第4章 卷积神经网络:计算机的视觉革命
本文介绍了卷积神经网络(CNN)在图像识别中的核心思想:1) 局部连接性,通过小感受野检测局部特征;2) 参数共享,使用相同卷积核扫描全图;3) 下采样操作,通过汇聚层保留关键特征。这些特性使CNN能高效处理图像,大幅减少参数量的同时保持识别能力。文章还实现了一个基于CNN的围棋AI系统,展示了这些原理在实际应用中的价值。这些观察和简化策略构成了现代计算机视觉的基础,体现了"以简驭繁&q
4.1 观察1:检测模式不需要整幅图像
想象一下,你正在欣赏一幅美丽的风景画。要识别画面中的一棵树,你不需要一次性看清整幅画的每一个细节。实际上,你的眼睛会自然地聚焦在树的轮廓、枝叶的纹理这些局部特征上。即使只看画面的一小部分,你也能认出那是一棵树。
这就是卷积神经网络(CNN)的第一个关键观察:识别图像中的模式(如边缘、纹理、物体部件)通常只需要查看图像的局部区域,而不需要全局信息。
局部连接的直觉
让我们用一个人脸识别的例子来说明这个观点。当判断一张图片是否包含人脸时,我们主要关注几个关键区域:
-
眼睛区域:有没有两个对称的椭圆形
-
鼻子区域:有没有一个三角形的凸起
-
嘴巴区域:有没有一个水平的线条
重要的是,识别眼睛只需要看图像的上半部分,识别嘴巴只需要看下半部分。我们不需要同时看到整张脸的所有细节就能做出判断。
全连接网络的问题
在传统的全连接神经网络中,每个神经元都与前一层的所有神经元相连。对于图像处理来说,这种架构存在严重问题:
假设我们有一张100×100像素的彩色图片(总共30,000个输入值),第一个隐藏层有1,000个神经元。那么仅第一层就需要30,000 × 1,000 = 3千万个参数!这会导致:
-
参数爆炸:需要训练的参数数量巨大
-
过拟合:模型容易记住训练数据而不是学习通用特征
-
计算效率低:前向传播和反向传播计算量巨大
局部感受野的生物学基础
这个观察实际上受到了生物视觉系统的启发。1962年,神经科学家Hubel和Wiesel在研究猫的视觉皮层时发现:
-
每个视觉神经元只响应视网膜特定区域的刺激
-
这个区域称为神经元的"感受野"
-
不同神经元对不同类型的刺激(如边缘、角度、运动方向)有选择性响应
这种局部连接的结构使得视觉系统能够高效处理信息。
局部连接的计算优势
卷积神经网络通过局部连接解决了全连接网络的问题:
-
参数共享:同一个特征检测器(卷积核)在图像的不同位置共享参数
-
平移不变性:无论特征出现在图像的哪个位置,都能被检测到
-
层次化特征:底层检测简单特征(边缘、角点),高层组合这些特征形成复杂模式
实际例子:边缘检测
考虑一个简单的任务:检测图像中的垂直边缘。
我们不需要看整张图片来判断是否存在垂直边缘。实际上,我们可以在每个小区域(比如3×3像素)内独立判断:
-
如果左侧像素暗,右侧像素亮,可能就是垂直边缘
-
如果亮度均匀,就不是边缘
通过在整个图像上滑动这个小窗口,我们就能找出所有的垂直边缘。
从局部到全局
卷积神经网络的强大之处在于它通过层次化结构将局部信息组合成全局理解:
-
第一层检测边缘和角点
-
第二层组合边缘形成纹理和简单形状
-
第三层组合纹理形成物体部件
-
更高层组合部件形成完整物体
这种"由简到繁"的处理方式既符合人类的视觉认知过程,也计算高效。
工程实践的意义
这个观察催生了卷积神经网络的核心组件——卷积层。卷积层通过以下方式实现局部连接:
-
使用远小于输入图像尺寸的卷积核(如3×3、5×5)
-
在每个位置应用相同的卷积核
-
通过堆叠多个卷积层来构建层次化表示
这种设计使得CNN在保持强大表达能力的同时,大幅减少了参数数量,使训练深度网络成为可能。
4.2 简化1:感受野
感受野是卷积神经网络中最重要的概念之一,它定义了每个神经元"看到"的输入区域。理解感受野对于掌握CNN的工作原理至关重要。
什么是感受野?
