LangChain 常用Memory模块的分类和使用
本文介绍了LangChain中的6种常见记忆模块,重点讲解了ChatMessageHistory、ConversationBufferMemory、ConversationBufferWindowMemory和ConversationTokenBufferMemory四种模块。这些模块可帮助大模型实现对话记忆功能,各有特点:ChatMessageHistory是基础存储工具;Conversatio
0前言
首先大模型本身是没有记忆的,而大模型的记忆功能本质上是把历史消息记录跟随问题一起发送给大模型。实现这一功能可以自己手动实现,即把每次对话消息手动存进消息列表中,这样的缺点是实现起来繁琐,也可以使用LangChain封装好的Memory模块来快速轻松实现记忆功能。以下将通过实现各种Memory模块的案例来介绍它们的基本使用。本文主要讲述以下6大常见记忆模块
- ChatMessageHistory
- ConversationBufferMemory
- ConversationBufferWindowMemory
- ConversationTokenBufferMemory
- ConversationSummaryMemory
- ConversationSummaryBufferMemory
1 ChatMessageHistory
ChatMessageHistory是一个用于 存储和管理对话消息 的基础类,它直接操作消息对象(如 HumanMessage, AIMessage等),是其它记忆组件的底层存储工具。同时它还有个别名类叫InMemoryChatMessageHistor,使用Api得导这个名字的Api
1.1 示例代码
通过实例化InMemoryChatMessageHistory,然后将消息add进去,调用大模型时把history作为参数传入即可
from langchain_core.chat_history import InMemoryChatMessageHistory
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ["OPENAI_BASE_URL"] = os.getenv("QWEN_BASE_URL")
os.environ["OPENAI_API_KEY"] = os.getenv("QWEN_API_KEY")
