第5章 循环神经网络--让AI拥有记忆力的魔法(上)
5.1 独热编码
在深度学习中,我们经常需要处理非数值型数据,比如文字、类别等。这些数据不能直接输入到神经网络中,需要转换为数值形式。独热编码(One-Hot Encoding)就是这样一种简单而有效的编码方式。
什么是独热编码?
独热编码是一种将分类变量转换为二进制向量的方法。对于一个有N个不同取值的分类变量,我们创建一个长度为N的向量,其中只有一个元素为1,其余都为0。这个为1的位置就代表了对应的类别。
举个例子,假设我们有三种水果:苹果、香蕉和橙子。用独热编码表示就是:
-
苹果:[1, 0, 0]
-
香蕉:[0, 1, 0]
-
橙子:[0, 0, 1]
为什么需要独热编码?
你可能会问,为什么不直接用1、2、3来表示这些类别呢?原因在于,如果直接用数字编码,会引入错误的数值关系。比如,如果我们用1表示苹果,2表示香蕉,3表示橙子,那么模型可能会错误地认为橙子是苹果的"3倍",或者香蕉处于苹果和橙子之间的"中间状态"。这种数值关系在类别数据中是不存在的,会误导模型的学习。
独热编码避免了这个问题,因为它让每个类别都在自己的维度上,彼此之间是正交的,没有数值上的大小关系。
独热编码的实际应用
在自然语言处理中,独热编码被广泛用于表示单词。假设我们的词汇表有10000个单词,那么每个单词都可以用一个10000维的向量表示,其中只有对应单词的位置为1,其他都为0。
import numpy as np
# 假设我们的词汇表有5个单词
vocab = ['我', '爱', '深度', '学习', '神经网络']
# 创建单词到索引的映射
word_to_index = {word: i for i, word in enumerate(vocab)}
def one_hot_encode(word):
vector = np.zeros(len(vocab))
vector[word_to_index[word]] = 1
return vector
# 测试
print("'我'的独热编码:", one_hot_encode('我'))
print("'学习'的独热编码:", one_hot_encode('学习'))输出结果:
text
'我'的独热编码: [1. 0. 0. 0. 0.] '学习'的独热编码: [0. 0. 0. 1. 0.]
独热编码的优缺点
优点:
-
简单直观,容易理解和实现
-
解决了分类器不好处理属性数据的问题
-
在一定程度上起到了扩充特征的作用
缺点:
-
维度灾难:当类别很多时,向量维度会非常高,导致计算和存储成本大大增加
-
词汇鸿沟:无法表示单词之间的相似性关系,所有单词之间的距离都相等
-
数据稀疏:向量中大部分元素都是0,只有少数是1
应对高维度的策略
对于词汇表很大的情况,独热编码会导致极高的维度。有几种策略可以应对:
-
特征哈希:使用哈希函数将单词映射到固定大小的向量空间
-
降维技术:使用PCA等降维方法减少向量维度
-
词嵌入:使用Word2Vec、GloVe等方法学习低维的稠密向量表示
在神经网络中的应用
在神经网络中,独热编码通常作为第一层的输入。由于独热向量非常稀疏,实际实现时往往使用嵌入层(Embedding Layer)来高效处理。
import torch
import torch.nn as nn
# 使用嵌入层代替独热编码
vocab_size = 10000 # 词汇表大小
embedding_dim = 300 # 嵌入维度
embedding_layer = nn.Embedding(vocab_size, embedding_dim)
# 输入是单词的索引,不是独热向量
input_indices = torch.LongTensor([123, 456, 789])
embedded_vectors = embedding_layer(input_indices)嵌入层本质上是一个查找表,它将离散的索引映射到连续的向量空间,既解决了独热编码的高维度问题,又能学习到单词之间的语义关系。
总结
独热编码是处理类别数据的基础技术,虽然在高维情况下存在效率问题,但其思想简单明了,是理解更高级编码方式的基础。在实际应用中,我们通常使用嵌入层来获得更高效、更有表达力的表示。
5.2 什么是RNN
在我们日常生活中,很多信息都是有顺序的。比如一句话中的单词、音乐中的音符、股票价格的时间序列等。传统的神经网络在处理这种序列数据时存在一个明显的问题:它们假设所有的输入(和输出)都是相互独立的。但对于序列数据来说,这种独立性假设显然不成立 - 一句话中前面的单词会影响后面的单词,昨天的股价会影响今天的股价。
这就是循环神经网络(Recurrent Neural Network, RNN)要解决的问题。RNN是一类专门用于处理序列数据的神经网络。
RNN的核心思想
RNN的核心思想非常直观:在处理序列的每个元素时,不仅要考虑当前的输入,还要考虑之前的"记忆"。换句话说,RNN具有"内部状态",这个状态会随着序列的处理而更新,包含了到目前为止已经处理过的序列信息。
想象一下你在读一本书:理解每一页的内容时,你都会记得前面几页讲了什么。RNN也是类似的工作原理。
RNN与传统神经网络的对比
为了更好地理解RNN,让我们对比一下传统的前馈神经网络:
前馈神经网络:
-
数据流动是单向的,从输入层到输出层
-
每层神经元只与下一层神经元相连
-
同一层的神经元之间没有连接
-
处理每个样本时都是独立的
循环神经网络:
-
