掌握C++ map:高效键值对操作指南
C++ map为key-value结构,基于红黑树实现,具有O(logN)操作效率。key唯一且自动排序。核心操作:插入使用insert或make_pair;遍历推荐结构化绑定for(auto& [k,v] : map);删除用erase;查找用find。重点掌握operator[],兼具查找、插入、修改三重功能:若key存在返回value引用,不存在则插入默认值后返回引用,广泛应用于统计场景。m

🔥个人主页:胡萝卜3.0
📖个人专栏: 《C语言》、《数据结构》 、《C++干货分享》、LeetCode&牛客代码强化刷题
⭐️人生格言:不试试怎么知道自己行不行
🎥胡萝卜3.0🌸的简介:


目录
一、map和multimap参考文档
二、map类的介绍

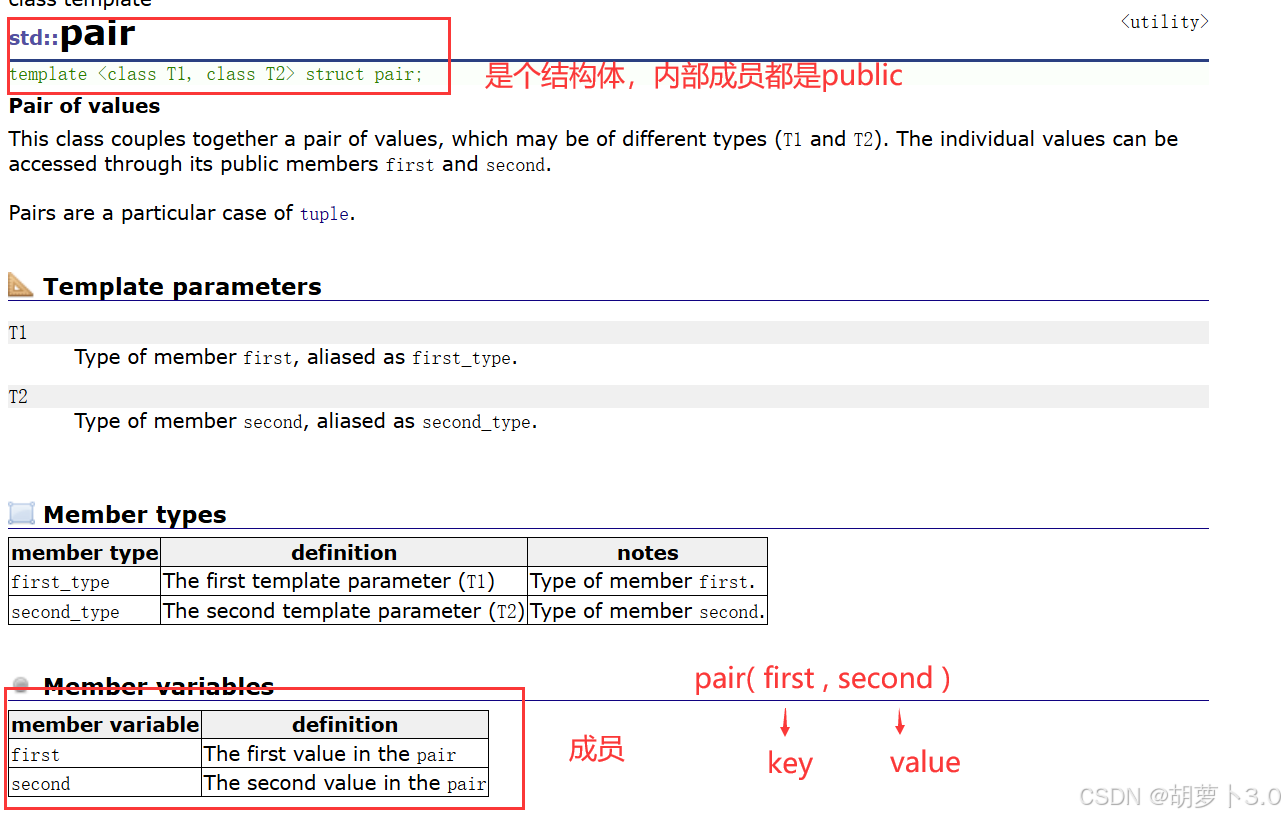
map是一个key_value的结构,不允许出现重复的数据,从上图中我们可以看出map由四部分组成:
- Key就是map底层关键字的类型
- T是map底层value的类型
- map默认要求Key支持小于的比较,如果不满足要求或者不满足相应的需要可以自行实现仿函数传给模板参数
- map底层存储数据的内存是从空间配置器申请的
一般情况下,我们都不需要传后两个参数,map底层是用红黑树实现的,增删插改效率是,迭代器遍历走的是中序,所以是按key有序顺序遍历(map的顺序是由key决定的)
