RAG从入门到精通(三)——非结构化数据读取与导入
在 LangChain 中, 是处理文本数据的核心数据结构,用于封装原始文本内容及相关元数据,是连接文档加载、分割、存储、检索等环节的基础载体。 的设计目的是标准化文本数据的表示形式,让不同来源(如网页、PDF、本地文件等)、不同格式的文本都能以统一的结构在 LangChain 流程中流转(例如分块、嵌入、检索等)。 是 LangChain 中文本数据的标准化容器,通过存储核心文本,通过携带额外信
1. 读取单个txt文件
# 读取单个txt文件
import os
from langchain_community.document_loaders import TextLoader
# 获取当前脚本文件所在的目录
script_dir = os.path.dirname(__file__)
print(f"获取当前脚本文件所在的目录:{script_dir}")
# 结合相对路径构建完整路径
file_dir = os.path.join(script_dir, '../../90-文档-Data/黑悟空/设定.txt')
loader = TextLoader(file_dir, encoding='utf-8')
documents = loader.load()
print(documents)

2. Document 数据结构
在 LangChain 中,Document 是处理文本数据的核心数据结构,用于封装原始文本内容及相关元数据,是连接文档加载、分割、存储、检索等环节的基础载体。
2.1 Document 的核心作用
Document 的设计目的是标准化文本数据的表示形式,让不同来源(如网页、PDF、本地文件等)、不同格式的文本都能以统一的结构在 LangChain 流程中流转(例如分块、嵌入、检索等)。Document 是 LangChain 中文本数据的标准化容器,通过 page_content 存储核心文本,通过 metadata 携带额外信息,确保了从数据加载到最终生成的全流程兼容性和可追溯性,是构建 RAG 等应用的基础组件。
2.2 Document 的核心属性
Document 类的定义简化后如下(核心字段):
class Document:
page_content: str # 文档的核心文本内容
metadata: dict # 文档的元数据(额外信息)
-
page_content- 类型:字符串(
str) - 作用:存储文档的原始文本内容,是后续处理(如分块、嵌入、生成回答)的核心依据。
- 示例:
page_content = "黑神话悟空的战斗系统融合了武侠风格,招式灵动且富有冲击力。"
- 类型:字符串(
-
metadata- 类型:字典(
dict) - 作用:存储与文本相关的额外信息,辅助后续检索、过滤或溯源。
- 常见元数据字段(按需自定义):
source:文本来源(如文件路径、网页 URL);page:页码(适用于 PDF 等分页文档);author:作者;created_at:创建时间等。
- 示例:
metadata = {"source": "https://zh.wikipedia.org/wiki/黑神话:悟空", "page": 1}
- 类型:字典(
2.3 为什么需要 Document?
- 标准化:无论文本来自网页、PDF 还是 TXT,都被封装为
Document对象,确保后续处理逻辑(如分块、嵌入)无需适配不同格式。 - 元数据跟踪:在文档分块后,元数据会被继承到子文档中,方便追溯回答的来源(例如“该信息来自某网页的第 3 段”)。
- 扩展性:可通过自定义元数据添加业务相关信息(如标签、优先级),支持更灵活的检索和过滤。
2.4 使用示例
from langchain_core.documents import Document
# 创建一个 Document 对象
doc = Document(
page_content="72变是黑神话悟空的核心技能,可化身不同形态探索世界。",
metadata={"source": "游戏设定文档", "category": "技能介绍"}
)
# 访问内容和元数据
print(doc)
print(doc.page_content) # 输出:72变是黑神话悟空的核心技能...