神经元之间可以有循环连接
-
隐藏层的输出会反馈到自身,形成"记忆"
-
能够处理可变长度的序列
-
考虑了时间或顺序的依赖性
RNN的基本结构
RNN的基本单元包含三个部分:
-
输入:当前时间步的输入数据
-
隐藏状态:包含了过去信息的"记忆"
-
输出:当前时间步的输出
用数学公式表示就是:
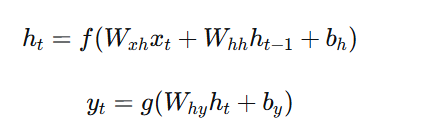
其中:
-
$x_t$ 是时间步t的输入
-
$h_t$ 是时间步t的隐藏状态
-
$y_t$ 是时间步t的输出
-
$W$ 是权重矩阵,$b$ 是偏置项
-
$f$ 和 $g$ 是激活函数
一个简单的例子:字符预测
让我们通过一个具体的例子来理解RNN的工作原理。假设我们要训练一个RNN来预测单词中的下一个字符。
比如,输入序列是"h", "e", "l", "l",我们希望RNN能预测出下一个字符是"o"。
import numpy as np
import torch
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
# 输入到隐藏层的权重
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
# 隐藏层到输出的权重
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
# 将当前输入和之前的隐藏状态拼接
combined = torch.cat((input, hidden), 1)
# 计算新的隐藏状态
hidden = torch.tanh(self.i2h(combined))
# 计算输出
output = self.i2o(combined)
output = self.softmax(output)
return output, hidden
def init_hidden(self):
return torch.zeros(1, self.hidden_size)
# 使用示例
rnn = SimpleRNN(input_size=10, hidden_size=20, output_size=10)
# 模拟输入序列
input_sequence = [torch.randn(1, 10) for _ in range(5)]
hidden = rnn.init_hidden()
# 逐个时间步处理序列
for i in range(5):
output, hidden = rnn(input_sequence[i], hidden)
print(f"时间步 {i}: 输出形状 {output.shape}, 隐藏状态形状 {hidden.shape}")RNN的展开形式
为了更清楚地理解RNN如何处理序列,我们通常将其按时间步展开。这种展开形式显示了RNN在多个时间步上的重复结构。
对于长度为3的序列,展开后的RNN看起来像三个共享参数的普通神经网络层:
text
时间步1: x1 -> RNN单元 -> h1, y1 时间步2: x2 + h1 -> RNN单元 -> h2, y2 时间步3: x3 + h2 -> RNN单元 -> h3, y3
这种参数共享机制是RNN的一个重要特性,它使得模型能够处理不同长度的序列,并且减少了需要学习的参数数量。
RNN的应用场景
RNN在很多序列数据处理任务中表现出色:
-
自然语言处理:机器翻译、文本生成、情感分析
-
语音识别:将音频序列转换为文本
-
时间序列预测:股票价格预测、天气预测
-
音乐生成:生成连贯的音乐序列
-
视频分析:动作识别、视频描述生成
RNN的局限性
尽管RNN很强大,但它也有一些局限性:
-
梯度消失/爆炸问题:在处理长序列时,梯度在反向传播过程中可能会消失或爆炸
-
短期记忆:基本的RNN难以捕捉长距离的依赖关系
-
计算效率:由于序列必须逐个处理,难以并行计算
这些局限性催生了更先进的RNN变体,如LSTM和GRU,我们将在后面详细介绍。
总结
RNN是处理序列数据的强大工具,它通过引入"记忆"机制来捕捉序列中的时间依赖性。虽然基本的RNN存在一些局限性,但它的核心思想为更复杂的序列模型奠定了基础。理解RNN是掌握现代自然语言处理和时间序列分析的关键第一步。
5.3 RNN架构
理解了RNN的基本概念后,让我们深入探讨RNN的具体架构设计。RNN的架构决定了它如何处理输入序列、如何维护内部状态,以及如何产生输出。不同的架构适用于不同的任务场景。
RNN的基本组成单元
RNN的核心是循环单元,这个单元在每个时间步执行相同的操作,但依赖于不同的输入和之前的隐藏状态。让我们详细分析这个单元的内部结构:
import torch
import torch.nn as nn
class RNNCell(nn.Module):
def __init__(self, input_size, hidden_size):
super(RNNCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 输入权重矩阵
self.w_ih = nn.Parameter(torch.randn(hidden_size, input_size))
# 隐藏状态权重矩阵
self.w_hh = nn.Parameter(torch.randn(hidden_size, hidden_size))
# 偏置项
self.b_ih = nn.Parameter(torch.randn(hidden_size))