在卷积神经网络中,感受野指的是网络中的某个神经元对应的输入图像上的区域。换句话说,就是该神经元的输出值是由输入图像的哪一部分计算得出的。
举个例子:
-
第一层卷积的神经元:感受野是3×3像素(如果使用3×3卷积核)
-
第二层卷积的神经元:感受野可能是5×5像素
-
更深层的神经元:感受野可能覆盖整个输入图像
感受野的计算
感受野的大小随着网络深度增加而增大。我们可以通过以下公式计算第l层神经元的感受野大小:
![]()
其中:
-
RF_l是第l层的感受野大小
-
k_l是第l层的卷积核大小
-
s_i是第i层的步长(stride)
-
∏表示连乘
感受野的层次化增长
让我们通过一个具体的例子来理解感受野的增长过程:
假设我们有一个5层卷积网络,每层都使用3×3卷积核,步长为1:
第1层:感受野 = 3×3像素
第2层:感受野 = 5×5像素(3 + (3-1)×1 = 5)
第3层:感受野 = 7×7像素(5 + (3-1)×1 = 7)
第4层:感受野 = 9×9像素(7 + (3-1)×1 = 9)
第5层:感受野 = 11×11像素(9 + (3-1)×1 = 11)
可以看到,虽然每层只使用3×3的小卷积核,但经过5层后,顶层的神经元已经能够看到11×11的区域。
步长对感受野的影响
步长(stride)是控制感受野增长的另一个重要因素。大步长会显著增加感受野:
假设3层网络,每层3×3卷积:
-
步长都为1:感受野从3→5→7
-
步长都为2:感受野从3→7→15
空洞卷积(Dilated Convolution)
为了进一步增大感受野而不增加参数数量或降低分辨率,现代CNN中经常使用空洞卷积。空洞卷积通过在卷积核元素之间插入空格来扩大感受野。
例如,空洞率为2的3×3卷积核实际上具有5×5的感受野,但只包含9个参数。
感受野与有效感受野
需要注意的是,理论感受野和有效感受野是不同的:
-
理论感受野:神经元理论上能看到的区域
-
有效感受野:实际上对神经元输出有显著影响的区域
由于反向传播中梯度的衰减,有效感受野通常比理论感受野小。
多尺度感受野
在现代CNN架构中,经常使用多尺度感受野来捕捉不同大小的特征。例如:
-
小感受野:捕捉细节纹理、边缘
-
中等感受野:捕捉物体部件
-
大感受野:捕捉整体结构和上下文关系
Inception模块的多尺度设计
Google的Inception网络通过并行使用不同大小的卷积核来实现多尺度特征提取:
-
1×1卷积:跨通道信息整合
-
3×3卷积:捕捉局部模式
-
5×5卷积:捕捉更大区域的特征
-
3×3最大池化:增加特征不变性
这种设计让网络能够自适应地选择合适尺度的特征。
感受野与物体检测
在物体检测任务中,感受野的设计尤为重要:
-
小物体检测:需要小感受野来精确定位
-
大物体检测:需要大感受野来理解上下文
-
多尺度检测:需要不同大小的感受野来处理不同尺度的物体
实践中的感受野设计
在设计CNN架构时,感受野是需要仔细考虑的因素:
-
任务驱动:根据具体任务选择适当的感受野大小
-
渐进增长:感受野应该随着网络深度逐渐增大
-
多尺度融合:结合不同尺度的感受野来增强模型鲁棒性
-
计算效率:在感受野和计算成本之间找到平衡
感受野的可视化
理解感受野的一个好方法是可视化。我们可以通过以下方法观察感受野:
-
激活最大化:找到最能激活特定神经元的输入模式
-
遮挡测试:遮挡输入图像的不同区域,观察对特定神经元的影响
-
反卷积网络:通过网络反向传播来重建感受野
感受野的概念不仅帮助我们理解CNN的工作原理,也为网络架构设计提供了重要指导。通过精心设计感受野,我们能够构建出既高效又强大的视觉识别系统。
4.3 观察2:同样的模式可能出现在图像的不同区域
想象一下,你在浏览一系列照片,寻找其中是否包含猫。你会发现,无论猫出现在照片的左上角、右下角,还是正中央,你都能识别出来。这是因为"猫"这种模式可能出现在图像的任意位置。
这就是卷积神经网络的第二个关键观察:相同的模式(如边缘、纹理、物体部件)可能出现在图像的不同位置。
平移不变性的直觉
这个观察的核心是"平移不变性"的概念。在图像识别中,平移不变性意味着:
-
一个特征(比如猫耳朵)无论出现在图像的哪个位置,都应该被识别为相同的特征
-
识别结果不应该依赖于特征在图像中的具体位置
这种性质对于视觉识别任务至关重要,因为现实世界中的物体可以出现在各种位置。
全连接网络的局限性
在全连接网络中,每个位置的权重是独立学习的。这意味着:
-
网络需要在每个可能的位置单独学习识别相同的模式
-
如果训练数据中没有某个位置的样本,网络在该位置的表现就会很差
-
参数效率极低,因为相同的知识被重复存储多次
参数共享的解决方案
卷积神经网络通过参数共享解决了这个问题:
-
使用相同的卷积核扫描整个图像
-
无论特征出现在什么位置,都使用相同的权重来检测
-
这显著减少了参数数量,提高了学习效率
卷积操作的平移等变性
卷积操作具有一个美妙的数学性质:平移等变性。这意味着:
-
如果输入图像平移,输出特征图也会相应平移
-
但特征图上的响应模式保持不变
用数学语言表达:
如果y = conv(x),那么conv(translate(x)) = translate(y)
这个性质确保了网络对平移的不变性。
实际例子:人脸检测
考虑人脸检测任务。无论人脸出现在图像的哪个区域,我们都希望检测到它。通过参数共享:
-
同一个"眼睛检测器"在图像的所有位置工作
-
不需要为每个位置训练单独的眼睛检测器
-
网络能够泛化到训练时未见过的位置
多层次的特征共享
参数共享不仅发生在空间维度上,也发生在特征层次中:
-
底层特征共享:边缘、角点等基本特征在所有位置共享检测器
-
中层特征共享:纹理、简单形状等中等复杂度特征也共享参数
-
高层特征共享:物体部件等复杂特征同样受益于参数共享
平移不变性的程度
需要注意的是,CNN的平移不变性不是绝对的,而是有程度的:
-
小平移:通常能够保持很好的不变性
-
大平移:可能受到边界效应的影响
-
极端位置:角落和边缘的响应可能与中心区域不同
数据增强与平移不变性
为了增强模型的平移不变性,实践中经常使用数据增强:
-
随机裁剪
-
随机平移
-
随机旋转
-
随机缩放
这些技术强迫网络学习对位置变化鲁棒的特征。
参数共享的扩展
