深度解析 GPT-5.1-Codex-Max:当 AI 真的学会“自己写代码”
OpenAI 刚刚扔出了一枚重磅炸弹——GPT-5.1-Codex-Max。这不仅仅是一个更强的代码补全工具,而是真正意义上的“Agentic Coding Model”。它能像资深工程师一样,处理长达数百万 Token 的项目上下文,自主进行“规划-编码-测试-修复”的闭环。本文将带你深入拆解它的核心黑科技“Compaction”机制,对比它在 SWE-bench 上的惊人表现,并分享作为开发者
深度解析 GPT-5.1-Codex-Max:当 AI 真的学会“自己写代码”
摘要:
OpenAI 刚刚扔出了一枚重磅炸弹——GPT-5.1-Codex-Max。这不仅仅是一个更强的代码补全工具,而是真正意义上的“Agentic Coding Model”。它能像资深工程师一样,处理长达数百万 Token 的项目上下文,自主进行“规划-编码-测试-修复”的闭环。本文将带你深入拆解它的核心黑科技“Compaction”机制,对比它在 SWE-bench 上的惊人表现,并分享作为开发者如何利用它在 Windows 环境下实现 24 小时无人值守开发。
引言:从“副驾驶”到“自动驾驶”
作为一名在代码堆里摸爬滚打十年的老兵,我见证了 Copilot 从“惊艳”到“日常”。但说实话,我们依然离不开“盯着它写”。它写一段,我审一段,本质上它还是个“副驾驶”。
但 11 月 19 日发布的 GPT-5.1-Codex-Max,让我第一次感觉到了“自动驾驶”的雏形。OpenAI 这次没有挤牙膏,直接端出了一个能自主干活的模型。它不再只是补全下一行代码,而是能接管整个 Feature 的开发流程。
今天,我们就来扒一扒,这个“Max”到底强在哪?
核心黑科技:Compaction(压缩机制)
大家都有过这样的痛苦:项目代码太多,扔给 GPT-4,它要么“忘事”,要么直接报错说 Context 满了。
