【AI大模型前沿】Qwen3-TTS-Flash:阿里通义的多语言多音色语音合成利器
Qwen3-TTS-Flash 是阿里通义团队精心打造的一款旗舰级文本转语音(TTS)模型,继承了 Qwen 系列模型的先进 AI 技术,专注于提供高效、高质量的语音合成服务。它具备强大的多语言和多方言支持能力,涵盖多种主流语言和方言,能够满足不同地区和场景下的语言需求。同时,模型生成的语音自然流畅,富有表现力,能根据文本内容自动调节语气,让语音更贴近人类表达。
系列篇章💥
目录
前言
在人工智能领域,语音合成技术一直是研究热点之一。随着深度学习的不断发展,语音合成模型的性能和表现力得到了显著提升。阿里通义推出的 Qwen3-TTS-Flash 模型,以其卓越的多语言、多音色和多方言支持能力,以及高效的语音生成性能,成为了当前语音合成领域的一大亮点。
一、项目概述
Qwen3-TTS-Flash 是阿里通义团队精心打造的一款旗舰级文本转语音(TTS)模型,继承了 Qwen 系列模型的先进 AI 技术,专注于提供高效、高质量的语音合成服务。它具备强大的多语言和多方言支持能力,涵盖多种主流语言和方言,能够满足不同地区和场景下的语言需求。同时,模型生成的语音自然流畅,富有表现力,能根据文本内容自动调节语气,让语音更贴近人类表达。
二、核心功能
(一)多音色支持
Qwen3-TTS-Flash 提供 17 种不同的音色选择,每种音色均支持多种语言,满足不同用户对音色的需求。无论是温暖亲切的女声,还是沉稳有力的男声,用户都可以根据具体应用场景和个人喜好进行选择,极大地丰富了语音合成的个性化体验。
(二)多语言与多方言支持
该模型支持普通话、英语、法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语等多种语言,以及闽南语、吴语、粤语、四川话、北京话、南京话、天津话、陕西话等方言。这种广泛的语言和方言覆盖能力,使其能够在全球化的应用场景中发挥重要作用,无论是国际化的商业交流,还是地方特色的文化传播,都能提供有力支持。
(三)高表现力
生成的语音自然、富有表现力,能根据输入文本自动调节语气,使语音更加生动。无论是严肃的新闻播报,还是亲切的产品介绍,模型都能精准地把握文本的情感色彩,通过语音表达出来,极大地提升了语音合成的实用性和感染力。
(四)高鲁棒性
Qwen3-TTS-Flash 对复杂文本具有很强的鲁棒性,能够自动处理复杂文本,抽取关键信息。即使面对格式多样、内容复杂的文本输入,模型也能稳定地生成高质量的语音,确保语音合成的准确性和流畅性,适用于各种复杂的文本场景。
(五)快速生成
该模型具有极低的首包延迟(低至 97ms),能快速生成语音,提升用户体验。这种高效的语音生成能力,使其在实时交互场景中表现出色,例如智能客服、语音助手等应用,能够实现无缝的语音交互,为用户提供即时的语音反馈。
(六)音色相似度高
在多语言的语音稳定性和音色相似度上,Qwen3-TTS-Flash 表现出色,超越其他同类模型。无论是在不同语言之间切换,还是在不同音色之间转换,模型都能保持稳定的语音质量和高度一致的音色表现,为用户带来连贯、自然的语音体验。
三、技术揭秘
(一)深度学习模型架构
Qwen3-TTS-Flash 的技术架构基于深度学习,采用文本编码器、语音解码器和注意力机制的组合。文本编码器负责将输入文本转换为语义表示,提取文本的关键信息和语义特征;语音解码器则根据文本编码器的输出生成语音波形,确保语音的自然度和表现力;注意力机制通过更好地对齐文本和语音,提高生成语音的准确性和流畅性。