map的底层直接存储了一个key_value的结构体——pair

pair是何方神圣呢?我们一起来看一下——
2.1 pair类型介绍
map底层的红黑树节点中的数据,使用pair<Key, T>存储键值对数据。
2.2 创建 map 对象
explicit map (const key_compare& comp = key_compare(),
const allocator_type& alloc = allocator_type()); |
无参构造,构造一个空的map对象 |
template <class InputIterator> map (InputIterator first, InputIterator last,const key_compare& comp = key_compare(), const allocator_type& = allocator_type()); |
迭代器区间构造 |
| map (const map& x); | 拷贝构造 |
| map (initializer_list<value_type> il; | initializer list (5) initializer 列表构造 |
创建一个空的map对象——(最常用的方式)
void test_map1()
{
//创建一个空的map对象
//假设key的类型是string,T的类型是string/int
map<string, string> map1;
map<string, int> map2;
}
一般情况下,我们都不需要传剩余的两个参数!!!
2.3 插入键值对:insert 方法
在map中使用insert插入一个数据,插入的数据也是一个pair!!!
假设现在我们要实现一个字典,那我们该怎么插入一个pair数据呢?

ok,我们先来看看怎么构造一个pair对象——
2.3.1 创建键值对:pair 的构造
void test_map2()
{
//创建一个pair对象(有名对象)
pair<string, string> kv1("sort", "排序");
//使用匿名对象
pair<string, string>("left", "左边");
//make_pair 一个函数模板:给两个值,会根据这两个值来构造一个类型
make_pair("right", "右边");
}ok,这样我们就可以实现插入的操作——
void test_map2()
{
map<string, string> dict;
//创建一个pair对象(有名对象)
pair<string, string> kv1("sort", "排序");
dict.insert(kv1);
//使用匿名对象
dict.insert(pair<string, string>("left", "左边"));
