世界模型:给普通人看的“AI 小脑”说明书
世界模型是AI模拟物理世界的"预演系统",通过感知压缩和未来推演让AI先在虚拟环境试错。它将传感器数据转化为场景理解(如交通灯状态),用算法模拟不同动作的后果(如加速/减速),选择最优方案执行。相比擅长语言处理的大模型,世界模型专精物理规律预测,应用在自动驾驶等领域。华为的WEWA架构已将其用于智能驾驶,实现快速决策。该技术面临物理准确性、数据需求等挑战,但与大模型融合将是AI
一句话先讲清
世界模型就是 AI 的“小脑”:先在脑子里快速过一遍“如果这么做会怎样”,再决定要不要真的去做。
1. 它到底在做什么?
想象你在厨房,手里端着热汤,面前是一排玻璃杯。你的大脑不会真的把汤倒进去试哪个会裂,而是先在脑子里“跑一遍”:这个杯子厚,应该没问题;那个杯子薄,可能会炸。世界模型就是 AI 的这套“脑内预演”系统。
技术上说,它干两件事:
• 看懂现在:把摄像头、雷达、文字等乱七八糟的输入,压缩成一句“现在发生了什么”。
• 推演未来:给定一个动作(比如左转、刹车),算出 2 秒后世界会变成什么样。
2. 算法傻瓜图解
别怕公式,我们用“快递小哥送外卖”来比喻:
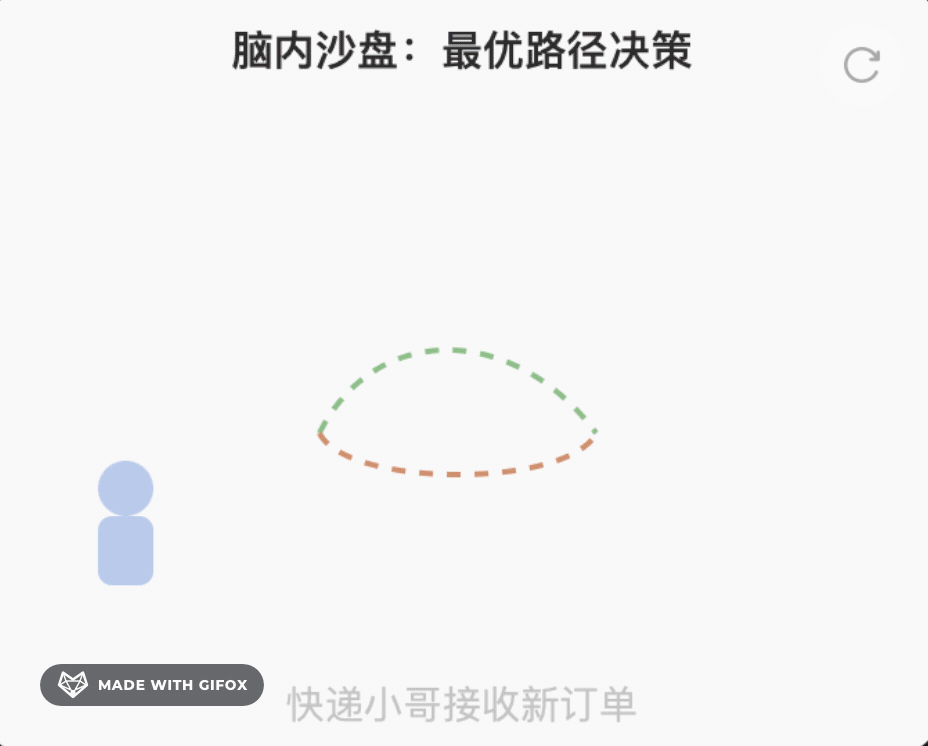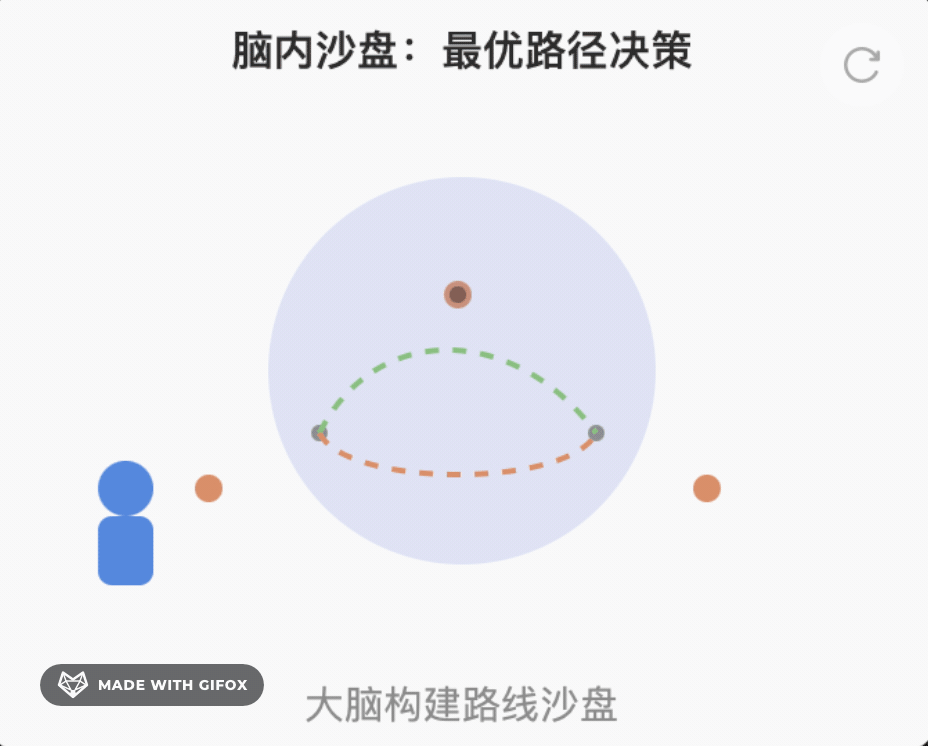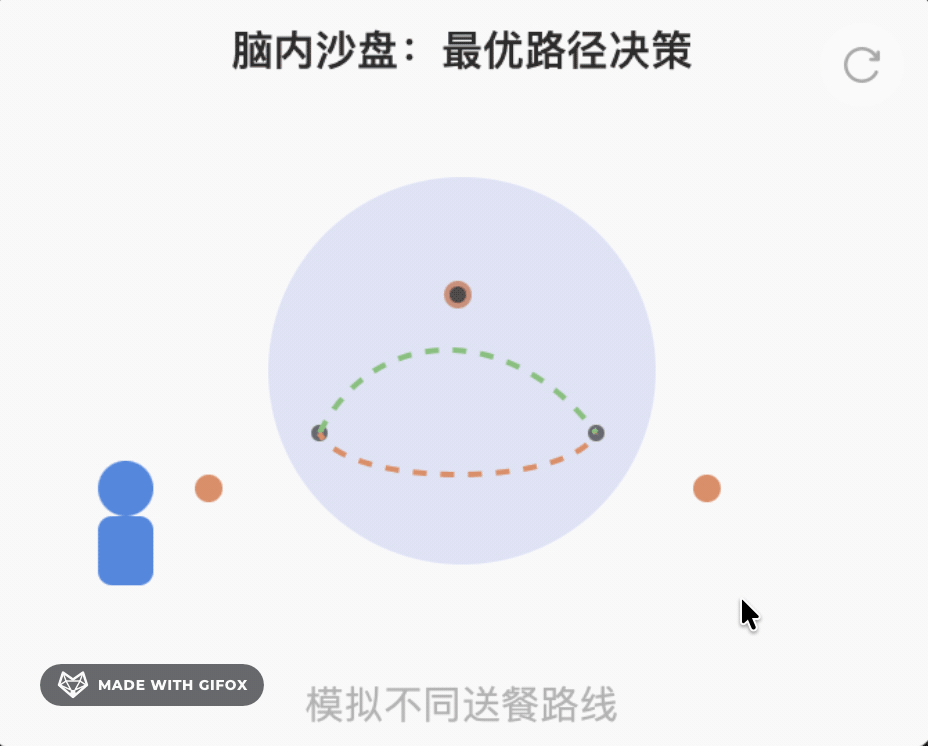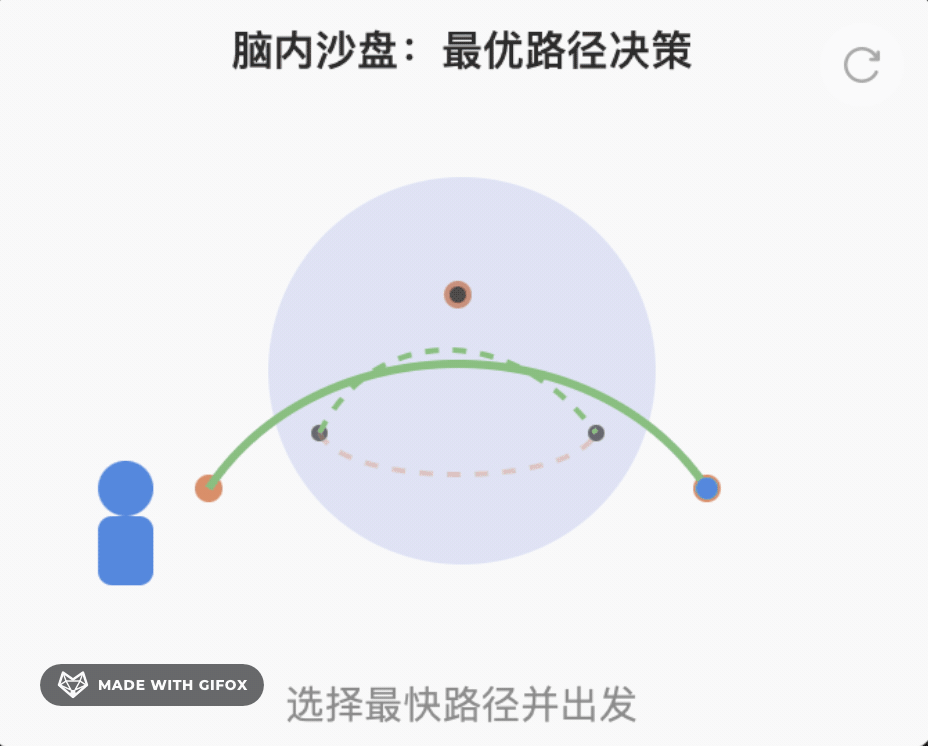
Step 1 感知压缩(打包)