参数共享的概念可以扩展到其他变换:
-
旋转不变性:通过旋转增强训练,但完全旋转等价的参数共享较难实现
-
尺度不变性:通过多尺度训练或特征金字塔网络实现
-
形变不变性:通过弹性形变数据增强实现
实践中的考虑
在设计CNN时,需要考虑以下几点:
-
特征图大小:随着网络加深,特征图尺寸减小,位置信息变得粗糙
-
边界处理:卷积的边界效应可能影响边缘位置的检测
-
步长选择:大步长会降低位置精度,但增加感受野
-
空洞卷积:可以在不减少分辨率的情况下增大感受野
现代架构中的发展
近年来,一些新的架构对传统的参数共享提出了挑战:
-
注意力机制:允许网络动态调整对不同位置的关注程度
-
可变形卷积:让卷积核的形状能够自适应学习
-
坐标卷积:显式地将位置信息注入到特征中
尽管如此,参数共享仍然是CNN的核心原则,为计算机视觉的发展奠定了坚实基础。
4.4 简化2:共享参数
共享参数是卷积神经网络降低模型复杂度、提高泛化能力的关键机制。让我们深入理解这个重要概念。
什么是参数共享?
参数共享指的是在神经网络的不同部分使用相同的权重。在CNN中,这具体表现为:
-
同一个卷积核在输入的不同位置重复使用
-
每个位置都使用相同的权重来计算输出
这就像是用同一个"特征检测器"扫描整张图片,寻找该特征可能出现的所有位置。
参数共享的数学表达
在数学上,卷积操作可以表示为:
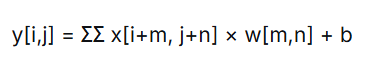
其中:
-
x是输入图像
-
w是共享的卷积核权重
-
b是偏置项
-
求和是对卷积核覆盖的所有位置m,n进行
重要的是,权重w和b在整个图像上共享。
参数数量的显著减少
让我们通过一个具体例子来感受参数共享的威力:
假设:
-
输入图像:100×100×3(高×宽×通道)
-
输出特征图:100×100×32
如果没有参数共享(全连接):
参数数量 = 100×100×3 × 100×100×32 ≈ 96亿
使用参数共享(3×3卷积):
参数数量 = 3×3×3 × 32 + 32 ≈ 900
参数减少了超过1千万倍!
共享参数的学习动态
在训练过程中,共享参数有着独特的学习特性:
-
梯度累积:每个卷积核的梯度来自所有位置的总和
-
稳健更新:由于梯度来自多个位置,参数更新更加稳定
-
快速收敛:每个参数在单个批次中会被多次使用,加速收敛
多层次参数共享
CNN中的参数共享发生在多个层次:
-
空间共享:同一卷积核在空间维度共享
-
通道共享:每个输出通道独立学习特征
-
层间共享:某些架构(如ResNet)在不同层间共享残差连接
共享参数与泛化能力
参数共享极大地提升了模型的泛化能力:
-
减少过拟合:参数数量大幅减少,降低了过拟合风险
-
位置不变性:强迫网络学习对位置不敏感的特征
-
样本效率:每个训练样本提供了多个"虚拟样本"(不同位置)
共享参数的局限性
虽然参数共享有很多优点,但也存在一些局限性:
-
各向同性假设:假设所有方向的重要性相同
-
尺度敏感性:对尺度变化敏感,需要多尺度训练
-
旋转敏感性:对旋转变化敏感,需要旋转增强
现代架构中的参数共享变体
随着CNN的发展,出现了多种参数共享的变体:
-
分组卷积:将通道分组,在组内共享参数
-
深度可分离卷积:将空间卷积和通道卷积分离
-
动态卷积:根据输入动态调整卷积核权重
实践中的参数共享策略
在设计CNN时,需要考虑以下参数共享策略:
-
局部共享:在某些层使用局部参数共享
-
层次化共享:不同层使用不同程度的参数共享
-
任务自适应共享:根据具体任务调整共享策略
参数共享的理论基础
参数共享的理论基础包括:
-
平移等变性:卷积操作的自然数学性质
-
组合爆炸避免:避免为每个位置学习独立参数
-
统计学习理论:通过减少VC维提高泛化能力
参数共享的生物学类比
参数共享在生物学上也有对应:
-
视觉皮层中相同类型的神经元在不同位置重复出现
-
这种结构允许大脑高效处理视觉信息
-
相似的原理也适用于其他感官处理
实现细节
在实现参数共享时,需要注意:
-
权重初始化:共享的权重需要适当初始化
-
正则化:对共享权重使用合适的正则化策略
-
优化器选择:选择适合参数共享结构的优化器
参数共享的未来发展
随着深度学习的发展,参数共享的概念也在演化:
-
条件参数共享:根据输入条件决定参数共享方式
-
元学习:学习如何共享参数
-
神经架构搜索:自动发现最优的参数共享模式
参数共享是CNN成功的关键因素之一,它使得训练深度网络在计算上变得可行,同时在理论上保证了良好的泛化性能。理解参数共享的原理对于设计和优化卷积神经网络至关重要。
4.5 简化1和简化2的总结
在前面的章节中,我们深入探讨了卷积神经网络的两个核心简化:局部连接(感受野)和参数共享。现在让我们对这两个革命性的概念进行系统总结,理解它们如何共同塑造了现代计算机视觉的基础。
两大简化的协同效应
局部连接和参数共享不是孤立的概念,而是相互补充、协同工作的两个支柱。它们共同解决了传统神经网络在图像处理中的根本性问题。
想象一下建造一栋大楼:
-
局部连接就像是用标准尺寸的砖块建造,而不是为每个位置定制特殊形状的砖块
-
参数共享就像是使用同一个模具生产所有砖块,保证一致性
-
两者结合,我们就能用有限的砖块类型建造出无限多样的大楼
计算复杂度的量化分析
让我们用具体的数字来感受这两大简化带来的革命性变化:
假设处理一张1000×1000像素的彩色图像:
-
全连接网络:输入层3百万神经元,第一个隐藏层1000神经元 → 30亿个连接
-
卷积网络:使用100个5×5卷积核 → 仅7500个参数(5×5×3×100)
参数数量减少了40万倍!这种数量级的差异使得训练深度网络从理论上的不可能变成了现实中的可行。
生物学合理性的再思考
这两个简化不仅计算高效,还具有深刻的生物学合理性:
-
视觉皮层的层次结构:大脑视觉皮层也是分层处理信息,从V1区的简单边缘检测到IT区的复杂物体识别
-
感受野的层级增长:从视网膜的小感受野到高级视觉皮层的大感受野,与CNN的感受野增长惊人相似
-
神经元的功能专业化:不同类型的神经元负责检测不同特征,类似于CNN中不同卷积核学习不同特征
工程实现的优雅性
从工程角度看,这两个简化带来了多重好处:
-
内存效率:参数大幅减少,使得在有限内存中训练大型网络成为可能
-