self.b_hh = nn.Parameter(torch.randn(hidden_size))
def forward(self, x, hidden):
# 计算新的隐藏状态: h_t = tanh(W_ih * x_t + b_ih + W_hh * h_{t-1} + b_hh)
hidden_new = torch.tanh(
torch.mm(x, self.w_ih.t()) + self.b_ih +
torch.mm(hidden, self.w_hh.t()) + self.b_hh
)
return hidden_new这个基本的RNN单元展示了核心计算:结合当前输入和之前隐藏状态来更新当前隐藏状态。
RNN的三种基本架构
根据输入和输出的对应关系,RNN主要有三种基本架构:
1. 一对一(One-to-One)
这是最简单的架构,每个输入对应一个输出,类似于传统的前馈神经网络。虽然这不太体现RNN的优势,但它是理解更复杂架构的基础。
text
输入: x1, x2, x3, ..., xT 输出: y1, y2, y3, ..., yT
应用示例:字符级语言模型,预测每个字符的下一个字符。
2. 多对一(Many-to-One)
多个输入时间步产生一个输出。这种架构适用于需要基于整个序列做出单一决策的任务。
text
输入: x1, x2, x3, ..., xT 输出: y
应用示例:情感分析(基于整个评论判断情感倾向)、序列分类。
3. 一对多(One-to-Many)
一个输入产生多个输出时间步。这种架构用于序列生成任务。
text
输入: x 输出: y1, y2, y3, ..., yT
应用示例:图像描述生成(从一张图片生成文字描述)、音乐生成。
深入理解隐藏状态
隐藏状态是RNN架构中最重要的概念之一。它充当了网络的"记忆",携带了从序列开始到当前时间步的所有相关信息。
# 演示隐藏状态如何随时间步传递
def process_sequence(rnn_cell, input_sequence):
# 初始化隐藏状态
hidden = torch.zeros(1, rnn_cell.hidden_size)
all_hidden_states = []
for t in range(len(input_sequence)):
# 更新隐藏状态
hidden = rnn_cell(input_sequence[t], hidden)
all_hidden_states.append(hidden.detach().numpy())
print(f"时间步 {t}: 隐藏状态均值 = {hidden.mean().item():.4f}")
return all_hidden_states隐藏状态的维度是一个重要的超参数。较大的隐藏状态可以存储更多信息,但也会增加计算复杂度和过拟合风险。
输出层的设计
RNN的输出层设计取决于具体任务:
class RNNModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(RNNModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# RNN层
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
# 输出层
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 初始化隐藏状态
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
# RNN前向传播
out, hidden = self.rnn(x, h0)
# 对于多对一任务,我们通常只使用最后一个时间步的输出
# 对于多对多任务,我们可能使用所有时间步的输出
out = self.fc(out[:, -1, :]) # 取最后一个时间步
return out多层RNN
为了增加模型的表达能力,我们可以堆叠多个RNN层:
class MultiLayerRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=2):
super(MultiLayerRNN, self).__init__()
self.num_layers = num_layers
self.rnn_layers = nn.ModuleList()
# 第一层
self.rnn_layers.append(nn.RNNCell(input_size, hidden_size))
# 中间层
for _ in range(1, num_layers):
self.rnn_layers.append(nn.RNNCell(hidden_size, hidden_size))
self.output_layer = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 初始化各层的隐藏状态
hidden_states = [torch.zeros(x.size(0), layer.hidden_size)
for layer in self.rnn_layers]
outputs = []
for t in range(x.size(1)):
# 第一层使用输入
hidden_states[0] = self.rnn_layers[0](x[:, t, :], hidden_states[0])
