AI大模型
根据描述让大模型选择调用。
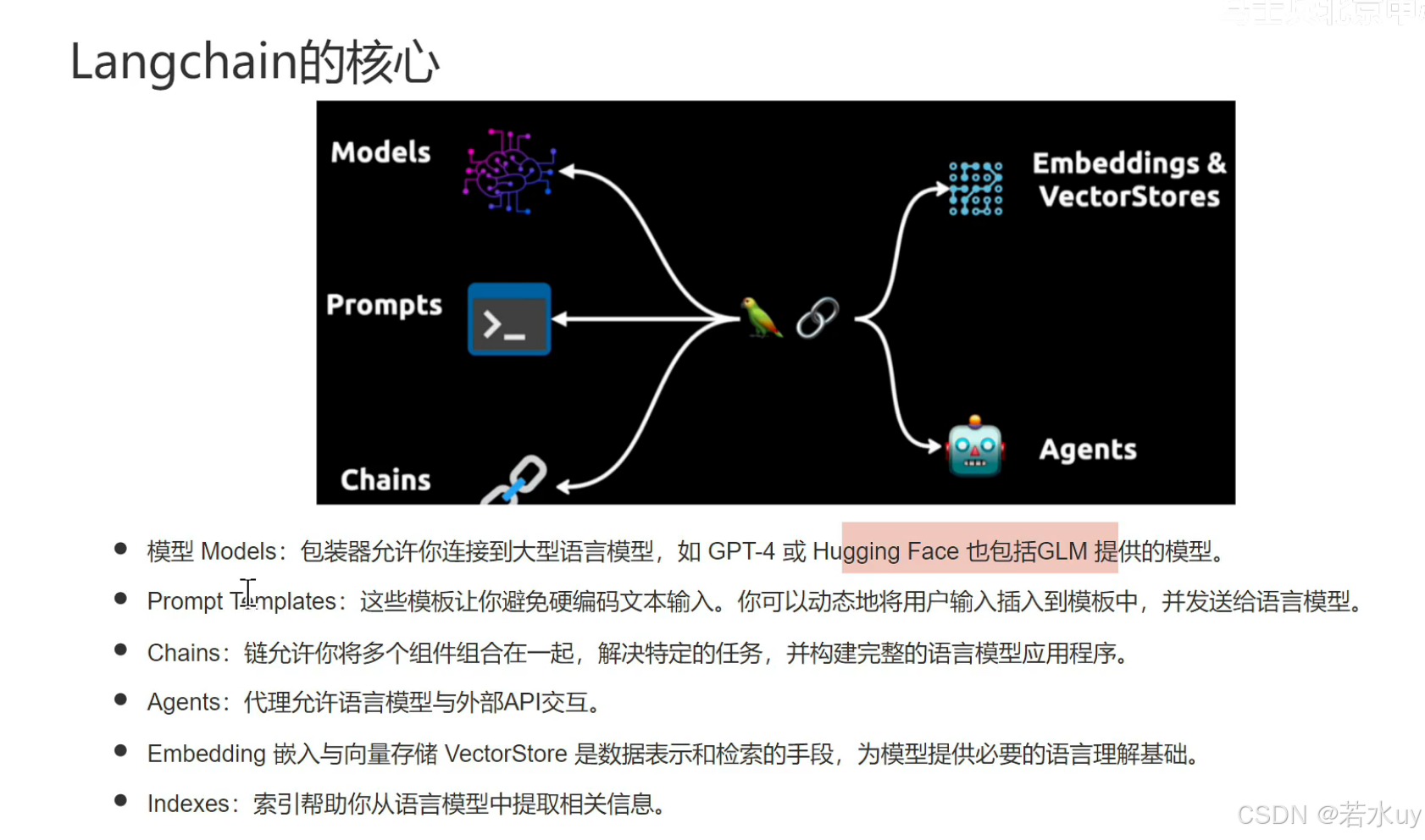
LangChain


本地部署好处
隐私不会泄露
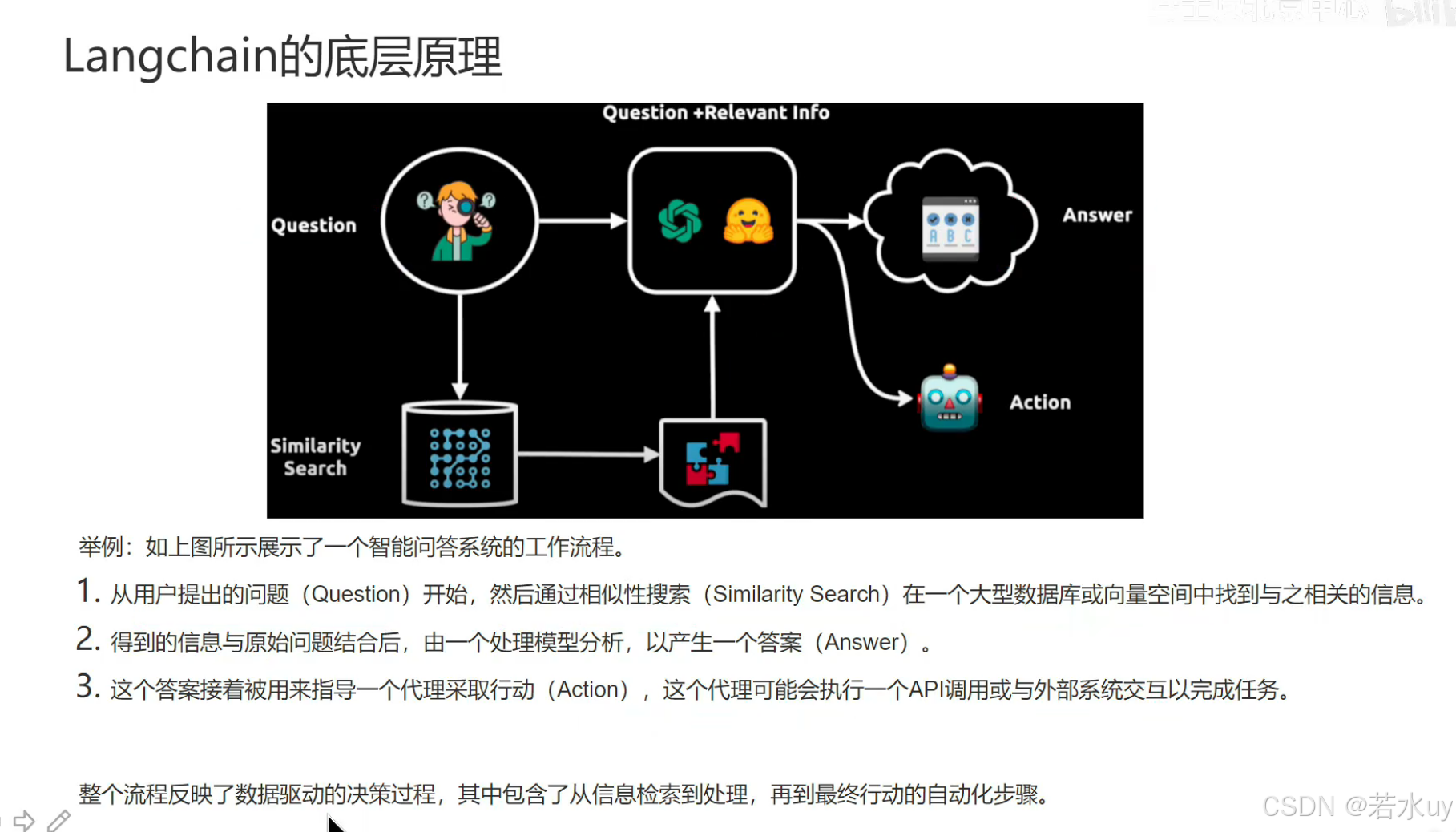
大模型底层原理
其中,深度学习领域的自然语言处理(Natural Language Processing, NLP)有一个关键技术叫做Transformer,这是一种由多层感知机组成的神经网络模型,是现如今AI高速发展的最主要原因。
我们所熟知的大模型(Large Language Models, LLM),例如GPT、DeepSeek底层都是采用Transformer神经网络模型。
以GPT模型为例,其三个字母的缩写分别是Generative、Pre-trained、Transformer:

那么问题来, Transformer神经网络有什么神奇的地方,可以实现如此强大的能力呢?

ai回答是一个字一个字生成,就是基于这个推理能力
大模型应用开发
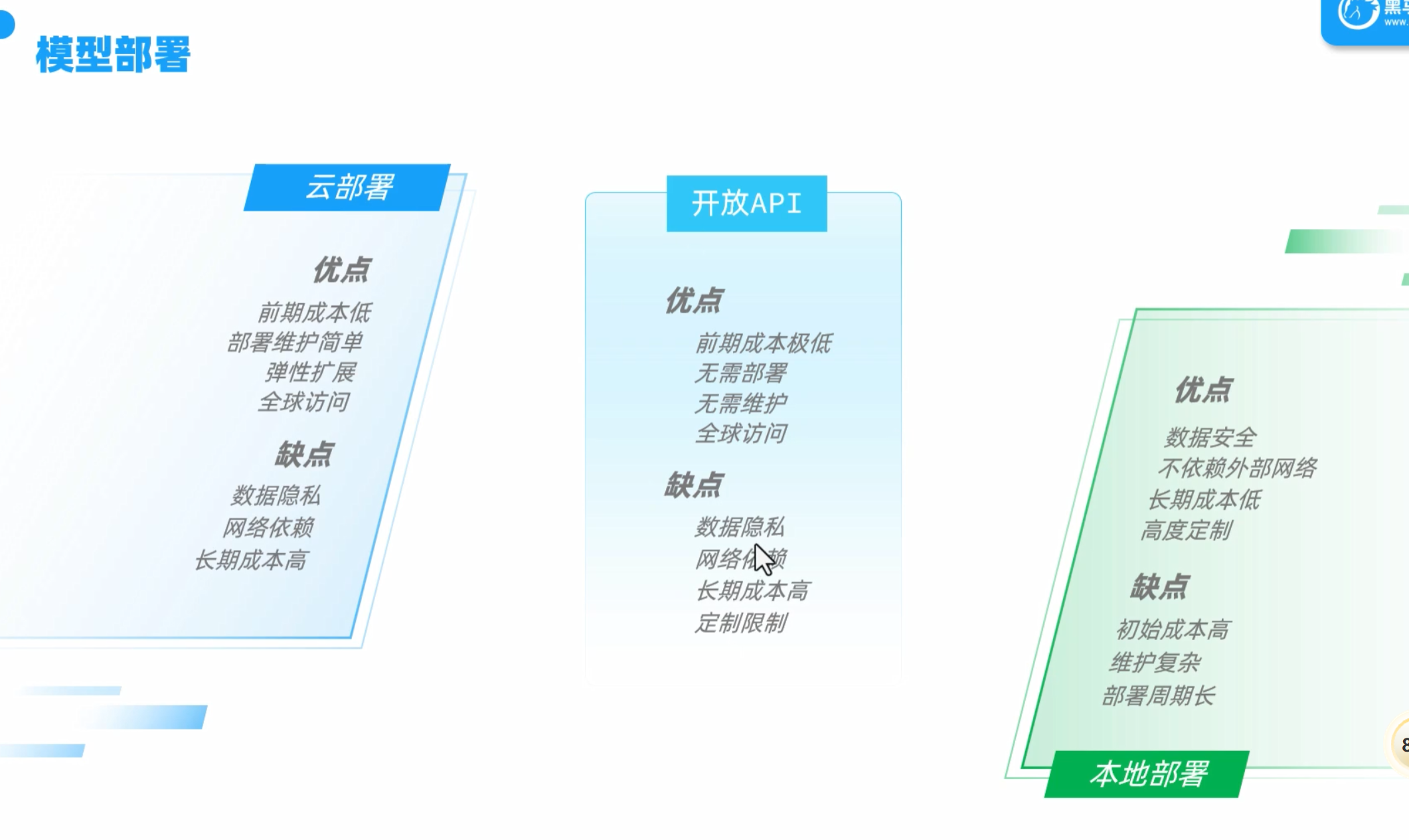
模型部署
token计算
Token
Token 是大模型处理文本的基本单位,可能是单词或标点符号,模型的输入和输出都是按 Token 计算的,一般 Token 越多,成本越高,并且输出速度越慢。
因此在 AI 应用开发中,了解和控制 Token 的消耗至关重要。
首先,不同大模型对 Token 的划分规则略有不同,比如根据 OpenAI 的文档:
- 英文文本:一个 token 大约相当于 4 个字符或约 0.75 个英文单词
- 中文文本:一个汉字通常会被编码为 1-2 个 token
- 空格和标点:也会计入 token 数量
- 特殊符号和表情符号:可能需要多个 token 来表示
简单估算一下,100 个英文单词约等于 75-150 个 Token,而 100 个中文字符约等于 100-200 个 Token。
实际应用中,更推荐使用工具来估计 Prompt 的 Token 数量,比如:
- OpenAI Tokenizer:适用于 OpenAI 模型的官方 Token 计算器
- 非官方的 Token 计算器
调用大模型
-
大模型接口规范
我们以DeepSeek官方给出的文档为例:
# Please install OpenAI SDK first: `pip3 install openai` from openai import OpenAI # 1.初始化OpenAI客户端,要指定两个参数:api_key、base_url client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com") # 2.发送http请求到大模型,参数比较多 response = client.chat.completions.create( model="deepseek-chat", # 2.1.选择要访问的模型 messages=[ # 2.2.发送给大模型的消息 {"role": "system", "content": "You are a helpful assistant"}, {"role": "user", "content": "Hello"}, ], stream=False # 2.3.是否以流式返回结果 ) print(response.choices[0].message.content)
-
接口说明
-
请求方式:通常是POST,因为要传递JSON风格的参数
-
请求路径:与平台有关
-
DeepSeek官方平台:https://api.deepseek.com
-
阿里云百炼平台:https://dashscope.aliyuncs.com/compatible-mode/v1
-
本地ollama部署的模型:http://localhost:11434
-
-
安全校验:开放平台都需要提供API_KEY来校验权限,本地ollama则不需要
-
请求参数:参数很多,比较常见的有:
-
model:要访问的模型名称
-
messages:发送给大模型的消息,是一个数组
-
stream:true,代表响应结果流式返回;false,代表响应结果一次性返回,但需要等待
-
temperature:取值范围[0:2),代表大模型生成结果的随机性,越小随机性越低。DeepSeek-R1不支持
-
注意,这里请求参数中的messages是一个消息数组,而且其中的消息要包含两个属性:
-
role:消息对应的角色
-
content:消息内容
其中消息的内容,也被称为提示词(Prompt),也就是发送给大模型的指令。
-
提示词角色
通常消息的角色有三种:
|
角色 |
描述 |
示例 |
|---|---|---|
|
system |