print(doc.metadata) # 输出:{"source": "游戏设定文档", "category": "技能介绍"}

2.5 在 RAG 流程中的作用
在检索增强生成(RAG)中,Document 是数据流转的“载体”:
- 加载阶段:文档加载器(如
WebBaseLoader、PyPDFLoader)将原始数据解析为Document对象(自动填充page_content和基础元数据,如source)。 - 分块阶段:文本分割器(如
RecursiveCharacterTextSplitter)将长Document拆分为多个短Document(子文档继承原文档的元数据)。 - 存储阶段:
Document的page_content被转换为向量存入向量库,metadata随向量一起存储,用于检索时的过滤或展示。 - 检索阶段:检索到的相关
Document会被传入大模型,其page_content作为上下文,metadata可用于标注答案来源。
3. 基于LangChain加载目录中所有文档
# 使用 LangChain 加载目录中所有文档
"""
# 需要安装 Tesseract OCR
### Ubuntu 执行如下命令:
sudo apt update
sudo apt install tesseract-ocr -y
### 说明
DirectoryLoader 在加载目录时,会尝试为遇到的不同文件类型找到合适的加载器。
对于 .pptx (PowerPoint)、.pdf 和 .jpg 等复杂格式,DirectoryLoader 通常会依赖 unstructured 库来处理。
unstructured 库在处理某些文件类型(特别是需要进行文本提取和处理的)时,会依赖 nltk (Natural Language Toolkit) 库。
nltk 库需要下载一些额外的数据包(如分词器、词性标注器等)才能正常工作。
如果遇到错误 zipfile.BadZipFile: File is not a zip file
这是发生发生在 nltk.data.py 内部,这强烈表明 nltk 在尝试加载其数据包时遇到了问题。
它尝试打开一个文件作为 zip 压缩包来查找数据,但该文件不是一个有效的 zip 文件。
您好!
根据您提供的错误信息和文件列表,问题出在 langchain_community.document_loaders.DirectoryLoader 尝试加载目录中的 .pptx 文件时。
根本原因分析:
DirectoryLoader 在加载目录时,会尝试为遇到的不同文件类型找到合适的加载器。
对于 .pptx (PowerPoint)、.pdf 和 .jpg 等复杂格式,DirectoryLoader 通常会依赖 unstructured 库来处理。
unstructured 库在处理某些文件类型(特别是需要进行文本提取和处理的)时,会依赖 nltk (Natural Language Toolkit) 库。
nltk 库需要下载一些额外的数据包(如分词器、词性标注器等)才能正常工作。
您的错误 zipfile.BadZipFile: File is not a zip file 发生在 nltk.data.py 内部,这强烈表明 nltk 在尝试加载其数据包时遇到了问题。它尝试打开一个文件作为 zip 压缩包来查找数据,但该文件不是一个有效的 zip 文件。
结论: 错误不是因为您的 .pptx 文件本身损坏,而是因为 unstructured 调用 nltk 时,nltk 找不到或无法正确加载其所需的数据包,导致了 BadZipFile 错误。当只有 .csv 文件时,DirectoryLoader 可能使用了一个不依赖 unstructured 或 nltk 的简单加载器,所以没有报错。
#解决方案:
# 最直接的解决方案是
# 下载 NLTK 所需的数据包。需要在你的 Python 环境中运行以下代码一次
import nltk
nltk.download('averaged_perceptron_tagger')
nltk.download('punkt')
"""
import os
from langchain_community.document_loaders import DirectoryLoader
# 获取当前脚本文件所在的目录
script_dir = os.path.dirname(__file__)
print(f"获取当前脚本文件所在的目录:{script_dir}")