//make_pair 一个函数模板:给两个值,会根据这两个值来构造一个类型
dict.insert(make_pair("right", "右边"));
}插入结果: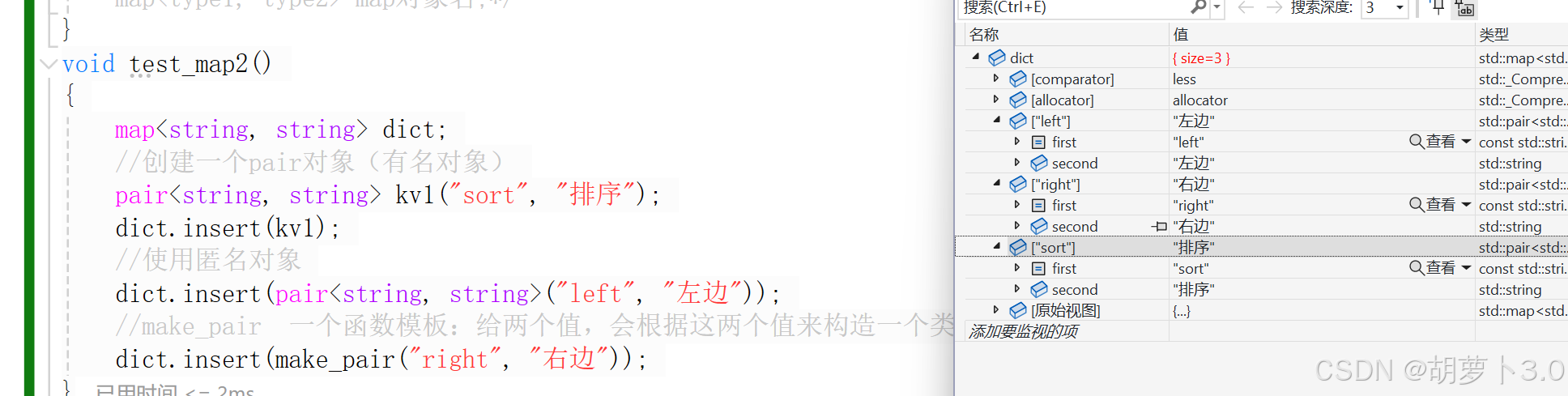
但是不知道有没有uu发现上面使用构造一个pair对象,匿名对象,make_pair进行插入的操作有点麻烦,那我们就可以使用下面的方式:
dict.insert({ "map","地图" });
注意:这里不是initializer_list的构造
如果是initializer_list的构造,应该是pair的initializer_list
dict.insert({ {"string","字符串"},{"begin","开始"} });//initializer_list构造注意:key相同的数据,无法插入(map不允许key重复)!!!
2.4 遍历键值对:map的迭代器使用
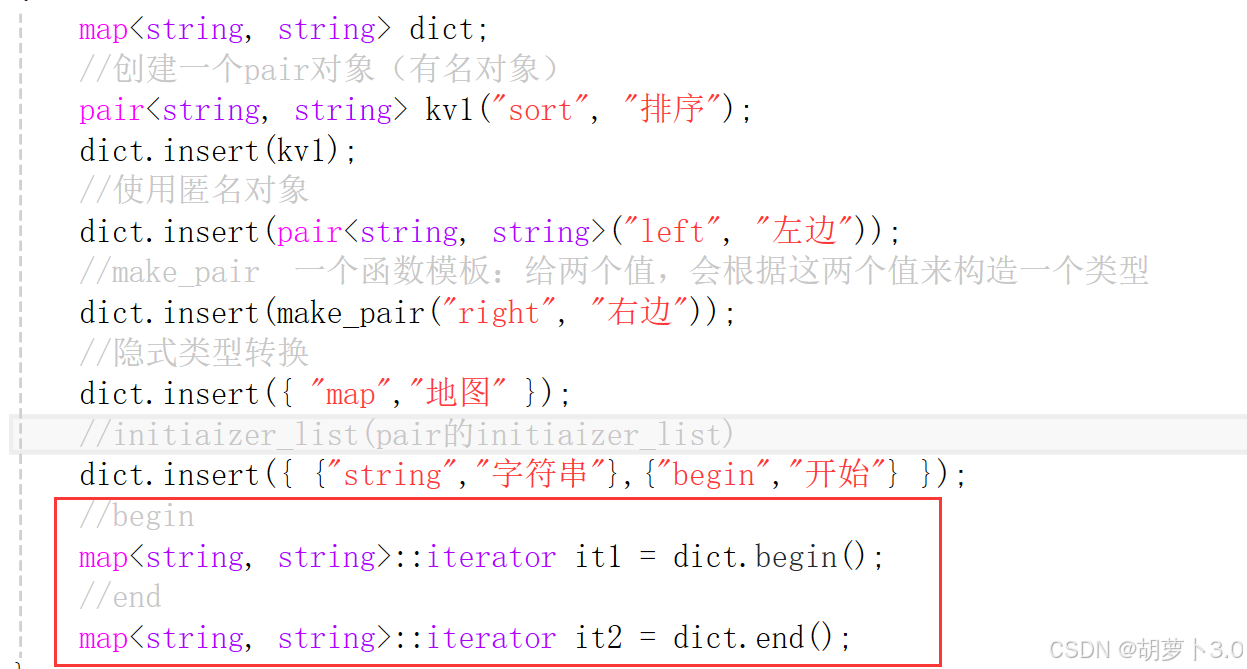
- 迭代器遍历map
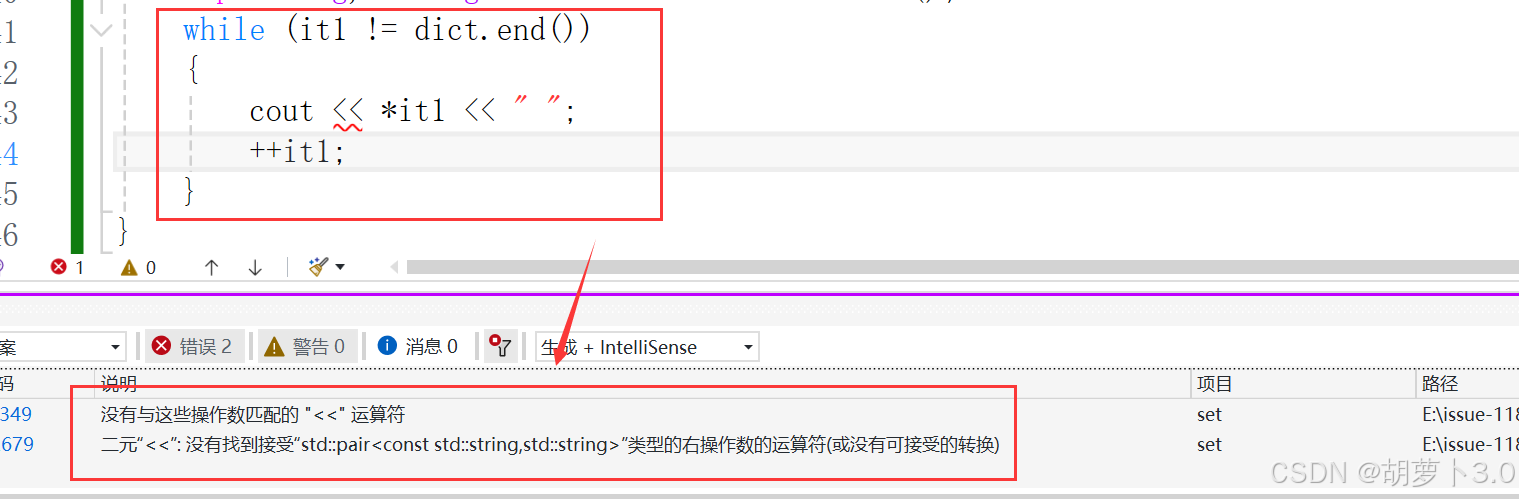
嗯?为什么这里会报错?
ok,这是因为这里无法直接进行打印,为什么?
*it1的结果是一个pair类型的结构体,pair不支持打印,pair中有两个成员:first和second;如果直接打印,该打印谁呢!