计算并行性:卷积操作天然适合并行计算,完美匹配GPU架构
-
训练稳定性:梯度来自多个位置,更新更加稳定
-
收敛速度:每个参数在单批次中被多次使用,加速收敛
理论基础的坚实性
从数学和统计学习理论的角度看:
-
归纳偏置:通过先验知识引导学习过程,提高样本效率
-
平移等变性:卷积的数学性质保证了位置不变性
-
组合爆炸避免:避免了为每个位置学习独立参数
-
VC维控制:参数减少意味着模型复杂度降低,泛化能力提升
实际应用的普适性
这两个简化的价值超越了图像处理:
-
音频处理:时域上的局部模式检测
-
自然语言处理:文本中的局部语法模式
-
时间序列分析:时间上的局部趋势模式
-
图神经网络:节点邻居关系的局部聚合
现代架构中的演进
虽然核心思想不变,但在现代CNN架构中,这两个简化有了新的发展:
-
可变形卷积:让感受野的形状能够自适应学习
-
深度可分离卷积:将空间相关性和通道相关性的学习分离
-
注意力机制:在保持局部性的同时引入全局信息
-
动态卷积:根据输入内容调整卷积核权重
实践指导意义
对于从业者来说,理解这两个简化具有重要指导意义:
-
架构设计:知道何时使用大卷积核,何时使用小卷积核
-
参数调优:理解参数共享对学习动态的影响
-
问题诊断:当模型表现不佳时,知道从哪个角度分析
-
创新思路:基于这些原理发展新的网络结构
局限性与挑战
当然,这两个简化也有其局限性:
-
各向同性假设:传统卷积假设所有方向同等重要
-
尺度敏感性:对物体尺度变化敏感
-
旋转敏感性:对旋转变化敏感
-
长距离依赖:难以捕捉远距离像素间的关系
未来发展方向
展望未来,这两个简化的概念仍在演化:
-
几何深度学习:将卷积推广到非欧几里得空间
-
等变网络:保证对更广泛变换的不变性
-
稀疏连接:学习最优的连接模式而非固定模式
-
神经架构搜索:自动发现最优的简化策略
总结反思
局部连接和参数共享的成功告诉我们一个深刻的道理:有时候,限制模型的自由度反而能获得更好的性能。通过引入合理的先验知识,我们不仅减少了计算负担,还提高了模型的泛化能力。
这两个简化体现了深度学习中的一个重要哲学:在适当的约束下寻找解决方案,往往比无约束的搜索更加有效。它们证明了"少即是多"的设计理念——通过精心设计的约束,我们能够构建出既简单又强大的模型。
4.6 观察3:下采样不影响模式检测
在图像处理中,下采样(降低图像分辨率)是一个常见操作。令人惊奇的是,对于大多数模式检测任务来说,适度的下采样不仅不会损害性能,反而可能带来好处。这个观察构成了卷积神经网络的第三个重要洞见。
多尺度视觉感知的生物学启示
人类视觉系统本身就采用了下采样的策略。当我们快速扫视一个场景时:
-
中央凹提供高分辨率信息,但视野很小
-
周边视觉提供低分辨率信息,但视野广阔
-
大脑巧妙地结合不同分辨率的信息来理解场景
这种多尺度处理方式既保证了细节感知,又维持了整体理解,还大大降低了处理负担。
下采样的直观理解
想象你在欣赏一幅巨大的壁画:
-
站在画前,你能看清每个笔触的细节,但看不到整体构图
-
退后几步,虽然看不清细节,但能更好地理解整体布局和主题
-
最理想的是在多个距离上观察,获得完整理解
下采样在CNN中就扮演着"后退观察"的角色。
下采样的数学基础
从信息论的角度看,自然图像具有显著的空间冗余性:
-
相邻像素高度相关
-
大部分信息集中在低频成分
-
高频成分主要包含细节和噪声
通过下采样,我们移除了冗余信息,保留了本质特征。
下采样的实际好处
-
计算效率:特征图尺寸减半,计算量减少到1/4
-
感受野增长:在相同层数下获得更大的感受野
-
过拟合控制:参数数量减少,降低过拟合风险
-
平移鲁棒性:对小位移不敏感
-
噪声抑制:平滑操作抑制高频噪声
下采样与信息保留的平衡
关键问题是:下采样到什么程度不会丢失重要信息?
这取决于具体任务:
-
图像分类:可以激进下采样,因为只需要识别物体类别
-
物体检测:需要中等程度下采样,要定位物体位置
-
语义分割:只能轻微下采样,需要像素级精度
-
超分辨率:不能下采样,需要所有细节信息
多尺度特征的金字塔结构
现代CNN通常采用特征金字塔结构:
-
高分辨率特征图:保留空间细节,检测小物体
-
中分辨率特征图:平衡细节和语义,检测中等物体
-
低分辨率特征图:强语义信息,检测大物体,理解场景
下采样的实现方式
在CNN中,下采样主要通过两种方式实现:
-
池化操作
-
最大池化:保留最显著特征
-
平均池化:保留平均特征
-
随机池化:增加随机性,有正则化效果
-
-
步长卷积
-
卷积同时下采样
-
可以学习下采样方式
-
参数效率更高
-
下采样的频率域理解
从信号处理角度看,下采样对应着:
-
抗混叠滤波:防止高频成分混叠到低频
-
频带限制:只保留特定频率范围的信息
-
多分辨率分析:类似小波变换的多尺度表示
下采样在深度网络中的累积效应
随着网络加深,下采样的累积效应显著:
-
第1层:看到像素级细节
-
第3层:看到边缘和纹理
-
第5层:看到物体部件
-
第8层:看到完整物体
-
第10层:看到场景关系
下采样的挑战与解决方案
下采样也带来一些挑战:
-
小物体丢失:解决方案→特征金字塔网络
-
位置信息损失:解决方案→坐标卷积
-
细节信息丢失:解决方案→跳跃连接
-
边界效应:解决方案→适当填充
实际应用中的下采样策略
在实践中,下采样策略需要精心设计:
-
渐进式下采样:不要一次性下采样太多
-
任务自适应:根据任务需求调整下采样程度
-
多路径架构:同时保持多个分辨率的信息
-
可学习下采样:让网络自己学习最佳下采样方式
下采样与计算资源的平衡
在资源受限的环境中,下采样策略尤为重要:
-
移动设备:需要更激进的下采样
-
服务器端:可以保持更高分辨率
-
实时应用:权衡精度和速度
下采样的未来展望
随着计算能力的提升,下采样的角色也在变化:
-
高分辨率网络:在保持高分辨率的同时提高效率
-
自适应下采样:根据输入内容动态调整下采样策略
-
神经下采样:用神经网络学习最优下采样方法
下采样作为CNN的第三个核心观察,体现了"舍弃以得到"的智慧。通过有选择地放弃一些信息,我们获得了计算效率、泛化能力和鲁棒性。这种权衡的艺术是深度学习成功的重要因素之一。
4.7 简化3:汇聚
