Agent AI架构
重点视频
视频合集: AI Agent 面试题01-09
https://www.bilibili.com/video/BV1UoaZzGEBK/?spm_id_from=333.1391.0.0&vd_source=8ca92588511fc633026e558331f021cb
AgentAI 整体架构
| 风格类型 | 具体步骤 | 适用方向 | 具体场景 | 缺点 | |
| react | 边想边干的实干派 | thought -> action -> ovservation (观察结果) | 适合工具调用, 任务执行场景 | 问答机器人 个人助理 |
|
| self-ask 自问式推理架构 |
自问自答的调查员 | 将大问题拆解成多个子问题 | 对目标明确,流程清洗的任务有效。 任务分解, 流程自动化 | ||
| plan & solve 计划 - 执行型架构 |
规划至上的项目经理 | 先做计划,再按步骤每一步执行 执行对应的行为颗粒度比较大 |
类项目经理, 旅行计划(计划-> 车票等细节) | 问题: 应变能力弱 | |
| chain of thought (COT) 思维链推理 |
写草稿的理工男 | prompt 增加: let's think step by step | 解数学题, 逻辑题, 法条分析 | ||
| tree of thought(ToT) | 头脑风暴大师 | 不是生成推理链, 而是每一步都考虑多个分支。 评估每一步分支可能性+质量, 选最优路径继续探索。 头脑风暴+投票 |
开放性问题,多解任务中使用 | 写小说, 多解任务 | 计算效率低 |
| reflection | 事后批改的完美主义者 | 反思型架构 任务执行-> 结果评估->反思总结-> 重试修正 |
提高准确率和稳定性 | 代码生成, 写作任务(质量要求高的场景) |
组成成分
6组成
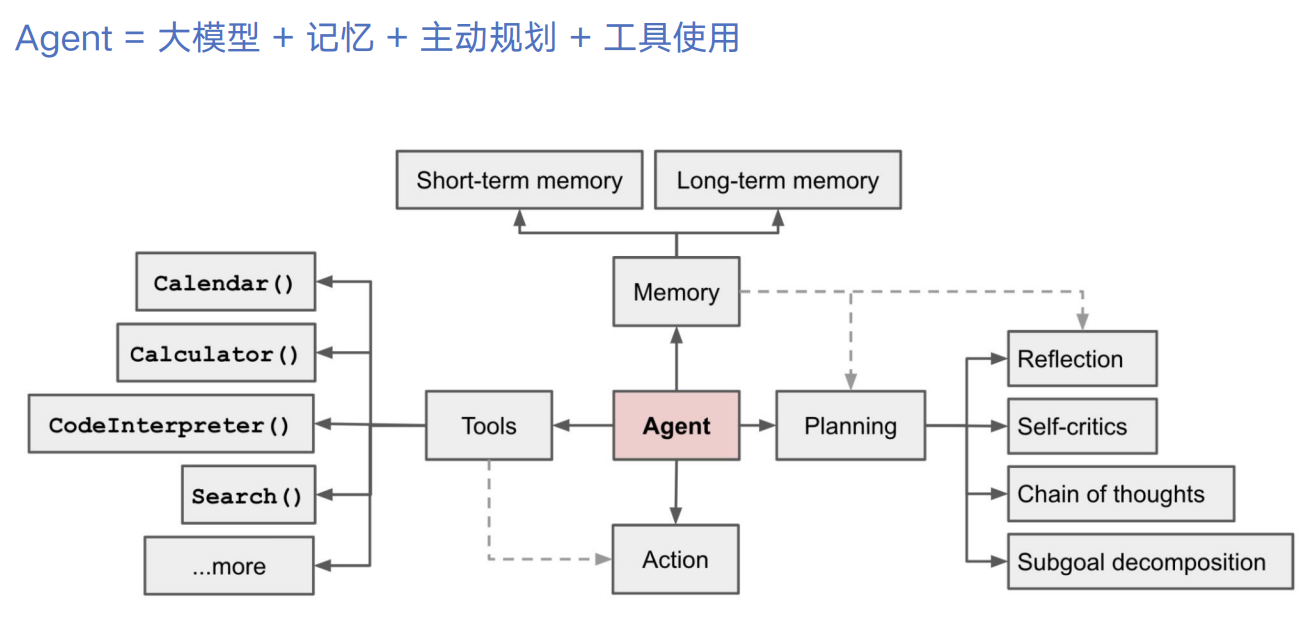
感知、记忆、规划、推理引擎、工具使用、行动
记忆
| 实现方式 | 适用场景 | 操作 | |||||||
| 写 | 读 | 更新 | 遗忘 | ||||||
| 类型 | 短期记忆 | 上下文信息 | 滑动窗口 | 只保留最近n条交互 | 直接存储、摘要 | 根据时间(5min中内), 根据语义相似度, 基于重要性打标签 SQL/Cypher精确获取 |
覆盖、 增量编辑(为编辑提供version号增量?) |
按时间衰减: 与当前时间越久的信息权重越低 相关性删除: 长时间未被访问, 与当前任务不相关 手动标记:标记临时记忆, 重要记忆 langchain实现: 滑窗 + 向量库 + 全局变量 |
|
| 摘要方式 | llm总结当前对话,提炼重点 | ||||||||
| 原始对话拼接 | |||||||||
| 长期记忆 | 类似数据库 存储长期积累下的知识, 用户偏好和经验 问题: 检索 |
向量数据库: Faiss, Weaviate | 记忆片段- > 向量表示, 语义相似度 | 向量化、结构化 | |||||
| 知识图谱: | 记忆片段-> 实体/关系 | 适合复杂逻辑推理, 问答系统 | |||||||
| 关系数据库 | 记录用户信息, 历史行为等结构化数据 | ||||||||
| 文件系统 | 非结构化, pdf, 网页, 日志 | ||||||||
| 工作记忆 | 当前任务中正在处理的信息, 临时变量 | ||||||||
需要关注的问题(写、读、用、忘)
1. 如何判断什么该被记住(过滤机制)
2. 如何在大规模记忆里快速、准确的找到记忆(检索)
3. 如何给LLM使用(上下文融合)
4. 如何减少记忆带来的开销(优化效率)
总体目标: 能记住, 会提取,能总结, 并不断改进
记忆架构:
1. 哪些信息要留存,
2. 如何组织他们,
3. 每次调用中,如何把最相关的记忆送给llm
规划
推理引擎
工具使用
6阶段:
1. 判断是否需要使用工具
2. 工具选择
3. 生成参数: 语言理解 + 结构化表达
4. 工具调用, 发出调用请求: api调用, 函数方式(openai function calling生成json格式请求)
5. 结果获取和处理: 理解, parser, 或识别异常
6. 结果整合 + 下一步规划: 整合到cot, 生成用户回复、或触发下一个任务
4种流程(判断使用哪些工具):
| 适用场景 | 问题 | ||||
|
语言理解 + 推理: 猜工具是干嘛的、然后使用(llm.bind_tools? 不确定是否是这种模式, llm和tools相关联?) |
机制灵活, 适合复杂任务 | 容易想错 | |||
|
函数调用机制(Function calling, 主流方式) |
可靠, 错误率低 | ||||
| 路由机制(routing): 训练一个简单的分类器, 或简单规则匹配 | 适合任务清晰, 流程标准化(智能客服机器人), 灵活性差 | ||||
| 示例驱动机制(Example-based), 在提示中给模型几个工具使用的示例。 few-shot | 简单易用 | 覆盖不了所有的场景 | |||
重点: 在于工具规范化的描述
规范描述:
工具名称: 简明清晰, get_stock_price
参数: 类型, 含义, 是否必填, 默认值
输出格式:
潜在问题
1. 工具选择不当会导致任务失败
2. 参数构造正确性: 格式不对, 类型错误
3. 错误处理机制: api超时, 结果缺失
4. 工具组合能力: 多工具协同时, 顺序
5. 安全控制问题: 避免agent进行危险操作: rm -rf , 转账资金等
行动
多智能体架构(MAS)
描述:
关注: 个体智能 + 群体智能的行程和管理
- 每个智能体彼此独立, 但又能相互作用,
- 智能体: 独立具备感知, 决策, 行动能力
- 可以合作, 竞争, 临时结盟
优势:
- 分布, 协作, 弹性, 适应能力
- 任务并行和专业化 e.g. AI客服: 查询语义的agent, 查询数据的agent, 生成回答的agent
- 鲁棒性和容错性 e.g. 单个agent挂掉不影响整体性能, 其他agent补位, 或重新协商策略
- 系统可扩展性 e.g. 加agent很容易
- 适应分布式任务和地理分散性问题:
- 物流调度, 交通管控, 能源管理
- 不同位置独立运行, 通过网络通信或协调
- 涌现行为: 局部简单交互下产生复杂的整体效果
问题:
- 协调(抢占行为)处理:e.g.两个仓储机器人抢占同一个货架。 处理:定义协调协议避免碰撞。
- 通信处理: 定义统一通信语言 + 处理延迟或者丢包问题
- 全局一致性: 局部决策不会导致整体混乱
- 学习策略问题:e.g. 单个agent的学习策略会相互影响, 出现非稳定博弈(两个AI股票Agent互相学习对方策略后出现价格操纵行为)
处理:
- 基于信任模型的协作策略
- 激励约束机制
- 防御恶意agent的安全协议
应用
- 金融: 多智能体根据各自模型计算, 行成风险对冲
- 灾难救援: 搜索,运输,通讯
- 智慧城市: 交通灯控制, 摄像监控,应急响应
MAS框架 AutoGen, Camel (todo)
实际项目: chatdev, AutoAgents
- 协作方式: 角色设定, 意图驱动, 历史记忆与反馈
- 适合: 需要自制, 多目标协商, 复杂环境应变的未来场景
评估方式 & 指标
| 任务完成度(Task success Rate) | 基础, 最重要 | 测试集上的任务完成比例 | |
| 结果质量(Quality of Outcome) | 人工打分 自动化指标(生成代码, 代码的通过率, 文本ROUGE分数) |
||
| 效率(Efficiency) | 完成任务所花时间 步骤数量 调用工具或语言模型的频率 整体token消耗 |
||
| 鲁棒性(Robustness) | 给模糊或者错误的信息, 看是否会崩溃 故意让外部工具故障 |
||
| 自主性(Autonomy) | 解决问题时, 是否频繁需要人工介入 | ||
| 推理能力(Reasoning Ability) | 理解任务, 拆解问题, 并规划多步操作 | React框架中, 需要分析Thought | |
| 泛化能力(Generalization) | 新问题, 新环境 | ||
| 安全与对齐(Safety & Alignment) | 伦理, 有害 偏离预期 |
ROUGE分数
| Recall-Oriented Understudy for Gisting Evaluation, 机器生成的文本对比人工写的文本的重叠度 | ||
| 指标名称 | 核心逻辑 | 适用场景 |
| ROUGE-N | 计算 “N 元语法(N-gram)” 的重叠率(N 为正整数,如 1、2、3) - N=1(ROUGE-1):单字(词)重叠,衡量 “词级匹配度” - N=2(ROUGE-2):双词短语重叠,衡量 “短语级连贯性” - N=3(ROUGE-3):三词短语重叠,更侧重 “长语义片段匹配” |
基础评估,ROUGE-1/2 是最常用的入门指标,适合快速判断文本整体匹配度 |
| ROUGE-L | 基于 “最长公共子序列(LCS)” 计算重叠率,不要求词的顺序完全一致,更贴合人类对 “语义连贯” 的判断(例如 “我爱中国” 和 “中国,我爱你” 的 LCS 重叠率很高) | 适合评估 “语义连贯性” 更重要的场景(如长文本摘要、对话生成) |
| ROUGE-W | 对 “最长公共子序列(LCS)” 中的连续匹配片段加权(连续匹配越长,权重越高),惩罚 “零散匹配”,更精准反映 “核心语义块的完整性” | 需严格评估 “核心信息完整性” 的场景(如新闻摘要、技术文档摘要) |
| ROUGE-S | 计算 “跳过 gram(Skip-gram)” 的重叠率(允许两个词之间跳过若干个词),灵活度更高,适合短文本匹配 | 短文本摘要、标题生成等场景 |
测试框架: AgentBench,ToolBench,WebArena,GAIA
安全问题:
| 安全问题(害越滥注私, 依拒副泛策) | 措施 | |
| 有害内容生成(Harmful content Generation) | 生成歧视性, 攻击性, 或非法文本 | 部署输入输出内容过滤器 |
| 指令微调(Instruction Tuning) | ||
| 强化学习和人类反馈(RLHF) | ||
| 提示工程 | ||
| 越狱攻击(Jailbreaking) | 用户通过精心设计的提示绕过Agent安全限制, 诱导其执行非法操作 | 强化提示鲁棒性 |
| 过滤越狱提示 | ||
| 输入严格净化 | ||
| 模型层、应用层、基础层、构建多层防护机制 | ||
| 工具滥用(Tool Misuse) | 调用外部工具时, 误用, 或被恶意利用, 导致数据泄露, 或系统破坏 | 权限控制(最小权限原则) |
| 严格参数验证 | ||
| 安全沙箱封装 | ||
| 资源限制 | ||
| 引入人工审批 | ||
| 提示注入(Prompt Injection) | 通过输入植入恶意指令, 改变Agent原始目标或行为 | 清晰区分用户输入与系统指令 |
| 对输出内容进行编码处理, 防止其被当做新指令 | ||
| 上下文管理中引入隔离机制 | ||