# 后续层使用前一层的输出
for layer_idx in range(1, self.num_layers):
hidden_states[layer_idx] = self.rnn_layers[layer_idx](
hidden_states[layer_idx-1], hidden_states[layer_idx]
)
# 输出
output_t = self.output_layer(hidden_states[-1])
outputs.append(output_t)
return torch.stack(outputs, dim=1)双向RNN
在某些任务中,我们不仅需要考虑前面的信息,还需要考虑后面的信息。双向RNN通过同时从两个方向处理序列来解决这个问题:
class BidirectionalRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(BidirectionalRNN, self).__init__()
# 前向RNN
self.rnn_forward = nn.RNN(input_size, hidden_size, batch_first=True)
# 反向RNN
self.rnn_backward = nn.RNN(input_size, hidden_size, batch_first=True)
# 输出层,输入维度是2倍隐藏大小(前向+反向)
self.fc = nn.Linear(2 * hidden_size, output_size)
def forward(self, x):
# 前向传播
out_forward, _ = self.rnn_forward(x)
# 反向传播(反转序列)
reversed_x = torch.flip(x, [1])
out_backward, _ = self.rnn_backward(reversed_x)
out_backward = torch.flip(out_backward, [1]) # 再反转回来
# 拼接前向和反向的输出
combined = torch.cat((out_forward, out_backward), dim=2)
# 输出
out = self.fc(combined[:, -1, :]) # 多对一任务
return out实际应用考虑
在设计RNN架构时,需要考虑几个实际问题:
-
批次处理:为了效率,我们通常同时处理多个序列
-
序列填充:批次中的序列可能长度不同,需要填充到相同长度
-
序列掩码:忽略填充部分的影响
# 处理变长序列的示例 from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence def process_variable_length_sequences(rnn_model, sequences, lengths): # 排序序列按长度降序 lengths_sorted, indices = lengths.sort(descending=True) sequences_sorted = sequences[indices] # 打包序列 packed_sequences = pack_padded_sequence( sequences_sorted, lengths_sorted.cpu(), batch_first=True ) # RNN处理 packed_output, hidden = rnn_model(packed_sequences) # 解包输出 output, _ = pad_packed_sequence(packed_output, batch_first=True) return output, hidden总结
RNN的架构设计提供了处理序列数据的灵活框架。从基本的单向RNN到复杂的双向多层RNN,不同的架构适用于不同的任务需求。理解这些架构的组成和特性,是有效应用RNN解决实际问题的关键。在选择架构时,需要综合考虑任务需求、数据特性和计算资源等因素。
5.4 其他RNN
虽然基本的RNN在理论上很优雅,但在实际应用中,它面临着一些严重的挑战,特别是梯度消失问题和短期记忆限制。这促使研究人员开发了多种RNN的变体,每种都有其独特的优势和适用场景。
5.4.1 Elman网络和Jordan网络
Elman网络和Jordan网络是RNN的两种早期架构,它们在不同的地方引入了循环连接。
Elman网络
Elman网络是最经典的简单RNN架构,由Jeffrey Elman在1990年提出。它的特点是隐藏层到隐藏层的循环连接。
class ElmanRNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(ElmanRNN, self).__init__() self.hidden_size = hidden_size # 输入到隐藏层的权重 self.w_ih = nn.Linear(input_size, hidden_size) # 隐藏层到隐藏层的权重(循环连接) self.w_hh = nn.Linear(hidden_size, hidden_size) # 隐藏层到输出层的权重 self.w_ho = nn.Linear(hidden_size, output_size) def forward(self, x, hidden=None): if hidden is None: hidden = torch.zeros(x.size(0), self.hidden_size) outputs = [] for t in range(x.size(1)): # Elman网络的核心公式 hidden = torch.tanh(self.w_ih(x[:, t, :]) + self.w_hh(hidden)) output = self.w_ho(hidden) outputs.append(output) return torch.stack(outputs, dim=1), hiddenElman网络的结构可以表示为:
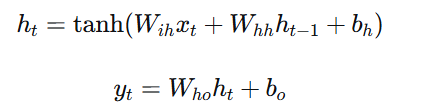
Jordan网络
Jordan网络由Michael Jordan在1986年提出,它的循环连接是从输出层到隐藏层,而不是隐藏层到隐藏层。
class JordanRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(JordanRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
# 输入到隐藏层
self.w_ih = nn.Linear(input_size, hidden_size)
# 前一输出到隐藏层(循环连接)
self.w_oh = nn.Linear(output_size, hidden_size)
# 隐藏层到输出层
self.w_ho = nn.Linear(hidden_size, output_size)
def forward(self, x, previous_output=None):
if previous_output is None:
previous_output = torch.zeros(x.size(0), self.output_size)
outputs = []
for t in range(x.size(1)):
# Jordan网络的核心公式
hidden = torch.tanh(
self.w_ih(x[:, t, :]) + self.w_oh(previous_output)
)
output = self.w_ho(hidden)
outputs.append(output)
previous_output = output
return torch.stack(outputs, dim=1), previous_outputJordan网络的结构:
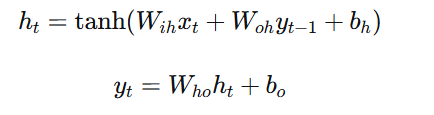
对比分析
-
Elman网络更适合捕捉序列的内部状态变化,因为隐藏状态直接依赖于之前的内部状态
-
Jordan网络在某些任务中可能更稳定,因为输出通常比隐藏状态更有意义且范围受限
-
在实际应用中,Elman网络更为常见,但Jordan网络在某些特定任务中可能表现更好
5.4.2 双向循环神经网络
传统的RNN只考虑了过去的信息,但在很多任务中,未来的信息同样重要。双向循环神经网络(Bidirectional RNN)通过同时从两个方向处理序列来解决这个问题。
工作原理
双向RNN包含两个独立的RNN:一个从前向后处理序列,另一个从后向前处理序列。每个时间步的最终输出是两个方向隐藏状态的组合。
class BidirectionalRNNDetailed(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(BidirectionalRNNDetailed, self).__init__()
self.hidden_size = hidden_size
# 前向RNN
self.forward_rnn = nn.RNN(input_size, hidden_size, batch_first=True)
# 反向RNN
self.backward_rnn = nn.RNN(input_size, hidden_size, batch_first=True)
# 输出层
self.fc = nn.Linear(2 * hidden_size, output_size)
def forward(self, x):
batch_size = x.size(0)
seq_len = x.size(1)
# 前向传播
forward_out, _ = self.forward_rnn(x)
# 反向传播:反转输入序列
reversed_idx = torch.arange(seq_len-1, -1, -1)
reversed_x = x[:, reversed_idx, :]
backward_out, _ = self.backward_rnn(reversed_x)
# 将反向输出再反转回来,使其与原始序列对齐
backward_out = backward_out[:, reversed_idx, :]
# 拼接前向和反向输出
combined = torch.cat((forward_out, backward_out), dim=2)
# 应用输出层
output = self.fc(combined)
return output数学表达
对于双向RNN,每个时间步的输出计算为:
前向隐藏状态:
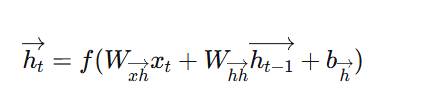
反向隐藏状态:
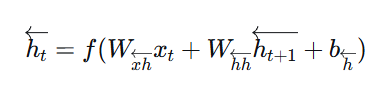
最终输出:
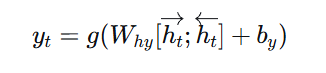
其中 $[;]$ 表示向量拼接。
应用场景
双向RNN特别适合以下任务:
-
自然语言处理:在理解一个单词时,既需要考虑前面的上下文,也需要考虑后面的上下文
-
手写识别:识别一个字符时,周围的字符提供重要线索
-
生物信息学:DNA序列分析中,两端的序列都可能影响中间部分
局限性
-
需要完整的输入序列才能开始处理,不适合实时流式应用
-
计算复杂度大约是单向RNN的两倍
-
在序列很长时,内存消耗较大
5.4.3 LSTM
长短期记忆网络(Long Short-Term Memory, LSTM)是RNN最重要和最成功的变体之一,由Hochreiter和Schmidhuber在1997年提出。LSTM专门设计用来解决基本RNN的梯度消失问题。
LSTM的核心思想
LSTM引入了"门"机制来精确控制信息的流动。与基本RNN只有一个隐藏状态不同,LSTM有两个状态向量:
-
隐藏状态 ($h_t$):短期记忆,类似于基本RNN的隐藏状态
-
细胞状态 ($C_t$):长期记忆,是LSTM的关键创新
LSTM的门结构
LSTM包含三个门,每个门都是一个sigmoid神经网络层,输出0到1之间的值,表示应该让多少信息通过:
-
遗忘门:决定从细胞状态中丢弃什么信息
-
输入门:决定哪些新信息要存储到细胞状态中
-
输出门:决定从细胞状态中输出什么信息
class LSTMCell(nn.Module):
def __init__(self, input_size, hidden_size):
super(LSTMCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 所有门的权重矩阵
self.w_ih = nn.Linear(input_size, 4 * hidden_size)
self.w_hh = nn.Linear(hidden_size, 4 * hidden_size)
def forward(self, x, state):
# state是元组 (h, c)
h, c = state
# 计算所有门的激活值
gates = self.w_ih(x) + self.w_hh(h)
# 分割成输入门、遗忘门、细胞候选、输出门
i_gate, f_gate, g_gate, o_gate = gates.chunk(4, 1)
# 应用激活函数
i_gate = torch.sigmoid(i_gate) # 输入门
f_gate = torch.sigmoid(f_gate) # 遗忘门
g_gate = torch.tanh(g_gate) # 细胞候选值
o_gate = torch.sigmoid(o_gate) # 输出门
# 更新细胞状态
c_new = f_gate * c + i_gate * g_gate
# 更新隐藏状态
h_new = o_gate * torch.tanh(c_new)
return h_new, c_newLSTM的工作流程
1. 遗忘门决定丢弃的信息:
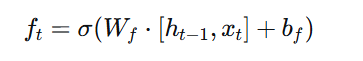
2. 输入门决定更新的信息:
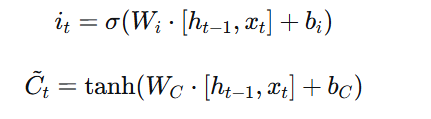
3. 更新细胞状态:
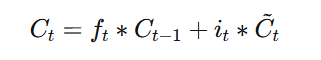
4.输出门决定输出的信息:
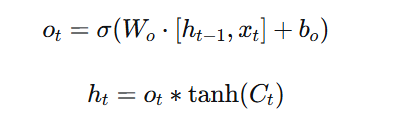
LSTM的优势
-
解决梯度消失:细胞状态提供了贯穿整个序列的梯度高速公路
-
长期依赖:能够记住数百个时间步之前的信息
-
选择性记忆:门机制让网络学会什么时候记住、什么时候忘记
5.4.4 LSTM举例
让我们通过一个具体的例子来理解LSTM如何处理序列数据。我们将构建一个用于文本生成的LSTM模型。
字符级文本生成
假设我们要训练一个LSTM来生成莎士比亚风格的文本。我们将在字符级别进行建模,即每次输入一个字符,预测下一个字符。
import torch
import torch.nn as nn
import numpy as np
class CharLSTM(nn.Module):
def __init__(self, vocab_size, hidden_size, num_layers=2):
super(CharLSTM, self).__init__()
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_layers = num_layers
# 字符嵌入层
self.embedding = nn.Embedding(vocab_size, hidden_size)
# LSTM层
self.lstm = nn.LSTM(hidden_size, hidden_size, num_layers, batch_first=True)
# 输出层
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, x, hidden=None):
# 字符嵌入
x = self.embedding(x)
# LSTM前向传播
lstm_out, hidden = self.lstm(x, hidden)
