【Java手搓RAGFlow】-7- 向量化与Embedding
本文介绍了如何在Java中实现RAG流程的向量化与Embedding步骤。主要内容包括: 向量化的核心作用:将文本转换为高维向量使计算机能够理解语义相似度 选择通义千问text-embedding-v4作为向量模型的原因: 高性价比和学生友好 兼容OpenAI API 完善的文档支持 具体实现方案: 配置Embedding API参数 使用Spring WebClient构建非阻塞HTTP客户端
【Java手搓RAGFlow】-7- 向量化与Embedding
1 引言
在上一章节中,我们成功地将上传的文档解析并切分成了语义相关的文本块(Chunks)。这些文本块是构建我们知识库的基础单元。然而,计算机本身无法理解这些文本的“含义”。为了让机器能够理解和比较文本之间的相似度,我们需要将它们转换成一种数学表示形式——向量。这个过程就是向量化(Vectorization),也常被称为嵌入(Embedding)。
向量化是RAG(检索增强生成)流程的绝对核心。它通过一个深度学习模型(Embedding Model),将每一段文本映射到一个高维空间中的一个点(即一个向量)。在这个空间中,语义上相近的文本,其对应的向量在空间位置上也会更接近。这为我们后续实现“根据用户问题,查找最相关知识”的语义搜索功能奠定了数学基础。
关于向量化的理论,我们在之前的博客 【AI应用探索】-2- RAG初步实战 中已有详细介绍,此处不再赘述。有兴趣的可以看看【AI应用探索】-2- RAG初步实战
在本文中,我们选择通义千问的 text-embedding-v4 作为我们的向量模型。选择它的原因有三:
- 性价比高:对学生和开发者非常友好,提供了大量的免费额度,非常适合学习和开发阶段使用。
- 兼容OpenAI:其API接口设计与OpenAI的规范高度兼容,这意味着我们编写的代码未来可以轻松地切换到其他兼容模型,扩展性好。
- 文档全面:官方文档清晰易懂,便于我们快速集成和调试。
2 配置Embedding
要调用外部的Embedding API,我们首先需要进行相关的配置,包括API的地址、密钥以及我们与API交互的客户端。
2.1 配置参数
在 application.yml 中添加:
embedding:
api:
url: https://dashscope.aliyuncs.com/compatible-mode/v1
key: your-api-key
model: text-embedding-v4
dimension: 2048
2.2 配置WebClient
为了调用外部HTTP API,我们选择使用Spring 3引入的现代化、非阻塞的HTTP客户端——WebClient。
创建com.alibaba.config.WebClientConfig
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.http.HttpHeaders;
import org.springframework.http.MediaType;
import org.springframework.web.reactive.function.client.ExchangeStrategies;
import org.springframework.web.reactive.function.client.WebClient;
/**
* WebClient 配置
* 用于调用外部 Embedding API
*/
@Configuration
public class WebClientConfig {
@Value("${embedding.api.url}")
private String apiUrl;
@Value("${embedding.api.key}")
private String apiKey;
@Bean
public WebClient embeddingWebClient() {
// 配置缓冲区大小(用于处理大响应)
ExchangeStrategies strategies = ExchangeStrategies.builder()
.codecs(configurer -> configurer
.defaultCodecs()
.maxInMemorySize(16 * 1024 * 1024)) // 16MB
.build();
return WebClient.builder()
.baseUrl(apiUrl)
.exchangeStrategies(strategies)
.defaultHeader(HttpHeaders.AUTHORIZATION, "Bearer " + apiKey)
.defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.build();
}