| 数据隐私泄露(Data Privacy Leakage) | Agent处理任务中以外暴露用户敏感信息 | 数据最小化原则(对传输数据进行脱敏处理) |
| 严格访问控制 | ||
| 保障记忆模块的安全性 | ||
| 过度依赖与错误放大(Over-reliance and Error Amplification ) | 用户对Agent输出的过度信任, 可能导致错误的信息扩散。 Agent 本身也可能放大微小错误 |
提升Agent输出透明度 |
| 展示信息来源和置信度 | ||
| 加强用户教育, 强调审慎使用Agent | ||
| 增加结果冗余校验和自我检查能力 | ||
| 拒绝服务攻击(Denial of Service) | 构造大量请求, 或构造复杂输入,攻击Agent资源 | 设置用户请求速率限制 |
| 任务资源配额 | ||
| 拒绝处理高复杂度请求 | ||
| 代理攻击(Confused Deputy Attack) | 攻击者诱使Agent滥用其合法权限完成恶意操作 | 实现细粒度权限划分 |
| 敏感任务执行前进行意图认证 | ||
| 根据上下文动态调整权限配置 | ||
| 通用安全策略 | 设计Agent初期就纳入安全架构 | 红队测试(按攻击者方式攻击) |
| 实时监控 & 审计 | ||
| 安全事件响应机制 | ||
| 模型和开发框架及时更新 | ||
| 鼓励用户反馈潜在问题 |
React
| 过程 | llm感知, 使用工具,工具将返回作为上下文传给llm, llm observation分析, 进行下一步,循环, 指导模型观察到所有需要做的事都完结, 结束 | |
| TAO循环, Thought-> Action -> Observation | ||
| 优点 | 可解释性 | 每一步思考, 决策, 都有文本输出, 便于追踪模型能力 |
| 弹性,动态调整 | 根据观察结果动态调整计划 | |
| 工具集成能力 | 使用工具,扩展知识边界 | |
| 容错、纠错能力 | 行动失败或信息不足, 下一轮改进 | |
| 应用 | 多轮问答 | 问答、搜索、推理 |
| 自动化分析系统 | 逐步分解任务,调取数据, 评估结果 | |
| 工具链型agent | react统筹调度工具 |
react vs llm 的优势
- 提供了显式的推理路径与动作反馈机制
- 支持在知识不全方式的推理(RAG, 加在memory上)
- 任务复杂: 支持多步骤任务。 (记忆模式、工具支持)
- 需要外部协同的场景(工具)
- 实现可解释、可复用、可扩展的智能解决方案
modelscope课程
modelscope agent课程![]() https://www.modelscope.cn/learn/1926?pid=1921
https://www.modelscope.cn/learn/1926?pid=1921
应用开发与落地全景
OpenAI AGI五级分类
- Level 1: Conversational AI,仅限于语言对话,能力有限
- Level 2: Reasoners,在专业领域能够独立推理,不需外 部工具
- Level 3: Agents,能长时间自主行动执行任务
- Level 4: Innovators,产生新思路,推动科技突破
- Level 5: Organizers,能管理协调整个组织
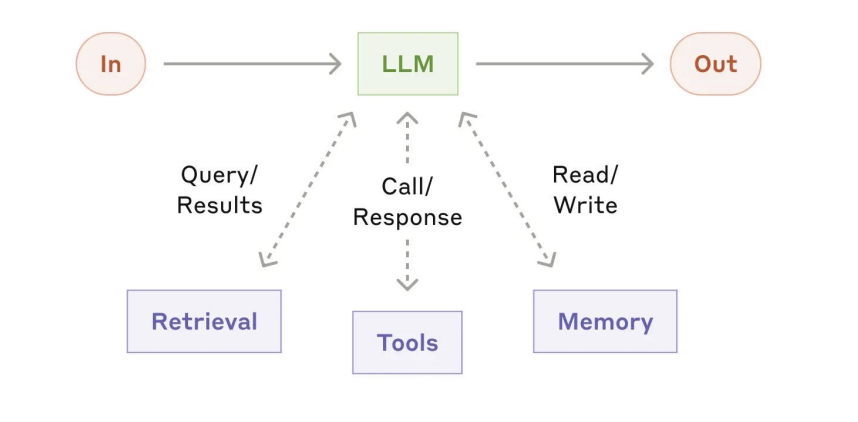
类型:
- 工作流: 预定义代码路径编排LLM + 工具
- 自主智能体(Autonomous Agent): LLM动态控制, 自主规划
基础LLM模块: 增强型LLM
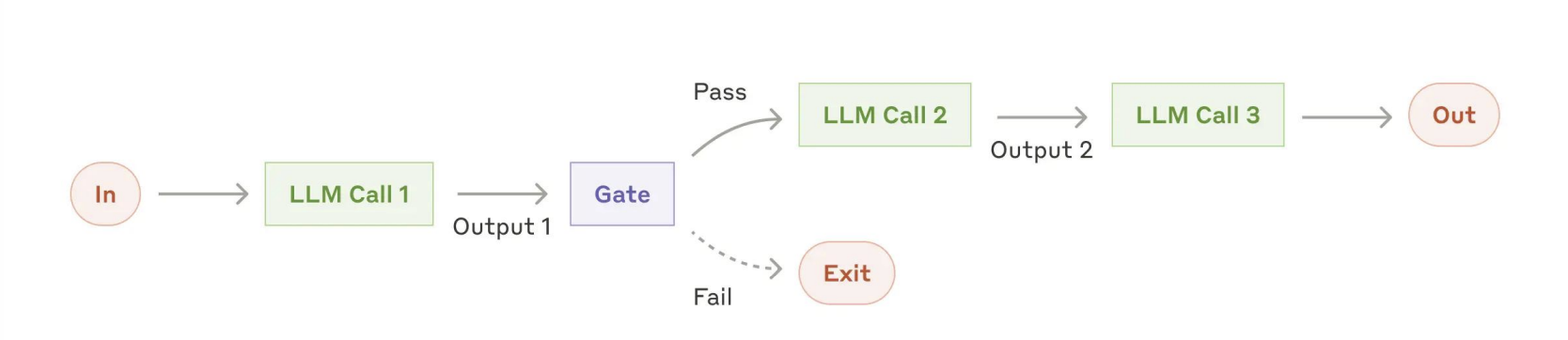
workflow:
常见模式:
- prompt chain:
- 场景: 编写文档提纲、检验提纲是否符合某些标准,然后再根据提纲写出
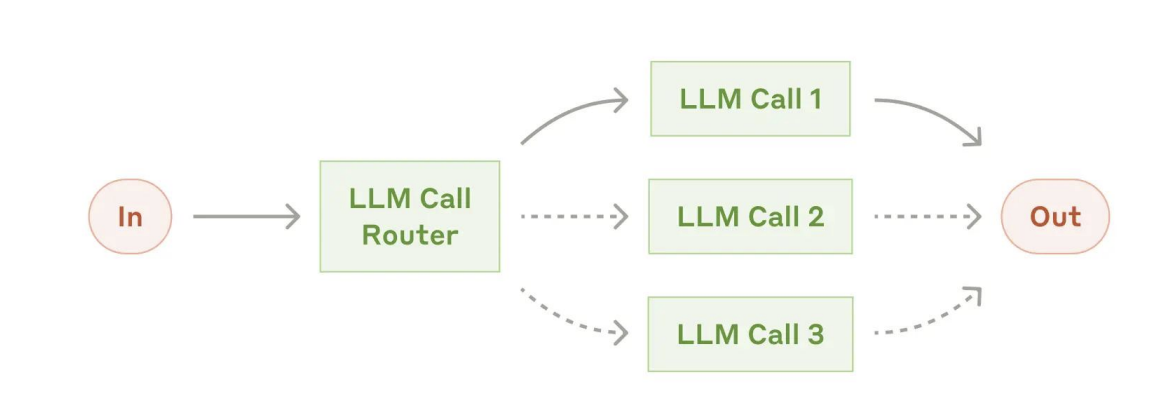
- 路由 Routing:
- 将简单/常见问题路由给较小的模型,将困难/罕见问题路由给更强大的模型,以优化成本与速度
- 并行 Parallelization:
- 阶段: 分段 + 投票
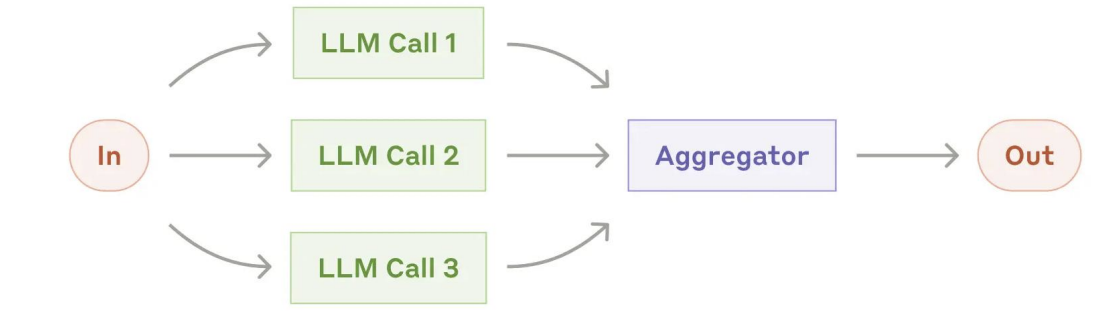
- 协调者-工作者 Orchestrator-Workers
- 协调者拆任务, 工作者干活 Cursor
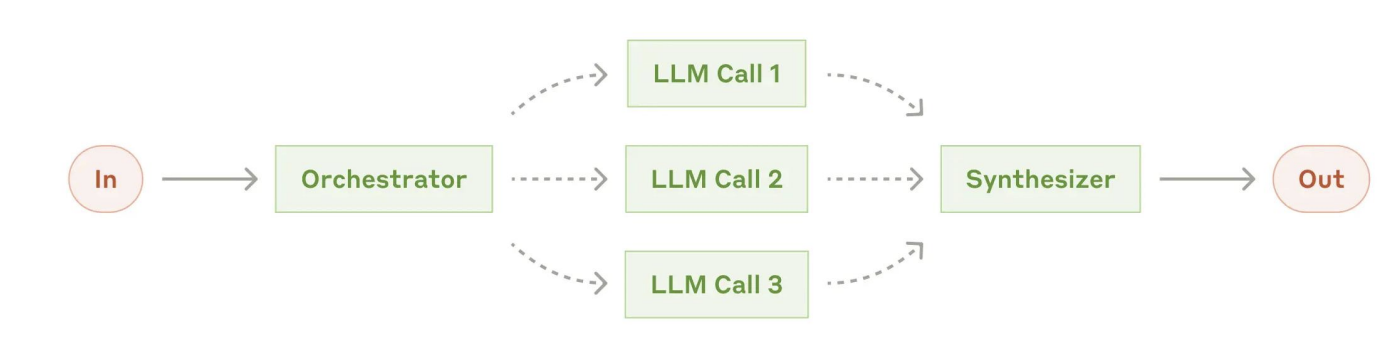
- 评估-优化循环 Evaluator-Optimizer
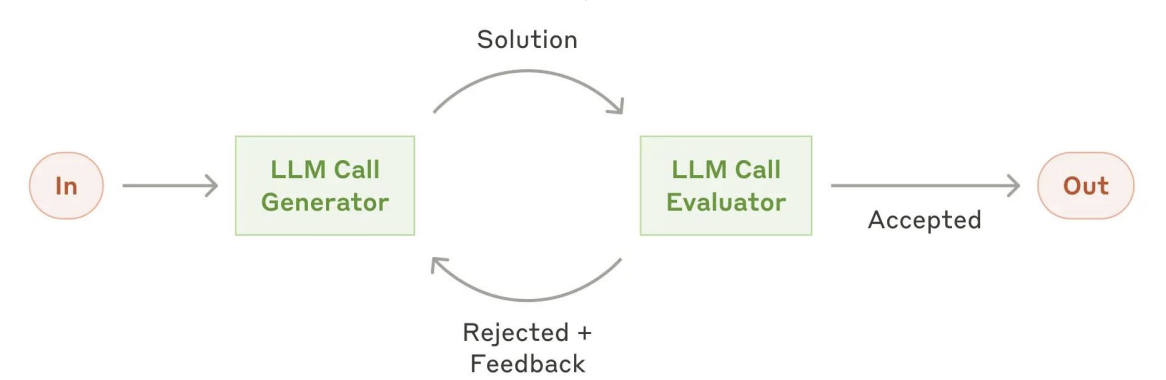
自主智能体
- 适用场景: 适用于开放性问题,即当任务步骤数量难以预知或无法预先固定时。
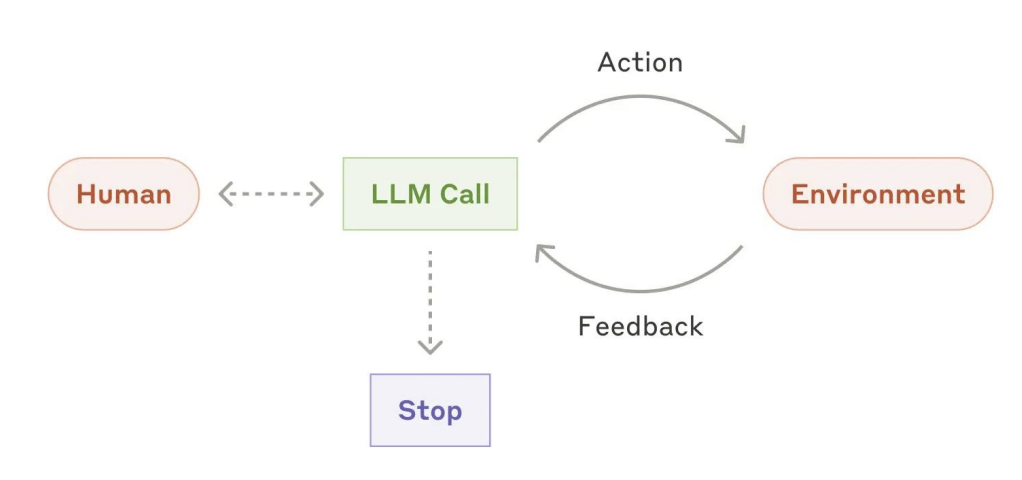
- 组成模块:
- 规划模块(子目标拆解 + 反思优化),
- 记忆系统(短期记忆(上下文), 长期记忆(外部存储)),
- 工具使用
多智能体:
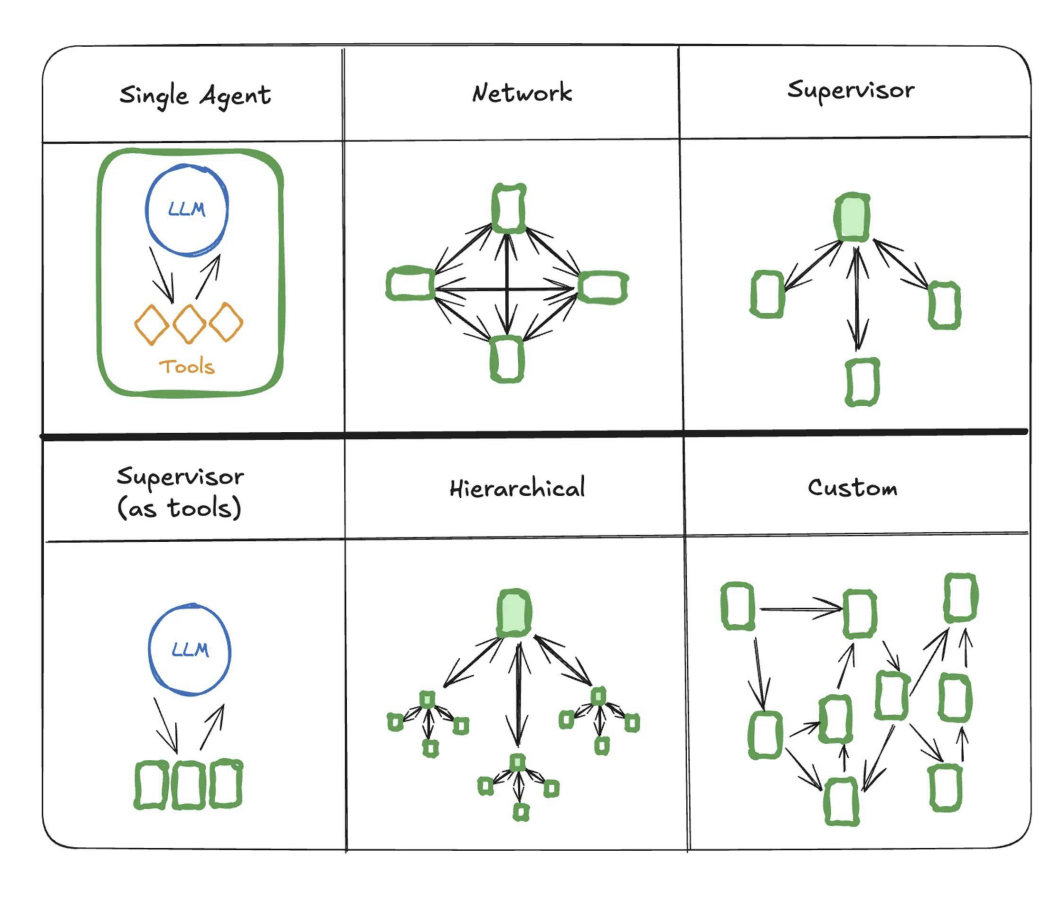
框架:
| 类型 | 框架 / 平台 | 特点 | |
|---|---|---|---|
| 全代码框架 | LangChain & LangGraph | 开源 | https://www.langchain.com/ |
| LlamaIndex | 开源 | https://www.llamaindex.ai/ | |
| 低代码平台 |
毕昇(BISHENG) 作者公司 |
