SQL优化利器:EXPLAIN关键字详解与实践指南
本文深入解析MySQL的EXPLAIN关键字,帮助开发者优化SQL查询性能。EXPLAIN可分析SQL执行计划,显示查询执行顺序、索引使用情况、扫描行数等关键信息。文章详细解读了EXPLAIN结果中的各个字段,特别是连接类型(type)的性能等级,从最优的system/const到最差的全表扫描(ALL)。通过多个实战案例,演示了如何诊断慢查询问题、避免索引失效,并介绍了MySQL 5.6+的JS
本文通过丰富的示例和图示,深入解析MySQL EXPLAIN关键字,帮助开发者快速定位SQL性能瓶颈。
前言:为什么需要EXPLAIN?
在日常开发中,我们经常会遇到SQL查询性能问题。当数据量达到百万级别时,一条糟糕的SQL语句可能导致系统响应缓慢甚至崩溃。EXPLAIN就是MySQL提供的性能分析神器,能够揭示SQL语句的执行计划,让我们直观地了解查询是如何被执行的。
1. 什么是EXPLAIN?
EXPLAIN是MySQL的一个关键字,用于显示MySQL如何执行SQL查询语句。通过分析EXPLAIN的结果,我们可以:
- 了解查询的执行顺序
- 判断是否使用了索引
- 估算需要扫描的数据行数
- 识别性能瓶颈
基本使用方法
-- 基本语法
EXPLAIN SELECT * FROM users WHERE age > 25;
-- 扩展信息(MySQL 5.6+)
EXPLAIN FORMAT=JSON SELECT * FROM users WHERE age > 25;
-- 实际执行计划(MySQL 8.0+)
EXPLAIN ANALYZE SELECT * FROM users WHERE age > 25;2. EXPLAIN结果列详解
执行EXPLAIN后,我们会看到类似下面的结果:
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | users | NULL | ALL | NULL | NULL | NULL | NULL | 1000 | 100.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+让我们逐一解析每个列的含义:
2.1 id - 查询标识符
表示查询中SELECT语句的执行顺序
- id相同:执行顺序从上到下
- id不同:数值越大优先级越高
- id为NULL:表示结果集,如UNION查询
-- 复杂查询示例
EXPLAIN
SELECT u.name,
(SELECT COUNT(*) FROM orders o WHERE o.user_id = u.id) as order_count
FROM users u
WHERE u.id IN (SELECT user_id FROM vip_users);2.2 select_type - 查询类型
表示查询的复杂程度
| 类型 | 含义 | 示例 |
|---|---|---|
| SIMPLE | 简单SELECT查询 | SELECT * FROM users |
| PRIMARY | 最外层的查询 | 包含子查询时的主查询 |
| SUBQUERY | 子查询 | SELECT * FROM users WHERE id = (SELECT...) |
| DERIVED | 派生表 | SELECT * FROM (SELECT * FROM users) t |
| UNION | UNION中的第二个或后续查询 | SELECT ... UNION SELECT ... |
2.3 table - 访问的表
显示查询涉及的表名
- 真实表名
- 派生表:
<derivedN> - UNION结果:
<union1,2>
2.4 type - 连接类型(最重要)
表示MySQL在表中找到所需行的方式,性能从好到坏排序:
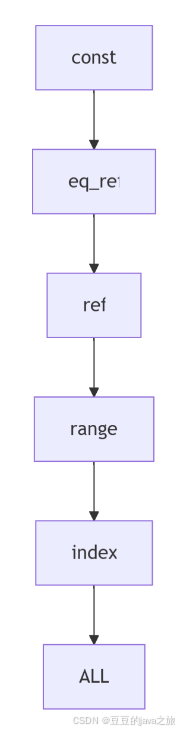
🔥 system & const - 最优级别
-- 示例:主键或唯一索引查询
EXPLAIN SELECT * FROM users WHERE id = 1;- system:表只有一行记录
- const:通过主键或唯一索引一次就找到
⭐ eq_ref - 高性能连接
-- 示例:多表关联,使用唯一索引
EXPLAIN SELECT * FROM users u
JOIN orders o ON u.id = o.user_id
WHERE u.id = 1;- 使用唯一索引进行关联
- 对于前表的每一行,后表只有一行匹配
✅ ref - 普通索引查询
-- 示例:使用非唯一索引
CREATE INDEX idx_age ON users(age);
EXPLAIN SELECT * FROM users WHERE age = 25;- 使用非唯一索引或前缀查询
- 可能返回多行记录
📊 range - 范围
- 使用索引检索给定范围的行
- 操作符:
BETWEEN、IN、>、<等
⚠️ index - 全索引扫描
-- 示例:扫描整个索引
EXPLAIN SELECT id FROM users; -- id是主键- 遍历整个索引树
- 比全表扫描稍好(索引通常比数据小)
🚨 ALL - 全表扫描(需要优化)
-- 示例:无索引查询
EXPLAIN SELECT * FROM users WHERE name LIKE '%John%';- 扫描整个表,性能最差
- 数据量大时必须优化
2.5 possible_keys & key - 可能和实际使用的索引
-- 创建测试索引
CREATE INDEX idx_age_name ON users(age, name);
CREATE INDEX idx_email ON users(email);
EXPLAIN SELECT * FROM users
WHERE age > 25 AND email = 'test@example.com';结果分析:
possible_keys:idx_age_name, idx_email(可能用到的索引)key:idx_email(实际选择的索引)key_len: 索引使用的字节数(判断索引使用程度)
2.6 rows - 预估扫描行数
MySQL估计需要读取的行数,数值越小越好:
-- 优化前:全表扫描,rows=10000
EXPLAIN SELECT * FROM users WHERE name LIKE '%John%';
-- 优化后:索引扫描,rows=50
EXPLAIN SELECT * FROM users WHERE email = 'john@example.com';2.7 Extra - 额外信息
包含MySQL解决查询的详细信息:
| 值 | 含义 | 优化建议 |
|---|---|---|
| Using where | 使用WHERE过滤 | 正常 |
| Using index | 覆盖索引 | ✅ 优秀 |
| Using temporary | 使用临时表 | ⚠️ 需要优化 |
| Using filesort | 文件排序 | ⚠️ 需要优化 |
| Using join buffer | 使用连接缓冲 | 🔧 考虑调整join_buffer_size |
3. 实战案例解析
案例1:慢查询优化
优化前:
-- 执行时间:2.3秒
EXPLAIN SELECT * FROM orders o
JOIN users u ON o.user_id = u.id
WHERE u.create_time > '2023-01-01'
AND o.amount > 1000
ORDER BY o.create_time DESC;EXPLAIN结果分析:
+----+-------------+-------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | key | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | u | ALL | NULL | 50000| Using where; Using temporary; Using filesort |
| 1 | SIMPLE | o | ALL | NULL | 100000| Using where; Using join buffer |
+----+-------------+-------+------+---------------+------+---------+------+--------+-------------+问题诊断:
- 全表扫描(type=ALL)
- 使用临时表和文件排序
- 扫描行数过多
优化方案:
-- 添加索引
CREATE INDEX idx_user_create_time ON users(create_time);
CREATE INDEX idx_order_user_amount ON orders(user_id, amount);
CREATE INDEX idx_order_create_time ON orders(create_time);
-- 优化后查询
EXPLAIN SELECT o.* FROM orders o
WHERE o.user_id IN (
SELECT id FROM users
WHERE create_time > '2023-01-01'
)
AND o.amount > 1000
ORDER BY o.create_time DESC;案例2:索引失效分析
-- 索引失效的常见场景
EXPLAIN SELECT * FROM users WHERE age + 1 > 25; -- 索引列参与运算
EXPLAIN SELECT * FROM users WHERE LEFT(name, 1) = 'J'; -- 使用函数
EXPLAIN SELECT * FROM users WHERE name LIKE '%John%'; -- 前导通配符
-- 优化方案
EXPLAIN SELECT * FROM users WHERE age > 24; -- 避免列运算
EXPLAIN SELECT * FROM users WHERE name LIKE 'John%'; -- 前导匹配4. 高级技巧
4.1 EXPLAIN FORMAT=JSON(MySQL 5.6+)
EXPLAIN FORMAT=JSON
SELECT u.name, COUNT(o.id)
FROM users u
LEFT JOIN orders o ON u.id = o.user_id
GROUP BY u.id;JSON输出包含更详细的信息:
- 成本估算(cost)
- 索引使用统计
- 优化器决策过程
4.2 EXPLAIN ANALYZE(MySQL 8.0+)
EXPLAIN ANALYZE
SELECT * FROM users WHERE age > 25;输出实际执行统计:
-> Filter: (users.age > 25) (cost=1000.25 rows=5000) (actual time=0.125..5.250 rows=3000 loops=1)
-> Table scan on users (cost=1000.25 rows=10000) (actual time=0.100..3.500 rows=10000 loops=1)5. 优化 checklist
✅ 索引优化
- 避免全表扫描(type=ALL)
- 优先使用eq_ref、ref连接类型
- 合理设计复合索引顺序
- 注意索引选择性
✅ 查询优化
- 避免SELECT *,只查询需要的列
- 合理使用覆盖索引(Using index)
- 减少临时表和文件排序
- 优化JOIN顺序和条件
✅ 架构优化
- 大数据量表考虑分库分表
- 读写分离缓解压力
- 适当使用缓存
总结
EXPLAIN是SQL优化的必备工具,通过理解其输出结果,我们可以:
- 快速定位性能瓶颈所在
- 验证索引是否有效使用
- 避免全表扫描等低效操作
- 优化查询语句和数据库设计
记住优化黄金法则:先分析,再优化。不要盲目添加索引,而是基于EXPLAIN的数据做出科学决策。
希望本文能帮助你更好地理解和使用EXPLAIN进行SQL优化!如有疑问欢迎留言讨论。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 28
28 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)