(二)多语言和多方言支持技术
模型在多种语言和方言的数据上进行训练,学习不同语言和方言的发音特点和语调规律。通过音色嵌入技术,模型能生成不同音色的语音,同时保持同一音色在不同语言中的一致性。这种技术使得 Qwen3-TTS-Flash 能够在多语言和多方言的语音合成中表现出色,为用户提供高质量的语音服务。
(三)高鲁棒性技术
对输入文本进行预处理,包括分词、词性标注、语义解析等,确保模型能正确理解文本内容。模型还具备自动处理复杂文本和错误文本的能力,能抽取关键信息,生成准确的语音。这种高鲁棒性技术使得 Qwen3-TTS-Flash 能够在各种复杂的文本场景下稳定运行,提供可靠的语音合成服务。
四、性能表现
官方团队对Qwen3-TTS-Flash在语音稳定性和音色相似度方面进行了全面评估,结果显示其在多项指标上都达到了SOTA性能。具体来说,在seed-tts-eval test set上,Qwen3-TTS-Flash在中英文的语音稳定性表现上均取得了SOTA成绩,超越了SeedTTS、MiniMax和GPT-4o-Audio-Preview。此外,在MiniMax TTS multilingual test set上,Qwen3-TTS-Flash在中文、英文、意大利语和法语的WER均达到了SOTA,显著低于MiniMax、ElevenLabs和GPT-4o-Audio-Preview。在说话人相似度方面,Qwen3-TTS-Flash在英文、意大利语和法语均超过了上述模型,在多语言的语音稳定性和音色相似度上展现出了卓越的表现。
五、应用场景
(一)智能客服
Qwen3-TTS-Flash 可以为用户提供自然流畅的语音交互,提升服务体验。在智能客服领域,模型能够自动回答常见问题、引导用户操作,为用户提供高效、便捷的语音服务,降低人工客服的工作负担,提高客户服务效率。
(二)有声读物
该模型能够将文字内容转化为生动的语音,让听众享受听书的乐趣。适用于小说、新闻、教材等多种内容,为用户提供了全新的阅读体验,尤其对于视力不佳或不方便阅读的人群来说,有声读物成为了获取知识和娱乐的重要方式。
(三)语音助手
在智能家居、智能穿戴等设备中,Qwen3-TTS-Flash 可以提供语音交互功能,方便用户控制设备和获取信息。用户可以通过语音指令操作家电设备、查询天气信息、设置提醒事项等,极大地提高了生活的便利性和智能化程度。
(四)教育领域
Qwen3-TTS-Flash 辅助教学,为学生提供多语言、多音色的语音讲解,帮助用户更好地学习语言和知识。在语言教学中,模型可以模拟不同语言的发音和语调,为学生提供真实的语言学习环境,提高学习效果;在其他学科教学中,模型可以通过语音讲解帮助学生更好地理解和掌握知识,丰富教学手段。
(五)娱乐产业
该模型可以用在动画、游戏、影视等制作,为角色配音,创造更具感染力的声音效果。在动画和游戏中,模型可以为虚拟角色生成自然、生动的语音,增强角色的个性和故事的吸引力;在影视制作中,模型可以用于配音工作,为演员提供备用配音方案,提高制作效率和质量。
六、快速使用
(一)在线体验