}
2.3 实现EmbeddingClient
EmbeddingClient 是一个专门负责与外部Embedding API进行交互的客户端组件。
业务层只需调用 embeddingClient.embed(texts) 方法,传入文本列表,就能拿到对应的向量列表。
创建com.alibaba.client.EmbeddingClient
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import org.springframework.web.reactive.function.client.WebClient;
import org.springframework.web.reactive.function.client.WebClientResponseException;
import reactor.util.retry.Retry;
import java.time.Duration;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Embedding API 客户端
* 负责调用外部 Embedding API 生成向量
*/
@Component
public class EmbeddingClient {
private static final Logger logger = LoggerFactory.getLogger(EmbeddingClient.class);
@Value("${embedding.api.model}")
private String modelId;
@Value("${embedding.api.batch-size:10}")
private int batchSize;
@Value("${embedding.api.dimension:2048}")
private int dimension;
private final WebClient webClient;
private final ObjectMapper objectMapper;
public EmbeddingClient(WebClient embeddingWebClient, ObjectMapper objectMapper) {
this.webClient = embeddingWebClient;
this.objectMapper = objectMapper;
}
/**
* 批量生成向量
*
* @param texts 文本列表
* @return 向量列表(每个文本对应一个向量)
*/
public List<float[]> embed(List<String> texts) {
try {
logger.info("开始生成向量,文本数量: {}", texts.size());
List<float[]> allVectors = new ArrayList<>(texts.size());
// 分批处理(因为 API 有批量限制)
for (int start = 0; start < texts.size(); start += batchSize) {
int end = Math.min(start + batchSize, texts.size());
List<String> batch = texts.subList(start, end);
logger.debug("调用向量 API,批次: {}-{} (size={})", start, end - 1, batch.size());
// 调用 API
String response = callApiOnce(batch);
// 解析响应
List<float[]> vectors = parseVectors(response);
allVectors.addAll(vectors);
}
logger.info("成功生成向量,总数量: {}", allVectors.size());
return allVectors;
} catch (Exception e) {
logger.error("调用向量化 API 失败", e);
throw new RuntimeException("向量生成失败: " + e.getMessage(), e);
}
}
/**
* 调用一次 API
*/
private String callApiOnce(List<String> batch) {
// 构建请求体
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("model", modelId);
requestBody.put("input", batch);
requestBody.put("dimension", dimension);
