DailyCoding 点云配准库 fast_gicp库代码详解 |(一)VGICP代码调用顺序与核心原理讲解
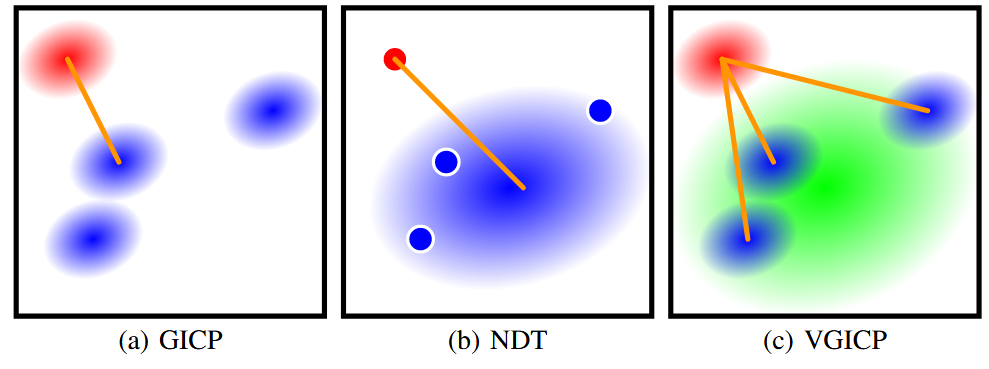
VGICP(Voxelized GICP)是一种高效的点云配准算法,其核心流程包括:1)初始化阶段设置目标/源点云并构建体素地图;2)配准阶段通过迭代优化求解位姿变换。核心创新在于使用体素化匹配替代传统点对点匹配,每个源点可对应多个目标体素(1/7/27个),提高了鲁棒性。关键函数包括update_correspondences()实现体素对应关系更新,linearize()计算Hessian矩阵
VGICP代码调用顺序与核心原理详解
一、VGICP代码调用顺序
1.1 主要调用流程
用户代码 (align.cpp) ↓ vgicp.setInputTarget(target_cloud) // 设置目标点云 ↓ vgicp.setInputSource(source_cloud) // 设置源点云 ↓ vgicp.align(*aligned) // 执行配准 ↓ computeTransformation(output, guess) // 继承自LsqRegistration ↓ [迭代优化循环] ├─ step_optimize() // LM或GN优化步骤 │ ├─ linearize() // 线性化,计算H和b │ │ ├─ update_correspondences() // 更新对应关系 │ │ └─ 计算雅可比和误差 │ └─ compute_error() // 计算误差 └─ is_converged() // 检查收敛
1.2 详细调用链
初始化阶段
// 1. 创建VGICP对象
FastVGICP<pcl::PointXYZ, pcl::PointXYZ> vgicp;
vgicp.setResolution(1.0); // 设置体素分辨率
// 2. 设置目标点云
vgicp.setInputTarget(target_cloud);
→ FastGICP::setInputTarget() // 父类方法
→ search_target_->setInputCloud(cloud)
→ target_covs_.clear()
→ voxelmap_.reset() // VGICP特有:重置体素地图
// 3. 设置源点云
vgicp.setInputSource(source_cloud);
→ FastGICP::setInputSource()
→ search_source_->setInputCloud(cloud)
→ source_covs_.clear()配准阶段
// 4. 执行配准
vgicp.align(*aligned);
→ LsqRegistration::computeTransformation()
→ [迭代循环]
→ step_optimize() // LM或GN优化
→ linearize() // VGICP重写的linearize()
→ 创建/获取体素地图 (voxelmap_)
→ update_correspondences() // 更新对应关系
→ 计算Hessian矩阵H和梯度向量b
→ compute_error() // 计算误差
→ is_converged() // 检查收敛二、核心函数原理
2.1 update_correspondences() - 更新对应关系
VGICP的核心创新:使用体素地图而非点对点匹配
void FastVGICP::update_correspondences(const Eigen::Isometry3d& trans) {
// 1. 获取邻域搜索偏移量(DIRECT1/DIRECT7/DIRECT27)
auto offsets = neighbor_offsets(search_method_);
// 2. 对每个源点,查找其变换后在目标体素地图中的对应体素
for (int i = 0; i < input_->size(); i++) {
Eigen::Vector4d transed_mean_A = trans * mean_A;
Eigen::Vector3i coord = voxelmap_->voxel_coord(transed_mean_A);
// 3. 检查当前体素及其邻域体素(1/7/27个)
for (const auto& offset : offsets) {
auto voxel = voxelmap_->lookup_voxel(coord + offset);
if (voxel != nullptr) {
voxel_correspondences_.push_back({i, voxel});
}
}
}
// 4. 预计算组合协方差矩阵的逆(Mahalanobis距离)
