
秩分解矩阵 Rank decomposition matrix.
秩分解矩阵就是两个线性投影,用于降低并恢复输入的维度。这两个线性投影的输出会被加到模型预训练权重的输出上。由这两个并行变换相加形成的更新层,公式如下。可以看到,在某一层中加入LoRA,会直接学习该层底层权重的更新。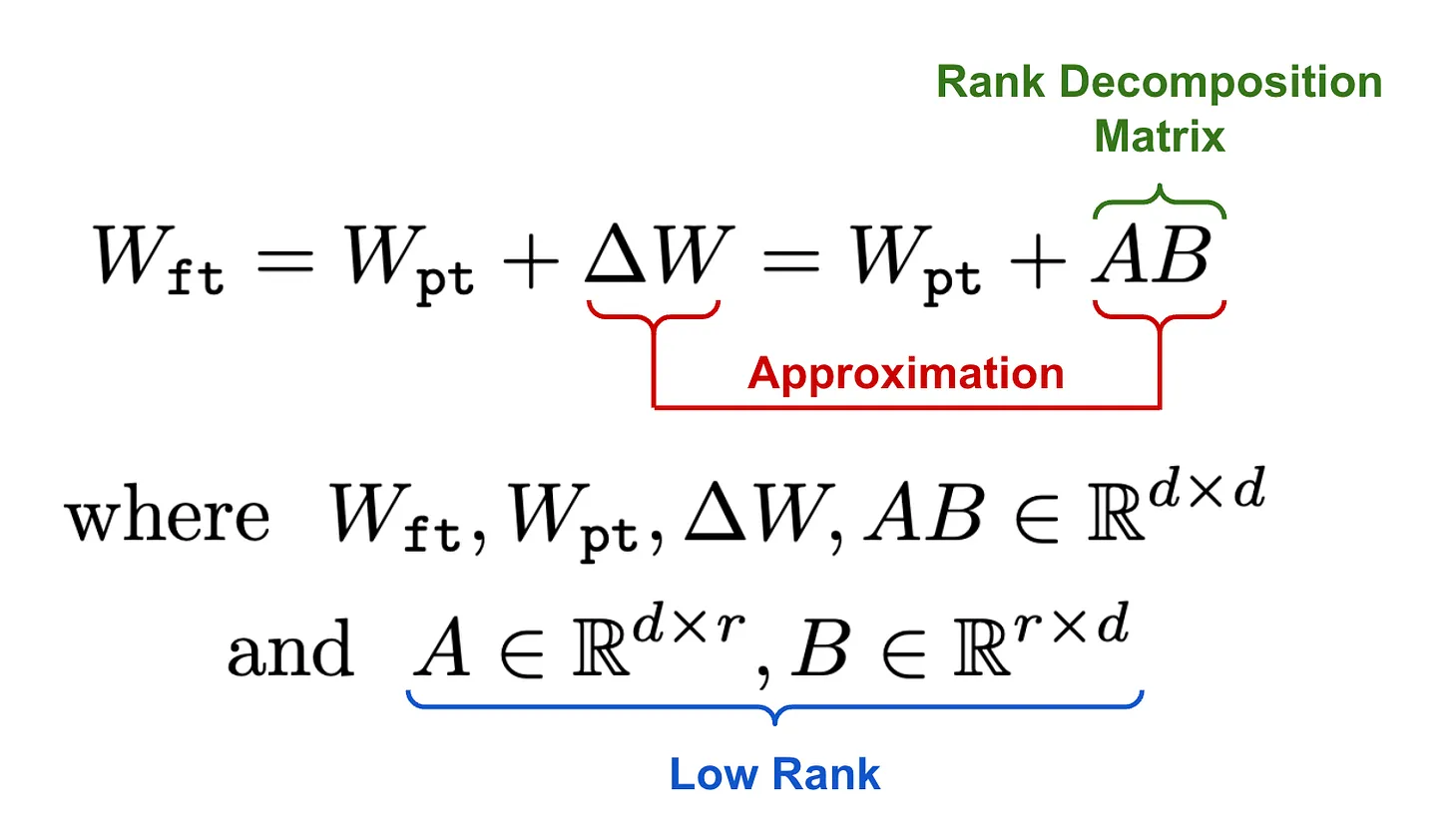
W f t = W p t + Δ W = W p t + A B ⏞ 秩分解矩阵 W_{\mathbf{ft}} = W_{\mathbf{pt}} + \Delta W = W_{\mathbf{pt}} + \overbrace{AB}^{\text{秩分解矩阵}} Wft=Wpt+ΔW=Wpt+AB
秩分解矩阵
其中, W f t , W p t , Δ W , A B ∈ R d × d W_{\mathbf{ft}}, W_{\mathbf{pt}}, \Delta W, AB \in \mathbb{R}^{d \times d} Wft,Wpt,ΔW,AB∈Rd×d(均为 d × d d×d d×d 维实数矩阵),且
A ∈ R d × r , B ∈ R r × d ⏟ 低秩 \underbrace{A \in \mathbb{R}^{d \times r}, B \in \mathbb{R}^{r \times d}}_{\text{低秩}} 低秩 A∈Rd×r,B∈Rr×d
LoRA 训练的是微调过程中权重矩阵更新的低秩近似
矩阵乘积 AB 的维度与完整微调更新的维度相同。将更新分解为两个更小矩阵的乘积,可确保更新是低秩的,且大幅减少需要训练的参数数量。LoRA 并非直接微调预训练大语言模型(LLM)各层的参数,而是仅优化秩分解矩阵,得到的结果近似于完整微调带来的更新。用随机的小值初始化 A,而将 B 初始化为零,以确保微调过程从模型原始的预训练权重开始。
通过将 LoRA 的秩 r 设置为预训练权重矩阵的秩,大致能恢复完整微调的表达能力。
增大 r 可以提升 LoRA 对完整微调更新的近似程度,但实际上极小的 r 值就足够了。
矩阵 A \mathbf{A} A和 B \mathbf{B} B的秩由超参数 r r r决定。
A \mathbf{A} A的维度是 d in × r d_{\text{in}} \times r din×r,其秩最多为 r r r;
B \mathbf{B} B的维度是 d out × r d_{\text{out}} \times r dout×r,其秩最多也为 r r r。
缩放因子
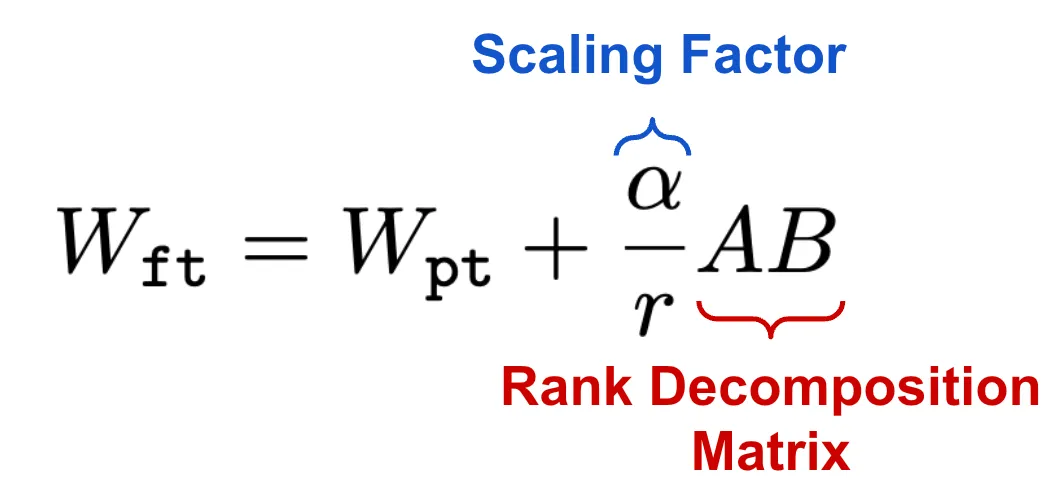