requestBody.put("encoding_format", "float");
return webClient.post()
.uri("/embeddings")
.bodyValue(requestBody)
.retrieve()
.bodyToMono(String.class)
.retryWhen(Retry.fixedDelay(3, Duration.ofSeconds(1))
.filter(e -> e instanceof WebClientResponseException))
.block(Duration.ofSeconds(30));
}
/**
* 解析 API 响应,提取向量
*/
private List<float[]> parseVectors(String response) throws Exception {
JsonNode jsonNode = objectMapper.readTree(response);
JsonNode data = jsonNode.get("data");
if (data == null || !data.isArray()) {
throw new RuntimeException("API 响应格式错误: data 字段不存在或不是数组");
}
List<float[]> vectors = new ArrayList<>();
for (JsonNode item : data) {
JsonNode embedding = item.get("embedding");
if (embedding != null && embedding.isArray()) {
float[] vector = new float[embedding.size()];
for (int i = 0; i < embedding.size(); i++) {
vector[i] = (float) embedding.get(i).asDouble();
}
vectors.add(vector);
}
}
return vectors;
}
}
3 实现VectorizationService
3.1 创建TextChunk 实体
我们先定义一个简单的DTO
我们在数据库中持久化文本块使用的是 DocumentVector 实体,它是一个与JPA绑定的重对象。而在向量化流程中,我们其实只需要文本块的ID和内容。创建一个轻量级的 TextChunk DTO,可以实现逻辑与持久化的解耦。服务层处理的是简单的 TextChunk 对象,而不需要关心数据库的复杂细节,这使得代码更清晰,职责更单一。
创建com.alibaba.entity.TextChunk
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* 文本块实体(用于向量化)
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class TextChunk {
private Integer chunkId;
private String content;
}
3.2 创建EsDocument实体
类似地,我们创建一个 EsDocument DTO
这个类预先定义了我们向量数据库中一条记录的完整 schéma。它聚合了向量化流程中产生的所有重要信息:原始文件信息(fileMd5),文本块信息(chunkId, content),生成的向量(vector),以及用于检索和权限控制的元数据(userId, orgTag, isPublic等)。在流程的最后,我们会将这个对象序列化为JSON并存入Elasticsearch。
创建com.alibaba.entity.EsDocument
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* Elasticsearch 文档实体
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class EsDocument {
private String id; // ES 文档 ID
private String fileMd5; // 文件 MD5
private Integer chunkId; // 文本块 ID
private String content; // 文本内容
private float[] vector; // 向量
private String model; // 使用的模型
private String userId; // 用户ID
private String orgTag; // 组织标签
private boolean isPublic; // 是否公开
}
3.3 创建VectorizationService
