昇腾Atlas加速卡与Ascend C:从硬件基石到编程哲学的深度解析与实战
本文深入解析华为昇腾Atlas加速卡的达芬奇架构及AscendC编程模型。通过对比CUDA,揭示AscendC"显式并行、软硬协同"的设计哲学,重点剖析Cube/Vector计算单元协同机制及多级存储体系。结合EmbeddingDenseGrad算子开发案例,详解原子操作解决数据竞争的关键技术,并分享InternVL大模型适配中的算子融合等优化经验。文章指出,尽管AscendC
目录
3. Ascend C编程范式:一种“工匠式”的并行编程艺术
4. 实战深潜:从PPT案例解读EmbeddingDenseGrad算子开发
摘要
本文深入剖析了华为昇腾(Ascend)Atlas 300I/V Pro加速卡的达芬奇(Da Vinci)架构设计理念,及其专用编程语言Ascend C的核心哲学。文章不仅从硬件微架构层面解析AI Core中Cube/Vector Unit的协同机制,更从编程范式上对比了Ascend C与CUDA的异同,揭示了其“显式并行、软硬协同”的设计思想。通过解读PPT中的
EmbeddingDenseGrad算子开发实例,并结合InternVL大模型适配的实战经验,文章将提供从原理到高级优化的全链路深度解析,为开发者切入异构计算新赛道提供硬核指南。
1. 引子:我们为何需要“另一种”AI芯片和编程模型?
干了这行十多年,我亲眼见证了AI计算从CPU到GPGPU的跃迁。今天,当我们谈论大模型训练时,动辄需要成千上万张卡,电费和维护成本成了不可忽视的“大象”。这时,一个问题自然浮现:在NVIDIA的CUDA生态几乎一统江湖的今天,为什么我们还需要像华为昇腾这样的NPU(Neural Processing Unit)和Ascend C这样的编程模型?
答案的核心在于 “专用化”带来的极致能效比。通用GPU(GPGPU)的强大在于其灵活性,但这也意味着大量晶体管和功耗被用于支撑其通用性,而非完全用于AI计算。NPU,如同ASIC之于通用CPU,是为AI计算负载量身定制的。这带来的直接好处是,在完成相同AI计算任务时,NPU通常拥有更高的TOPS(每秒万亿次操作)和更低的功耗。
但天下没有免费的午餐。专用化带来的挑战是编程模型的颠覆。从熟悉的CUDA切换到Ascend C,不仅仅是API的变换,更是从“隐式”并行到“显式”管理的思维转变。接下来,让我们剥茧抽丝,从基石开始。
2. 昇腾Atlas加速卡硬件架构:达芬奇核心的匠心独运
Atlas 300I/V Pro加速卡的核心是昇腾AI处理器。要理解Ascend C,必须先理解它所要驱动的硬件。其计算核心的架构可以用下图清晰地展示其层级和数据流:
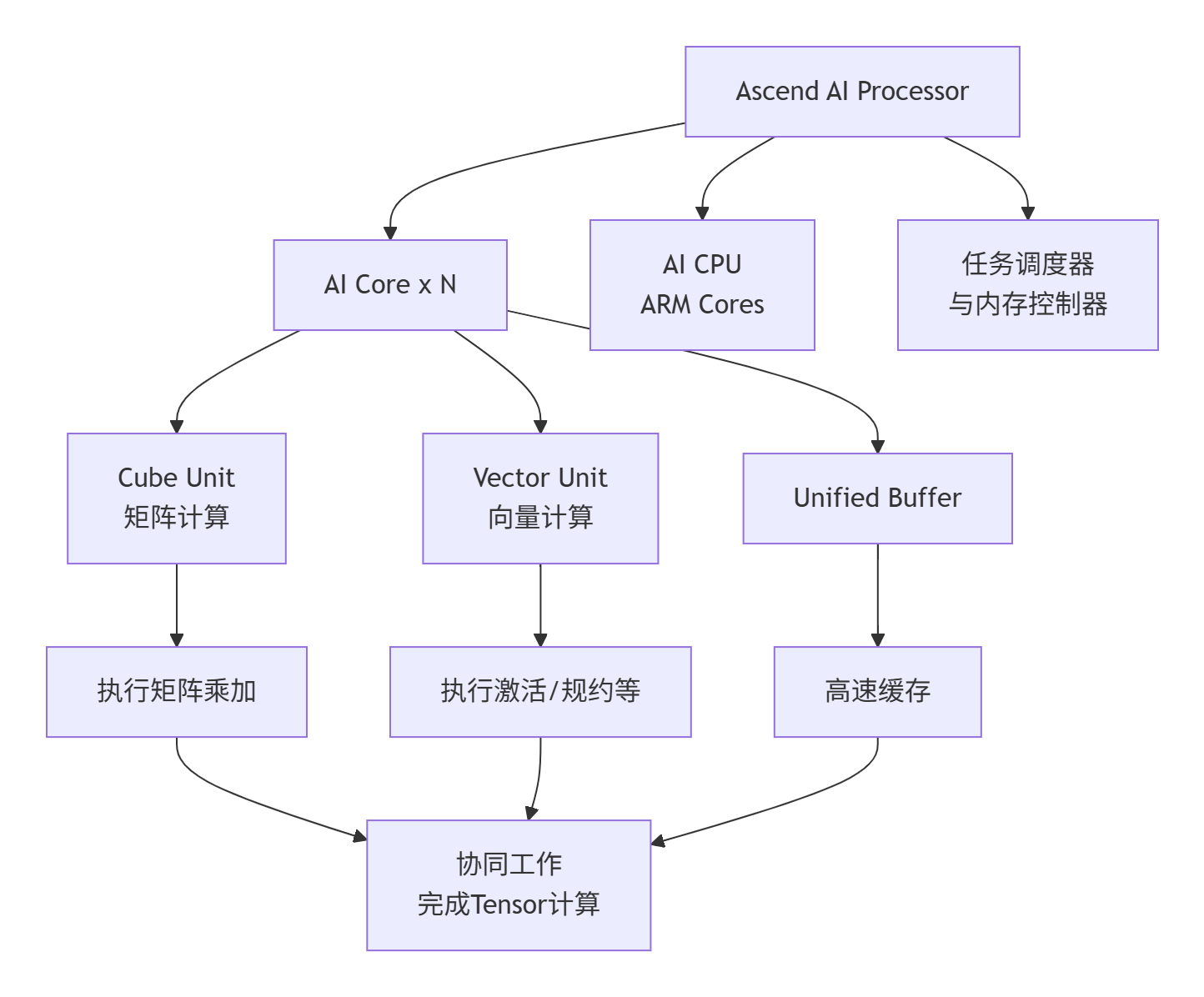
1. AI Core:算力引擎
这是达芬奇架构的灵魂,专门为张量计算而生。它与GPU的SM(Streaming Multiprocessor)概念类似,但内部结构差异巨大。
-