一旦得到权重矩阵的低秩更新,会在将其加到模型的预训练权重之前,用因子α对其进行缩放。缩放因子的默认值为1,这意味着在计算模型前向传播时,预训练权重和低秩权重更新的权重是相等的。不过,α的值可以调整,以平衡预训练模型和新任务特定适配的重要性。近期的经验是,对于秩更高的LoRA(即更大的r),需要更大的α值。
与适配器层的对比
适配器层(Adapter Layers)是一种插入在预训练模型现有层之间的小型可训练神经网络模块,作用是在不修改原模型参数的前提下,仅通过训练少量新增参数来让模型适配特定任务。
适配器层像是给模型“插了个小插件”,而LoRA是给模型权重“打了个轻量级补丁”。
其典型结构包含:
一个下采样线性层(将输入维度压缩到低维瓶颈)
一个非线性激活函数(如ReLU,引入非线性表达能力)
一个上采样线性层(将维度恢复到原尺寸,与原模型输出融合)
这种设计能让模型在保持预训练通用能力的同时,仅用1%-4%的额外参数实现任务专精,且支持多任务并行(不同任务使用独立适配器层,互不干扰)。
与LoRA的差异在于:
- 适配器层是新增的独立模块(按顺序插入原模型层之间),而LoRA是直接对原模型权重做低秩增量更新;
- 适配器层包含非线性激活,LoRA则是纯线性的低秩矩阵乘积。
LoRA的两个线性投影之间没有非线性(激活函数),秩分解矩阵被注入到模型的现有层中,而非作为额外层按顺序添加。
这些变化带来的最大影响是,与原始预训练模型相比,LoRA不会增加推理延迟。在将微调后的LoRA模型部署到生产环境时,可以直接计算并存储由LoRA得到的更新后的权重矩阵。因此,模型的结构与预训练模型完全相同——只是权重不同。
猜想如果改成SVD 分解,正交矩阵 + 奇异值矩阵 的分解 怎么做
分解权重变化量 Δ W \Delta W ΔW的两种方式对比
| 分解方式 | 结构与约束 | 需要解决的问题 |
|---|---|---|
| LoRA(两低秩矩阵) | Δ W = B A \Delta W = BA ΔW=BA, A 、 B A、B A、B无任何约束(非正交、非对角),仅需低秩 | 无约束、参数少、训练快、推理可合并 |
| SVD分解(正交+奇异值) | Δ W = U Σ V T \Delta W = U\Sigma V^T ΔW=UΣVT, U 、 V T U、V^T U、VT必须正交, Σ \Sigma Σ必须对角 | 正交约束增加训练难度,冗余参数+推理低效 |
SVD的 U U U( d o u t × r d_{out}×r dout×r)和 V T V^T VT( r × d i n r×d_{in} r×din)是强制正交矩阵(列/行两两垂直),这对梯度下降优化是“致命约束”:
大模型微调依赖反向传播更新参数,正交约束会让梯度计算变得异常复杂(需要维持正交性的额外梯度项)。