汇聚(Pooling)是卷积神经网络中实现下采样的关键技术,它通过汇总局部区域的信息来生成更具鲁棒性的特征表示。让我们深入探索这个简单却强大的操作。
汇聚的基本概念
汇聚操作可以理解为"局部摘要":在一个小窗口内,用单个值代表整个区域的信息。就像读书时做摘要,我们不是逐字记忆,而是抓住每段的中心思想。
最大汇聚:突出最强信号
最大汇聚选择每个区域中的最大值:
-
直觉:只要有一个强烈的特征响应,就说明该特征存在
-
优点:保留最显著特征,对噪声鲁棒
-
缺点:可能过度突出异常值
想象一个侦探在分析犯罪现场:
-
最大汇聚就像只关注最有力的证据
-
即使有其他干扰信息,只要关键证据存在,就能做出判断
平均汇聚:寻求共识
平均汇聚计算每个区域的平均值:
-
直觉:考虑所有证据,做出均衡判断
-
优点:平滑噪声,提供稳定估计
-
缺点:可能稀释重要特征
这类似于委员会决策:
-
考虑所有成员的意见
-
通过平均获得集体智慧
-
但可能淹没少数派的重要见解
全局平均汇聚:终极简化
全局平均汇聚将整个特征图压缩为一个值:
-
直觉:对整个图像的特征存在性进行投票
-
优点:极大减少参数,防止过拟合
-
应用:替代全连接层,用于分类输出
这就像对整本书写一句话总结:
-
抓住了核心主题
-
忽略了具体细节
-
适合高层次分类任务
汇聚的几何理解
从几何角度看,汇聚操作实现了:
-
近似不变性:对小平移、旋转、缩放保持不变
-
降维:减少数据维度,保留重要信息
-
抽象化:从具体实例中提取抽象概念
汇聚的统计意义
在统计学上,汇聚操作提供了:
-
充分统计量:用少量数字概括大量数据
-
鲁棒估计:对异常值不敏感
-
多尺度分析:在不同粒度上分析数据
汇聚在深度网络中的作用
随着网络加深,汇聚的作用也在变化:
-
浅层:主要提供平移不变性
-
中层:增大感受野,组合特征
-
深层:提供强语义信息,用于决策
高级汇聚技术
除了基本的最大汇聚和平均汇聚,还有一些改进方法:
-
随机汇聚:随机选择区域代表,有正则化效果
-
混合汇聚:结合最大和平均汇聚的优点
-
可学习汇聚:让网络学习最佳汇聚策略
-
注意力汇聚:根据重要性加权汇聚
汇聚与信息保留的权衡
汇聚本质上是在信息保留和计算效率之间权衡:
-
太多汇聚:丢失细节信息
-
太少汇聚:计算负担重,容易过拟合
-
最优平衡:取决于具体任务
实践中的汇聚策略
在设计网络时,汇聚策略需要考虑:
-
汇聚窗口大小:通常2×2或3×3
-
汇聚步长:通常等于窗口大小(不重叠)
-
汇聚类型:根据任务选择最大或平均汇聚
-
汇聚位置:在卷积层之后插入
汇聚的替代方案
在现代架构中,汇聚有时被其他技术替代:
-
步长卷积:通过大步长卷积实现下采样
-
空洞卷积:增大感受野而不下采样
-
可分离卷积:更高效的特征提取
汇聚的理论分析
从理论角度看,汇聚操作:
-
降低VC维:减少模型复杂度
-
增加稳定性:对输入微小变化不敏感
-
促进稀疏性:只有显著特征能够通过
汇聚的神经科学类比
汇聚操作在大脑视觉处理中有对应:
-
复杂细胞:对特定特征的位置不敏感
-
层级处理:从局部特征到全局概念
-
注意力机制:选择重要信息进行传递
汇聚的局限性
尽管汇聚很有效,但也有局限性:
-
信息损失:不可避免丢失一些信息
-
位置模糊:精确位置信息丢失
-
固定模式:传统汇聚使用固定模式,可能不是最优
未来发展方向
汇聚技术仍在不断发展:
-
动态汇聚:根据输入内容调整汇聚策略
-
多模态汇聚:结合不同类型的信息
-
可微分汇聚:端到端学习最佳汇聚方式
汇聚作为CNN的第三个简化,体现了"以简驭繁"的智慧。通过有选择地压缩信息,我们既保留了本质特征,又获得了计算效率和泛化能力。这种平衡艺术是深度学习成功的关键所在。
围棋游戏与卷积神经网络实现
下面是一个使用Python和PyTorch实现的简单围棋游戏,包含一个基础的卷积神经网络用于评估棋盘状态。这个实现包含了围棋的基本规则和简单的AI对弈功能。
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import random
from collections import deque
import copy
# 围棋棋盘类
class GoBoard:
def __init__(self, size=9):
self.size = size
self.board = np.zeros((size, size), dtype=int) # 0: 空, 1: 黑, 2: 白
self.current_player = 1 # 黑棋先行
self.ko_point = None # 劫点
self.history = [] # 历史记录,用于判断重复局面
self.last_move = None
self.passes = 0 # 连续虚着次数
def reset(self):
self.board.fill(0)
self.current_player = 1
self.ko_point = None
self.history = []
self.last_move = None
self.passes = 0
def get_legal_moves(self):
moves = []
# 添加所有空点
for i in range(self.size):
for j in range(self.size):
if self.board[i, j] == 0 and self.is_legal_move(i, j):
moves.append((i, j))
# 添加虚着
moves.append((-1, -1)) # 虚着用(-1, -1)表示
return moves
def is_legal_move(self, i, j):
# 检查是否是虚着
if i == -1 and j == -1:
return True
# 检查是否在棋盘内
if i < 0 or i >= self.size or j < 0 or j >= self.size:
return False
# 检查是否为空点
if self.board[i, j] != 0:
return False
# 创建临时棋盘测试落子
test_board = GoBoard(self.size)
test_board.board = self.board.copy()
