SQL 优化技术精要:让查询飞起来
SQL查询优化指南摘要 本文介绍了优化SQL查询性能的5个关键技术: 只选择必要列,避免使用SELECT *,减少I/O和网络开销,提高缓存效率。 使用SARGable查询:避免在WHERE子句中对列使用函数,确保查询可以利用索引。 避免前导通配符:LIKE '%term'会阻止索引使用,应优先使用前缀匹配。 理解执行计划:通过EXPLAIN分析查询执行方式,识别全表扫描等问题。 优化索引策略:合
我们都经历过这种情况:你运行一个查询,去泡杯咖啡,回来后它还在运行。慢速 SQL 查询会严重影响应用程序性能并让用户感到沮丧。
SQL 查询优化:将慢查询转换为闪电般快速的操作,使用索引和执行计划
优化 SQL 既是一门艺术,也是一门科学。在这份综合指南中,我们将探讨数据库专家用来将缓慢查询转换为闪电般快速操作的技术。
性能思维
在深入技术之前,请理解这一点:数据库不了解你的业务逻辑。它遵循规则和统计信息。你的工作是编写符合数据库引擎想要工作方式的查询。
关键原则:
- 数据库优化器基于统计信息做决策
- 你的查询应该帮助优化器做出正确选择
- 理解数据库的工作原理是优化的基础
1. 只选择需要的列
可怕的 SELECT * 是常见的性能杀手。它强制数据库获取每一列,增加 I/O 和网络开销。
错误做法:
SELECT * FROM orders;
优化后:
SELECT order_id, customer_id, total_amount
FROM orders;
为什么这很重要:
- 减少 I/O 操作:只读取需要的数据
- 降低网络传输:传输更少的数据
- 提高缓存效率:更多行可以放入内存
- 避免未来问题:表结构变化不会影响查询
示例数据(orders_opt_select 表):
| order_id | customer_id | total_amount | order_date | status | shipping_address | notes |
|---|---|---|---|---|---|---|
| 1 | 101 | 250.00 | 2023-01-15 | completed | 123 Main St | … |
| 2 | 102 | 180.00 | 2023-01-16 | pending | 456 Oak Ave | … |
查询示例:
SELECT order_id, total_amount
FROM orders_opt_select;
查询结果:
| order_id | total_amount |
|---|---|
| 1 | 250.00 |
| 2 | 180.00 |
性能对比:
SELECT *:读取 7 列,假设每行 500 字节SELECT order_id, total_amount:读取 2 列,每行约 20 字节- 性能提升:约 25 倍的数据量减少
2. 使用 SARGable 查询
SARGable 代表 Search ARGument able(可搜索参数)。这意味着编写可以利用索引的查询。
在 WHERE 子句中对列使用函数通常会阻止数据库使用索引。
非 SARGable(慢):
-- 数据库必须为每一行计算 YEAR()
SELECT * FROM users
WHERE YEAR(created_at) = 2023;
SARGable(快):
-- 这可以使用 created_at 列上的索引
SELECT * FROM users
WHERE created_at >= '2023-01-01'
AND created_at < '2024-01-01';
为什么非 SARGable 查询慢:
- 数据库必须对每一行应用函数
- 无法使用索引进行快速查找
- 必须进行全表扫描
常见的非 SARGable 模式:
| 非 SARGable(慢) | SARGable(快) |
|---|---|
WHERE YEAR(date_col) = 2023 |
WHERE date_col >= '2023-01-01' AND date_col < '2024-01-01' |
WHERE UPPER(name) = 'JOHN' |