# 获取对话模型
chat_model = ChatOpenAI(
model="qwen-plus"
)
# 实例化ChatMessageHistory对象
history = InMemoryChatMessageHistory()
# 添加UserMessage
history.add_user_message("我是Jevon,你好,你是谁?")
# 添加AIMessage
history.add_ai_message("你好呀,我是你的私人助理小贝")
# 提问
history.add_user_message("我是谁?")
# 打印history
print(history.messages)
# 打印大模型回复
print(chat_model.invoke(history.messages))
1.2 运行效果
控制台输出历史消息记录以及大模型回复,此时大模型有了记忆力,知道“我是谁”。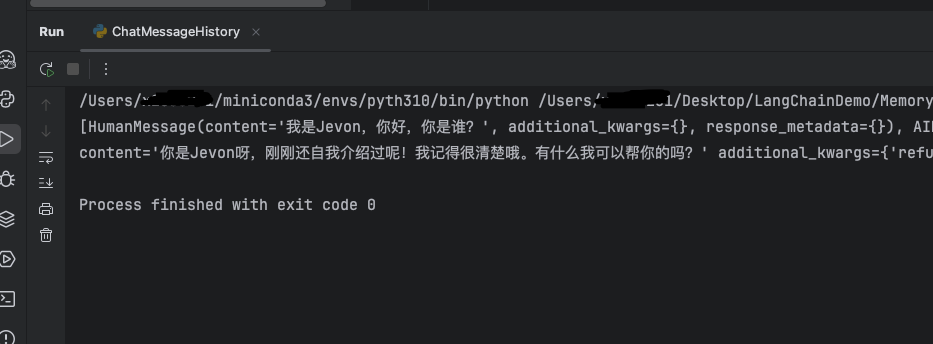
2 ConversationBufferMemory
ConversationBufferMemory是一个基础的 对话记忆(Memory)组件 ,专门用于按
原始顺序存储完整的对话历史。总结就是最基础的记忆组件,使用这个模块会把完整的对话记录传给大模型,所以缺点也很明显,消息太多太长时,会消耗大量token。适用场景:对话轮次较少、依赖完整上下文的场景(如简单的聊天机器)
支持两种返回格式(通过 return_messages 参数控制输出格式)
- return_message=True:返回消息对象列表(List[BaseMessage])
- return_message=False:(默认) 返回拼接的纯文本字符串
2.1 示例代码
该示例通过修改memory_key,将默认的”history“改为”chat_history“,修改后的key可以被prompt模版识别,使用ConversationBufferMemory无需像ChatMessageHistory一样手动输入对话消息,它会自动塞入memory中
from langchain_classic.chains.llm import LLMChain
from langchain_classic.memory import ConversationBufferMemory
import os
import dotenv