GPT-5.1-Codex-Max 引入了一个革命性的机制——Compaction。
简单来说,它不像以前那样傻傻地把所有历史对话都堆在窗口里。它学会了“做笔记”。当上下文太长时,它会自动修剪掉无关的细节,只保留核心的逻辑和决策路径(Essential Context)。
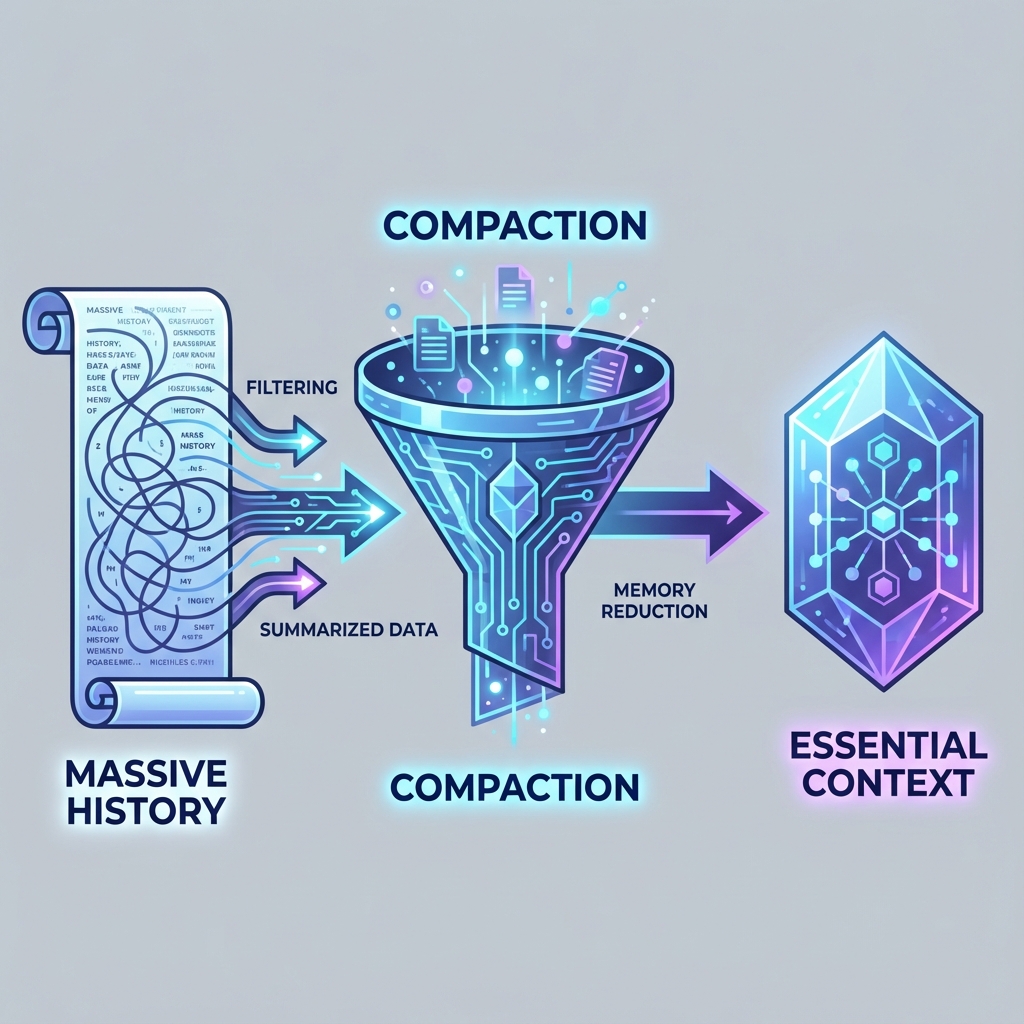
这就好比一个经验丰富的工程师,在看几千行屎山代码时,脑子里不会记住每一行变量名,而是记住了“模块 A 负责鉴权,模块 B 负责数据清洗”。这种能力,让 Codex-Max 能够处理数百万 Token 的项目,甚至进行长达数小时的持续重构任务而不“断片”。
实战表现:SWE-bench 刷榜
光说不练假把式。在软件工程领域最硬核的 SWE-bench 测试中,GPT-5.1-Codex-Max 交出了一份恐怖的答卷。
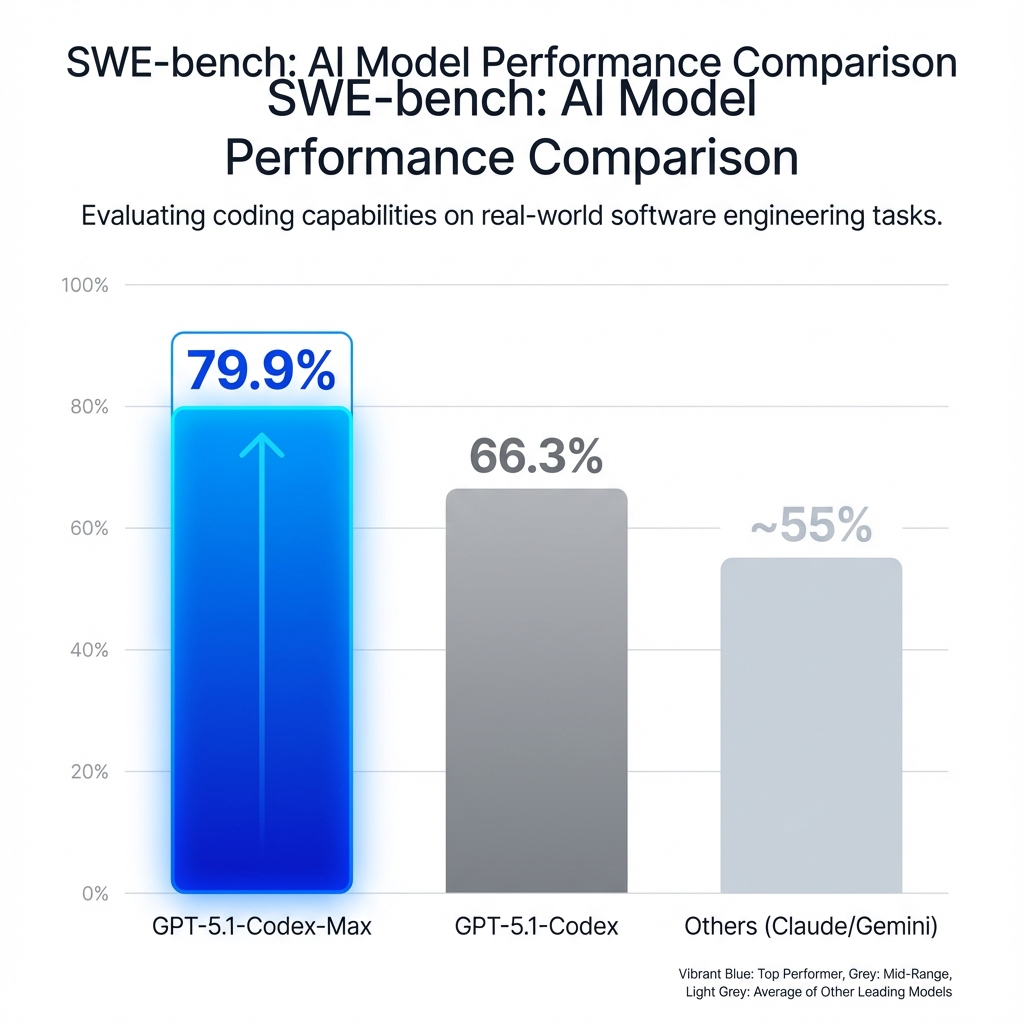
79.9% 的解决率!这是什么概念?上一代 GPT-5.1-Codex 只有 66.3%。而我们熟知的其他顶尖模型,大多还在 50%-60% 的区间挣扎。这意味着,在 10 个真实的 GitHub Issue 中,它能独立解决 8 个。
更值得一提的是它的Token 效率。在 Verified 榜单上,它不仅分高,还比前代少用了 30% 的“思维 Token”。活儿干得好,还更省钱,这才是工程化的胜利。
真正的 Agentic Workflow
Codex-Max 最让我兴奋的,是它原生支持的 Agentic Workflow(代理工作流)。
以前我们用 AI,是“我问你答”。现在用 Codex-Max,是“我下令,你执行”。

它内置了一个完整的闭环:
- Plan(规划):拆解需求,制定修改方案。