Apache 2.0 开源,专注企业级场景,具备便捷性(业务人员可通过预置应用模板快速搭建智能应用)、可靠性(高并发下的高可用性和持续优化的应用运营能力,适合生产使用),2023 年 8 月底基于 Apache 2.0 协议开源,支持二次开发和商业应用 | https://bisheng.ai.com/ |
| Dify | 开源 | https://cloud.dify.ai/ | |
| Coze | Apache 2.0 开源 | https://www.coze.cn/ | |
| FastGPT | 开源 |
产品
- ChatGPT DeepResearch
- Manus
- 扣子空间
- 毕昇灵思
- AutoGLM 沉思
推荐材料: (todo)
- OpenAI API 文档:https://platform.openai.com/docs/guides/function-calling
- lilian weng:《LLM Powered Autonomous Agents》, https://lilianweng.github.io/posts/2023-06-23-agent/
- Langchain:《What is an AI agent?》,https://blog.langchain.dev/what-is-an-agent/
- Anthropic:《Building effective agents》, https://www.anthropic.com/research/building-effective-agents
产品案例深度拆解
langchain的评估方法:
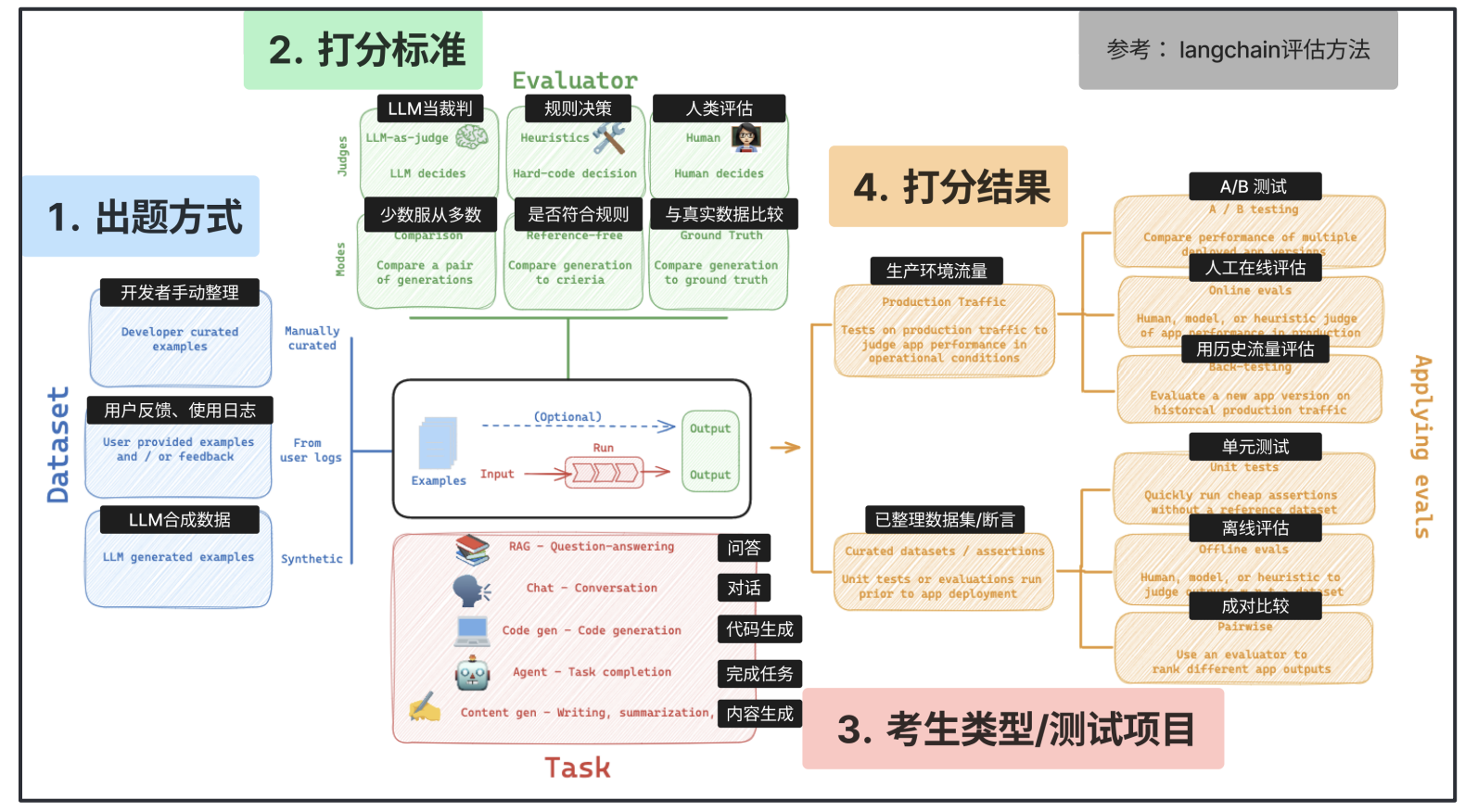
- 数据:
- 开发者手动整理
- 用户反馈、使用日志
- LLM合成数据
- Evaluator:
- LLM当裁判(少数服从多数)
- 规则决策
- 人类评估
- Task:
- 问答
- 对话
- 代码生成
- 完成任务
- 内容生成
- 具体使用:
- 生产环境流量:
- A/B test,
- 人工在线评估
- 用历史流量评估
- 生产环境流量:
- 已整理的数据(离线):
- 单元测试
- 离线评估
- 成对比较
cursor(todo, 仔细看下)
cursor![]() https://www.anthropic.com/engineering/building-effective-agents印象中有几点:
https://www.anthropic.com/engineering/building-effective-agents印象中有几点:
- 首先通过superviser llm进行plan, 结果输出为多个todo
- 多个子agent进行按模块进行开发, 并各自进行self-test
MCP原理和最简实践
结构:
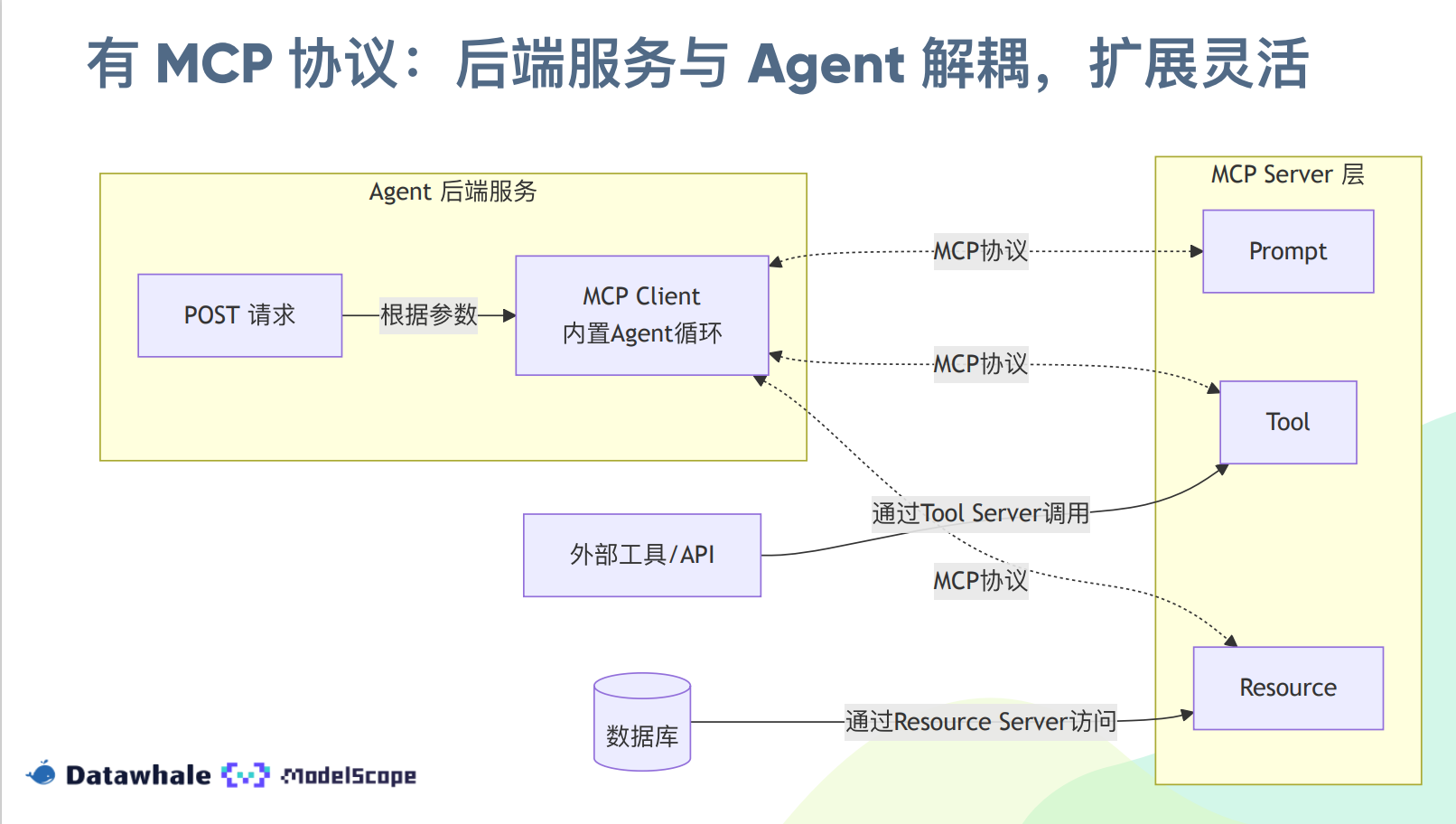
mcp服务器包括: 工具, 提示词, 资源
几种MCP Server框架:
- python: fastmcp
- TypeScript: typescript-sdk, TS官方
- Java: java-sdk, java官方
- Go: mcp-go, 适合云原生、微服务
调试:
- MCP Inspector
- MCP-CLI
- Cherry Studio
- OpenMCP Client: 插件, vscode可用
资源:
- Claude官方: modelcontextprotocol/servers
- 魔塔社区
- Smithery: 在线
具体举例:
依赖: uv add mcp "mcp[cli]"
代码:
# server.py
from mcp.server.fastmcp import FastMCP
# 创建一个 MCP Server
mcp = FastMCP("HelloMCP")
# 定义一个 prompt
@mcp.prompt()
def hello(name: str) -> str:
"""
hello prompt
"""
return f"hello {name}"
# 定义一个工具
@mcp.tool()
def say_hello(name: str) -> str:
"""
向指定的人打招呼
"""
return f"你好, {name}!这是来自 MCP 的问候 👋"
if __name__ == "__main__":
# 如果没有这句话,需要通过脚手架启动服务器,也就是
# mcp run server.py (全局安装 mcp[cli]) 或者 uv run mcp run server.py (本地安装 mcp)
mcp.run()验证思路:
- 根据领域知识和对问题的认知设置出第一个版本的 mcp server
- 测试工具完备性(工具自检)。
- 测试语义完备性(交互测试)。
- 迭代mcp server(调整mcp tool设计和mcp prompt),然后继续测试。
Agent原理 & 最简实践
当前主流的 Agent 架构:
-
ReAct(推理+行动)
- 将思考和行动融合在每个步骤中
- 通过观察-思考-行动的循环实现决策
- 适合需要实时响应的动态任务
-
Plan-and-Solve(规划-求解)
- 先规划再执行的解耦式架构
- 制定详细计划后严格按照步骤执行
- 适合需要长远规划的复杂任务
-
Reflection(反思优化)
- 执行→反思→优化的三步循环
- 通过自我评估和迭代改进提升质量
- 适合追求高精度的关键任务
ReAct 决策循环:
- Thought:基于当前观察进行推理
- Action:选择并执行具体行动
- Observation:观察行动结果
- 循环:根据新观察继续思考