# 结合相对路径构建完整路径
data_dir = os.path.join(script_dir, '../../90-文档-Data/黑悟空')
loader = DirectoryLoader(data_dir)
docs = loader.load()
print(f"文档数:{len(docs)}") # 输出文档总数
print(docs[0]) # 输出第一个文档
批量加载多格式文档的预处理步骤,目的是将指定目录中(90-文档-Data/黑悟空)的所有文档统一转换为 LangChain 可处理的 Document 格式,为后续构建 RAG 问答系统(分块、向量存储、检索等)做准备。
3.1 读取文档时指定参数
from langchain_community.document_loaders import DirectoryLoader
import os
# 获取当前脚本文件所在的目录
script_dir = os.path.dirname(__file__)
print(f"获取当前脚本文件所在的目录:{script_dir}")
# 结合相对路径构建完整路径
data_dir = os.path.join(script_dir, '../../90-文档-Data/黑悟空')
loader = DirectoryLoader(data_dir,
glob="**/*.md",
use_multithreading=True,
show_progress=True,
)
docs = loader.load()
print(f"文档数:{len(docs)}") # 输出文档总数
print(docs[0]) # 输出第一个文档
使用 LangChain 的 DirectoryLoader 加载指定目录中的文档,但相比之前的版本增加了更具体的配置,专注于加载目录中所有 Markdown(.md)格式的文件。以下是详细解释:
- 关键参数详解:
glob="**/*.md":glob是文件匹配模式,**表示递归遍历所有子目录,*.md表示只匹配后缀为.md的 Markdown 文件。这一步会过滤掉目录中其他格式的文件(如.txt、.pdf等),只保留 Markdown 文档。use_multithreading=True:
启用多线程加载,当目录中文档数量多或文件较大时,能显著提高加载速度(避免单线程逐个加载的等待时间)。show_progress=True:
加载过程中显示进度(例如“已加载 3/10 个文件”),方便观察加载状态,避免因文件多而误以为程序未响应。
相比未指定 glob 的版本,这段代码的针对性更强:
- 只加载 Markdown 文件:通过
glob="**/*.md"过滤无关格式,避免加载不需要的文件(节省资源,提高效率)。 - 优化加载体验:多线程加速和进度显示让加载过程更高效、更透明。
3.2 指定加载工具
DirectoryLoader 的设计允许通过 loader_cls 参数自定义具体文件的加载器,原因如下:
- 默认逻辑的补充:
DirectoryLoader会默认根据文件后缀自动选择加载器(例如.md用UnstructuredMarkdownLoader,.txt用TextLoader),但有时需要强制使用特定加载器(比如希望用更简单的TextLoader处理.md文件)。 - 灵活性需求:不同加载器对同一种文件的处理方式可能不同(例如
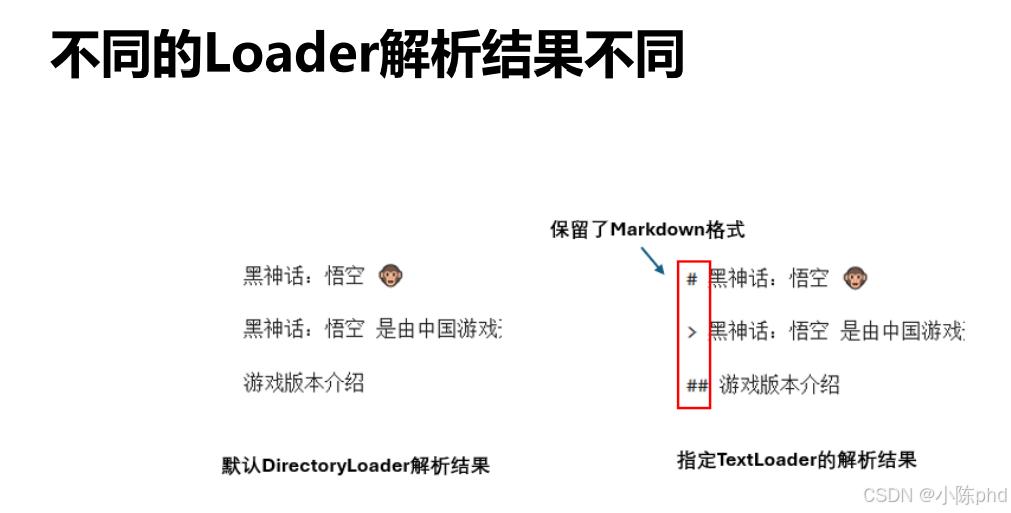
TextLoader直接读取纯文本,而UnstructuredMarkdownLoader会解析 Markdown 格式并保留结构),通过loader_cls可以按需选择。
TextLoader是 LangChain 中最简单的文本加载器,功能是直接读取文件的原始文本内容(忽略格式,仅提取字符)。- 对于
.md(Markdown)文件,默认加载器可能会解析标题、列表等格式并转换为结构化文本,而指定TextLoader后,会直接读取.md文件的原始内容(包括#、*等 Markdown 语法符号)。
当你: - 不需要解析文件格式(如 Markdown 的标题、表格),只需要纯文本内容时;
- 发现默认加载器对某种文件处理有问题(如格式错乱),想换一种更简单的加载方式时;
- 希望统一不同文件的加载逻辑(例如用
TextLoader处理.txt、.md等所有文本类文件)时。
可以通过 loader_cls 指定加载器,增强灵活性。
from langchain_community.document_loaders import DirectoryLoader, TextLoader