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ["OPENAI_BASE_URL"] = os.getenv("QWEN_BASE_URL")
os.environ["OPENAI_API_KEY"] = os.getenv("QWEN_API_KEY")
# 获取对话模型
chat_model = ChatOpenAI(
model="qwen-plus"
)
# 实在例化ConversationBufferMemory对象,修改历史消息的key为chat_history(默认为history)
memory = ConversationBufferMemory(memory_key="chat_history")
# 创建提示词模版
prompt = PromptTemplate.from_template("你是个对话机器人,对话记录:{chat_history}, 人类问题:{question}, 回复:")
# 创建LLMChain
chain = LLMChain(
llm=chat_model,
prompt=prompt,
memory=memory
)
# 对话1
print(chain.invoke({"question": "你好, 我是Jevon"}))
# 对话2
print(chain.invoke({"question": "我是谁?"}))
2.2 运行效果
第一次提问时,chat_history里没有内容,第二次提问时第一次的对话被插入。并能通过历史对话知道“我是谁”,因为没有设置return_messages所以它的值默认为False,输出的内容是纯文本字符串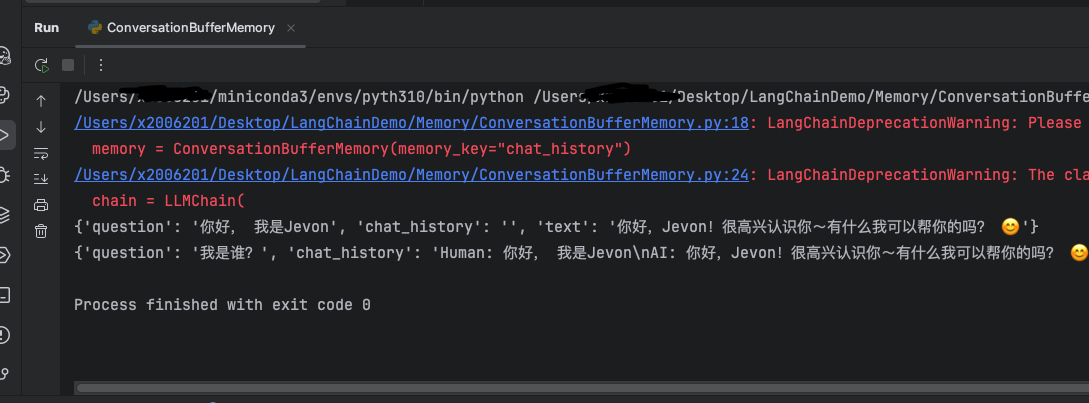
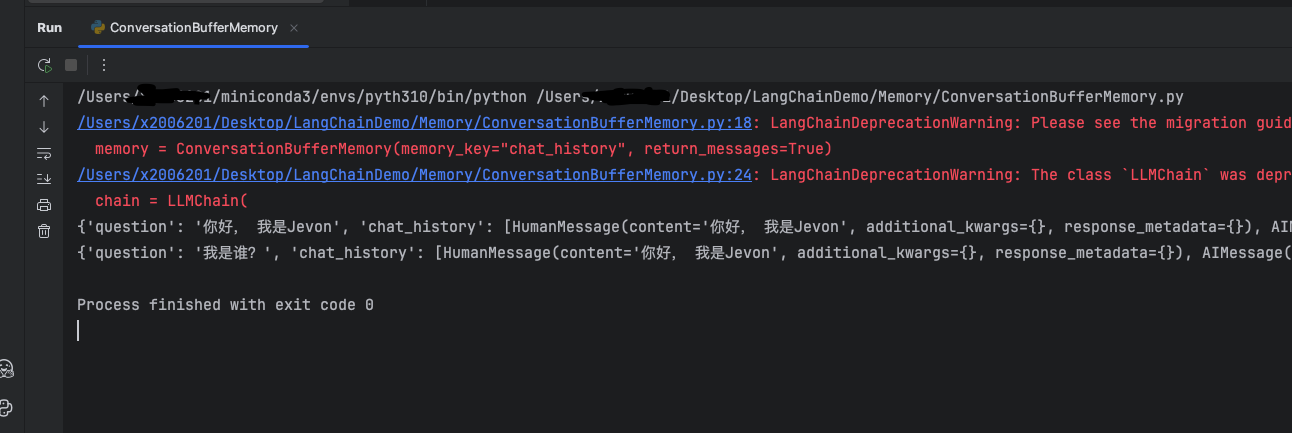
以下为将return_messages设置为True时,输出消息对象列表
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
3 ConversationBufferWindowMemory
在了解了ConversationBufferMemory记忆类后,我们知道了它能够无限的将历史对话信息填充到 History中,从而给大模型提供上下文的背景。但这会导致内存量十分大,并且消耗的token是非常多的,此外,每个大模型都存在最大输入的Token限制。