test_board.current_player = self.current_player
test_board.ko_point = self.ko_point
# 尝试落子
if not test_board.place_stone(i, j):
return False
# 检查是否违反劫规则
if (i, j) == self.ko_point:
return False
# 检查是否导致重复局面
new_state = self.get_state_after_move(i, j)
if new_state in self.history:
return False
return True
def place_stone(self, i, j):
# 虚着
if i == -1 and j == -1:
self.last_move = (-1, -1)
self.history.append(self.get_state())
self.current_player = 3 - self.current_player # 切换玩家
self.passes += 1
return True
# 检查是否在棋盘内
if i < 0 or i >= self.size or j < 0 or j >= self.size:
return False
# 检查是否为空点
if self.board[i, j] != 0:
return False
# 放置棋子
self.board[i, j] = self.current_player
# 检查并移除被提的棋子
captured = self.remove_captured_stones(i, j)
# 检查自提(自杀)
if not self.has_liberty(i, j) and not captured:
self.board[i, j] = 0 # 撤销落子
return False
# 更新劫点
if len(captured) == 1:
self.ko_point = captured[0]
else:
self.ko_point = None
# 更新历史记录
self.history.append(self.get_state())
if len(self.history) > 6: # 保留最近6个局面
self.history.pop(0)
self.last_move = (i, j)
self.current_player = 3 - self.current_player # 切换玩家
self.passes = 0 # 重置虚着计数
return True
def remove_captured_stones(self, i, j):
captured = []
opponent = 3 - self.current_player
# 检查相邻的对手棋子
for ni, nj in self.get_neighbors(i, j):
if self.board[ni, nj] == opponent:
if not self.has_liberty(ni, nj):
group = self.get_group(ni, nj)
for stone in group:
self.board[stone[0], stone[1]] = 0
captured.append(stone)
return captured
def has_liberty(self, i, j):
visited = set()
return self._has_liberty(i, j, visited)
def _has_liberty(self, i, j, visited):
if (i, j) in visited:
return False
visited.add((i, j))
color = self.board[i, j]
if color == 0: # 空点
return True
for ni, nj in self.get_neighbors(i, j):
if self.board[ni, nj] == 0: # 有空点
return True
if self.board[ni, nj] == color:
if self._has_liberty(ni, nj, visited):
return True
return False
def get_group(self, i, j):
color = self.board[i, j]
group = []
visited = set()
self._get_group(i, j, color, visited, group)
return group
def _get_group(self, i, j, color, visited, group):
if (i, j) in visited or self.board[i, j] != color:
return
visited.add((i, j))
group.append((i, j))
for ni, nj in self.get_neighbors(i, j):
self._get_group(ni, nj, color, visited, group)
def get_neighbors(self, i, j):
neighbors = []
for di, dj in [(-1, 0), (1, 0), (0, -1), (0, 1)]:
ni, nj = i + di, j + dj
if 0 <= ni < self.size and 0 <= nj < self.size:
neighbors.append((ni, nj))
return neighbors
def get_state(self):
return tuple(map(tuple, self.board))
def get_state_after_move(self, i, j):
if i == -1 and j == -1: # 虚着
return self.get_state()
temp_board = self.board.copy()