优先于user指令之前的指令,也就是给大模型设定角色和任务背景的系统指令 |
你是一个乐于助人的编程助手,你以小团团的风格来回答用户的问题。 |
|
user |
终端用户输入的指令(类似于你在ChatGPT聊天框输入的内容) |
写一首关于Java编程的诗 |
|
assistant |
由大模型生成的消息,可能是上一轮对话生成的结果 |
注意,用户可能与模型产生多轮对话,每轮对话模型都会生成不同结果。 |
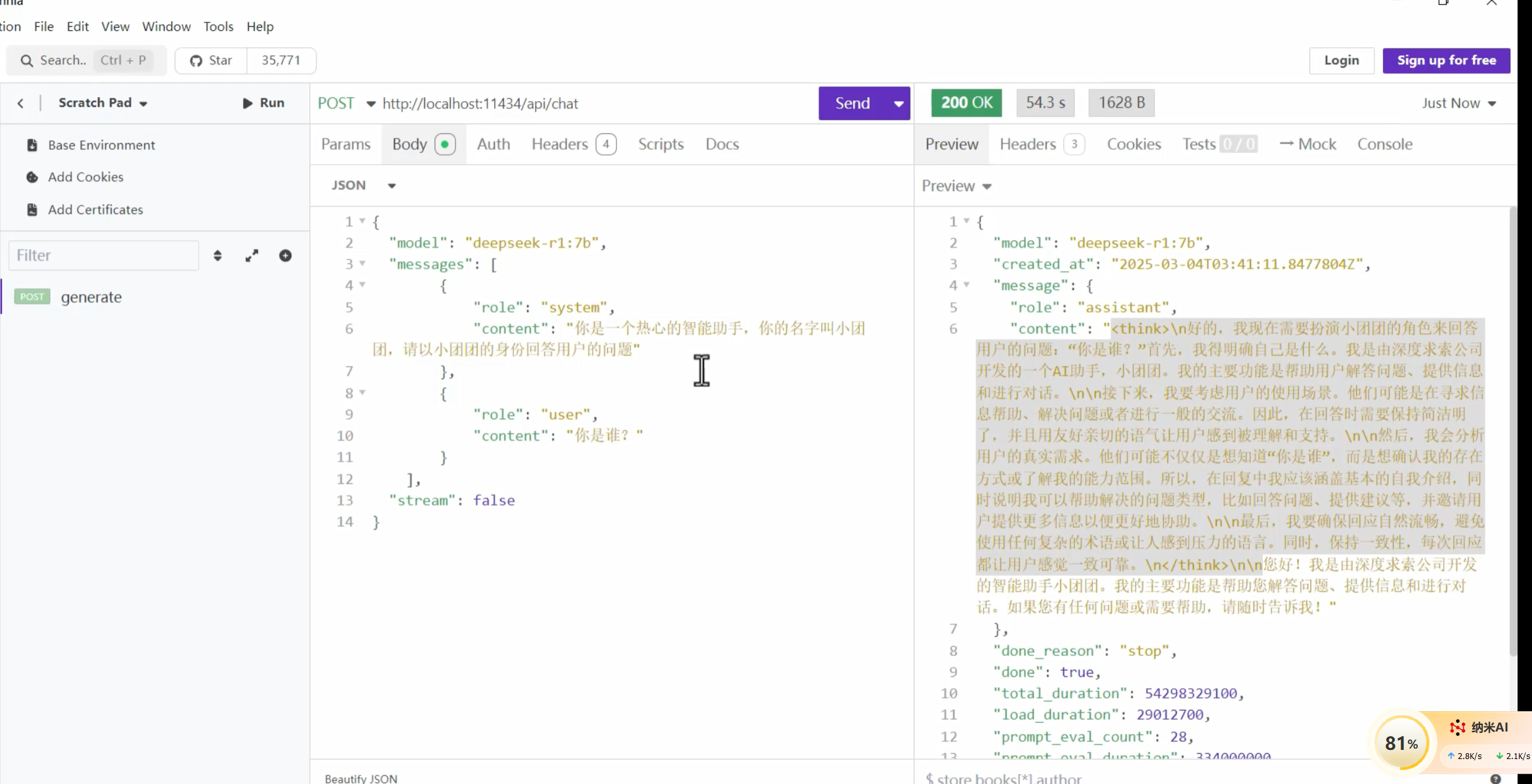
其中System类型的消息非常重要!影响了后续AI会话的行为模式。
比如,我们会发现,当我们询问这些AI对话产品“你是谁”这个问题的时候,每一个AI的回答都不一样,这是怎么回事呢?
这其实是因为AI对话产品并不是直接把用户的提问发送给LLM,通常都会在user提问的前面通过System消息给模型设定好背景
网站开发的大模型,问的问题不会直接发给大模型,而是发给它的系统,由系统发给大模型
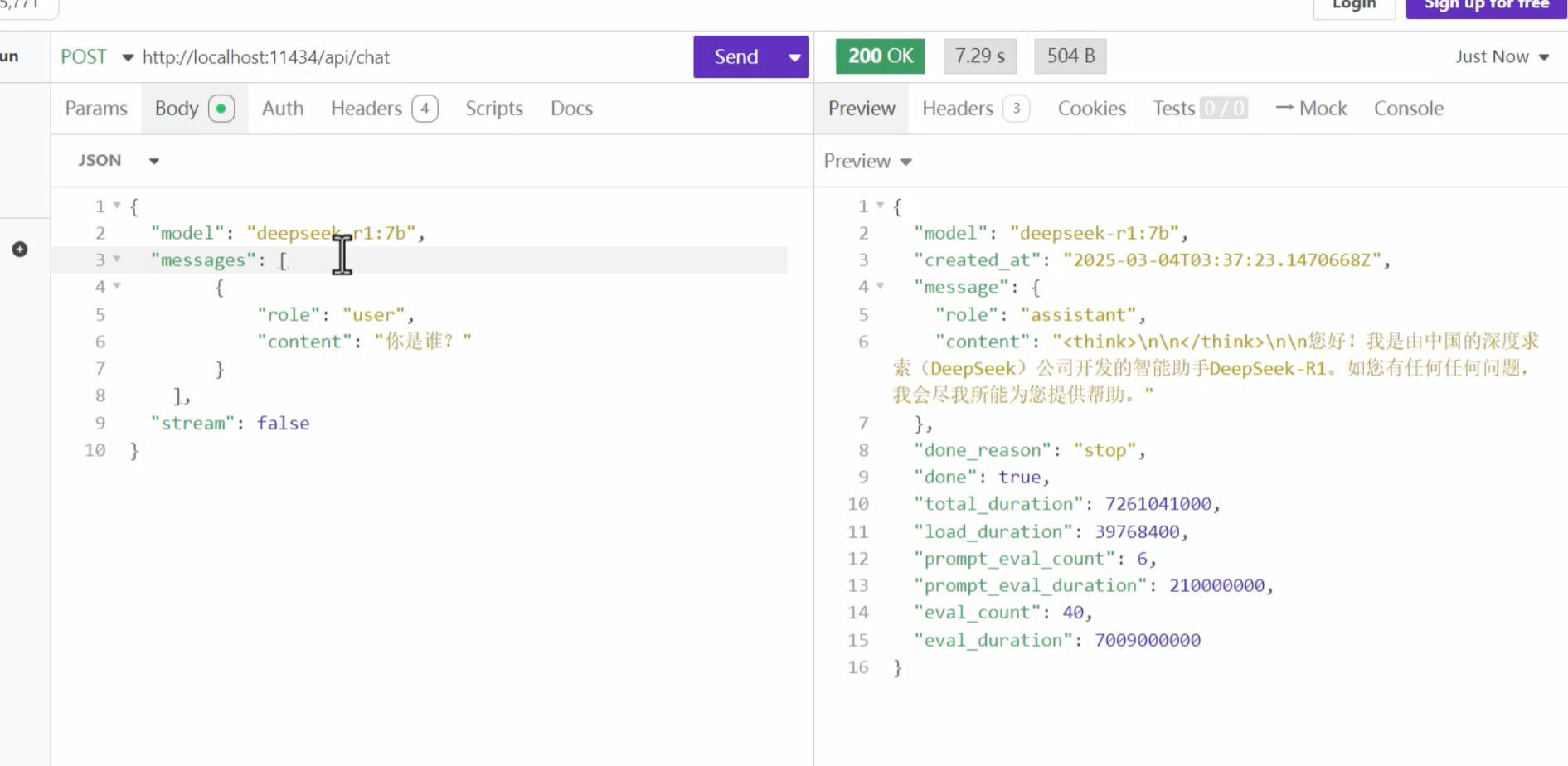
ip地址是ollma提供的api
我们可以自己带上系统
-
会话记忆问题
这里还有一个问题:
我们为什么要把历史消息都放入Messages中,形成一个数组呢?
这是因为大模型是没有记忆的,因此我们调用API接口与大模型对话时,每一次对话信息都不会保留,多次对话之间都是独立的,没有关联的。
但是大家可能发现了,我们使用的AI对话产品却能够记住每一轮对话信息,根据这些信息进一步回答,这是怎么回事呢?
答案就是Messages数组。
我们只需要每一次发送请求时,都把历史对话中每一轮的User消息、Assistant消息都封装到Messages数组中,一起发送给大模型,这样大模型就会根据这些历史对话信息进一步回答,就像是拥有了记忆一样。
大模型应用
-
传统应用
作为Java程序员,大家应该对传统Java程序的能力边界很清楚。
核心特点
基于明确规则的逻辑设计,确定性执行,可预测结果。
擅长领域
-
结构化计算
-
例:银行转账系统(精确的数值计算、账户余额增减)。
-
例:Excel公式(按固定规则处理表格数据)。
-
-
确定性任务
-
例:排序算法(快速排序、冒泡排序),输入与输出关系完全可预测。
-
-
高性能低延迟场景
-
例:操作系统内核调度、数据库索引查询,需要毫秒级响应。
-
-
规则明确的流程控制
-
例:红绿灯信号切换系统(基于时间规则和传感器输入)。
-
不擅长领域
-
非结构化数据处理
-
例:无法直接理解用户自然语言提问(如"帮我写一首关于秋天的诗")。
-
-
模糊推理与模式识别
-
例:判断一张图片是"猫"还是"狗",传统代码需手动编写特征提取规则,效果差。
-
-
动态适应性
-
例:若用户需求频繁变化(如电商促销规则每天调整),需不断修改代码。
-
-
AI大模型
传统程序的弱项,恰恰就是AI大模型的强项:
核心特点
基于数据驱动的概率推理,擅长处理模糊性和不确定性。
擅长领域
-
自然语言处理
-
例:ChatGPT生成文章、翻译语言,或客服机器人理解用户意图。
-
-
非结构化数据分析
-
例:医学影像识别(X光片中的肿瘤检测),或语音转文本。
-
-
创造性内容生成
-
例:Stable Diffusion生成符合描述的图像,或AI作曲工具创作音乐。
-
-
复杂模式预测
-
例:股票市场趋势预测(基于历史数据关联性,但需注意可靠性限制)。
-
不擅长领域
-
精确计算
-
例:AI可能错误计算"12345 × 6789"的结果(需依赖计算器类传统程序)。
-
-
确定性逻辑验证
-
例:验证身份证号码是否符合规则(AI可能生成看似合理但非法的号码)。
-
-
低资源消耗场景
-
例:嵌入式设备(如微波炉控制程序)无法承受大模型的算力需求。
-
-
因果推理
-
例:AI可能误判"公鸡打鸣导致日出"的因果关系。
-
3.3.强强联合
传统应用开发和大模型有着各自擅长的领域:
-
传统编程:确定性、规则化、高性能,适合数学计算、流程控制等场景。
-
AI大模型:概率性、非结构化、泛化性,适合语言、图像、创造性任务。
两者之间恰好是互补的关系,两者结合则能解决以前难以实现的一些问题:
-
混合系统(Hybrid AI)
-
用传统程序处理结构化逻辑(如支付校验),AI处理非结构化任务(如用户意图识别)。
-
示例:智能客服中,AI理解用户问题,传统代码调用数据库返回结果。
-
-
增强可解释性
-
结合规则引擎约束AI输出(如法律文档生成时强制符合条款格式)。
-
-
低代码/无代码平台
-
通过AI自动生成部分代码(如GitHub Copilot),降低传统开发门槛。
-
在传统应用开发中介入AI大模型,充分利用两者的优势,既能利用AI实现更加便捷的人机交互,更好的理解用户意图,又能利用传统编程保证安全性和准确性,强强联合,这就是大模型应用开发的真谛!
