手把手教你快速玩转LLaMA-Factory:大模型微调入门级教程!
对于希望尝试大模型训练的同学来说,从 LLaMA-Factory 入手是一个非常不错的选择!在实际工作中,也经常用到 LLaMA-Factory 进行模型训练。

对于希望尝试大模型训练的同学来说,从 LLaMA-Factory 入手是一个非常不错的选择!在实际工作中,也经常用到 LLaMA-Factory 进行模型训练。用得越多,越能体会到它的便捷与高效。尤其值得一提的是,LLaMA-Factory 提供了完整的中文学习文档,这对英文阅读不太熟练的同学来说,真的非常友好!
01 安装
小编一般喜欢从源码安装,源码里面有很多可以参考的文档~
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
验证是否安装成功:
llamafactory-cli version
简单看一下项目结构:
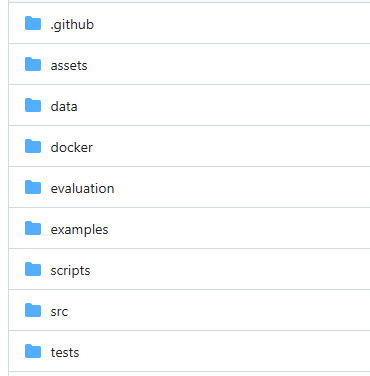
其中:
- src:核心源码目录
- data:主要包含数据集配置和示例数据
- dataset_info.json - 数据集注册配置文件,定义所有可用数据集的元信息
- 示例数据集文件 - 包含各种格式的示例数据集(JSON、JSONL等)
- examples:包含各种训练和推理的配置示例文件
- docker:包含不同硬件平台的 Docker 配置
如果看了官方文档你还是不知道训练数据怎么组织你可以去data目录下面找一找示例数集文件;如果你不知道训练脚本怎么写你可以去examples目录下找一找示例脚本
02 使用
第一步:准备好你的数据
LLaMA-Factory 支持的微调数据格式有:
- Alpaca
- ShareGPT
- OpenAI
预训练格式和DPO、KTO等强化学习的训练格式也支持,不同训练方式数据格式组织方式也不一样,具体可见官方文档,写的非常详细:
https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/data_preparation.html
上面也提到过在LLaMA-Factory项目的data目录下也给出了一些数据文件的例子,可供参考~
准备好的数据文件需要在LLaMA-Factory项目的data目录下的dataset_info.json文件中增加你的数据集说明
比如openai的数据组织格式如下:
[
{
"messages":[
{
"role":"system",
"content":"系统提示词(选填)"
},
{
"role":"user",
"content":"人类指令"
},
{
"role":"assistant",
"content":"模型回答"
}
]
}
]
对于上述格式的数据, dataset_info.json 中需要新增数据集描述:
"数据集名称": {
"file_name": "data.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant",
"system_tag": "system"
}
}
第二步:下载好你的训练模型
下载预训练模型到你的路径下,一般我们会从modelscope这个网站上下载,非常方便
第三步:组织训练脚本
这里给出了一个参考脚本,主要通过deepspeed进行单机多卡训练
你需要替换的地方有模型路径、数据集名称、数据集路径、deepspeed脚本文件位置等,其他参数可按需修改或者添加(每个脚本参数的含义后文已给出相关解释)
nohup deepspeed --include localhost:1,2,3 --master_port
1234 ./src/train.py \
--stage sft \
--do_train \
--deepspeed ./examples/deepspeed/ds_z3_config.json \
--model_name_or_path YOUR_MODEL_PATH \
--dataset YOUR_DATASET_NAME \
--val_size 0.05 \
--dataset_dir YOUR_DATASET_PATH \
--template qwen \
--max_length 4096 \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0.1 \
--output_dir ${out_dir} \
--overwrite_cache \
--overwrite_output_dir \
--cutoff_len 4096 \
--mask_history False \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--logging_steps 5 \
--save_steps 16 \
--save_total_limit 3 \
--learning_rate 5e-5 \
--num_train_epochs 6 \
--eval_steps 8 \
--plot_loss \
--bf16 \
--warmup_ratio 0.05 \
--ddp_find_unused_parameters False \
--preprocessing_num_workers 16 > ${out_dir}/train.log 2>&1 &
1. 启动与环境配置