ok,对于这种内部有多个成员组成的结构体类型,我们可以使用下面的方法进行打印——
while (it1 != dict.end())
{
cout << (*it1).first << ":" << (*it1).second << endl;
++it1;
}但是我们更建议使用下面的方式进行打印——
while (it1 != dict.end())
{
cout << it1->first << ":" << it1->second << endl;
++it1;
}
- 范围for遍历
方式一:

方式二:(结构化绑定C++17支持)最推荐使用

对于这种方式我们可以这么理解:

void test_map2()
{
map<string, string> dict;
//创建一个pair对象(有名对象)
pair<string, string> kv1("sort", "排序");
dict.insert(kv1);
//使用匿名对象
dict.insert(pair<string, string>("left", "左边"));
//make_pair 一个函数模板:给两个值,会根据这两个值来构造一个类型
dict.insert(make_pair("right", "右边"));
//隐式类型转换
dict.insert({ "map","地图" });
//initiaizer_list(pair的initiaizer_list)
dict.insert({ {"string","字符串"},{"begin","开始"} });
//begin
map<string, string>::iterator it1 = dict.begin();
//end
map<string, string>::iterator it2 = dict.end();
//遍历方式一:
while (it1 != dict.end())
{
cout << (*it1).first << ":" << (*it1).second << endl;
++it1;
}
//遍历方式二:(相较于1更推荐2)
while (it1 != dict.end())
{
cout << it1->first << ":" << it1->second << endl;
++it1;
}
//方式三
for (auto& e : dict)//*iterator是一个pair
{
cout << e.first << ":" << e.second << endl;
}
//方式四(最推荐使用)
for (auto& [k, v] : dict)
{
cout << k << ":" << v << endl;
}
}注意:遍历的结果按key值升序排列(从小到大)!!!
2.5 删除键值对:erase 操作
iterator erase (const_iterator position); |
删除指定迭代器位置上的数据 |
size_type erase (const key_type& k); |
删除指定key数据(删除只看key,不看value),成功删除返回1,失败返回0 |
iterator erase (const_iterator first, const_iterator last); |
删除[first,last)区间的数据 |
map<string, string>::iterator it1 = dict.begin();
//删除指定迭代器位置上的数据
dict.erase(it1);
//删除指定key的数据(存在就删,否则什么都不做)
dict.erase("map");
//删除一段迭代器区间的数据
map<string, string>::iterator it2 = dict.begin();
dict.erase(++it2, dict.end());注意:erase会有迭代器失效!!!
2.6 查找键值对:find 操作
iterator find (const key_type& k); |
查找key,查找到返回key所在的迭代器;没有查找到,返回end迭代器 |
const_iterator find (const key_type& k) const; |
查找const key,查找到返回const key所在的const 迭代器;没有查找到,返回end迭代器 |
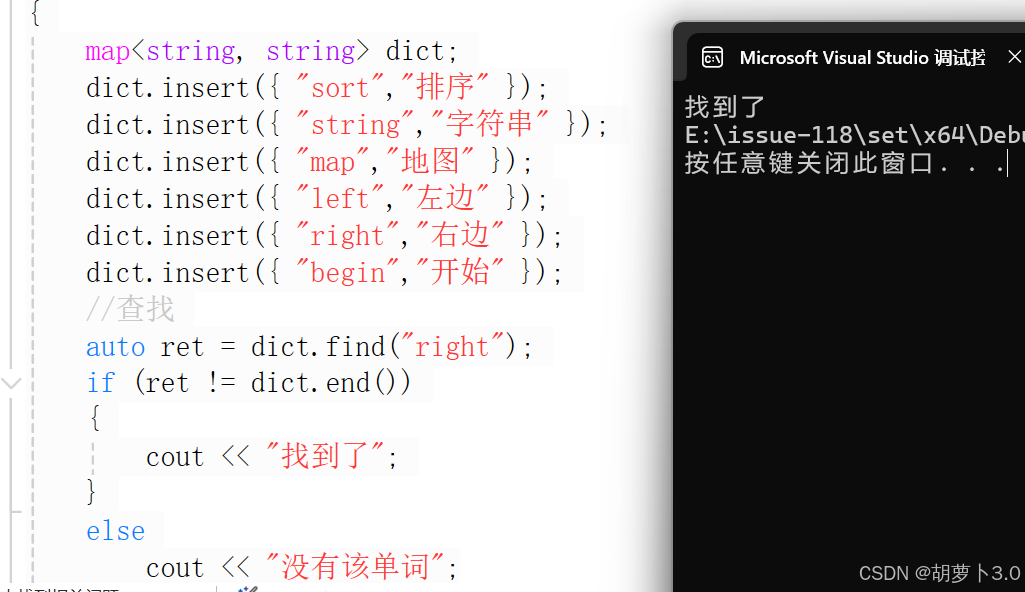
void test_map3()
{
map<string, string> dict;
dict.insert({ "sort","排序" });
dict.insert({ "string","字符串" });
dict.insert({ "map","地图" });
dict.insert({ "left","左边" });
dict.insert({ "right","右边" });
dict.insert({ "begin","开始" });
//查找
auto ret = dict.find("right");
if (ret != dict.end())
{
cout << "找到了";
}
else
cout << "没有该单词";
}运行结果:
2.7 更新键对应的值
通过前面的学习,我们知道set是不能进行修改操作的,但是map可以进行修改操作:通过key来修改value

运行结果:

ok,那除了上面这种修改的方式还有没有其他更便捷,更牛逼的修改方式呢?