WHERE name = 'JOHN'(或使用不区分大小写的索引) |
WHERE salary * 1.1 > 50000 |
WHERE salary > 50000 / 1.1 |
WHERE SUBSTRING(code, 1, 3) = 'ABC' |
WHERE code LIKE 'ABC%' |
最佳实践:
- 避免在 WHERE 子句中对索引列使用函数
- 将计算移到等号的另一侧
- 使用函数索引(如果数据库支持)
3. 避免前导通配符
使用 LIKE '%term' 会阻止索引使用,因为数据库必须扫描每个字符串以查看它是否以该术语结尾。
示例数据(products_opt_like 表):
| product_id | product_name | category |
|---|---|---|
| 1 | Laptop Pro | Electronics |
| 2 | Desktop PC | Electronics |
| 3 | Laptop Air | Electronics |
可以使用索引的查询:
-- 可以使用索引(前缀匹配)
SELECT * FROM products_opt_like
WHERE product_name LIKE 'Lap%';
查询结果:
| product_id | product_name | category |
|---|---|---|
| 1 | Laptop Pro | Electronics |
| 3 | Laptop Air | Electronics |
无法使用索引的查询:
-- ❌ 无法使用索引(后缀匹配)
SELECT * FROM products_opt_like
WHERE product_name LIKE '%top';
-- ❌ 无法使用索引(中间匹配)
SELECT * FROM products_opt_like
WHERE product_name LIKE '%top%';
LIKE 模式性能对比:
| LIKE 模式 | 可以使用索引 | 性能 |
|---|---|---|
'Lap%' |
✅ 是 | 快 |
'%top' |
❌ 否 | 慢 |
'%top%' |
❌ 否 | 慢 |
'Lap_op%' |
✅ 是(部分) | 中等 |
替代方案:
- 使用全文搜索索引(MySQL FULLTEXT、PostgreSQL tsvector)
- 使用专门的搜索引擎(Elasticsearch、Solr)
- 重新设计数据模型以支持前缀搜索
4. 理解执行计划
优化最强大的工具是 EXPLAIN 关键字(或 PostgreSQL 中的 EXPLAIN ANALYZE)。它准确告诉你数据库引擎打算如何执行查询——是使用全表扫描还是索引查找。
基本用法:
-- MySQL, PostgreSQL, SQLite
EXPLAIN SELECT * FROM orders WHERE customer_id = 123;
-- PostgreSQL(包含实际执行时间)
EXPLAIN ANALYZE SELECT * FROM orders WHERE customer_id = 123;
-- SQL Server
SET SHOWPLAN_TEXT ON;
GO
SELECT * FROM orders WHERE customer_id = 123;
GO
SET SHOWPLAN_TEXT OFF;
执行计划中的关键指标:
| 指标 | 含义 | 好/坏 |
|---|---|---|
| Table Scan | 全表扫描 | ❌ 坏(大表) |
| Index Scan | 索引扫描 | ✅ 好 |
| Index Seek | 索引查找 | ✅ 非常好 |
| Nested Loop | 嵌套循环连接 | ⚠️ 取决于数据量 |
| Hash Join | 哈希连接 | ✅ 好(大表) |
| Merge Join | 合并连接 | ✅ 好(已排序数据) |
如何阅读执行计划:
- 查找 “Table Scan” 或 “Seq Scan”(全表扫描)
- 检查 “rows” 或 “cost” 估计值
- 查看是否使用了索引
- 注意 JOIN 类型和顺序