- Code(编码):执行具体的代码变更。
- Test(测试):自动运行测试用例。
- Fix(修复):如果测试挂了,它会自己看报错,自己改代码,直到测试通过。
OpenAI 内部测试显示,它可以连续运行 24 小时,像一个不知疲倦的初级工程师一样,把积压的 Bug 一个个修好。
Windows 开发者的福音
还有一个小惊喜:这是 OpenAI 第一个原生支持 Windows 环境的模型。
以前很多 AI 工具都默认你是 macOS 或 Linux 用户,Windows 用户往往要折腾 WSL。但这次,Codex-Max 针对 Windows 的终端、文件系统做了专门训练。作为一名 Windows 死忠粉,看到它在 PowerShell 里行云流水地操作,简直感动。
总结与建议
GPT-5.1-Codex-Max 的出现,标志着 AI 编程进入了 Agent 时代。
我的建议:
- 拥抱 CLI:尽快熟悉 OpenAI 的 Codex CLI 工具,这是目前使用它的最佳姿势。
- 转变思维:从“如何写好 Prompt 让它生成代码”,转变为“如何定义清晰的任务和测试标准,让它自主完成”。
- 保持警惕:虽然它很强,但 Code Review 依然不能省。79.9% 不是 100%,它依然会犯错,只是犯得更高级了。
未来已来,你准备好把键盘交给它了吗?
参考文献
- Simon Willison, “GPT-5.1-Codex-Max release notes and analysis”.
- OpenAI Official Blog, “Introducing GPT-5.1-Codex-Max”.
- CyberPress, “Deep dive into GPT-5.1-Codex-Max architecture”.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)