LoRA的 A 、 B A、B A、B无任何约束,梯度更新直接高效。
SVD中的 Σ \Sigma Σ是对角矩阵,作用是“缩放奇异值”,但这一功能在LoRA中用全局缩放因子 α / r \alpha/r α/r 就能实现——无需单独训练一个 r × r r×r r×r的对角矩阵,既省了 r 2 r² r2个参数,又避免了对角矩阵带来的计算冗余。
例: r = 8 r=8 r=8时,SVD多训练8个对角元参数; r = 16 r=16 r=16时多训练16个,看似不多,但违背了LoRA“极致参数效率”的诉求(大模型微调就是要省参数、省计算)。
大模型微调的关键是“不破坏原模型的预训练知识”,LoRA通过 B B B全零初始化,让训练初期 Δ W = 0 \Delta W=0 ΔW=0,模型完全等价于原预训练模型,稳定性拉满;而SVD的正交矩阵初始化难度高:
若 U 、 V T U、V^T U、VT初始化不当,训练初期 Δ W \Delta W ΔW会出现大幅波动,直接打乱原模型的权重分布,导致模型性能骤降(相当于“废掉”预训练知识)。
即便初始化得当,正交约束也会限制参数的优化空间——大模型需要灵活调整权重增量来适配复杂任务,而正交性强行锁死了参数的取值范围,让模型“放不开手脚”。
LoRA的优势之一是“推理无额外开销”——训练后可将 B A BA BA直接合并到原权重 W 0 W_0 W0,推理时仍用原模型结构,速度和原模型一致;而SVD分解 Δ W \Delta W ΔW后:
推理时需要执行三次矩阵乘法( U × Σ × V T × x U \times \Sigma \times V^T \times x U×Σ×VT×x),比LoRA多一次计算,增加推理延迟。
无法将 U Σ V T U\Sigma V^T UΣVT直接合并到 W 0 W_0 W0(合并会破坏 U 、 V T U、V^T U、VT的正交性,导致权重增量失效),只能保留三矩阵结构,部署时需要额外处理。
那怎么做呢 可以看 TRANSFORMER-SQUARED: SELF-ADAPTIVE LLMS(Self-adaptive large language models (LLMs) )
还可以 看
SVFT: Parameter-Efficient Fine-Tuning with Singular Vectors
还可以看 PiSSA、 MiLoRA、 LoRA-XS等

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 35
35 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)