import os
# 获取当前脚本文件所在的目录
script_dir = os.path.dirname(__file__)
print(f"获取当前脚本文件所在的目录:{script_dir}")
# 结合相对路径构建完整路径
data_dir = os.path.join(script_dir, '../../90-文档-Data/黑悟空')
# 加载目录下所有 Markdown 文件
loader = DirectoryLoader(data_dir,
glob="**/*.md",
loader_cls=TextLoader # 指定加载工具
)
docs = loader.load()
print(docs[0].page_content[:100]) # 打印第一个文档内容的前100个字符
3.3 跳过错误文件
通过设置 silent_errors=True 实现了 “跳过加载失败的文件” 的功能,专门用于处理目录中存在非文本文件(如图片、二进制文件等)导致的加载错误。
from langchain_community.document_loaders import DirectoryLoader, TextLoader
# 加载目录下所有文件,跳过出错文件,因为有些文件是图片,TextLoader 无法加载
import os
# 获取当前脚本文件所在的目录
script_dir = os.path.dirname(__file__)
print(f"获取当前脚本文件所在的目录:{script_dir}")
# 结合相对路径构建完整路径
data_dir = os.path.join(script_dir, '../../90-文档-Data/黑悟空')
# 加载目录下所有 Markdown 文件
loader = DirectoryLoader(data_dir,
silent_errors=True,
loader_cls=TextLoader
)
docs = loader.load()
print(docs[0].page_content[:100]) # 打印第一个文档内容的前100个字符
4. 基于LlamaIndex加载文档
from llama_index.core import SimpleDirectoryReader
# 使用 SimpleDirectoryReader 加载目录中的文件
dir_reader = SimpleDirectoryReader("90-文档-Data/黑悟空")
documents = dir_reader.load_data()
# 查看加载的文档数量和内容
print(f"文档数量: {len(documents)}")
print(documents[0].text[:100]) # 打印第一个文档的前100个字符
# 仅加载某一个特定文件
dir_reader = SimpleDirectoryReader(input_files=["90-文档-Data/黑悟空/设定.txt"])
documents = dir_reader.load_data()
print(f"文档数量: {len(documents)}")
print(documents[0].text[:100]) # 打印第一个文档的前100个字符
- SimpleDirectoryReader 作用:自动遍历指定目录(90-文档-Data/黑悟空)下的所有文件,根据文件类型(如 .txt、.pdf、.md 等)调用对应的解析器,将文件内容提取为 LlamaIndex 专用的 Document 对象。
- 核心特性:
支持多种常见文件格式(文本、PDF、Markdown 等),无需手动指定加载器。
会递归读取子目录中的文件(即目录下的子文件夹里的文件也会被加载)。
提取的内容存储在 Document 对象的 text 属性中,同时包含文件路径等元数据(如 doc_id、metadata)。
5. LlamaIndex-构建Document对象
Document 对象的作用:
- 标准化数据格式:将文本和元数据封装成统一结构,方便 LlamaIndex 后续处理(如分块、嵌入、检索等)。
- 元数据辅助检索:元数据可用于筛选文档(例如只检索 category=“游戏场景” 的文档),或在回答中标注信息来源(如 “该场景来自 火照深渊场景.md”)。
兼容 LlamaIndex 流程:Document 对象是构建向量索引(VectorStoreIndex)的输入,确保后续的 RAG 流程能正常运行。
