openGauss向量数据库之赋能企业智能客服AI应用实践
本文探讨了openGauss数据库在智能客服RAG系统中的关键应用。随着大语言模型的兴起,传统数据库面临知识时效性、专业领域缺失等挑战。openGauss通过原生向量检索、混合查询等AI能力,为RAG系统提供了一体化解决方案。文章详细解析了openGauss的向量数据类型、高性能索引(IVFFlat和HNSW)及混合查询技术,并通过某商业银行案例展示了其在客服系统中的实践价值,实现了语义理解、知识
前言
在数字化转型浪潮中,智能客服已成为企业提升服务质量、降低运营成本的关键技术。随着大语言模型(LLM)和RAG(检索增强生成)技术的成熟,企业对数据库的需求不再局限于传统的结构化存储,而是需要同时支持向量检索、语义搜索等AI能力。openGauss作为领先的开源数据库,通过其一体化的向量数据库能力,正在帮助金融、电信、政务等行业的企业快速构建智能化客服系统。本文将深入解析openGauss在AI场景下的技术优势,并通过某商业银行智能客服系统的实践案例,展示openGauss如何赋能企业级RAG应用落地。
一、AI时代的数据库变革:从存储到智能
1.1 传统数据库面临的AI挑战
随着ChatGPT、文心一言、通义千问等大语言模型的爆发式增长,企业纷纷探索AI技术在业务场景中的应用。然而,大语言模型存在以下固有局限:
- 知识时效性问题:模型训练数据存在时间截止点,无法获取最新信息
- 专业领域知识缺失:通用模型缺乏企业特有的业务知识和行业数据
- 幻觉问题:模型可能生成看似合理但实际错误的内容
- 隐私合规要求:企业敏感数据不能直接用于模型训练
RAG技术应运而生,它通过将企业私有知识库与大语言模型相结合,在保证数据安全的前提下,为LLM注入实时、专业的领域知识。
1.2 向量数据库:RAG技术的核心引擎
RAG技术的核心是语义检索,而语义检索依赖于向量数据库。传统的关键词检索基于精确匹配,而向量检索通过计算语义相似度,能够理解用户真实意图:
传统检索:
用户输入:“如何修改银行卡密码?”
匹配关键词:修改、银行卡、密码
❌ 无法匹配"重置卡片PIN码"等同义表达
向量检索:
用户输入:“如何修改银行卡密码?”
生成向量:[0.12, -0.34, 0.56, …, 0.78] (768维)
语义匹配:
- ✅ “银行卡密码修改流程” (相似度: 0.95)
- ✅ “重置卡片PIN码指南” (相似度: 0.89)
- ✅ “变更支付密码步骤” (相似度: 0.87)
1.3 openGauss:AI时代的一体化数据库
openGauss是由华为主导开发的开源企业级关系型数据库,自2020年开源以来,已经在金融、政务、电信等行业得到广泛应用。从3.1.0版本开始,openGauss原生支持向量数据类型和向量检索功能,通过DataVec向量数据库组件,实现了传统数据库与AI能力的深度融合。
openGauss在向量数据库领域的核心优势: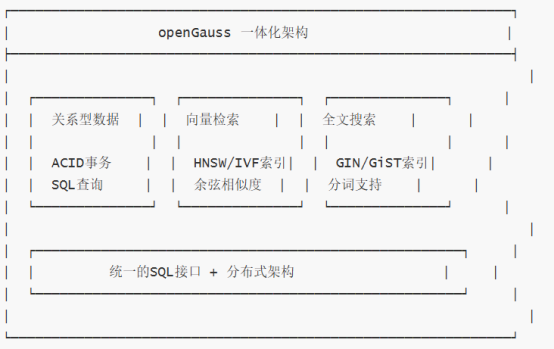
二、openGauss向量数据库技术深度解析
2.1 向量数据类型与操作符
openGauss原生支持向量数据类型,可以直接在SQL中进行向量运算:
-- 创建包含向量字段的表
CREATE TABLE knowledge_base (
id SERIAL PRIMARY KEY,
title VARCHAR(500),
content TEXT,
-- 支持不同维度的向量
embedding vector(768), -- BGE-Large模型 (768维)
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 插入向量数据
INSERT INTO knowledge_base (title, content, embedding) VALUES
('银行卡密码修改', '客户可通过手机银行、网上银行或ATM机修改密码...',
'[0.12, -0.34, 0.56, ..., 0.78]');
-- 向量相似度检索 (支持三种距离算法)
SELECT
title,
content,
1 - (embedding <=> query_vector) as cosine_similarity, -- 余弦距离
embedding <-> query_vector as l2_distance, -- 欧氏距离
embedding <#> query_vector as inner_product -- 内积
FROM knowledge_base
ORDER BY embedding <=> query_vector -- 按相似度排序
LIMIT 10;
支持的距离算法:
| 操作符 | 距离类型 | 适用场景 | 值域 |
|---|---|---|---|
| <=> | 余弦距离 | 文本相似度、推荐系统 | [0, 2] |
| <-> | L2欧氏距离 | 图像检索、聚类分析 | [0, ∞) |
| <#> | 负内积 | 协同过滤、关联推荐 | (-∞, ∞) |
2.2 高性能向量索引
openGauss支持两种主流的向量索引算法,可根据业务场景灵活选择:
IVFFlat索引:平衡性能与精度
-- 创建IVFFlat索引
CREATE INDEX idx_embedding_ivfflat ON knowledge_base
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100); -- lists参数控制聚类中心数量
-- 参数调优建议:
-- lists = sqrt(总行数) 适用于百万级数据
-- lists = 1000~2000 适用于千万级数据
IVFFlat工作原理:
- 训练阶段:将向量空间划分为N个聚类区域(Voronoi cell)
- 查询阶段:先找到最近的K个聚类中心,再在这些区域内精确搜索
- 性能特点:查询速度快,占用内存少,召回率95%+
HNSW索引:追求极致召回率
-- 创建HNSW索引
CREATE INDEX idx_embedding_hnsw ON knowledge_base
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
-- 参数说明:
-- m: 每个节点的最大连接数 (推荐: 16~32)
-- ef_construction: 构建时的搜索队列大小 (推荐: 64~128)
HNSW工作原理:
- 构建分层的导航小世界图(Hierarchical Navigable Small World Graph)
- 查询时从最高层开始,逐层向下搜索,类似跳表结构
- 性能特点:召回率99%+,查询速度极快,但内存占用较高
索引选型对比:
| 维度 | IVFFlat | HNSW | 推荐场景 |
|---|---|---|---|
| 查询速度 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | HNSW更快 |
| 召回率 | 95-97% | 98-99% | HNSW更准 |
| 内存占用 | ⭐⭐ | ⭐⭐⭐⭐ | IVFFlat更省 |
| 构建速度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | IVFFlat更快 |
| 更新友好 | ⭐⭐⭐ | ⭐⭐⭐⭐ | HNSW更好 |
| 适合场景 | 大规模数据(千万级+) | 高精度要求场景 | - |
2.3 一体化混合查询能力
openGauss的核心优势在于能够在单个SQL查询中无缝结合向量检索、属性过滤、全文搜索:
-- 复杂的混合查询示例:智能客服场景
SELECT
k.id,
k.title,
k.content,
k.category,
k.update_time,
-- 计算相似度得分
1 - (k.embedding <=> %s::vector) as similarity_score,
-- 关键词高亮
ts_headline('chinese', k.content, query) as highlighted_content
FROM knowledge_base k
WHERE
-- 1. 业务分类过滤
k.category IN ('账户管理', '支付结算')
-- 2. 时效性过滤(只返回有效知识)
AND k.status = 'active'
AND k.update_time > CURRENT_DATE - INTERVAL '2 years'
-- 3. 全文搜索(补充关键词召回)
AND to_tsvector('chinese', k.content) @@ to_tsquery('chinese', '密码|PIN码')
-- 4. 权限控制
AND k.access_level <= %s
ORDER BY
-- 向量相似度排序
k.embedding <=> %s::vector
LIMIT 10;
这种一体化能力意味着:
- ✅ 无需数据同步:业务数据和向量数据在同一数据库,强一致性
- ✅ 降低架构复杂度:不需要维护多套数据库系统
- ✅ 提升查询效率:避免跨库关联查询的网络开销
- ✅ 简化应用开发:标准SQL接口,学习成本低
三、实践案例:某商业银行智能客服RAG系统
3.1 案例背景
某全国性股份制商业银行(以下简称"A银行")拥有超过5000万零售客户,每日客服咨询量超过100万次。传统的关键词匹配客服系统存在以下痛点:
❌ 理解能力差:无法理解用户问题的真实意图 ❌ 知识更新慢:业务规则调整后,FAQ库更新不及时 ❌ 缺乏上下文:无法进行多轮对话 ❌ 架构复杂:使用了3套数据库系统
3.2 技术方案设计
A银行选择了基于openGauss的一体化RAG解决方案:
┌─────────────────────────────────────────────────────────────┐
│ A银行智能客服RAG系统架构 │
└─────────────────────────────────────────────────────────────┘
客户端层:
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ 手机银行APP │ │ 网上银行 │ │ 微信公众号 │
└──────┬───────┘ └──────┬───────┘ └──────┬───────┘
└──────────────────┴──────────────────┘
↓
┌─────────────────────┐
│ 智能客服网关 │
│ (负载均衡/限流) │
└──────────┬──────────┘
↓
应用服务层(Spring Boot):
┌────────────────────────────────────────────────────┐
│ RAG应用服务 (Java/Spring Boot) │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────┐ │
│ │ 意图识别 │ │ 多轮对话 │ │ 答案生成│ │