肯定是有的
2.7.1 map中的operator[ ] (重点)
在map中重载了" [ ] " 运算符,我们可以通过它来进行修改操作
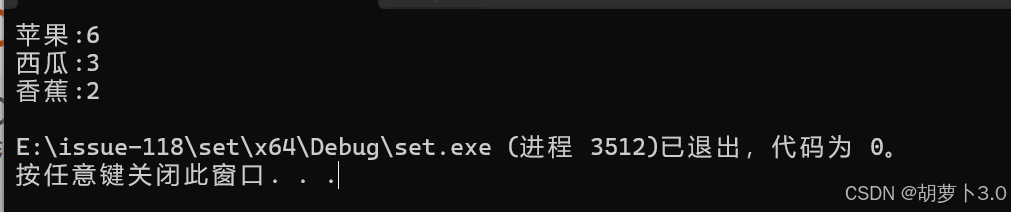
void test_map4()
{
string arr[]= { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
map<string, int> countmap;
for (auto& e : arr)
{
countmap[e]++;
}
for (auto& [k, v]:countmap)
{
cout << k << ":" << v << endl;
}
}运行结果:
这到底是咋做到了,感觉有点小牛逼啊!!!
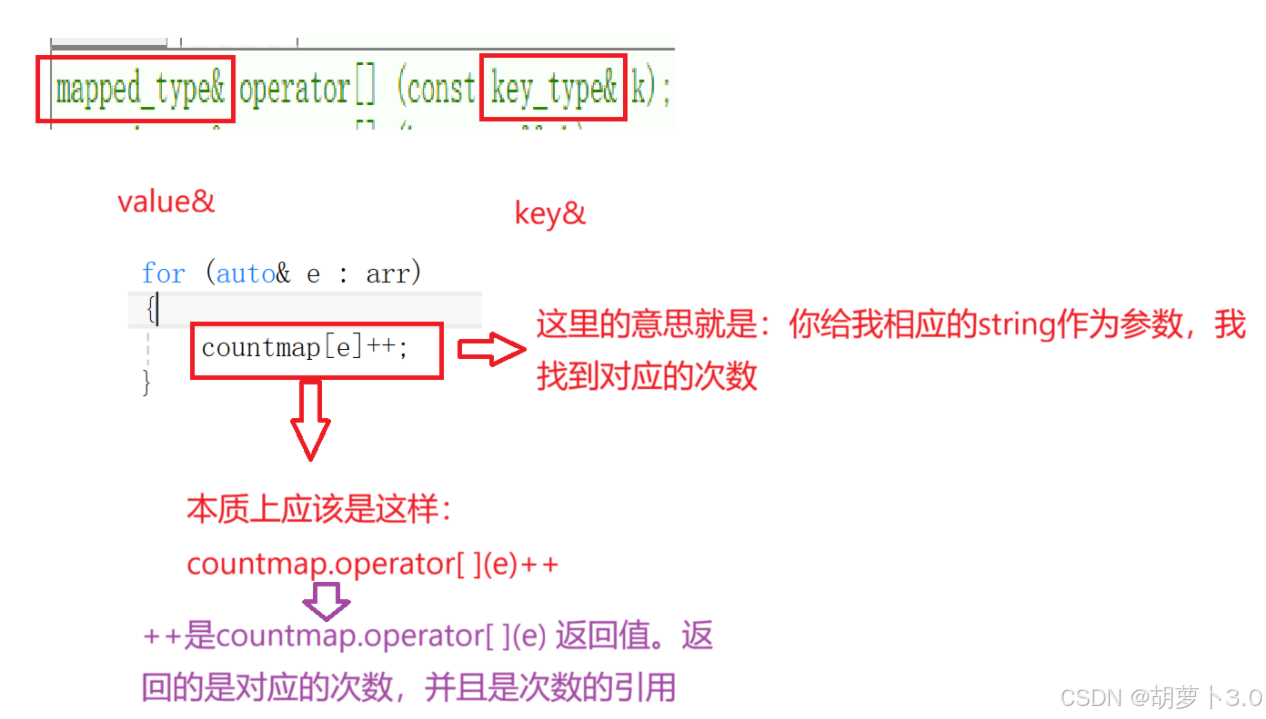
map::operator[ ] 的意思是 你给我key,我找到对应的value
ok,这里还有一个问题:
如果这个key是第一次出现怎么办?这个key都不在map中怎么办呢?
countmap[ ](e)++;
- key已经在map中,返回value的引用,然后++,没有任何问题;
- key不在map中,第一次出现在map中呢?怎么办?
这就说明[ ] 还有他的新功能!!!

ok,上图中所展示的就是 [ ] 的调用逻辑,我们一起来看一下,这到底表示什么意思?
通过上图中的解释,我们可以知道:[ ] 的底层的意思就是不管三七二十一,先insert,然后通过insert的返回值拿到key所在节点的iterator。
但是这里好像还没有说出key不在map中,这个value是怎么回事?接着看——

也就是说(按照统计水果案例):
- 如果这个水果是第一次出现,insert成功,插入成功后通过insert的返回值(pair<iterator,bool>),拿到key位置的迭代器(iterator(iterator指向pair<key,value>));再对iterator解引用,拿到key_value的pair(pair<key_type,value_type>);再取key_value的pair中的second(也就是次数),这个次数是0次(刚才默认构造的),0次就相当于这个水果第一次出现时:先插入,返回对应次数,次数是0次,++之后就变成1次
- 水果再次出现,我先去insert,insert失败,返回pair<iterator,bool>,拿到key节点所在位置的迭代器(iterator(iterator指向pair<key,value>)),然后对iterator解引用拿到key_value的pair(pair<key_type,value_type>);再取key_type的pair中的second(也就是次数),然后++,变成2,3……