Cube Unit(立方计算单元):这是昇腾芯片的“杀手锏”。它不像GPU的CUDA Core那样以标量或矢量方式计算,而是直接以小块矩阵为基本单位进行乘加运算。这意味着对于FP16数据,它可以一次性完成一个16x16x16的矩阵块计算,为密集的矩阵乘法(MatMul)和卷积(Convolution)提供骇人的吞吐量。这是其高算力(TOPS)的直接来源。
-
Vector Unit(矢量计算单元):负责处理Cube Unit不擅长的“零散”计算,如激活函数(ReLU, GeLU)、归一化(LayerNorm)、以及各种逐元素(Element-wise)操作。它可以看作是Cube Unit的“最佳搭档”。
2. 多级存储体系:性能的生命线
这是Ascend C编程中需要显式管理的部分,也是性能优化的主战场。
-
外部内存(External Memory / Global Memory):即加速卡上的HBM或GDDR,容量大(数十GB),但延迟高。对应Ascend C中的
__gm__地址空间。 -
统一缓冲区(Unified Buffer, UB):AI Core上的片上高速缓存,相当于GPU的Shared Memory+L1 Cache,但容量更大(以MB计)。它是编程中可直接操作的高速暂存区。对应
__ub__地址空间。PPT素材中反复强调的“32Byte对齐”主要就是针对UB的访问。 -
L0 Buffer:更靠近计算单元的超高速缓存,通常对程序员透明或部分可控,访问粒度更细(64Byte对齐)。
3. AI CPU与控制核心
通常为ARM架构的CPU核心,负责处理控制逻辑复杂、并行度不高的任务,如整个计算任务的调度、复杂条件判断等。
与GPU架构对比,一个核心思想是:GPU通过复杂的硬件逻辑(如Warp Scheduler、Cache Hierarchy)来简化编程模型(让程序员感觉在写串行代码),而昇腾NPU则将部分控制权和责任交还给程序员,通过更“简单”但更“直接”的硬件,换取更高的效率和灵活性。 这就是Ascend C编程哲学的硬件根源。
3. Ascend C编程范式:一种“工匠式”的并行编程艺术
如果说CUDA编程像是开自动挡汽车,那么早期的Ascend C编程就更像是开手动挡赛车。你需要自己换挡(管理数据搬运)、控制油门和离合(组织流水线),但一旦精通,就能跑出更快的圈速。
核函数:执行的基本单位
一个Ascend C程序由核函数(Kernel Function) 组成。一个Kernel被加载到AI Core上执行。
// 一个典型的Ascend C核函数声明
extern "C" __global__ __aicore__ void my_custom_kernel(
uint8_t* input1, // 指向Global Memory的输入指针
uint8_t* input2,
uint8_t* output,
int32_t total_length
) {
// ... 核函数体
}-