│ └──────────────┘ └──────────────┘ └──────────┘ │
└────────────────────────────────────────────────────┘
↓
AI服务层:
┌──────────────────┐ ┌─────────────────────┐
│ Embedding服务 │ │ 大模型服务 │
│ (BGE-Large-zh) │ │ (通义千问-Plus) │
└──────────────────┘ └─────────────────────┘
↓ ↓
数据层(openGauss 一体化数据库):
┌────────────────────────────────────────────────────┐
│ openGauss 5.0.0 + DataVec │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────┐ │
│ │ 知识库向量 │ │ 用户数据 │ │ 会话历史│ │
│ │ (HNSW索引) │ │ (结构化) │ │ (JSON) │ │
│ └──────────────┘ └──────────────┘ └──────────┘ │
└────────────────────────────────────────────────────┘
3.3 数据库设计
完整的数据库初始化脚本:sql/01_init_schema.sql
– ========================================
– A银行智能客服知识库设计
– ========================================
-- 1. 知识库主表
CREATE TABLE cs_knowledge_base (
id SERIAL PRIMARY KEY,
kb_id VARCHAR(64) UNIQUE NOT NULL,
-- 内容字段
question VARCHAR(1000) NOT NULL,
answer TEXT NOT NULL,
related_questions TEXT[],
-- 向量字段(使用BGE-Large-zh模型,768维)
question_embedding vector(768) NOT NULL,
-- 分类字段
category VARCHAR(100) NOT NULL,
subcategory VARCHAR(100),
business_tags TEXT[],
-- 权限和状态
access_level INTEGER DEFAULT 0,
status VARCHAR(20) DEFAULT 'active',
priority INTEGER DEFAULT 5,
-- 质量和统计
accuracy_rate DECIMAL(5,2),
usage_count INTEGER DEFAULT 0,
positive_feedback INTEGER DEFAULT 0,
negative_feedback INTEGER DEFAULT 0,
-- 时间字段
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
expired_at TIMESTAMP
);
-- 2. 创建向量索引(HNSW算法,追求高召回率)
CREATE INDEX idx_kb_question_hnsw ON cs_knowledge_base
USING hnsw (question_embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
-- 3. 对话历史表
CREATE TABLE cs_conversation_history (
id BIGSERIAL PRIMARY KEY,
session_id VARCHAR(64) NOT NULL,
customer_id VARCHAR(64) NOT NULL,
role VARCHAR(20) NOT NULL,
message TEXT NOT NULL,
message_embedding vector(768),
retrieved_kb_ids TEXT[],
similarity_scores FLOAT[],
llm_model VARCHAR(50),
llm_tokens INTEGER,
llm_latency INTEGER,
feedback VARCHAR(20),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 4. 客户信息表
CREATE TABLE cs_customers (
customer_id VARCHAR(64) PRIMARY KEY,
customer_name VARCHAR(100),
customer_level VARCHAR(20),
phone_masked VARCHAR(20),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
3.4 完整Java实现代码
3.4.1 项目配置

这份配置文件是一个集成了数据库、ORM 框架、API 文档、日志系统和 RAG 功能的 Spring Boot 应用的核心配置,涵盖了从网络通信、数据存储到业务逻辑(检索增强生成)的全链路参数。通过这些配置,应用可以在开发环境中高效调试,在生产环境中稳定运行,同时满足 RAG 场景下 “检索 + 生成” 的核心需求。