from llama_index.core import Document
# 创建多个文档对象,并为其添加元数据
documents = [
Document(
text="一个充满烈焰和硫磺气息的地下洞窟,火焰从地底不断喷涌,照亮整个深渊。场景中有熔岩河流穿行,燃烧的火山石在空中漂浮。悟空需要利用自己的跳跃能力和金箍棒在熔岩之间穿行,同时对抗来自地狱的火焰妖怪。",
metadata={
"filename": "火照深渊场景.md",
"category": "游戏场景",
"file_path": "/data/黑悟空/火照深渊场景.md",
"author": "GameScience",
"creation_date": "2024-11-20",
"last_modified_date": "2024-11-21",
"file_type": "markdown",
"word_count": 28,
},
),
Document(
text="一片高耸入云的山脉,云雾缭绕,风力强劲。悟空需要通过飞跃山崖、利用筋斗云飞行,以及在大风中保持平衡来穿越场景。敌人主要是隐匿在云层中的飞禽妖怪和岩石机关兽。",
metadata={
"filename": "风起长空场景.md",
"category": "游戏场景",
"file_path": "/data/黑悟空/风起长空场景.md",
"author": "GameScience",
"creation_date": "2024-11-20",
"last_modified_date": "2024-11-21",
"file_type": "markdown",
"word_count": 28,
},
)]
# 打印每个文档的元数据
for doc in documents:
print(f"Metadata for {doc.metadata['filename']}:")
for key, value in doc.metadata.items():
print(f" {key}: {value}")
print("-" * 40)
将原始文本转换为 LlamaIndex 专用的 Document 对象,并通过 metadata 丰富文档信息。这一步是将非结构化文本(如游戏场景描述)纳入 LlamaIndex 处理流程的基础,为后续构建索引、实现精准问答提供数据支持。
6. unstructured解析非结构化数据
unstructured 库的核心价值是将非结构化文本(如原始 TXT、PDF)转换为结构化的元素列表,每个元素包含文本内容和元数据。这种结构化处理方便后续步骤(如导入 LangChain/LlamaIndex 构建文档、按段落检索等)。 unstructured 库解析 设定.txt 文件,将其拆分为按段落划分的 Element 元素,然后展示每个元素的文本内容、类型和元数据。本质上是文本预处理的一环,为后续的自然语言处理或 RAG 系统构建提供结构化的数据基础。
from unstructured.partition.text import partition_text
text = "90-文档-Data/黑悟空/设定.txt"
elements = partition_text(text)
for element in elements:
print(element)
# 通过vars函数查看所有可用的元数据
for i, element in enumerate(elements):
print(f"\n--- Element {i+1} ---")
print(f"类型: {type(element)}")
print(f"元素类型: {element.__class__.__name__}")
print(f"文本内容: {element.text}")
# 元数据展示
if hasattr(element, 'metadata'):
print("元数据:")
metadata = vars(element.metadata)
valid_metadata = {k: v for k, v in metadata.items()
if not k.startswith('_') and v is not None}
for key, value in valid_metadata.items():
print(f" {key}: {value}")
解析文本文件为结构化元素,展示每个段落的文本内容、类型及元数据.