__global__:表明这是一个核函数。 -
__aicore__:表明这个函数用于在AI Core上执行。
任务划分与流水线
当Kernel启动时,会并行启动多个计算单元(计算核)。每个核处理总数据的一部分。其核心执行流程体现了经典的“生产者-消费者”流水线模型,如下图所示:
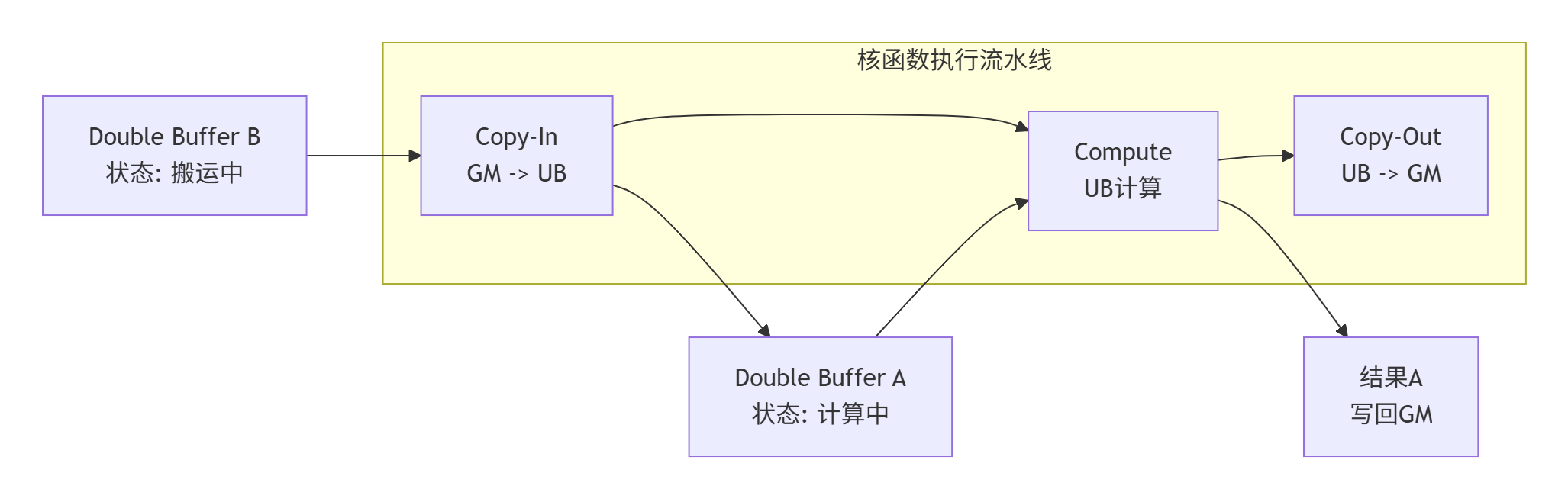
图示:基于Double Buffer的“搬运-计算”重叠流水线
-
数据搬运(Copy-In):这是流水线的第一阶段。程序员需要显式地使用
DataCopy之类的接口,将当前计算所需的数据块从低速的Global Memory搬运到高速的UB中。这里必须遵守PPT素材中强调的“32字节对齐”约束,否则会导致性能劣化甚至错误。 -
计算(Compute):数据在UB中就绪后,调用相应的计算API(如基于Cube Unit的
mad接口做矩阵乘,或基于Vector Unit的接口做逐元素计算)进行处理。 -
结果写回(Copy-Out):将UB中的计算结果再搬回Global Memory。
为了隐藏数据搬运的漫长延迟,Ascend C强烈推荐使用Double Buffer技术。即为UB分配两块缓冲区(Buffer A和Buffer B)。当计算单元在处理Buffer A中的数据时,DMA(直接内存访问)控制器同时在为Buffer B搬运下一批数据。这样,计算和搬运得以并行,极大地提升了硬件利用率。
与CUDA的直观对比
为了让有CUDA背景的读者快速理解,我做一个简单的对比:
|
特性 |
CUDA |
Ascend C |
核心差异 |
|---|---|---|---|
|
并行模型 |
网格-块-线程 |
块-任务 |
Ascend C的Task粒度更粗,通常一个Task处理一个数据块 |
|
内存管理 |
自动缓存(L1/L2) + 可选的Shared Memory |
显式管理UB |
Ascend C要求程序员显式控制数据在GM和UB间的流动 |
|
同步方式 |
|
内置同步机制或通过流水线阶段控制 |
思维从“线程级同步”转向“任务级/数据流同步” |
|
编程思维 |
如何让成千上万的线程高效协作 |
如何为单个计算核组织好“搬运-计算-写回”的流水线 |
从“线程视角”切换到“核函数视角” |
我的判断:这种显式管理模型,在初期学习曲线确实陡峭,但一旦掌握,对于性能的预测和控制力更强。你非常清楚你的数据在哪、何时在移动、何时在计算。这在优化极端性能敏感的操作时,是一个优势。
4. 实战深潜:从PPT案例解读EmbeddingDenseGrad算子开发
现在,我们结合您提供的第二张PPT素材,来剖析一个真实算子的开发。这个算子是在大模型训练中非常关键的EmbeddingDenseGrad,用于在反向传播中计算嵌入层(Embedding Layer)的梯度。
问题定义与挑战
-
数学逻辑:给定上游传来的梯度
grad和对应的索引indices,将grad中每个向量累加到输出梯度output_grad中由indices指定的行上。 -