- 查找临时表或文件排序
示例执行计划分析:
-- 慢查询
EXPLAIN SELECT * FROM orders WHERE YEAR(order_date) = 2023;
-- 结果:Seq Scan on orders (cost=0.00..1000.00 rows=5000)
-- 问题:全表扫描,因为使用了函数
-- 优化后
EXPLAIN SELECT * FROM orders
WHERE order_date >= '2023-01-01' AND order_date < '2024-01-01';
-- 结果:Index Scan using idx_order_date on orders (cost=0.00..50.00 rows=5000)
-- 改进:使用索引,成本降低 20 倍
5. 索引策略:游戏规则改变者
索引就像书的索引——它们帮助你找到数据而无需阅读每一页。但设计不当的索引可能弊大于利。
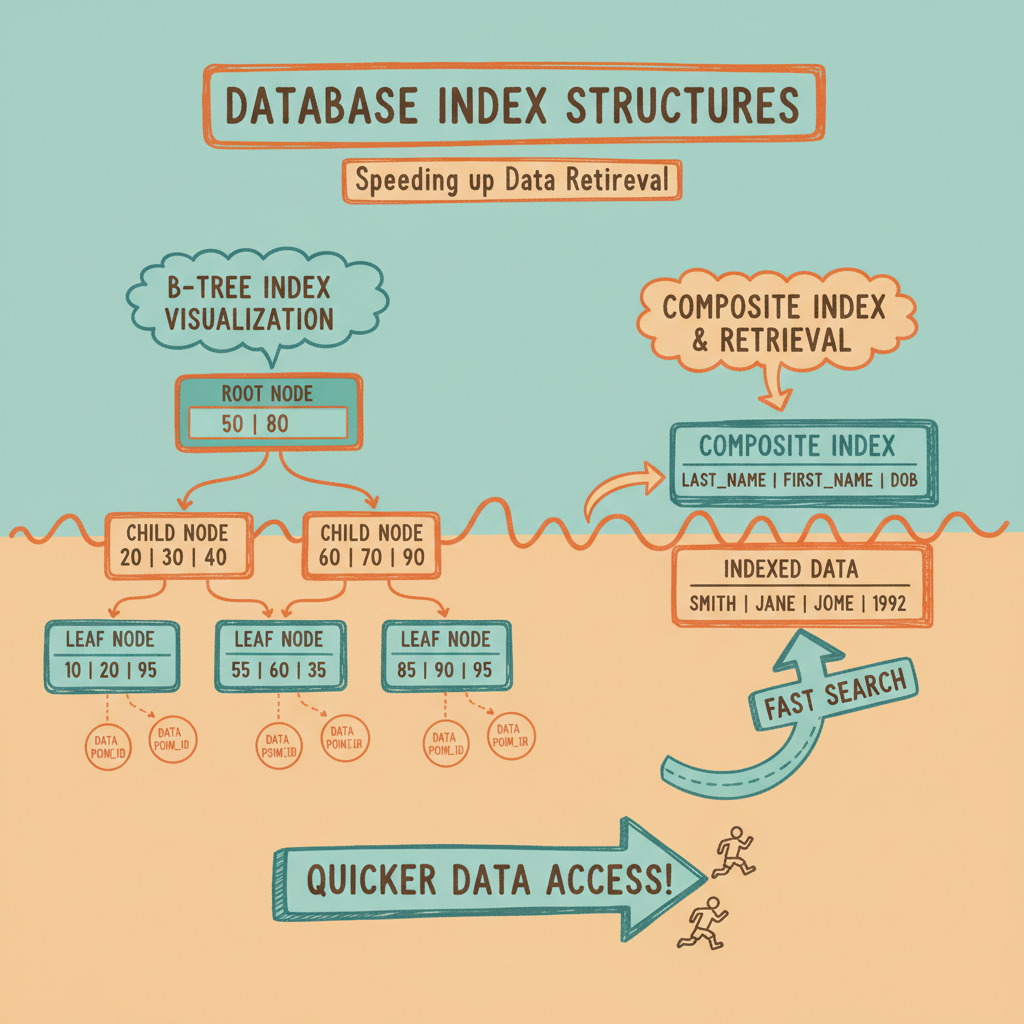
数据库 B-tree 索引结构:展示复合索引和高效的数据检索路径
复合索引和列顺序
复合索引中列的顺序很重要。"最左前缀"规则意味着只有当查询过滤最左列时,索引才能被使用。
示例:
-- 在 (last_name, first_name, age) 上创建索引
CREATE INDEX idx_user_name ON users(last_name, first_name, age);
-- ✅ 可以使用索引
SELECT * FROM users WHERE last_name = 'Smith';
SELECT * FROM users WHERE last_name = 'Smith' AND first_name = 'John';
SELECT * FROM users WHERE last_name = 'Smith' AND first_name = 'John' AND age = 30;
-- ❌ 无法有效使用索引
SELECT * FROM users WHERE first_name = 'John';
SELECT * FROM users WHERE age = 30;
SELECT * FROM users WHERE first_name = 'John' AND age = 30;
最左前缀规则详解:
| 查询条件 | 使用索引 | 原因 |
|---|---|---|
last_name = 'Smith' |
✅ 完全使用 | 匹配最左列 |
last_name = 'Smith' AND first_name = 'John' |
✅ 完全使用 | 匹配前两列 |
last_name = 'Smith' AND age = 30 |
⚠️ 部分使用 | 只使用 last_name |
first_name = 'John' |
❌ 不使用 | 跳过最左列 |
age = 30 |
❌ 不使用 | 跳过最左列 |
如何选择列顺序:
- 选择性高的列在前:唯一值多的列
- 常用过滤条件在前:WHERE 子句中最常用的列
- 等值条件在前,范围条件在后:
=在前,>,<,BETWEEN在后
示例:
-- 假设查询模式:
-- 1. WHERE status = 'active' AND created_at > '2023-01-01'
-- 2. WHERE status = 'active' AND user_id = 123
-- 最佳索引:
CREATE INDEX idx_status_created ON orders(status, created_at);
CREATE INDEX idx_status_user ON orders(status, user_id);
-- 或者使用一个更通用的索引:
CREATE INDEX idx_status_user_created ON orders(status, user_id, created_at);
覆盖索引
"覆盖索引"包含查询所需的所有列,因此数据库永远不必访问实际表。
示例数据(orders_covering 表):