temp_board[i, j] = self.current_player
return tuple(map(tuple, temp_board))
def is_game_over(self):
# 连续两次虚着或一方无合法着法
return self.passes >= 2 or len(self.get_legal_moves()) == 0
def display(self):
symbols = {0: '.', 1: 'X', 2: 'O'}
print(' ', end='')
for j in range(self.size):
print(chr(ord('A') + j), end=' ')
print()
for i in range(self.size):
print(i+1, end=' ')
for j in range(self.size):
print(symbols[self.board[i, j]], end=' ')
print()
print(f"当前玩家: {'黑(X)' if self.current_player == 1 else '白(O)'}")
if self.last_move:
if self.last_move == (-1, -1):
print("上一步: 虚着")
else:
print(f"上一步: {chr(ord('A') + self.last_move[1])}{self.last_move[0] + 1}")
# 卷积神经网络模型
class GoCNN(nn.Module):
def __init__(self, board_size=9, num_filters=64, num_blocks=5):
super(GoCNN, self).__init__()
self.board_size = board_size
# 输入通道: 3 (当前玩家棋子, 对手棋子, 空点)
self.conv1 = nn.Conv2d(3, num_filters, 3, padding=1)
self.blocks = nn.ModuleList([
nn.Sequential(
nn.Conv2d(num_filters, num_filters, 3, padding=1),
nn.BatchNorm2d(num_filters),
nn.ReLU(),
nn.Conv2d(num_filters, num_filters, 3, padding=1),
nn.BatchNorm2d(num_filters)
) for _ in range(num_blocks)
])
# 策略头 - 预测每个位置的落子概率
self.policy_conv = nn.Conv2d(num_filters, 2, 1)
self.policy_fc = nn.Linear(2 * board_size * board_size, board_size * board_size + 1) # +1 for pass
# 价值头 - 预测当前局面的胜率
self.value_conv = nn.Conv2d(num_filters, 1, 1)
self.value_fc1 = nn.Linear(board_size * board_size, 64)
self.value_fc2 = nn.Linear(64, 1)
def forward(self, x):
# 初始卷积
x = F.relu(self.conv1(x))
# 残差块
for block in self.blocks:
residual = x
x = block(x)
x = F.relu(x + residual)
# 策略头
policy = self.policy_conv(x)
policy = policy.view(policy.size(0), -1)
policy = self.policy_fc(policy)
policy = F.softmax(policy, dim=1)
# 价值头
value = self.value_conv(x)
value = value.view(value.size(0), -1)
value = F.relu(self.value_fc1(value))
value = torch.tanh(self.value_fc2(value))
return policy, value
def predict(self, board_tensor):
self.eval()
with torch.no_grad():
policy, value = self.forward(board_tensor)
return policy, value
# 围棋AI类
class GoAI:
def __init__(self, model=None, board_size=9):
self.board_size = board_size
self.model = model
if model is None:
self.model = GoCNN(board_size)
def get_move(self, board):
if not self.model:
return self.random_move(board)
# 准备输入数据
board_tensor = self.board_to_tensor(board)
policy, value = self.model.predict(board_tensor)
# 获取合法着法
legal_moves = board.get_legal_moves()
# 选择概率最高的合法着法
move_probs = policy[0].numpy()
legal_probs = []
for move in legal_moves:
if move == (-1, -1): # 虚着
idx = self.board_size * self.board_size
else:
i, j = move
idx = i * self.board_size + j
legal_probs.append((move, move_probs[idx]))