我们发现,过久远的对话数据往往并不能对当前轮次的问答提供有效的信息,LangChain 给出的解决方式是: ConversationBufferWindowMemory模块。该记忆类会 保存一段时间内对话交互 的列表,仅使用最近K个交互。这样就使缓存区不会变得太大。
简而言之就是只取最近k组对话,超过k组的就不放进大模型的上下文中了
3.1 示例代码
以下示例设置了k=1,即只保留一组对话,第一次说了自己的是谁,第二次说自己喜欢吃苹果,再次问大模型我是谁时,大模型此时只保留了关于“苹果”的那一组对话,对于“我是谁”那一段直接忘记了,所以再次提问我是谁时大模型会不知道。
from langchain_classic.chains.llm import LLMChain
from langchain_classic.memory import ConversationBufferMemory, ConversationBufferWindowMemory
import os
import dotenv
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ["OPENAI_BASE_URL"] = os.getenv("QWEN_BASE_URL")
os.environ["OPENAI_API_KEY"] = os.getenv("QWEN_API_KEY")
# 获取对话模型
chat_model = ChatOpenAI(
model="qwen-plus"
)
# 实在例化ConversationBufferWindowMemory对象
memory = ConversationBufferWindowMemory(k=1, return_messages=True)
# 创建提示词模版
prompt = PromptTemplate.from_template("你是个对话机器人,对话记录:{history}, 人类问题:{question}, 回复:")
# 创建LLMChain
chain = LLMChain(
llm=chat_model,
prompt=prompt,
memory=memory
)
# 对话1
print(chain.invoke({"question": "你好, 我是Jevon"}))