| order_id | customer_id | status | total_amount | order_date |
|---|---|---|---|---|
| 1 | 101 | completed | 250.00 | 2023-01-15 |
| 2 | 102 | pending | 180.00 | 2023-01-16 |
| 3 | 101 | completed | 320.00 | 2023-01-17 |
创建覆盖索引:
-- 如果我们在 (status, total_amount) 上有索引,
-- 这个查询将非常快
CREATE INDEX idx_status_amount ON orders_covering(status, total_amount);
查询示例:
SELECT status, SUM(total_amount)
FROM orders_covering
GROUP BY status;
查询结果:
| status | SUM(total_amount) |
|---|---|
| completed | 570.00 |
| pending | 180.00 |
覆盖索引的优势:
- 无需访问表:所有数据都在索引中
- 减少 I/O:只读取索引页,不读取数据页
- 提高缓存效率:索引通常比表小得多
何时使用覆盖索引:
- 查询只需要少数几列
- 这些列经常一起查询
- 表很大但查询结果集很小
注意事项:
- 索引会增加存储空间
- 索引会减慢 INSERT/UPDATE/DELETE
- 不要创建过多索引
6. JOIN 优化
JOIN 可能很昂贵。数据库必须匹配多个表中的行,顺序很重要。
在 JOIN 之前减少数据
尽早过滤。让数据库在 JOIN 之前消除行,而不是之后。
错误做法:
SELECT o.*, c.name
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE o.order_date > '2023-01-01';
更好的做法(使用子查询或 CTE):
WITH RecentOrders AS (
SELECT * FROM orders WHERE order_date > '2023-01-01'
)
SELECT o.*, c.name
FROM RecentOrders o
JOIN customers c ON o.customer_id = c.customer_id;
说明:在实践中,现代查询优化器通常会将第一个版本重写为类似第二个版本的内容。但在复杂场景中,显式过滤会有所帮助。
为什么这很重要:
- 减少 JOIN 处理的行数
- 降低内存使用
- 提高缓存效率
JOIN vs 子查询
有时关联子查询编写起来更清晰,但性能很差,因为它对每一行运行一次。
示例数据(customers_join 表):
| customer_id | customer_name |
|---|---|
| 101 | Alice |
| 102 | Bob |
| 103 | Charlie |
示例数据(orders_join 表):
| order_id | customer_id | total_amount |
|---|---|---|
| 1 | 101 | 250.00 |
| 2 | 102 | 80.00 |
| 3 | 101 | 150.00 |
使用 JOIN(高效):
SELECT DISTINCT c.customer_name
FROM customers_join c
JOIN orders_join o ON c.customer_id = o.customer_id
WHERE o.total_amount > 100;
查询结果:
| customer_name |
|---|
| Alice |
使用关联子查询(可能很慢):
-- 关联子查询(可能很慢)
SELECT customer_name
FROM customers
WHERE EXISTS (
SELECT 1 FROM orders
WHERE orders.customer_id = customers.customer_id
AND total_amount > 100