from unstructured.partition.text import partition_text
text = "90-文档-Data/黑悟空/设定.txt"
elements = partition_text(text)
for element in elements:
print(element)
# 使用__dict__来查看所有可用的元数据
for i, element in enumerate(elements):
print(f"\n--- Element {i+1} ---")
print(f"类型: {type(element)}")
print(f"元素类: {element.__class__.__name__}")
print(f"文本内容: {element.text}")
if hasattr(element, 'metadata'):
print("元数据:")
metadata_dict = element.metadata.__dict__
for key, value in metadata_dict.items():
if not key.startswith('_') and value is not None:
print(f" {key}: {value}")
综上所述,总结使用,基于unstructured+langchain:
# 1. 安装依赖(如需运行,先执行以下命令)
# pip install langchain langchain-community langchain-text-splitters langchain-huggingface langchain-deepseek unstructured "unstructured[pdf]" "unstructured[docx]" python-dotenv
# 2. 导入必要的库
import os
from dotenv import load_dotenv
from langchain_community.document_loaders import UnstructuredDirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_core.prompts import ChatPromptTemplate
from langchain_deepseek import ChatDeepSeek
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 3. 加载环境变量(存储 API 密钥等)
load_dotenv() # 从 .env 文件加载环境变量(需提前创建,包含 DEEPSEEK_API_KEY)
# 4. 配置路径
# 文档目录(存放 PDF、TXT、Markdown 等多格式文件)
DATA_DIR = "./90-文档-Data/黑悟空"
# 确保目录存在
os.makedirs(DATA_DIR, exist_ok=True)
# 5. 使用 unstructured 加载目录中的多格式文档
print("===== 加载文档 =====")
loader = UnstructuredDirectoryLoader(
directory_path=DATA_DIR,
glob="*.*", # 匹配目录中所有文件(可指定格式,如 "*.pdf")
strategy="hi_res", # 保留文档格式(如标题、表格结构)
silent_errors=True, # 忽略加载失败的文件(如损坏的文件)
# 可选:指定只提取文本元素(过滤图片、表格等)
# elements=["NarrativeText"]
)
documents = loader.load()
print(f"成功加载 {len(documents)} 个文档")
if len(documents) == 0:
print("请在目录中放入文档后再运行")
exit()
# 6. 文档分块(将长文档拆分为小块,优化检索精度)
print("\n===== 文档分块 =====")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每块最大字符数
chunk_overlap=200, # 块之间重叠字符数(避免割裂语义)