# 对话2
print(chain.invoke({"question": "我爱吃苹果"}))
# 对话3
print(chain.invoke({"question": "我是谁?"})['text'])
3.2 运行效果
大模型只记得关于“苹果”的历史消息,所以就尽量往这方面靠,但是并不知道“我是谁”。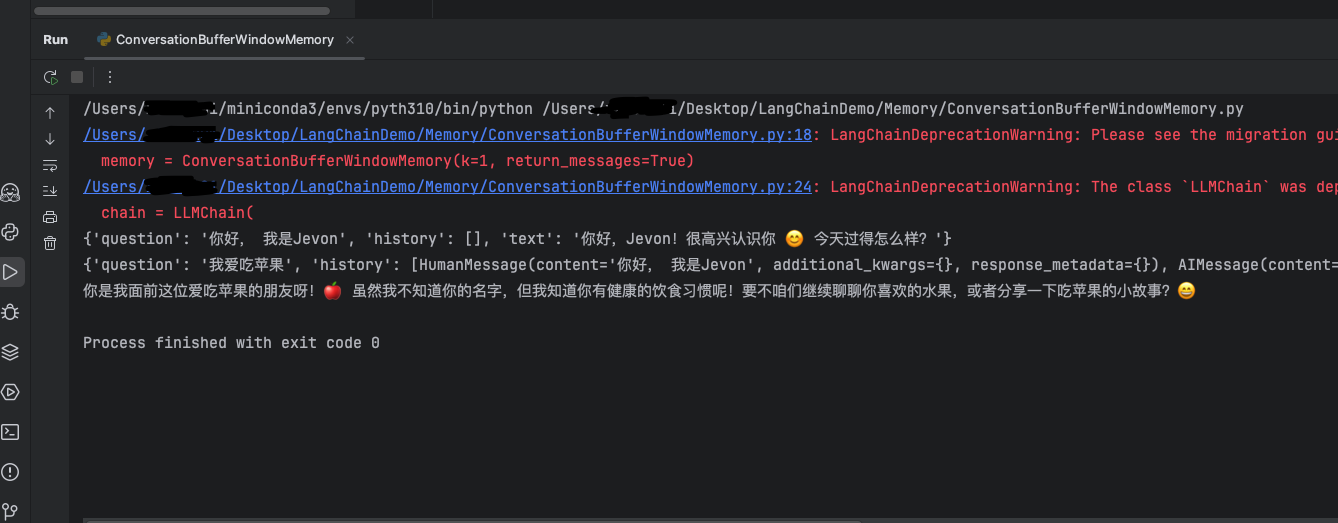
4 ConversationTokenBufferMemory
ConversationTokenBufferMemory 是LangChain 中一种基于 Token 数量控制的对话记忆机制。如果字符数量超出指定数目,它会切掉这个对话的早期部分,以保留与最近的交流相对应的字符数量。
特点:
- Token 精准控制
- 原始对话保留
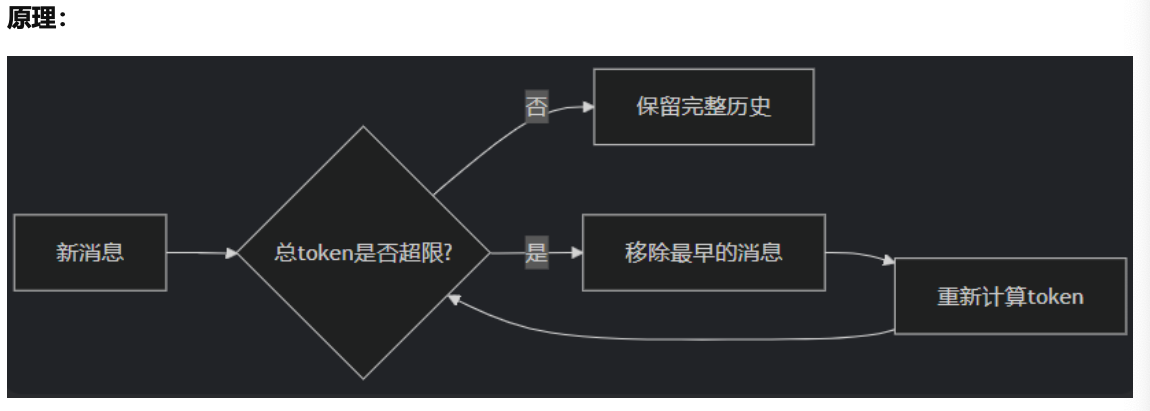
ConversationBufferWindowMemory通过控制消息对数的数量k来控制与大模型交互的上下文长度,而ConversationTokenBufferMemory则直接控制每一次交互的最大token数量来控制交互上下文长度,这种方式相比ConversationBufferWindowMemory则更加精准。
缺点:
测试了一下,似乎这个api兼容性不太好,对于普通的大模型都会显示未实现获取token数量的方法,以下是使用千问系列大模型,会报NotImplementedError: get_num_tokens_from_messages() is not presently implemented for model qwen-plus.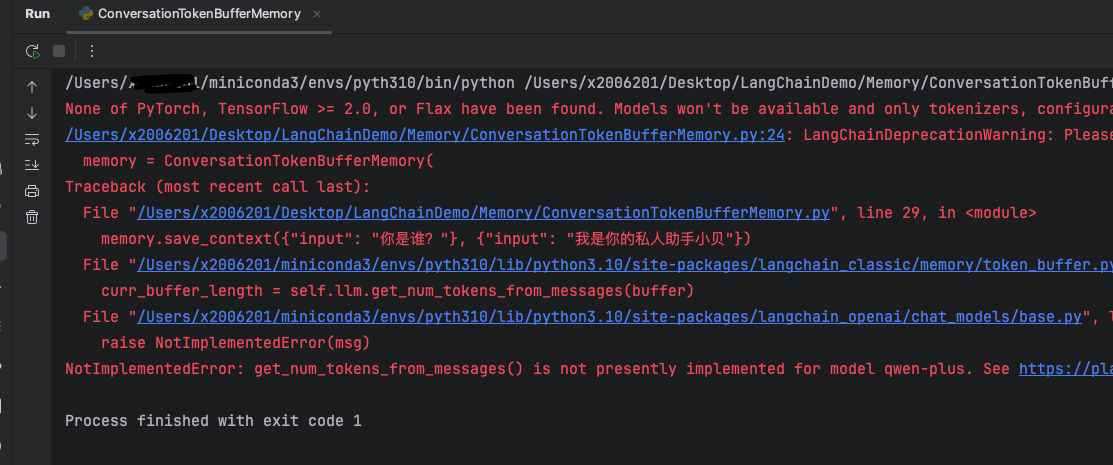
所以以下示例改用本地部署的deepseek大模型测试
4.1 示例代码
以下示例使用ollama部署的本地deepseek-r1:1.5b大模型,设置最大token数max_token_limit=50
from langchain_classic.memory import ConversationTokenBufferMemory
from langchain_ollama import ChatOllama
# 获取对话模型
ollama_llm = ChatOllama(
model="deepseek-r1:1.5b"
)