nohup: 在后台运行命令,即使终端关闭也不会中断进程。deepspeed: 使用 DeepSpeed 库进行分布式训练。--include localhost:1,2,3: 指定使用本地的 GPU 设备(编号为 1、2、3 的 GPU)。--master_port 1234: 设置分布式训练的主节点端口号为 1234。
2. 训练脚本入口
./src/train.py: 主要的训练脚本路径(llamafactory项目的src目录下)
3. 训练任务配置
--stage sft: 训练阶段为监督微调(Supervised Fine-Tuning)。--do_train: 执行训练模式。
4. DeepSpeed 配置
--deepspeed ./examples/deepspeed/ds_z3_config.json: 指定 DeepSpeed 的配置文件路径(ZeRO Stage 3 配置),这个配置文件在llamafactory项目的examples目录下可以找到
5. 模型与数据配置
--model_name_or_path YOUR_MODEL_PATH: 预训练模型的路径或 Hugging Face 模型名称。--dataset YOUR_DATASET_NAME: 使用的数据集名称。--val_size 0.05: 验证集比例(5%)。--dataset_dir YOUR_DATASET_PATH: 数据集存放的目录路径。--template qwen: 使用 Qwen 模型的对话模板格式。--max_length 4096: 输入序列的最大长度。--cutoff_len 4096: 截断长度(与max_length一致)。--mask_history False: 不屏蔽历史对话内容。
6. LoRA 参数配置
--finetuning_type lora: 使用 LoRA(Low-Rank Adaptation)进行微调。--lora_target q_proj,v_proj: 对模型的q_proj(查询投影)和v_proj(值投影)模块应用 LoRA。--lora_rank 8: LoRA 的秩(rank)为 8。--lora_alpha 16: LoRA 的缩放系数为 16。--lora_dropout 0.1: LoRA 层的 Dropout 比例为 0.1。
7. 训练超参数
--per_device_train_batch_size 1: 每个 GPU 的训练批次大小为 1。--per_device_eval_batch_size 1: 每个 GPU 的验证批次大小为 1。--gradient_accumulation_steps 8: 梯度累积步数为 8(等效批次大小 = 批次大小 × 梯度累积步数 × GPU 数量)。--learning_rate 5e-5: 学习率为 0.00005。--num_train_epochs 6: 训练 epoch 数为 6。--lr_scheduler_type cosine: 使用余弦学习率调度器。--warmup_ratio 0.05: 学习率预热步数占总训练步数的 5%。
8. 训练过程管理
--output_dir ${out_dir}: 模型和日志的输出目录。--overwrite_cache: 覆盖已有的缓存文件。--overwrite_output_dir: 覆盖输出目录(如果已存在)。--logging_steps 5: 每 5 步记录一次日志。--save_steps 16: 每 16 步保存一次模型。--save_total_limit 3: 最多保留 3 个模型检查点(旧的会被删除)。--eval_steps 8: 每 8 步进行一次验证。--plot_loss: 绘制损失曲线。--preprocessing_num_workers 16: 使用 16 个进程进行数据预处理。
9. 硬件与性能优化
--bf16: 使用 BF16 混合精度训练(适合 NVIDIA Ampere+ GPU)。--ddp_find_unused_parameters False: 禁用 DDP 中未使用参数的检测(节省内存,可能适用于某些模型)。
10. 日志重定向
> ${out_dir}/train.log 2>&1 &: 将标准输出和错误输出重定向到train.log文件,并在后台运行
第四步:训练与查看
运行上述脚本即可启动训练
训练完成后,在你文件保存的目录下除了有模型文件还有两个loss文件:
- training_eval_loss.png
- training_loss.png
通过loss文件可以查看模型训练效果
第五步:模型推理
如果你是lora训练,推理之前还需要进行模型合并,合并脚本merge_config.yaml如下:
### examples/merge_lora/llama3_lora_sft.yaml
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft
template: llama3
finetuning_type: lora
### export
export_dir: models/llama3_lora_sft
export_size: 2
export_device: cpu
export_legacy_format: false
通过 llamafactory-cli export merge_config.yaml 指令运行即可得到合并之后的模型,模型推理这里就不再过多赘述!
有任何问题,欢迎评论区留言交流!Good good study,day day up!
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献430条内容
已为社区贡献430条内容

所有评论(0)