for (int i = 0; i < voxel_correspondences_.size(); i++) {
Eigen::Matrix4d RCR = cov_B + trans.matrix() * cov_A * trans.matrix().transpose();
voxel_mahalanobis_[i] = RCR.inverse();
}
}关键点:
-
体素化:将目标点云组织成体素地图,每个体素包含多个点的统计信息(均值、协方差)
-
多对应关系:一个源点可以对应多个体素(1/7/27个),增加鲁棒性
-
预计算:Mahalanobis矩阵在对应关系更新时预计算,避免重复计算
2.2 linearize() - 线性化函数(计算H和b)
double FastVGICP::linearize(const Eigen::Isometry3d& trans,
Eigen::Matrix<double, 6, 6>* H,
Eigen::Matrix<double, 6, 1>* b) {
// 1. 首次调用时创建体素地图
if (voxelmap_ == nullptr) {
voxelmap_.reset(new GaussianVoxelMap<PointTarget>(voxel_resolution_, voxel_mode_));
voxelmap_->create_voxelmap(*target_, target_covs_);
}
// 2. 更新对应关系
update_correspondences(trans);
// 3. 对每个对应关系计算误差和雅可比
for (int i = 0; i < voxel_correspondences_.size(); i++) {
const auto& corr = voxel_correspondences_[i];
Eigen::Vector4d error = mean_B - transed_mean_A;
// 4. 加权误差(权重 = sqrt(体素中的点数))
double w = std::sqrt(target_voxel->num_points);
sum_errors += w * error.transpose() * voxel_mahalanobis_[i] * error;
// 5. 计算雅可比矩阵
Eigen::Matrix<double, 4, 6> dtdx0;
dtdx0.block<3, 3>(0, 0) = skewd(transed_mean_A.head<3>()); // 旋转部分
dtdx0.block<3, 3>(0, 3) = -Eigen::Matrix3d::Identity(); // 平移部分
// 6. 累加Hessian和梯度
Hi = w * jlossexp.transpose() * voxel_mahalanobis_[i] * jlossexp;
bi = w * jlossexp.transpose() * voxel_mahalanobis_[i] * error;
}
return sum_errors;
}2.3 体素地图创建 (create_voxelmap)
void GaussianVoxelMap::create_voxelmap(const PointCloud& cloud,
const std::vector<Matrix4d>& covs) {
// 1. 将点云分配到体素
for (int i = 0; i < cloud.size(); i++) {
Eigen::Vector3i coord = voxel_coord(cloud.at(i));
auto voxel = lookup_or_create_voxel(coord);
// 2. 根据模式累加(ADDITIVE或MULTIPLICATIVE)
voxel->append(mean, cov);
}
// 3. 最终化:计算每个体素的均值和协方差
for (auto& voxel : voxels_) {
voxel.second->finalize();
}
}体素累加模式:
-
ADDITIVE:简单平均
mean = Σmean_i / N,cov = Σcov_i / N -
MULTIPLICATIVE:信息融合
cov = (Σcov_i^-1)^-1,mean = cov * (Σcov_i^-1 * mean_i)
三、VGICP与GICP的代价函数对比
3.1 GICP的代价函数
// GICP: 点对点匹配
for (int i = 0; i < input_->size(); i++) {
int target_index = correspondences_[i]; // 1对1对应
Eigen::Vector4d error = mean_B - transed_mean_A;
// 无权重,直接使用Mahalanobis距离