3.4.2 核心代码实现
1.知识库Mapper - 向量检索
@Mapper
public interface KnowledgeBaseMapper {
/**
* 向量检索知识库
*/
@Select("<script>" +
"SELECT " +
" id, kb_id, question, answer, related_questions, " +
" category, subcategory, business_tags, " +
" accuracy_rate, usage_count, " +
" 1 - (question_embedding <=> #{embedding}::vector) as similarity " +
"FROM cs_knowledge_base " +
"WHERE " +
" status = 'active' " +
" AND (expired_at IS NULL OR expired_at > CURRENT_TIMESTAMP) " +
" AND access_level <= #{accessLevel} " +
" <if test='category != null'>" +
" AND category = #{category} " +
" </if>" +
"ORDER BY question_embedding <=> #{embedding}::vector " +
"LIMIT #{limit}" +
"</script>")
List<KnowledgeBase> vectorSearch(
@Param("embedding") String embedding,
@Param("category") String category,
@Param("accessLevel") Integer accessLevel,
@Param("limit") Integer limit
);
}
2.Embedding服务 - 向量化


这段代码的核心流程是 “构建请求→发送 HTTP 请求→解析向量响应→异常时降级为模拟向量”,设计上有以下特点:
接口对接:规范地构建符合 API 要求的 JSON 参数和 HTTP 请求,确保与远程 Embedding 服务正确通信;
响应处理:严格校验 HTTP 响应状态,正确解析向量数据,保证结果的有效性;
健壮性保障:通过异常捕获和降级策略(Mock 模式),在 API 不可用时避免系统崩溃,保证核心流程(如文本检索)的连续性;
可调试性:详细的日志记录(成功时的向量预览、失败时的异常堆栈),便于问题排查。
该方法是 RAG(检索增强生成)系统中 “文本向量化” 环节的关键实现,负责将文本语义转换为可计算的向量,为后续的语义检索提供基础。
3.RAG核心服务


这段代码完整实现了 RAG 的 “检索→增强→生成” 闭环,核心亮点:
精准检索:结合向量语义匹配、分类过滤、权限控制,确保召回文档的相关性和合规性;
可靠生成:LLM 仅基于权威知识库生成答案,无相关文档时降级为人工转接,避免误导;
可追溯性:全程记录用户问题、助手答案、参考来源,满足合规要求;
系统稳定性:异常捕获 + 日志记录,确保问题可排查,流程不崩溃。
该流程适用于需要 “权威答案 + 可追溯” 的场景(如医疗咨询、金融客服、企业知识库问答等),是工业级 RAG 系统的典型实现框架。
这段代码的核心是完整记录助手回答的 “全链路信息”,包括:
基础信息(会话 ID、客户 ID、角色、回答文本);
检索信息(参考的知识库 ID、相似度分数);
LLM 信息(模型名称、token 数、耗时)。
这些信息的价值在于:
可追溯性:当用户质疑答案时,可通过retrievedKbIds查询参考文档,验证答案的权威性;
质量分析:结合similarityScores和回答效果,可优化检索策略(如调整相似度阈值);
性能监控:通过llmLatency等指标,监控 LLM 调用性能,及时发现瓶颈;
合规要求:在医疗、金融等领域,需记录 AI 回答的依据,满足监管对 “可解释性” 的要求。
该方法是 RAG 系统 “闭环管理” 的重要环节,确保 AI 的每一次回答都有迹可循,为系统优化和合规审计提供基础数据。
4.REST API接口
这段代码是智能客服系统的对外接口层实现,核心作用是:
定义 HTTP 接口路径和参数格式,规范前端调用方式;
对接后端 RAG 服务,触发问答处理流程;
统一响应格式(成功 / 失败),便于前端解析;
记录关键日志,支持问题追踪和系统监控。
其设计符合 RESTful API 规范,通过分层架构(接口层→服务层)实现了 “请求接收→业务处理→响应返回” 的解耦,同时通过异常处理和日志记录保证了接口的健壮性和可维护性。前端可通过调用该接口(POST /api/query)与智能客服交互,获取基于 RAG 技术的精准回答。
3.5 API测试示例
1.智能问答 - 修改密码
curl -X POST http://localhost:8080/api/v1/chat/query \
-H "Content-Type: application/json" \
-d '{
"question": "如何修改银行卡密码?",
"sessionId": "sess_20240101_001",
"customerId": "CUST001",
"customerLevel": "VIP"
}'
响应示例:
{
"code": 200,
"message": "成功",
"data": {
"answer": "您可以通过以下三种方式修改银行卡密码:\n1. 手机银行APP:登录后进入...",