核心挑战:数据竞争(Data Race)。如果多个索引指向同一行(这在自然语言中非常常见,例如同一个单词出现多次),多个计算核(或多次计算)会同时尝试更新
output_grad的同一行,造成结果错误。
Ascend C实现的关键步骤
PPT素材中的代码片段展示了解决这一问题的核心——原子操作(Atomic Operation)。
1. 核函数与任务划分
// 伪代码,体现核心逻辑
__global__ __aicore__ void embedding_dense_grad_kernel(
const float* grad, // 输入梯度,形状为 [num_indices, embedding_dim]
const int32_t* indices, // 输入索引,形状为 [num_indices]
float* output_grad, // 输出梯度,形状为 [vocab_size, embedding_dim]
int64_t num_indices,
int64_t embedding_dim,
int64_t vocab_size
) {
int32_t task_id = get_block_idx(); // 当前任务ID
int32_t task_num = get_block_dim(); // 总任务数
// 计算当前任务负责的索引范围
int64_t indices_per_task = (num_indices + task_num - 1) / task_num;
int64_t start = task_id * indices_per_task;
int64_t end = min(start + indices_per_task, num_indices);
}2. UB中申请对齐内存与数据搬运
// 在UB中为当前批次的索引和梯度数据申请空间,注意对齐
__ub__ int32_t* ub_indices = (__ub__ int32_t*)__builtin_acl_ub_malloc(indices_per_task * sizeof(int32_t), 32);
__ub__ float* ub_grad = (__ub__ float*)__builtin_acl_ub_malloc(indices_per_task * embedding_dim * sizeof(float), 32);
// 使用DataCopy将Global Memory中[start, end)范围的数据拷贝到UB
// 这里应该使用Double Buffer实现流水线,为简化示例,此处省略3. 核心计算循环与原子累加
这是算子的灵魂所在。
for (int64_t i = 0; i < (end - start); ++i) {
int32_t idx = ub_indices[i]; // 当前处理的索引值
// 检查索引合法性
if (idx < 0 || idx >= vocab_size) {
// 错误处理...