sum_errors += error.transpose() * mahalanobis_[i] * error;
// 雅可比计算
Hi = jlossexp.transpose() * mahalanobis_[i] * jlossexp;
bi = jlossexp.transpose() * mahalanobis_[i] * error;
}GICP特点:
-
点对点匹配:每个源点对应一个最近的目标点
-
无权重:所有对应关系权重相同
-
Mahalanobis距离:
RCR = cov_B + R*cov_A*R^T,考虑两个点的协方差
3.2 VGICP的代价函数
// VGICP: 点对体素匹配
for (int i = 0; i < voxel_correspondences_.size(); i++) {
const auto& corr = voxel_correspondences_[i];
auto target_voxel = corr.second; // 体素而非单个点
Eigen::Vector4d error = mean_B - transed_mean_A;
// 加权误差:权重 = sqrt(体素中的点数)
double w = std::sqrt(target_voxel->num_points);
sum_errors += w * error.transpose() * voxel_mahalanobis_[i] * error;
// 加权雅可比
Hi = w * jlossexp.transpose() * voxel_mahalanobis_[i] * jlossexp;
bi = w * jlossexp.transpose() * voxel_mahalanobis_[i] * error;
}VGICP特点:
-
点对体素匹配:源点对应目标体素(包含多个点的统计信息)
-
加权优化:权重 =
sqrt(体素点数),体素中点数越多权重越大 -
多对应关系:一个源点可以对应多个体素(1/7/27个),提高鲁棒性
-
体素协方差:体素的协方差融合了多个点的信息,更稳定
3.3 关键差异总结
| 特性 | GICP | VGICP |
|---|---|---|
| 对应关系 | 点↔点 (1对1) | 点↔体素 (1对多) |
| 权重 | 无权重 | w = sqrt(体素数) |
| 匹配方式 | KDTree最近邻搜索 | 体素坐标查找 |
| 协方差 | 单点协方差 | 体素融合协方差 |
| 计算复杂度 | O(N log N) | O(N) |
| 鲁棒性 | 中等 | 高(多对应关系) |
四、雅可比矩阵求解
4.1 雅可比矩阵的推导
VGICP使用李代数参数化,将6DOF位姿表示为 ξ = [ω, t],其中:
-
ω ∈ R³:旋转(角速度) -
t ∈ R³:平移
误差函数:
e(ξ) = mean_B - T(ξ) * mean_A
雅可比矩阵(误差对位姿参数的导数):
Eigen::Matrix<double, 4, 6> dtdx0;
// 旋转部分:∂(R*p)/∂ω = -[R*p]× (反对称矩阵)
dtdx0.block<3, 3>(0, 0) = skewd(transed_mean_A.head<3>());
// 平移部分:∂(R*p + t)/∂t = -I
dtdx0.block<3, 3>(0, 3) = -Eigen::Matrix3d::Identity();skewd函数(反对称矩阵):
skewd([x, y, z]) = [ 0 -z y ]
[ z 0 -x ]
[-y x 0 ]
4.2 Hessian矩阵和梯度向量
Hessian矩阵(二阶导数,用于GN/LM优化):
H = Σ w_i * J_i^T * M_i * J_i
其中:
-
J_i = dtdx0:雅可比矩阵 (4×6) -
M_i = voxel_mahalanobis_[i]:Mahalanobis矩阵 (4×4) -
w_i = sqrt(体素数):权重
梯度向量(一阶导数):
b = Σ w_i * J_i^T * M_i * e_i
其中 e_i = mean_B - transed_mean_A 是误差向量
4.3 优化求解
Gauss-Newton方法:
H * Δξ = -b Δξ = -H^(-1) * b T_new = exp(Δξ) * T_old
Levenberg-Marquardt方法(更鲁棒):
(H + λ*I) * Δξ = -b
通过调整λ(阻尼因子)来控制步长,避免发散。
五、setNearestNeighborSearchMethod的区别
5.1 方法概述
setNearestNeighborSearchMethod 是 FastVGICPCuda 特有的方法,用于选择协方差估计时的最近邻搜索方法。
注意:这与 setNeighborSearchMethod(体素对应关系搜索)不同!