# 实在例化ConversationTokenBufferMemory对象
memory = ConversationTokenBufferMemory(
llm=ollama_llm,
max_token_limit=50
)
memory.save_context({"input": "你是谁?"}, {"input": "我是你的私人助手小贝"})
memory.save_context({"input": "今天天气如何?"}, {"input": "今天天气不错,天气晴朗"})
memory.save_context({"input": "世界上最高的山是?"}, {"input": "世界上最高的山是珠穆朗玛峰"})
# 查看大模型记忆
print(memory.load_memory_variables({}))
4.2 运行效果
由于记忆最大token数限制,大模型只存储了一条消息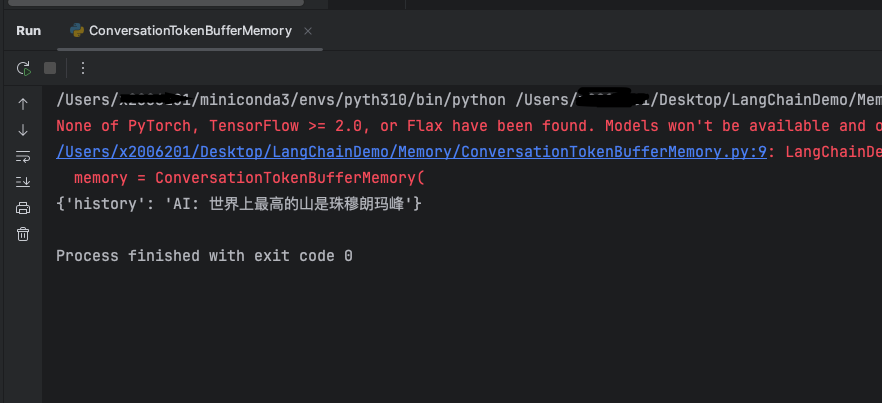
5 ConversationSummaryMemory
ConversationSummaryMemory是 LangChain 中一种 智能压缩对话历史 的记忆机制,它通过大语言模 型(LLM)自动生成对话内容的 精简摘要 ,而不是存储原始对话文本。 这种记忆方式特别适合长对话和需要保留核心信息的场景。
前面提到的不论是限制对话条数还是限制最大token数都无法即节省内存又保证对话质量,限制太小了会导致对话质量不佳,限制很大会导致token消耗大,所以可以使用ConversationSummaryMemory方法和ConversationSummaryBufferMemory方法来做个折中。
本节将论述一下ConversationSummaryMemory,该方法简而言之就是将历史消息摘要化,就是做总结,缩短token数
5.1 示例代码
实例化ConversationSummaryMemory并存入历史数据
import os
import dotenv
from langchain_classic.memory import ConversationSummaryMemory
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ["OPENAI_BASE_URL"] = os.getenv("QWEN_BASE_URL")