continue;
}
// 计算当前梯度向量在output_grad中的起始地址
float* row_addr = output_grad + idx * embedding_dim;
// 当前要累加的梯度向量在UB中的起始地址
float* grad_vec_addr = ub_grad + i * embedding_dim;
// 关键!使用原子加操作,将grad_vec_addr开始的embedding_dim个float元素
// 原子地累加到row_addr指向的内存区域。
// 这确保了即使多个task同时更新同一行,结果也是正确的。
atomic_add(row_addr, grad_vec_addr, embedding_dim);
}-
atomic_add:这个操作是硬件保证的原子性操作。它意味着对同一目标地址的“读-改-写”过程是不可分割的,从而彻底避免了数据竞争。PPT素材中的代码核心就是在展示这一机制。
我的经验:在早期版本中,原子操作可能会有性能开销。需要评估索引的冲突程度。如果冲突非常严重,可能需要考虑其他优化,比如先局部归并再全局更新。但对于像EmbeddingDenseGrad这种典型负载,直接使用向量化的原子操作是最直接有效的方式。
5. 企业级实践:从InternVL适配看大模型训练优化
第一张PPT提到了华中科技大学团队在Atlas 300I/V Pro上对InternVL这类大型视觉-语言模型进行训练适配的进展。这提供了一个绝佳的企业级实践视角。
面临的挑战
-
算子覆盖度:像InternVL这样的SOTA模型,会使用一些非标准或较新的算子。昇腾AI计算架构(CANN)的算子库可能未能100%覆盖,需要自定义开发(正如PPT中“算子开发经验分享”部分所示)。
-
资源瓶颈:大模型对显存(NPU内存)、CPU内存、主机-设备通信带宽都构成巨大压力。PPT中提到了“CPU”、“内存”等资源成为瓶颈。
-
训练稳定性:在新硬件上确保混合精度训练(FP16/BF16)的稳定性,避免梯度溢出/下溢,是一个关键挑战。
解决方案与优化技巧
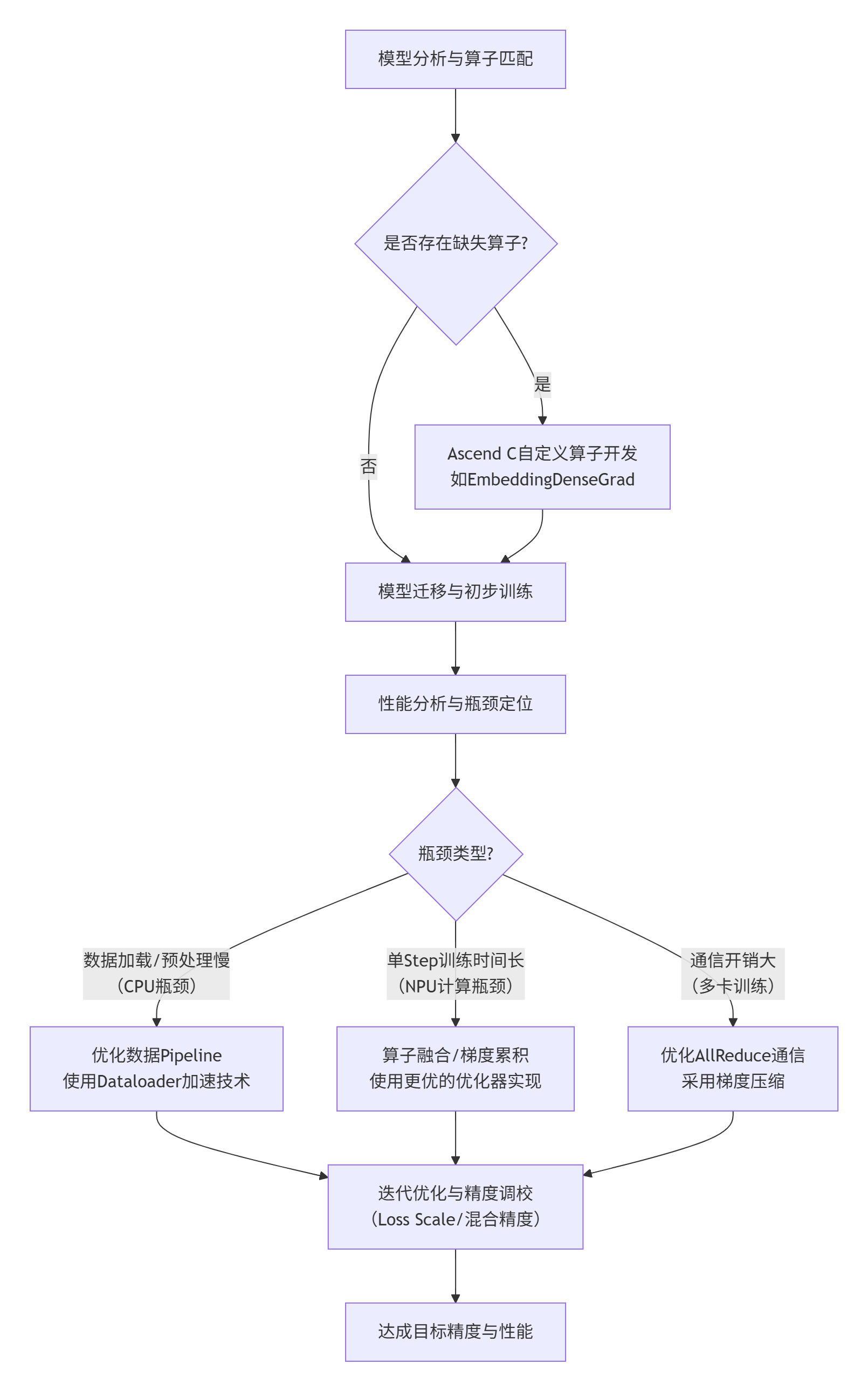
基于PPT的提示和我的经验,适配优化流程大致如下:
-
使用LAMA Factory等迁移工具:PPT中提到“基于LAMA Factory实现”,这类工具可以自动化大部分模型转换和迁移工作,大大降低入门门槛。
-
性能分析与
msprof工具:华为提供了性能分析工具msprof,它可以生成类似Nsight Systems的时间线图,帮助定位是数据加载、NPU计算还是通信占了主导,从而进行针对性优化。 -
高级优化技巧:
-