);
性能对比:
| 方法 | 执行次数 | 性能 |
|---|---|---|
| JOIN | 1 次 | ✅ 快 |
| 关联子查询 | N 次(每个客户一次) | ❌ 慢 |
最佳实践:
- 优先使用 JOIN 而不是关联子查询
- 使用 EXISTS 而不是 IN(对于大数据集)
- 在 JOIN 之前过滤数据
7. EXISTS vs IN
对于检查成员资格,EXISTS 通常优于 IN,特别是当子查询返回许多行时。
原因:EXISTS 一旦找到匹配就停止(短路),而 IN 可能需要评估所有值。
示例数据(customers_exists 表):
| customer_id | customer_name |
|---|---|
| 101 | Alice |
| 102 | Bob |
| 103 | Charlie |
示例数据(orders_exists 表):
| order_id | customer_id | total_amount |
|---|---|---|
| 1 | 101 | 250.00 |
| 2 | 102 | 80.00 |
| 3 | 101 | 150.00 |
使用 EXISTS(推荐):
-- EXISTS 通常对大数据集更快
SELECT customer_name
FROM customers_exists
WHERE EXISTS (
SELECT 1 FROM orders_exists
WHERE orders_exists.customer_id = customers_exists.customer_id
AND total_amount > 100
);
查询结果:
| customer_name |
|---|
| Alice |
使用 IN(可能较慢):
-- IN 可能较慢
SELECT customer_name
FROM customers_exists
WHERE customer_id IN (
SELECT customer_id FROM orders_exists
WHERE total_amount > 100
);
EXISTS vs IN 对比:
| 特性 | EXISTS | IN |
|---|---|---|
| 短路 | ✅ 找到第一个匹配就停止 | ❌ 可能评估所有值 |
| NULL 处理 | ✅ 正确处理 NULL | ⚠️ NULL 可能导致意外结果 |
| 性能(大数据集) | ✅ 快 | ❌ 慢 |
| 可读性 | ⚠️ 稍复杂 | ✅ 简单 |
何时使用 EXISTS:
- 子查询返回大量行
- 需要检查存在性而不是具体值
- 处理可能包含 NULL 的数据
何时使用 IN:
- 子查询返回少量固定值
- 值列表很小且已知
- 可读性比性能更重要
8. 批量操作
逐行插入由于事务开销而非常慢。批量处理你的操作。
慢(N 次往返):
INSERT INTO logs VALUES (1, 'Event A');
INSERT INTO logs VALUES (2, 'Event B');
-- ... 重复 10,000 次
快(1 次往返):
INSERT INTO logs VALUES
(1, 'Event A'),
(2, 'Event B'),
(3, 'Event C')
-- ... 最多数千行
;
性能对比:
| 方法 | 插入 10,000 行 | 性能 |
|---|---|---|
| 逐行插入 | ~10 秒 | ❌ 慢 |
| 批量插入(1000 行/批) | ~0.5 秒 | ✅ 快 |
| 批量插入(10,000 行/批) | ~0.3 秒 | ✅ 非常快 |
最佳实践:
- 每批 100-1000 行
- 使用事务包装批量操作
- 考虑使用 LOAD DATA(MySQL)或 COPY(PostgreSQL)
批量更新示例:
-- 慢:逐行更新
UPDATE products SET price = price * 1.1 WHERE product_id = 1;
UPDATE products SET price = price * 1.1 WHERE product_id = 2;
-- ...