用户可以通过访问 Qwen3-TTS-Flash 的在线 Demo 页面(https://huggingface.co/spaces/Qwen/Qwen3-TTS-Demo),输入文本内容,选择音色和语言,点击“生成”即可获取语音。支持实时播放和下载生成的音频文件。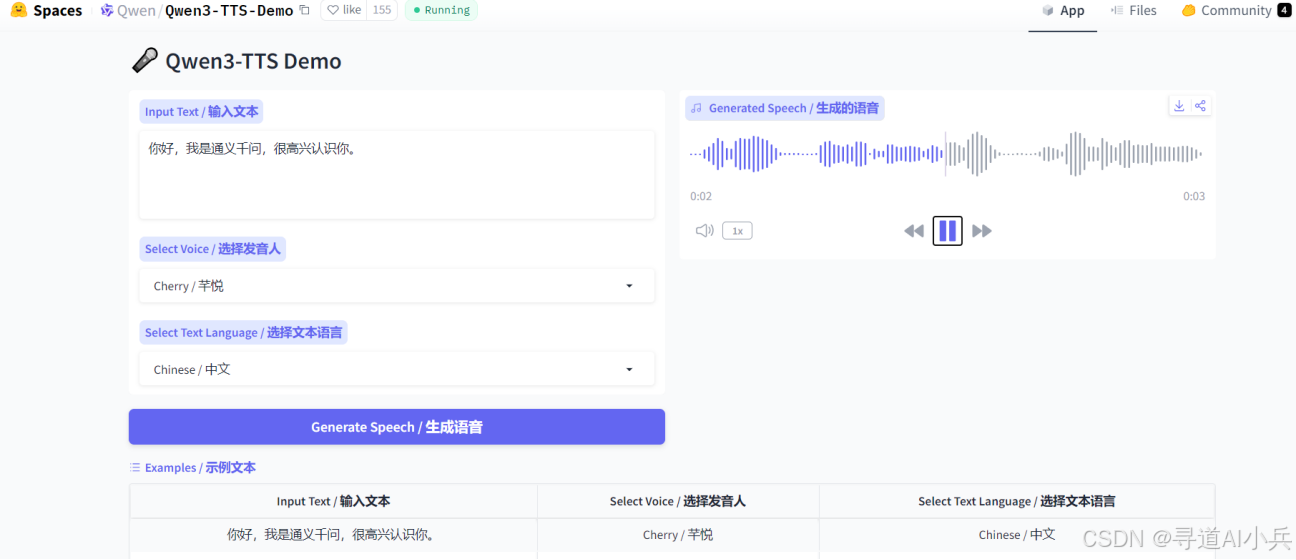
(二)API 调用
通过阿里云百炼平台开通 Qwen3-TTS 服务,获取 API Key。使用 HTTP 请求发送文本和参数(如音色、语言),获取生成的语音 URL。
# 请安装 DashScope SDK 的最新版本
import os
import requests
import dashscope
text = "那我来给大家推荐一款T恤,这款呢真的是超级好看,这个颜色呢很显气质,而且呢也是搭配的绝佳单品,大家可以闭眼入,真的是非常好看,对身材的包容性也很好,不管啥身材的宝宝呢,穿上去都是很好看的。推荐宝宝们下单哦。"
# SpeechSynthesizer接口使用方法:dashscope.audio.qwen_tts.SpeechSynthesizer.call(...)
response = dashscope.MultiModalConversation.call(
model="qwen3-tts-flash",
api_key=os.getenv("DASHSCOPE_API_KEY"),
text=text,
voice="Cherry",
language_type="Chinese", # 建议与文本语种一致,以获得正确的发音和自然的语调。
stream=False
)
audio_url = response.output.audio.url
save_path = "downloaded_audio.wav" # 自定义保存路径
try:
response = requests.get(audio_url)
response.raise_for_status() # 检查请求是否成功
with open(save_path, 'wb') as f:
f.write(response.content)
print(f"音频文件已保存至:{save_path}")
except Exception as e:
print(f"下载失败:{str(e)}")
七、结语
Qwen3-TTS-Flash 作为阿里通义推出的旗舰级语音合成模型,凭借其多音色、多语言和多方言的支持能力,以及高效的语音生成性能和卓越的音色表现力,在语音合成领域展现出了强大的竞争力。无论是在智能客服、有声读物、语音助手、教育领域还是娱乐产业,Qwen3-TTS-Flash 都能够为用户提供高质量的语音合成服务,满足多样化的语言需求。随着技术的不断进步和应用场景的不断拓展,Qwen3-TTS-Flash 将在更多领域发挥重要作用,为人们的生活和工作带来更多的便利和创新体验。更多关于 Qwen3-TTS-Flash 的信息,可以访问以下项目地址:
八、项目地址
- 项目官网:https://qwen.ai/blog?id=b4264e11fb80b5e37350790121baf0a0f10daf82&from=research.latest-advancements-list
- 在线体验 Demo:https://huggingface.co/spaces/Qwen/Qwen3-TTS-Demo

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)