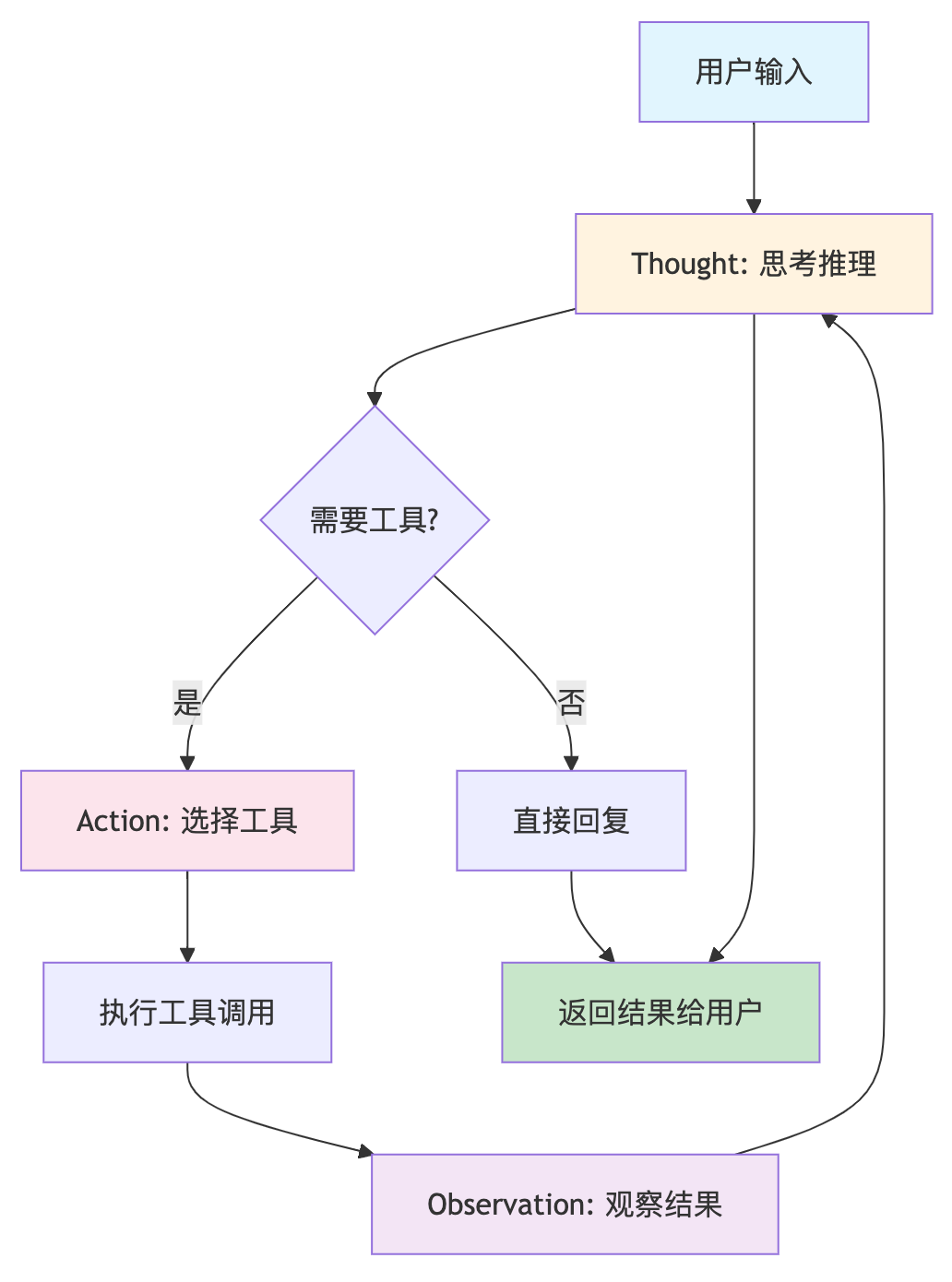
其他主流agent架构:
- Plan-and-Solve Agent:
- 工作原理:由 Lei Wang 在2023年提出,将整个流程解耦为规划阶段和执行阶段
- 规划阶段:接收完整问题,分解任务并制定分步骤的行动计划
- 执行阶段:严格按照计划执行,保持目标一致性,避免中间步骤迷失方向
- 优势:在处理多步骤复杂任务时能够保持更高的目标一致性
- Reflection Agent:
- 核心思想:灵感来源于人类学习过程,通过执行→反思→优化的循环提升质量
- 执行阶段:使用 ReAct 或 Plan-and-Solve 生成初步解决方案
- 反思阶段:调用独立的 LLM 实例担任"评审员",评估事实性、逻辑性、效率等维度
- 优化阶段:基于反馈内容对初稿进行修正,生成更完善的修订稿
- LangChain Agent:
- 基于链式调用的 Agent 框架
- 支持多种提示模板
- 丰富的工具集成生态
- 适合复杂工作流
- AutoGPT:
- 完全自主的目标追求
- 长期记忆系统
- 自我提示生成
- 适合开放式任务
- MetaGPT:
- 软件开发的 Multi-Agent 协作框架
- 模拟真实软件团队角色分工
- 产品经理、架构师、工程师等角色扮演
- 适合自动化软件开发任务
- CAMELAI:
- 基于角色扮演的对话式 Agent 框架
- 多 Agent 协作完成复杂任务
- 强调角色定义和通信协议
- 适合创意写作、教育培训等场景
prompt设计要点:
- 中文提示:更符合国内用户习惯
- 具体工具名:明确告诉模型可用工具
- 循环指导:说明可以多次使用工具
- 最终答案:明确结束条件
prompt = f"""现在时间是 {time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())}。
你是一位智能助手,可以使用以下工具来回答问题:
{tool_descriptions}
请遵循以下 ReAct 模式:
思考:分析问题和需要使用的工具
行动:选择工具 [google_search] 中的一个
行动输入:提供工具的参数
观察:工具返回的结果
你可以重复以上循环,直到获得足够的信息来回答问题。
最终答案:基于所有信息给出最终答案
开始!"""parser
- 多层匹配:先用正则提取,再用JSON解析
- 容错设计:解析失败时提供降级方案
- 格式兼容:支持JSON字符串和纯文本参数
react结构:
循环结构:
- 思考阶段(Thought):模型分析问题,决定是否需要工具
- 行动阶段(Action):选择合适的工具并提供参数
- 观察阶段(Observation):执行工具并获取结果
- 整合阶段(Integration):将新信息整合到上下文中
注意 max_iterators:防止无限循环, 控制成本, 用户体验(响应时间)
每次循环: 保持上下文, 更新输入, 历史记录
设计模式与工程化
工作流应用范式与最佳实践(dify)
agent + MCP开发范式与最佳实践(AgentScope 阿里系)
方便调优mcp: 显示定义connect、close
多智能体开发范式与最佳实践:(camel)
camel: 提供了一个set_language接口
思考: 提示词以全英文写比较好, 方便关联变量。 最后转为中文
智能体通信协议
MCP :核心共享:
- Root:让服务器安全访问 客户端的文件
- Sampling:让MCP server 使用client的AI能力
- Prompt:服务器向客户端 公开提示模板,与资源工 具配合使用
- Resource:服务器向客户 端公开资源
- Tools:服务器公开可以由 语言模型调用的工具
A2A :
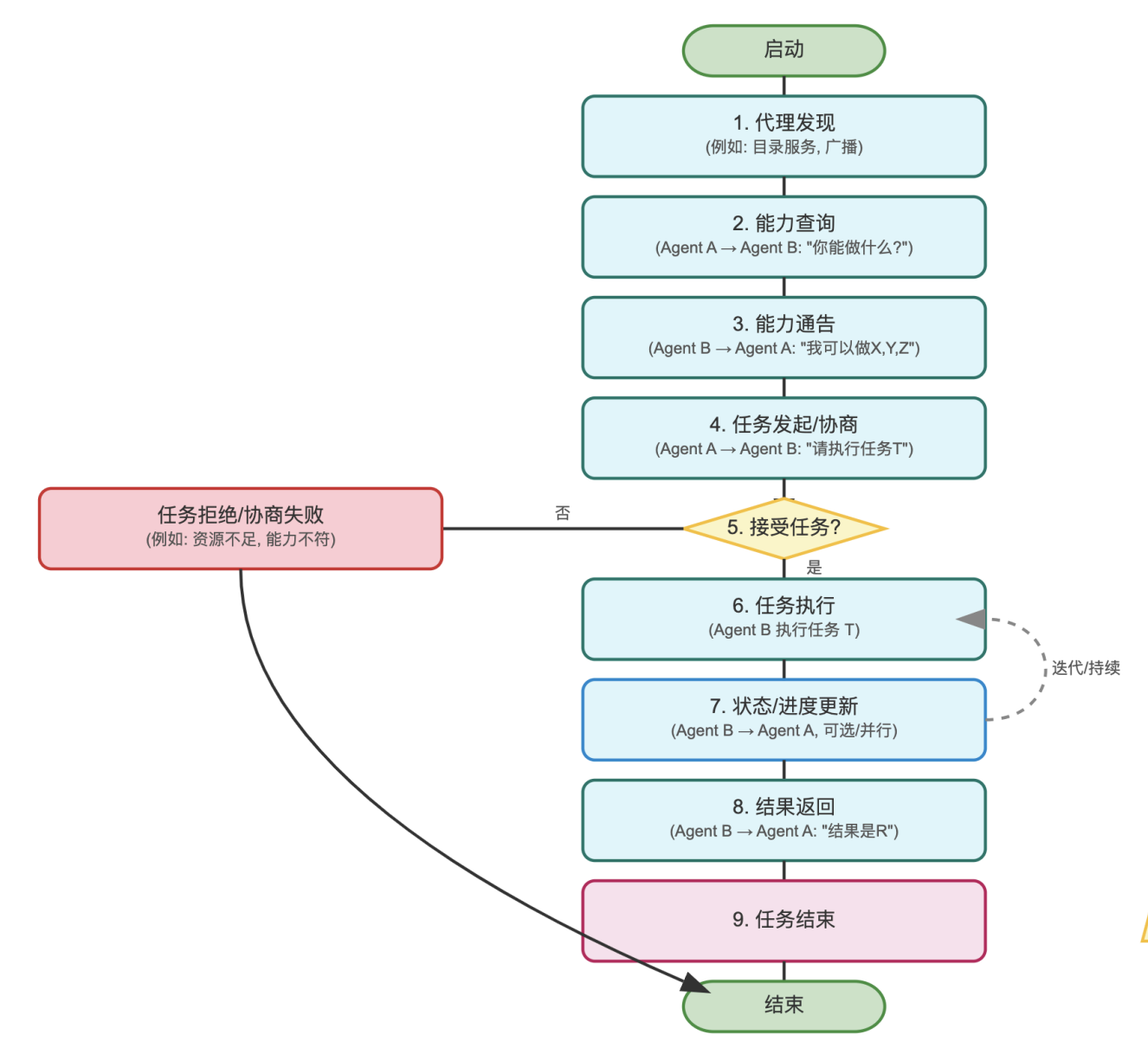
ANP: 智能体对智能体, 网络
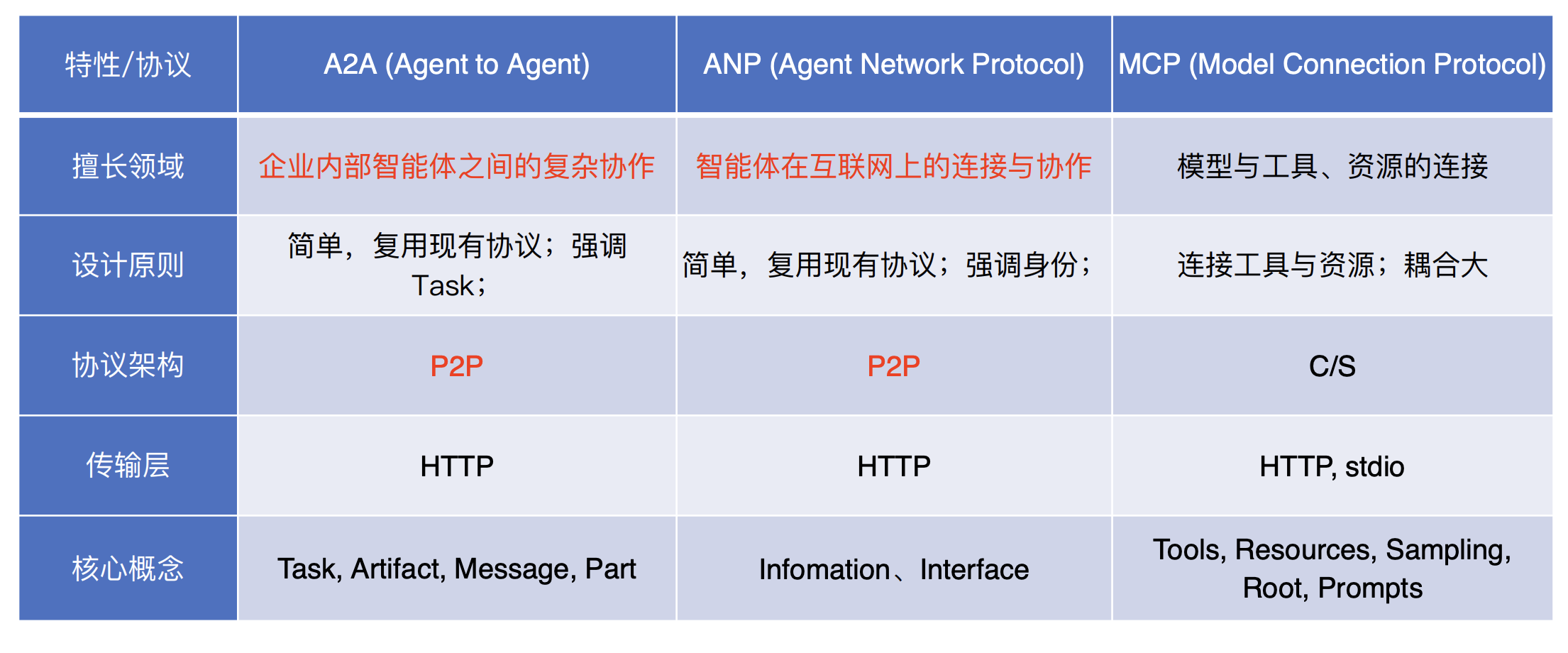
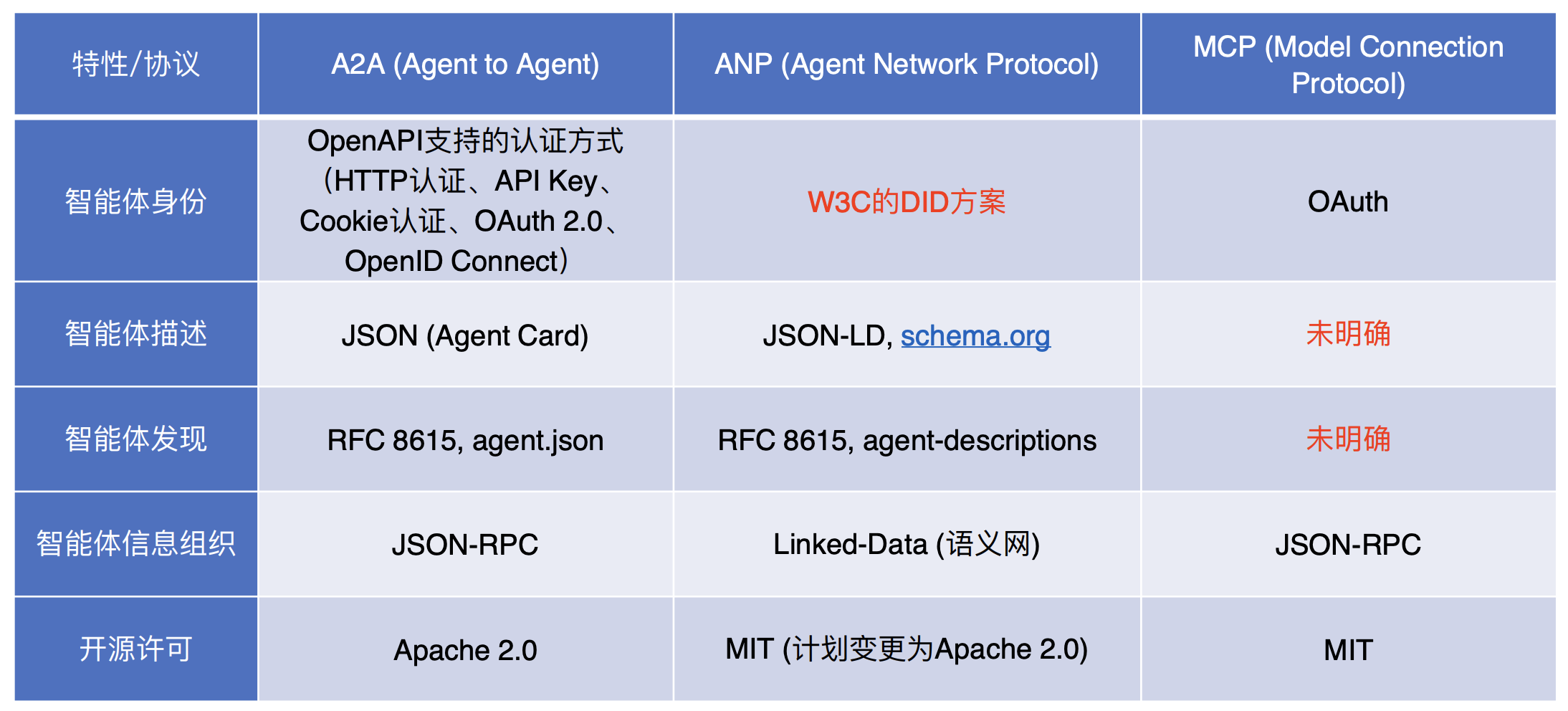
MCP vs A2A vs ANP
端侧agent开发
移动端: adb
pc端: pcauto
AI原生应用架构白皮书
AI原生应用架构:
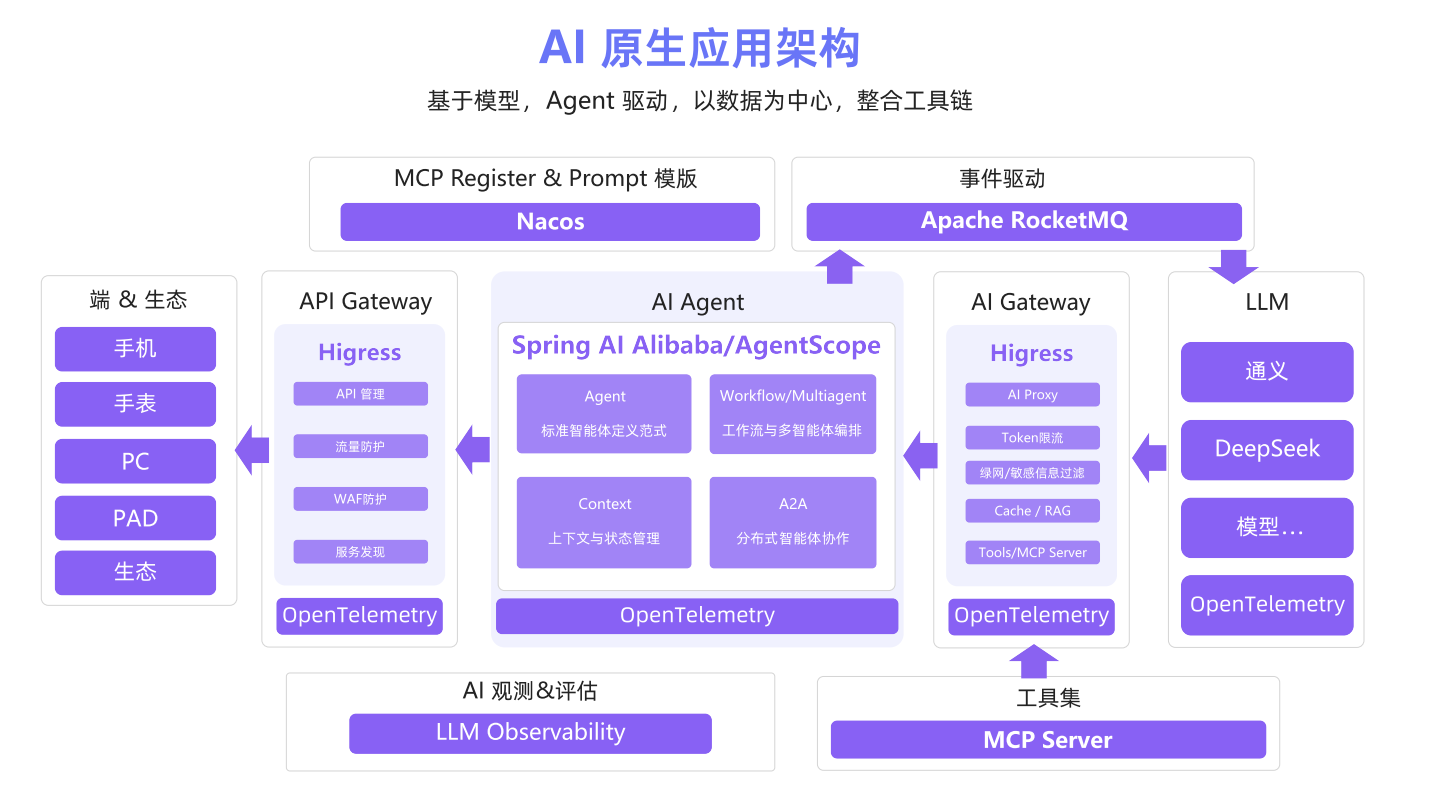
Higress: Higress 是一款基于 Istio 和 Envoy 构建的云原生 API 网关1。它源自阿里巴巴内部实践,具备先进的 AI 功能,可提供流量网关、微服务网关、安全网关三合一的高集成能力
OpenTelemetry: OpenTelemetry(简称 OTel)是一套由 CNCF(Cloud Native Computing Foundation,云原生计算基金会) 托管的开源可观测性框架,旨在统一分布式系统的 追踪(Tracing)、指标(Metrics)、日志(Logging) 数据采集与处理标准,解决传统可观测性工具碎片化、数据孤岛的问题。它的核心目标是提供 “vendor-agnostic(厂商无关)” 的标准化方案,让开发者无需绑定特定监控平台,即可构建全链路可观测能力。
AI 原生应用架构成熟度能力模型:
- 自然语言交互能力
- 多模态理解与生成的能力
- 动态推理与自主决策能力
- 持续学习与送代能力
- 安全可信
模式:
- CoT:一步步写过程
- Self-Ask:拆分成小问题
- ReAct:既思考也动手
- Plan-Execute:先计划再执行
- TOT:树状多分支探索
- Reflexion:自我反思迭代
- Role-playing:多人协作分工