# 输出层
output = self.fc(lstm_out.contiguous().view(-1, self.hidden_size))
return output, hidden
def init_hidden(self, batch_size):
# 初始化隐藏状态和细胞状态
return (torch.zeros(self.num_layers, batch_size, self.hidden_size),
torch.zeros(self.num_layers, batch_size, self.hidden_size))
# 文本生成函数
def generate_text(model, start_string, char_to_idx, idx_to_char, length=1000, temperature=0.8):
model.eval()
# 初始化输入
chars = [char_to_idx[c] for c in start_string]
hidden = model.init_hidden(1)
generated = start_string
for i in range(length):
# 准备输入
input_tensor = torch.LongTensor([chars[-1]]).unsqueeze(0)
# 前向传播
with torch.no_grad():
output, hidden = model(input_tensor, hidden)
# 应用温度采样
output = output / temperature
probabilities = torch.softmax(output, dim=1).squeeze()
# 采样下一个字符
char_idx = torch.multinomial(probabilities, 1).item()
chars.append(char_idx)
generated += idx_to_char[char_idx]
return generated
# 使用示例
vocab_size = 100 # 假设有100个不同字符
hidden_size = 512
model = CharLSTM(vocab_size, hidden_size)
# 假设我们已经训练好了模型
# generated_text = generate_text(model, "To be or not to be", char_to_idx, idx_to_char)
# print(generated_text)LSTM在机器翻译中的应用
LSTM在序列到序列(seq2seq)模型中发挥着关键作用,特别是在机器翻译任务中。
class Seq2SeqLSTM(nn.Module):
def __init__(self, input_vocab_size, output_vocab_size, hidden_size):
super(Seq2SeqLSTM, self).__init__()
self.hidden_size = hidden_size
# 编码器
self.encoder_embedding = nn.Embedding(input_vocab_size, hidden_size)
self.encoder_lstm = nn.LSTM(hidden_size, hidden_size, batch_first=True)
# 解码器
self.decoder_embedding = nn.Embedding(output_vocab_size, hidden_size)
self.decoder_lstm = nn.LSTM(hidden_size, hidden_size, batch_first=True)
self.decoder_fc = nn.Linear(hidden_size, output_vocab_size)
def forward(self, src, trg, teacher_forcing_ratio=0.5):
# 编码器
src_embedded = self.encoder_embedding(src)
_, (hidden, cell) = self.encoder_lstm(src_embedded)
# 解码器
batch_size = trg.size(0)
trg_len = trg.size(1)
trg_vocab_size = self.decoder_fc.out_features
# 存储输出
outputs = torch.zeros(batch_size, trg_len, trg_vocab_size)
# 第一个输入是<sos>标记
input = trg[:, 0]
for t in range(1, trg_len):
# 解码器前向传播
output, (hidden, cell) = self.decoder_step(input, hidden, cell)
outputs[:, t] = output
# 决定使用教师强制还是自己的预测
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.argmax(1)
input = trg[:, t] if teacher_force else top1
return outputs
def decoder_step(self, input, hidden, cell):