也就意味着:
- 若第一次出现会插入,次数是0次,++之后次数变成1次
- 若出现过了,返回对应的次数的引用,然后++
通过上面的解释,我们可以发现 operator [ ] 有多重功能:
- 查找——你给我key,我返回对应key的value
- 修改——你给我key,我返回对应key的value的引用,可以修改key对应value
- 插入——第一次出现,插入
2.7.1.1 只插入key
//插入
dict["sort"]; // 插入 {"sort", ""},string 默认构造value为空字符串2.7.1.2 插入+修改
//插入+修改
dict["left"] = "左边的";2.7.1.3 修改
//修改
//sort这个key已经存在,可以通过key来修改相应的value
dict["sort"] = "排序";2.7.1.4 查找
//查找(若查找的这个值(key)第一次出现,会插入)
cout << dict["map"] << endl;2.8 at()
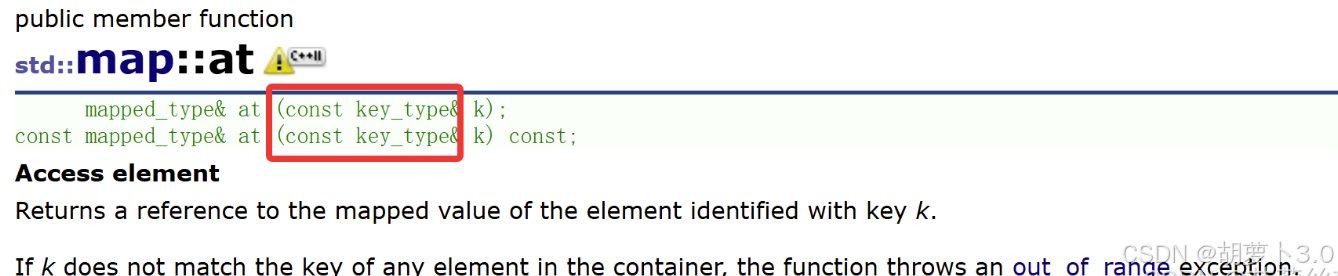
2.8.1 修改存在的 key
dict.at("left") = "xxxxxxxxxx"; // 安全修改2.8.2 访问不存在的 key(抛异常)
// dict.at("insert") = "xxxxxxxxxx"; // 抛出 std::out_of_range 异常ok,map的使用就说这么多,其余使用和set一模一样,这里不过于赘述啦~~~
三、multimap
multimap和map的区别是:
- key一样会插入,key不一样也会插入
multimap的使用和map差不多,这里不过于论述~~~
四、map:算法题中的解题利器
- 题目描述:

- 解题思路:
思路1:
创建一个map对象,统计单词出现的次数,然后将map对象的中的数据存入vector对象中,在vector对象中进行sort排序(在这里sort的第三个参数需要自己写个仿函数),然后再创建一个vector<string> 对象,用来存放前k个次数最多的单词
思路2:
创建一个map对象,统计单词出现的次数,然后将map对象的中的数据存入priority_queue对象中(priority_queue<pair<string,int>,vector<pair<string,int>>,kv_com> p),(在这里priority_queue对象的第三个参数需要自己写个比较的仿函数),然后再创建一个vector<string> 对象,用来存放前k个次数最多的单词