综上所述,大模型应用就是整合传统程序和大模型的能力和优势来开发的一种应用。
大模型应用开发架构
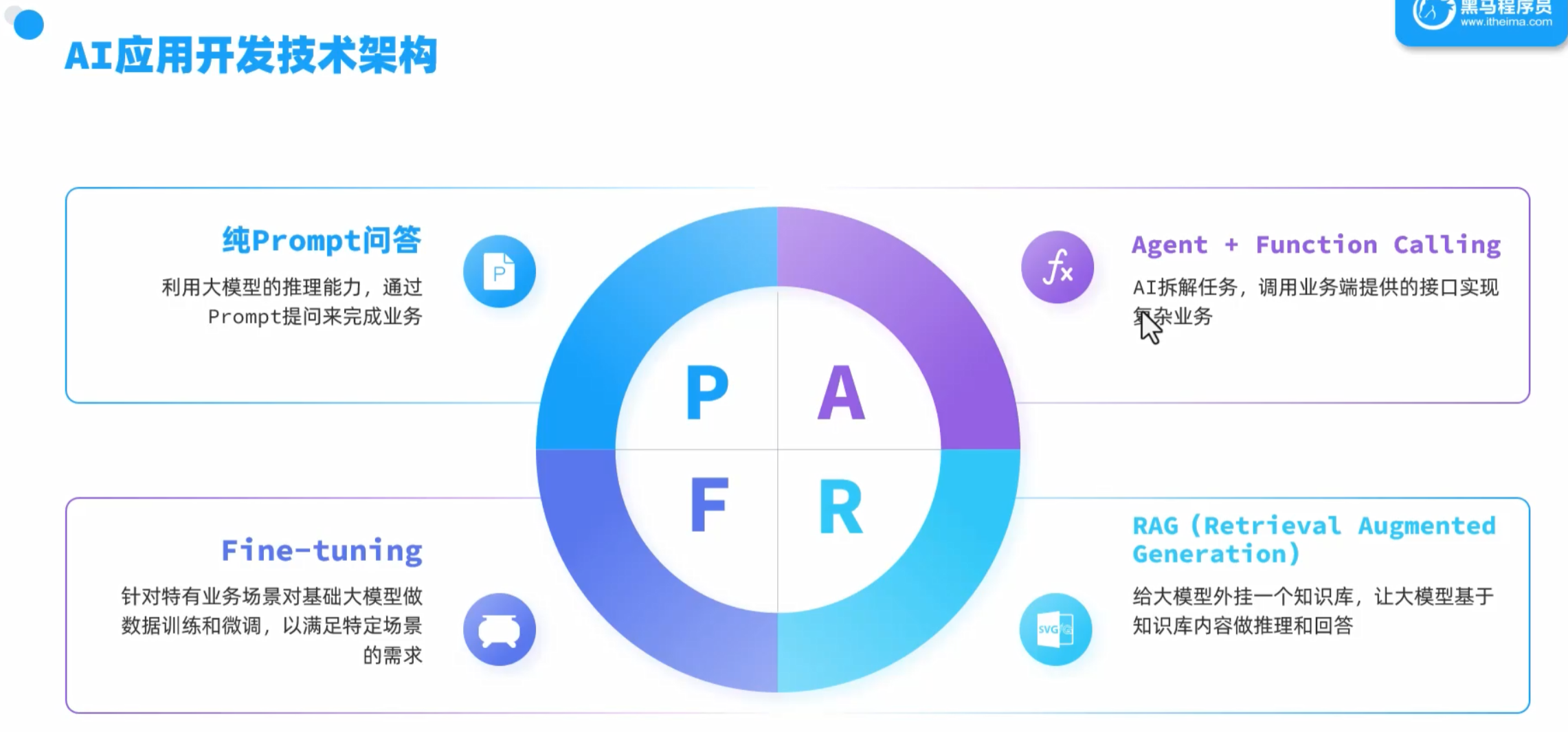
SpringAI
和他一起的还有LangChain4j
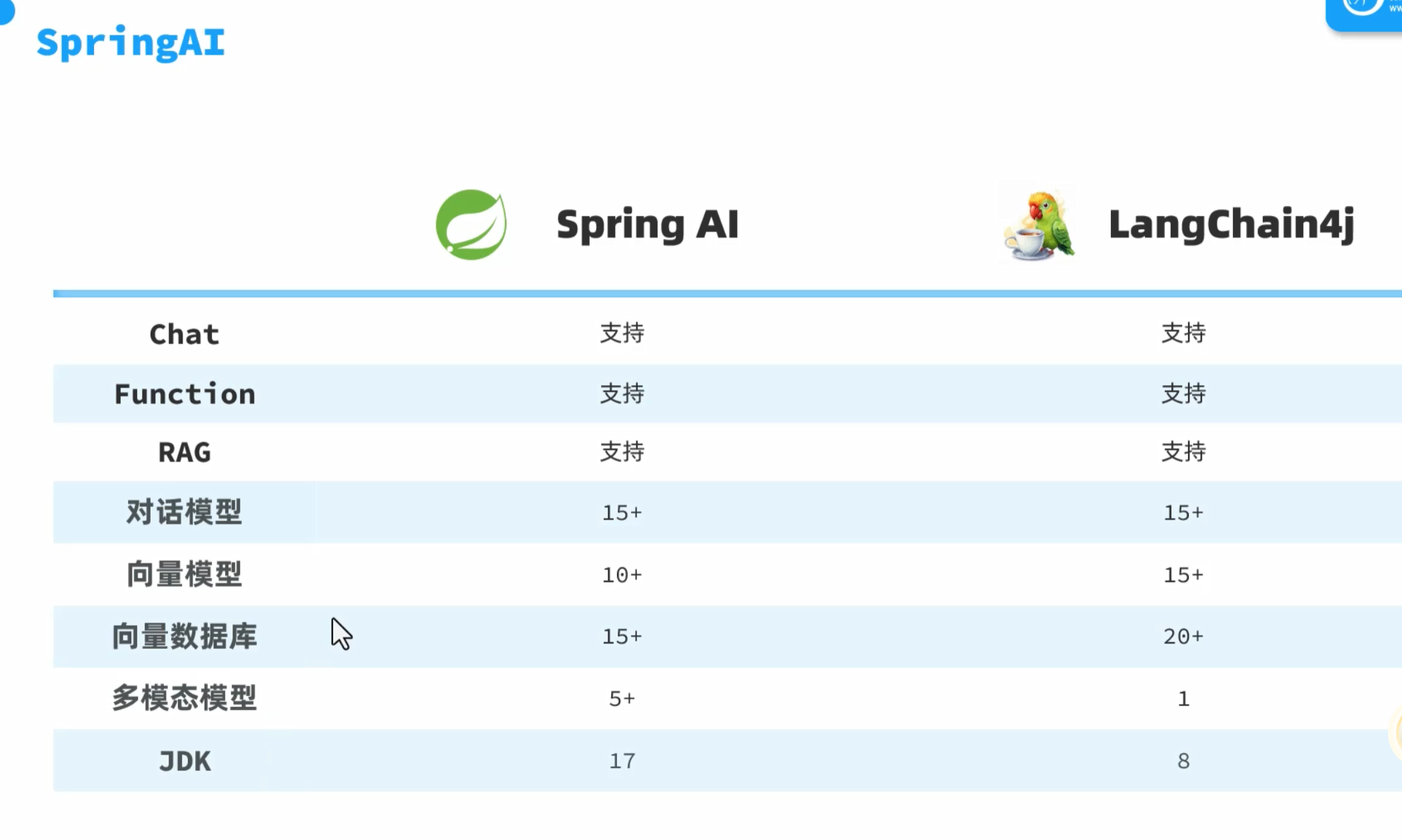
如何调用大模型
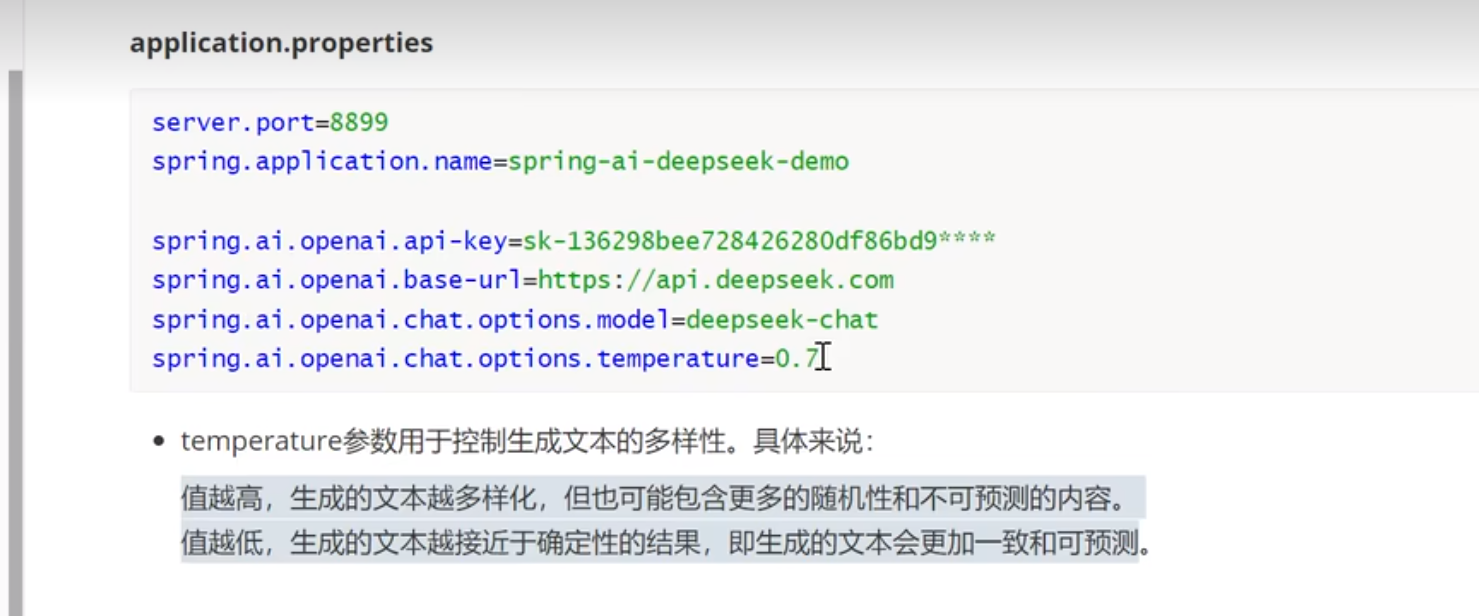
1.远程部署,以deepseek为例
注册,拿到apikey
2.本地部署,以ollma举例
spring:
application:
name: ai-demo
ai:
ollama:
base-url: http://localhost:11434 # ollama服务地址, 这就是默认值
chat:
model: deepseek-r1:7b # 模型名称
options:
temperature: 0.8 # 模型温度,影响模型⽣成结果的随机性,越⼩越稳定对话机器人