摄像头看到“马路、行人、红绿灯”→ 压缩成一句 token:“十字路口,绿灯 5 秒,行人 3 个”。
Step 2 记忆更新(记路)
用 RNN 或 Transformer 把“上一秒的路况 + 当前动作”变成“下一秒的路况”。就像你在脑子里更新“如果我加速,5 秒后到达路口刚好红灯”。
Step 3 想象未来(模拟)
把可能的动作都试一遍:
• 加速 → 到达路口时红灯,急刹
• 匀速 → 绿灯刚好,顺利通过
• 减速 → 绿灯错过,多等 60 秒
选代价最小的那条。
Step 4 输出动作(执行)
把“匀速通过”翻译成方向盘角度、油门大小,发给汽车。
3. 两种常见“流派”
| 流派 | 像什么 | 擅长 |
|---|---|---|
| 理解型 | 学霸做笔记 | 用少量数据看懂场景规律 |
| 预测型 | 导演拍预告片 | 生成未来视频,做反事实推理 |
Meta V-JEPA 属于前者,NVIDIA Cosmos 属于后者。
4. 真实案例:华为怎么用它开车
华为的 WEWA 架构把世界模型拆成两步:
• World Engine(云端沙盘):用数百万公里真实路采 + 仿真规则训练,能在 100 ms 内想象出“如果前面行人突然横穿”的画面。
• World Action(车端小脑):把想象结果直接变成方向盘、刹车信号,跳过传统“感知→规划→控制”的级联,省 75 % 车端算力。

华为ADS 4.0自动驾驶汽车
5. 为什么它难?
- 物理不准:AI 想象的篮球弹跳高度可能违反牛顿定律。
- 数据饥渴:要“看过”足够多的车祸,才能想象出“如果突然刹车会怎样”。
- 算力黑洞:实时想象 5 秒后的世界,需要云端几十张高端显卡。