- 代码一:
class Solution {
public:
struct kv_pair
{
bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2)
{
return kv1.second>kv2.second||
//如果不同的单词有相同出现频率, 按字典顺序排序。
(kv1.second==kv2.second&&kv1.first<kv2.first);
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> countMap;
//计算单词出现的频率
for(auto& str: words)
{
countMap[str]++;
}
//将conutmap中的数据放入vector中进行排序
vector<pair<string,int>> v(countMap.begin(),countMap.end());
//进行排序,按second进行排序(出现次数)
sort(v.begin(),v.end(),kv_pair());
vector<string> ret;
for(size_t i=0;i<k;i++)
{
ret.push_back(v[i].first);
}
return ret;
}
};- 代码二:
class Solution {
public:
struct kv_com
{
bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2 )
{
return kv1.second<kv2.second||(kv1.second==kv2.second&&kv1.first>kv2.first);
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> countmap;
for(auto& e:words)
{
countmap[e]++;
}
//使用优先级队列
priority_queue<pair<string,int>,vector<pair<string,int>>,kv_com> p(countmap.begin(),countmap.end());
vector<string> v;
for(size_t i=0;i<k;i++)
{
v.push_back((p.top()).first);
p.pop();
}
return v;
}
};结尾
写到这里map的使用这一章节就完美散花啦,那请大佬不要忘记给博主来个赞哦!
૮₍ ˶ ˊ ᴥ ˋ˶₎ა

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)