RAG的迭代
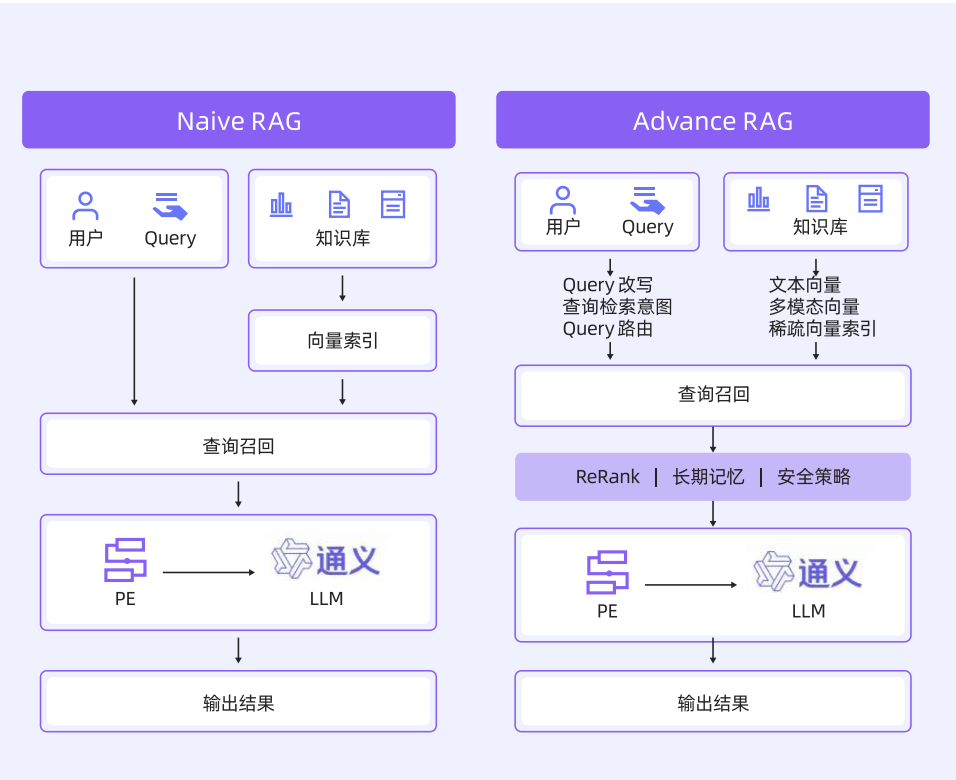
知识库:
- 文本向量
- 多模态向量
- 稀疏向量索引
用户搜索阶段:
- query改写
- 查询检索意图
- Query路由
召回阶段:
- rerank
- 长期记忆
- 安全策略
AI 网关
目的:
- 策略路由(token计价, 延迟, 显存占用), 故障转移
- 成本控制:语义缓存, 流量控制
- 企业合规
- 数据采集和观测
核心能力:
- 多模型代理, 多模型回退/容灾
- 消费者认证
- 内容安全防护
- Token限流
- 语义缓存
- 可观测性
- mcp代理
- 工具的动态组装: 这里没看懂: 请求携带大量工具通过API网关时, 可以通过query改写+ rerank模型对大量工具进行压缩
- 工具智能路由
可观测:
一个完整的 AI可观测体系,应具备3大核心能力:
- 端到端全链路追踪
- 全栈可观测
- 自动化评估功能: 通过引入评估 Agent
- 在线: A/B Test框架
- 离线
评估
- 语义评估从文本中提取实体、格式、抽象语义(如意图、情绪、主题)等多层次信息,并生成相关问题以深化理解。
- 例如,对 Prompt 进行语义评估时,分析其是否含歧义、信息缺失或逻辑矛盾。
- Rag 评估则针对从知识库中召回语料的质量进行多维度衡量,包括
- 检索准确性(找到最相关的知识片段)、
- 生成内容可靠(回答不偏离事实)、
- 重复性
- 多样性等指标。
- 工具调用评估针对需要执行动作的 AI 原生应用,评估其工具调用的合理性与效率。
- 合理
- 效率
- 端到端的 Agent 评估
prompt
- 核心任务或目标:明确智能体需要完成什么工作。
- 性格或角色(Persona):定义智能体的交流风格,例如,“你是一个乐于助人的助手”或“你是一位言辞诙谐的海盗”
- 行为约束:为其行为设定限制,例如,“只回答关于X的问题”或“绝不能透露Y信息”
- 如何及何时使用工具(Tools):您需要在此解释每个工具的用途以及在何种情况下应该调用它作为工具自身描述的补充说明。
- 期望的输出格式:指定其最终响应的格式,例如,“以JSON 格式回应”或“提供一个项目符号列表”。
具体要求:
- 清晰具体:避免模糊不清的表述。明确地陈述期望的动作和结果。
- 使用 Markdown: 对于复杂的指令,可以使用标题、列表等 Markdown 格式来提高可读性。
- 提供示例(Few-Shot Learning)
- 引导工具使用: 不要仅仅罗列工具有哪些,更要解释智能体何时(when)以及为何(why)应该使用它们。
Spring AI
三种类型:
- ReactAgent
- FlowAgent: SequentialAgent, ParralelAgent, LoopAgent, LlmRoutingAgent
- A2ARemoteAgent:
A2A 协议:
- Agentcard(智能体卡片)
- 一个JSON 格式的元数据文档,通常位于固定URL(如/well-known/agent-card.json)用于描述 A2A 服务端的能力。
- 包含智能体身份(名称、描述)、服务端点 URL、版本号、支持的 A2A功能(如流式传输或推送通知)、提供的技能列表、默认输入/输出模式及鉴权要求。
- 客户端通过解析该文档发现智能体,并获取安全交互的规范。
- Task(任务)
- 当客户端向智能体发送请求时,若需通过状态化流程完成任务(如生成报告、预订航班)智能体会创建唯一任务 ID 并维护其生命周期(提交、处理中、需输入、完成、失败)
- 任务支持多次客户端与服务端的交互,涵盖复杂场景的多轮通信,
- Message(消息)
- 客户端与服务端单次通信的基本单元,包含以下属性:
- 角色:user(客户端发送)或 agent(服务端发送)。
- 消息ID:由发送方生成的唯一标识。
- 内容块(Part):承载实际数据的结构化内容(如指令、问题、状态更新)。
- 主要用于非任务产出的普通通信场景,即同步请求的单次调用回复。
- 客户端与服务端单次通信的基本单元,包含以下属性:
- Artifact(产出物)
- 任务完成后返回的实体化结果(如文档、图片、结构化数据),由多个内容块(Part)构成,支持流式增量传输。
- 建议任务完成时通过该对象返回最终输出
- Part(内容块)
- eMessage(消息)或 Artifact(产出物)中的最小内容单元,支持多类型数据文本块(TextPart):
- 纯文本内容。
- 文件块(FilePart):文件数据(通过 Base64 内联或 URI 引用传输),含文件名、媒体类型等元数据。
- 数据块(DataPart):结构化JSON数据(如表单参数、机器可读信息)
- eMessage(消息)或 Artifact(产出物)中的最小内容单元,支持多类型数据文本块(TextPart):
交互机制
- 轮询(Polling)
- 轮询通过传统的 请求/响应 方式实现
- 客户端发起请求(如调用 message/send RPC方法),服务端返回即时响应
- 长任务场景:若需状态化长时运行任务,服务端可能返回“处理中”状态,客户端需周期性调用 tasks/get 轮询获取状态更新,直至任务完成或失败。
- 流式传输(Streaming)
- 流式传输通过SSE(Server-Send Events)方式实现
- 适用场景:需增量生成结果或实时进度反馈的任务。
- 流程:
- 客户端通过 message/stream 发起交互