一句话总结
世界模型 = 让 AI 先“做梦”再行动,省掉现实世界的试错成本。
🧠✨
6. 世界模型 vs 大模型:一句话看懂区别
核心差异
大模型是"语言专家",世界模型是"物理专家"
五大维度对比
| 维度 | 大模型 | 世界模型 |
| 数据来源 | 文本、书籍、网页 | 摄像头、雷达、传感器 |
| 学习方式 | 统计模式匹配 | 物理规律建模 |
| 核心能力 | 语言生成、知识问答 | 物理预测、场景模拟 |
| 优势场景 | 写作、对话、翻译 | 自动驾驶、机器人控制 |
| 局限性 | 缺乏物理常识 | 语言理解较弱 |
生活化比喻
大模型就像一位读过所有书的图书馆管理员,你问什么它都能引经据典,但可能不知道书从书架上掉下来会砸到脚。
世界模型则像一位经验丰富的工程师,他知道螺丝刀掉地上会弹起来,但可能说不出"螺丝刀"这个词的拉丁语词源。

图书馆管理员与工程师工作场景对比
技术实现差异
大模型的核心是Transformer,处理的是离散的文本token;
世界模型的核心是潜在空间模拟,处理的是连续的感官数据。
技术架构对比
大模型:文本 → Transformer → 文本
世界模型:传感器数据 → 编码器 → 潜在空间模拟 → 预测未来状态
未来趋势:融合而非对立
就像人既有语言能力又有物理直觉一样,最聪明的AI将是两者的结合。Meta的V-JEPA项目就在尝试让大模型"看懂"物理世界,而Sora这样的视频生成模型则在让世界模型"理解"语言描述。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)