embedded = self.decoder_embedding(input.unsqueeze(1))
output, (hidden, cell) = self.decoder_lstm(embedded, (hidden, cell))
prediction = self.decoder_fc(output.squeeze(1))
return prediction, (hidden, cell)5.4.5 LSTM运算示例
为了更好地理解LSTM的内部工作机制,让我们通过一个具体的数值示例来跟踪LSTM在一个时间步中的计算过程。
假设的设置
假设我们有以下参数:
-
输入大小:3
-
隐藏大小:2
-
批大小:1
输入数据:
-
$x_t = [0.5, -0.2, 0.1]$
-
前一个隐藏状态 $h_{t-1} = [0.3, -0.4]$
-
前一个细胞状态 $C_{t-1} = [0.8, -0.6]$
权重矩阵(为了简化,我们使用小数值):
text
W_ih = [[0.1, 0.2, 0.3], # 输入门
[0.4, 0.5, 0.6], # 遗忘门
[0.7, 0.8, 0.9], # 细胞候选
[1.0, 1.1, 1.2]] # 输出门
W_hh = [[0.1, 0.2], # 输入门
[0.3, 0.4], # 遗忘门
[0.5, 0.6], # 细胞候选
[0.7, 0.8]] # 输出门
偏置项:
b_ih = [0.01, 0.02, 0.03, 0.04]
b_hh = [0.05, 0.06, 0.07, 0.08]
计算步骤
让我们手动计算LSTM的一个时间步:
import numpy as np
# 输入数据
x_t = np.array([0.5, -0.2, 0.1])
h_prev = np.array([0.3, -0.4])
C_prev = np.array([0.8, -0.6])
# 权重矩阵
W_ih = np.array([[0.1, 0.2, 0.3],
[0.4, 0.5, 0.6],
[0.7, 0.8, 0.9],
[1.0, 1.1, 1.2]])
W_hh = np.array([[0.1, 0.2],
[0.3, 0.4],
[0.5, 0.6],
[0.7, 0.8]])
# 偏置项
b_ih = np.array([0.01, 0.02, 0.03, 0.04])
b_hh = np.array([0.05, 0.06, 0.07, 0.08])
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 步骤1: 计算所有门的激活值
gates = np.dot(W_ih, x_t) + b_ih + np.dot(W_hh, h_prev) + b_hh
# 分割成各个门
i_gate = gates[0:2] # 输入门 (2维)
f_gate = gates[2:4] # 遗忘门 (2维)
g_gate = gates[4:6] # 细胞候选 (2维)
o_gate = gates[6:8] # 输出门 (2维)
print("原始门值:")
print(f"输入门: {i_gate}")
print(f"遗忘门: {f_gate}")
print(f"细胞候选: {g_gate}")
print(f"输出门: {o_gate}")
# 步骤2: 应用激活函数
i_gate = sigmoid(i_gate) # 输入门
f_gate = sigmoid(f_gate) # 遗忘门
g_gate = np.tanh(g_gate) # 细胞候选值
o_gate = sigmoid(o_gate) # 输出门
print("\n激活后的门值:")
print(f"输入门: {i_gate}")
print(f"遗忘门: {f_gate}")
print(f"细胞候选: {g_gate}")
print(f"输出门: {o_gate}")
# 步骤3: 更新细胞状态
C_t = f_gate * C_prev + i_gate * g_gate
print(f"\n新的细胞状态: {C_t}")
# 步骤4: 更新隐藏状态
h_t = o_gate * np.tanh(C_t)
print(f"新的隐藏状态: {h_t}")运行这个代码,我们可以看到LSTM内部的具体计算过程。这个示例虽然使用了简化的小数值,但它清晰地展示了LSTM如何通过门机制来控制信息流。
门的作用分析
通过这个数值示例,我们可以清楚地看到每个门的作用:
-
遗忘门:决定从前一个细胞状态中保留多少信息。值接近1表示完全保留,接近0表示完全忘记。
-
输入门:决定有多少新信息要加入到细胞状态中。它与细胞候选值共同作用,决定更新什么内容。
-
输出门:基于更新后的细胞状态,决定输出什么信息到隐藏状态。
这种精密的门控机制让LSTM能够有选择地记住重要信息、忘记无关信息,从而有效地处理长期依赖关系。
总结
本节我们深入探讨了RNN的各种变体,从早期的Elman和Jordan网络,到强大的双向RNN,再到革命性的LSTM。每种架构都有其独特的优势和适用场景。特别是LSTM,通过精密的门控机制解决了长期依赖问题,成为了处理序列数据的首选工具之一。理解这些不同RNN变体的工作原理,对于选择合适模型解决实际问题至关重要。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)