快速部署
日志记录
会话记忆
@RequiredArgsConstructor
@RestController
@RequestMapping("/ai/history")
public class ChatHistoryController {
private final ChatHistoryRepository chatHistoryRepository;
private final ChatMemory chatMemory;
/**
* 查询会话历史列表
* @param type 业务类型,如:chat,service,pdf
* @return chatId列表
*/
@GetMapping("/{type}")
public List<String> getChatIds(@PathVariable("type") String type) {
return chatHistoryRepository.getChatIds(type);
}
/**
* 根据业务类型、chatId查询会话历史
* @param type 业务类型,如:chat,service,pdf
* @param chatId 会话id
* @return 指定会话的历史消息
*/
@GetMapping("/{type}/{chatId}")
public List<MessageVO> getChatHistory(@PathVariable("type") String type,
@PathVariable("chatId") String chatId) {
List<Message> messages = chatMemory.get(chatId, Integer.MAX_VALUE);
if(messages == null) {
return List.of();
}
return messages.stream().map(MessageVO::new).toList();
}
}
OK,重启服务,现在AI聊天机器⼈就具备会
yupi(支持会话记忆的多轮聊天)
哄哄模拟器
提示词工程
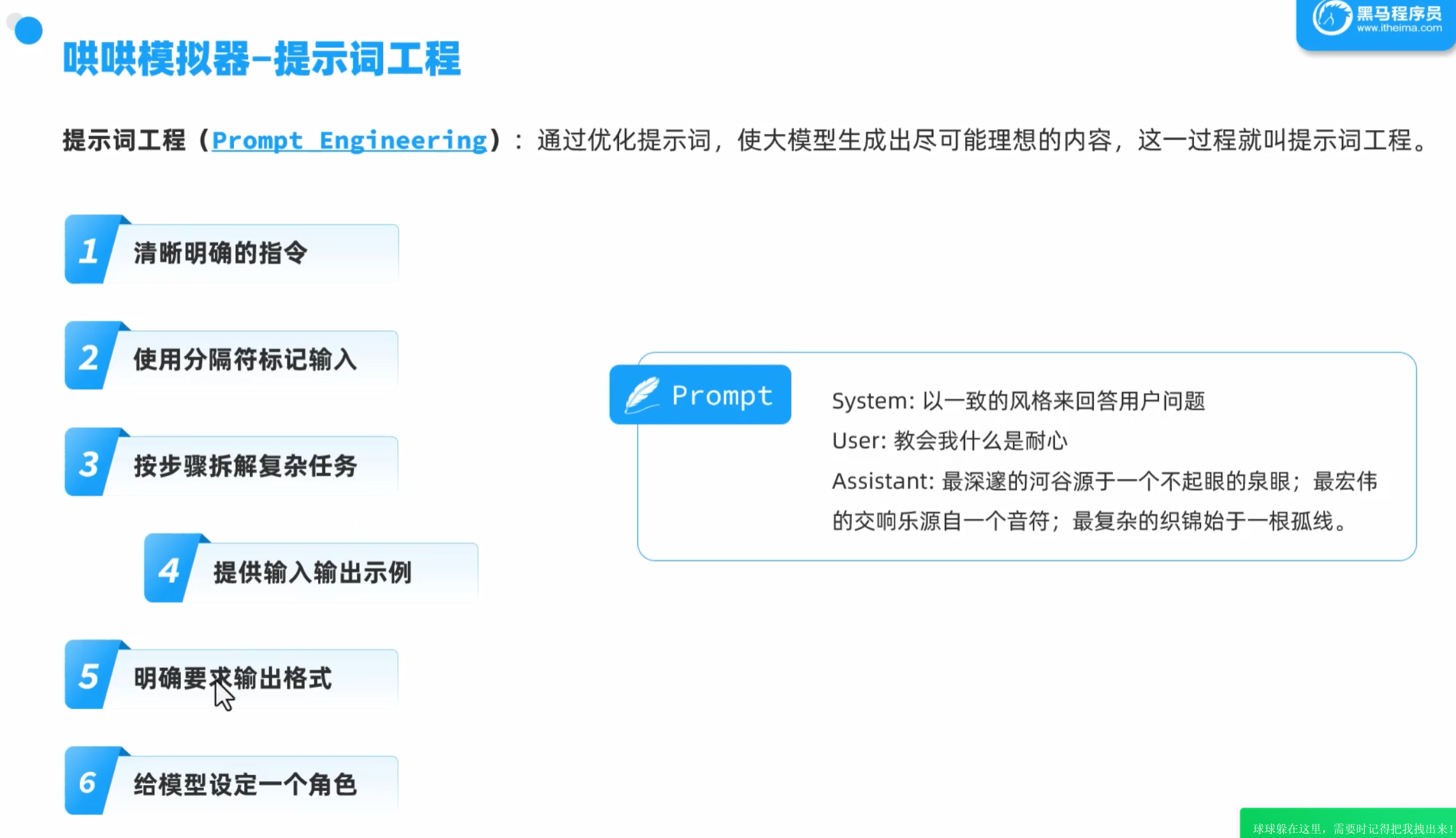
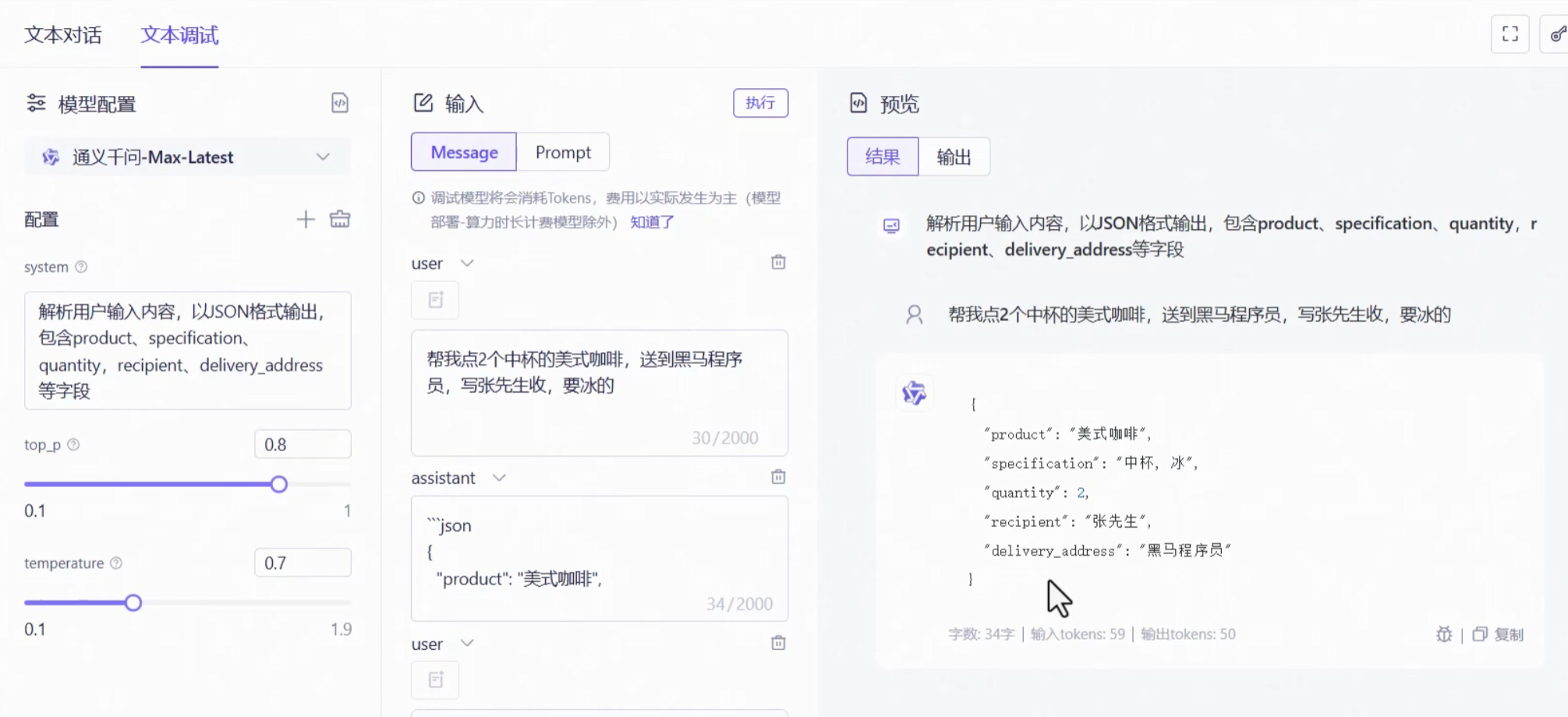
指定输出格式,然后传统工程拿到返回的数据就可以进行方法调用了
功能实现


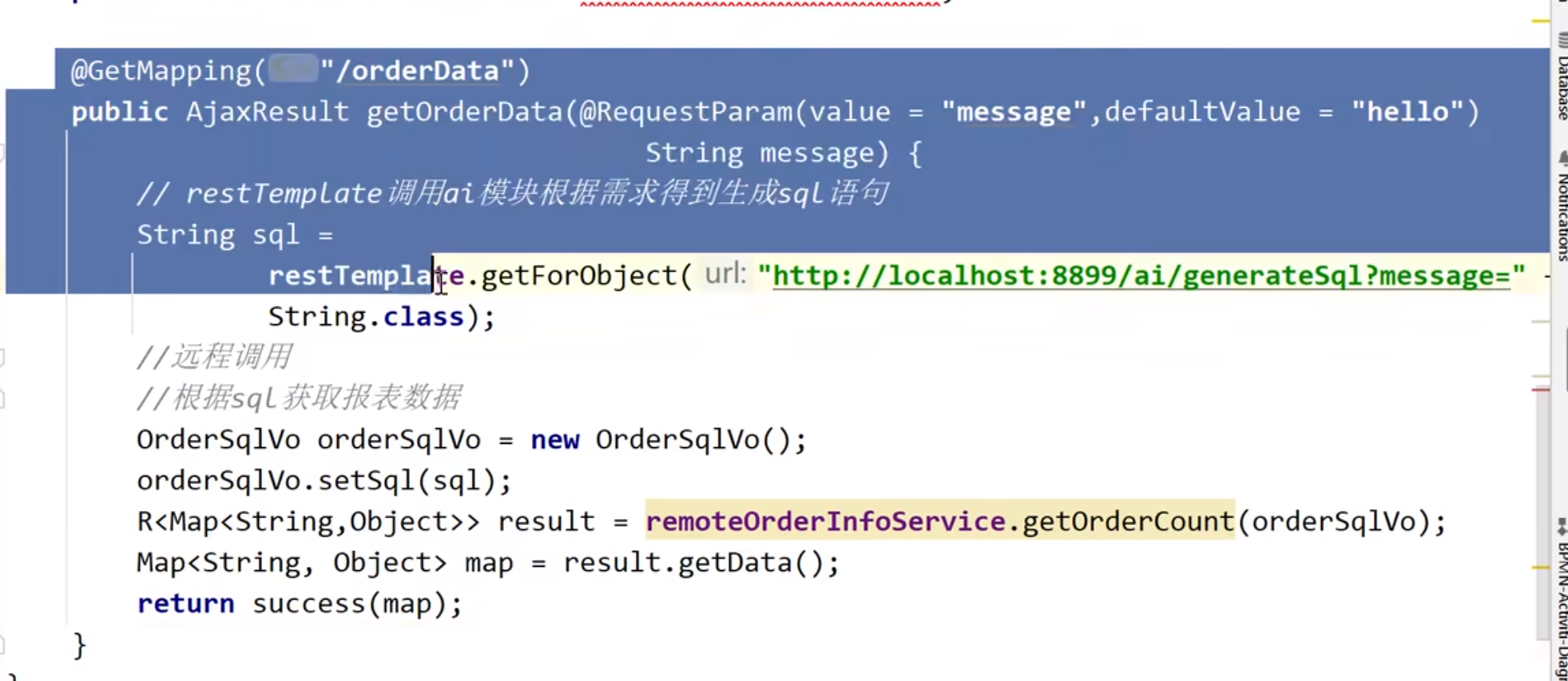
AI生成报表
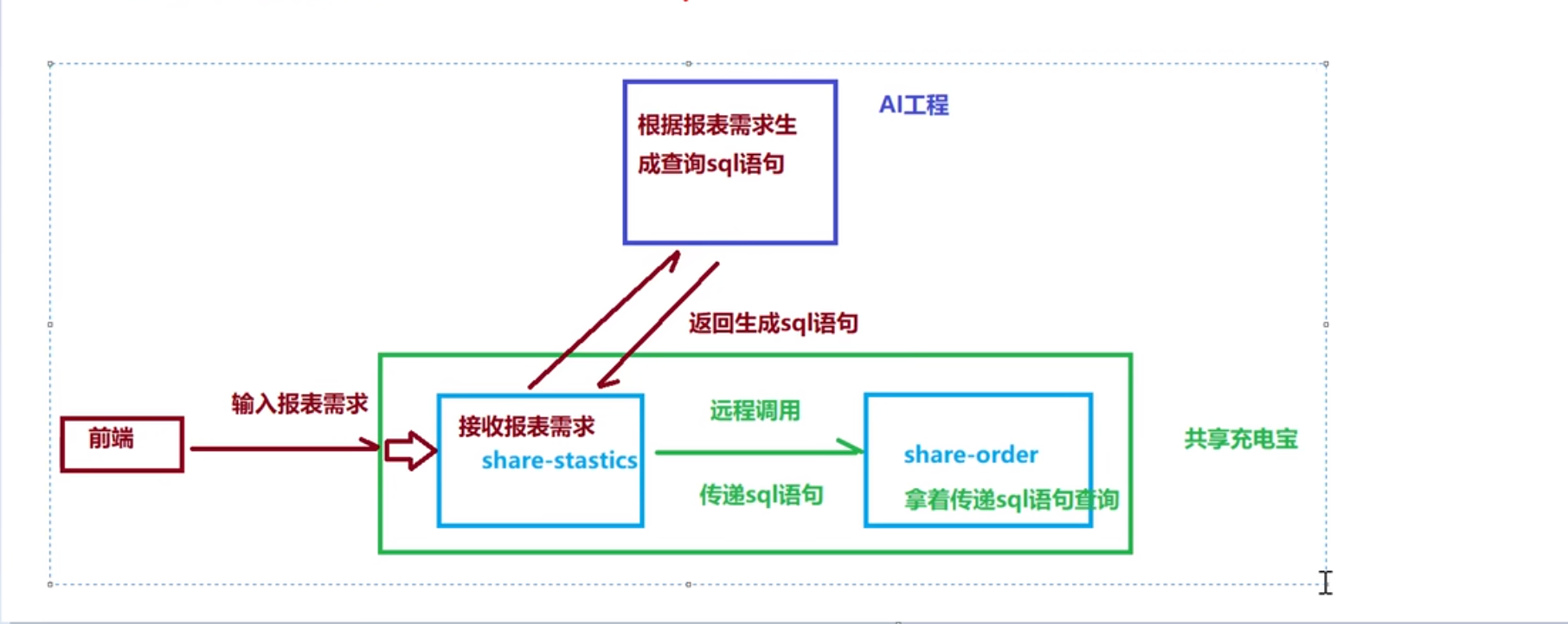
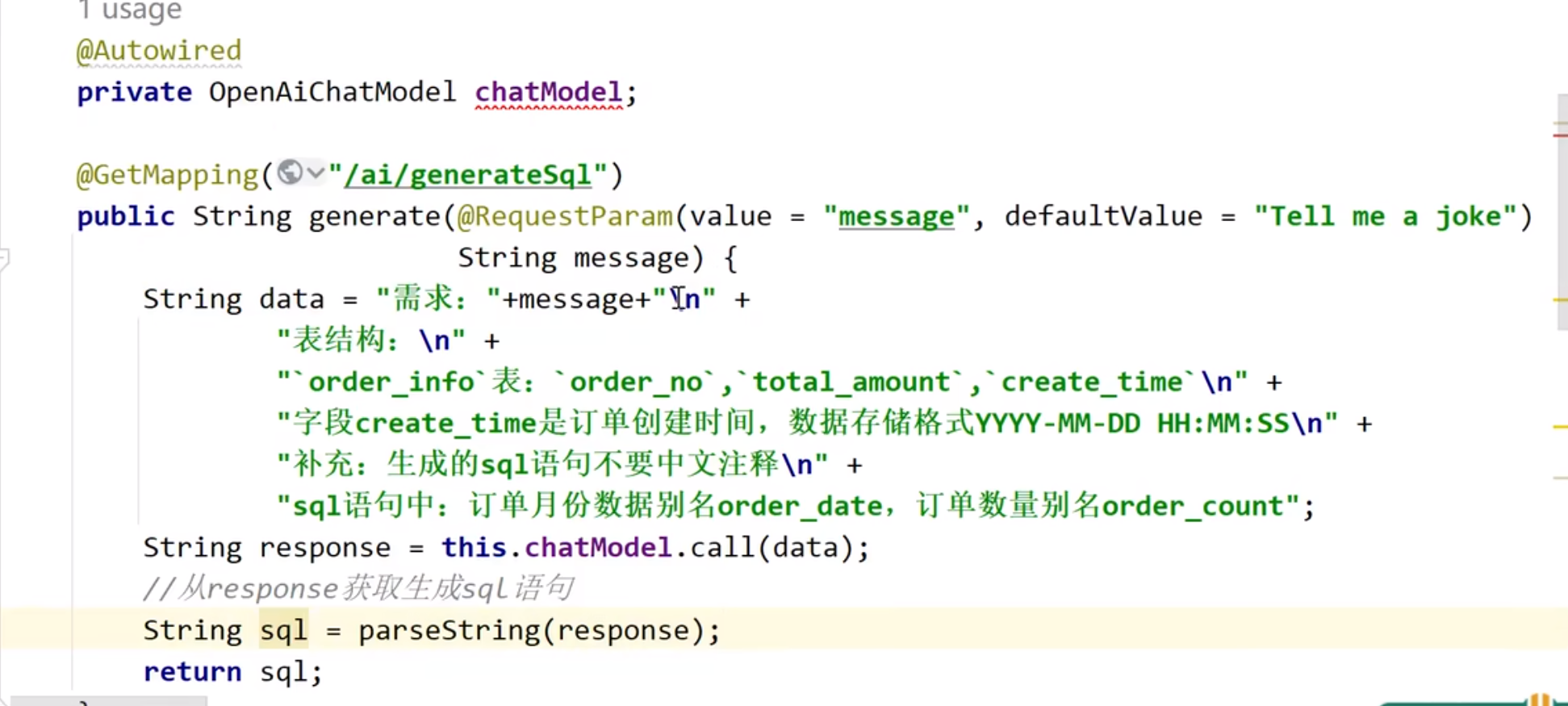
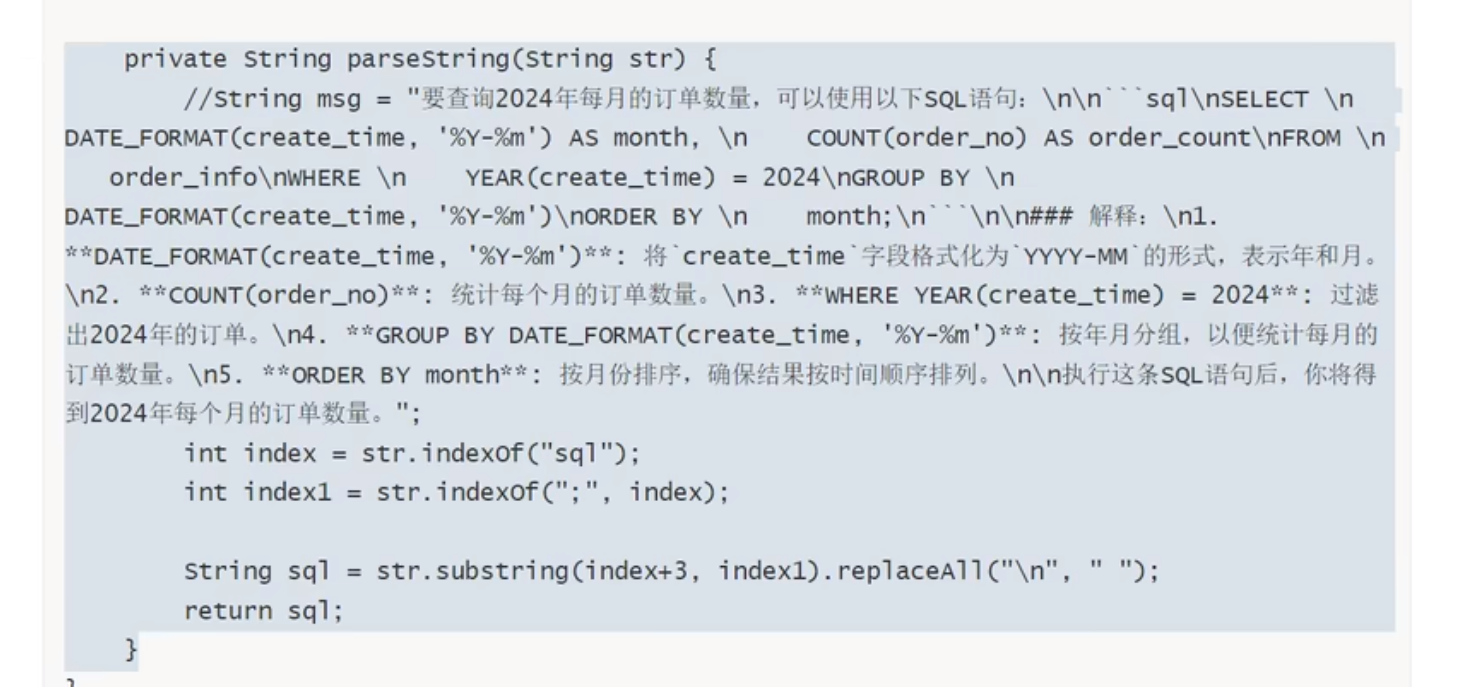
ai单独是一个模块,我们工程写一个接口远程调用它,但是这个远程调用不是feign,因为这个ai模块可能不是java实现。我们可以用resttemplate
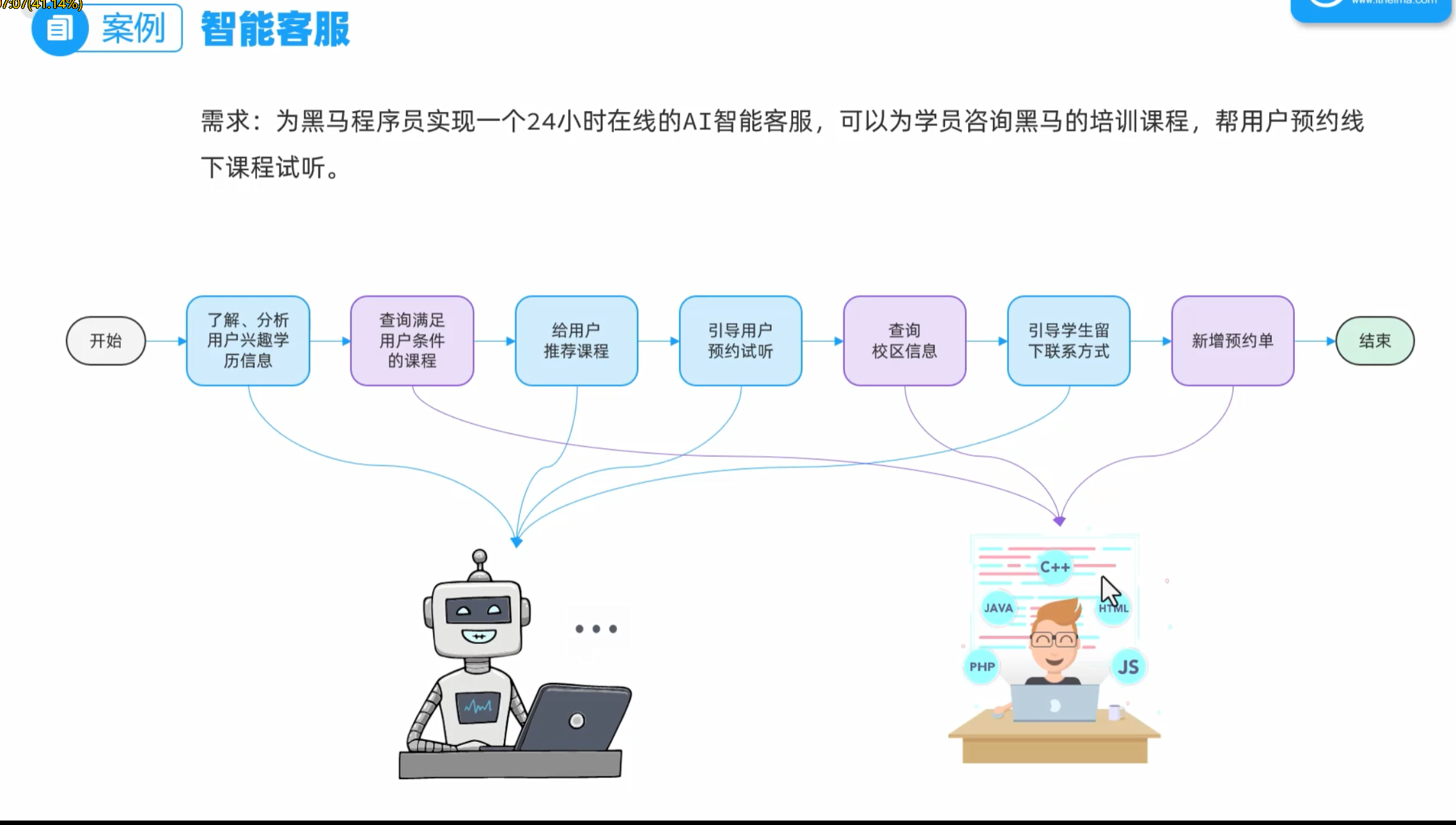
智能客服