现在,我们来构建 VectorizationService:
- 从数据库加载文本块。
- 调用 EmbeddingClient 将文本转换为向量。
- 将文本、向量和元数据组装成 EsDocument 对象。
- (下一步)将 EsDocument 存储到Elasticsearch中。
创建com.alibaba.service.VectorizationService
package com.alibaba.service;
import com.alibaba.client.EmbeddingClient;
import com.alibaba.entity.EsDocument;
import com.alibaba.entity.TextChunk;
import com.alibaba.model.DocumentVector;
import com.alibaba.repository.DocumentVectorRepository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.UUID;
import java.util.stream.IntStream;
/**
* 向量化服务
* 负责将文本块转换为向量并存储
*/
@Service
public class VectorizationService {
private static final Logger logger = LoggerFactory.getLogger(VectorizationService.class);
@Autowired
private EmbeddingClient embeddingClient;
//@Autowired
//private ElasticsearchService elasticsearchService; // 下一章实现
@Autowired
private DocumentVectorRepository documentVectorRepository;
/**
* 执行向量化操作
*
* @param fileMd5 文件 MD5
* @param userId 用户ID
* @param orgTag 组织标签
* @param isPublic 是否公开
*/
public void vectorize(String fileMd5, String userId, String orgTag, boolean isPublic) {
try {
logger.info("开始向量化文件,fileMd5: {}, userId: {}, orgTag: {}, isPublic: {}",
fileMd5, userId, orgTag, isPublic);
// 1. 获取文件分块内容
List<TextChunk> chunks = fetchTextChunks(fileMd5);
if (chunks == null || chunks.isEmpty()) {
logger.warn("未找到分块内容,fileMd5: {}", fileMd5);
return;
}
logger.info("获取到 {} 个文本块", chunks.size());
// 2. 提取文本内容
List<String> texts = chunks.stream()
.map(TextChunk::getContent)
.toList();
// 3. 调用 Embedding API 生成向量
logger.info("开始调用 Embedding API 生成向量");
List<float[]> vectors = embeddingClient.embed(texts);
logger.info("向量生成完成,共 {} 个向量", vectors.size());
// 4. 构建 Elasticsearch 文档
List<EsDocument> esDocuments = IntStream.range(0, chunks.size())
.mapToObj(i -> new EsDocument(
UUID.randomUUID().toString(), // ES 文档 ID
fileMd5,
chunks.get(i).getChunkId(),
chunks.get(i).getContent(),
vectors.get(i), // 对应的向量
"text-embedding-v4", // 模型名称
userId,
orgTag,
isPublic
))
.toList();
// 5. 批量存储到 Elasticsearch(下一章实现)
logger.info("开始存储向量到 Elasticsearch");
//elasticsearchService.bulkIndex(esDocuments);
logger.info("向量存储完成");