-- 快:批量更新
UPDATE products SET price = price * 1.1 WHERE category = 'Electronics';
9. 正确的分页
经典的 OFFSET 分页在进入后面的页面时变慢,因为数据库仍然必须扫描所有跳过的行。
朴素方法(第 1000 页很慢):
SELECT * FROM products
ORDER BY product_id
LIMIT 20 OFFSET 20000; -- 第 1001 页
键集分页(快):
-- 记住上一页的最后一个 product_id
SELECT * FROM products
WHERE product_id > 54320 -- 上一页的最后一个 ID
ORDER BY product_id
LIMIT 20;
示例数据(products_pagination 表):
| product_id | product_name | price |
|---|---|---|
| 1 | Product A | 10.00 |
| 2 | Product B | 15.00 |
| 3 | Product C | 20.00 |
| 4 | Product D | 25.00 |
| 5 | Product E | 30.00 |
| 6 | Product F | 35.00 |
键集分页示例:
-- 假设我们在上一页看到了 product_id 3
SELECT * FROM products_pagination
WHERE product_id > 3
ORDER BY product_id
LIMIT 3;
查询结果:
| product_id | product_name | price |
|---|---|---|
| 4 | Product D | 25.00 |
| 5 | Product E | 30.00 |
| 6 | Product F | 35.00 |
OFFSET vs 键集分页性能对比:
| 页数 | OFFSET 方法 | 键集分页 |
|---|---|---|
| 第 1 页 | 0.01 秒 | 0.01 秒 |
| 第 100 页 | 0.5 秒 | 0.01 秒 |
| 第 1000 页 | 5 秒 | 0.01 秒 |
| 第 10000 页 | 50 秒 | 0.01 秒 |
键集分页的优势:
- 性能稳定,不随页数增加而变慢
- 避免跳过行的开销
- 适合深度分页
键集分页的限制:
- 不能跳转到任意页
- 需要唯一且有序的键
- 实现稍复杂
10. 避免隐式类型转换
当你将字符串列与数字比较时,数据库可能需要转换每一行,从而阻止索引使用。
问题:
-- 如果 user_id 是 VARCHAR,这会强制对每一行进行转换
SELECT * FROM users WHERE user_id = 12345;
解决方案:
-- 使用正确的类型
SELECT * FROM users WHERE user_id = '12345';
隐式类型转换示例:
| 列类型 | 查询值 | 是否转换 | 性能 |
|---|---|---|---|
| VARCHAR | = '12345' |
❌ 否 | ✅ 快 |
| VARCHAR | = 12345 |
✅ 是 | ❌ 慢 |
| INT | = 12345 |
❌ 否 | ✅ 快 |
| INT | = '12345' |
✅ 是 | ⚠️ 中等 |
常见的隐式转换陷阱:
-- ❌ 错误:字符串列与数字比较
WHERE phone_number = 1234567890
-- ✅ 正确:使用字符串
WHERE phone_number = '1234567890'
-- ❌ 错误:日期列与字符串比较(某些数据库)
WHERE date_col = '2023-01-01'
-- ✅ 正确:使用日期类型
WHERE date_col = DATE '2023-01-01'
最佳实践:
- 始终使用正确的数据类型
- 避免在 WHERE 子句中进行类型转换
- 使用参数化查询(自动处理类型)
总结:优化检查清单
当你遇到慢查询时,按照这个检查清单进行检查:
1. 运行 EXPLAIN
查看执行计划,了解数据库如何执行查询。
EXPLAIN SELECT * FROM orders WHERE customer_id = 123;
2. 检查表扫描
查找应该使用索引的地方是否进行了表扫描。
查找:
- “Table Scan” 或 “Seq Scan”
- “rows” 估计值很大
- “cost” 估计值很高
3. 避免 SELECT *