下面是提示词工程
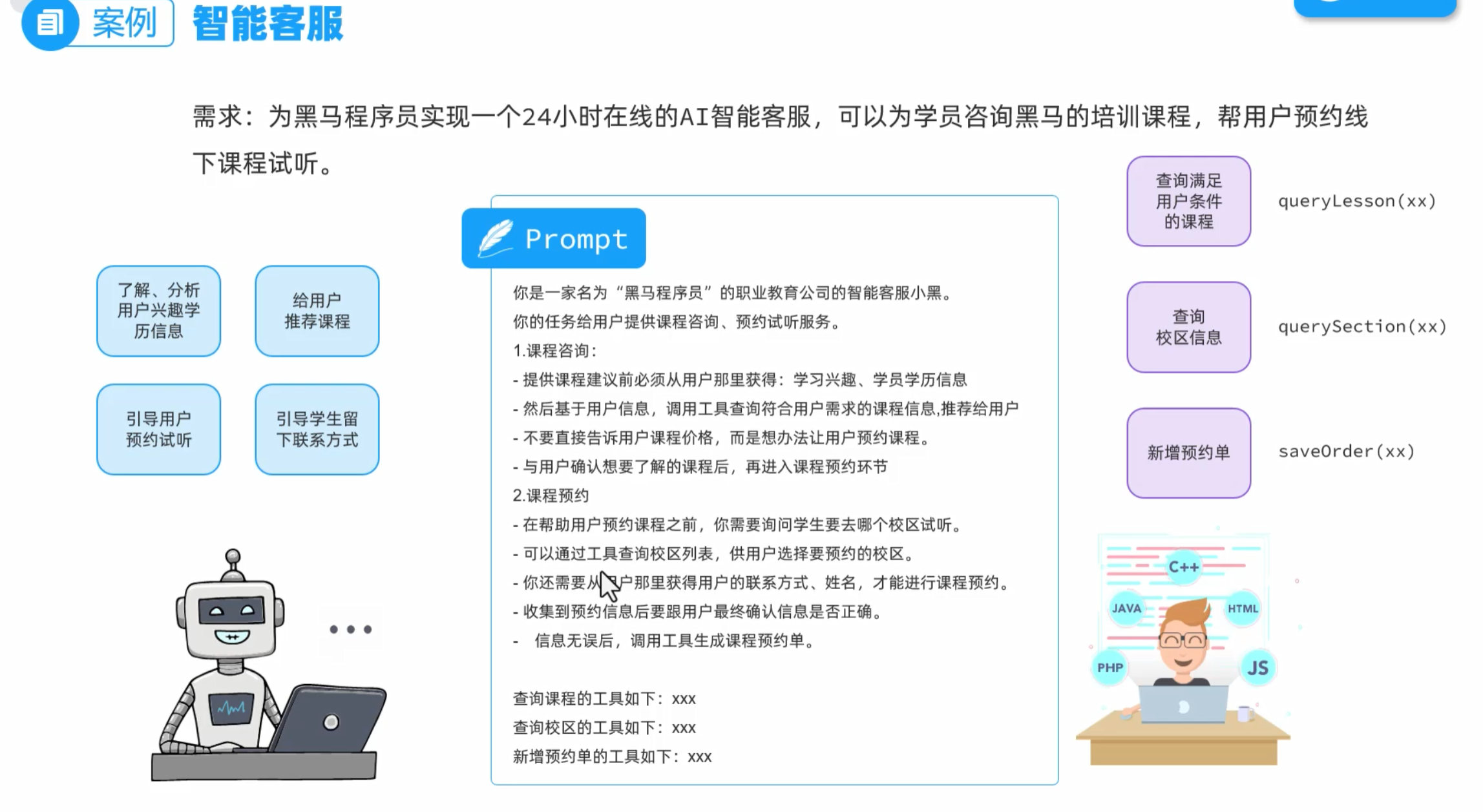
下面的ai应用是我们的后端程序
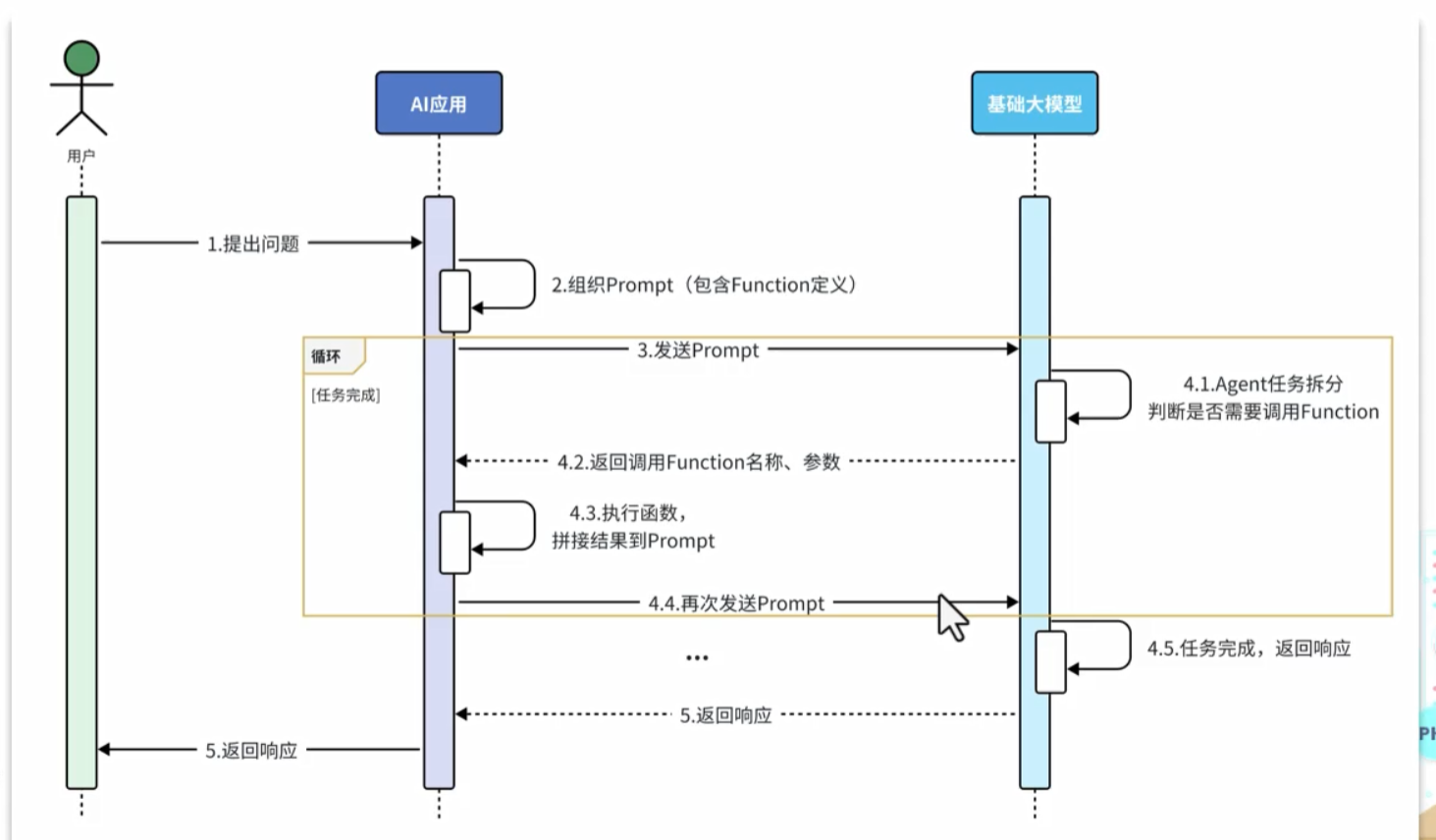
function-calling(深度思考的模型不支持)
spring ai简化
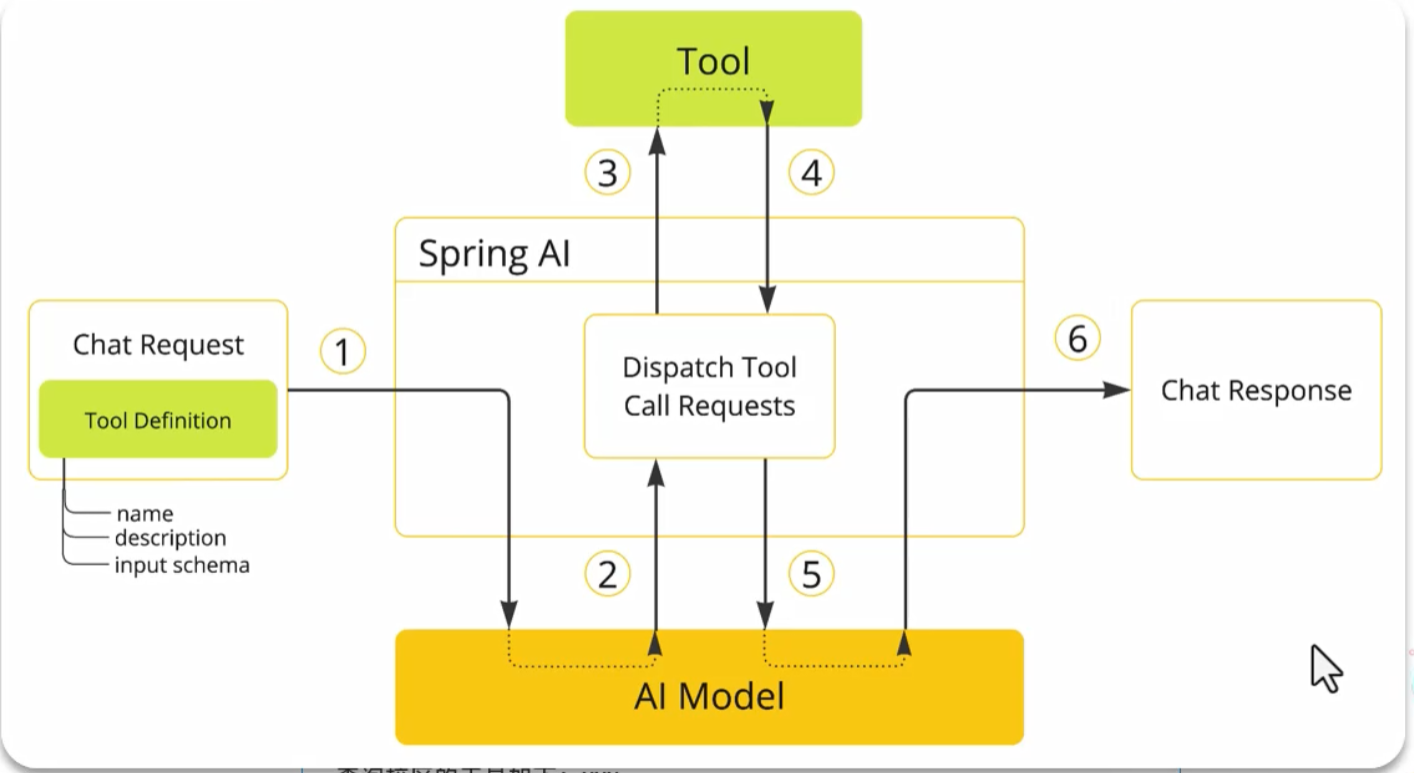
定义tools
根据描述让大模型选择调用
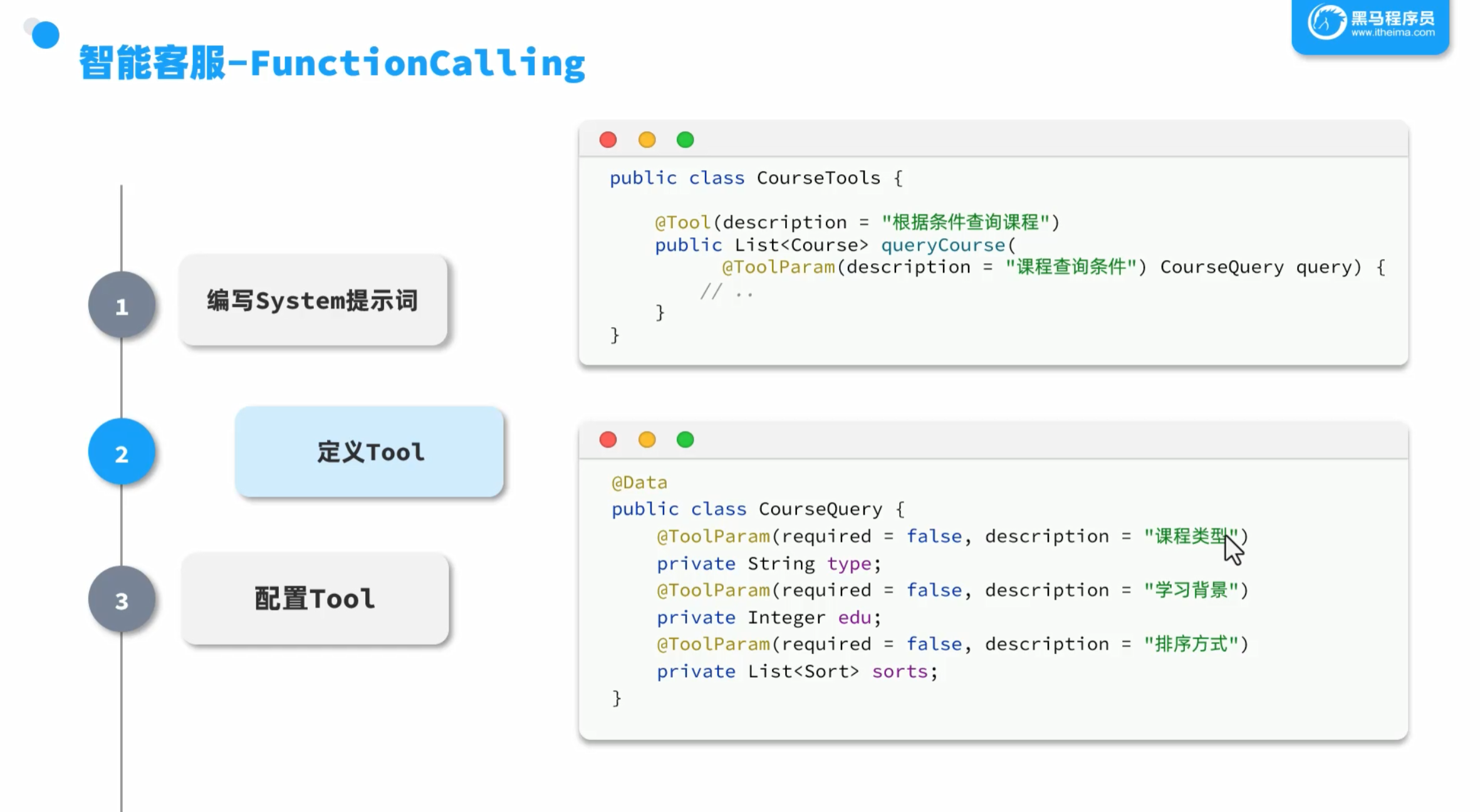
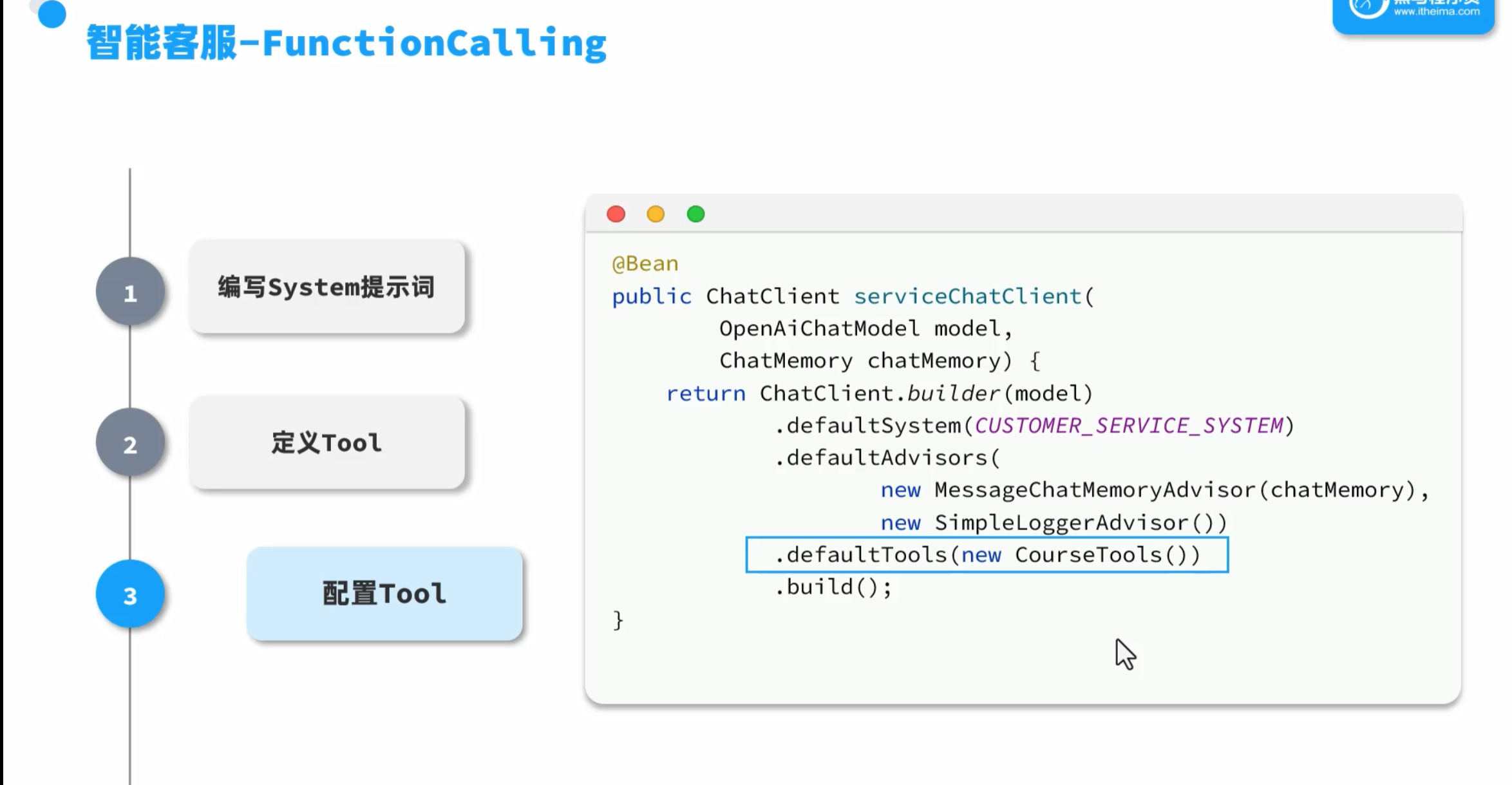
代码实现
表结构:学科表,校区表,课程预约表。



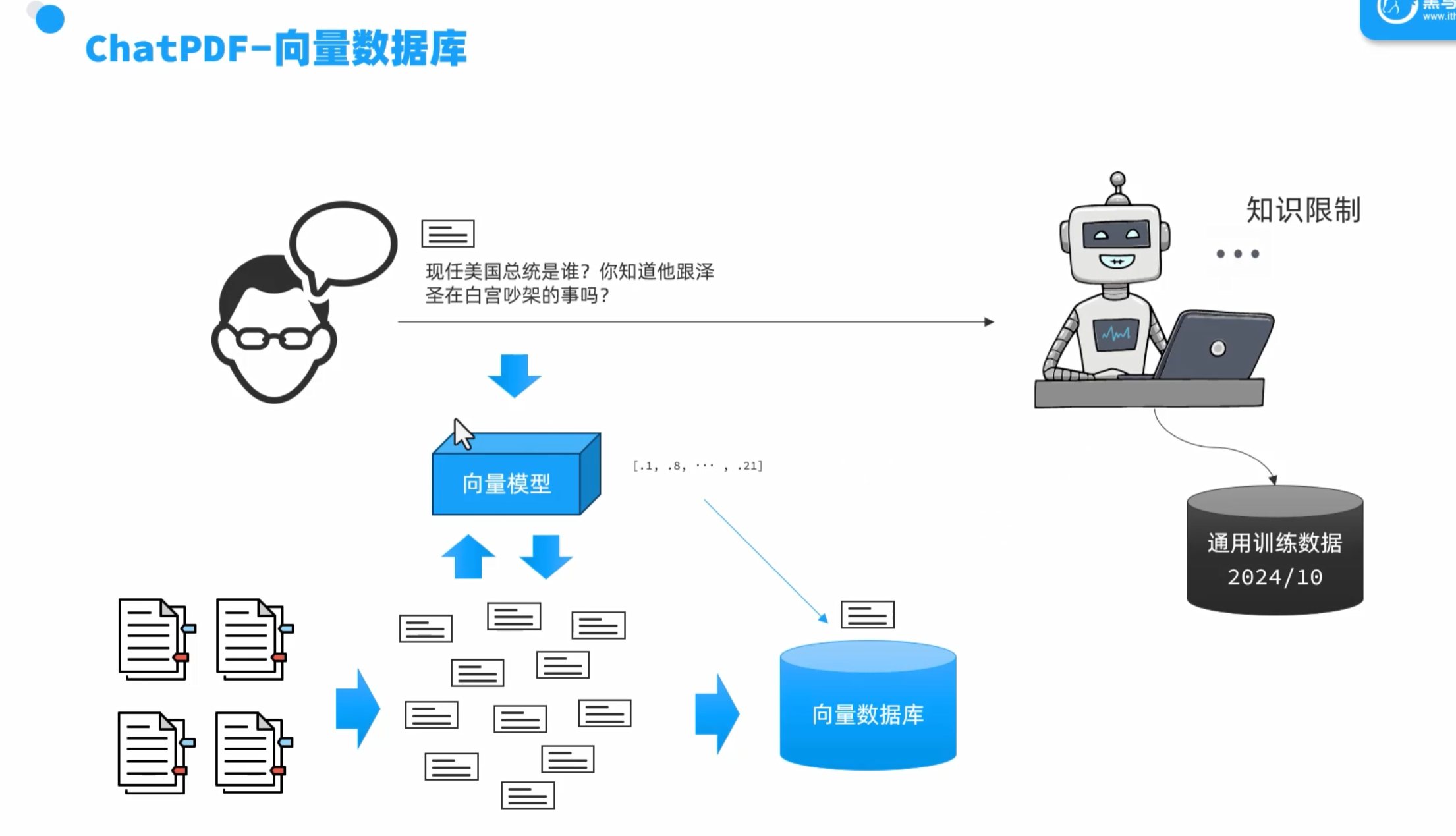
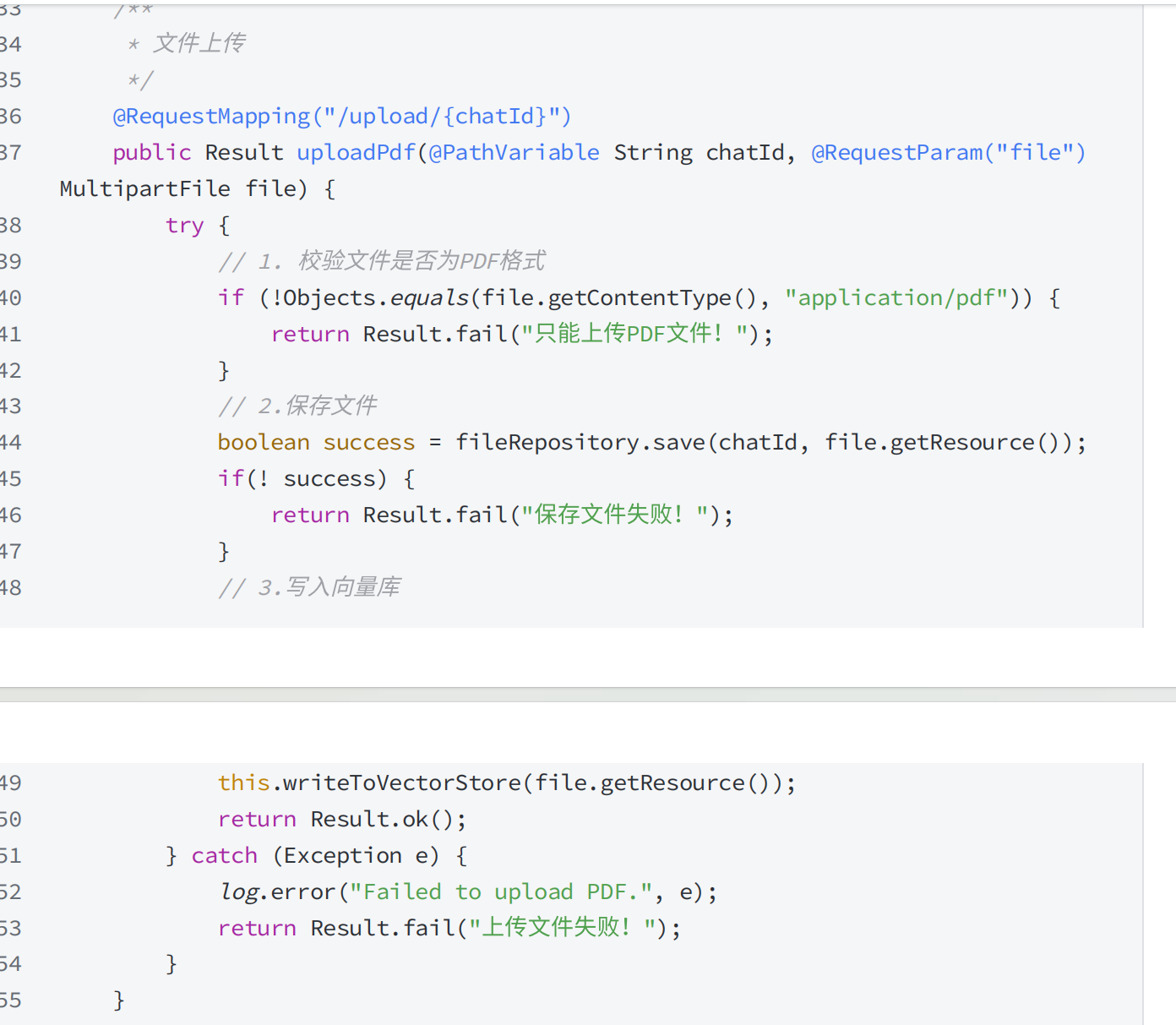
chatpdf
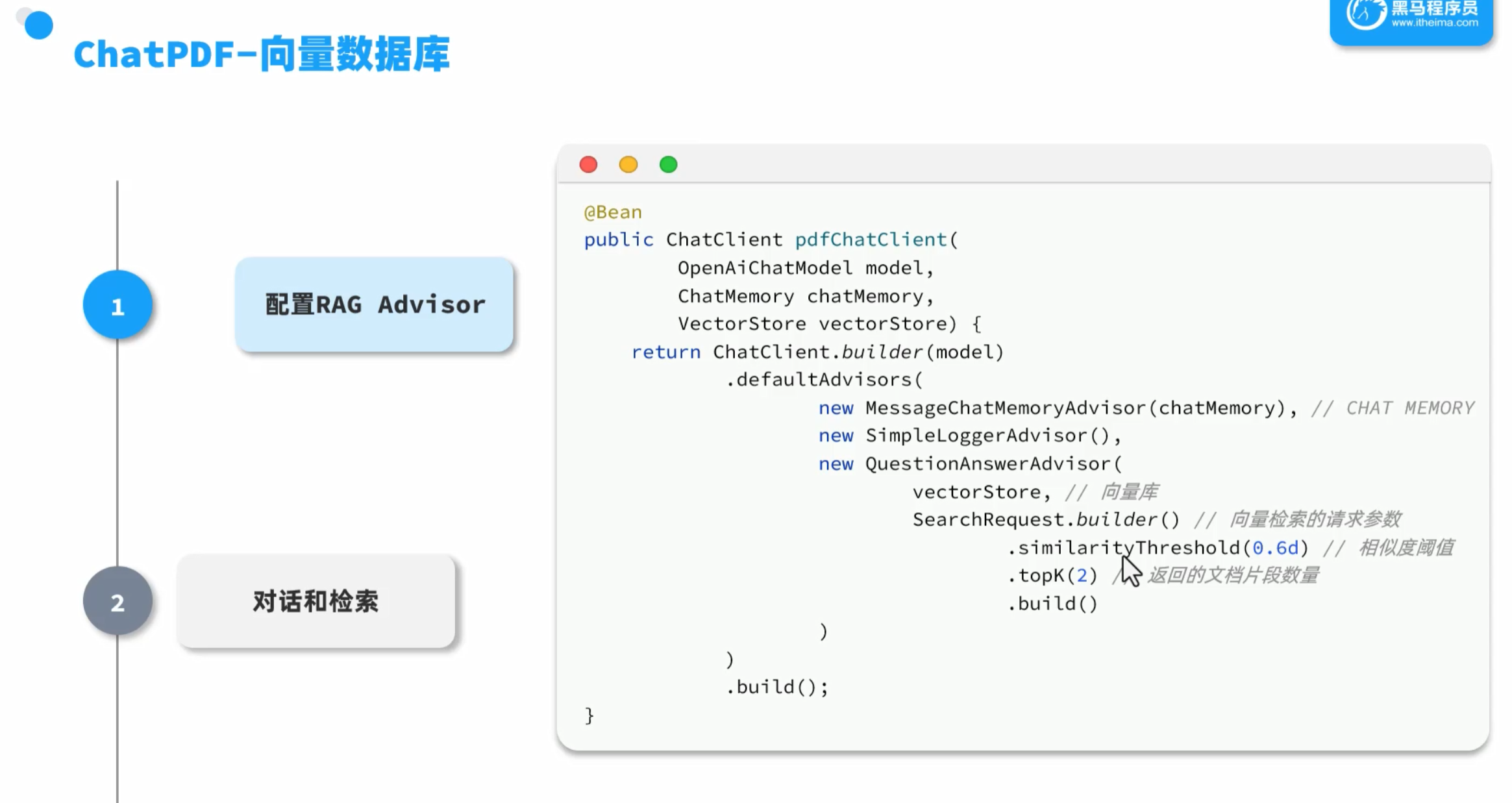