- 服务端保持 HTTP 连接开放,持续发送 SSE事件流(包括 Task、Message、状态变更的 TaskStatusUpdateEvent 或产出物更新的 TaskArtifactUpdate Event )。
- 前置条件:服务端需在智能体卡片(AgentCard)中声明流式传输支持能力。
- 推送通知(Push Notifications)
- 推送通知通过 WebHoook 方式实现
- 适用场景:超长耗时任务或SSE长连接不可行的场景
- 流程:
- 客户端在任务初始化时提供回调 URL(通过 tasks/pushNotificationconfig/set配置)
- 当任务状态变更(完成、失败或需输入)时,服务端向该URL发送异步HTTPPOST通知。
- 前置条件:服务端需在智能体卡片(AgentCard)中声明推送通知支持能力。
A2A协议工作流:
- 发现A2A Server的AgentCard
- A2A 授权和权限认证: 认证生命, 平局传递
- 发起A2A请求: 同步请求, 流失请求
基于Nacos
AgentCard:
- 身份信息:名称、描述、服务提供方。
- 服务端点:远端 Agent 的访问URL,包含完整的域名/IP,端口,URI等,
- 协议能力:支持的协议功能(如流式传输streaming 或推送通知 pushNotifications)
- 认证方式:交互所需的鉴权机制(如 Bearer令牌、OAuth2)
- 技能列表:智能体可执行的任务或功能(AgentSkill对象),含技能ID、名称、描述、输入/输出模式及示例。
消息队列:
目标:
- 支持长会话与大消息体的消息中枢,
- 实现削峰填谷、定速消费的智能调度能力。
- 提供优先级、权重控制的分级事件驱动机制。
- 构建高可靠、可恢复的 Agent 编排引擎。
上下文工程
组成部分:
- 外部知识库的动态供给:RAG
- 索引:
- 文档解析提取:
- 文本分块:
- 基本策略: 固定分块, 基于句子或者段落, 语义分块(计算相邻单元语义相似度)
- 高级策略:
- 滑窗、
- 小块检索+大块生成(父子文档映射, 子块去做映射,增强时返回父块),
- 元数据标注和过滤(为每个文本块增加信息)
- 语义向量化:
- 构建向量索引库:
- 索引策略:
- 层次化索引
- 多模态内容: 表格(转为markdown或json, 或摘要, 或单独索引), 图像(OCR提取内容文字, 并结合图像描述模型Image Captioning生成描述)
- 索引策略:
- 检索: top-k
- 查询理解与增强:
- 查询改写扩充: Rewrite-Retrieve-Read
- 复杂问题分解
- 假设性文档嵌入: 先用LLM生成一个假设答案, 然后用答案去查
- 多路召回、混合检索:
- 向量检索 + 关键词匹配
- RRF(Reciprocal Rank Fusion, 倒数排名融合)
- 结果精炼 + 上下文重组
- 重排序(Rerank): Cross Encoder, 将query 和文档放到一个transformer模型里计算分数
- 自动合并检索: 父子块那个
- 查询理解与增强:
- 生成: 构建一个增强的提示词:
-
请根据以下提供的上下文信息来回答用户的问题。如果上下文信息不足以回答,请明确告知。 上下文: [检索到的知识块1] [检索到的知识块2] 问题: [用户的原始查询1]
-
- 问题:
- 知识单元完整性、信息密度: 截断导致语义不完整。 文档中的页眉页脚、广告等稀释语义
- 用户意图模糊、多样
- 召回匹配难以兼顾语义相关性、和关键词精确性
- 检索精度和完整性需要平衡: 精度高,内容多, 上下文窗口消耗大, 且容易中间遗忘
- 多知识点Multi-hop: GraphRAG(直接寻找关联), 多次搜索
- 未来方向:
- Agentic RAG: 自动评估检索质量,确认是否要继续检索
- 多模态RAG:
- 知识图谱与RAG的结合
- 索引:
- 长期、短期记忆系统
- 问题: 成本升高与性能下降, 中间遗忘, 信息噪声
- 运行时上下文处理:写入, 选择, 压缩(trim/filter), 隔离(针对多智能体)
- 短期记忆管理策略:
- 滑动窗口
- 关键信息保留
- 定期清理
- 长期记忆:
- 定期提取
- 搞笑检索
- 版本管理
- 长短期转化时机:
- 对话自然结束时
- 识别到重要特征时
- 定期摘要
- 工具、能力扩展
- api网关: HiMarket, 集成mcp 和AI网关
- Nacos 3.0: mcp registry + mcp router
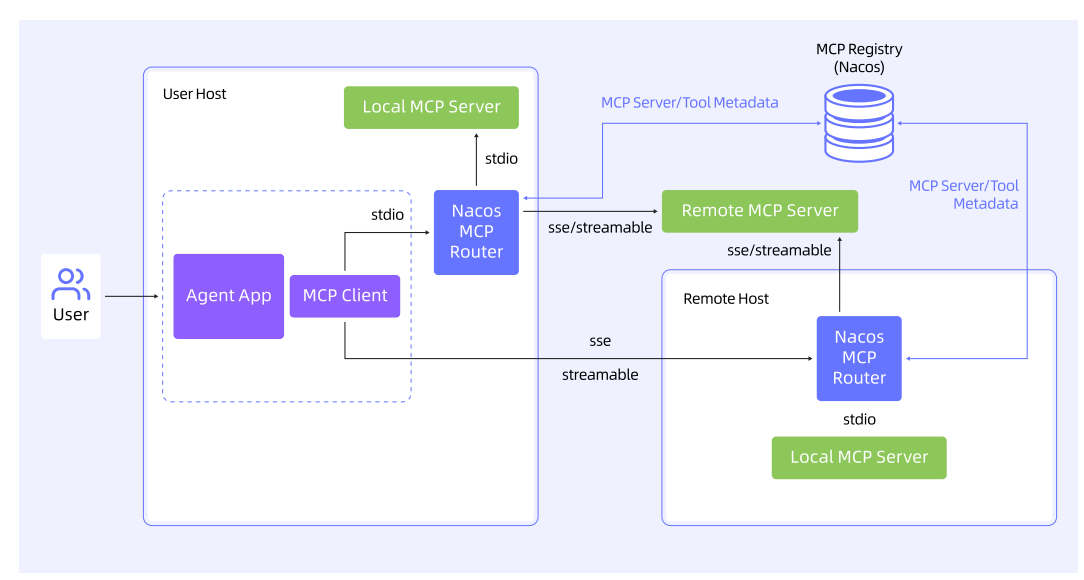
- 运行时上下文管理(上下文压缩 + 摘要, rerank(用于解决中间遗忘问题, 将重要的内容留在模型关注的位置))
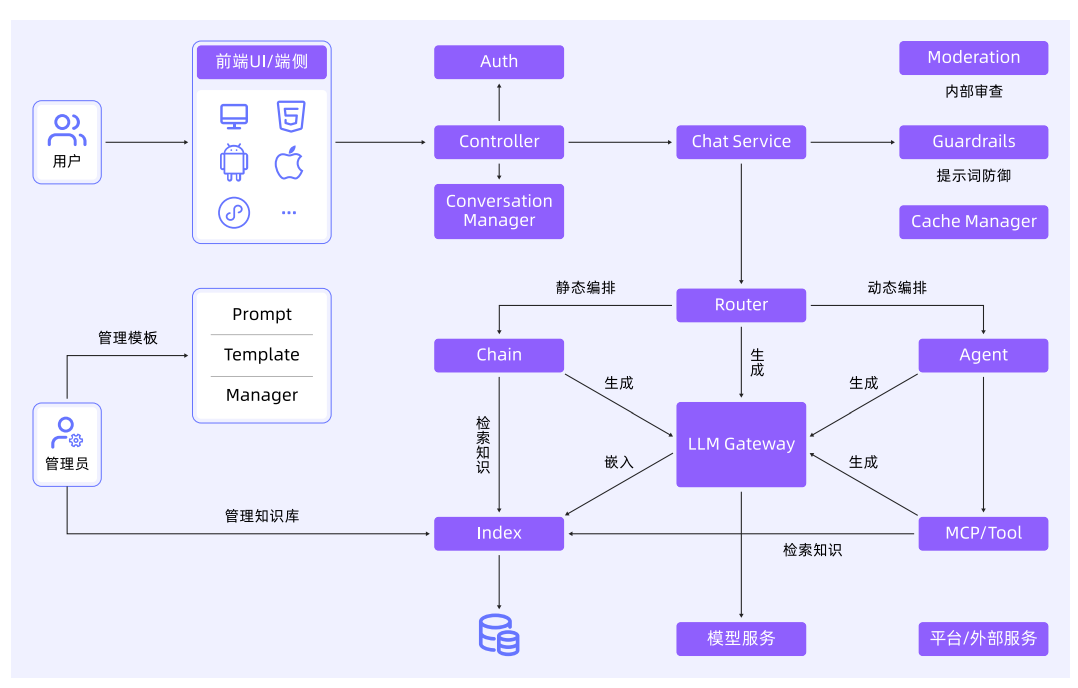
应用架构:
使用AI网关快速构件应用: ChatGPT-Next-Web (typescript)

agent ai 应用趋势:
- 交互式智能创作助手: 多轮对话, 异构任务流, 上下文记忆, 流式响应
- 个性化AI客服: 事件驱动, 监听+ 推送服务
- AIGC创意应用
工具:
- MCP
- File Search(RAG , 文件检索)
- Image Generation(图像生成)
- Code Interpreter(沙箱 + 多语言运行环境)
- Browser Use(浏览器使用)
- Computer Use(键盘鼠标操作)
- Mobile Use(手机使用)
复杂工具使用需要关注的内容:
- 隔离与安全
- 状态管理与成本
- 可扩展性与运维
AI可观测
全链路:
观测框架 OpenTelemetry(Trace?)