# 按概率排序并选择
legal_probs.sort(key=lambda x: x[1], reverse=True)
best_move = legal_probs[0][0]
return best_move
def random_move(self, board):
legal_moves = board.get_legal_moves()
return random.choice(legal_moves)
def board_to_tensor(self, board):
# 创建3个通道: 当前玩家棋子, 对手棋子, 空点
channels = []
# 当前玩家棋子
player_channel = np.zeros((board.size, board.size))
player_channel[board.board == board.current_player] = 1
channels.append(player_channel)
# 对手棋子
opponent_channel = np.zeros((board.size, board.size))
opponent_channel[board.board == (3 - board.current_player)] = 1
channels.append(opponent_channel)
# 空点
empty_channel = np.zeros((board.size, board.size))
empty_channel[board.board == 0] = 1
channels.append(empty_channel)
# 转换为tensor
board_tensor = torch.FloatTensor(np.array(channels)).unsqueeze(0)
return board_tensor
# 游戏主循环
def main():
board_size = 9
board = GoBoard(board_size)
ai_black = GoAI(board_size=board_size)
ai_white = GoAI(board_size=board_size)
print("欢迎使用围棋游戏!")
print("输入格式: A1 (表示第1行第A列)")
print("输入 'pass' 表示虚着")
print("输入 'quit' 退出游戏")
player_color = input("选择你的棋子颜色 (b: 黑棋, w: 白棋): ").lower()
if player_color == 'b':
human_player = 1 # 黑棋
ai_players = {2: ai_white} # 白棋是AI
else:
human_player = 2 # 白棋
ai_players = {1: ai_black} # 黑棋是AI
while not board.is_game_over():
board.display()
if board.current_player == human_player:
# 人类玩家回合
move_str = input("请输入你的着法: ").strip().lower()
if move_str == 'quit':
print("游戏结束!")
break
elif move_str == 'pass':
i, j = -1, -1
else:
try:
col_char = move_str[0].upper()
row_str = move_str[1:]
j = ord(col_char) - ord('A')
i = int(row_str) - 1
except:
print("输入格式错误,请重新输入!")
continue
if board.is_legal_move(i, j):
board.place_stone(i, j)
else:
print("非法着法,请重新输入!")
else:
# AI回合
print("AI思考中...")
ai = ai_players[board.current_player]
i, j = ai.get_move(board)
if i == -1 and j == -1:
print("AI选择虚着")
else:
col_char = chr(ord('A') + j)
print(f"AI落子: {col_char}{i+1}")
board.place_stone(i, j)
# 游戏结束
board.display()
print("游戏结束!")
# 简单计分 (实际围棋计分更复杂)
black_count = np.sum(board.board == 1)
white_count = np.sum(board.board == 2)
print(f"黑棋: {black_count} 子, 白棋: {white_count} 子")
if black_count > white_count:
print("黑棋获胜!")
elif white_count > black_count:
print("白棋获胜!")
else:
print("平局!")
if __name__ == "__main__":
main()运行说明
-
这个程序实现了一个简单的围棋游戏,包含:
-
围棋棋盘和基本规则
-
卷积神经网络模型
-
人机对弈功能
-
-
运行程序后,你可以选择执黑或执白,然后与AI进行对弈。
-
输入格式:
-
使用字母+数字格式,如"A1"表示第1行第A列
-
输入"pass"表示虚着
-
输入"quit"退出游戏
-
注意事项
-
这个实现中的AI使用的是未经训练的随机模型,所以它的棋力很弱。要获得更强的AI,需要使用大量围棋对局数据进行训练。
-
围棋的完整规则非常复杂,这个实现简化了一些规则(如劫争、眼形判断等)。
-
要运行此程序,需要安装以下Python库:
text
pip install numpy torch
这个程序提供了一个基础的围棋游戏框架,你可以在此基础上进一步扩展和完善功能。
更多信息请关注微信公众号:AI弟

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)