logger.info("向量化完成,fileMd5: {}", fileMd5);
} catch (Exception e) {
logger.error("向量化失败,fileMd5: {}", fileMd5, e);
throw new RuntimeException("向量化失败: " + e.getMessage(), e);
}
}
/**
* 获取文件分块内容
*/
private List<TextChunk> fetchTextChunks(String fileMd5) {
// 从数据库获取分块内容
List<DocumentVector> vectors = documentVectorRepository.findByFileMd5(fileMd5);
// 转换为 TextChunk 列表
return vectors.stream()
.map(vector -> new TextChunk(
vector.getChunkId(),
vector.getTextContent()
))
.toList();
}
}
因为我们的向量化的数据最后存在es里,我们下一章再实现es相关,先把结构搭建起来。
3.4 创建VectorizationController
最后,我们创建com.alibaba.controller.VectorizationController
import com.baoragflow.service.VectorizationService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.util.Map;
/**
* 向量化控制器
*/
@RestController
@RequestMapping("/api/v1/vectorize")
public class VectorizationController {
@Autowired
private VectorizationService vectorizationService;
/**
* 向量化文件
*/
@PostMapping("/{fileMd5}")
public ResponseEntity<?> vectorizeFile(
@PathVariable String fileMd5,
@RequestParam(value = "orgTag", required = false) String orgTag,
@RequestParam(value = "isPublic", required = false, defaultValue = "false") boolean isPublic,
@RequestAttribute("userId") String userId) {
try {
vectorizationService.vectorize(fileMd5, userId, orgTag, isPublic);
return ResponseEntity.ok(Map.of(
"code", 200,
"message", "向量化成功",
"data", Map.of("fileMd5", fileMd5)
));
} catch (Exception e) {
return ResponseEntity.status(500)
.body(Map.of("code", 500, "message", "向量化失败: " + e.getMessage()));
}
}
}
4 测试
项目成功启动
4.1 测试向量化文件接口
POST “http://localhost:8081/api/v1/vectorize/$FILE_MD5”
操作前提:和文档解析一样,你必须先上传一个文件,获得其MD5值,然后才能对它进行向量化。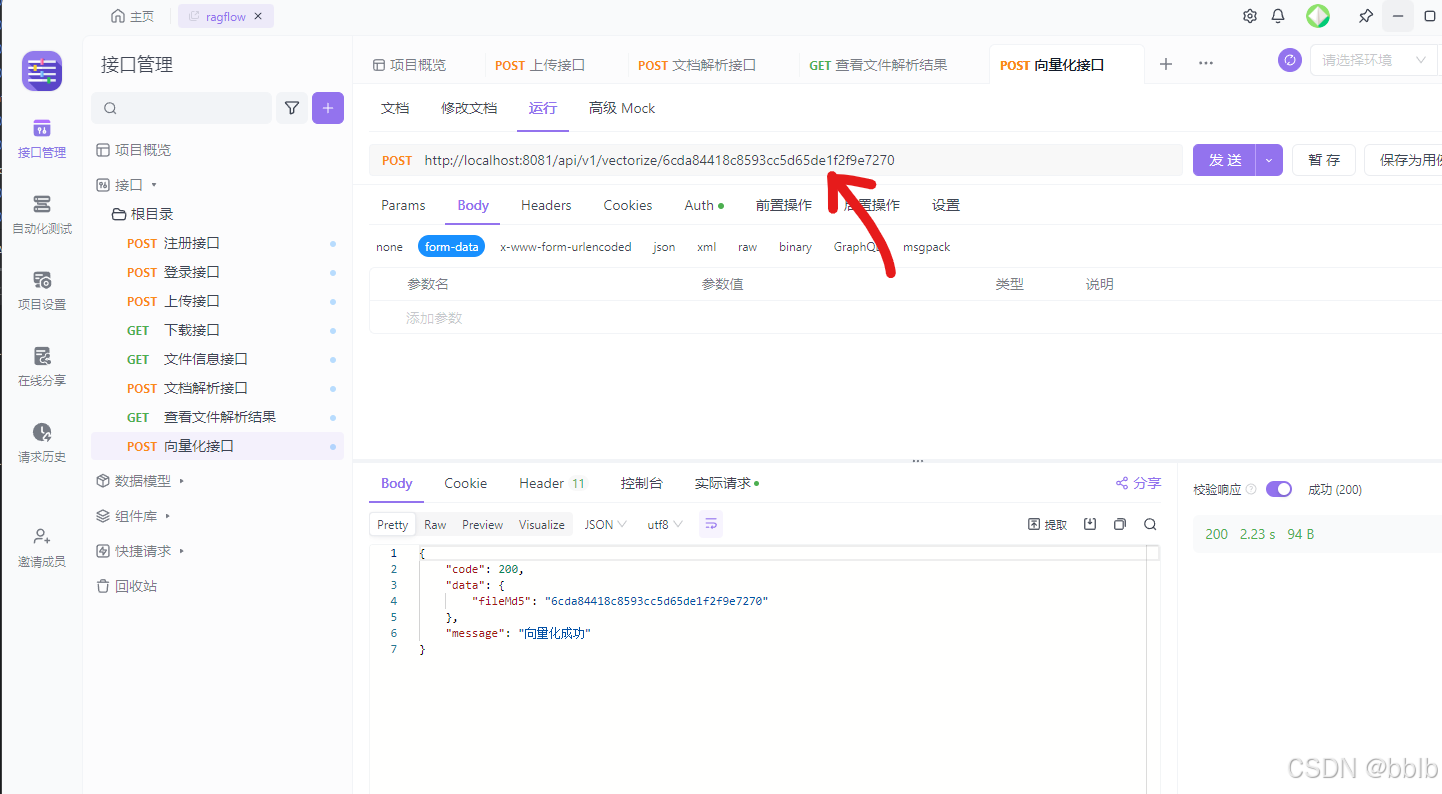
返回成功
我们观察日志: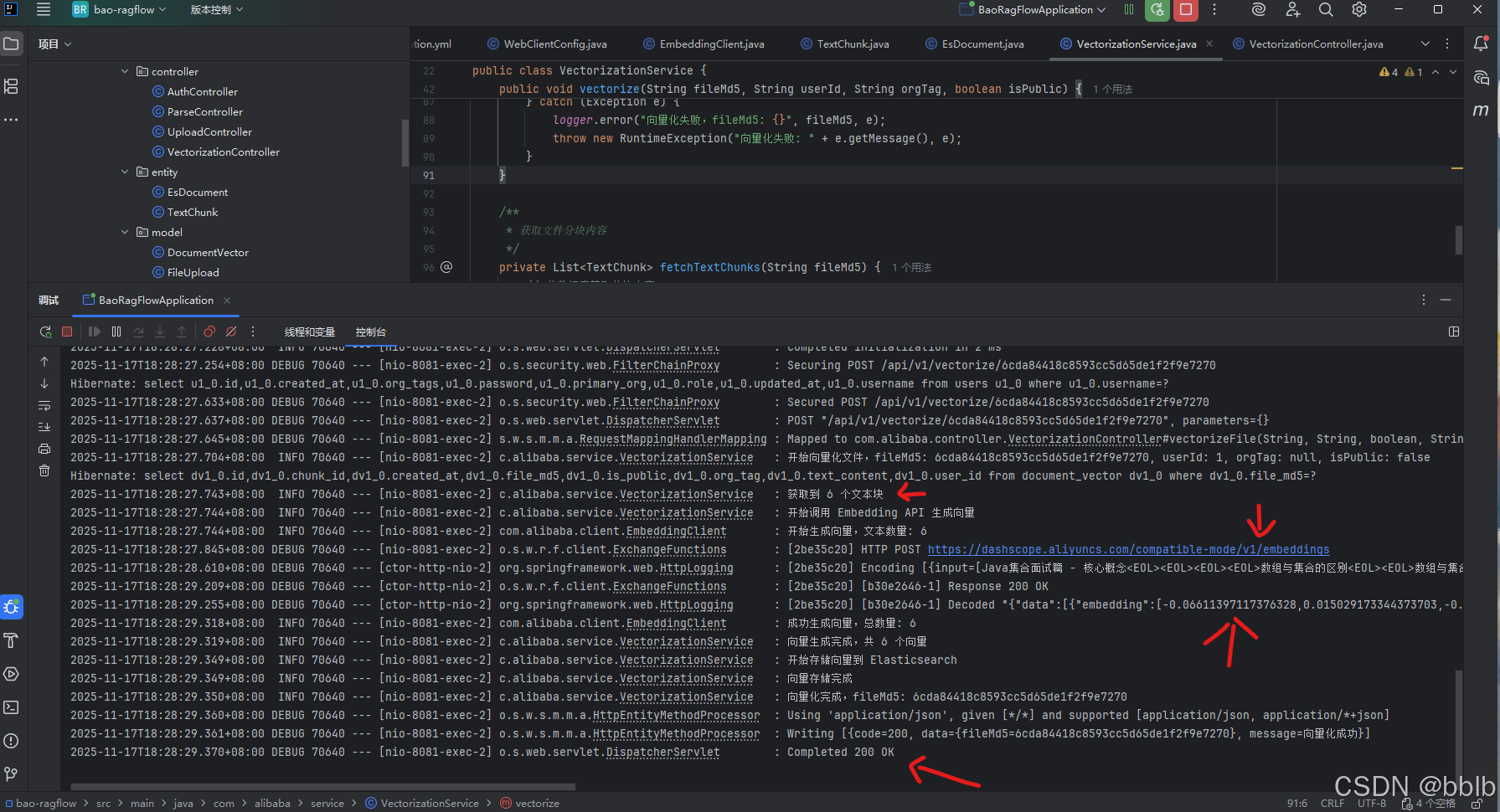
从日志中我们可以清晰地看到:
- 服务成功启动了对特定 fileMd5 的向量化任务。
- 从数据库中获取到了我们上一章解析出的文本块(日志中显示为 "获取到6个chunk)。
- EmbeddingClient 开始分批调用API。
- 最终,日志显示“向量生成完成,共生成6个向量”。
证明了我们的整个数据流是通畅的:Controller接收请求 -> Service从数据库拉取数据 -> Client调用外部API将文本转换为向量 -> Service组装最终数据。
至此,我们已经成功跨越了RAG流程中最关键的技术门槛。下一步,就是将这些宝贵的向量数据存入一个专业的向量数据库中,以便进行高效的相似度检索。下一章,我们将集成Elasticsearch!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)