只获取需要的列,减少 I/O 和网络开销。
-- ❌ 错误
SELECT * FROM orders;
-- ✅ 正确
SELECT order_id, total_amount FROM orders;
4. 使过滤器 SARGable
WHERE 中不对索引列使用函数。
-- ❌ 错误
WHERE YEAR(order_date) = 2023
-- ✅ 正确
WHERE order_date >= '2023-01-01' AND order_date < '2024-01-01'
5. 明智使用复合索引
遵守最左前缀规则,选择合适的列顺序。
-- 索引:(status, customer_id, order_date)
-- ✅ 可以使用
WHERE status = 'active' AND customer_id = 123
-- ❌ 无法使用
WHERE customer_id = 123 AND order_date > '2023-01-01'
6. 在 JOIN 之前过滤
尽早减少行数,降低 JOIN 开销。
WITH FilteredOrders AS (
SELECT * FROM orders WHERE order_date > '2023-01-01'
)
SELECT o.*, c.name
FROM FilteredOrders o
JOIN customers c ON o.customer_id = c.customer_id;
7. 对大子查询优先使用 EXISTS
EXISTS 找到第一个匹配就停止,性能更好。
-- ✅ 推荐
WHERE EXISTS (SELECT 1 FROM orders WHERE ...)
-- ⚠️ 可能较慢
WHERE customer_id IN (SELECT customer_id FROM orders WHERE ...)
8. 批量操作
批量处理而不是逐行处理,减少事务开销。
-- ✅ 快
INSERT INTO logs VALUES (1, 'A'), (2, 'B'), (3, 'C');
-- ❌ 慢
INSERT INTO logs VALUES (1, 'A');
INSERT INTO logs VALUES (2, 'B');
INSERT INTO logs VALUES (3, 'C');
9. 对深分页使用键集分页
避免大 OFFSET 值,使用 WHERE id > last_id。
-- ✅ 快
WHERE product_id > 54320 ORDER BY product_id LIMIT 20
-- ❌ 慢
LIMIT 20 OFFSET 20000
10. 匹配数据类型
避免隐式转换,使用正确的数据类型。
-- ✅ 正确
WHERE user_id = '12345' -- user_id 是 VARCHAR
-- ❌ 错误
WHERE user_id = 12345 -- 强制类型转换
优化是迭代的
优化不是一次性的工作,而是一个持续的过程:
- 测量:使用 EXPLAIN 和性能监控工具
- 识别瓶颈:找到最慢的查询
- 修复:应用优化技术
- 重复:持续监控和改进
通过这些技术,你可以将需要几分钟的查询转变为在毫秒内返回的查询。
关键要点:
- 理解数据库的工作原理
- 使用执行计划指导优化
- 索引是性能的关键
- 避免常见的性能陷阱
- 持续监控和改进
掌握这些 SQL 优化技术,你将能够构建高性能的数据库应用程序!
相关文章推荐
- How to Read SQL Execution Plans: A Beginner’s Guide - 停止猜测为什么你的查询很慢,学习阅读执行计划
- Understanding Database Indexes: The Key to Performance - 为什么我的查询很慢?答案通常是索引
- SQL Anti-Patterns: The Silent Performance Killers in Your Queries - 你的查询能工作但很慢?你可能在使用反模式
本文转载自 www.hisqlboy.com
原文标题:Essential SQL Optimization Techniques for Faster Queries
原文链接:https://www.hisqlboy.com/blog/sql-optimization-techniques
原作者:SQL Boy Team
转载日期:2026-02-12
著作权归原作者所有。本文仅用于学习交流,非商业用途。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)