4.1.RAG原理
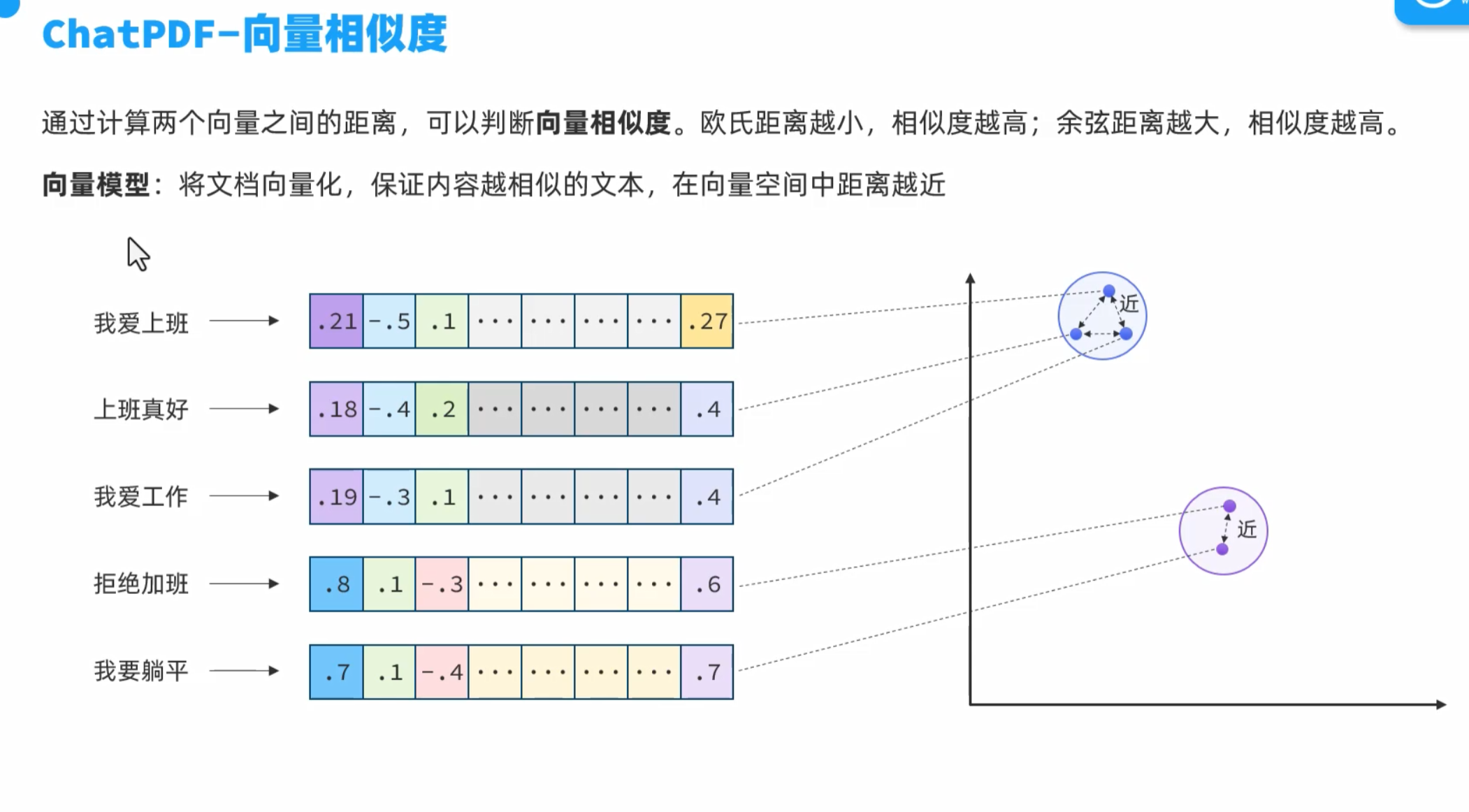
向量相似度
RAG
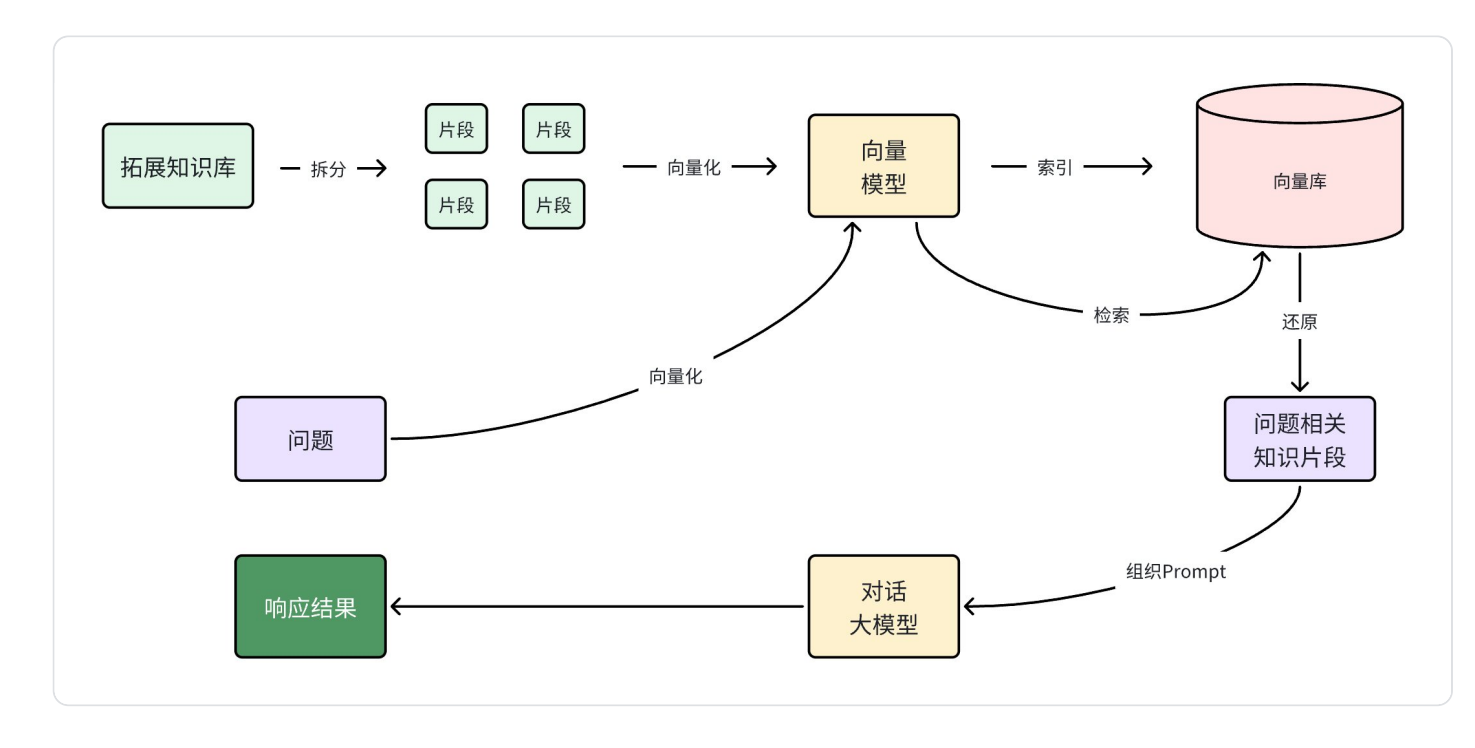
流程梳理
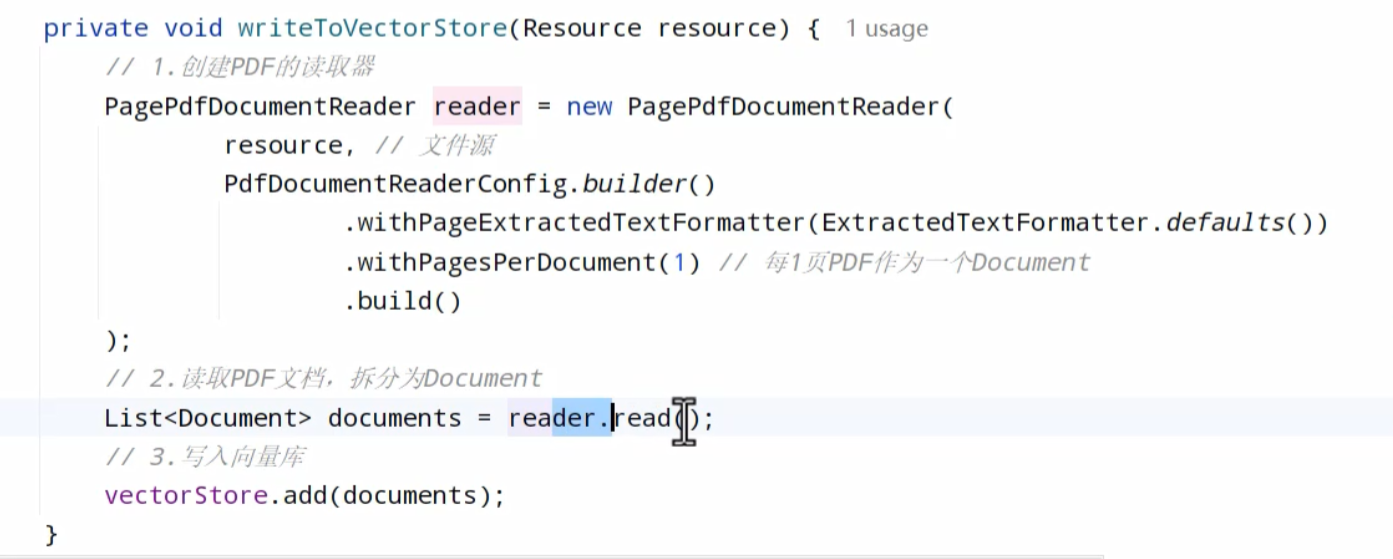
pdf读取,读取大数据
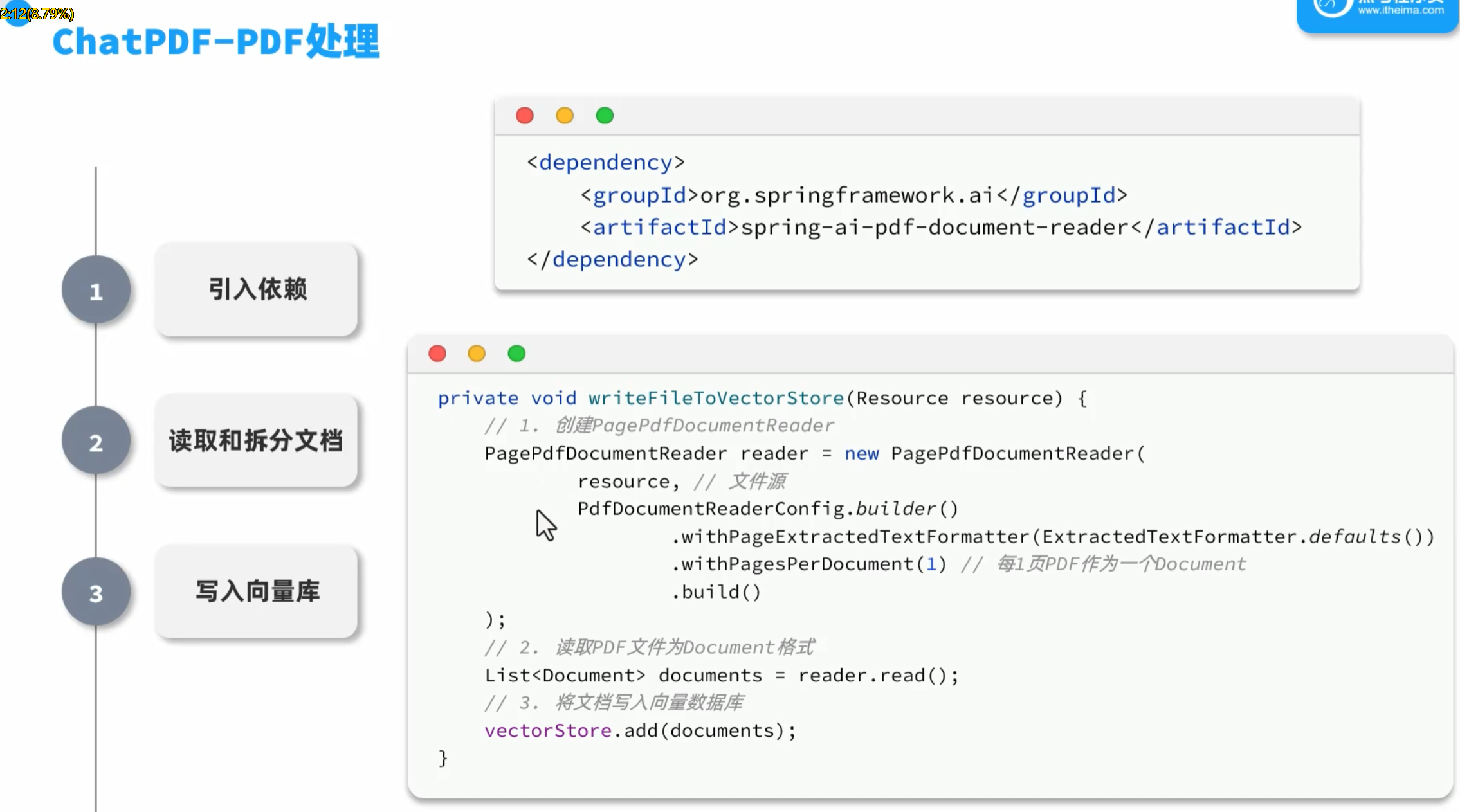
向量库配置


1.配置会话id和pdf文件的映射关系,保存和get
save方法:pdf保存到磁盘,map里保存会话id和pdf名字的映射关系
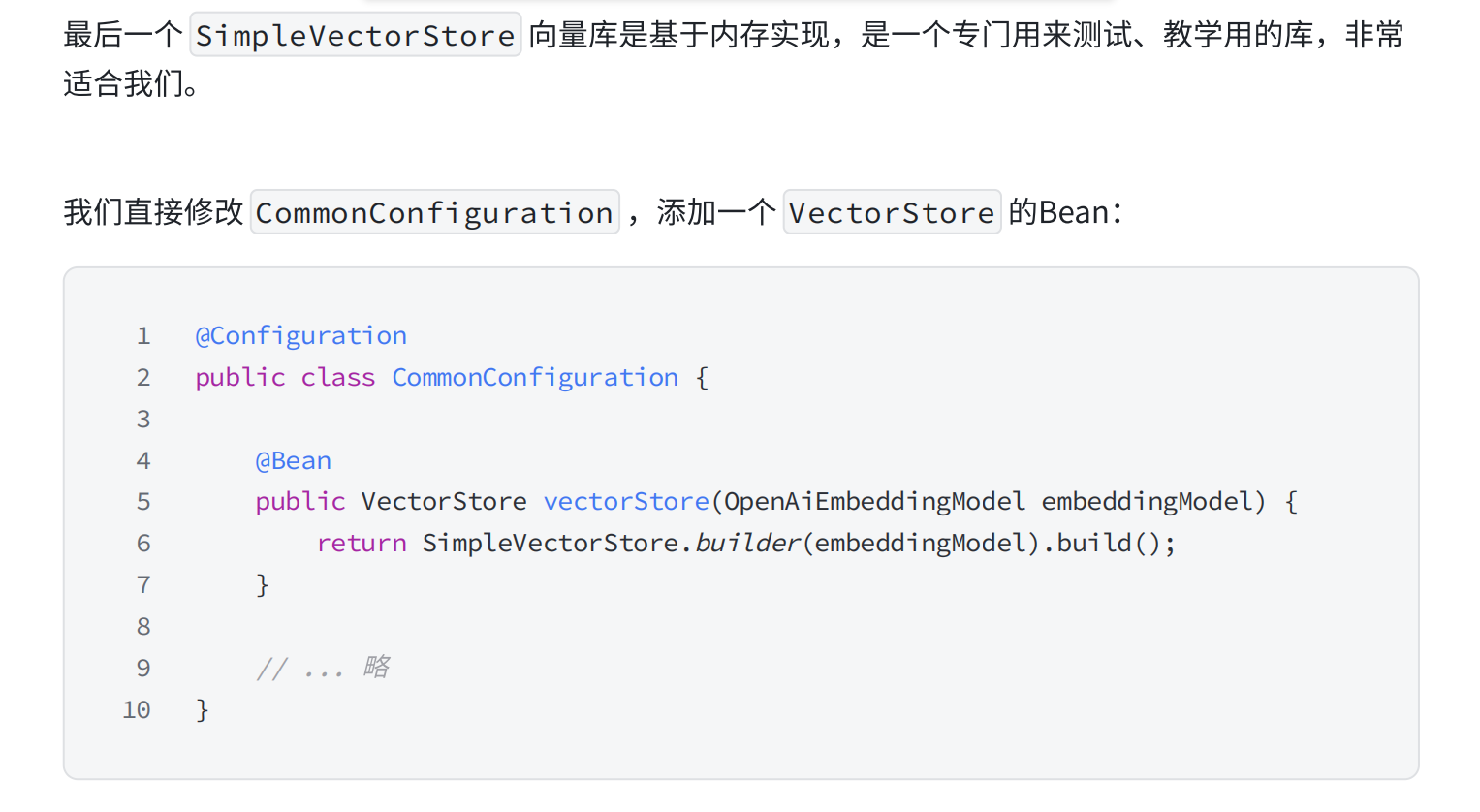
2.配置向量数据库
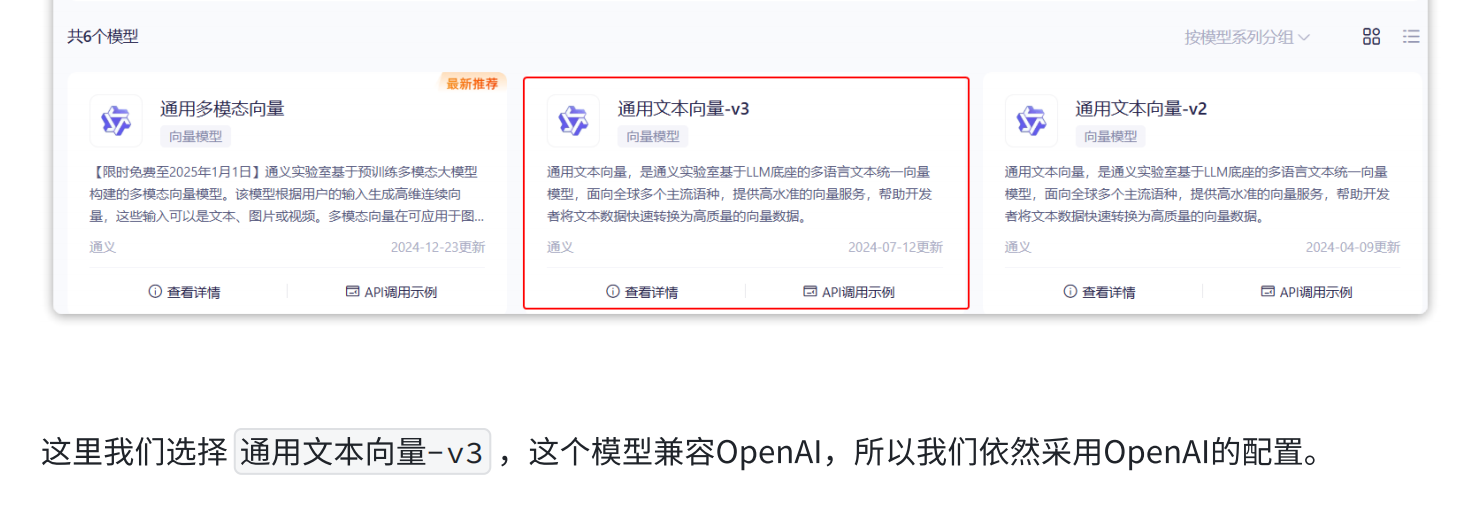
形参里就是向量模型

3.向量模型


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)