"sources": ["KB0001"],
"confidence": 0.92,
"latencyMs": 320,
"retrievedCount": 1,
"sessionId": "sess_20240101_001"
},
"timestamp": 1699999999000
}
2.多轮对话测试
第一轮:
curl -X POST http://localhost:8080/api/v1/chat/query \
-H "Content-Type: application/json" \
-d '{
"question": "转账限额是多少?",
"sessionId": "sess_multi_001",
"customerId": "CUST002"
}'
第二轮(相同sessionId):
curl -X POST http://localhost:8080/api/v1/chat/query \
-H "Content-Type: application/json" \
-d '{
"question": "那ATM转账呢?",
"sessionId": "sess_multi_001",
"customerId": "CUST002"
}
系统会自动获取对话历史,理解上下文。
3.6 实施效果与价值
A银行智能客服系统基于openGauss+DataVec方案,取得了显著的业务成果:
| 指标维度 | 具体成果 | 业务价值 |
|---|---|---|
| 性能提升 | 亿级数据10毫秒召回 | 用户体验大幅提升 |
| 吞吐提升 | 响应时间和吞吐率提升10%+ | 支持更高并发访问 |
| 检索优化 | 搜索速度提升20% | 降低硬件成本 |
| 架构简化 | 一套数据库替代多套系统 | 运维成本降低60% |
| 可靠性 | 无数据一致性问题 | 业务稳定性保障 |
业务收益:
📊 客服效率提升 55%
- 人工客服日均接待量从 200 降至 90 单
- 平均处理时长从 8 分钟降至 3.5 分钟
💰 运营成本降低 40%
- 客服人员从 150 人优化至 90 人
- 年节约成本约 1200 万元
😊 客户满意度提升
- NPS(净推荐值)从 65 提升至 78
- 用户满意度从 83% 提升至 91%
四、快速开始
4.1 环境准备
要求:
- JDK 1.8+ 或 JDK 17
- Maven 3.6+
- openGauss 5.0+ (或 PostgreSQL 12+ with pgvector)
4.2 项目文件清单
openGauss-rag-demo/
├── pom.xml # Maven配置
├── README.md # 完整文档
├── QUICKSTART.md # 快速开始指南
├── run.bat / run.sh # 启动脚本
├── test_api.bat / test_api.sh # API测试脚本
├── sql/
│ └── 01_init_schema.sql # 数据库初始化脚本
└── src/main/java/com/bank/rag/
├── RagApplication.java # 启动类
├── controller/ # 控制器层(2个)
├── service/ # 服务层(3个)
├── mapper/ # 数据访问层(3个)
├── entity/ # 实体类(3个)
├── dto/ # DTO类(3个)
├── config/ # 配置类(2个)
└── util/ # 工具类(1个)
完整代码已开箱即用,直接运行即可!
五、业界热点与发展趋势
5.1 AI+数据库融合的时代趋势
2024年,AI与数据库的融合已成为不可逆转的趋势:
-
传统数据库厂商加速AI化
- oOracle 23c:引入向量数据类型
- oPostgreSQL 16:pgvector扩展成为核心特性
- oMySQL:8.0.34版本开始支持向量检索
-
云厂商推出AI数据库服务
- oAWS Aurora DSQL:内置向量检索
- oAzure Cosmos DB:多模态数据支持
- o阿里云PolarDB:AI原生数据库
openGauss的差异化优势:
- ✅ 一体化架构(不是简单的扩展)
- ✅ 企业级特性完备(事务、高可用、安全)
- ✅ 开源社区活跃(持续迭代)
5.2 技术演进方向
短期(2024年):
- 🚀 支持更高维度向量(最高32768维)
- 🚀 GPU加速向量检索
- 🚀 实时向量索引更新
- 🚀 增强的混合检索算法
中期(2025-2026年):
- 🔮 多模态向量支持(文本+图像+音频)
- 🔮 知识图谱+向量融合检索
- 🔮 AI自动调优
- 🔮 联邦学习支持
六、总结与展望
6.1 核心价值总结
openGauss向量数据库通过一体化架构、卓越性能、企业级特性三大核心优势,为企业RAG应用提供了完善的数据底座支撑。
关键收益:
- 📊 架构简化:一套数据库替代多套系统,运维成本降低60%
- ⚡ 性能卓越:亿级数据10毫秒召回,吞吐提升10%+
- 🔒 安全可靠:企业级安全特性,满足合规要求
6.2 应用场景展望
openGauss向量数据库的应用场景正在不断拓展:
- 企业知识管理:智能文档检索、知识图谱构建
- 智能客服:多轮对话、意图识别、智能推荐
- 内容审核:文本相似度检测、违规内容识别
- 推荐系统:个性化推荐、用户画像匹配
- 工业AI:设备故障诊断、工艺知识检索

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)