算子融合:将多个小算子(如:Scale + Softmax + Mask)融合成一个大的核函数,减少Kernel启动开销和中间结果写回GM的开销。
-
梯度累积:在内存受限时,通过累积多个小批次的梯度再更新权重,来模拟更大的批处理大小(Batch Size)。
-
动态Loss Scale:在混合精度训练中,动态调整损失缩放因子,是保证训练稳定性的不二法门。
-
6. 总结与前瞻
昇腾Atlas加速卡和Ascend C代表了一条不同于CUDA的AI计算路径。它通过软硬协同的深度优化,在特定领域展现了巨大的能效潜力。对于开发者而言,学习Ascend C不仅是学习一门新的语言,更是对并行计算本质的更深层次理解。
-
核心要点回顾:
-
硬件基石:达芬奇架构通过Cube/Vector Unit的分工,高效处理张量计算。
-
编程哲学:Ascend C的“显式并行、显式管理”模型,赋予开发者极高的控制力,以换取极致性能。
-
实战关键:理解内存体系、掌握流水线(尤其是Double Buffer)、善用原子操作等同步原语,是高效开发的核心。
-
生态现状:工具链(如LAMA Factory、msprof)正在快速成熟,但在算子覆盖度和社区资源上,仍需时日追赶CUDA生态。
-
-
前瞻性思考:
-
编程模型会如何演化? 当前的Ascend C对专家友好,但门槛高。未来是否会推出更高级别的抽象(如类似Triton的DSL),在保持性能的同时降低开发难度?
-
通用性与专用性如何平衡? 随着AI模型范式的快速演变(如MoE、State Space Model),NPU的架构是否需要引入更多灵活性?这将如何影响编程模型?
-
异构计算架构的未来:CPU、GPU、NPU共存的异构系统将成为常态。如何设计统一的编程接口或运行时,让开发者能无缝地、高效地利用所有计算资源,是整个行业面临的大课题。
-
这条路充满挑战,但也充满机遇。对于有志于在AI基础设施领域深耕的开发者来说,现在正是深入探索昇腾生态和Ascend C的最佳时机。
参考链接
-
昇腾社区官方文档:最权威的开发者文档、API参考和教程入口。
-
CANN 软件开发文档:特别是《Ascend C编程指南》和《性能调优指南》。
-
LAMA Factory GitHub Repository:一个强大的大模型微调框架,支持昇腾平台。
-
论文: A Study of AI Accelerator Architectures: A Perspective from Deep Learning Benchmarks:提供了对不同AI加速器架构的学术视角对比。
-
华为昇腾开发者论坛:与社区开发者交流实战问题的最佳场所。
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)