5.2 三种方法详解
方法1: CPU_PARALLEL_KDTREE(默认)
case NearestNeighborMethod::CPU_PARALLEL_KDTREE: {
// 使用CPU并行KDTree查找每个点的k个最近邻
std::vector<int> neighbors = find_neighbors_parallel_kdtree(k, cloud);
vgicp_cuda_->set_source_neighbors(k, neighbors);
vgicp_cuda_->calculate_source_covariances(regularization_method_);
}实现:
std::vector<int> find_neighbors_parallel_kdtree(int k, PointCloud cloud) {
pcl::search::KdTree kdtree;
kdtree.setInputCloud(cloud);
#pragma omp parallel for
for (int i = 0; i < cloud->size(); i++) {
kdtree.nearestKSearch(cloud->at(i), k, k_indices, k_sq_dists);
// 存储k个最近邻索引
}
}特点:
-
✅ 准确:使用精确的KDTree搜索
-
✅ 快速:现代CPU上通常比GPU暴力搜索更快
-
✅ 并行化:OpenMP并行处理
-
⚠️ 需要CPU资源:依赖CPU性能
方法2: GPU_BRUTEFORCE
case NearestNeighborMethod::GPU_BRUTEFORCE:
// GPU上暴力搜索每个点的k个最近邻
vgicp_cuda_->find_source_neighbors(k_correspondences_);
vgicp_cuda_->calculate_source_covariances(regularization_method_);
break;特点:
-
✅ GPU加速:利用GPU并行计算能力
-
✅ 适合弱CPU:CPU性能较弱但GPU较强的场景(如NVIDIA Jetson)
-
⚠️ 计算量大:O(N²)复杂度,但GPU并行化后仍较快
-
⚠️ 需要GPU:必须有CUDA支持
方法3: GPU_RBF_KERNEL
case NearestNeighborMethod::GPU_RBF_KERNEL:
// 使用RBF(径向基函数)核直接估计协方差
vgicp_cuda_->calculate_source_covariances_rbf(regularization_method_);
break;特点:
-
✅ 极快:不需要搜索最近邻,直接基于RBF核计算
-
✅ GPU加速:完全在GPU上执行
-
⚠️ 可能不够准确:近似方法,精度可能略低
-
⚠️ 需要调参:需要设置合适的kernel_width
RBF核方法原理:
-
使用径向基函数(如高斯核)直接估计点的局部协方差
-
不需要显式查找最近邻,通过核函数权重计算
5.3 方法对比表
| 方法 | 精度 | 速度 | 适用场景 | 依赖 |
|---|---|---|---|---|
| CPU_PARALLEL_KDTREE | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 现代CPU | CPU + OpenMP |
| GPU_BRUTEFORCE | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 弱CPU+强GPU | CUDA GPU |
| GPU_RBF_KERNEL | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 实时性要求高 | CUDA GPU |
5.4 使用建议
// 默认推荐(现代CPU)
vgicp_cuda.setNearestNeighborSearchMethod(
fast_gicp::NearestNeighborMethod::CPU_PARALLEL_KDTREE
);
// Jetson等嵌入式设备
vgicp_cuda.setNearestNeighborSearchMethod(
fast_gicp::NearestNeighborMethod::GPU_BRUTEFORCE
);
// 实时性要求极高的场景
vgicp_cuda.setNearestNeighborSearchMethod(
fast_gicp::NearestNeighborMethod::GPU_RBF_KERNEL
);
vgicp_cuda.setKernelWidth(0.5); // 需要调参
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 34
34 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)