os.environ["OPENAI_API_KEY"] = os.getenv("QWEN_API_KEY")
# 获取对话模型
chat_model = ChatOpenAI(
model="qwen-plus"
)
# 实在例化ConversationTokenBufferMemory对象
memory = ConversationSummaryMemory(
llm=chat_model
)
memory.save_context({"input": "你是谁呀?"}, {"input": "我是你的私人助手小贝"})
memory.save_context({"input": "今天天气如何?"}, {"input": "今天天气不错,天气晴朗"})
memory.save_context({"input": "世界上最高的山是?"}, {"input": "世界上最高的山是珠穆朗玛峰"})
# 查看大模型记忆
print(memory.load_memory_variables({}))
5.2 运行效果
大模型将所有消息进行了摘要总结,如果消息比较少的时候,可能摘要会比原消息还要长,但是如果消息量很大,摘要的作用就很显著了。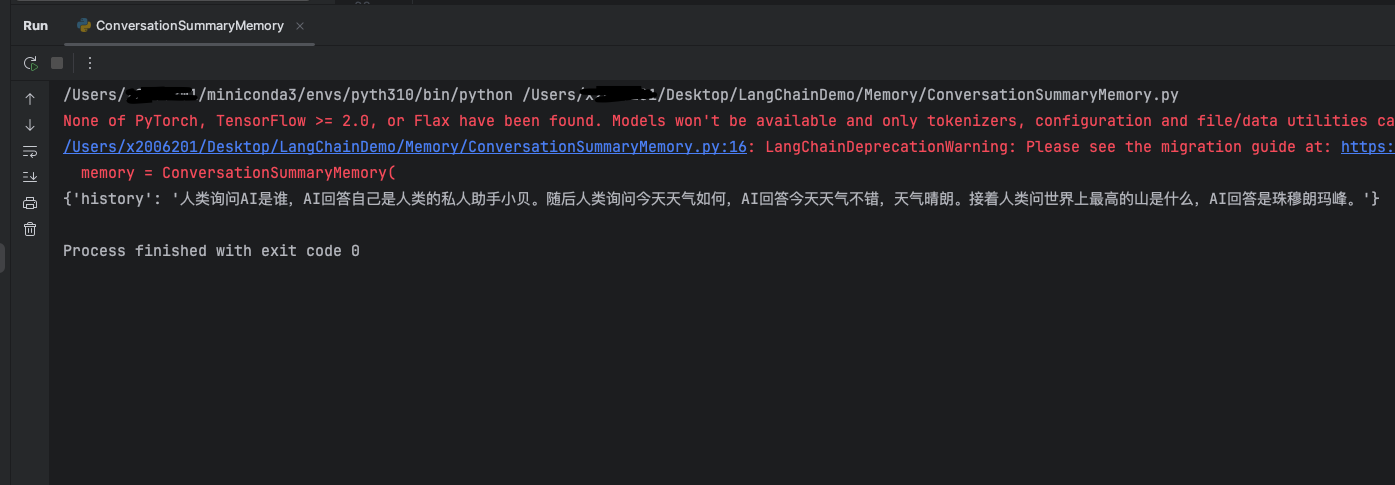
6 ConversationSummaryBufferMemory
ConversationSummaryBufferMemory 是 LangChain 中一种混合型记忆机制,它结合了ConversationBufferMemory(完整对话记录)和
ConversationSummaryMemory(摘要记忆)的优点,在保留最近对话原始记录的同时,对较早的对话内容进行 智能摘要 。特点:
- 保留最近N条原始对话:确保最新交互的完整上下文
- 摘要较早历史:对超出缓冲区的旧对话进行压缩,避免信息过载
- 平衡细节与效率:既不会丢失关键细节,又能处理长对话
原理图: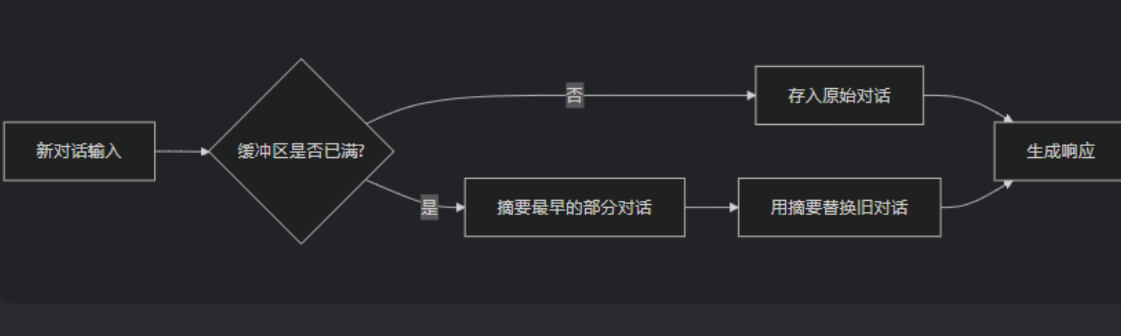
即可以设置最新的n条消息完整记录,后面的消息就摘要化,这样即能保证太久远的消息不会被完全遗忘,又能保证最大token数量
6.2 示例代码
该示例构造一个ConversationSummaryBufferMemory实例,然后设置最大token数为50,接着传入几组对话消息,后面大模型会将超过50token数的消息摘要化,50token内的最近的消息完整保留。