核心技术:
- 链路插桩技术: python 探针(monkeypatch埋点), java探针, 各种探针
- 链路采集预加工
- LLM Trace查询分析
llm推理需要关注的内容:
- API Server: 路径, 状态码, 客户端类别,耗时
- 模型输入输出: 提示词,响应方式,模型名称,最大token数, 温度,top-k(k个词), top-p (概率值), N (建议答案数量)
- 推理过程: e2e时间, 首token时间, prefill 时间, decode时间, 等待时间, token间隔时间
- 推理引擎状态:
- 运行中请求数
- 等待请求数
- 被抢占请求数
- KV Cache使用率
- 总提示词Token数量
- 总生成Token数量
- 处理成功的请求数
评估:
6个评估范式
- 基准测试范式: GLUE
- Evals范式: 对抗性测试, 红队演练
- 心里测量学范式
- 人机交互范式
- 形式化方法
- 社会技术范式
整体性评估(8核心):
- 性能指标
- 鲁棒性与泛化测试
- 偏见与公平性评估
- 可解释性: LIME, SHAP
- 合规性和伦理: 欧盟GDPR(通用数据保护条例), AI Act(人工智能法案)
- 持续监控与模型飘逸检测
- 决策框架
- 自动化与人在回路
LLM作为打分工具:
- 系统性偏见: 位置偏见, 冗长偏见, 自我偏好偏见,情绪与语气偏见, 评分力度优先
- 递归依赖(打分llm和评分llm互相正相关, 要不懂都不懂): 能力天花板, 推理幻觉
提升llm打分工具可靠性的策略:
- 提示工程技术: cot, few-shot prompting, 清晰的评分指南prompt
- 结构化缓解措施: 交换位置(成对比较之后, 换下前后位置), 基于参考的评分, 约束裁判输出
- sft 的评分模型, 多个裁判
- 高质量数据集
云原生的评估系统
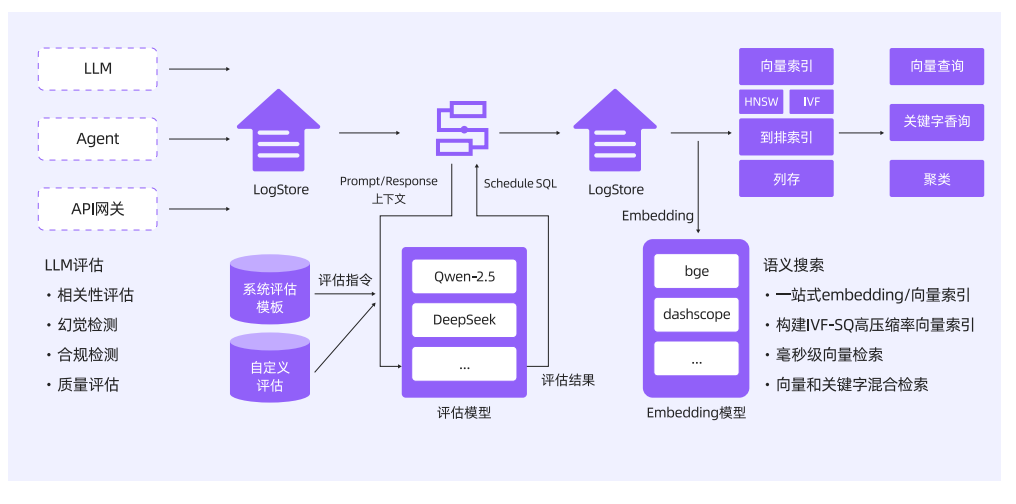
评估场景:
- 通用场景评估: 准确度,计算器正确性,简洁性,包含代码,包含个人身份信息,上下文相关性,禁忌词,幻觉,仇视言论,有用性,语言检测器,开源,问题与Python相关,毒性
- 语义评估: NER, 重点词抽取, 数值信息抽取, 抽象信息抽取(意图识别, 文本摘要, 情绪分类, 主题分类, 角色分类, 语言分类), 生成相关问题
- rag评估:
- 召回语料和问题的相关性
- 召回语料和答案的相关性
- 语料是否重复
- 语料多样性
- agent评估
- 指令是否清晰
- 规划是否有错误
- 任务是否复杂
- 执行路径是否有错误
- 最终目标达成
- 执行路径是否简介
- 工具使用评估
- 规划是否调用工具,
- 参数错误时是否修正
- 工具调用正确
- 参数是否有错误
- 工具调用效率
- 工具是否合适
安全:
风险类型: 系统风险, 网络风险, 身份风险, 数据风险, 模型风险, 应用风险
高危场景:
- 输入层威胁:
- 对抗样本攻击(如通过微调图像/音频诱导多模态Agent误判)、
- 提示词注入(PromptInjection)的变种攻击(如上下文分割攻击、语义混淆攻击),
- 通过恶意文件(如PDF隐写术)触发供应链漏洞;
- 推理层威胁:
- 模型越狱(Jailbreaking)导致的伦理失控、
- RAG知识库的定向爬取(PromptCrawling)引发的数据资产泄露,
- 函数调用劫持(如篡改API参数执行未授权操作):
- 输出层威胁:
- 涉及生成式钓鱼内容(如伪造银行通知)、
- 模型幻觉(Hallucination)在医疗/金融场景的致命误导,
- 以及通过隐写术(Steganography)在AIGC内容中植入隐蔽指令。
防护维度
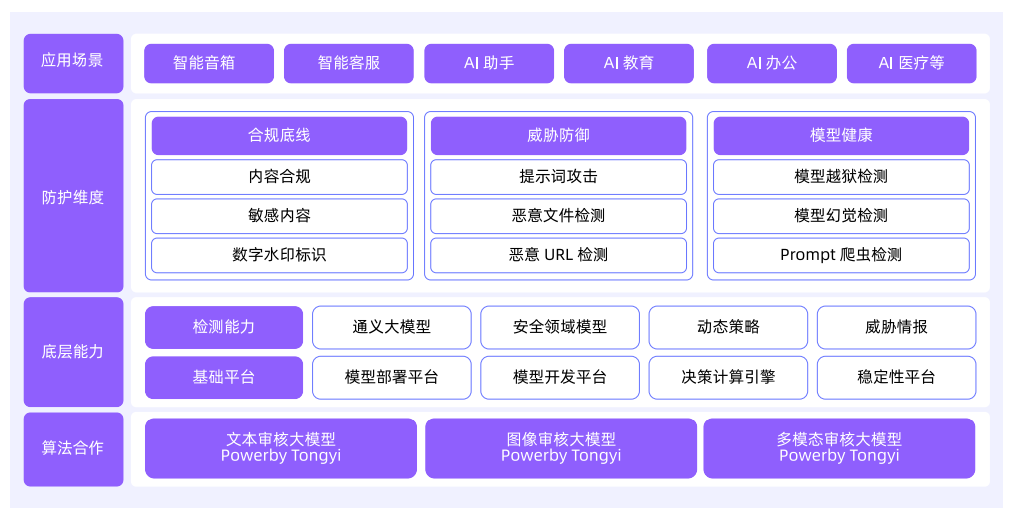
模块:
- 内容合规审核
- 提示词攻击防御: ignore previous instructions
- 敏感信息防护
- 恶意文件检测
- 恶意URL拦截
- 提示词反爬机制
- 模型越狱检测
- 模型幻觉抑制
- 数字水印标识
数据资产保护:
- 数据收集:
- 数据来源:
- 用户训练/测试, RAG知识库, 多模态
- 模型文件 + 推理数据
- 运行日志
- 数据分类
- 数据脱敏
- 数据去毒
- 数据来源:
- 数据传输: 数据传输提供私有网络加密,提示词推理加密,应用协议加密
- 数据存储: 存储隔离, 存储加密
- 数据访问
- 数据处理
- 数据删除
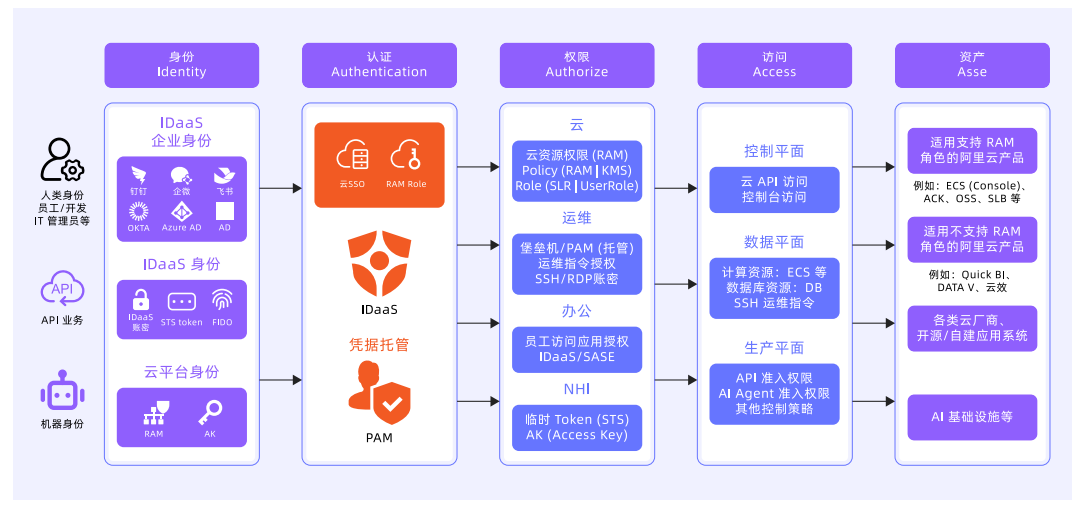
身份安全(NHI non-human identity): 事前检测和风险识别, 事中动态分配+用完收回/超时 + 细粒度,事后审计 + 对抗训练
重要问题
2025年12月25日
问题来源:
影响范围:
- 影响所有存在env中的秘钥
- 所有使用streaming, 缓存, 消息历史的应用
原理:
langchain会给tool_call等request内部加一个lc的标签, 用来区分langchain自己的序列化对象和用户的。 但dumps()函数中忘了检查用户输入是否含有这个标记。 通过设计prompt使response中生成含lc的标签, 并流入additional_keywards/response_metadata流入系统, 在streaming/缓存/消息历史中被序列化, 反序列化的时候使这些lc被使用。
问题带来的思考:
langchain模糊了problem solving阶段的一个边界。 将所有需求都委托给agent进行处理,导致在非必要的阶段进行了授权。llm输出/additional_kwards/response_metadata变成了半可信
比较合理方式是直接通过llm如openai的一些接口, 而不是使用langchain这种比较厚重的方式。
处理方式:
快速的解决方式是: 升级langchain到1.2.5/0.3.81, python到14
高危流程:
- astream_events(version="v1")
- Runable.astream_log()
- RunnableWithMessageHistory
- InMemoryVectorStore.load()
- hub.pull
- 自定义的缓存实现
归纳为不信任原则:
- additional_kwards
- response_metadata
- tool输出
- retrieved documents
- 消息历史
llm的输出不是可信对象
注意:
- langchain相当于增加抽象层, 但凡增加一层, 对安全就有代价。
- AI的安全模型还在早期, 需要更多的考虑信任边界
langchain入门视频:
langchain 1.0版本更新:
- middleware
- human in the loop(人机集成)
Agent协议:
- agent->tools: MCP
- agent->agent: A2A

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)