separators=["\n\n", "\n", "。", ",", " "] # 中文优先分隔符
)
split_docs = text_splitter.split_documents(documents)
print(f"分块后共 {len(split_docs)} 个片段")
# 7. 初始化嵌入模型(将文本转为向量)
print("\n===== 初始化嵌入模型 =====")
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5", # 中文优化的轻量级嵌入模型
model_kwargs={'device': 'cpu'}, # 在 CPU 上运行(无 GPU 时使用)
encode_kwargs={'normalize_embeddings': True} # 向量归一化
)
# 8. 创建向量存储(存储分块后的文档向量)
print("\n===== 创建向量存储 =====")
vector_store = InMemoryVectorStore.from_documents(
documents=split_docs,
embedding=embeddings
)
print("向量存储创建完成")
# 9. 构建 RAG 链(检索 + 生成)
print("\n===== 构建问答链 =====")
# 检索器:从向量存储中查找相关文档
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # 取最相关的 3 个片段
# 提示词模板:告诉 LLM 基于检索到的上下文回答
prompt = ChatPromptTemplate.from_template("""
基于以下上下文内容,回答用户的问题。如果上下文没有相关信息,请说“无法从提供的文档中找到答案”。
上下文:
{context}
问题:{question}
回答:
""")
# 初始化大语言模型(DeepSeek)
llm = ChatDeepSeek(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"), # 从环境变量获取 API 密钥
temperature=0.3 # 控制回答随机性(0 表示更确定)
)
# 构建 LCEL 链:检索 → 格式化上下文 → 生成回答 → 解析输出
rag_chain = (
{
"context": retriever | (lambda docs: "\n\n".join(doc.page_content for doc in docs)),
"question": RunnablePassthrough()
}
| prompt
| llm
| StrOutputParser()
)
# 10. 运行问答
print("\n===== 开始问答 =====")
while True:
question = input("\n请输入问题(输入 'exit' 退出):")
if question.lower() == "exit":
break
response = rag_chain.invoke(question)
print(f"\n回答:{response}")
- 文档加载:UnstructuredDirectoryLoader 调用 unstructured 解析目录中所有文件
- 支持多格式,自动提取文本和元数据。
- 文档分块:将长文档拆分为小块,避免因文本过长导致检索精度下降。
- 向量存储:用嵌入模型将文本转为向量,存储在内存向量库中,方便快速检索。
- 问答链:用户提问时,先检索相关文档片段,再让 LLM 基于这些片段生成回答,确保答案基于文档内容。
- 特点
多格式支持:通过 unstructured 处理 PDF、Word、图片(需额外安装 OCR 依赖)等格式。
可扩展性:可替换嵌入模型(如 text2vec)或 LLM(如本地模型)。
容错性:silent_errors=True 确保个别文件加载失败不影响整体流程。
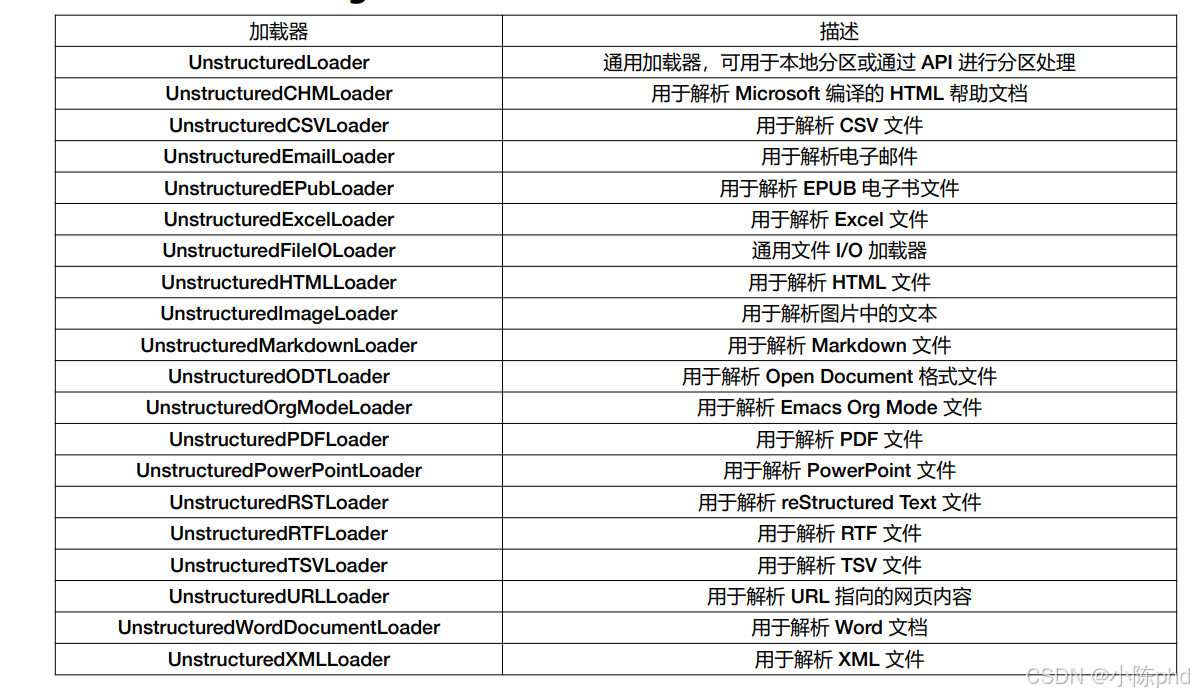
备注:langchain 集成各种Unstructured Loader

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)