from langchain_classic.memory import ConversationSummaryBufferMemory
from langchain_ollama import ChatOllama
# 获取对话模型
ollama_llm = ChatOllama(
model="deepseek-r1:1.5b"
)
# 实在例化ConversationTokenBufferMemory对象
memory = ConversationSummaryBufferMemory(
llm=ollama_llm,
max_token_limit=50
)
memory.save_context({"input": "请问你是谁?"}, {"output": "我是你的私人助手小贝"})
memory.save_context({"input": "今天天气如何?"}, {"output": "今天天气不错,天气晴朗"})
memory.save_context({"input": "世界上最高的山是?"}, {"output": "世界上最高的山是珠穆朗玛峰"})
# 查看大模型记忆
print(memory.load_memory_variables({})['history'])
坑点注意:
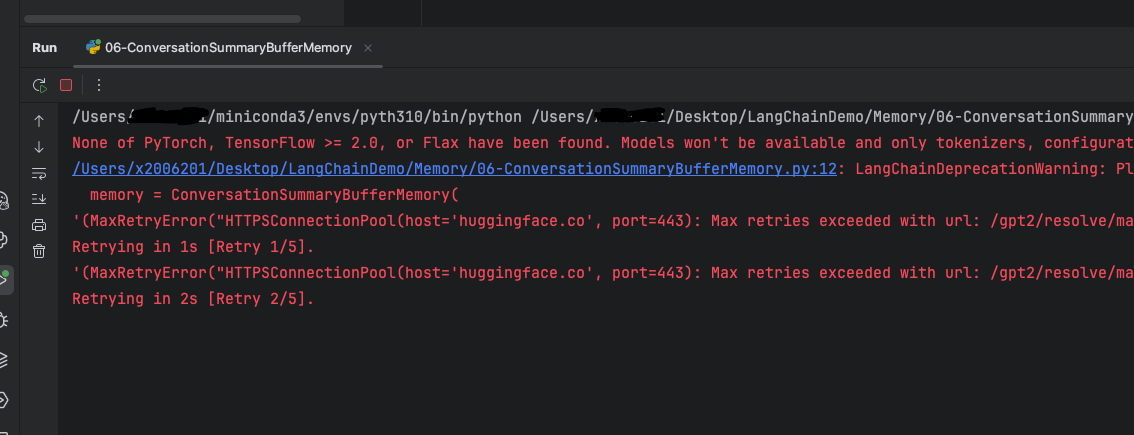
- 涉及token数计算的LangChain方法,似乎国内的大模型都不能很好地适配,大部分都不能直接使用,就连本处的deepseek大模型都需要下载transformers库来保证这个函数运行。
- 其次,使用transformers库会调用到 Hugging Face 的远程资源,所以如果没有魔法可能回复很慢或者失败,如下图
6.3 运行效果
大模型对超过50token的消息进行了摘要总结,只保留了最新的没有超过50token的一条消息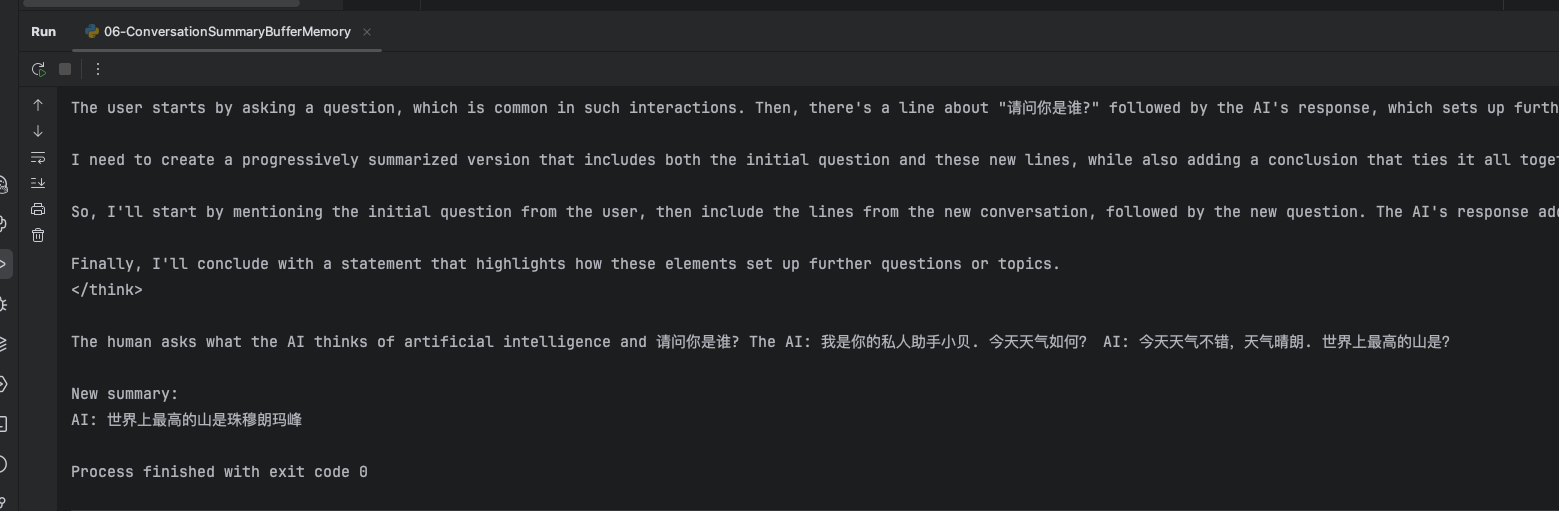
7 总结
还没了解1.0的版本,当前只感觉1.0前的版本确实不太适用国内大模型,但是对各种LangChain的记忆模块有了大致了解。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 28
28 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)